ভেক্টর এমবেডিং কি?
ভেক্টর এমবেডিং হল সাংখ্যিক উপস্থাপনা যা শব্দ, বাক্যাংশ এবং অন্যান্য ডেটা প্রকারের সম্পর্ক এবং অর্থ ক্যাপচার করে। ভেক্টর এম্বেডিংয়ের মাধ্যমে, একটি বস্তুর প্রয়োজনীয় বৈশিষ্ট্য বা বৈশিষ্ট্যগুলিকে একটি সংক্ষিপ্ত এবং সংগঠিত সংখ্যার বিন্যাসে অনুবাদ করা হয়, যা কম্পিউটারকে দ্রুত তথ্য পুনরুদ্ধার করতে সহায়তা করে। একটি বহুমাত্রিক স্থানের বিন্দুতে অনুবাদ করার পরে অনুরূপ ডেটা পয়েন্টগুলিকে একসাথে ক্লাস্টার করা হয়।
বিস্তৃত অ্যাপ্লিকেশনে ব্যবহৃত হয়, বিশেষ করে প্রাকৃতিক ভাষা প্রক্রিয়াকরণে (NLP) এবং মেশিন লার্নিং (ML), ভেক্টর এম্বেডিংগুলি সাদৃশ্য তুলনা, ক্লাস্টারিং এবং শ্রেণীবিভাগের মতো কাজের জন্য ডেটা ম্যানিপুলেট এবং প্রক্রিয়া করতে সহায়তা করে। যেমন টেক্সট ডেটা দেখার সময়, যেমন শব্দ বিড়াল এবং বিড়ালছানা তাদের অক্ষর গঠনে পার্থক্য থাকা সত্ত্বেও একই অর্থ প্রকাশ করে। কার্যকর শব্দার্থক অনুসন্ধান সুনির্দিষ্ট উপস্থাপনাগুলির উপর নির্ভর করে যা পদগুলির মধ্যে এই শব্দার্থিক সাদৃশ্যকে পর্যাপ্তভাবে ক্যাপচার করে।
[এম্বেড করা সামগ্রী]
এমবেডিং এবং ভেক্টর কি একই জিনিস?
শর্তাবলী ভেক্টর এবং এমবেডিং ভেক্টর এমবেডিং এর প্রেক্ষাপটে বিনিময়যোগ্যভাবে ব্যবহার করা যেতে পারে। তারা উভয়ই সাংখ্যিক তথ্য উপস্থাপনা উল্লেখ করে যার মধ্যে প্রতিটি তথ্যকেন্দ্র একটি উচ্চ-মাত্রিক স্থান একটি ভেক্টর হিসাবে প্রতিনিধিত্ব করা হয়.
ভেক্টর একটি সংজ্ঞায়িত মাত্রা সহ সংখ্যার একটি বিন্যাস বোঝায়, যখন ভেক্টর এম্বেডিংগুলি একটি অবিচ্ছিন্ন স্থানের ডেটা পয়েন্টগুলিকে উপস্থাপন করতে এই ভেক্টরগুলি ব্যবহার করে।
এই নিবন্ধটি অংশ
এমবেডিংগুলি উল্লেখযোগ্য তথ্য, শব্দার্থিক লিঙ্ক, প্রাসঙ্গিক গুণাবলী বা প্রশিক্ষণ অ্যালগরিদমের মাধ্যমে শেখা ডেটার সংগঠিত উপস্থাপনা ক্যাপচার করার জন্য ভেক্টর হিসাবে ডেটা প্রকাশ করাকে বোঝায় বা মেশিন লার্নিং মডেল.
ভেক্টর এমবেডিং এর প্রকার
ভেক্টর এমবেডিংগুলি বিভিন্ন ধরণের আকারে আসে, প্রতিটিতে বিভিন্ন ধরণের ডেটা উপস্থাপনের জন্য একটি স্বতন্ত্র ফাংশন থাকে। নিম্নলিখিত ভেক্টর এমবেডিংয়ের কিছু সাধারণ প্রকার রয়েছে:
- শব্দ এমবেডিং. শব্দ এমবেডিংগুলি একটি অবিচ্ছিন্ন স্থানে পৃথক শব্দের ভেক্টর উপস্থাপনা। এগুলি প্রায়শই কাজের মধ্যে শব্দগুলির মধ্যে শব্দার্থিক লিঙ্কগুলি ক্যাপচার করতে ব্যবহৃত হয় যেমন অনুভূতির বিশ্লেষণ, ভাষা অনুবাদ এবং শব্দের মিল।
- বাক্য এমবেডিং। সম্পূর্ণ বাক্যের ভেক্টর উপস্থাপনাকে বাক্য এমবেডিং বলা হয়। তারা অনুভূতি বিশ্লেষণ, পাঠ্য শ্রেণীকরণ এবং তথ্য পুনরুদ্ধার সহ কাজের জন্য সহায়ক কারণ তারা বাক্যের অর্থ এবং প্রসঙ্গ ক্যাপচার করে।
- নথি এমবেডিং. নথি এমবেডিং হল সম্পূর্ণ নথির ভেক্টর উপস্থাপনা, যেমন নিবন্ধ বা প্রতিবেদন। সাধারণত নথির মিল, ক্লাস্টারিং এবং সুপারিশ সিস্টেমের মতো কাজে ব্যবহৃত হয়, তারা নথির সাধারণ অর্থ এবং বিষয়বস্তু ক্যাপচার করে।
- ব্যবহারকারীর প্রোফাইল ভেক্টর। এগুলি ব্যবহারকারীর পছন্দ, ক্রিয়া বা বৈশিষ্ট্যের ভেক্টর উপস্থাপনা। তারা ব্যবহার করা হয় গ্রাহক বিভাজন, ব্যক্তিগতকৃত সুপারিশ সিস্টেম এবং ব্যবহারকারী-নির্দিষ্ট ডেটা সংগ্রহ করতে লক্ষ্যযুক্ত বিজ্ঞাপন।
- ইমেজ ভেক্টর। এগুলি ভিজ্যুয়াল আইটেমগুলির ভেক্টর উপস্থাপনা, যেমন ছবি বা ভিডিও ফ্রেম। তারা যেমন কাজ ব্যবহার করছি বস্তু স্বীকৃতি, চিত্র অনুসন্ধান এবং বিষয়বস্তু ভিত্তিক সুপারিশ সিস্টেম চাক্ষুষ বৈশিষ্ট্য ক্যাপচার.
