দ্বারা চিত্র Freepik
কথোপকথনমূলক AI বলতে বোঝায় ভার্চুয়াল এজেন্ট এবং চ্যাটবট যা মানুষের মিথস্ক্রিয়াকে অনুকরণ করে এবং কথোপকথনে মানুষকে জড়িত করতে পারে। কথোপকথনমূলক এআই ব্যবহার করা দ্রুত জীবনের একটি উপায় হয়ে উঠছে - আলেক্সাকে জিজ্ঞাসা করা থেকে "সবচেয়ে কাছের রেস্টুরেন্ট খুঁজুন" সিরিকে জিজ্ঞাসা করতে "একটি অনুস্মারক তৈরি করুন," ভার্চুয়াল সহকারী এবং চ্যাটবটগুলি প্রায়শই গ্রাহকদের প্রশ্নের উত্তর দিতে, অভিযোগের সমাধান করতে, সংরক্ষণ করতে এবং আরও অনেক কিছু করতে ব্যবহৃত হয়।
এই ভার্চুয়াল সহকারীগুলির বিকাশের জন্য যথেষ্ট প্রচেষ্টা প্রয়োজন৷ যাইহোক, মূল চ্যালেঞ্জগুলি বোঝা এবং মোকাবেলা করা উন্নয়ন প্রক্রিয়াকে প্রবাহিত করতে পারে। আমি একটি নিয়োগ প্ল্যাটফর্মের জন্য একটি পরিপক্ক চ্যাটবট তৈরি করার ক্ষেত্রে আমার প্রথম হাতের অভিজ্ঞতা ব্যবহার করেছি একটি রেফারেন্স পয়েন্ট হিসাবে মূল চ্যালেঞ্জ এবং তাদের সংশ্লিষ্ট সমাধানগুলি ব্যাখ্যা করার জন্য।
একটি কথোপকথনমূলক AI চ্যাটবট তৈরি করতে, ডেভেলপাররা চ্যাটবট তৈরি করতে RASA, Amazon's Lex বা Google এর Dialogflow এর মতো ফ্রেমওয়ার্ক ব্যবহার করতে পারেন। বেশিরভাগ RASA পছন্দ করে যখন তারা কাস্টম পরিবর্তনের পরিকল্পনা করে বা বটটি পরিণত পর্যায়ে থাকে কারণ এটি একটি ওপেন-সোর্স ফ্রেমওয়ার্ক। অন্যান্য ফ্রেমওয়ার্কগুলিও শুরুর পয়েন্ট হিসাবে উপযুক্ত।
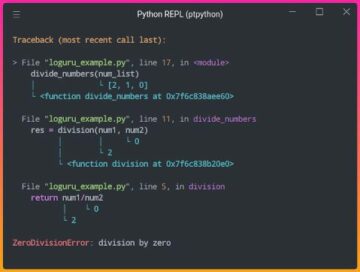
চ্যালেঞ্জগুলিকে একটি চ্যাটবটের তিনটি প্রধান উপাদান হিসাবে শ্রেণীবদ্ধ করা যেতে পারে।
প্রাকৃতিক ভাষা বোঝাপড়া (এনএলইউ) মানুষের কথোপকথন বোঝার জন্য একটি বটের ক্ষমতা। এটি অভিপ্রায় শ্রেণীবিভাগ, সত্তা নিষ্কাশন, এবং প্রতিক্রিয়া পুনরুদ্ধার করে।
ডায়ালগ ম্যানেজার ব্যবহারকারীর ইনপুটগুলির বর্তমান এবং পূর্ববর্তী সেটের উপর ভিত্তি করে সঞ্চালিত ক্রিয়াগুলির একটি সেটের জন্য দায়ী৷ এটি ইনপুট হিসাবে অভিপ্রায় এবং সত্তা নেয় (আগের কথোপকথনের অংশ হিসাবে) এবং পরবর্তী প্রতিক্রিয়া সনাক্ত করে।
প্রাকৃতিক ভাষা জেনারেশন (এনএলজি) প্রদত্ত ডেটা থেকে লিখিত বা কথ্য বাক্য তৈরি করার প্রক্রিয়া। এটি প্রতিক্রিয়া ফ্রেম করে, যা ব্যবহারকারীর কাছে উপস্থাপন করা হয়।
ট্যালেন্টিকা সফটওয়্যার থেকে ছবি
অপর্যাপ্ত তথ্য
যখন ডেভেলপাররা প্রায়শই জিজ্ঞাসিত প্রশ্নাবলী বা অন্যান্য সহায়তা সিস্টেমগুলিকে চ্যাটবট দিয়ে প্রতিস্থাপন করে, তখন তারা একটি শালীন পরিমাণ প্রশিক্ষণ ডেটা পায়। কিন্তু যখন তারা স্ক্র্যাচ থেকে বট তৈরি করে তখন এটি ঘটে না। এই ধরনের ক্ষেত্রে, বিকাশকারীরা কৃত্রিমভাবে প্রশিক্ষণের ডেটা তৈরি করে।
কি করো?
