ভূমিকা
ট্রান্সফরমার এবং বৃহৎ ভাষার মডেলগুলি এই ক্ষেত্রে প্রবর্তিত হওয়ার পরে বিশ্বকে ঝড় তুলেছে স্বাভাবিক ভাষা প্রক্রিয়াকরণ (NLP)। তাদের সূচনা থেকে, ক্ষেত্রটি উদ্ভাবন এবং গবেষণার সাথে দ্রুত বিকশিত হচ্ছে যা এই এলএলএমগুলিকে আরও দক্ষ করে তোলে। এর মধ্যে রয়েছে LoRA(নিম্ন-র্যাঙ্ক অ্যাডাপশন), ফ্ল্যাশ অ্যাটেনশন, কোয়ান্টাইজেশন এবং উল্লেখযোগ্য এলএলএমগুলির সাম্প্রতিক মার্জিং পদ্ধতি। এই নির্দেশিকায়, আমরা মার্জ করার একটি নতুন পদ্ধতির দিকে নজর দেব এলএলএম (সৌর 10.7B) আপস্টেজ এআই দ্বারা প্রবর্তিত।

শিক্ষার উদ্দেশ্য
- Solar 10.7B এর অনন্য আর্কিটেকচার এবং এর উদ্ভাবনী "গভীরতা আপ-স্কেলিং" বুঝুন
- মডেলের প্রাক-প্রশিক্ষণ প্রক্রিয়া এবং এটি ব্যবহার করা বিভিন্ন ডেটা অন্বেষণ করুন
- বিভিন্ন NLP টাস্ক জুড়ে Solar 10.7B-এর চিত্তাকর্ষক কর্মক্ষমতা বেঞ্চমার্ক বিশ্লেষণ করুন
- মিক্সট্রাল এমওই-এর মতো অন্যান্য উল্লেখযোগ্য LLM-এর সাথে Solar 10.7B-এর তুলনা করুন এবং বৈসাদৃশ্য করুন
- আপনার প্রকল্পগুলির জন্য সোলার 10.7B এর সাথে কীভাবে অ্যাক্সেস এবং কাজ করবেন তা শিখুন
এই নিবন্ধটি একটি অংশ হিসাবে প্রকাশিত হয়েছিল ডেটা সায়েন্স ব্লগাথন।
সুচিপত্র
SOLAR 10.7B কি?
Upstange AI নতুন 10.7 বিলিয়ন প্যারামিটার মডেল, SOLAR 10.7B প্রবর্তন করেছে। এই মডেলটি দুটি 7 বিলিয়ন প্যারামিটার মডেল, বিশেষ করে দুটি লামা 2 7 বিলিয়ন মডেলকে একত্রিত করার ফলাফল, যা SOLAR 10.7B তৈরি করার জন্য প্রশিক্ষিত ছিল। এই একত্রিতকরণের অনন্য দিক হল ডেপথ আপ-স্কেলিং (DUS) নামে একটি নতুন পদ্ধতির প্রয়োগ, যা মিক্সট্রাল পদ্ধতির সাথে বিপরীত যেখানে বিশেষজ্ঞদের একটি মিশ্রণ নিযুক্ত করা হয়।
নতুন 10.7B মডেলটি Mistral 7B, Qwen 14B কে ছাড়িয়ে গেছে। SOLAR 10.7B Instruct নামে একটি ইন্সট্রাক্ট সংস্করণ প্রকাশ করা হয়েছে, এবং এটি প্রকাশের পরে, এটি Qwen 72B এবং Mixtral 8x7B লার্জ ল্যাঙ্গুয়েজ মডেল উভয়কেই ছাড়িয়ে লিডারবোর্ডে শীর্ষে রয়েছে। 10.7 বিলিয়ন প্যারামিটার মডেল হওয়া সত্ত্বেও, সোলার এলএলএমগুলিকে ছাড়িয়ে যেতে সক্ষম হয়েছিল যা তার আকারের বহুগুণ বেশি
ডেপথ আপ স্কেলিং কি?
আসুন বুঝতে পারি কিভাবে এটি সব শুরু হয়েছিল, এবং SOLAR 10.7B গঠন। এটি সব একটি একক বেস মডেল দিয়ে শুরু হয়। বৃহত্তর ওপেন সোর্স কন্ট্রিবিউটারের কারণে আপস্টেজ তার বেস মডেলের জন্য 2টি ট্রান্সফরমার লেয়ার ধারণকারী লামা 32 বেছে নিয়েছে। তারপর এই বেস মডেলের একটি অনুলিপি তৈরি করা হয়েছিল

আমরা তারপর দুটি বেস মডেল পেতে. ওজনের ক্ষেত্রে, আপস্টেজ মিস্ট্রাল 7বি থেকে পূর্বপ্রশিক্ষিত ওজন নিয়েছে কারণ এটি সেই সময়ে সেরা পারফর্ম করছিল। এখন, আমরা গভীরতার দিক থেকে স্কেলিং শুরু করি। প্রতিটি বেস মডেলে 32টি স্তর রয়েছে। এই 32টি স্তর থেকে, আমরা m স্তরগুলিকে সরিয়ে ফেলি, এটি আসল মডেল থেকে চূড়ান্ত m স্তর এবং এর অনুলিপি সংস্করণ থেকে প্রথম m স্তরগুলি। এটি তাদের প্রতিটিতে 24টি স্তর পর্যন্ত যোগ করে। তারপরে আমরা এই দুটি মডেল একত্রিত করি:
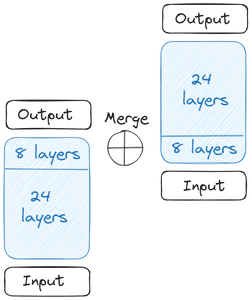
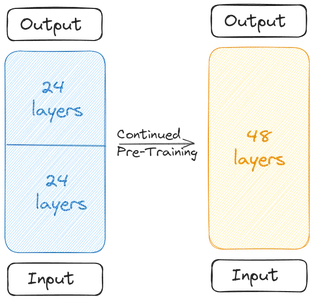
দুটি বেস মডেল স্কেল করা মডেল গঠনের জন্য একত্রিত হয়। স্কেল করা মডেলটিতে এখন 48টি স্তর রয়েছে। মার্জ করার কারণে স্কেল করা মডেলটি খারাপভাবে কাজ করে। তাই স্কেল করা মডেলটি প্রাক-প্রশিক্ষণের মধ্য দিয়ে যায়। এই Depthwise স্কেলিং এর পরে অবিরত প্রিট্রেনিং একসাথে ডেপথ আপ-স্কেলিং (DUS) করে।
সোলার 10.7B প্রশিক্ষণ
