সারা বিশ্ব জুড়ে সংস্থাগুলি - লাভ এবং অলাভজনক উভয়ই - উন্নত ব্যবসায়িক কর্মক্ষমতার জন্য ডেটা বিশ্লেষণের সুবিধার দিকে নজর দিচ্ছে৷ একটি থেকে অনুসন্ধান ম্যাককিনসে জরিপ নির্দেশ করে যে ডেটা-চালিত সংস্থাগুলি গ্রাহকদের অর্জনের সম্ভাবনা 23 গুণ বেশি, গ্রাহক ধরে রাখার সম্ভাবনা ছয় গুণ এবং 19 গুণ বেশি লাভজনক [1]। এমআইটি দ্বারা গবেষণা দেখা গেছে যে ডিজিটালভাবে পরিপক্ক সংস্থাগুলি তাদের সমবয়সীদের তুলনায় 26% বেশি লাভজনক [2]। কিন্তু অনেক কোম্পানি, ডেটা-সমৃদ্ধ হওয়া সত্ত্বেও, ব্যবসায়িক চাহিদা, উপলব্ধ ক্ষমতা এবং সংস্থানগুলির মধ্যে বিরোধপূর্ণ অগ্রাধিকারের কারণে ডেটা বিশ্লেষণ বাস্তবায়ন করতে লড়াই করে। গার্টনার দ্বারা গবেষণা পাওয়া গেছে যে 85% এর বেশি ডেটা এবং বিশ্লেষণ প্রকল্প ব্যর্থ হয় [3] এবং ক যৌথ প্রতিবেদন IBM এবং Carnegie Melon থেকে দেখা যায় যে একটি প্রতিষ্ঠানের 90% ডেটা সফলভাবে কোনো কৌশলগত উদ্দেশ্যে ব্যবহার করা হয় না [4]।
এই পটভূমিতে, আমরা একটি ইকোসিস্টেম বা একটি কাঠামো হিসাবে "ডেটা অ্যানালিটিক্স ফ্যাব্রিক (ডিএএফ)" ধারণাটি প্রবর্তন করি যা ডেটা বিশ্লেষণকে কার্যকরভাবে কাজ করতে সক্ষম করে (ক) ব্যবসার প্রয়োজন বা উদ্দেশ্য, (খ) উপলব্ধ ক্ষমতা যেমন মানুষ/দক্ষতা , প্রক্রিয়া, সংস্কৃতি, প্রযুক্তি, অন্তর্দৃষ্টি, সিদ্ধান্ত গ্রহণের দক্ষতা, এবং আরও অনেক কিছু এবং (গ) সংস্থান (অর্থাৎ, ব্যবসা পরিচালনা করার জন্য একটি ব্যবসার প্রয়োজনীয় উপাদান)।
ডেটা অ্যানালিটিক্স ফ্যাব্রিক প্রবর্তনের আমাদের প্রাথমিক লক্ষ্য হল এই মৌলিক প্রশ্নের উত্তর দেওয়া: “কার্যকরভাবে একটি সিদ্ধান্ত-সক্ষম সিস্টেম তৈরি করতে কী প্রয়োজন? ডেটা বিজ্ঞান ব্যবসার কর্মক্ষমতা পরিমাপ এবং উন্নত করার জন্য অ্যালগরিদম? ডেটা অ্যানালিটিক্স ফ্যাব্রিক এবং এর পাঁচটি মূল প্রকাশ নীচে দেখানো এবং আলোচনা করা হয়েছে।
