ধরুন আপনি প্রতিযোগী ওয়েবসাইটগুলিকে তাদের মূল্য পৃষ্ঠার তথ্যের জন্য স্ক্র্যাপ করতে চান। তুমি কি করবে? কপি-পেস্ট করা বা ম্যানুয়ালি ডেটা প্রবেশ করা খুব ধীর, সময়সাপেক্ষ এবং ত্রুটি-প্রবণ। আপনি পাইথন ব্যবহার করে সহজেই এটি স্বয়ংক্রিয় করতে পারেন।
এই টিউটোরিয়ালে পাইথন ব্যবহার করে কিভাবে ওয়েবপেজ স্ক্র্যাপ করা যায় তা দেখা যাক।
বিভিন্ন পাইথন ওয়েব স্ক্র্যাপিং লাইব্রেরি কি কি?
থার্ড-পার্টি লাইব্রেরির প্রাচুর্যের কারণে পাইথন ওয়েব স্ক্র্যাপিংয়ের জন্য জনপ্রিয় যা জটিল এইচটিএমএল স্ট্রাকচার, টেক্সট পার্স করতে এবং এইচটিএমএল ফর্মের সাথে ইন্টারঅ্যাক্ট করতে পারে। এখানে, আমরা কিছু শীর্ষ পাইথন ওয়েব স্ক্র্যাপিং লাইব্রেরি তালিকাভুক্ত করেছি।
- Urllib3 পাইথনের জন্য একটি শক্তিশালী HTTP ক্লায়েন্ট লাইব্রেরি। এটি প্রোগ্রামগতভাবে HTTP অনুরোধগুলি সম্পাদন করা সহজ করে তোলে। এটি HTTP শিরোনাম, পুনঃপ্রচার, পুনঃনির্দেশ এবং অন্যান্য নিম্ন-স্তরের বিবরণ পরিচালনা করে, এটি ওয়েব স্ক্র্যাপিংয়ের জন্য একটি চমৎকার লাইব্রেরি করে তোলে। এটি SSL যাচাইকরণ, সংযোগ পুলিং এবং প্রক্সি করাকেও সমর্থন করে।
- সুন্দর স্যুপ আপনাকে HTML এবং XML ডকুমেন্ট পার্স করতে দেয়। আপনি সহজেই HTML ডকুমেন্ট ট্রির মাধ্যমে নেভিগেট করতে পারেন এবং API ব্যবহার করে ট্যাগ, মেটা শিরোনাম, গুণাবলী, পাঠ্য এবং অন্যান্য সামগ্রী বের করতে পারেন। BeautifulSoup তার শক্তিশালী ত্রুটি পরিচালনার জন্যও পরিচিত।
- যান্ত্রিক স্যুপ দক্ষতার সাথে একটি ওয়েব ব্রাউজার এবং একটি ওয়েবসাইটের মধ্যে মিথস্ক্রিয়া স্বয়ংক্রিয় করে। এটি ওয়েব স্ক্র্যাপিংয়ের জন্য একটি উচ্চ-স্তরের API প্রদান করে যা মানুষের আচরণকে অনুকরণ করে। MechanicalSoup-এর মাধ্যমে, আপনি HTML ফর্মের সাথে ইন্টারঅ্যাক্ট করতে পারেন, বোতামে ক্লিক করতে পারেন এবং একজন প্রকৃত ব্যবহারকারীর মতো উপাদানগুলির সাথে ইন্টারঅ্যাক্ট করতে পারেন।
- অনুরোধ HTTP অনুরোধ করার জন্য একটি সহজ কিন্তু শক্তিশালী পাইথন লাইব্রেরি। এটি একটি পরিষ্কার এবং সামঞ্জস্যপূর্ণ API সহ ব্যবহার করা সহজ এবং স্বজ্ঞাত হওয়ার জন্য ডিজাইন করা হয়েছে৷ অনুরোধের মাধ্যমে, আপনি সহজেই GET এবং POST অনুরোধ পাঠাতে পারেন এবং কুকি, প্রমাণীকরণ এবং অন্যান্য HTTP বৈশিষ্ট্যগুলি পরিচালনা করতে পারেন। এটির সরলতা এবং ব্যবহারের সহজতার কারণে এটি ওয়েব স্ক্র্যাপিংয়েও ব্যাপকভাবে ব্যবহৃত হয়।
- সেলেনিউম্ আপনাকে ক্রোম, ফায়ারফক্স এবং সাফারির মতো ওয়েব ব্রাউজারগুলিকে স্বয়ংক্রিয় করতে এবং ওয়েবসাইটগুলির সাথে মানুষের মিথস্ক্রিয়া অনুকরণ করতে দেয়৷ আপনি বোতামে ক্লিক করতে পারেন, ফর্মগুলি পূরণ করতে পারেন, পৃষ্ঠাগুলি স্ক্রোল করতে পারেন এবং অন্যান্য ক্রিয়া সম্পাদন করতে পারেন৷ এটি ওয়েব অ্যাপ্লিকেশন পরীক্ষা এবং পুনরাবৃত্তিমূলক কাজগুলি স্বয়ংক্রিয় করার জন্যও ব্যবহৃত হয়।
- পান্ডাস CSV, Excel, JSON, এবং SQL ডাটাবেস সহ বিভিন্ন ফর্ম্যাটে ডেটা সংরক্ষণ এবং ম্যানিপুলেট করার অনুমতি দেয়। পান্ডা ব্যবহার করে, আপনি সহজেই ওয়েবসাইটগুলি থেকে বের করা ডেটা পরিষ্কার, রূপান্তর এবং বিশ্লেষণ করতে পারেন।
মাত্র এক ক্লিকে যেকোনো ওয়েবপেজ থেকে টেক্সট বের করুন। উপর মাথা Nanonets ওয়েবসাইট স্ক্র্যাপার, URL যোগ করুন এবং "স্ক্র্যাপ" এ ক্লিক করুন এবং ওয়েবপৃষ্ঠার পাঠ্যটিকে একটি ফাইল হিসাবে অবিলম্বে ডাউনলোড করুন৷ এখন বিনামূল্যে এটি চেষ্টা করুন.