একত্রিত হওয়ার কারণে কর্মক্ষমতা হ্রাসের কারণে স্কেল করা মডেলটিকে পূর্বপ্রশিক্ষিত করতে হবে। নির্মাতারা জানিয়েছেন, প্রি-ট্রেনিংয়ের মাধ্যমে পারফরম্যান্স দ্রুত বেড়েছে। প্রাক-প্রশিক্ষণ/সূক্ষ্ম টিউনিং দুটি পর্যায়ে জড়িত
প্রথম পর্যায় ছিল নির্দেশনা ফাইন-টিউনিং। এই ধরনের ফাইন-টিউনিং-এ, মডেলটি নির্দেশাবলীর সাথে সারিবদ্ধ করার জন্য ডেটাসেটের উপর প্রশিক্ষণ নিয়েছে। ফাইন-টিউনিং প্রক্রিয়ায় জনপ্রিয় ওপেন সোর্স ডেটাসেট যেমন Alpaca-GPT4 এবং OpenOrca এর সাথে কাজ করা জড়িত। কাগজটি উল্লেখ করেছে যে ডেটাসেটের একটি উপসেট একত্রিত মডেলটিকে সূক্ষ্ম-টিউনিংয়ে ব্যবহার করা হয়েছিল। ওপেন সোর্স ডেটার পাশাপাশি, আপস্টেজ এমনকি কিছু ক্লোজ সোর্স ম্যাথ ডেটা দিয়ে প্রশিক্ষিত করেছে।
দ্বিতীয় পর্যায়ে, প্রান্তিককরণ টিউনিং সঞ্চালিত হয়। অ্যালাইনমেন্ট টিউনিং-এ, আমরা স্টেজ ওয়ান ফাইন-টিউনড মডেলটি গ্রহণ করি এবং মানুষের বা GPT4-এর মতো শক্তিশালী AI-এর সাথে আরও সারিবদ্ধ হতে এটিকে আরও সূক্ষ্ম-টিউন করি। এটি ডিপিওট্রেইনার (ডাইরেক্ট প্রেফারেন্স অপ্টিমাইজেশান) একটি RLHF (মানব প্রতিক্রিয়া সহ রিইনফোর্সমেন্ট লার্নিং)-এর মতো কৌশলের মাধ্যমে করা হয়েছিল।
ডাইরেক্ট প্রেফারেন্স অপ্টিমাইজেশানে, আমাদের কাছে তিনটি কলাম, একটি প্রম্পট, একটি পছন্দের উত্তর কলাম এবং একটি প্রত্যাখ্যাত উত্তর কলাম রয়েছে এমন একটি ডেটাসেট রয়েছে। এটি তখন স্কেল করা মডেলটিকে প্রশিক্ষণ দিতে ব্যবহার করা হয় যাতে এটি তৈরি করতে আমাদের প্রয়োজন এমন উত্তরগুলি তৈরি করে। একই ডেটাসেটগুলি যেগুলিকে নির্দেশনা-ফাইনটিউনিংয়ের জন্য প্রশিক্ষণ দেওয়া হয়েছিল এখানে ব্যবহার করা হয়েছে৷
মূল্যায়ন এবং বেঞ্চমার্ক ফলাফল
হাগিং ফেস ওপেনএলএলএম লিডারবোর্ড লার্জ ল্যাঙ্গুয়েজ মডেলের (এলএলএম) ক্ষমতা মূল্যায়ন করার জন্য বিভিন্ন বেঞ্চমার্ক ব্যবহার করে। প্রতিটি বেঞ্চমার্ক এলএলএম-এর কর্মক্ষমতার বিভিন্ন দিক মূল্যায়ন করে:
- ARC (AI2 রিজনিং চ্যালেঞ্জ): এই বেঞ্চমার্কটি প্রাথমিক স্তরের বিজ্ঞানের প্রশ্নের উত্তর দেওয়ার জন্য এলএলএম-এর ক্ষমতা পরীক্ষা করে, মডেলের বৈজ্ঞানিক ধারণাগুলির বোঝা এবং যুক্তির অন্তর্দৃষ্টি প্রদান করে।
- MMLU (ম্যাসিভ মাল্টিটাস্ক ল্যাঙ্গুয়েজ আন্ডারস্ট্যান্ডিং): MMLU হল একটি বৈচিত্র্যময় মাপকাঠি যা মৌলিক গণিত, ইতিহাস, আইন, কম্পিউটার বিজ্ঞান এবং অন্যান্য সম্পর্কিত প্রশ্ন সহ 57টি বিভিন্ন কাজ কভার করে। এটি একাধিক শাখায় তথ্য প্রক্রিয়াকরণ এবং বোঝার ক্ষমতা এলএলএম-এর মূল্যায়ন করে।
- HellaSwag: একটি LLM-এর কমনসেন্স যুক্তি পরীক্ষা করার লক্ষ্যে, HellaSwag মডেলগুলিকে বিভিন্ন পরিস্থিতিতে দৈনন্দিন যুক্তি প্রয়োগ করার জন্য চ্যালেঞ্জ করে, মানুষের চিন্তা প্রক্রিয়ার অনুরূপ স্বজ্ঞাত বিচার করার তাদের ক্ষমতা মূল্যায়ন করে।
- উইনোগ্রান্ড: HellaSwag-এর মতো এই বেঞ্চমার্ক, কমনসেন্স যুক্তির উপর ফোকাস করে কিন্তু HellaSwag-এর তুলনায় বিভিন্ন সূক্ষ্মতার সাথে। এটির জন্য LLM-এর প্রয়োজন একটি পরিশীলিত স্তরের বোঝাপড়া এবং যৌক্তিক যুক্তি প্রদর্শন করতে।
- সত্যবাদী প্রশ্ন: TruthfulQA LLM দ্বারা প্রদত্ত তথ্যের যথার্থতা এবং নির্ভরযোগ্যতা মূল্যায়ন করে। এতে বিজ্ঞান, আইন, রাজনীতি এবং আরও অনেক কিছু সহ বিভিন্ন ক্ষেত্রের প্রশ্ন রয়েছে, যা সত্যবাদী এবং বাস্তব প্রতিক্রিয়া তৈরি করার মডেলের ক্ষমতা পরীক্ষা করে।
- GSM8K: গণিতের দক্ষতা পরীক্ষা করার জন্য বিশেষভাবে ডিজাইন করা হয়েছে, GSM8K-তে বহু-পদক্ষেপের গণিত সমস্যা রয়েছে যার জন্য যৌক্তিক যুক্তি এবং গণনামূলক চিন্তাভাবনা প্রয়োজন, গণিতে তাদের সমস্যা সমাধানের দক্ষতা মূল্যায়ন করার জন্য এলএলএমকে চ্যালেঞ্জ করে।