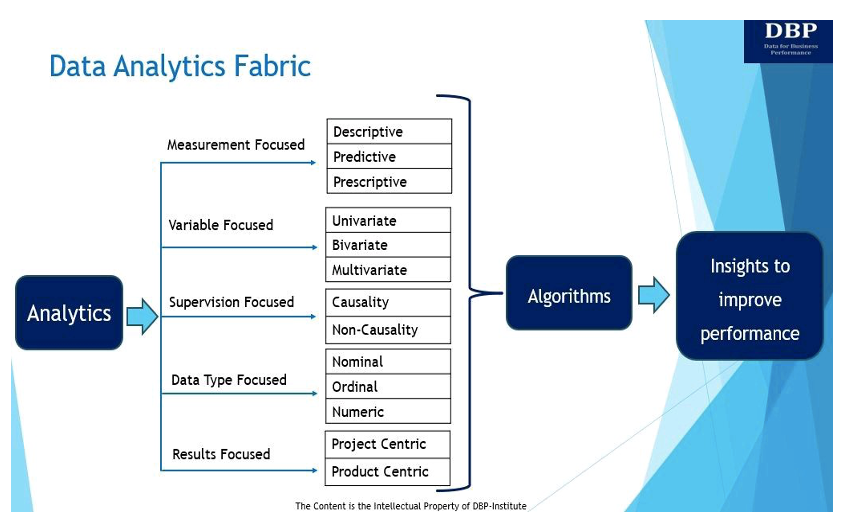
1. পরিমাপ-কেন্দ্রিক
এর মূলে, বিশ্লেষণ হল অন্তর্দৃষ্টি পরিমাপ এবং ব্যবসায়িক কর্মক্ষমতা উন্নত করার জন্য ডেটা ব্যবহার করা। ব্যবসায়িক কর্মক্ষমতা পরিমাপ এবং উন্নত করার জন্য তিনটি প্রধান ধরণের বিশ্লেষণ রয়েছে:
- বর্ণনামূলক বিশ্লেষণ প্রশ্ন করে, "কি হয়েছে?" বর্ণনামূলক বিশ্লেষণগুলি অনুসন্ধানমূলক, সহযোগী, এবং অনুমানমূলক ডেটা বিশ্লেষণ কৌশল ব্যবহার করে নিদর্শন, প্রবণতা এবং সম্পর্ক সনাক্ত করতে ঐতিহাসিক ডেটা বিশ্লেষণ করতে ব্যবহৃত হয়। অনুসন্ধানমূলক ডেটা বিশ্লেষণ কৌশলগুলি ডেটা সেটগুলিকে বিশ্লেষণ এবং সংক্ষিপ্ত করে। সহযোগী বর্ণনামূলক বিশ্লেষণ ভেরিয়েবলের মধ্যে সম্পর্ক ব্যাখ্যা করে। অনুমানমূলক বর্ণনামূলক ডেটা বিশ্লেষণ নমুনা ডেটা সেটের উপর ভিত্তি করে একটি বৃহত্তর জনসংখ্যা সম্পর্কে প্রবণতা অনুমান বা উপসংহার করতে ব্যবহৃত হয়।
- আনুমানিক বিশ্লেষণ প্রশ্নের উত্তরের দিকে তাকায়, "কি হবে?" মূলত, ভবিষ্যদ্বাণীমূলক বিশ্লেষণ হল ভবিষ্যত প্রবণতা এবং ঘটনাগুলির পূর্বাভাস দেওয়ার জন্য ডেটা ব্যবহার করার প্রক্রিয়া। ভবিষ্যদ্বাণীমূলক বিশ্লেষণ ম্যানুয়ালি পরিচালিত হতে পারে (সাধারণত বিশ্লেষক-চালিত ভবিষ্যদ্বাণীমূলক বিশ্লেষণ হিসাবে পরিচিত) বা ব্যবহার করে মেশিন লার্নিং অ্যালগরিদম (ডেটা-চালিত ভবিষ্যদ্বাণীমূলক বিশ্লেষণ হিসাবেও পরিচিত)। যেভাবেই হোক, ঐতিহাসিক তথ্য ভবিষ্যতের ভবিষ্যদ্বাণী করতে ব্যবহৃত হয়।
