পাইথন ব্যবহার করে ডেটা ম্যানিপুলেশন এবং বিশ্লেষণের জন্য পান্ডাস একটি শক্তিশালী এবং ব্যাপকভাবে ব্যবহৃত ওপেন-সোর্স লাইব্রেরি। এর মূল বৈশিষ্ট্যগুলির মধ্যে একটি হল গ্রুপবাই ফাংশন ব্যবহার করে ডেটা ফ্রেমকে এক বা একাধিক কলামের উপর ভিত্তি করে গোষ্ঠীতে বিভক্ত করে এবং তারপর তাদের প্রতিটিতে বিভিন্ন একত্রীকরণ ফাংশন প্রয়োগ করার ক্ষমতা।

চিত্র থেকে Unsplash
সার্জারির groupby ফাংশনটি অবিশ্বাস্যভাবে শক্তিশালী, কারণ এটি আপনাকে দ্রুত বড় ডেটাসেটগুলির সংক্ষিপ্তসার এবং বিশ্লেষণ করতে দেয়। উদাহরণস্বরূপ, আপনি একটি নির্দিষ্ট কলাম দ্বারা একটি ডেটাসেটকে গোষ্ঠীবদ্ধ করতে পারেন এবং প্রতিটি গোষ্ঠীর জন্য অবশিষ্ট কলামগুলির গড়, যোগফল বা গণনা গণনা করতে পারেন। আপনার ডেটার আরও দানাদার বোঝার জন্য আপনি একাধিক কলাম দ্বারা গোষ্ঠীবদ্ধ করতে পারেন। উপরন্তু, এটি আপনাকে কাস্টম একত্রীকরণ ফাংশন প্রয়োগ করতে দেয়, যা জটিল ডেটা বিশ্লেষণের কাজগুলির জন্য একটি খুব শক্তিশালী হাতিয়ার হতে পারে।
এই টিউটোরিয়ালে, আপনি শিখবেন কিভাবে পান্ডাসে গ্রুপবাই ফাংশন ব্যবহার করে বিভিন্ন ধরনের ডেটা গ্রুপ করতে হয় এবং বিভিন্ন অ্যাগ্রিগেশন অপারেশন করতে হয়। এই টিউটোরিয়ালের শেষে, আপনি বিভিন্ন উপায়ে ডেটা বিশ্লেষণ এবং সংক্ষিপ্ত করতে এই ফাংশনটি ব্যবহার করতে সক্ষম হবেন।
ভালভাবে অনুশীলন করার সময় ধারণাগুলি অভ্যন্তরীণ হয় এবং এটিই আমরা পরবর্তীতে করতে যাচ্ছি অর্থাৎ পান্ডাস গ্রুপবাই ফাংশনের সাথে হ্যান্ডস-অন করতে যাচ্ছি। এটি একটি ব্যবহার করার সুপারিশ করা হয় Jupyter নোটবুক এই টিউটোরিয়ালের জন্য আপনি প্রতিটি ধাপে আউটপুট দেখতে সক্ষম।
নমুনা ডেটা তৈরি করুন
নিম্নলিখিত লাইব্রেরি আমদানি করুন:
- পান্ডা: একটি ডেটাফ্রেম তৈরি করতে এবং এর দ্বারা গ্রুপ প্রয়োগ করতে