বেস সোলার 10.7B মডেল মিস্ট্রাল 7B ইন্সট্রাক্ট v0.2 মডেল এবং Qwen 14B মডেলের মতো মডেলগুলিকে ছাড়িয়ে গেছে। SOLAR 10.7B-এর ইন্সট্রাক্ট সংস্করণটি এমনকি মিস্ট্রাল 8x7B, Qwen 72B, Falcon 180B এবং অন্যান্য বিশাল ভাষার মডেলগুলির মতো খুব বড় ভাষার মডেলগুলিকে হারাতে সক্ষম হয়েছিল। এটি ARC এবং TruthfulQA বেঞ্চমার্কের সমস্ত মডেলের চেয়ে এগিয়ে ছিল
SOLAR 10.7B দিয়ে শুরু করা
SOLAR 10.7B মডেলটি ট্রান্সফরমার লাইব্রেরির সাথে কাজ করার জন্য HuggingFace হাবে সহজেই উপলব্ধ। এমনকি SOLAR 10.7B এর কোয়ান্টাইজড মডেলগুলি কাজ করার জন্য উপলব্ধ। এই বিভাগে, আমরা কোয়ান্টাইজড সংস্করণ ডাউনলোড করব এবং বিভিন্ন কাজের সাথে মডেলটি ইনপুট করার চেষ্টা করব এবং আউটপুট জেনারেট করা দেখব।
SOLAR 10.7B এর কোয়ান্টাইজড সংস্করণের সাথে পরীক্ষার জন্য, আমরা পাইথনের llama_cpp_python লাইব্রেরির সাথে কাজ করব যা আমাদের কোয়ান্টাইজড লার্জ ল্যাঙ্গুয়েজ মডেলগুলি চালাতে দেয়। এই ডেমোর জন্য, আমরা Google Colab-এর বিনামূল্যের সংস্করণ নিয়ে কাজ করব।
প্যাকেজ ডাউনলোড করুন
!CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 pip3 install llama-cpp-python
!pip3 install huggingface-hub- সার্জারির CMAKE_ARGS=”-DLLAMA_CUBLAS=on” এবং FORCE_CMAKE=1, অনুমতি দেবে llama_cpp_python বিনামূল্যে কোলাব সংস্করণে উপলব্ধ Nvidia GPU কাজ করতে
- তারপর আমরা ইনস্টল llama_cpp_python pip3 মাধ্যমে প্যাকেজ
- আমরা এমনকি ডাউনলোড আলিঙ্গনমুখ-হাব, যার সাহায্যে আমরা কোয়ান্টাইজড SOLAR 10.7B মডেলটি ডাউনলোড করব
SOLAR 10.7B মডেলের সাথে কাজ করার জন্য, আমাদের প্রথমে এটির কোয়ান্টাইজড সংস্করণ ডাউনলোড করতে হবে। এটি ডাউনলোড করতে, আমরা নিম্নলিখিত কোড চালাব:
from huggingface_hub import hf_hub_download
# specifying the model name
model_name = "TheBloke/SOLAR-10.7B-Instruct-v1.0-GGUF"
# specifying the type of quantization of the model
model_file = "solar-10.7b-instruct-v1.0.Q2_K.gguf"
# download the model by specifying the model name and quantized model name
model_path = hf_hub_download(model_name, filename=model_file)
হাগিং ফেস হাবের সাথে কাজ করা
এখানে, আমরা সঙ্গে কাজ আলিঙ্গন_মুখ_হাব কোয়ান্টাইজড মডেল ডাউনলোড করতে। এই জন্য, আমরা আমদানি hf_hub_download যে নিম্নলিখিত পরামিতি লাগে
- ণশড: এই ধরনের মডেল যা আমরা ডাউনলোড করতে চাই। এখানে আমরা SOLAR 10.7B Instruct GGUF মডেলটি ডাউনলোড করতে চাই
- মডেল_ফাইল: এখানে আমরা বলি কোন কোয়ান্টাইজড ভার্সন আমরা ডাউনলোড করতে চাই। এখানে আমরা SOLAR 2B নির্দেশের 10.7bit কোয়ান্টাইজড সংস্করণ ডাউনলোড করব
- আমরা তারপর এই পরামিতি পাস hf_hub_download, যা এই পরামিতিগুলি গ্রহণ করে এবং নির্দিষ্ট মডেল ডাউনলোড করে। ডাউনলোড করার পরে, এটি সেই পাথ ফিরিয়ে দেয় যেখানে মডেলটি ডাউনলোড করা হয়
- এই পথ ফিরে সংরক্ষিত হচ্ছে মডেল_পথ পরিবর্তনশীল
এখন, আমরা লামার মাধ্যমে এই মডেলটি লোড করতে পারি_cpp_python লাইব্রেরি মডেল লোড করার জন্য কোড নিচের মত হবে
from llama_cpp import Llama
llm = Llama(
model_path=model_path,
n_ctx=512, # the number of i/p tokens the model can take
n_threads=8, # the number of threads to use
n_gpu_layers=110 # how many layers of the model to offload to the GPU
)
লামা ক্লাস আমদানি করুন
আমরা থেকে লামা ক্লাস আমদানি করি llama_cpp, যা নিম্নলিখিত পরামিতিগুলিতে লাগে৷