- নির্দেশমূলক বিশ্লেষণ প্রশ্নের উত্তর দিতে সাহায্য করে, "আমরা কীভাবে এটি ঘটতে পারি?" মূলত, প্রেসক্রিপটিভ অ্যানালিটিক্স অপ্টিমাইজেশান এবং সিমুলেশন কৌশলগুলি ব্যবহার করে এগিয়ে যাওয়ার জন্য সর্বোত্তম পদক্ষেপের সুপারিশ করে। সাধারণত, ভবিষ্যদ্বাণীমূলক বিশ্লেষণ এবং প্রেসক্রিপটিভ বিশ্লেষণ একসাথে যায় কারণ ভবিষ্যদ্বাণীমূলক বিশ্লেষণ সম্ভাব্য ফলাফলগুলি খুঁজে পেতে সহায়তা করে, যখন প্রেসক্রিপটিভ বিশ্লেষণ সেই ফলাফলগুলি দেখে এবং আরও বিকল্প খুঁজে পায়।
2. পরিবর্তনশীল-কেন্দ্রিক
উপলভ্য ভেরিয়েবলের সংখ্যার উপর ভিত্তি করে ডেটাও বিশ্লেষণ করা যেতে পারে। এই বিষয়ে, ভেরিয়েবলের সংখ্যার উপর ভিত্তি করে, ডেটা বিশ্লেষণের কৌশলগুলি একবিভিন্ন, দ্বিভঙ্গিপূর্ণ বা বহুমুখী হতে পারে।
- স্বতন্ত্র বিশ্লেষণ: ইউনিভেরিয়েট অ্যানালাইসিসে কেন্দ্রীয়তা (গড়, মাঝারি, মোড, ইত্যাদি) এবং প্রকরণ (স্ট্যান্ডার্ড ডেভিয়েশন, স্ট্যান্ডার্ড ত্রুটি, প্রকরণ ইত্যাদি) ব্যবহার করে একটি একক ভেরিয়েবলে উপস্থিত প্যাটার্ন বিশ্লেষণ করা জড়িত।
- দ্বিমুখী বিশ্লেষণ: দুটি ভেরিয়েবল রয়েছে যেখানে বিশ্লেষণটি কারণ এবং দুটি ভেরিয়েবলের মধ্যে সম্পর্ক সম্পর্কিত। এই দুটি ভেরিয়েবল একে অপরের উপর নির্ভরশীল বা স্বাধীন হতে পারে। পারস্পরিক সম্পর্ক কৌশলটি সবচেয়ে বেশি ব্যবহৃত দ্বিভারী বিশ্লেষণ কৌশল।
- বহুচলকীয় বিশ্লেষণ: এই কৌশলটি দুটির বেশি ভেরিয়েবল বিশ্লেষণের জন্য ব্যবহৃত হয়। মাল্টিভেরিয়েট সেটিংয়ে, আমরা সাধারণত ভবিষ্যদ্বাণীমূলক বিশ্লেষণের ক্ষেত্রে কাজ করি এবং বেশিরভাগ সুপরিচিত মেশিন লার্নিং (এমএল) অ্যালগরিদম যেমন লিনিয়ার রিগ্রেশন, লজিস্টিক রিগ্রেশন, রিগ্রেশন ট্রি, সাপোর্ট ভেক্টর মেশিন এবং নিউরাল নেটওয়ার্ক সাধারণত মাল্টিভেরিয়েটে প্রয়োগ করা হয়। বিন্যাস.