পাইথন ব্যবহার করে ওয়েবসাইটগুলি থেকে ডেটা কীভাবে স্ক্র্যাপ করবেন?
আসুন ওয়েবসাইট ডেটা স্ক্র্যাপ করতে পাইথন ব্যবহার করার ধাপে ধাপে প্রক্রিয়াটি দেখে নেওয়া যাক।
ধাপ 1: ওয়েবসাইট এবং ওয়েবপৃষ্ঠা URL চয়ন করুন
প্রথম ধাপ হল আপনি যে ওয়েবসাইটটি স্ক্র্যাপ করতে চান সেটি নির্বাচন করা। এই বিশেষ টিউটোরিয়ালের জন্য, এর স্ক্র্যাপ করা যাক https://www.imdb.com/. আমরা ওয়েবসাইটে টপ-রেট করা সিনেমার ডেটা বের করার চেষ্টা করব।
ধাপ 2: ওয়েবসাইট পরিদর্শন করুন
এখন পরবর্তী ধাপ হল ওয়েবসাইট কাঠামো বোঝা। আপনার আগ্রহের উপাদানগুলির বৈশিষ্ট্যগুলি কী তা বুঝুন। "পরিদর্শন" নির্বাচন করতে ওয়েবসাইটে ডান-ক্লিক করুন। এটি HTML কোড খুলবে। কোডে ব্যবহার করার জন্য সমস্ত উপাদানের নাম দেখতে ইন্সপেক্টর টুল ব্যবহার করুন।
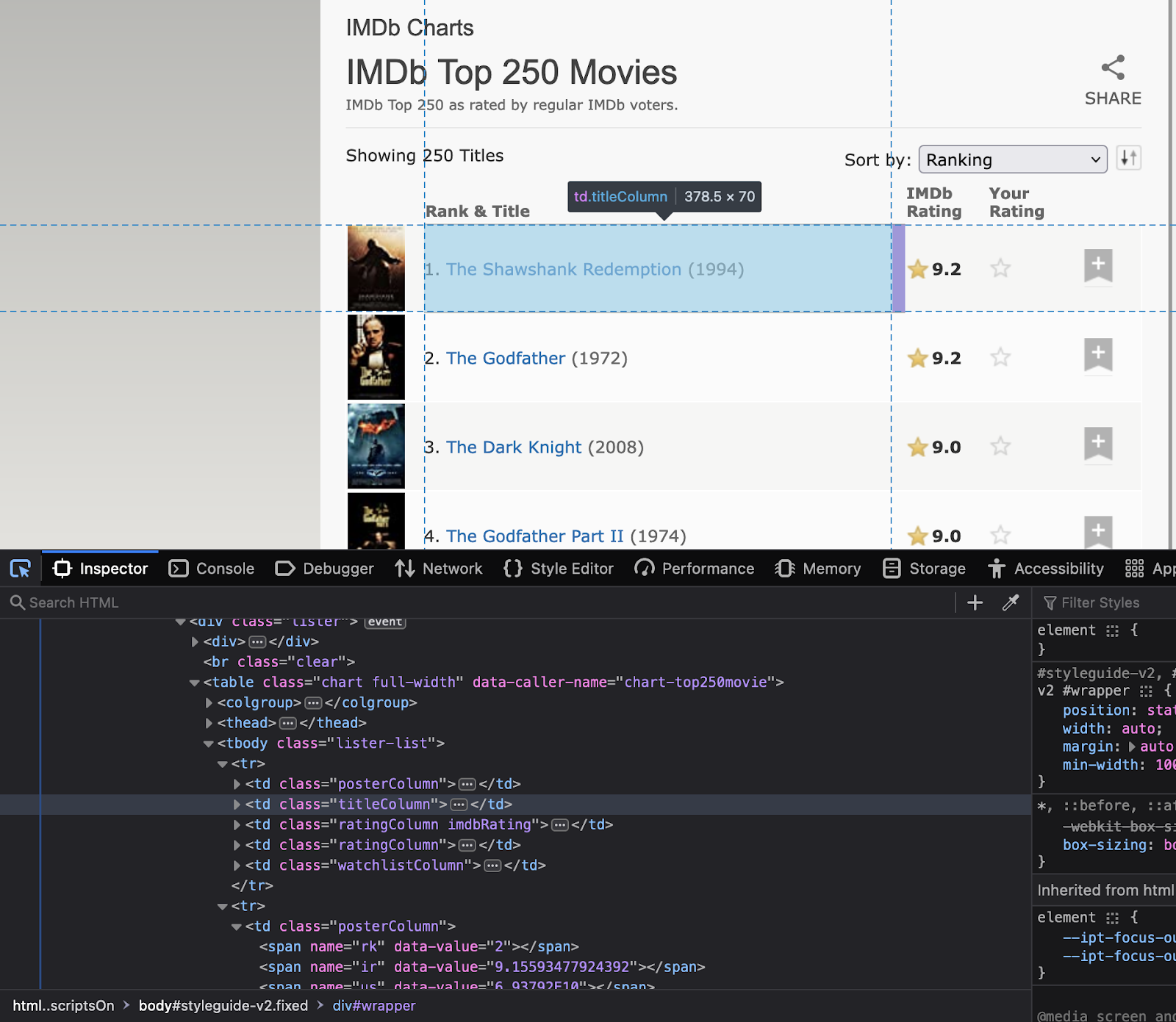
এই উপাদানগুলির ক্লাসের নাম এবং আইডিগুলি নোট করুন কারণ সেগুলি পাইথন কোডে ব্যবহার করা হবে।
ধাপ 3: গুরুত্বপূর্ণ লাইব্রেরি ইনস্টল করা
আগে আলোচনা করা হয়েছে, পাইথনের বেশ কয়েকটি ওয়েব স্ক্র্যাপিং লাইব্রেরি রয়েছে। আজ, আমরা নিম্নলিখিত লাইব্রেরিগুলি ব্যবহার করব:
- অনুরোধ - ওয়েবসাইটে HTTP অনুরোধ করার জন্য
- সুন্দর স্যুপ - HTML কোড পার্স করার জন্য
- পান্ডাস - একটি ডেটা ফ্রেমে স্ক্র্যাপ করা ডেটা সংরক্ষণ করার জন্য
- সময় - অনুরোধের সাথে ওয়েবসাইটকে অপ্রতিরোধ্য এড়াতে অনুরোধের মধ্যে বিলম্ব যোগ করার জন্য
নিম্নলিখিত কমান্ড ব্যবহার করে লাইব্রেরি ইনস্টল করুন
pip install requests beautifulsoup4 pandas timeধাপ 4: পাইথন কোড লিখুন
এখন, মূল পাইথন কোড লেখার সময় এসেছে। কোডটি নিম্নলিখিত পদক্ষেপগুলি সম্পাদন করবে:
- একটি HTTP GET অনুরোধ পাঠাতে অনুরোধ ব্যবহার করে
- HTML কোড পার্স করতে BeautifulSoup ব্যবহার করে
- HTML কোড থেকে প্রয়োজনীয় ডাটা বের করা
- একটি পান্ডাস ডেটাফ্রেমে তথ্য সংরক্ষণ করুন