- পণ্য ভেক্টর। পণ্য বা আইটেমগুলিকে ভেক্টর হিসাবে উপস্থাপন করে, এগুলি পণ্য অনুসন্ধানে, পণ্যের শ্রেণিবিন্যাস এবং সুপারিশ সিস্টেমগুলিতে পণ্যগুলির মধ্যে বৈশিষ্ট্য এবং মিল সংগ্রহ করতে ব্যবহৃত হয়।
- ব্যবহারকারীর প্রোফাইল ভেক্টর। ব্যবহারকারীর প্রোফাইল ভেক্টর একটি ব্যবহারকারীর পছন্দ, কর্ম বা বৈশিষ্ট্য প্রতিনিধিত্ব করে। তারা ব্যবহারকারী বিভাজন, ব্যক্তিগতকৃত সুপারিশ সিস্টেম এবং ব্যবহার করা হয় লক্ষ্যযুক্ত বিজ্ঞাপন ব্যবহারকারী-নির্দিষ্ট ডেটা সংগ্রহ করতে।
কিভাবে ভেক্টর এমবেডিং তৈরি করা হয়?
ভেক্টর এমবেডিংগুলি একটি এমএল পদ্ধতির ব্যবহার করে তৈরি করা হয় যা একটি মডেলকে ডেটাকে সংখ্যাসূচক ভেক্টরে পরিণত করতে প্রশিক্ষণ দেয়। সাধারণত, একটি গভীর কনভোলশনাল নিউরাল নেটওয়ার্ক এই ধরনের মডেল প্রশিক্ষণের জন্য ব্যবহৃত হয়। ফলস্বরূপ এমবেডিংগুলি প্রায়শই ঘন হয় — সমস্ত মান শূন্য নয় — এবং উচ্চ মাত্রিক — 2,000 মাত্রা পর্যন্ত। জনপ্রিয় মডেল যেমন Word2Vec, GLoVE এবং বার্ট টেক্সট ডেটার জন্য ভেক্টর এম্বেডিং-এ শব্দ, বাক্যাংশ বা অনুচ্ছেদ রূপান্তর করুন।
নিম্নলিখিত পদক্ষেপগুলি সাধারণত প্রক্রিয়াটিতে জড়িত থাকে:
- একটি বড় ডেটা সেট একত্রিত করুন। নির্দিষ্ট ডেটা বিভাগ ক্যাপচার করা একটি ডেটা সেট যার জন্য এম্বেডিং করা হয়েছে — তা পাঠ্য বা চিত্রের সাথে সম্পর্কিত হোক — একত্রিত করা হয়।
- ডেটা প্রিপ্রসেস করুন। তথ্যের প্রকারের উপর নির্ভর করে, পরিষ্কার করা, প্রস্তুতি এবং ডেটা প্রিপ্রোসেসিং গোলমাল দূর করা, ফটোর আকার পরিবর্তন করা, পাঠ্যকে স্বাভাবিক করা এবং অতিরিক্ত ক্রিয়াকলাপ করা জড়িত।
- মডেলকে প্রশিক্ষণ দিন। ডেটাতে লিঙ্ক এবং প্যাটার্ন সনাক্ত করতে, মডেলটিকে ডেটা সেট ব্যবহার করে প্রশিক্ষণ দেওয়া হয়। লক্ষ্য এবং পূর্বাভাসিত ভেক্টরের মধ্যে বৈষম্য কমাতে, প্রশিক্ষণ পর্বের সময় পূর্বপ্রশিক্ষিত মডেলের পরামিতিগুলি পরিবর্তন করা হয়।
- ভেক্টর এমবেডিং তৈরি করুন। প্রশিক্ষণের পরে, মডেলটি নতুন ডেটাকে সংখ্যাসূচক ভেক্টরে রূপান্তর করতে পারে, একটি অর্থবহ এবং কাঠামোগত উপস্থাপনা উপস্থাপন করে যা কার্যকরভাবে মূল ডেটার শব্দার্থিক তথ্যকে এনক্যাপসুলেট করে।
ভেক্টর এম্বেডিংগুলি টাইম সিরিজ ডেটা, টেক্সট, ছবি, অডিও সহ বিভিন্ন ধরণের ডেটার জন্য তৈরি করা যেতে পারে। ত্রিমাত্রিক (3D) মডেল এবং ভিডিও। এম্বেডিংগুলি যেভাবে গঠিত হয় তার কারণে, অনুরূপ শব্দার্থবিশিষ্ট বস্তুগুলির ভেক্টর স্থানগুলিতে ভেক্টর থাকবে যা একে অপরের কাছাকাছি।
ভেক্টর এমবেডিং কোথায় সংরক্ষণ করা হয়?