3. তত্ত্বাবধান-কেন্দ্রিক
তৃতীয় প্রকারের ডেটা অ্যানালিটিক্স ফ্যাব্রিক ইনপুট ডেটা বা স্বাধীন পরিবর্তনশীল ডেটাকে প্রশিক্ষণের সাথে সম্পর্কিত যা একটি নির্দিষ্ট আউটপুটের জন্য লেবেল করা হয়েছে (যেমন, নির্ভরশীল পরিবর্তনশীল)। মূলত, স্বাধীন পরিবর্তনশীল হল একটি পরীক্ষাকারী নিয়ন্ত্রণ করে। নির্ভরশীল ভেরিয়েবল হল সেই পরিবর্তনশীল যা স্বাধীন চলকের প্রতিক্রিয়ায় পরিবর্তিত হয়। তত্ত্বাবধান-কেন্দ্রিক DAF দুই ধরনের হতে পারে।
- কার্যকারণ: লেবেলযুক্ত ডেটা, স্বয়ংক্রিয়ভাবে বা ম্যানুয়ালি তৈরি হোক না কেন, তত্ত্বাবধানে শেখার জন্য অপরিহার্য। লেবেলযুক্ত ডেটা একজনকে একটি নির্ভরশীল ভেরিয়েবলকে স্পষ্টভাবে সংজ্ঞায়িত করতে দেয় এবং তারপরে এটি একটি এআই/এমএল টুল তৈরি করা ভবিষ্যদ্বাণীমূলক বিশ্লেষণ অ্যালগরিদমের বিষয় যা লেবেল (নির্ভরশীল পরিবর্তনশীল) এবং স্বাধীন ভেরিয়েবলের সেটের মধ্যে একটি সম্পর্ক তৈরি করবে। একটি নির্ভরশীল ভেরিয়েবলের ধারণা এবং স্বাধীন ভেরিয়েবলের একটি সেটের মধ্যে আমাদের একটি স্বতন্ত্র সীমাবদ্ধতা রয়েছে, আমরা সম্পর্কটিকে সর্বোত্তমভাবে ব্যাখ্যা করার জন্য "কারণ-কারণ" শব্দটি প্রবর্তন করার অনুমতি দিই।
- অকারণঃ যখন আমরা আমাদের মাত্রা হিসাবে "তত্ত্বাবধান-কেন্দ্রিক" নির্দেশ করি, তখন আমরা "তত্ত্বাবধানের অনুপস্থিতি"ও বোঝায় এবং এটি অ-কারণমূলক মডেলগুলিকে আলোচনায় নিয়ে আসে। অ-কারণমূলক মডেলগুলি উল্লেখ করার যোগ্য কারণ তাদের লেবেলযুক্ত ডেটার প্রয়োজন হয় না। এখানে মৌলিক কৌশল হল ক্লাস্টারিং, এবং সবচেয়ে জনপ্রিয় পদ্ধতি হল k-Means এবং Hierarchical Clustering।
4. ডেটা টাইপ-ফোকাসড
ডেটা অ্যানালিটিক্স ফ্যাব্রিকের এই মাত্রা বা প্রকাশটি তিনটি ভিন্ন ধরণের ডেটা ভেরিয়েবলের উপর ফোকাস করে যা স্বাধীন এবং নির্ভরশীল উভয় ভেরিয়েবলের সাথে সম্পর্কিত যেগুলি অন্তর্দৃষ্টি অর্জনের জন্য ডেটা বিশ্লেষণ কৌশলগুলিতে ব্যবহৃত হয়।
- নামমাত্র তথ্য ডেটা লেবেল বা শ্রেণীকরণের জন্য ব্যবহৃত হয়। এটি একটি সংখ্যাসূচক মান জড়িত করে না এবং তাই নামমাত্র ডেটা দিয়ে কোন পরিসংখ্যানগত গণনা সম্ভব নয়। নামমাত্র ডেটার উদাহরণ হল লিঙ্গ, পণ্যের বিবরণ, গ্রাহকের ঠিকানা এবং এর মতো।