- এলোমেলো - এলোমেলো ডেটা জেনারেট করতে
- প্রিন্ট - অভিধান প্রিন্ট করতে
import pandas as pd
import random
import pprint
এর পরে, আমরা একটি খালি ডেটাফ্রেম শুরু করব এবং নীচে দেখানো হিসাবে প্রতিটি কলামের জন্য মান পূরণ করব:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
বোনাস টিপ - একই কাজ করার একটি পরিষ্কার উপায় হল সমস্ত ভেরিয়েবল এবং মানগুলির একটি অভিধান তৈরি করা এবং পরে এটিকে একটি ডেটাফ্রেমে রূপান্তর করা৷
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
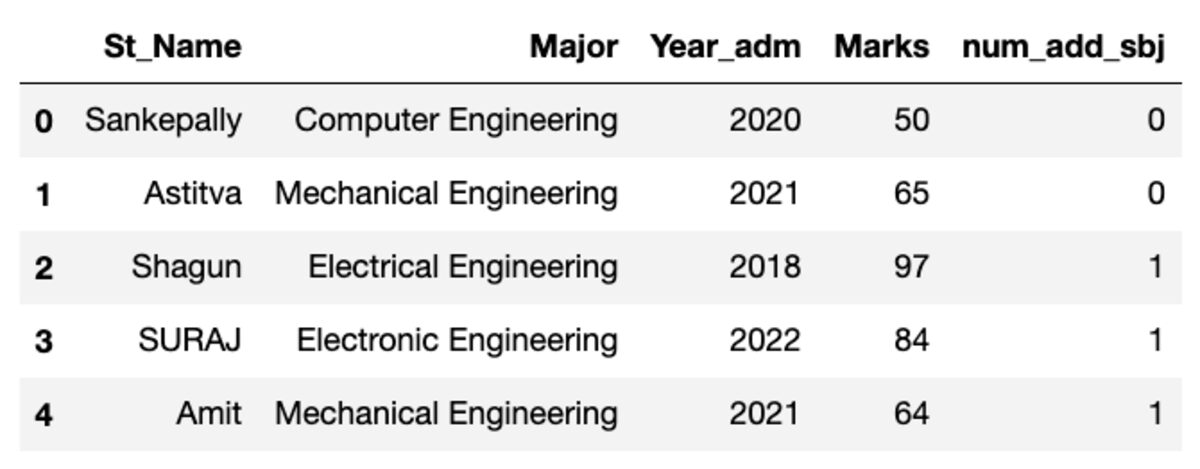
ডাটাফ্রেম দেখতে নিচের মত দেখাচ্ছে। এই কোডটি চালানোর সময়, কিছু মান মিলবে না কারণ আমরা একটি এলোমেলো নমুনা ব্যবহার করছি।
গ্রুপ তৈরি করা
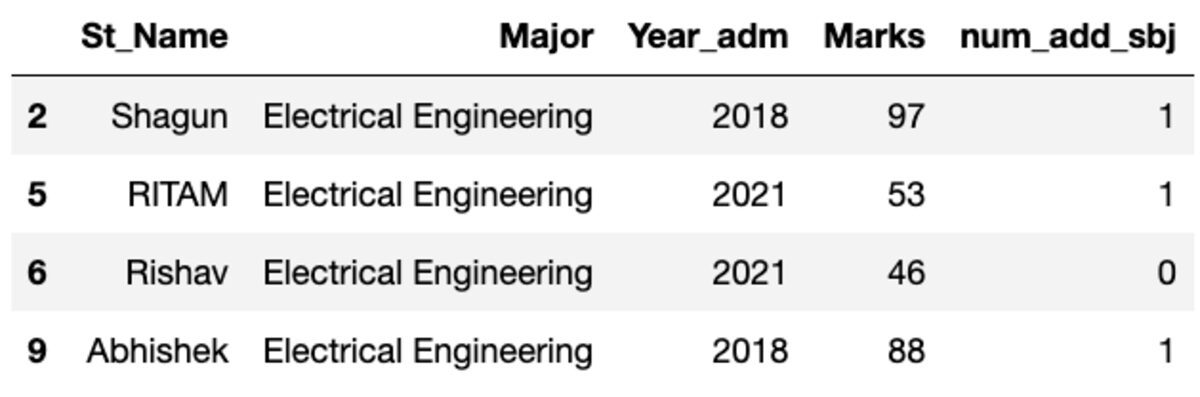
আসুন "মেজর" বিষয় অনুসারে ডেটা গ্রুপ করি এবং কতগুলি রেকর্ড এই গ্রুপে পড়ে তা দেখতে গ্রুপ ফিল্টার প্রয়োগ করি।
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
সুতরাং, চার ছাত্র ইলেকট্রিক্যাল ইঞ্জিনিয়ারিং মেজরভুক্ত।
আপনি একাধিক কলাম দ্বারা গোষ্ঠীবদ্ধ করতে পারেন (এই ক্ষেত্রে প্রধান এবং num_add_sbj)।
groups = df.groupby(['Major', 'num_add_sbj'])
মনে রাখবেন যে সমস্ত সমষ্টিগত ফাংশন যা একটি কলাম সহ গোষ্ঠীগুলিতে প্রয়োগ করা যেতে পারে একাধিক কলাম সহ গোষ্ঠীগুলিতে প্রয়োগ করা যেতে পারে। টিউটোরিয়ালের বাকি অংশের জন্য, আসুন উদাহরণ হিসাবে একটি একক কলাম ব্যবহার করে বিভিন্ন ধরণের সমষ্টির উপর ফোকাস করি।
আসুন "মেজর" কলামে গ্রুপবাই ব্যবহার করে গ্রুপ তৈরি করি।
groups = df.groupby('Major')সরাসরি ফাংশন প্রয়োগ করা
ধরা যাক আপনি প্রতিটি মেজরে গড় নম্বর পেতে চান। আপনি কি করতে চান?