একটি টেমপ্লেট-ভিত্তিক ডেটা জেনারেটর প্রশিক্ষণের জন্য ব্যবহারকারীর প্রশ্নগুলির একটি শালীন পরিমাণ তৈরি করতে পারে। একবার চ্যাটবট প্রস্তুত হয়ে গেলে, প্রকল্পের মালিকরা এটিকে সীমিত সংখ্যক ব্যবহারকারীর কাছে প্রকাশ করতে পারে প্রশিক্ষণের ডেটা উন্নত করতে এবং একটি নির্দিষ্ট সময়ের মধ্যে এটি আপগ্রেড করতে।
অনুপযুক্ত মডেল নির্বাচন
উপযুক্ত মডেল নির্বাচন এবং প্রশিক্ষণ ডেটা সর্বোত্তম অভিপ্রায় এবং সত্তা নিষ্কাশন ফলাফল পেতে অত্যন্ত গুরুত্বপূর্ণ। বিকাশকারীরা সাধারণত একটি নির্দিষ্ট ভাষা এবং ডোমেনে চ্যাটবটগুলিকে প্রশিক্ষণ দেয় এবং বেশিরভাগ উপলব্ধ প্রাক-প্রশিক্ষিত মডেলগুলি প্রায়শই ডোমেন-নির্দিষ্ট এবং একটি একক ভাষায় প্রশিক্ষিত হয়।
মিশ্র ভাষার ক্ষেত্রেও হতে পারে যেখানে মানুষ বহুভুজ। তারা একটি মিশ্র ভাষায় প্রশ্ন লিখতে পারে. উদাহরণস্বরূপ, একটি ফরাসি-অধ্যুষিত অঞ্চলে, লোকেরা এক ধরনের ইংরেজি ব্যবহার করতে পারে যা ফরাসি এবং ইংরেজি উভয়ের মিশ্রণ।
কি করো?