- সাধারণ বা র্যাঙ্ক করা ডেটা মানগুলির ক্রম, তবে প্রতিটির মধ্যে পার্থক্যগুলি সত্যিই জানা যায় না। এখানে সাধারণ উদাহরণ হল বাজার মূলধন, বিক্রেতার অর্থপ্রদানের শর্তাবলী, গ্রাহক সন্তুষ্টি স্কোর, ডেলিভারি অগ্রাধিকার ইত্যাদির উপর ভিত্তি করে কোম্পানিগুলিকে র্যাঙ্কিং করা।
- সংখ্যাসূচক তথ্য কোনো ভূমিকার প্রয়োজন নেই এবং মান সংখ্যাসূচক। এই ভেরিয়েবলগুলি হল সবচেয়ে মৌলিক ডেটা প্রকার যা সমস্ত ধরণের অ্যালগরিদম মডেল করতে ব্যবহার করা যেতে পারে।
5. ফলাফল-কেন্দ্রিক
এই ধরনের ডেটা অ্যানালিটিক্স ফ্যাব্রিক বিশ্লেষণ থেকে প্রাপ্ত অন্তর্দৃষ্টি থেকে ব্যবসায়িক মূল্য কীভাবে সরবরাহ করা যেতে পারে তা দেখে। ব্যবসায়িক মূল্য বিশ্লেষণ দ্বারা চালিত হতে পারে এমন দুটি উপায় রয়েছে এবং সেগুলি পণ্য বা প্রকল্পের মাধ্যমে। যদিও পণ্যগুলিকে ব্যবহারকারীর অভিজ্ঞতা এবং সফ্টওয়্যার প্রকৌশলের আশেপাশে অতিরিক্ত প্রভাবগুলি মোকাবেলা করতে হতে পারে, মডেল তৈরির জন্য যে মডেলিং অনুশীলন করা হয়েছে তা প্রকল্প এবং পণ্য উভয় ক্ষেত্রেই একই রকম হবে।
- A ডেটা বিশ্লেষণ পণ্য ব্যবসার দীর্ঘমেয়াদী চাহিদা পূরণের জন্য একটি পুনঃব্যবহারযোগ্য ডেটা সম্পদ। এটি প্রাসঙ্গিক ডেটা উত্স থেকে ডেটা সংগ্রহ করে, ডেটার গুণমান নিশ্চিত করে, এটি প্রক্রিয়া করে এবং যাদের এটি প্রয়োজন তাদের কাছে এটি অ্যাক্সেসযোগ্য করে তোলে। পণ্যগুলি সাধারণত ব্যক্তিদের জন্য ডিজাইন করা হয় এবং এতে একাধিক জীবনচক্রের পর্যায় বা পুনরাবৃত্তি থাকে যেখানে পণ্যের মূল্য উপলব্ধি করা হয়।
- A তথ্য বিশ্লেষণ প্রকল্প একটি নির্দিষ্ট বা অনন্য ব্যবসার প্রয়োজনের জন্য ডিজাইন করা হয়েছে এবং একটি সংজ্ঞায়িত বা সংকীর্ণ ব্যবহারকারীর ভিত্তি বা উদ্দেশ্য রয়েছে। মূলত, একটি প্রকল্প হল একটি অস্থায়ী প্রচেষ্টা যা বাজেটের মধ্যে এবং সময়মতো একটি সংজ্ঞায়িত সুযোগের সমাধান প্রদানের উদ্দেশ্যে করা হয়।
আগামী বছরগুলিতে বিশ্বের অর্থনীতি নাটকীয়ভাবে রূপান্তরিত হবে কারণ সংস্থাগুলি ক্রমবর্ধমানভাবে তথ্য এবং বিশ্লেষণগুলিকে অন্তর্দৃষ্টি অর্জন করতে এবং ব্যবসায়িক কর্মক্ষমতা পরিমাপ এবং উন্নত করার সিদ্ধান্ত নিতে ব্যবহার করবে৷ ম্যাকিনজি দেখা গেছে যে অন্তর্দৃষ্টি-চালিত সংস্থাগুলি EBITDA (সুদ, কর, অবমূল্যায়ন এবং পরিশোধের আগে আয়) 25% পর্যন্ত বৃদ্ধি করে [5] রিপোর্ট করে। যাইহোক, অনেক সংস্থা ব্যবসায়িক