- মার্কস কলাম নির্বাচন করুন
- গড় ফাংশন প্রয়োগ করুন
- দুই দশমিক স্থানে রাউন্ড অফ মার্ক করতে রাউন্ড ফাংশন প্রয়োগ করুন (ঐচ্ছিক)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
থোক
একই ফলাফল অর্জনের আরেকটি উপায় হল নীচে দেখানো হিসাবে একটি সমষ্টিগত ফাংশন ব্যবহার করে:
groups['Marks'].aggregate('mean').round(2)
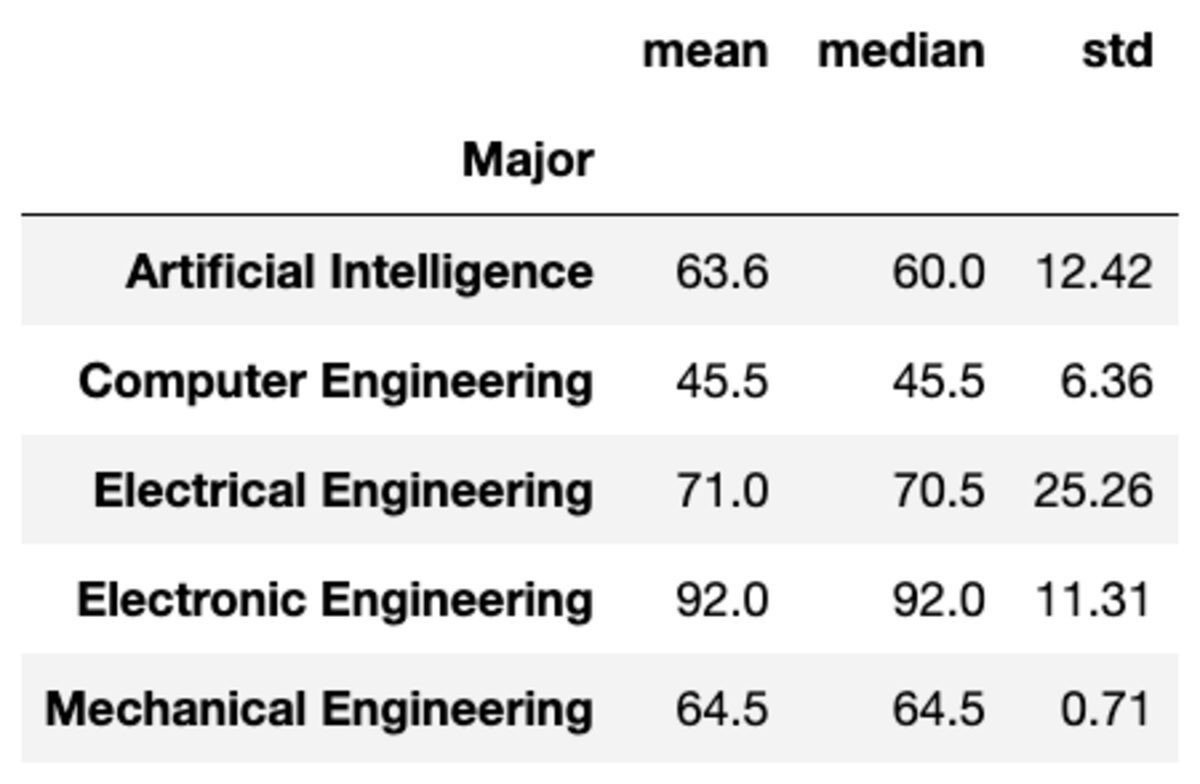
আপনি স্ট্রিংগুলির একটি তালিকা হিসাবে ফাংশনগুলি পাস করে গ্রুপগুলিতে একাধিক সমষ্টি প্রয়োগ করতে পারেন।
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
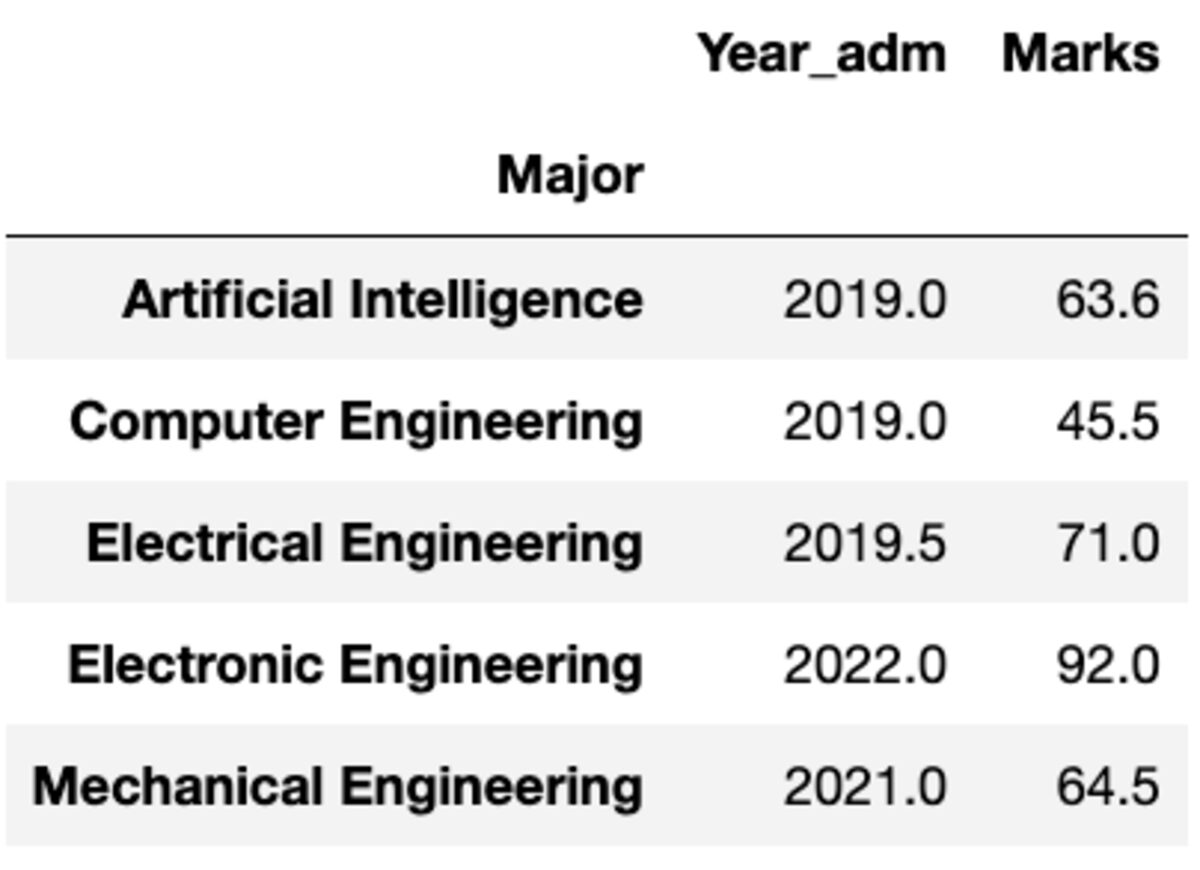
কিন্তু আপনি যদি একটি ভিন্ন কলামে একটি ভিন্ন ফাংশন প্রয়োগ করতে চান তাহলে কি হবে। চিন্তা করবেন না। আপনি এটি {কলাম: ফাংশন} জোড়া পাস করেও করতে পারেন।
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
বদলে দেয়
আপনি খুব ভালভাবে একটি নির্দিষ্ট কলামে কাস্টম রূপান্তর করতে হবে যা গ্রুপবাই() ব্যবহার করে সহজেই অর্জন করা যেতে পারে। sklearn এর প্রিপ্রসেসিং মডিউলে উপলব্ধ একটি স্ট্যান্ডার্ড স্কেলারের অনুরূপ একটি স্ট্যান্ডার্ড স্কেলার সংজ্ঞায়িত করা যাক। আপনি ট্রান্সফর্ম পদ্ধতিতে কল করে এবং কাস্টম ফাংশন পাস করে সমস্ত কলাম রূপান্তর করতে পারেন।