- অনুরোধের সাথে ওয়েবসাইটকে অপ্রতিরোধ্য এড়াতে অনুরোধগুলির মধ্যে একটি বিলম্ব যোগ করুন
IMDb থেকে শীর্ষ-রেটেড মুভিগুলিকে স্ক্র্যাপ করার জন্য এখানে পাইথন কোড রয়েছে:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
# URL of the website to scrape
url = "https://www.imdb.com/chart/top"
# Send an HTTP GET request to the website
response = requests.get(url)
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the relevant information from the HTML code
movies = []
for row in soup.select('tbody.lister-list tr'):
title = row.find('td', class_='titleColumn').find('a').get_text()
year = row.find('td', class_='titleColumn').find('span', class_='secondaryInfo').get_text()[1:-1]
rating = row.find('td', class_='ratingColumn imdbRating').find('strong').get_text()
movies.append([title, year, rating])
# Store the information in a pandas dataframe
df = pd.DataFrame(movies, columns=['Title', 'Year', 'Rating'])
# Add a delay between requests to avoid overwhelming the website with requests
time.sleep(1)ধাপ 5: নিষ্কাশিত ডেটা রপ্তানি করা হচ্ছে
এখন, একটি CSV ফাইল হিসাবে ডেটা রপ্তানি করা যাক। আমরা পান্ডাস লাইব্রেরি ব্যবহার করব।
# Export the data to a CSV file
df.to_csv('top-rated-movies.csv', index=False)ধাপ 6: নিষ্কাশিত ডেটা যাচাই করুন
ডেটা সফলভাবে স্ক্র্যাপ এবং সংরক্ষণ করা হয়েছে তা যাচাই করতে CSV ফাইলটি খুলুন।
আমরা আশা করি এই টিউটোরিয়ালটি আপনাকে ওয়েবপেজ থেকে সহজে ডেটা বের করতে সাহায্য করবে।
মাত্র এক ক্লিকে যেকোনো ওয়েবপেজ থেকে টেক্সট বের করুন। উপর মাথা Nanonets ওয়েবসাইট স্ক্র্যাপার, URL যোগ করুন এবং "স্ক্র্যাপ" এ ক্লিক করুন এবং ওয়েবপৃষ্ঠার পাঠ্যটিকে একটি ফাইল হিসাবে অবিলম্বে ডাউনলোড করুন৷ এখন বিনামূল্যে এটি চেষ্টা করুন.