ফলাফলের উন্নতির জন্য ডেটা এবং বিশ্লেষণগুলি ব্যবহার করতে সফল হয় না। কিন্তু ডেটা অ্যানালিটিক্স ডেলিভারির জন্য কোনো একটি আদর্শ উপায় বা পদ্ধতি নেই। ডেটা অ্যানালিটিক্স সমাধানের স্থাপনা বা বাস্তবায়ন ব্যবসায়িক উদ্দেশ্য, ক্ষমতা এবং সম্পদের উপর নির্ভর করে। এখানে আলোচনা করা DAF এবং এর পাঁচটি প্রকাশগুলি ব্যবসায়িক চাহিদা, উপলব্ধ ক্ষমতা এবং সংস্থানগুলির উপর ভিত্তি করে কার্যকরভাবে স্থাপন করা বিশ্লেষণকে সক্ষম করতে পারে।
তথ্যসূত্র
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance
- ide.mit.edu/insights/digitally-mature-firms-are-26-more-profitable-than-their-peers/
- gartner.com/en/newsroom/press-releases/2018-02-13-gartner-says-nearly-half-of-cios-are-planning-to-deploy-artificial-intelligence
- forbes.com/sites/forbestechcouncil/2023/04/04/three-key-misconceptions-of-data-quality/?sh=58570fc66f98
- Southekal, প্রশান্ত, "বিশ্লেষণের সেরা অনুশীলন", টেকনিক্স, 2020
- mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/insights-to-impact-creating-and-sustaining-data-driven-commercial-growth
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। মোটরগাড়ি / ইভি, কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- চার্টপ্রাইম। ChartPrime এর সাথে আপনার ট্রেডিং গেমটি উন্নত করুন। এখানে প্রবেশ করুন.
- ব্লকঅফসেট। পরিবেশগত অফসেট মালিকানার আধুনিকীকরণ। এখানে প্রবেশ করুন.
- উত্স: https://www.dataversity.net/introducing-the-data-analytics-fabric-concept/
- : আছে
- : হয়
- :না
- $ ইউপি
- 1
- 19
- 23
- a
- সম্পর্কে
- প্রবেশযোগ্য
- অর্জন
- কর্ম
- অতিরিক্ত
- ঠিকানা
- এআই / এমএল
- অ্যালগরিদম
- আলগোরিদিম
- সব
- অনুমতি
- অনুমতি
- এছাড়াও
- ঘাত-শোষণ
- an
- বিশ্লেষণ
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ করা
- বিশ্লেষণ
- বিশ্লেষণ
- এবং
- উত্তর
- কোন
- যে কেউ
- ফলিত
- অভিগমন
- রয়েছি
- রঙ্গভূমি
- কাছাকাছি
- AS
- সম্পদ
- At
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- b
- ব্যাকড্রপ
- ভিত্তি
- ভিত্তি
- মৌলিক
- মূলত
- BE
- কারণ
- হয়েছে
- আগে
- হচ্ছে
- নিচে
- সর্বোত্তম