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
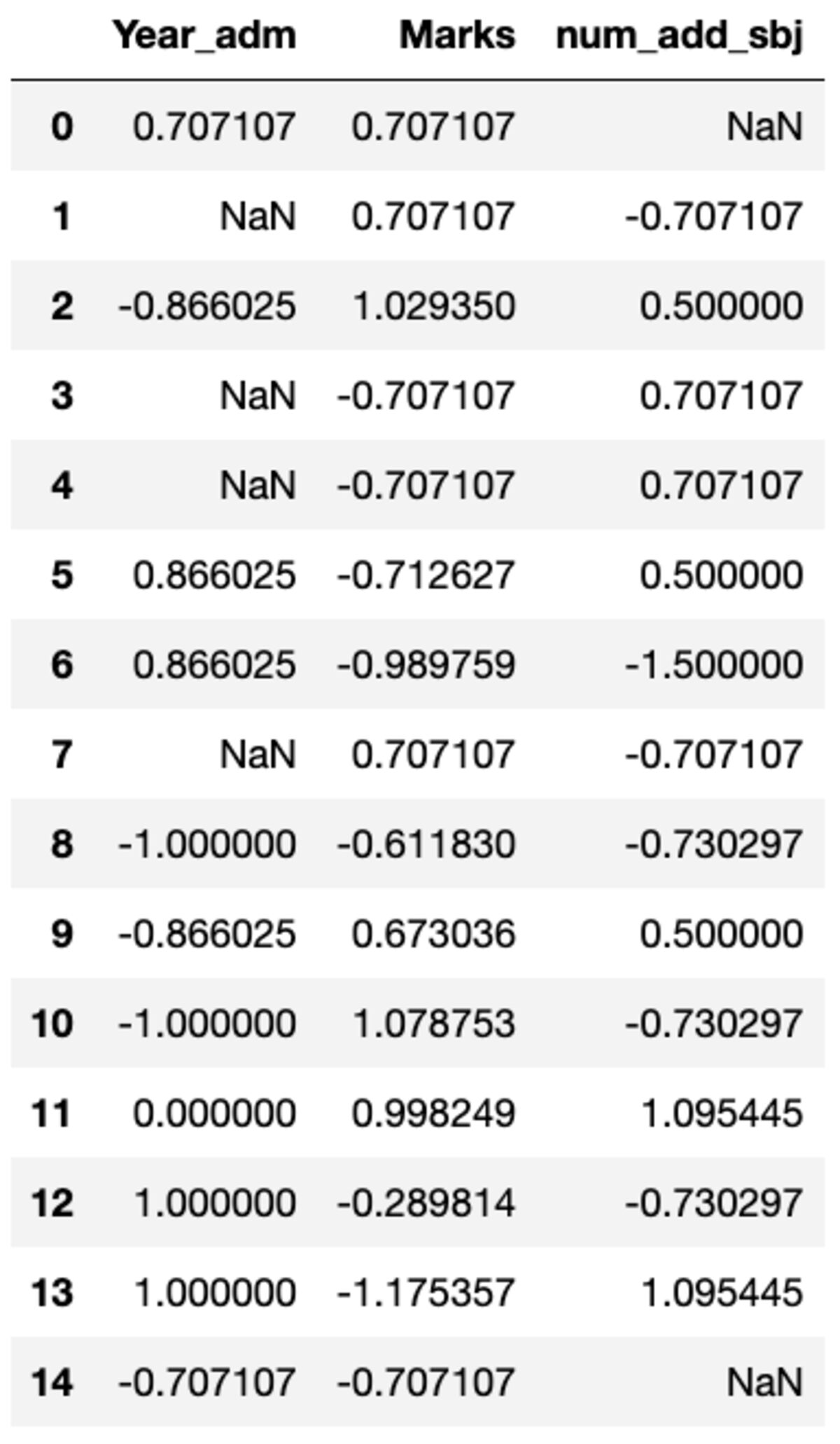
মনে রাখবেন যে "NaN" শূন্য স্ট্যান্ডার্ড বিচ্যুতি সহ গোষ্ঠীগুলিকে প্রতিনিধিত্ব করে৷
ফিল্টার
আপনি হয়ত পরীক্ষা করতে চাইতে পারেন কোন "মেজর" কম পারফরম্যান্স করছে অর্থাৎ যেখানে গড় শিক্ষার্থীর "মার্কস" 60 এর কম। এটির ভিতরে একটি ফাংশন সহ গ্রুপগুলিতে একটি ফিল্টার পদ্ধতি প্রয়োগ করতে হবে। নিচের কোডটি a ব্যবহার করে ল্যাম্বডা ফাংশন ফিল্টার করা ফলাফল অর্জন করতে।
groups.filter(lambda x: x['Marks'].mean() 60)

প্রথম
এটি আপনাকে সূচক অনুসারে সাজানো প্রথম উদাহরণ দেয়।
groups.first()
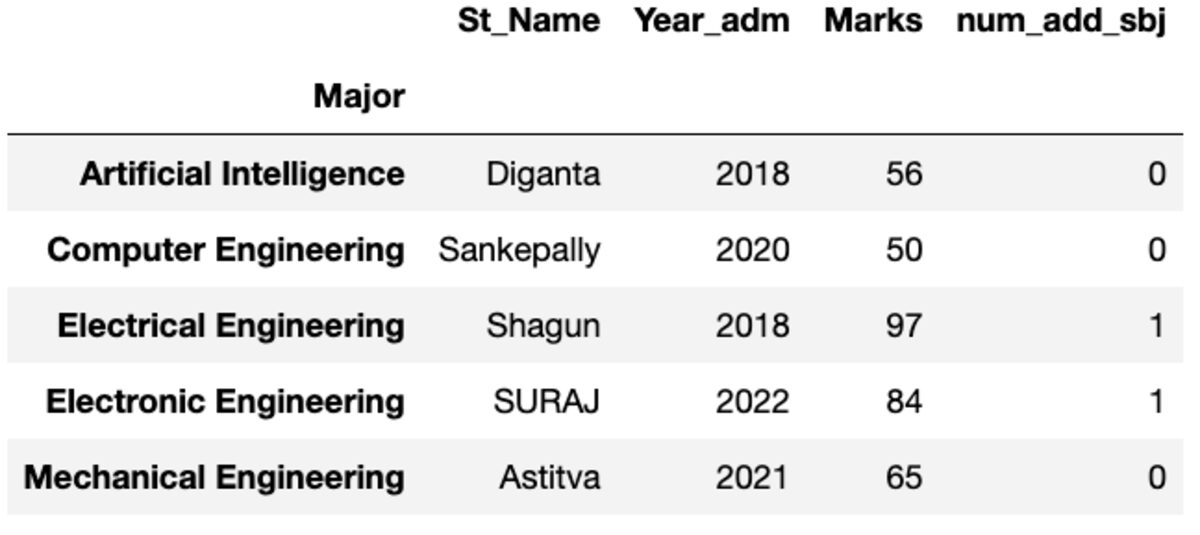
বর্ণনা করা
"বর্ণনা" পদ্ধতিটি প্রদত্ত কলামগুলির জন্য গণনা, গড়, std, সর্বনিম্ন, সর্বোচ্চ ইত্যাদির মতো মৌলিক পরিসংখ্যান প্রদান করে।
groups['Marks'].describe()
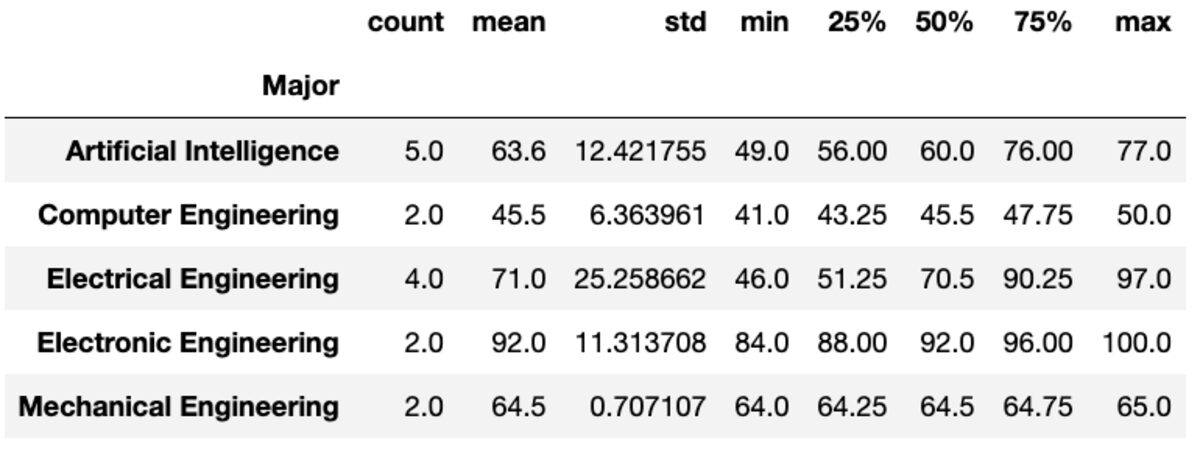
আয়তন
আকার, নাম অনুসারে, রেকর্ডের সংখ্যার পরিপ্রেক্ষিতে প্রতিটি গ্রুপের আকার প্রদান করে।
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64গণনা এবং Nunique
"গণনা" সমস্ত মান প্রদান করে যেখানে "নুনিক" শুধুমাত্র সেই গ্রুপের অনন্য মান প্রদান করে।