একাধিক ভাষায় প্রশিক্ষিত মডেল ব্যবহার করা সমস্যা কমাতে পারে। একটি প্রাক-প্রশিক্ষিত মডেল যেমন LaBSE (ভাষা-অজ্ঞেয়বাদী বার্ট বাক্য এম্বেডিং) এই ধরনের ক্ষেত্রে সহায়ক হতে পারে। LaBSE 109 টিরও বেশি ভাষায় প্রশিক্ষিত একটি বাক্যের সাদৃশ্য টাস্কে। মডেল ইতিমধ্যে একটি ভিন্ন ভাষায় অনুরূপ শব্দ জানেন. আমাদের প্রকল্পে, এটি সত্যিই ভাল কাজ করেছে।
অনুপযুক্ত সত্তা নিষ্কাশন
ব্যবহারকারী কি ধরনের ডেটা অনুসন্ধান করছে তা শনাক্ত করার জন্য Chatbots-এর প্রয়োজন হয়। এই সত্তাগুলির মধ্যে সময়, স্থান, ব্যক্তি, আইটেম, তারিখ, ইত্যাদি অন্তর্ভুক্ত রয়েছে৷ যাইহোক, বটগুলি প্রাকৃতিক ভাষা থেকে একটি সত্তা সনাক্ত করতে ব্যর্থ হতে পারে:
একই প্রসঙ্গ কিন্তু ভিন্ন সত্তা. উদাহরণস্বরূপ, বটগুলি একটি জায়গাকে সত্তা হিসাবে বিভ্রান্ত করতে পারে যখন কোনও ব্যবহারকারী "IIT দিল্লির ছাত্রদের নাম" এবং তারপরে "বেঙ্গালুরু থেকে ছাত্রদের নাম" টাইপ করে।
এমন পরিস্থিতিতে যেখানে সত্তা কম আত্মবিশ্বাসের সাথে ভুলভাবে অনুমান করা হয়। উদাহরণস্বরূপ, একটি বট আইআইটি দিল্লিকে কম আত্মবিশ্বাসের শহর হিসাবে চিহ্নিত করতে পারে।
মেশিন লার্নিং মডেল দ্বারা আংশিক সত্তা নিষ্কাশন। যদি কোনও ব্যবহারকারী "IIT দিল্লির ছাত্র" টাইপ করে, মডেলটি "IIT দিল্লি" এর পরিবর্তে শুধুমাত্র "IIT" কে শুধুমাত্র একটি সত্তা হিসাবে চিহ্নিত করতে পারে।
কোনো প্রসঙ্গ ছাড়াই একক-শব্দের ইনপুট মেশিন লার্নিং মডেলগুলিকে বিভ্রান্ত করতে পারে। উদাহরণস্বরূপ, "ঋষিকেশ" শব্দের অর্থ একজন ব্যক্তির পাশাপাশি একটি শহরের নামও হতে পারে।
কি করো?
আরও প্রশিক্ষণের উদাহরণ যোগ করা একটি সমাধান হতে পারে। কিন্তু একটি সীমা আছে যার পরে আরও যোগ করা সাহায্য করবে না। তদুপরি, এটি একটি অন্তহীন প্রক্রিয়া। আরেকটি সমাধান হতে পারে প্রাক-সংজ্ঞায়িত শব্দগুলি ব্যবহার করে রেজেক্স প্যাটার্নগুলিকে সংজ্ঞায়িত করা যা সম্ভাব্য মানগুলির একটি পরিচিত সেট, যেমন শহর, দেশ ইত্যাদি সহ সত্তাগুলিকে বের করতে সহায়তা করে।
মডেলরা যখনই সত্তার ভবিষ্যদ্বাণী সম্পর্কে নিশ্চিত নয় তখনই তারা কম আত্মবিশ্বাস ভাগ করে নেয়। বিকাশকারীরা এটিকে একটি কাস্টম উপাদান কল করার জন্য একটি ট্রিগার হিসাবে ব্যবহার করতে পারে যা কম-আস্থাশীল সত্তাকে সংশোধন করতে পারে। উপরের উদাহরণটি বিবেচনা করা যাক। যদি আইআইটি দিল্লি কম আস্থা সহ একটি শহর হিসাবে ভবিষ্যদ্বাণী করা হয়, তারপর ব্যবহারকারী সর্বদা ডাটাবেসে এটি অনুসন্ধান করতে পারেন। তে ভবিষ্যদ্বাণীকৃত সত্তা খুঁজে পেতে ব্যর্থ হওয়ার পর শহর টেবিলে, মডেলটি অন্য টেবিলে যাবে এবং অবশেষে, এটিতে খুঁজে পাবে প্রতিষ্ঠান টেবিল, সত্তা সংশোধনের ফলে.