ওয়েবসাইট থেকে টেক্সট পার্স কিভাবে?
আপনি BeautifulSoup বা lxml ব্যবহার করে সহজেই ওয়েবসাইট টেক্সট পার্স করতে পারেন। এখানে কোডের সাথে জড়িত পদক্ষেপগুলি রয়েছে৷
- আমরা URL-এ একটি HTTP অনুরোধ পাঠাব এবং ওয়েবপৃষ্ঠার HTML সামগ্রী পাব৷
- একবার আপনার এইচটিএমএল কাঠামো হয়ে গেলে, আমরা একটি নির্দিষ্ট HTML ট্যাগ বা বৈশিষ্ট্য সনাক্ত করতে BeautifulSoup এর find() পদ্ধতি ব্যবহার করব।
- এবং তারপর টেক্সট অ্যাট্রিবিউট দিয়ে টেক্সট কন্টেন্ট এক্সট্রাক্ট করুন।
BeautifulSoup ব্যবহার করে একটি ওয়েবসাইট থেকে পাঠ্য পার্স করার জন্য এখানে একটি কোড রয়েছে৷:
import requests
from bs4 import BeautifulSoup
# Send an HTTP request to the URL of the webpage you want to access
response = requests.get("https://www.example.com")
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the text content of the webpage
text = soup.get_text()
print(text)পাইথন ব্যবহার করে এইচটিএমএল ফর্মগুলি কীভাবে স্ক্র্যাপ করবেন?
পাইথন ব্যবহার করে এইচটিএমএল ফর্মগুলি স্ক্র্যাপ করতে, আপনি একটি লাইব্রেরি ব্যবহার করতে পারেন যেমন বিউটিফুলসুপ, lxml বা মেকানাইজ। এখানে সাধারণ পদক্ষেপগুলি রয়েছে:
- আপনি যে ফর্মটি স্ক্র্যাপ করতে চান তার সাথে ওয়েবপৃষ্ঠার URL-এ একটি HTTP অনুরোধ পাঠান। সার্ভার ওয়েবপৃষ্ঠার HTML বিষয়বস্তু ফেরত দিয়ে অনুরোধে সাড়া দেয়।
- একবার আপনি HTML বিষয়বস্তু অ্যাক্সেস করার পরে, আপনি যে ফর্মটি স্ক্র্যাপ করতে চান তা সনাক্ত করতে আপনি একটি HTML পার্সার ব্যবহার করতে পারেন। উদাহরণস্বরূপ, আপনি ফর্ম ট্যাগ সনাক্ত করতে BeautifulSoup এর find() পদ্ধতি ব্যবহার করতে পারেন।
- একবার আপনি ফর্মটি সনাক্ত করলে, আপনি HTML পার্সার ব্যবহার করে ইনপুট ক্ষেত্র এবং তাদের সংশ্লিষ্ট মানগুলি বের করতে পারেন। উদাহরণস্বরূপ, আপনি ফর্মের মধ্যে সমস্ত ইনপুট ট্যাগ সনাক্ত করতে BeautifulSoup এর find_all() পদ্ধতি ব্যবহার করতে পারেন এবং তারপরে তাদের নাম এবং মান বৈশিষ্ট্যগুলি বের করতে পারেন।
- তারপরে আপনি ফর্ম জমা দিতে বা আরও ডেটা প্রক্রিয়াকরণ করতে এই ডেটা ব্যবহার করতে পারেন।
মেকানাইজ ব্যবহার করে কীভাবে একটি এইচটিএমএল ফর্ম স্ক্র্যাপ করা যায় তার একটি উদাহরণ এখানে দেওয়া হল:
import mechanize
# Create a mechanize browser object
browser = mechanize.Browser()
# Send an HTTP request to the URL of the webpage with the form you want to scrape
browser.open("https://www.example.com/form")
# Select the form to scrape
browser.select_form(nr=0)
# Extract the input fields and their corresponding values
for control in browser.form.controls:
print(control.name, control.value)
# Submit the form
browser.submit()যেকোনো ওয়েবপেজ থেকে টেক্সট বের করুন মাত্র এক ক্লিকে। Nanonets ওয়েবসাইট স্ক্র্যাপারে যান, URL যোগ করুন এবং "স্ক্র্যাপ" এ ক্লিক করুন এবং ওয়েবপৃষ্ঠার পাঠ্যটি একটি ফাইল হিসাবে অবিলম্বে ডাউনলোড করুন। এখন বিনামূল্যে এটি চেষ্টা করুন.