- মডেল_পথ: এই ভেরিয়েবলটি সেই পথে নিয়ে যায় যেখানে আমাদের মডেলটি সংরক্ষণ করা হয়। আমরা পূর্ববর্তী ধাপ থেকে পথ পেয়েছি, যা আমরা এখানে প্রদান করব
- n_ctx: এখানে, আমরা মডেলের প্রসঙ্গ দৈর্ঘ্য দিই। আপাতত, আমরা প্রসঙ্গ দৈর্ঘ্যের জন্য 512 টোকেন প্রদান করছি
- n_থ্রেড: এখানে আমরা লামা শ্রেণীর দ্বারা ব্যবহৃত থ্রেডের সংখ্যা উল্লেখ করছি। আপাতত, আমরা এটি 8 পাস করি, কারণ আমাদের 4 কোর CPU আছে, যেখানে প্রতিটি কোর একসাথে 2 টি থ্রেড চালাতে পারে
- n_gpu_স্তর: আমাদের চলমান GPU থাকলে আমরা এটি দিই, যেটি আমরা করি কারণ আমরা বিনামূল্যে কোলাবের সাথে কাজ করছি। এর জন্য, আমরা 110 পাস করি, যা বলে যে আমরা পুরো মডেলটিকে GPU-তে অফলোড করতে চাই এবং এর কিছু অংশ সিস্টেম র্যামে চালাতে চাই না।
- অবশেষে, আমরা এই Llama ক্লাস থেকে একটি অবজেক্ট তৈরি করি এবং এটি পরিবর্তনশীল llm-এ দিই
এই কোডটি চালানোর ফলে SOLAR 10.7B কোয়ান্টাইজড মডেল GPU-তে লোড হবে এবং উপযুক্ত প্রসঙ্গ দৈর্ঘ্য সেট করবে। এখন, এই মডেলটিতে কিছু অনুমান করার সময় এসেছে। এই জন্য, আমরা নিচের কোড দিয়ে কাজ করি
output = llm(
"### User:nWho are you?nn### Assistant:", # User Prompt
max_tokens=512, # the number of output tokens generated
stop=["</s>"], # the token which tells the LLM to stop
)
print(output['choices'][0]['text']) # llm generated text
মডেল অনুমান করুন
মডেল অনুমান করার জন্য, আমরা LLM-তে নিম্নলিখিত পরামিতিগুলি পাস করি:
- প্রম্পট/চ্যাট টেমপ্লেট: এটি মডেলের সাথে চ্যাট করার জন্য প্রয়োজনীয় টেমপ্লেট। উপরে উল্লিখিত টেমপ্লেটটি(### User:n{user_prompt}?nn### Assistant:) যেটি SOLAR 10.7B মডেলের জন্য কাজ করে। টেমপ্লেটে, বাক্যটির পরে ব্যবহারকারী ইউজার প্রম্পট এবং জেনারেশন এর পরে তৈরি করা হবে সহায়ক
- সর্বোচ্চ_টোকেন: এটি হল সর্বাধিক পরিমাণ টোকেন যা লার্জ ল্যাঙ্গুয়েজ মডেল আউটপুট করতে পারে যখন একটি প্রম্পট দেওয়া হয়। আপাতত, আমরা এটিকে 512 টোকেনে সীমাবদ্ধ করছি
- বন্ধ: এই স্টপ টোকেন. স্টপ টোকেন বড় ভাষা মডেলকে বলে যে এটিকে আরও টোকেন তৈরি করা বন্ধ করতে হবে। SOLAR 10.7B এর জন্য, স্টপ টোকেন হল
এটি চালানোর ফলে ফলাফল সংরক্ষণ করা হবে আউটপুট পরিবর্তনশীল উৎপন্ন ফলাফল OpenAI API কলের অনুরূপ। তাই আমরা প্রদত্ত প্রিন্ট স্টেটমেন্টের মাধ্যমে প্রজন্মকে অ্যাক্সেস করতে পারি, যা আমরা OpenAI প্রতিক্রিয়া থেকে প্রজন্মকে কীভাবে অ্যাক্সেস করি তার অনুরূপ। উত্পন্ন আউটপুট নীচে দেখা যাবে

উৎপন্ন বাক্যটি বড় ব্যাকরণগত ভুলের উপস্থিতি ছাড়াই যথেষ্ট ভাল বলে মনে হচ্ছে। আসুন নিম্নলিখিত প্রম্পটগুলি দিয়ে মডেলটির সাধারণ জ্ঞানের অংশটি চেষ্টা করি
output = llm(
"### User:nHow many eggs can a monkey lay in its lifetime?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

output = llm(
"### User:nHow many smartphones can a human eat?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

এখানে আমরা সাধারণ জ্ঞানের সাথে সম্পর্কিত দুটি উদাহরণ দেখি এবং আশ্চর্যজনকভাবে SOLAR 10.7B এটি খুব ভালভাবে পরিচালনা করে। Large Language Model কিছু দরকারী বিষয়বস্তু সহ সঠিক উত্তর দিতে সক্ষম হয়েছে৷ আসুন নিম্নলিখিত প্রম্পটগুলির মাধ্যমে মডেলের গণিত এবং যুক্তির ক্ষমতা পরীক্ষা করার চেষ্টা করি
output = llm(
"### User:nLook at this series: 80, 10, 70, 15, 60, ...
What number should come next?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])
output = llm(
"### User:nJohn runs faster than Ken. Magnus runs faster than John.