ভুল অভিপ্রায় শ্রেণীবিভাগ
প্রতিটি ব্যবহারকারীর বার্তার সাথে কিছু উদ্দেশ্য যুক্ত থাকে। যেহেতু উদ্দেশ্যগুলি একটি বটের পরবর্তী ক্রিয়াকলাপগুলি অর্জন করে, তাই অভিপ্রায় সহ ব্যবহারকারীর প্রশ্নগুলিকে সঠিকভাবে শ্রেণিবদ্ধ করা অত্যন্ত গুরুত্বপূর্ণ৷ যাইহোক, বিকাশকারীদের অবশ্যই অভিপ্রায় জুড়ে ন্যূনতম বিভ্রান্তির সাথে অভিপ্রায়গুলি সনাক্ত করতে হবে। অন্যথায়, বিভ্রান্তির কারণে মামলা হতে পারে। উদাহরণ স্বরূপ, "আমাকে খোলা অবস্থান দেখান" বনামআমাকে উন্মুক্ত অবস্থানের প্রার্থী দেখান"।
কি করো?
বিভ্রান্তিকর প্রশ্নগুলিকে আলাদা করার দুটি উপায় রয়েছে। প্রথমত, একজন বিকাশকারী উপ-উদ্দেশ্য প্রবর্তন করতে পারে। দ্বিতীয়ত, মডেলগুলি চিহ্নিত সত্তার উপর ভিত্তি করে প্রশ্নগুলি পরিচালনা করতে পারে।
একটি ডোমেন-নির্দিষ্ট চ্যাটবট একটি বন্ধ সিস্টেম হওয়া উচিত যেখানে এটি স্পষ্টভাবে সনাক্ত করা উচিত যে এটি কী সক্ষম এবং এটি কী নয়৷ ডোমেন-নির্দিষ্ট চ্যাটবটগুলির জন্য পরিকল্পনা করার সময় বিকাশকারীদের অবশ্যই পর্যায়ক্রমে বিকাশ করতে হবে। প্রতিটি পর্যায়ে, তারা চ্যাটবটের অসমর্থিত বৈশিষ্ট্যগুলি সনাক্ত করতে পারে (অসমর্থিত অভিপ্রায়ের মাধ্যমে)।
এছাড়াও তারা শনাক্ত করতে পারে যে চ্যাটবট "স্কোপের বাইরে" অভিপ্রায়ে কী পরিচালনা করতে পারে না। কিন্তু এমন কিছু ক্ষেত্রে হতে পারে যেখানে বটটি অসমর্থিত এবং সুযোগের বাইরের উদ্দেশ্য নিয়ে বিভ্রান্ত হয়। এই ধরনের পরিস্থিতিগুলির জন্য, একটি ফলব্যাক ব্যবস্থা থাকা উচিত যেখানে, যদি অভিপ্রায় আত্মবিশ্বাস একটি থ্রেশহোল্ডের নীচে থাকে, তাহলে মডেলটি বিভ্রান্তিকর ঘটনাগুলি পরিচালনা করার জন্য একটি ফলব্যাক অভিপ্রায়ের সাথে সুন্দরভাবে কাজ করতে পারে।
একবার বট ব্যবহারকারীর বার্তার অভিপ্রায় সনাক্ত করলে, এটি অবশ্যই একটি প্রতিক্রিয়া পাঠাতে হবে। বট সংজ্ঞায়িত নিয়ম এবং গল্পের একটি নির্দিষ্ট সেটের উপর ভিত্তি করে প্রতিক্রিয়া নির্ধারণ করে। উদাহরণস্বরূপ, একটি নিয়ম উচ্চারণের মতো সহজ হতে পারে "সুপ্রভাত" যখন ব্যবহারকারী অভিবাদন জানায় "ওহে". যাইহোক, প্রায়শই, চ্যাটবটগুলির সাথে কথোপকথনে ফলো-আপ মিথস্ক্রিয়া থাকে এবং তাদের প্রতিক্রিয়াগুলি কথোপকথনের সামগ্রিক প্রেক্ষাপটের উপর নির্ভর করে।
কি করো?