- মধ্যে
- উভয়
- আনে
- বাজেট
- নির্মাণ করা
- ব্যবসায়
- ব্যবসা দক্ষতা
- কিন্তু
- by
- CAN
- ক্ষমতা
- নিজ সুবিধার্থে প্রয়োগ
- শ্রেণীকরণ
- কারণ
- কেন্দ্রীয়তা
- পরিবর্তন
- পরিষ্কারভাবে
- থলোথলো
- সংগ্রহ
- এর COM
- আসছে
- সাধারণ
- সাধারণভাবে
- কোম্পানি
- উপাদান
- ধারণা
- শেষ করা
- পরিচালিত
- দ্বন্দ্বমূলক
- নিয়ন্ত্রণগুলি
- মূল
- অনুবন্ধ
- পারা
- পথ
- সংস্কৃতি
- ক্রেতা
- গ্রাহক সন্তুষ্টি
- গ্রাহকদের
- উপাত্ত
- তথ্য বিশ্লেষণ
- ডেটা বিশ্লেষণ
- উপাত্ত গুণমান
- তথ্য সেট
- ডেটা সেট
- তথ্য চালিত
- ডেটাভার্সিটি
- প্রতিষ্ঠান
- সিদ্ধান্ত মেকিং
- সিদ্ধান্ত
- নির্ধারণ করা
- সংজ্ঞায়িত
- প্রদান করা
- নিষ্কৃত
- বিলি
- নির্ভরশীল
- নির্ভর করে
- মোতায়েন
- বিস্তৃতি
- অবচয়
- উদ্ভূত
- বিবরণ
- প্রাপ্য
- পরিকল্পিত
- সত্ত্বেও
- চ্যুতি
- পার্থক্য
- বিভিন্ন
- ডিজিটালরূপে
- মাত্রা
- আলোচনা
- আলোচনা
- স্বতন্ত্র
- do
- না
- সম্পন্ন
- নাটকীয়ভাবে
- চালিত
- কারণে
- e
- প্রতি
- উপার্জন
- EBITDA
- অর্থনীতি
- বাস্তু
- কার্যকরীভাবে
- পারেন
- সক্ষম করা
- সম্ভব
- প্রচেষ্টা
- প্রকৌশল
- নিশ্চিত
- ভুল
- অপরিহার্য
- ঘটনাবলী
- উদাহরণ
- ব্যায়াম
- অভিজ্ঞতা
- ব্যাখ্যা করা
- ব্যাখ্যা
- অনুসন্ধানের ডেটা বিশ্লেষণ
- ফ্যাব্রিক
- সত্য
- ব্যর্থ
- আবিষ্কার
- তথ্যও
- খুঁজে বের করে
- সংস্থাগুলো
- পাঁচ
- গুরুত্ত্ব
- জন্য
- ফোর্বস
- পূর্বাভাস
- অগ্রবর্তী
- পাওয়া
- থেকে
- ক্রিয়া
- মৌলিক
- ভবিষ্যৎ
- গার্টনার
- লিঙ্গ
- উত্পন্ন
- Go
- লক্ষ্য
- ঘটা
- ঘটেছিলো
- আছে
- সাহায্য
- অত: পর
- এখানে
- ঐতিহাসিক
- যাহোক
- HTTPS দ্বারা
- i
- আইবিএম
- সনাক্ত করা
- বাস্তবায়ন
- বাস্তবায়ন
- উন্নত করা
- উন্নত
- উন্নতি
- in
- বৃদ্ধি
- ক্রমবর্ধমানভাবে
- স্বাধীন
- ইঙ্গিত
- ইনপুট
- অর্ন্তদৃষ্টি
- অভিপ্রেত
- স্বার্থ
- প্রবর্তন করা
- উপস্থাপক
- ভূমিকা
- জড়িত করা
- জড়িত
- IT
- পুনরাবৃত্তি
- এর
- চাবি
- পরিচিত
- লেবেল
- লেবেল
- বৃহত্তর
- শিক্ষা
- উপজীব্য
- জীবনচক্র
- মত
- সম্ভবত
- দীর্ঘ মেয়াদী
- খুঁজছি
- সৌন্দর্য
- মেশিন
- মেশিন লার্নিং
- মেশিন
- প্রধান
- করা
- তৈরি করে
- ম্যানুয়ালি
- অনেক
- বাজার
- বাজার মূলধন
- ব্যাপার
- পরিণত
- সর্বোচ্চ প্রস্থ
- মে..