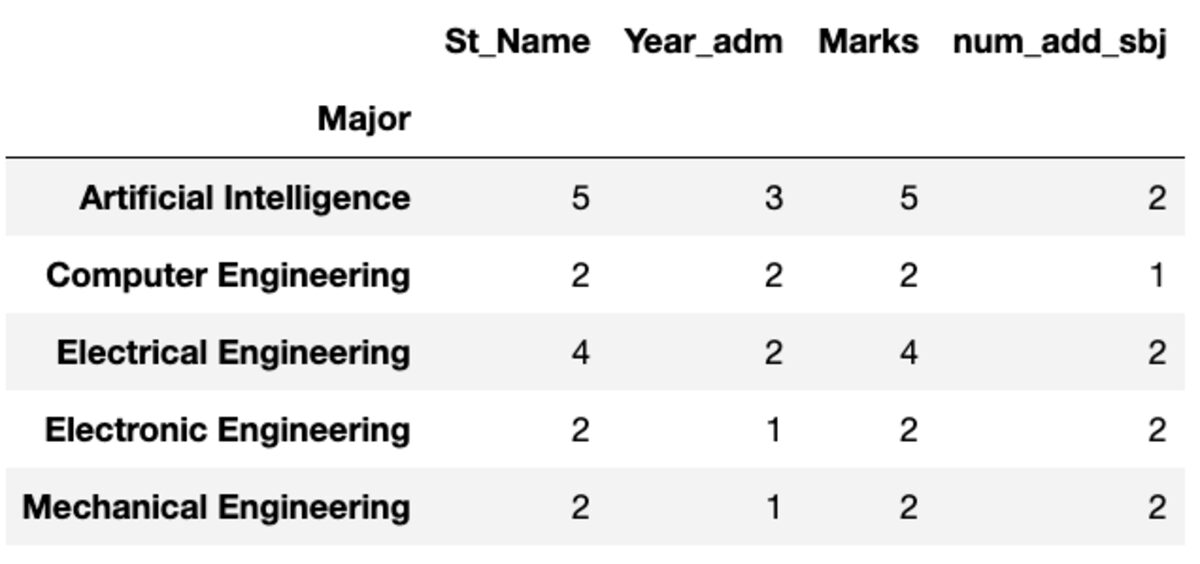
groups.count()
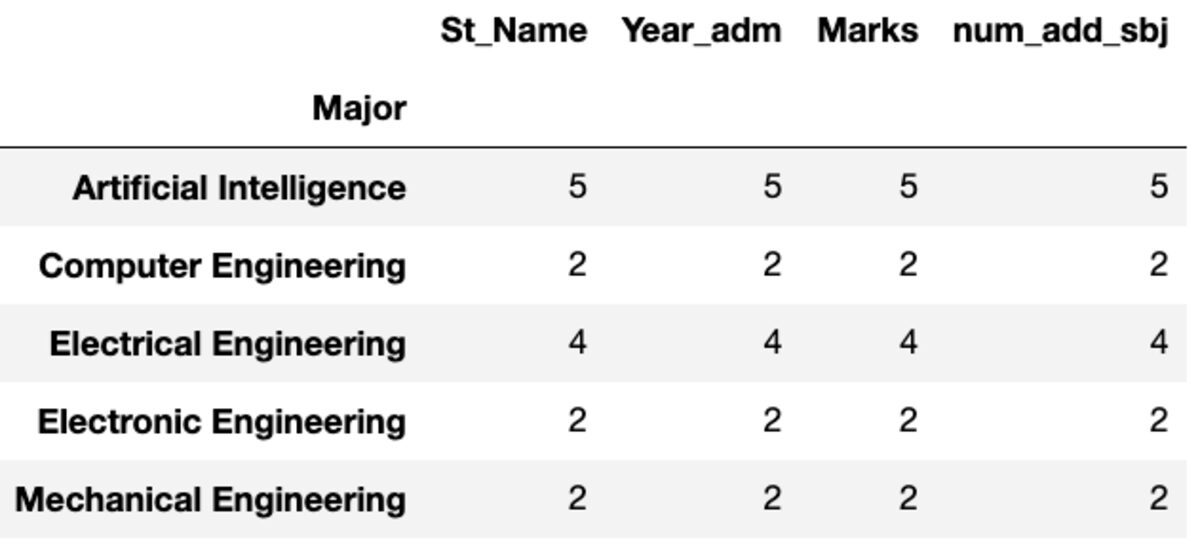
groups.nunique()
পুনঃনামকরণ
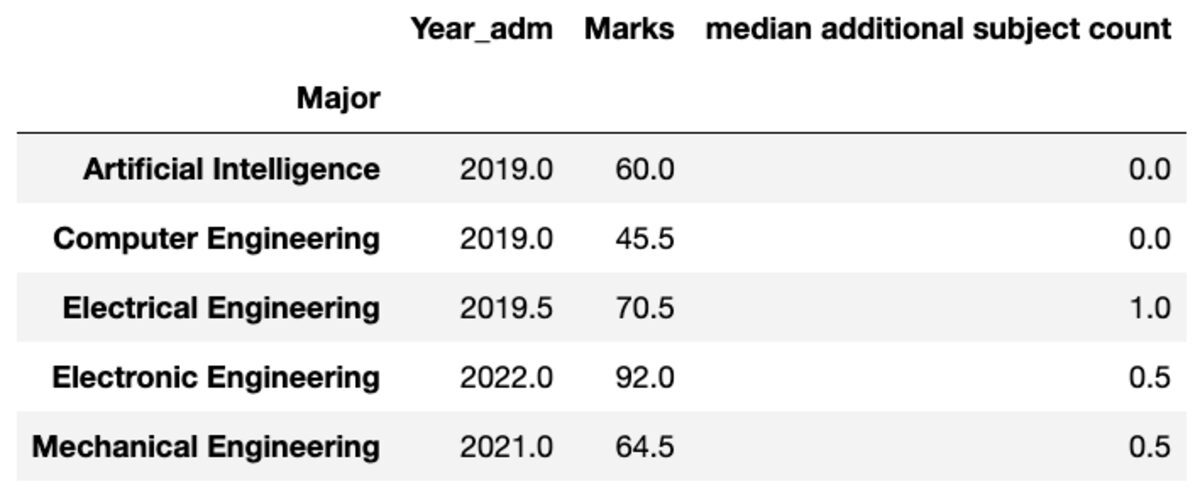
আপনি আপনার পছন্দ অনুযায়ী একত্রিত কলামের নাম পরিবর্তন করতে পারেন।
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- গ্রুপের উদ্দেশ্য সম্পর্কে পরিষ্কার হোন: আপনি কি অন্য কলামের গড় পেতে একটি কলাম দ্বারা ডেটা গ্রুপ করার চেষ্টা করছেন? অথবা আপনি প্রতিটি গ্রুপের সারি গণনা পেতে একাধিক কলাম দ্বারা ডেটা গ্রুপ করার চেষ্টা করছেন?
- ডেটা ফ্রেমের ইন্ডেক্সিং বুঝুন: গ্রুপবাই ফাংশন ডেটা গ্রুপ করতে সূচক ব্যবহার করে। আপনি যদি একটি কলাম দ্বারা ডেটা গ্রুপ করতে চান, নিশ্চিত করুন যে কলামটি সূচী হিসাবে সেট করা আছে বা আপনি .set_index() ব্যবহার করতে পারেন
- উপযুক্ত সমষ্টি ফাংশন ব্যবহার করুন: এটি বিভিন্ন সমষ্টি ফাংশনের সাথে ব্যবহার করা যেতে পারে যেমন মানে(), যোগফল(), গণনা(), মিন(), সর্বোচ্চ()
- as_index প্যারামিটার ব্যবহার করুন: False এ সেট করা হলে, এই প্যারামিটারটি পান্ডাকে সূচীর পরিবর্তে নিয়মিত কলাম হিসেবে গোষ্ঠীবদ্ধ কলাম ব্যবহার করতে বলে।