সমস্ত পাইথন ওয়েব স্ক্র্যাপিং লাইব্রেরি তুলনা করা হচ্ছে
আসুন সমস্ত পাইথন ওয়েব স্ক্র্যাপিং লাইব্রেরি তুলনা করি। তাদের সকলেরই চমৎকার সম্প্রদায়ের সমর্থন রয়েছে, তবে ব্লগের শুরুতে উল্লিখিত হিসাবে তারা ব্যবহারের সহজে এবং তাদের ব্যবহারের ক্ষেত্রে ভিন্ন।
|
লাইব্রেরি |
ব্যবহারে সহজ |
সম্পাদন |
নমনীয়তা |
কমিউনিটি সাপোর্ট |
আইনি/নৈতিক বিবেচনা |
|
সুন্দর স্যুপ |
সহজ |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
স্ক্র্যাপি |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
সেলেনিউম্ |
সহজ |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
সেরা অভ্যাস অনুসরণ করুন |
|
অনুরোধ |
সহজ |
উচ্চ |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
PyQuery |
সহজ |
উচ্চ |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
এলএক্সএমএল |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
যান্ত্রিক স্যুপ |
সহজ |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
সুন্দর স্যুপ4 |
সহজ |
মধ্যপন্থী |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
|
পাইস্পাইডার |
সহজ |
উচ্চ |
উচ্চ |
উচ্চ |
ব্যবহারের শর্তাবলী মেনে চলুন |
উপসংহার
পাইথন রিয়েল-টাইমে ওয়েবসাইট ডেটা স্ক্র্যাপ করার জন্য একটি চমৎকার বিকল্প। আরেকটি বিকল্প হল স্বয়ংক্রিয় ব্যবহার করা ওয়েবসাইট স্ক্র্যাপিং টুল like Nanonets. আপনি ব্যবহার করতে পারেন বিনামূল্যে ওয়েবসাইট-টু-টেক্সট টুল. কিন্তু, যদি আপনার বড় প্রকল্পগুলির জন্য ওয়েব স্ক্র্যাপিং স্বয়ংক্রিয় করার প্রয়োজন হয়, আপনি Nanonets এর সাথে যোগাযোগ করতে পারেন।
মাত্র এক ক্লিকে যেকোনো ওয়েবপেজ থেকে টেক্সট বের করুন। Nanonets ওয়েবসাইট স্ক্র্যাপারে যান, URL যোগ করুন এবং "স্ক্র্যাপ" এ ক্লিক করুন এবং ওয়েবপৃষ্ঠার পাঠ্যটি একটি ফাইল হিসাবে অবিলম্বে ডাউনলোড করুন। এখন বিনামূল্যে এটি চেষ্টা করুন.
বিবরণ
পাইথন ব্যবহার করে ওয়েব স্ক্র্যাপিংয়ের জন্য কীভাবে এইচটিএমএল পার্সার ব্যবহার করবেন?