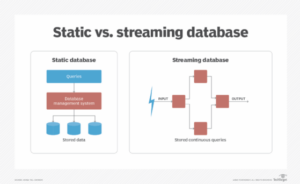
ভেক্টর এম্বেডিং বিশেষায়িত ডাটাবেসের ভিতরে সংরক্ষণ করা হয় যা নামে পরিচিত ভেক্টর ডাটাবেস. এই ডেটাবেসগুলি ডেটা বৈশিষ্ট্যগুলির উচ্চ-মাত্রিক গাণিতিক উপস্থাপনা। স্ট্যান্ডার্ড স্কেলার-ভিত্তিক ডেটাবেস বা স্বাধীন ভেক্টর সূচকের বিপরীতে, ভেক্টর ডেটাবেসগুলি স্কেলে ভেক্টর এম্বেডিংগুলি সংরক্ষণ এবং পুনরুদ্ধারের জন্য নির্দিষ্ট দক্ষতা প্রদান করে। তারা ভেক্টর অনুসন্ধান ফাংশনগুলির জন্য বিপুল পরিমাণ ডেটা কার্যকরভাবে সঞ্চয় এবং পুনরুদ্ধার করার ক্ষমতা প্রদান করে।
ভেক্টর ডাটাবেসে কর্মক্ষমতা সহ বেশ কিছু মূল উপাদান অন্তর্ভুক্ত থাকে দোষ সহনশীলতা. ভেক্টর ডাটাবেসগুলি ত্রুটি-সহনশীল, প্রতিলিপিকরণ এবং শারডিং কৌশল ব্যবহার করা হয়। প্রতিলিপি হল অসংখ্য নোড জুড়ে ডেটার কপি তৈরি করার প্রক্রিয়া, যেখানে শার্ডিং হল বিভিন্ন নোডের উপর ডেটা বিভাজন করার প্রক্রিয়া। এটি একটি নোড ব্যর্থ হলেও ত্রুটি সহনশীলতা এবং নিরবচ্ছিন্ন কর্মক্ষমতা প্রদান করে।
ভেক্টর ডাটাবেস মেশিন লার্নিং এবং কৃত্রিম বুদ্ধিমত্তার ক্ষেত্রে কার্যকরী (AI) অ্যাপ্লিকেশন, যেহেতু তারা পরিচালনায় বিশেষজ্ঞ অসংগঠিত এবং আধা কাঠামোগত ডেটা.
ভেক্টর এমবেডিংয়ের অ্যাপ্লিকেশন
বিভিন্ন শিল্প জুড়ে ভেক্টর এমবেডিংয়ের জন্য বিভিন্ন ব্যবহার রয়েছে। ভেক্টর এম্বেডিংয়ের সাধারণ অ্যাপ্লিকেশনগুলির মধ্যে নিম্নলিখিতগুলি অন্তর্ভুক্ত রয়েছে:
- সুপারিশ সিস্টেম. Netflix এবং Amazon সহ শিল্প জায়ান্টদের সুপারিশ সিস্টেমে ভেক্টর এম্বেডিং একটি গুরুত্বপূর্ণ ভূমিকা পালন করে। এই এমবেডিংগুলি সংস্থাগুলিকে ব্যবহারকারী এবং আইটেমগুলির মধ্যে মিলগুলি গণনা করতে দেয়, ব্যবহারকারীর পছন্দগুলি এবং আইটেম বৈশিষ্ট্যগুলিকে ভেক্টরে অনুবাদ করে৷ এই প্রক্রিয়াটি স্বতন্ত্র ব্যবহারকারীর পছন্দ অনুসারে ব্যক্তিগতকৃত পরামর্শ প্রদানে সহায়তা করে।
- সার্চ ইঞ্জিন. সার্চ ইঞ্জিন তথ্য পুনরুদ্ধারের কার্যকারিতা এবং দক্ষতা উন্নত করতে ব্যাপকভাবে ভেক্টর এম্বেডিং ব্যবহার করুন। যেহেতু ভেক্টর এম্বেডিংগুলি কীওয়ার্ড মিলের বাইরে যায়, তাই তারা অনুসন্ধান ইঞ্জিনগুলিকে শব্দ এবং বাক্যের অর্থ ব্যাখ্যা করতে সহায়তা করে। এমনকি যখন সঠিক বাক্যাংশগুলি মেলে না, তখনও সার্চ ইঞ্জিনগুলি শব্দার্থক স্থানে ভেক্টর হিসাবে শব্দের মডেলিং করে প্রাসঙ্গিকভাবে প্রাসঙ্গিক নথি বা অন্যান্য তথ্য খুঁজে পেতে এবং পুনরুদ্ধার করতে পারে৷
- চ্যাটবট এবং প্রশ্ন-উত্তর সিস্টেম। ভেক্টর এমবেডিং সহায়তা চ্যাটবট এবং জেনারেটিভ এআই-ভিত্তিক প্রশ্ন-উত্তর সিস্টেম মানুষের মত প্রতিক্রিয়া বোঝার এবং উত্পাদন. পাঠ্যের প্রসঙ্গ এবং অর্থ ক্যাপচার করে, এম্বেডিংগুলি চ্যাটবটগুলিকে অর্থপূর্ণ এবং যৌক্তিক উপায়ে ব্যবহারকারীর জিজ্ঞাসার উত্তর দিতে সহায়তা করে। উদাহরণস্বরূপ, ভাষা মডেল এবং এআই চ্যাটবট সহ GPT-4 এবং ইমেজ প্রসেসর যেমন ডাল-ই 2, মানুষের মত কথোপকথন এবং প্রতিক্রিয়া তৈরি করার জন্য ব্যাপক জনপ্রিয়তা অর্জন করেছে।
- জালিয়াতি সনাক্তকরণ এবং বহিরাগত সনাক্তকরণ। ভেক্টর এম্বেডিংগুলি ভেক্টরগুলির মধ্যে সাদৃশ্য মূল্যায়ন করে অসামঞ্জস্যতা বা প্রতারণামূলক কার্যকলাপ সনাক্ত করতে ব্যবহার করা যেতে পারে। এম্বেডিং এবং পিনপয়েন্টিংয়ের মধ্যে দূরত্ব মূল্যায়ন করে অস্বাভাবিক নিদর্শনগুলি চিহ্নিত করা হয় বহিরাগত.