- ম্যাকিনজি
- গড়
- মাপ
- পরিমাপ
- উল্লেখ
- পদ্ধতি
- এমআইটি
- ML
- মোড
- মডেল
- মূর্তিনির্মাণ
- মডেল
- অধিক
- সেতু
- সবচেয়ে জনপ্রিয়
- চলন্ত
- বহু
- প্রয়োজন
- চাহিদা
- নেটওয়ার্ক
- নিউরাল
- নিউরাল নেটওয়ার্ক
- না
- না।
- আয়হীন
- ধারণা
- সংখ্যা
- উদ্দেশ্য
- of
- on
- ONE
- পরিচালনা করা
- অপ্টিমাইজেশান
- অপশন সমূহ
- or
- ক্রম
- সংগঠন
- সংগঠন
- অন্যান্য
- আমাদের
- নিজেদেরকে
- ফলাফল
- আউটপুট
- শেষ
- বিশেষ
- প্যাটার্ন
- নিদর্শন
- প্রদান
- কর্মক্ষমতা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- জনপ্রিয়
- জনসংখ্যা
- সম্ভব
- সম্ভাব্য
- ভবিষ্যতবাণী
- ভবিষ্যদ্বাণীপূর্ণ
- ভবিষ্যদ্বাণীমূলক বিশ্লেষণ
- আনুমানিক বিশ্লেষণ
- বর্তমান
- প্রাথমিক
- অগ্রাধিকার
- প্রক্রিয়া
- প্রসেস
- পণ্য
- পণ্য
- মুনাফা
- লাভজনক
- প্রকল্প
- প্রকল্প
- উদ্দেশ্য
- গুণ
- প্রশ্ন
- প্রভাব
- স্থান
- রাঙ্কিং
- প্রতীত
- সত্যিই
- বিশেষ পরামর্শ দেওয়া হচ্ছে
- চেহারা
- প্রত্যাগতি
- সংশ্লিষ্ট
- সম্পর্ক
- সম্পর্ক
- প্রাসঙ্গিক
- রিপোর্ট
- প্রয়োজন
- প্রয়োজনীয়
- Resources
- প্রতিক্রিয়া
- রাখা
- পুনর্ব্যবহারযোগ্য
- সন্তোষ
- সুযোগ
- স্কোর
- পরিবেশন করা
- সেট
- সেট
- বিন্যাস
- প্রদর্শিত
- শো
- অনুরূপ
- ব্যাজ
- একক
- ছয়
- So
- সফটওয়্যার
- সফ্টওয়্যার প্রকৌশল
- সমাধান
- সলিউশন
- উৎস
- সোর্স
- ইন্টার্নশিপ
- মান
- পরিসংখ্যানসংক্রান্ত
- কৌশলগত
- গঠন
- সংগ্রাম
- সফল
- সফলভাবে
- এমন
- সংক্ষিপ্ত করা
- তদারকি শেখা
- ভুল
- সমর্থন
- পদ্ধতি
- করের
- প্রযুক্তি
- প্রযুক্তি
- অস্থায়ী
- মেয়াদ
- শর্তাবলী
- চেয়ে
- যে
- সার্জারির
- বিশ্ব
- তাদের
- তারপর
- সেখানে।
- এইগুলো
- তারা
- তৃতীয়
- এই
- সেগুলো
- তিন
- দ্বারা
- সময়
- বার
- থেকে
- একসঙ্গে
- টুল
- প্রশিক্ষণ
- রুপান্তর
- গাছ
- প্রবণতা
- দুই
- আদর্শ
- ধরনের
- সাধারণত
- অনন্য
- ব্যবহার
- ব্যবহৃত
- ব্যবহারকারী
- ব্যবহারকারীর অভিজ্ঞতা
- ব্যবহার
- মূল্য
- মানগুলি
- পরিবর্তনশীল
- বিক্রেতা
- উপায়..
- উপায়
- we
- সুপরিচিত
- কখন
- কিনা
- যে
- যখন
- হু
- ইচ্ছা
- সঙ্গে
- মধ্যে
- বিশ্ব
- বিশ্বের
- would
- বছর
- zephyrnet