Does Ken run faster than Magnus?nn### Assistant:",
max_tokens=512,
stop=["</s>"],
)
print(output['choices'][0]['text'])

প্রদত্ত উদাহরণ থেকে, SOLAR 10.7B একটি ভাল প্রতিক্রিয়া তৈরি করেছে। এটি প্রদত্ত গাণিতিক, এবং যৌক্তিক যুক্তি এবং এমনকি সাধারণ জ্ঞান সম্পর্কিত প্রশ্নের সঠিকভাবে উত্তর দিতে সক্ষম হয়েছিল। সামগ্রিকভাবে আমরা উপসংহারে আসতে পারি যে SOLAR 10.7B বড় ভাষা মডেল ভাল প্রতিক্রিয়া তৈরি করছে
SOLAR 10.7B বনাম Mixtral MoE
Mixtral 8x7B MoE তৈরি করেছে Mistral AI দ্বারা বিশেষজ্ঞদের আর্কিটেকচারের মিশ্রণে। সংক্ষেপে, বিশেষজ্ঞদের এই মিশ্রণ, মিস্ট্রাল 8 7 বিলিয়ন প্যারামিটার মডেল নিয়োগ করে। এই মডেলগুলির প্রত্যেকটির কিছু ফিড-ফরোয়ার্ড নেটওয়ার্ক রয়েছে যা বিশেষজ্ঞদের নামক অন্যান্য স্তর দ্বারা প্রতিস্থাপিত হয়েছে। তাই Mixtral 8x7B-তে 8 জন বিশেষজ্ঞ আছে বলে মনে করা হয়। এবং মডেলটি ইনপুট প্রম্পটে প্রত্যেককে গ্রহণ করে, সেখানে একটি গেটিং ব্যবস্থা থাকবে যা এই 2 জনের মধ্যে থেকে শুধুমাত্র 8 জন বিশেষজ্ঞকে বেছে নেয়। তারপর 2 জন বিশেষজ্ঞ এই ইনপুট প্রম্পটে নেয় এবং চূড়ান্ত আউটপুট টোকেন তৈরি করে। সুতরাং আমরা দেখতে পাচ্ছি যে এই ধরনের একত্রিতকরণের সাথে জড়িত কিছুটা জটিলতা রয়েছে, যেখানে আমাদের ফিড-ফরোয়ার্ড স্তরগুলিকে অন্যান্য স্তরগুলির সাথে প্রতিস্থাপন করতে হবে এবং একটি গেটিং প্রক্রিয়া চালু করতে হবে যা এই বিশেষজ্ঞদের মধ্যে নির্বাচন করে।
যখন আপস্টেজ থেকে SOLAR 10.7B মডেলটি ডেপথ আপ-স্কেলিং পদ্ধতির ব্যবহার করে। ডেপথ আপ-স্কেলিং-এ, আমরা কেবলমাত্র একটি বেস মডেল থেকে কিছু সংখ্যক প্রারম্ভিক স্তর এবং এর অনুলিপি সংস্করণ থেকে একই সংখ্যক চূড়ান্ত স্তরগুলি সরিয়ে ফেলি। তারপরে আমরা মডেলগুলিকে অন্যটির উপরে স্ট্যাক করে একত্রিত করি। এবং মাত্র কয়েক যুগের সূক্ষ্ম-টিউনিংয়ের সাথে একত্রিত মডেলটি কর্মক্ষমতাতে দ্রুত বৃদ্ধি দেখাতে পারে। এখানে আমরা বিদ্যমান স্তরগুলিকে অন্য কিছু স্তর দিয়ে প্রতিস্থাপন করি না। এছাড়াও এখানে আমাদের একটি গেটিং প্রক্রিয়া নেই। সামগ্রিকভাবে, ডেপথ আপ-স্কেলিং জটিলতা জড়িত নয় এমন মডেলগুলিকে একত্রিত করার একটি সহজ এবং কার্যকর উপায়।
এছাড়াও পারফরম্যান্সের সাথে তুলনা করে, ডেপথ আপ-স্কেলিং, যদিও মাত্র দুটি 7 বিলিয়ন মডেলকে একত্রিত করে, SOLAR 10.7B স্পষ্টভাবে Mixtral 8x7B কে ছাড়িয়ে যেতে সক্ষম হয়েছে, যা তুলনামূলকভাবে অনেক বড় মডেল। এটি বিশেষজ্ঞদের মিক্সট্রালের মতো জটিল একের উপর একটি সহজ মার্জিং পদ্ধতির কার্যকারিতা প্রমাণ করে
সীমাবদ্ধতা এবং বিবেচনা
- হাইপারপ্যারামিটার এক্সপ্লোরেশন: একটি গুরুত্বপূর্ণ সীমাবদ্ধতা হল DUS পদ্ধতিতে হাইপারপ্যারামিটারের অপর্যাপ্ত অনুসন্ধান। হার্ডওয়্যার সীমাবদ্ধতার কারণে, বেস মডেলের উভয় প্রান্ত থেকে 8টি স্তর সরানো হয়েছে এই সংখ্যাটি সেরা পারফরম্যান্স পাওয়ার জন্য সর্বোত্তম কিনা তা যাচাই না করেই। ভবিষ্যত কাজের লক্ষ্য হল আরও কঠোর পরীক্ষা-নিরীক্ষা করা এবং এটি সমাধানের জন্য একটি বিশ্লেষণ করা।
- গণনামূলক চাহিদা: মডেলটির প্রশিক্ষণ এবং অনুমানের জন্য প্রচুর পরিমাণে গণনামূলক সংস্থান প্রয়োজন। এটি এর ব্যবহার সীমিত করতে পারে, প্রধানত যাদের সীমিত গণনাগত ক্ষমতা রয়েছে তাদের জন্য।
- প্রশিক্ষণের ডেটাতে পক্ষপাতিত্ব: সমস্ত মেশিন লার্নিং মডেলের মতো, এটি প্রশিক্ষণের ডেটাতে উপস্থিত পক্ষপাতের জন্য সংবেদনশীল, যা সম্ভাব্যভাবে নির্দিষ্ট পরিস্থিতিতে তির্যক ফলাফলের দিকে পরিচালিত করে।
- পরিবেশগত প্রভাব: এমনকি মডেলটি প্রশিক্ষণ এবং পরিচালনার জন্য প্রয়োজনীয় শক্তি খরচ পরিবেশগত উদ্বেগ প্রকাশ করে, টেকসই এআই উন্নয়নের গুরুত্ব তুলে ধরে।
- মডেলের বিস্তৃত প্রভাব: যদিও মডেলটি নিম্নলিখিত নির্দেশাবলীতে উন্নত কর্মক্ষমতা দেখায়, তবুও বিশেষায়িত অ্যাপ্লিকেশনগুলিতে সর্বোত্তম কর্মক্ষমতার জন্য এটির জন্য টাস্ক-নির্দিষ্ট ফাইন-টিউনিং প্রয়োজন। এই ফাইন-টিউনিং প্রক্রিয়াটি সম্পদ-নিবিড় এবং সর্বদা কার্যকর নাও হতে পারে।