- ডেটা প্রিপ্রসেসিং। পরিবর্তন করতে ML-এর জন্য উপযুক্ত এমন একটি বিন্যাসে আনপ্রসেসড ডেটা এবং গভীর শিক্ষার মডেল, এমবেডিংগুলি ডেটা প্রিপ্রসেসিং কার্যক্রমে ব্যবহৃত হয়। উদাহরণস্বরূপ, শব্দ এমবেডিংগুলি ভেক্টর হিসাবে শব্দগুলিকে উপস্থাপন করতে ব্যবহৃত হয়, যা পাঠ্য ডেটা প্রক্রিয়াকরণ এবং বিশ্লেষণের সুবিধা দেয়।
- এক-শট এবং শূন্য-শট শিক্ষা। ওয়ান-শট এবং জিরো-শট লার্নিং হল ভেক্টর এম্বেডিং পদ্ধতি যা মেশিন লার্নিং মডেলগুলিকে সীমিত লেবেলযুক্ত ডেটা সরবরাহ করা হলেও নতুন ক্লাসের ফলাফলের পূর্বাভাস দিতে সাহায্য করে। মডেলগুলি এম্বেডিং-এ অন্তর্ভুক্ত শব্দার্থিক তথ্য ব্যবহার করে অল্প সংখ্যক প্রশিক্ষণের দৃষ্টান্তের সাথেও সাধারণীকরণ এবং পূর্বাভাস তৈরি করতে পারে।
- শব্দার্থগত মিল এবং ক্লাস্টারিং। ভেক্টর এম্বেডিংগুলি উচ্চ-মাত্রিক পরিবেশে দুটি বস্তু কতটা অনুরূপ তা পরিমাপ করা সহজ করে। এটি কম্পিউটিং শব্দার্থিক সাদৃশ্য, ক্লাস্টারিং এবং তাদের এমবেডিংয়ের উপর ভিত্তি করে সম্পর্কিত জিনিসগুলিকে একত্রিত করার মতো অপারেশনগুলি করা সম্ভব করে তোলে।
কি ধরনের জিনিস এমবেড করা যেতে পারে?
ভেক্টর এমবেডিং ব্যবহার করে বিভিন্ন ধরণের অবজেক্ট এবং ডেটা টাইপ উপস্থাপন করা যেতে পারে। এম্বেড করা যেতে পারে এমন সাধারণ ধরণের জিনিসগুলির মধ্যে নিম্নলিখিতগুলি অন্তর্ভুক্ত রয়েছে:
পাঠ
টেক্সট এম্বেডিং ব্যবহার করে শব্দ, বাক্যাংশ বা নথি ভেক্টর হিসেবে উপস্থাপন করা হয়। এনএলপি কাজগুলি - সেন্টিমেন্ট বিশ্লেষণ, শব্দার্থিক অনুসন্ধান এবং ভাষা অনুবাদ সহ - প্রায়শই এম্বেডিং ব্যবহার করে।
ইউনিভার্সাল সেন্টেন্স এনকোডার হল সবচেয়ে জনপ্রিয় ওপেন সোর্স এমবেডিং মডেলগুলির মধ্যে একটি এবং এটি দক্ষতার সাথে পৃথক বাক্য এবং পুরো পাঠ্য অংশগুলিকে এনকোড করতে পারে।
চিত্র
চিত্র এম্বেডিংগুলি ভেক্টর হিসাবে চিত্রগুলির চাক্ষুষ বৈশিষ্ট্যগুলিকে ক্যাপচার করে এবং উপস্থাপন করে। তাদের ব্যবহারের ক্ষেত্রে অবজেক্ট আইডেন্টিফিকেশন, ছবির শ্রেণীবিভাগ এবং বিপরীত চিত্র অনুসন্ধান, প্রায়ই হিসাবে পরিচিত চিত্র দ্বারা অনুসন্ধান.