এটি পরিচালনা করার জন্য, চ্যাটবটগুলিকে গল্প বলা হয় বাস্তব কথোপকথনের উদাহরণ দেওয়া হয়। যাইহোক, ব্যবহারকারীরা সবসময় উদ্দেশ্য অনুযায়ী ইন্টারঅ্যাক্ট করেন না। একটি পরিপক্ক চ্যাটবটকে এই ধরনের সমস্ত বিচ্যুতি সুন্দরভাবে পরিচালনা করা উচিত। ডিজাইনার এবং ডেভেলপাররা এই গ্যারান্টি দিতে পারেন যদি তারা গল্প লেখার সময় শুধুমাত্র একটি সুখী পথের দিকে মনোনিবেশ না করে বরং অসুখী পথে কাজ করে।
চ্যাটবটগুলির সাথে ব্যবহারকারীর ব্যস্ততা চ্যাটবট প্রতিক্রিয়াগুলির উপর অনেক বেশি নির্ভর করে। প্রতিক্রিয়াগুলি খুব রোবোটিক বা খুব পরিচিত হলে ব্যবহারকারীরা আগ্রহ হারাতে পারেন। উদাহরণস্বরূপ, প্রতিক্রিয়া সঠিক হওয়া সত্ত্বেও একজন ব্যবহারকারী ভুল ইনপুটের জন্য "আপনি একটি ভুল প্রশ্ন টাইপ করেছেন" এর মতো একটি উত্তর পছন্দ নাও করতে পারেন। এখানে উত্তরটি একজন সহকারীর ব্যক্তিত্বের সাথে মেলে না।
কি করো?
চ্যাটবট একটি সহকারী হিসাবে কাজ করে এবং একটি নির্দিষ্ট ব্যক্তিত্ব এবং কণ্ঠস্বরের অধিকারী হওয়া উচিত। তাদের স্বাগত এবং নম্র হওয়া উচিত এবং বিকাশকারীদের সেই অনুযায়ী কথোপকথন এবং উচ্চারণ ডিজাইন করা উচিত। প্রতিক্রিয়াগুলি রোবোটিক বা যান্ত্রিক শোনা উচিত নয়। উদাহরণস্বরূপ, বট বলতে পারে, "দুঃখিত, মনে হচ্ছে আমার কাছে কোনো বিবরণ নেই। আপনি কি অনুগ্রহ করে আপনার প্রশ্নটি পুনরায় টাইপ করতে পারেন?" একটি ভুল ইনপুট সম্বোধন করতে।
LLM (Large Language Model) ভিত্তিক চ্যাটবট যেমন ChatGPT এবং Bard হল গেম পরিবর্তনকারী উদ্ভাবন এবং কথোপকথনমূলক AI-এর ক্ষমতা উন্নত করেছে। এরা শুধুমাত্র মানুষের মত খোলামেলা কথোপকথন করতেই পারদর্শী নয় বরং টেক্সট সংক্ষিপ্তকরণ, অনুচ্ছেদ লেখা ইত্যাদির মতো বিভিন্ন কাজ সম্পাদন করতে পারে, যা আগে শুধুমাত্র নির্দিষ্ট মডেলের মাধ্যমেই করা যেত।
ঐতিহ্যগত চ্যাটবট সিস্টেমের চ্যালেঞ্জগুলির মধ্যে একটি হল প্রতিটি বাক্যকে উদ্দেশ্যগুলিতে শ্রেণীবদ্ধ করা এবং সেই অনুযায়ী প্রতিক্রিয়া নির্ধারণ করা। এই পদ্ধতি ব্যবহারিক নয়। "দুঃখিত, আমি আপনাকে পেতে পারিনি" এর মতো প্রতিক্রিয়াগুলি প্রায়ই বিরক্তিকর হয়। উদ্দেশ্যহীন চ্যাটবট সিস্টেমগুলি এগিয়ে যাওয়ার পথ, এবং এলএলএম এটিকে বাস্তবে পরিণত করতে পারে।