উপসংহার
এই গাইডে, আমরা আপস্টেজ এআই দ্বারা সম্প্রতি প্রকাশিত সোলার 10.7 বিলিয়ন প্যারামিটার মডেলটি দেখেছি। Upstage AI মডেলগুলিকে মার্জ এবং স্কেল করার জন্য একটি নতুন পদ্ধতি গ্রহণ করেছে। কাগজটি শুরুর এবং চূড়ান্ত ট্রান্সফরমার স্তরগুলির কিছু অপসারণ করে দুটি Llama-2 7 বিলিয়ন প্যারামিটার মডেলকে একত্রিত করতে ডেপথ আপ-স্কেলিং নামে একটি নতুন পদ্ধতি ব্যবহার করেছে। পরবর্তীতে, এটি ওপেন সোর্স ডেটাসেটে মডেলটিকে সূক্ষ্মভাবে তৈরি করে এবং এটিকে OpenLLM লিডারবোর্ডে পরীক্ষা করে, সর্বোচ্চ H6 স্কোর অর্জন করে এবং লিডারবোর্ডে শীর্ষে।
কী Takeaways
- SOLAR 10.7B ডেপথ আপ-স্কেলিং প্রবর্তন করে, একটি অনন্য মার্জিং পদ্ধতি, প্রথাগত পদ্ধতিকে চ্যালেঞ্জ করে এবং মডেল আর্কিটেকচারে অগ্রগতি দেখায়
- এর 10.7 বিলিয়ন প্যারামিটার থাকা সত্ত্বেও, SOLAR 10.7B বৃহত্তর মডেলগুলিকে ছাড়িয়ে গেছে, Mistral 7B, Qwen 14B কে ছাড়িয়ে গেছে এবং এমনকি SOLAR 10.7B নির্দেশের মত সংস্করণ সহ লিডারবোর্ডের শীর্ষে রয়েছে।
- নির্দেশনা এবং সারিবদ্ধ টিউনিং জড়িত দুই-পর্যায়ের সূক্ষ্ম-টিউনিং প্রক্রিয়াটি বিভিন্ন কাজের জন্য মডেলের অভিযোজনযোগ্যতা নিশ্চিত করে, নির্দেশাবলী অনুসরণ করতে এবং মানুষের পছন্দের সাথে সারিবদ্ধভাবে এটিকে খুব ভাল করে তোলে।
- SOLAR 10.7B বিভিন্ন মাপকাঠিতে পারদর্শী, এইভাবে মৌলিক গণিত এবং ভাষা বোঝা থেকে শুরু করে কমনসেন্স যুক্তি এবং সত্যতা মূল্যায়ন পর্যন্ত কাজগুলিতে তার দক্ষতা দেখায়
- HuggingFace Hub-এ সহজেই উপলব্ধ, SOLAR 10.7B ডেভেলপার এবং গবেষকদের ভাষা-প্রক্রিয়াকরণ অ্যাপ্লিকেশনগুলির জন্য একটি দক্ষ এবং উপলব্ধ সরঞ্জাম সরবরাহ করে
- বৃহৎ ভাষার মডেলগুলিকে সূক্ষ্ম-টিউন করার জন্য নিযুক্ত নিয়মিত পদ্ধতিগুলি ব্যবহার করে আপনি মডেলটি সূক্ষ্ম-টিউন করতে পারেন। উদাহরণস্বরূপ, আপনি SOLAR 10.7B মডেলটিকে ফাইন-টিউন করতে Hugging Face থেকে সুপারভাইজড ফাইন-টিউন ট্রেনার (SFTrainer) ব্যবহার করতে পারেন।
সচরাচর জিজ্ঞাস্য
A. SOLAR 10.7B হল Upstage AI-এর একটি 10.7 বিলিয়ন প্যারামিটার মডেল, যা ডেপথ আপ-স্কেলিং নামে একটি অনন্য মার্জিং কৌশল ব্যবহার করে। এটি বৃহত্তর এলএলএম-কে ছাড়িয়ে যাওয়া এবং মডেল মার্জ করার ক্ষেত্রে অগ্রগতি প্রদর্শন করে নিজেকে আলাদা করে।
A. Depthwise Scaling এ দুটি বেস মডেল জড়িত। এই দুটি বেস মডেলকে একে অপরের উপরে স্ট্যাক করে সরাসরি একত্রিত করার প্রক্রিয়াটি জড়িত। একত্রিত হওয়ার আগে, একটি মডেল থেকে প্রাথমিক স্তর এবং অন্য মডেল থেকে চূড়ান্ত স্তরগুলি সরানো হয়।
A. SOLAR 10.7B একটি দুই-পর্যায়ের প্রাক-প্রশিক্ষণ প্রক্রিয়ার মধ্য দিয়ে যায়। ইন্সট্রাকশন ফাইন-টিউনিং-এর মধ্যে নির্দেশনা-অনুসরণের উপর জোর দিয়ে ডেটাসেটের মডেলকে প্রশিক্ষণ দেওয়া হয়। প্রান্তিককরণ টিউনিং ডাইরেক্ট প্রেফারেন্স অপ্টিমাইজেশন (DPO) নামক একটি কৌশল ব্যবহার করে মানুষের পছন্দের সাথে মডেলের সারিবদ্ধকরণকে পরিমার্জিত করে।
A. SOLAR 10.7B ARC (AI2 Reasoning Challenge), MMLU (ম্যাসিভ মাল্টিটাস্ক ল্যাঙ্গুয়েজ আন্ডারস্ট্যান্ডিং), HellaSwag, Winogrande, TruthfulQA, এবং GSM8K সহ বিভিন্ন বেঞ্চমার্ক জুড়ে পারদর্শী। এটি উচ্চ স্কোর অর্জন করে, বিভিন্ন ভাষার কাজ পরিচালনায় এর বহুমুখিতা প্রদর্শন করে।
A. SOLAR 10.7B মিস্ট্রাল 7B এবং Qwen 14B এর মতো মডেলগুলিকে ছাড়িয়ে গেছে, কম প্যারামিটার থাকা সত্ত্বেও উচ্চতর কর্মক্ষমতা প্রদর্শন করে৷ ইন্সট্রাক্ট সংস্করণটি এমনকি মিস্ট্রাল 8x7B এবং Qwen 72B সহ অনেক বড় মডেলের সাথে বিভিন্ন বেঞ্চমার্কে প্রতিযোগিতা করে এবং ছাড়িয়ে যায়।
এই নিবন্ধে দেখানো মিডিয়া Analytics বিদ্যার মালিকানাধীন নয় এবং লেখকের বিবেচনার ভিত্তিতে ব্যবহার করা হয়।
সংশ্লিষ্ট
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://www.analyticsvidhya.com/blog/2024/01/solar-10-7b-comparing-its-performance-to-other-notable-llms/