আপনি আপনার ডেটা থেকে আরও অন্তর্দৃষ্টি বের করতে pivot_table(), crosstab(), এবং cut() এর মতো অন্যান্য পান্ডা ফাংশনের সাথে একত্রে groupby() ব্যবহার করতে পারেন।
একটি গ্রুপবাই ফাংশন ডেটা বিশ্লেষণ এবং ম্যানিপুলেশনের জন্য একটি শক্তিশালী হাতিয়ার কারণ এটি আপনাকে এক বা একাধিক কলামের উপর ভিত্তি করে ডেটার সারিগুলিকে গোষ্ঠীভুক্ত করতে এবং তারপর গোষ্ঠীগুলিতে সামগ্রিক গণনা সম্পাদন করতে দেয়। টিউটোরিয়াল কোড উদাহরণের সাহায্যে গ্রুপবাই ফাংশন ব্যবহার করার বিভিন্ন উপায় প্রদর্শন করেছে। আশা করি এটি আপনাকে এটির সাথে আসা বিভিন্ন বিকল্পগুলি এবং কীভাবে তারা ডেটা বিশ্লেষণে সহায়তা করে সে সম্পর্কে একটি বোঝাপড়া প্রদান করবে৷
বিধি চুগ একজন AI কৌশলবিদ এবং একজন ডিজিটাল ট্রান্সফরমেশন লিডার যিনি পণ্য, বিজ্ঞান এবং প্রকৌশলের সংযোগস্থলে স্কেলযোগ্য মেশিন লার্নিং সিস্টেম তৈরি করতে কাজ করছেন। তিনি একজন পুরস্কার বিজয়ী উদ্ভাবনী নেতা, একজন লেখক এবং একজন আন্তর্জাতিক বক্তা। তিনি মেশিন লার্নিংকে গণতন্ত্রীকরণের একটি মিশনে রয়েছেন এবং প্রত্যেকের জন্য এই রূপান্তরের অংশ হওয়ার জন্য জারগন ভাঙতে চলেছেন৷
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- ক্ষমতা
- সক্ষম
- অর্জন করা
- অর্জন
- অতিরিক্ত
- উপরন্তু
- মোট পরিমাণ
- AI
- সব
- অনুমতি
- বিশ্লেষণ
- বিশ্লেষণ করা