চিত্র এম্বেডিংগুলি ভিজ্যুয়াল অনুসন্ধান ক্ষমতা সক্ষম করতেও ব্যবহার করা যেতে পারে। ডাটাবেস ইমেজ থেকে এমবেডিং বের করে, একজন ব্যবহারকারী একটি ক্যোয়ারী ইমেজ এর এমবেডিং এর সাথে ডাটাবেস ফটোর এমবেডিং এর সাথে তুলনা করতে পারে ভিজ্যুয়লি একই মিল খুঁজে বের করতে। এটি সাধারণত ব্যবহৃত হয় ই-কমার্স অ্যাপস, যেখানে ব্যবহারকারীরা অনুরূপ পণ্যের ফটো আপলোড করে আইটেমগুলি অনুসন্ধান করতে পারে৷
Google Lens হল একটি ছবি-অনুসন্ধানকারী অ্যাপ্লিকেশন যা ক্যামেরার ফটোগুলিকে দৃশ্যত অনুরূপ পণ্যের সাথে তুলনা করে। উদাহরণস্বরূপ, এটি ইন্টারনেট পণ্যগুলির সাথে মিল করতে ব্যবহার করা যেতে পারে যা একজোড়া স্নিকার্স বা পোশাকের টুকরোগুলির মতো।
Audio
অডিও এমবেডিং হল অডিও সিগন্যালের ভেক্টর উপস্থাপনা। ভেক্টর এম্বেডিংগুলি শ্রবণ বৈশিষ্ট্যগুলি ক্যাপচার করে, সিস্টেমগুলিকে অডিও ডেটা আরও কার্যকরভাবে ব্যাখ্যা করতে দেয়। উদাহরণস্বরূপ, অডিও এম্বেডিংগুলি সঙ্গীত সুপারিশ, জেনার শ্রেণীবিভাগ, অডিও মিল অনুসন্ধান, বক্তৃতা সনাক্তকরণ এবং স্পিকার যাচাইকরণের জন্য ব্যবহার করা যেতে পারে।
যখন AI বিভিন্ন ধরনের এম্বেডিংয়ের জন্য ব্যবহার করা হচ্ছে, তখন অডিও AI টেক্সট বা ইমেজ AI থেকে কম মনোযোগ পেয়েছে। Google স্পিচ-টু-টেক্সট এবং OpenAI হুইস্পার হল অডিও এম্বেডিং অ্যাপ্লিকেশন যেমন কল সেন্টার, চিকিৎসা প্রযুক্তি, অ্যাক্সেসিবিলিটি এবং স্পিচ-টু-টেক্সট অ্যাপ্লিকেশনে ব্যবহৃত।
গ্রাফ
গ্রাফ এম্বেডিং একটি গ্রাফে নোড এবং প্রান্তগুলিকে উপস্থাপন করতে ভেক্টর ব্যবহার করে। তারা গ্রাফ বিশ্লেষণ সম্পর্কিত কাজে ব্যবহৃত যেমন লিঙ্ক পূর্বাভাস, সম্প্রদায় স্বীকৃতি এবং সুপারিশ সিস্টেম।
প্রতিটি নোড একটি সত্তাকে প্রতিনিধিত্ব করে, যেমন একজন ব্যক্তি, একটি ওয়েব পৃষ্ঠা বা একটি পণ্য এবং প্রতিটি প্রান্ত সেই সত্তাগুলির মধ্যে বিদ্যমান লিঙ্ক বা সংযোগের প্রতীক৷ এই ভেক্টর এম্বেডিংগুলি বন্ধুদের সুপারিশ করা থেকে সবকিছু সম্পন্ন করতে পারে৷ সামাজিক যোগাযোগ সাইবার নিরাপত্তা সমস্যা সনাক্ত করতে.
টাইম সিরিজ ডেটা এবং 3D মডেল
টাইম সিরিজ এম্বেডিং ক্রমিক ডেটাতে অস্থায়ী প্যাটার্ন ক্যাপচার করে। তারা ব্যবহার করা হয় কিছু ইন্টারনেট অ্যানোমলি সনাক্তকরণ সহ ক্রিয়াকলাপগুলির জন্য অ্যাপ্লিকেশন, আর্থিক ডেটা এবং সেন্সর ডেটা, সময় সিরিজের পূর্বাভাস এবং প্যাটার্ন সনাক্তকরণ।
3D বস্তুর জ্যামিতিক দিকগুলিও 3D মডেল এমবেডিং ব্যবহার করে ভেক্টর হিসাবে প্রকাশ করা যেতে পারে। এগুলি 3D পুনর্গঠন, অবজেক্ট সনাক্তকরণ এবং ফর্ম ম্যাচিংয়ের মতো কাজে প্রয়োগ করা হয়।
অণু
অণু এমবেডিং রাসায়নিক যৌগগুলিকে ভেক্টর হিসাবে উপস্থাপন করে। এগুলি ওষুধ আবিষ্কার, রাসায়নিক মিল অনুসন্ধান এবং আণবিক সম্পত্তি ভবিষ্যদ্বাণীতে ব্যবহৃত হয়। এই এমবেডিংগুলি অণুর গঠনগত এবং রাসায়নিক বৈশিষ্ট্যগুলি ক্যাপচার করতে গণনামূলক রসায়ন এবং ওষুধের বিকাশেও ব্যবহৃত হয়।

Word2Vec কি?