পাইথনে ওয়েব স্ক্র্যাপিংয়ের জন্য একটি এইচটিএমএল পার্সার ব্যবহার করতে, আপনি বিউটিফুলসুপ বা lxml এর মতো একটি লাইব্রেরি ব্যবহার করতে পারেন। এখানে সাধারণ পদক্ষেপগুলি রয়েছে:
- আপনি যে ওয়েবপৃষ্ঠাটি অ্যাক্সেস করতে চান তার URL-এ একটি HTTP অনুরোধ পাঠান। সার্ভার ওয়েবপৃষ্ঠার HTML বিষয়বস্তু ফেরত দিয়ে অনুরোধে সাড়া দেয়।
- একবার আপনি HTML বিষয়বস্তু অ্যাক্সেস করার পরে, আপনি আপনার প্রয়োজনীয় ডেটা বের করতে একটি HTML পার্সার ব্যবহার করতে পারেন। উদাহরণস্বরূপ, আপনি একটি নির্দিষ্ট HTML ট্যাগ বা বৈশিষ্ট্য সনাক্ত করতে BeautifulSoup এর find() পদ্ধতি ব্যবহার করতে পারেন এবং তারপর পাঠ্য বৈশিষ্ট্য সহ পাঠ্য সামগ্রীটি বের করতে পারেন।
ওয়েব স্ক্র্যাপিংয়ের জন্য বিউটিফুল স্যুপ কীভাবে ব্যবহার করবেন তার একটি উদাহরণ এখানে রয়েছে:
পাইথন
আমদানি করার অনুরোধ
বিএস 4 আমদানি করা বিউটিফুলসপ থেকে
# আপনি যে ওয়েবপৃষ্ঠাটি অ্যাক্সেস করতে চান তার URL-এ একটি HTTP অনুরোধ পাঠান
প্রতিক্রিয়া = requests.get("https://www.example.com")
# BeautifulSoup ব্যবহার করে HTML বিষয়বস্তু পার্স করুন
স্যুপ = সুন্দর স্যুপ(response.content, “html.parser”)
# ওয়েবপেজ থেকে নির্দিষ্ট ডেটা বের করুন
title = soup.title
মুদ্রণ (শিরোনাম)
এই উদাহরণে, আমরা ওয়েবপেজের এইচটিএমএল কন্টেন্ট পার্স করতে BeautifulSoup ব্যবহার করি এবং টাইটেল অ্যাট্রিবিউট ব্যবহার করে পেজের শিরোনাম বের করি।
কেন ওয়েব স্ক্র্যাপিং ব্যবহার করা হয়?
ওয়েব স্ক্র্যাপিং স্বয়ংক্রিয় সরঞ্জাম বা স্ক্রিপ্ট ব্যবহার করে ওয়েবসাইট ডেটা স্ক্র্যাপ করতে ব্যবহৃত হয়। এটি একাধিক উদ্দেশ্যে ব্যবহার করা যেতে পারে
- একাধিক ওয়েবপেজ থেকে ডেটা বের করা এবং আরও বিশ্লেষণ করতে ডেটা একত্রিত করা।
- বিভিন্ন টাইম স্ট্যাম্পে রিয়েল-টাইম ডেটা স্ক্র্যাপ করে প্রবণতা প্রাপ্ত করা।
- প্রতিযোগী মূল্য প্রবণতা নিরীক্ষণ.
- ওয়েবসাইট থেকে ইমেল স্ক্র্যাপ করে লিড তৈরি করা।
ওয়েব স্ক্র্যাপিং কী?
ওয়েব স্ক্র্যাপিং আমি অসংগঠিত HTML ওয়েবসাইট থেকে স্ট্রাকচার্ড ডেটা বের করতে ব্যবহার করি। ওয়েব স্ক্র্যাপিং স্বয়ংক্রিয় ব্যবহার জড়িত ওয়েব স্ক্র্যাপিং সরঞ্জাম অথবা জটিল ওয়েব পেজ পার্স করার জন্য স্ক্রিপ্ট।
ওয়েব স্ক্র্যাপিং কি বৈধ?
আপনি যখন কোনও ওয়েবসাইটে সর্বজনীনভাবে উপলব্ধ ডেটা পার্স করার চেষ্টা করছেন তখন ওয়েব স্ক্র্যাপিং আইনী। সাধারণভাবে, ব্যক্তিগত ব্যবহার বা অ-বাণিজ্যিক উদ্দেশ্যে ওয়েব স্ক্র্যাপিং আইনী। যাইহোক, কপিরাইট দ্বারা সুরক্ষিত বা গোপনীয় বা ব্যক্তিগত হিসাবে বিবেচিত ডেটা স্ক্র্যাপ করা আইনি সমস্যাগুলির দিকে নিয়ে যেতে পারে।
কিছু ক্ষেত্রে, ওয়েব স্ক্র্যাপিং একটি ওয়েবসাইটের পরিষেবার শর্তাবলী লঙ্ঘন করতে পারে। অনেক ওয়েবসাইট তাদের বিষয়বস্তুর স্বয়ংক্রিয় স্ক্র্যাপিং নিষিদ্ধ করে এমন শর্তাবলী অন্তর্ভুক্ত করে। যদি কোনও ওয়েবসাইটের মালিক আবিষ্কার করেন যে কেউ তাদের বিষয়বস্তু স্ক্র্যাপ করছে, তারা এটি বন্ধ করার জন্য আইনি ব্যবস্থা নিতে পারে।
পাইথন কেন ওয়েব স্ক্র্যাপিংয়ের জন্য ভাল?