- : আছে
- : হয়
- :না
- :কোথায়
- $ ইউপি
- 10
- 110
- 12
- 15%
- 16
- 24
- 300
- 32
- 60
- 7
- 70
- 8
- 80
- 9
- a
- ক্ষমতার
- ক্ষমতা
- সক্ষম
- প্রবেশ
- সঠিকতা
- জাতিসংঘের
- অর্জনের
- দিয়ে
- ঠিকানা
- যোগ করে
- উন্নয়নের
- পর
- এগিয়ে
- AI
- AI2
- উপলক্ষিত
- লক্ষ্য
- শ্রেণীবদ্ধ করা
- প্রান্তিককৃত
- সারিবদ্ধ করা
- শ্রেণীবিন্যাস
- সব
- অনুমতি
- বরাবর
- এছাড়াও
- সর্বদা
- পরিমাণ
- an
- বিশ্লেষণ
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ বিদ্যা
- এবং
- অন্য
- উত্তর
- উত্তর
- API
- আবেদন
- অ্যাপ্লিকেশন
- প্রয়োগ করা
- অভিগমন
- যথাযথ
- চাপ
- স্থাপত্য
- রয়েছি
- এলাকার
- প্রবন্ধ
- AS
- দৃষ্টিভঙ্গি
- আ
- নির্ণয়
- পরিমাপন
- সহায়ক
- At
- মনোযোগ
- সহজলভ্য
- ভিত্তি
- মৌলিক
- BE
- বীট
- কারণ
- হয়েছে
- আগে
- শুরু হয়
- হচ্ছে
- নিচে
- উচ্চতার চিহ্ন
- benchmarks
- সর্বোত্তম
- মধ্যে
- গোঁড়ামির
- বিলিয়ন
- বিট
- ব্লগাথন
- উভয়
- বৃহত্তর
- কিন্তু
- by
- কল
- নামক
- CAN
- ক্ষমতা
- কিছু
- চ্যালেঞ্জ
- চ্যালেঞ্জ
- চ্যালেঞ্জিং
- চ্যাট
- পছন্দ
- মনোনীত
- শ্রেণী
- পরিষ্কারভাবে
- বন্ধ
- কোড
- স্তম্ভ
- কলাম
- মিশ্রন
- আসা
- সাধারণ
- সাধারণ বোধ
- তুলনা করা
- তুলনা
- তুলনা
- তুলনা
- প্রতিদ্বন্দ্বিতা
- জটিল
- জটিলতার
- জটিলতা
- গণনা
- কম্পিউটার
- কম্পিউটার বিজ্ঞান
- ধারণা
- উদ্বেগ
- শেষ করা
- আচার
- বিবেচিত
- খরচ
- ধারণ
- বিষয়বস্তু
- প্রসঙ্গ
- অব্যাহত
- বিপরীত হত্তয়া
- অবদানকারী
- মূল
- সঠিকভাবে
- পারা
- কভার
- সিপিইউ
- সৃষ্টি
- নির্মিত
- কঠোর
- উপাত্ত
- ডেটাসেট
- হ্রাস
- প্রদান করা
- দাবি
- ডেমো
- প্রদর্শন
- প্রদর্শক
- গভীরতা
- পরিকল্পিত
- সত্ত্বেও
- ডেভেলপারদের
- উন্নয়ন
- বিভিন্ন
- সরাসরি
- সরাসরি
- নিয়মানুবর্তিতা
- বিচক্ষণতা
- আলাদা
- বিচিত্র
- do
- না
- সম্পন্ন
- ডাউনলোড
- ডাউনলোড
- কারণে
- প্রতি
- খাওয়া
- কার্যকর
- কার্যকারিতা
- দক্ষ
- ডিম
- জোর
- নিযুক্ত
- নিয়োগ
- প্রান্ত
- শক্তি
- শক্তি খরচ
- যথেষ্ট
- নিশ্চিত
- সমগ্র
- পরিবেশ
- পরিবেশগত উদ্বেগ
- পর্বগুলি
- থার (eth)
- মূল্যায়ন
- মূল্যায়ন
- এমন কি
- প্রতিদিন
- সবাই
- নব্য
- উদাহরণ
- উদাহরণ
- বিদ্যমান
- পরীক্ষা-নিরীক্ষা
- বিশেষজ্ঞদের
- অন্বেষণ
- মুখ
- বাস্তবিক
- বাজপাখি
- এ পর্যন্ত
- দ্রুত
- প্রতিক্রিয়া
- কয়েক
- কম
- ক্ষেত্র
- চূড়ান্ত
- প্রথম
- ফ্ল্যাশ
- গুরুত্ত্ব
- অনুসৃত
- অনুসরণ
- জন্য
- ফর্ম
- গঠন
- বিনামূল্যে
- থেকে
- অধিকতর
- ভবিষ্যৎ
- উত্পাদন করা
- উত্পন্ন
- উৎপাদিত
- প্রজন্ম
- পাওয়া
- পেয়ে
- দাও
- প্রদত্ত
- দান
- ভাল
- গুগল
- পেয়েছিলাম
- জিপিইউ
- উন্নতি
- কৌশল
- হ্যান্ডলগুলি
- হ্যান্ডলিং
- হার্ডওয়্যারের
- আছে
- জমিদারি
- অত: পর
- এখানে
- উচ্চ
- সর্বোচ্চ
- হাইলাইট
- ইতিহাস
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- নাভি
- প্রচুর
- জড়িয়ে আছে
- মানবীয়
- মানুষেরা
- if
- প্রভাব
- প্রভাব
- আমদানি
- গুরুত্ব
- চিত্তাকর্ষক
- উন্নত
- in
- গোড়া
- অন্তর্ভুক্ত করা
- অন্তর্ভুক্ত
- সুদ্ধ
- তথ্য
- প্রারম্ভিক
- প্রবর্তিত
- উদ্ভাবনী
- ইনপুট
- অর্ন্তদৃষ্টি
- ইনস্টল
- উদাহরণ
- নির্দেশাবলী
- মধ্যে
- প্রবর্তন করা
- উপস্থাপিত
- পরিচয় করিয়ে দেয়
- স্বজ্ঞাত
- জড়িত করা
- জড়িত
- জড়িত
- ঘটিত
- IT
- এর
- নিজেই
- জন
- আদালতের রায়
- মাত্র
- কুমার
- ভাষা
- বড়
- বৃহত্তর
- আইন
- রাখা
- স্তর
- লিডারবোর্ড
- নেতৃত্ব
- শিক্ষা
- লম্বা
- যাক
- উচ্চতা
- ওঠানামায়
- লাইব্রেরি
- জীবনকাল
- মত
- LIMIT টি
- সীমাবদ্ধতা
- সীমাবদ্ধতা
- সীমিত
- শিখা
- বোঝা
- বোঝাই
- যুক্তিবিদ্যা
- যৌক্তিক
- দেখুন
- মেশিন
- মেশিন লার্নিং
- প্রধানত
- মুখ্য
- করা
- প্রস্তুতকর্তা
- তৈরি করে
- মেকিং
- অনেক
- বৃহদায়তন
- গণিত
- গাণিতিক
- অংক
- সর্বোচ্চ প্রস্থ
- সর্বাধিক
- সর্বোচ্চ পরিমাণ
- মে..