Word2Vec একটি জনপ্রিয় NLP শব্দ ভেক্টর এমবেডিং পদ্ধতি। Google দ্বারা তৈরি, Word2Vec একটি ক্রমাগত ভেক্টর স্পেসে ঘন ভেক্টর হিসাবে শব্দগুলিকে উপস্থাপন করার জন্য ডিজাইন করা হয়েছে। এটি একটি নথিতে একটি শব্দের প্রসঙ্গ চিনতে পারে এবং সাধারণত টেক্সট শ্রেণীকরণ, অনুভূতি বিশ্লেষণ এবং এনএলপি কাজগুলিতে ব্যবহৃত হয় যন্ত্রানুবাদ মেশিনগুলিকে আরও কার্যকরভাবে প্রাকৃতিক ভাষা বুঝতে এবং প্রক্রিয়া করতে সহায়তা করতে।
Word2Vec এই নীতির উপর ভিত্তি করে তৈরি করা হয়েছে যে একই অর্থ সহ শব্দগুলির একই ভেক্টর উপস্থাপনা থাকা উচিত, যা মডেলটিকে শব্দগুলির মধ্যে শব্দার্থিক লিঙ্কগুলি ক্যাপচার করতে সক্ষম করে।
Word2Vec এর দুটি মৌলিক আর্কিটেকচার রয়েছে, CBOW (কন্টিনিউয়াস ব্যাগ অফ ওয়ার্ডস) এবং স্কিপ-গ্রাম:
- CBOW. এই আর্কিটেকচারটি প্রসঙ্গ শব্দের উপর ভিত্তি করে লক্ষ্য শব্দের পূর্বাভাস দেয়। মডেলটিকে একটি প্রসঙ্গ বা পার্শ্ববর্তী শব্দ দেওয়া হয় এবং কেন্দ্রে লক্ষ্য শব্দের পূর্বাভাস দেওয়ার দায়িত্ব দেওয়া হয়। উদাহরণস্বরূপ, বাক্যটিতে, "দ্রুত বাদামী শিয়াল অলস কুকুরের উপর লাফ দেয়," CBOW ভবিষ্যদ্বাণী করতে প্রসঙ্গ বা পার্শ্ববর্তী শব্দ ব্যবহার করে শিয়াল লক্ষ্য শব্দ হিসাবে।
- স্কিপ-গ্রাম। CBOW এর বিপরীতে, স্কিপ-গ্রাম আর্কিটেকচার লক্ষ্য শব্দের উপর ভিত্তি করে প্রসঙ্গ শব্দের পূর্বাভাস দেয়। মডেলটিকে একটি টার্গেট শব্দ দেওয়া হয় এবং আশেপাশের প্রসঙ্গ পদগুলির পূর্বাভাস দিতে বলা হয়। "দ্রুত বাদামী শিয়াল অলস কুকুরের উপর লাফ দেয়" এর উপরের উদাহরণ বাক্যটি নিলে স্কিপ-গ্রাম লক্ষ্য শব্দটি গ্রহণ করবে শিয়াল এবং প্রসঙ্গ শব্দগুলি আবিষ্কার করুন যেমন “The,” “দ্রুত,” “বাদামী,” “জাম্পস,” “ওভার,” “দ্য,” “অলস” এবং “কুকুর”।
ব্যবসার একটি বিস্তৃত পরিসর জেনারেটিভ এআইকে আলিঙ্গন করতে শুরু করেছে, এর ব্যাঘাতমূলক সম্ভাবনা প্রদর্শন করছে। পরীক্ষা করা কিভাবে জেনারেটিভ এআই বিকাশ করছে, ভবিষ্যতে এটি কোন দিকে যাবে এবং যে কোন চ্যালেঞ্জ হতে পারে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://www.techtarget.com/searchenterpriseai/definition/vector-embeddings
- : আছে
- : হয়
- :কোথায়
- $ ইউপি
- 000
- 1
- 26
- 27
- 31
- 360
- 3d
- 40
- 43
- a
- উপরে
- অভিগম্যতা
- সম্পাদন
- দিয়ে
- স্টক
- ক্রিয়াকলাপ
- অতিরিক্ত
- পর্যাপ্তরূপে
- বিজ্ঞাপন
- পর
- AI
- চিকিত্সা
- এইডস
- আলগোরিদিম
- সব
- এছাড়াও
- মর্দানী স্ত্রীলোক
- an
- বিশ্লেষণ
- এবং
- অসঙ্গতি সনাক্তকরণ
- অন্য
- কোন
- আবেদন
- অ্যাপ্লিকেশন
- ফলিত
- অভিগমন
- পন্থা
- যথাযথ
- অ্যাপস
- স্থাপত্য
- রয়েছি
- উঠা
- বিন্যাস
- প্রবন্ধ
- প্রবন্ধ
- কৃত্রিম
- কৃত্রিম বুদ্ধিমত্তা
- AS
- আ
- একত্র
- পরিমাপন
- At
- মনোযোগ
- অডিও
- ব্যাগ
- শব্দ ব্যাগ
- ভিত্তি
- মৌলিক
- BE
- কারণ
- শুরু
- হচ্ছে
- মধ্যে
- তার পরেও
- উভয়
- বাদামী