নির্দিষ্ট ডোমেন-নির্দিষ্ট সত্তা স্বীকৃতি ব্যতীত সাধারণ নামকৃত সত্তা স্বীকৃতিতে এলএলএমগুলি সহজেই অত্যাধুনিক ফলাফল অর্জন করতে পারে। যেকোন চ্যাটবট ফ্রেমওয়ার্কের সাথে এলএলএম ব্যবহার করার জন্য একটি মিশ্র পদ্ধতি একটি আরও পরিপক্ক এবং শক্তিশালী চ্যাটবট সিস্টেমকে অনুপ্রাণিত করতে পারে।
কথোপকথনমূলক AI-তে সাম্প্রতিক অগ্রগতি এবং ক্রমাগত গবেষণার সাথে, চ্যাটবটগুলি প্রতিদিন আরও ভাল হচ্ছে। "মুম্বাইয়ের জন্য একটি ফ্লাইট বুক করুন এবং দাদারে একটি ক্যাবের ব্যবস্থা করুন" এর মতো জটিল কাজগুলিকে একাধিক অভিপ্রায় সহ পরিচালনা করার মতো ক্ষেত্রগুলি অনেক মনোযোগ পাচ্ছে৷
ব্যবহারকারীকে নিযুক্ত রাখতে ব্যবহারকারীর বৈশিষ্ট্যের উপর ভিত্তি করে শীঘ্রই ব্যক্তিগতকৃত কথোপকথন হবে। উদাহরণস্বরূপ, যদি একটি বট দেখতে পায় যে ব্যবহারকারী অসন্তুষ্ট, এটি কথোপকথনটি একটি আসল এজেন্টের কাছে পুনঃনির্দেশ করে। উপরন্তু, ক্রমবর্ধমান চ্যাটবট ডেটার সাথে, ChatGPT-এর মতো গভীর শিক্ষার কৌশলগুলি জ্ঞানের ভিত্তি ব্যবহার করে স্বয়ংক্রিয়ভাবে প্রশ্নের উত্তর তৈরি করতে পারে।
সুমন সৌরভ ট্যালেন্টিকা সফ্টওয়্যার, একটি সফ্টওয়্যার প্রোডাক্ট ডেভেলপমেন্ট কোম্পানির একজন ডেটা সায়েন্টিস্ট। তিনি এনআইটি আগরতলার একজন প্রাক্তন ছাত্র এবং এনএলপি, কথোপকথনমূলক এআই এবং জেনারেটিভ এআই ব্যবহার করে বিপ্লবী এআই সমাধান ডিজাইন এবং বাস্তবায়নের 8 বছরেরও বেশি অভিজ্ঞতার সাথে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : আছে
- : হয়
- :না
- :কোথায়
- 8
- a
- ক্ষমতা
- সম্পর্কে
- উপরে
- তদনুসারে
- অর্জন করা
- অর্জন
- দিয়ে
- স্টক
- যোগ
- উপরন্তু
- ঠিকানা
- সম্ভাষণ
- উন্নয়নের
- পর
- প্রতিনিধি
- এজেন্ট
- AI
- এআই চ্যাটবট
- আলেক্সা
- সব
- ইতিমধ্যে
- এছাড়াও
- প্রাক্তন ছাত্র
- সর্বদা
- পরিমাণ
- an
- এবং
- অন্য
- উত্তর
- কোন
- অভিগমন
- রয়েছি
- এলাকার
- AS
- জিজ্ঞাসা
- সহায়ক
- সহায়ক
- যুক্ত
- At
- মনোযোগ
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- এড়াতে
- পিছনে
- ভিত্তি
- ভিত্তি
- BE
- মানানসই
- প্রাণী
- নিচে
- সর্বোত্তম
- উত্তম
- বট
- উভয়
- বট
- নির্মাণ করা
- কিন্তু
- by
- কল
- নামক
- CAN
- না পারেন
- ক্ষমতা
- সক্ষম
- মামলা
- শ্রেণীকরণ
- কিছু
- চ্যালেঞ্জ
- পরিবর্তন
- বৈশিষ্ট্য