- পদ্ধতি
- মিডিয়া
- উল্লেখ
- মার্জ
- মার্জ
- পদ্ধতি
- পদ্ধতি
- ভুল
- মিশ্রণ
- মডেল
- মডেল
- অধিক
- আরো দক্ষ
- বহু
- নাম
- প্রয়োজনীয়
- প্রয়োজন
- প্রয়োজন
- চাহিদা
- নেটওয়ার্ক
- নতুন
- পরবর্তী
- NLP
- স্মরণীয়
- সুপরিচিত
- এখন
- শেড
- সংখ্যা
- এনভিডিয়া
- লক্ষ্য
- of
- on
- ONE
- কেবল
- খোলা
- ওপেন সোর্স
- OpenAI
- অপারেটিং
- অনুকূল
- অপ্টিমাইজেশান
- or
- মূল
- অন্যান্য
- অন্যরা
- আমাদের
- বাইরে
- ফলাফল
- ছাড়িয়া যাত্তয়া
- পারফর্ম করেছে
- outperforming
- outperforms
- আউটপুট
- শেষ
- সামগ্রিক
- মালিক হয়েছেন
- কাগজ
- স্থিতিমাপ
- পরামিতি
- অংশ
- পাস
- পথ
- সম্পাদন করা
- কর্মক্ষমতা
- ক্রিয়াকাণ্ড
- সম্পাদিত
- করণ
- সঞ্চালিত
- জায়গা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- রাজনীতি
- জনপ্রিয়
- ভঙ্গি
- সম্ভাব্য
- ক্ষমতাশালী
- পছন্দগুলি
- পছন্দের
- বর্তমান
- আগে
- প্রিন্ট
- সমস্যা সমাধান
- সমস্যা
- প্রক্রিয়া
- প্রসেস
- অনুরোধ জানানো
- প্রমাণ
- প্রদত্ত
- উপলব্ধ
- প্রদানের
- প্রকাশিত
- পাইথন
- প্রশ্ন
- দ্রুত
- রেঞ্জিং
- দ্রুত
- ইচ্ছাপূর্বক
- সাম্প্রতিক
- সম্প্রতি
- নিয়মিত
- শক্তিবৃদ্ধি শেখার
- প্রত্যাখ্যাত..
- সংশ্লিষ্ট
- মুক্তি
- মুক্ত
- বিশ্বাসযোগ্যতা
- অপসারণ
- অপসারিত
- সরানোর
- প্রতিস্থাপন করা
- প্রতিস্থাপিত
- প্রয়োজন
- গবেষণা
- গবেষকরা
- সংস্থান-নিবিড়
- Resources
- প্রতিক্রিয়া
- প্রতিক্রিয়া
- ফল
- ফলাফল
- আয়
- অধিকার
- কঠোর
- উদিত
- চালান
- দৌড়
- রান
- বলেছেন
- একই
- সংরক্ষিত
- স্কেল
- আরোহী
- পরিস্থিতিতে
- বিজ্ঞান
- বৈজ্ঞানিক
- স্কোর
- স্কোর
- দ্বিতীয়
- অধ্যায়
- দেখ
- এইজন্য
- মনে হয়
- দেখা
- অনুভূতি
- বাক্য
- ক্রম
- সেট
- বিভিন্ন
- উচিত
- প্রদর্শনী
- বেড়াবে
- দেখাচ্ছে
- প্রদর্শিত
- শো
- অনুরূপ
- সহজ
- থেকে
- একক
- দক্ষতা
- স্মার্টফোনের
- So
- সৌর
- কিছু
- বাস্তববুদ্ধিসম্পন্ন
- উৎস
- বিশেষজ্ঞ
- বিশেষভাবে
- নিদিষ্ট
- স্ট্যাক
- পর্যায়
- থাকা
- শুরু
- শুরু
- শুরু হচ্ছে
- শুরু
- বিবৃতি
- ধাপ
- এখনো
- থামুন
- দোকান
- সঞ্চিত
- ঝড়
- এমন
- উচ্চতর
- ছাড়িয়ে
- সবাইকে অতিক্রমকারী
- কার্যক্ষম
- টেকসই
- করা SVG
- পদ্ধতি
- গ্রহণ করা
- ধরা
- লাগে
- কাজ
- প্রযুক্তি
- বলা
- বলে
- টেমপ্লেট
- পরীক্ষা
- প্রমাণিত
- পরীক্ষামূলক
- পরীক্ষা
- পাঠ
- চেয়ে
- যে
- সার্জারির
- বিশ্ব
- তাদের
- তাহাদিগকে
- তারপর
- সেখানে।
- এইগুলো
- তারা
- চিন্তা
- এই
- সেগুলো
- যদিও?
- চিন্তা
- তিন
- দ্বারা
- এইভাবে
- সময়
- বার
- থেকে
- একসঙ্গে
- টোকেন
- টোকেন
- টুল
- শীর্ষ
- শীর্ষস্থানে
- ঐতিহ্যগত
- রেলগাড়ি
- প্রশিক্ষিত
- প্রশিক্ষণ
- ট্রান্সফরমার
- ট্রান্সফরমার
- চেষ্টা
- দুই
- আদর্শ
- ক্ষয়ের
- বোঝা
- বোধশক্তি
- নিয়েছেন
- অনন্য
- উপরে
- us
- ব্যবহার
- ব্যবহার
- ব্যবহৃত
- দরকারী
- ব্যবহারকারী
- ব্যবহারসমূহ
- ব্যবহার
- সদ্ব্যবহার করা
- ব্যবহার
- ব্যবহার
- পরিবর্তনশীল
- বৈচিত্র্য
- বিভিন্ন
- যাচাই
- বহুমুখতা
- সংস্করণ
- খুব
- vs
- প্রয়োজন
- ছিল
- উপায়..
- we
- webp
- আমরা একটি
- ছিল
- কি
- কখন
- যে
- যখন
- ব্যাপকতর
- ইচ্ছা
- সঙ্গে
- ছাড়া
- হয়া যাই ?
- কাজ
- কাজ
- বিশ্ব
- আপনি
- আপনার
- zephyrnet