- ব্যবসা
- by
- গণনা করা
- কল
- নামক
- ক্যামেরা
- CAN
- ক্ষমতা
- ধারণক্ষমতা
- গ্রেপ্তার
- ক্যাপচার
- বহন
- মামলা
- বিভাগ
- কেন্দ্র
- সেন্টার
- চ্যালেঞ্জ
- পরিবর্তিত
- বৈশিষ্ট্য
- chatbots
- রাসায়নিক
- রসায়ন
- ক্লাস
- শ্রেণীবিন্যাস
- পরিস্কার করা
- ঘনিষ্ঠ
- কাছাকাছি
- বস্ত্র
- থলোথলো
- এর COM
- আসা
- সাধারণ
- সাধারণভাবে
- সম্প্রদায়
- তুলনা করা
- তুলনা
- সম্পূর্ণ
- উপাদান
- গঠন
- বোঝা
- গণনা
- কম্পিউটার
- কম্পিউটিং
- সংক্ষিপ্ত
- সংযোগ
- বিষয়বস্তু
- প্রসঙ্গ
- বর্ণনাপ্রাসঙ্গিক
- একটানা
- কথোপকথন
- রূপান্তর
- কপি
- নির্মিত
- কঠোর
- সাইবার নিরাপত্তা
- উপাত্ত
- ডেটা পয়েন্ট
- তথ্য সেট
- ডেটাবেস
- ডাটাবেস
- গভীর
- গভীর জ্ঞানার্জন
- সংজ্ঞায়িত
- সংজ্ঞা
- বিলি
- প্রদর্শক
- ঘন
- নির্ভর করে
- পরিকল্পিত
- সত্ত্বেও
- সনাক্ত
- সনাক্তকরণ
- উন্নয়ন
- পার্থক্য
- বিভিন্ন
- মাত্রা
- মাত্রা
- অভিমুখ
- আবিষ্কার করা
- আবিষ্কার
- সংহতিনাশক
- দূরত্ব
- স্বতন্ত্র
- do
- দলিল
- কাগজপত্র
- কুকুর
- ডন
- ড্রাগ
- ড্রাগ উন্নয়ন
- ওষুধের আবিষ্কার
- সময়
- প্রতি
- সহজ
- প্রান্ত
- কার্যকর
- কার্যকরীভাবে
- কার্যকারিতা
- দক্ষতা
- দক্ষতা
- দক্ষতার
- দূর
- এম্বেড করা
- এম্বেডিং
- আলিঙ্গন
- সক্ষম করা
- সক্রিয়
- encapsulates
- ইঞ্জিন
- নিশ্চিত করা
- সত্ত্বা
- সত্তা
- পরিবেশ
- বিশেষত
- অপরিহার্য
- থার (eth)
- মূল্যায়নের
- এমন কি
- সব
- পরীক্ষক
- উদাহরণ
- বিদ্যমান
- প্রকাশিত
- প্রকাশ
- ব্যাপকভাবে
- সমাধা
- ব্যর্থ
- বৈশিষ্ট্য
- আর্থিক
- অর্থনৈতিক উপাত্ত
- আবিষ্কার
- অনুসরণ
- জন্য
- ফর্ম
- বিন্যাস
- গঠিত
- ফর্ম
- শিয়াল
- প্রতারণাপূর্ণ
- ঘনঘন
- তাজা
- বন্ধুদের
- থেকে
- ক্রিয়া
- ক্রিয়াকলাপ
- ভবিষ্যৎ
- অর্জন
- সংগ্রহ করা
- হিসাব করার নিয়ম
- সাধারণ
- উত্পাদন করা
- উত্পন্ন
- সৃজক
- জেনারেটিভ এআই
- রীতি
- দৈত্যদের
- প্রদত্ত
- দস্তানা
- Go
- গুগল
- চিত্রলেখ
- আছে
- সাহায্য
- সহায়ক
- সাহায্য
- উচ্চ
- কিভাবে
- HTTPS দ্বারা
- প্রচুর
- আইকন
- শনাক্ত
- চিহ্নিত
- সনাক্ত করা
- if
- ভাবমূর্তি
- চিত্র অনুসন্ধান
- চিত্র
- অপরিমেয়
- উন্নত করা
- in
- অন্তর্ভুক্ত করা
- অন্তর্ভুক্ত
- সুদ্ধ
- স্বাধীন
- ইনডেক্স
- স্বতন্ত্র
- শিল্প
- শিল্প
- তথ্য
- অনুসন্ধান
- ভিতরে
- উদাহরণ
- দৃষ্টান্ত
- বুদ্ধিমত্তা
- অভিপ্রেত
- Internet
- মধ্যে
- জড়িত
- জড়িত
- সমস্যা
- IT
- আইটেম
- এর
- জাম্প
- চাবি
- পরিচিত
- ভাষা
- বড়
- জ্ঞানী
- শিক্ষা
- লেন্স
- কম
- দিন
- চিঠি
- লেট
- সীমিত
- LINK
- লিঙ্ক
- যৌক্তিক
- খুঁজছি
- মেশিন
- মেশিন লার্নিং
- মেশিন
- প্রণীত
- করা
- তৈরি করে
- পরিচালক
- পদ্ধতি
- ম্যাচ
- ম্যাচ
- ম্যাচিং
- গাণিতিক
- অর্থ
- অর্থপূর্ণ
- অর্থ
- চিকিৎসা
- হতে পারে
- ML
- মডেল
- মূর্তিনির্মাণ
- মডেল
- আণবিক
- অধিক
- সেতু
- সবচেয়ে জনপ্রিয়