- এবং
- অন্য
- ফলিত
- প্রয়োগ করা
- প্রয়োগ করা হচ্ছে
- যথাযথ
- কৃত্রিম
- কৃত্রিম বুদ্ধিমত্তা
- লেখক
- সহজলভ্য
- গড়
- পুরস্কার বিজয়ী
- ভিত্তি
- মৌলিক
- নিচে
- জৈবপ্রযুক্তি
- বিরতি
- নির্মাণ করা
- গণনা করা
- কলিং
- কেস
- চেক
- পরিষ্কার
- কোড
- স্তম্ভ
- কলাম
- আসা
- জটিল
- কম্পিউটার
- কম্পিউটার প্রকৌশল
- সৃষ্টি
- তৈরি করা হচ্ছে
- প্রথা
- উপাত্ত
- তথ্য বিশ্লেষণ
- ডেটাসেট
- গণতান্ত্রিক করা
- প্রদর্শিত
- চ্যুতি
- বিভিন্ন
- ডিজিটাল
- ডিজিটাল ট্রান্সফরমেসন
- সরাসরি
- Dont
- প্রতি
- সহজে
- কার্যকরীভাবে
- বৈদ্যুতিক প্রকৌশলী
- বৈদ্যুতিক
- প্রকৌশল
- ইত্যাদি
- সবাই
- উদাহরণ
- উদাহরণ
- নির্যাস
- পতন
- বৈশিষ্ট্য
- পূরণ করা
- ছাঁকনি
- আবিষ্কার
- প্রথম
- কেন্দ্রবিন্দু
- অনুসরণ
- ফ্রেম
- থেকে
- ক্রিয়া
- ক্রিয়াকলাপ
- উত্পাদন করা
- পাওয়া
- প্রদত্ত
- দেয়
- চালু
- গ্রুপ
- গ্রুপের
- হাত
- সাহায্য
- আশা
- কিভাবে
- কিভাবে
- এইচটিএমএল
- HTTPS দ্বারা
- আমদানি
- in
- অবিশ্বাস্যভাবে
- সূচক
- ইনোভেশন
- অর্ন্তদৃষ্টি
- উদাহরণ
- পরিবর্তে
- বুদ্ধিমত্তা
- আন্তর্জাতিক
- ছেদ
- IT
- অপভাষা
- কেডনুগেটস
- চাবি
- বড়
- নেতা
- শিখতে
- শিক্ষা
- লাইব্রেরি
- লাইব্রেরি
- তালিকা
- সৌন্দর্য
- মেশিন