- chatbot
- chatbots
- চ্যাটজিপিটি
- শহর
- শ্রেণীবিন্যাস
- শ্রেণীবদ্ধ
- পরিষ্কারভাবে
- বন্ধ
- কোম্পানি
- অভিযোগ
- জটিল
- উপাদান
- উপাদান
- বোঝা
- বিশ্বাস
- বিভ্রান্ত
- বিভ্রান্তিকর
- বিশৃঙ্খলা
- বিবেচনা
- প্রসঙ্গ
- একটানা
- কথোপকথন
- কথ্য
- কথোপকথন এআই
- কথোপকথন
- ঠিক
- সঠিকভাবে
- অনুরূপ
- পারা
- দেশ
- পথ
- সৃষ্টি
- তৈরি করা হচ্ছে
- কঠোর
- বর্তমান
- প্রথা
- উপাত্ত
- তথ্য বিজ্ঞানী
- ডেটাবেস
- তারিখ
- দিন
- শালীন
- সিদ্ধান্ত নিচ্ছে
- গভীর
- গভীর জ্ঞানার্জন
- নির্ধারণ করা
- সংজ্ঞায়িত
- দিল্লি
- নির্ভর
- প্রবাহ
- নকশা
- ডিজাইনার
- ফন্দিবাজ
- বিস্তারিত
- বিকাশকারী
- ডেভেলপারদের
- উন্নয়ন
- কথোপকথন
- সংলাপ
- বিভিন্ন
- ভেদ করা
- do
- না
- ডোমেইন
- Dont
- প্রতি
- পূর্বে
- সহজে
- প্রচেষ্টা
- এম্বেডিং
- অবিরাম
- চুক্তিবদ্ধ করান
- জড়িত
- প্রবৃত্তি
- ইংরেজি
- উন্নত করা
- প্রবেশ করান
- সত্ত্বা
- সত্তা
- ইত্যাদি
- এমন কি
- অবশেষে
- ক্রমবর্ধমান
- প্রতি
- প্রতিদিন
- উদাহরণ
- উদাহরণ
- অভিজ্ঞতা
- ব্যাখ্যা করা
- নির্যাস
- নিষ্কাশন
- ব্যর্থ
- ব্যর্থতা
- পরিচিত
- দ্রুত
- বৈশিষ্ট্য
- প্রতিপালিত
- আবিষ্কার
- খুঁজে বের করে
- ফ্লাইট
- কেন্দ্রবিন্দু
- জন্য
- অগ্রবর্তী
- ফ্রেমওয়ার্ক
- অবকাঠামো
- ফরাসি
- থেকে
- সাধারণ
- উত্পাদন করা
- উৎপাদিত
- প্রজন্ম
- সৃজক
- জেনারেটিভ এআই
- উত্পাদক
- পাওয়া
- পেয়ে
- প্রদত্ত
- ভাল
- Google এর
- জামিন
- হাতল
- হ্যান্ডলিং
- ঘটা
- খুশি
- আছে
- জমিদারি
- he
- প্রচন্ডভাবে
- সাহায্য
- সহায়ক
- এখানে
- কিভাবে
- কিভাবে
- যাহোক
- HTTPS দ্বারা
- মানবীয়
- নম্র
- i
- চিহ্নিত
- শনাক্ত
- সনাক্ত করা
- if
- বাস্তবায়ন
- উন্নত
- in
- অন্তর্ভুক্ত করা
- প্রবর্তিত
- ইনপুট
- ইনপুট
- অনুপ্রাণিত করা
- উদাহরণ
- পরিবর্তে
- অভিপ্রেত
- অভিপ্রায়
- গর্ভনাটিকা
- মিথষ্ক্রিয়া
- পারস্পরিক ক্রিয়ার
- স্বার্থ
- মধ্যে
- প্রবর্তন করা
- IT
- JPG
- মাত্র
- কেডনুগেটস
- রাখা
- চাবি
- রকম
- জ্ঞান
- পরিচিত
- জানে
- ভাষা
- ভাষাসমূহ
- বড়
- সর্বশেষ
- শিক্ষা
- জীবন
- মত
- LIMIT টি
- সীমিত
- লিঙ্কডইন
- হারান
- কম
- নিম্ন
- মেশিন
- মেশিন লার্নিং
- মুখ্য
- করা
- মেকিং
- ম্যাচ
- পরিণত
- মে..