পাইথন ওয়েব স্ক্র্যাপিংয়ের জন্য একটি জনপ্রিয় প্রোগ্রামিং ভাষা কারণ এটি বিভিন্ন সুবিধা প্রদান করে:
- পাইথনের একটি সহজ এবং পঠনযোগ্য সিনট্যাক্স রয়েছে এবং এটি নতুনদের শেখার জন্য সহজ।
- পাইথনের ডেভেলপারদের একটি বিশাল সম্প্রদায় রয়েছে যারা ওয়েব স্ক্র্যাপিংয়ের মতো বিভিন্ন কাজের জন্য সরঞ্জাম তৈরি করে।
- পাইথনের অনেকগুলি ওয়েব স্ক্র্যাপিং লাইব্রেরি রয়েছে যেমন সুন্দর স্যুপ এবং স্ক্র্যাপি।
- পাইথন অনেক কাজ করতে পারে যেমন স্ক্র্যাপিং, এক্সেল করতে ওয়েবসাইট ডেটা বের করা হচ্ছে, HTML ফর্মের সাথে ইন্টারঅ্যাকটিং, এবং আরও অনেক কিছু।
- পাইথন স্কেলযোগ্য, এটিকে প্রচুর পরিমাণে ডেটা স্ক্র্যাপ করার জন্য উপযুক্ত করে তোলে।
ওয়েব স্ক্র্যাপিং এর উদাহরণ কি?
ওয়েব স্ক্র্যাপিং হল স্বয়ংক্রিয় স্ক্রিপ্ট বা টুল ব্যবহার করে ওয়েব পেজ থেকে ডেটা বের করা। উদাহরণস্বরূপ, ওয়েব স্ক্র্যাপিং লিড জেনারেশনের জন্য ওয়েবসাইটগুলি থেকে ইমেলগুলি স্ক্র্যাপ করতে ব্যবহৃত হয়। আরেকটি ওয়েব স্ক্র্যাপিং উদাহরণ হল আপনার মূল্যের কাঠামো উন্নত করতে প্রতিযোগী মূল্যের তথ্য বের করা।
ওয়েব স্ক্র্যাপিং কোডিং প্রয়োজন?
ওয়েব স্ক্র্যাপিং অসংগঠিত ওয়েবসাইট ডেটাকে কাঠামোগত বিন্যাসে রূপান্তর করে। ওয়েবসাইটগুলিকে স্ক্র্যাপ করতে কোডিং ব্যবহার করা ছাড়াও, আপনি সম্পূর্ণরূপে নো-কোড ওয়েব স্ক্র্যাপিং সরঞ্জামগুলি ব্যবহার করতে পারেন যার জন্য কোনও কোডিংয়ের প্রয়োজন নেই।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://nanonets.com/blog/web-scraping-with-python-tutorial/
- : হয়
- 1
- 11
- 7
- 77
- a
- প্রাচুর্য
- প্রবেশ
- অ্যাক্সেসড
- কর্ম
- স্টক
- সুবিধাদি
- সব
- অনুমতি
- বিকল্প
- বিশ্লেষণ
- বিশ্লেষণ করা
- এবং
- অন্য
- পৃথক্
- API
- অ্যাপ্লিকেশন
- রয়েছি
- AS
- At
- বৈশিষ্ট্যাবলী
- প্রমাণীকরণ
- স্বয়ংক্রিয় পদ্ধতি প্রয়োগ করা
- অটোমেটেড
- স্বয়ংক্রিয়
- স্বয়ংক্রিয়করণ
- সহজলভ্য
- BE
- সুন্দর
- কারণ
- beginners
- সর্বোত্তম
- মধ্যে
- ব্লগ
- ব্রাউজার
- ব্রাউজার
- by
- CAN
- মামলা
- বেছে নিন
- ক্রৌমিয়াম
- শ্রেণী
- ক্লিক
- মক্কেল
- ঘনিষ্ঠ
- কোড
- কোডিং
- এর COM
- সম্প্রদায়
- তুলনা করা
- প্রতিদ্বন্দ্বী
- সম্পূর্ণরূপে
- জটিল
- উপসংহার
- সংযোগ
- বিবেচিত
- সঙ্গত
- যোগাযোগ
- বিষয়বস্তু
- নিয়ন্ত্রণ
- নিয়ন্ত্রণগুলি
- বিস্কুট
- কপিরাইট
- অনুরূপ
- সৃষ্টি
- উপাত্ত
- তথ্য প্রক্রিয়াজাতকরণ
- ডাটাবেস
- বিলম্ব
- পরিকল্পিত
- বিস্তারিত
- বিকাশ
- ডেভেলপারদের
- ভিন্ন
- বিভিন্ন
- আবিষ্কার
- আলোচনা
- দলিল
- কাগজপত্র
- ডাউনলোড
- পূর্বে
- ব্যবহারে সহজ
- সহজে
- দক্ষতার
- উপাদান
- ইমেল
- ভুল
- থার (eth)
- উদাহরণ
- সীমা অতিক্রম করা
- চমত্কার
- রপ্তানি
- নির্যাস
- তথ্য নিষ্কাশন