- মেশিন লার্নিং
- মুখ্য
- করা
- দক্ষতা সহকারে হস্তচালন
- অনেক
- ম্যাচ
- সর্বোচ্চ
- যান্ত্রিক
- যন্ত্র প্রকৌশল
- মধ্যম
- পদ্ধতি
- মিশন
- মডিউল
- অধিক
- বহু
- নাম
- নাম
- প্রয়োজন
- পরবর্তী
- সংখ্যা
- ONE
- ওপেন সোর্স
- অপারেশনস
- অপশন সমূহ
- অন্যান্য
- পান্ডাস
- স্থিতিমাপ
- অংশ
- বিশেষ
- পাসিং
- সম্পাদন করা
- জায়গা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- ক্ষমতাশালী
- প্রিন্ট
- পণ্য
- উপলব্ধ
- উদ্দেশ্য
- পাইথন
- দ্রুত
- এলোমেলো
- সুপারিশ করা
- রেকর্ড
- নিয়মিত
- অবশিষ্ট
- প্রতিনিধিত্ব করে
- প্রয়োজন
- বিশ্রাম
- ফল
- ফলাফল
- প্রত্যাবর্তন
- আয়
- রিচার্ড
- বৃত্তাকার
- দৌড়
- একই
- মাপযোগ্য
- বিজ্ঞান
- সেট
- উচিত
- প্রদর্শিত
- অনুরূপ
- একক
- আয়তন
- কিছু
- বক্তা
- নির্দিষ্ট
- মান
- পরিসংখ্যান
- ধাপ
- সৈনাপত্যে দক্ষ ব্যক্তি
- ছাত্র
- শিক্ষার্থীরা
- বিষয়
- প্রস্তাব
- সংক্ষিপ্ত করা
- সিস্টেম
- কার্য
- কাজ
- বলে
- শর্তাবলী
- সার্জারির
- ডগা
- থেকে
- টুল
- রুপান্তর
- রুপান্তর
- রূপান্তরের
- অভিভাবকসংবঁধীয়
- ধরনের
- বোধশক্তি
- অনন্য
- ব্যবহার
- মানগুলি
- বিভিন্ন
- উপায়
- কি
- যে
- ইচ্ছা
- কাজ
- would
- X
- বছর
- আপনার
- zephyrnet
- শূন্য