- সঙ্গীত
- প্রাকৃতিক
- স্বভাবিক ভাষা
- স্বাভাবিক ভাষা প্রক্রিয়াকরণ
- Netflix এর
- নিউরাল
- নতুন
- NLP
- নোড
- নোড
- গোলমাল
- সংখ্যা
- সংখ্যার
- অনেক
- লক্ষ্য
- বস্তু সনাক্তকরণ
- বস্তু
- of
- অর্পণ
- প্রায়ই
- on
- ONE
- খোলা
- ওপেন সোর্স
- অপারেশনস
- or
- সংগঠন
- সংগঠিত
- মূল
- অন্যান্য
- বাইরে
- ফলাফল
- Outlier
- শেষ
- পৃষ্ঠা
- যুগল
- পরামিতি
- অংশ
- প্যাটার্ন
- নিদর্শন
- কর্মক্ষমতা
- ব্যক্তি
- ব্যক্তিগতকৃত
- ফেজ
- দা
- বাক্যাংশ
- ছবি
- ছবি
- টুকরা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- খেলা
- পয়েন্ট
- জনপ্রিয়
- জনপ্রিয়তা
- সম্ভব
- সম্ভাব্য
- যথাযথ
- ভবিষ্যদ্বাণী করা
- পূর্বাভাস
- পূর্বাভাসের
- ভবিষ্যদ্বাণী
- ভবিষ্যতবাণী
- প্রেডিক্টস
- পছন্দগুলি
- প্রস্তুতি
- নীতি
- প্রক্রিয়া
- প্রক্রিয়াজাতকরণ
- প্রসেসর
- আবহ
- পণ্য
- উত্পাদনের
- পণ্য
- প্রোফাইল
- বৈশিষ্ট্য
- সম্পত্তি
- প্রদান
- উপলব্ধ
- গুণাবলী
- দ্রুত
- পরিসর
- দ্রুত
- RE
- গৃহীত
- স্বীকার
- চেনা
- সুপারিশ
- সুপারিশ
- সুপারিশ
- হ্রাস করা
- পড়ুন
- বোঝায়
- সংশ্লিষ্ট
- সম্পর্ক
- প্রাসঙ্গিক
- প্রতিলিপি
- প্রতিবেদন
- চিত্রিত করা
- প্রতিনিধিত্ব
- প্রতিনিধিত্ব
- প্রতিনিধিত্বমূলক
- প্রতিনিধিত্ব করে
- প্রতিক্রিয়া
- প্রতিক্রিয়া
- ফলে এবং
- উদ্ধার
- বিপরীত
- ভূমিকা
- s
- একই
- স্কেল
- সার্চ
- সার্চ ইঞ্জিন
- অনুসন্ধান
- অনুসন্ধানের
- অধ্যায়
- সেগমেন্টেশন
- শব্দার্থিক
- শব্দার্থবিদ্যা
- সেন্সর
- বাক্য
- অনুভূতি
- ক্রম
- সেট
- সেট
- বিভিন্ন
- শারডিং
- উচিত
- দেখাচ্ছে
- সংকেত
- গুরুত্বপূর্ণ
- অনুরূপ
- মিল
- থেকে
- ছোট
- কেডস
- কিছু
- উৎস
- স্থান
- বক্তা
- বিশেষজ্ঞ
- বিশেষজ্ঞ
- নির্দিষ্ট
- বক্তৃতা
- কন্ঠ সনান্তকরণ
- বক্তৃতা থেকে পাঠ্য
- মান
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- এখনো
- দোকান
- সঞ্চিত
- কাঠামোগত
- কাঠামোবদ্ধ
- এমন
- সরবরাহকৃত
- পার্শ্ববর্তী
- প্রতীক
- সিস্টেম
- T
- উপযোগী
- গ্রহণ করা
- গ্রহণ
- লক্ষ্য
- লক্ষ্যবস্তু
- কাজ
- প্রযুক্তি
- প্রযুক্তিঃ
- শর্তাবলী
- পাঠ
- চেয়ে
- যে
- সার্জারির
- ভবিষ্যৎ
- তাদের
- এইগুলো
- তারা
- জিনিস
- কিছু
- এই
- সেগুলো
- দ্বারা
- সময়
- সময় সিরিজ
- থেকে
- একসঙ্গে
- সহ্য
- রেলগাড়ি
- প্রশিক্ষিত
- প্রশিক্ষণ
- ট্রেন
- রুপান্তর
- অনুবাদ
- চালু
- দুই
- আদর্শ
- ধরনের
- সাধারণত
- বিরল
- বোধশক্তি
- নিরবচ্ছিন্ন
- সার্বজনীন
- অসদৃশ
- আপলোড
- ব্যবহার
- ব্যবহৃত
- ব্যবহারকারী
- ব্যবহারকারী
- ব্যবহারসমূহ
- ব্যবহার
- মানগুলি
- বৈচিত্র্য
- বিভিন্ন
- প্রতিপাদন
- মাধ্যমে
- ভিডিও
- চাক্ষুষ
- চাক্ষুষরূপে
- উপায়..
- ওয়েব
- কি
- কখন
- যেহেতু
- কিনা
- যে
- যখন
- ফিস্ ফিস্ শব্দ
- সমগ্র
- ব্যাপক
- প্রশস্ত পরিসর
- ইচ্ছা
- সঙ্গে
- শব্দ
- শব্দ
- ইউটিউব
- zephyrnet
- জিরো-শট লার্নিং