- বৈশিষ্ট্য
- ক্ষেত্রসমূহ
- ফাইল
- পূরণ করা
- ফায়ারফক্স
- প্রথম
- অনুসরণ
- জন্য
- ফর্ম
- বিন্যাস
- ফর্ম
- বিনামূল্যে
- থেকে
- অধিকতর
- সাধারণ
- প্রজন্ম
- পাওয়া
- ভাল
- হাতল
- হ্যান্ডলগুলি
- হ্যান্ডলিং
- আছে
- মাথা
- হেডার
- সাহায্য
- এখানে
- উচ্চস্তর
- আশা
- কিভাবে
- কিভাবে
- যাহোক
- এইচটিএমএল
- HTTP
- HTTPS দ্বারা
- প্রচুর
- মানবীয়
- i
- আমদানি
- গুরুত্বপূর্ণ
- উন্নত করা
- in
- অন্তর্ভুক্ত করা
- সুদ্ধ
- তথ্য
- ইনপুট
- ইনস্টল
- ইনস্টল করার
- গর্ভনাটিকা
- আলাপচারিতার
- মিথষ্ক্রিয়া
- স্বার্থ
- স্বজ্ঞাত
- জড়িত
- সমস্যা
- IT
- এর
- JSON
- শুধু একটি
- পরিচিত
- ভাষা
- বড়
- বৃহত্তর
- নেতৃত্ব
- বিশালাকার
- শিখতে
- আইনগত
- আইনানুগ ব্যবস্থা
- আইনি সমস্যা
- লাইব্রেরি
- লাইব্রেরি
- মত
- তালিকাভুক্ত
- অবস্থিত
- দেখুন
- অনেক
- প্রধান
- তৈরি করে
- মেকিং
- হেরফের
- ম্যানুয়ালি
- অনেক
- উল্লিখিত
- মেটা
- পদ্ধতি
- অধিক
- চলচ্চিত্র
- বহু
- নাম
- নাম
- নেভিগেট করুন
- প্রয়োজন
- পরবর্তী
- অবাণিজ্যিক
- লক্ষ্য
- of
- অফার
- on
- ONE
- খোলা
- পছন্দ
- অন্যান্য
- মালিক
- পৃষ্ঠা
- পান্ডাস
- বিশেষ
- সম্পাদন করা
- ব্যক্তিগত
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- জনপ্রিয়
- পোস্ট
- ক্ষমতাশালী
- মূল্য
- ব্যক্তিগত
- প্রক্রিয়া
- প্রক্রিয়াজাতকরণ
- প্রোগ্রামিং
- নিষিদ্ধ করা
- প্রকল্প
- রক্ষিত
- উপলব্ধ
- প্রকাশ্যে
- উদ্দেশ্য
- পাইথন
- নির্ধারণ
- বাস্তব
- প্রকৃত সময়
- রিয়েল-টাইম ডেটা
- নিয়মিত
- প্রাসঙ্গিক
- পুনরাবৃত্তিমূলক
- অনুরোধ
- অনুরোধ
- প্রয়োজন
- প্রয়োজনীয়
- প্রতিক্রিয়া
- ফিরতি
- সঠিক পছন্দ
- শক্তসমর্থ
- সারিটি
- s
- Safari
- মাপযোগ্য
- চাঁচুনি
- স্ক্রিপ্ট
- স্ক্রল
- সেবা
- বিভিন্ন
- সহজ
- সরলতা
- ধীর
- কিছু
- কেউ
- বিঘত
- নির্দিষ্ট
- এসকিউএল
- SSL এর
- শুরু
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- থামুন
- দোকান
- সঞ্চিত
- শক্তিশালী
- গঠন
- কাঠামোবদ্ধ
- জমা
- সফলভাবে
- এমন
- উপযুক্ত
- সমর্থন
- সমর্থন
- বাক্য গঠন
- TAG
- গ্রহণ করা
- কাজ
- TD
- শর্তাবলী
- সেবা পাবার শর্ত
- পরীক্ষামূলক
- যে
- সার্জারির
- তথ্য
- তাদের
- তাহাদিগকে
- এইগুলো
- তৃতীয় পক্ষের
- দ্বারা
- সময়
- সময় অপগিত হয় এমন
- শিরনাম
- শিরোনাম
- থেকে
- আজ
- অত্যধিক
- টুল
- সরঞ্জাম
- শীর্ষ
- রুপান্তর
- প্রবণতা
- অভিভাবকসংবঁধীয়
- বোঝা
- URL টি
- ব্যবহার
- ব্যবহারকারী
- মূল্য
- মানগুলি
- বিভিন্ন
- প্রতিপাদন
- যাচাই
- ভলিউম
- ওয়েব
- ওয়েব অ্যাপ্লিকেশন
- ওয়েব ব্রাউজার
- ওয়েব ব্রাউজার
- ওয়েব স্ক্র্যাপিং
- ওয়েবসাইট
- ওয়েবসাইট
- কি
- যে
- ব্যাপকভাবে
- ইচ্ছা
- সঙ্গে
- মধ্যে
- লেখা
- এক্সএমএল
- বছর
- আপনার
- zephyrnet