- me
- গড়
- যান্ত্রিক
- পদ্ধতি
- বার্তা
- হতে পারে
- যত্সামান্য
- মিশ্রিত করা
- মিশ্র
- মডেল
- মডেল
- অধিক
- পরন্তু
- সেতু
- অনেক
- বহু
- মুম্বাই
- অবশ্যই
- my
- নাম
- নামে
- প্রাকৃতিক
- স্বভাবিক ভাষা
- পরবর্তী
- NLG
- NLP
- nlu
- না।
- সংখ্যা
- of
- প্রায়ই
- on
- একদা
- কেবল
- খোলা
- ওপেন সোর্স
- or
- অন্যান্য
- অন্যভাবে
- আমাদের
- শেষ
- সামগ্রিক
- মালিকদের
- অংশ
- পথ
- পাথ
- নিদর্শন
- সম্প্রদায়
- সম্পাদন করা
- সম্পাদিত
- সঞ্চালিত
- কাল
- ব্যক্তি
- ব্যক্তিগতকৃত
- ফেজ
- পর্যায়ক্রমে
- জায়গা
- পরিকল্পনা
- পরিকল্পনা
- মাচা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- দয়া করে
- বিন্দু
- অবস্থান
- ভোগদখল করা
- সম্ভব
- ব্যবহারিক
- পূর্বাভাস
- ভবিষ্যদ্বাণী
- পছন্দ করা
- উপস্থাপন
- আগে
- সমস্যা
- এগিয়ে
- প্রক্রিয়া
- পণ্য
- পণ্য উন্নয়ন
- প্রকল্প
- প্রশ্নের
- প্রশ্ন
- R
- Rasa
- প্রস্তুত
- বাস্তব
- বাস্তবতা
- সত্যিই
- স্বীকার
- সংগ্রহ
- হ্রাস করা
- উল্লেখ
- বোঝায়
- এলাকা
- নির্ভর করা
- অনুস্মারক
- প্রতিস্থাপন করা
- প্রয়োজন
- প্রয়োজন
- গবেষণা
- সমাধান
- প্রতিক্রিয়া
- প্রতিক্রিয়া
- দায়ী
- ফলে এবং
- ফলাফল
- বৈপ্লবিক
- শক্তসমর্থ
- নিয়ম
- নিয়ম
- একই
- বলা
- পরিস্থিতিতে
- বিজ্ঞানী
- আঁচড়ের দাগ
- সার্চ
- অনুসন্ধানের
- মনে হয়
- নির্বাচন
- পাঠান
- বাক্য
- স্থল
- সেট
- শেয়ার
- উচিত
- অনুরূপ
- সহজ
- থেকে
- একক
- সিরীয়
- সফটওয়্যার
- সমাধান
- সলিউশন
- কিছু
- শব্দ
- নির্দিষ্ট
- উচ্চারিত
- পর্যায়
- শুরু হচ্ছে
- রাষ্ট্র-এর-শিল্প
- খবর
- স্ট্রিমলাইন
- শিক্ষার্থীরা
- সারগর্ভ
- এমন
- উপযুক্ত
- সমর্থন
- সমর্থন সিস্টেম
- নিশ্চিত
- কৃত্রিমভাবে
- পদ্ধতি
- সিস্টেম
- T
- টেবিল
- গ্রহণ করা
- লাগে
- কার্য
- কাজ
- প্রযুক্তি
- পাঠ
- চেয়ে
- যে
- সার্জারির
- তাদের
- তাহাদিগকে
- তারপর
- সেখানে।
- এইগুলো
- তারা
- এই
- যদিও?
- তিন
- গোবরাট
- সময়
- থেকে
- স্বন
- ভয়েস টোন
- অত্যধিক
- ঐতিহ্যগত
- রেলগাড়ি
- প্রশিক্ষিত
- প্রশিক্ষণ
- ট্রিগার
- দুই
- আদর্শ
- ধরনের
- বোধশক্তি
- আপগ্রেড
- ব্যবহার
- ব্যবহৃত
- ব্যবহারকারী
- ব্যবহারকারী
- ব্যবহার
- সাধারণত
- মানগুলি
- মাধ্যমে
- ভার্চুয়াল
- কণ্ঠস্বর
- vs
- W
- উপায়..
- উপায়
- স্বাগতপূর্ণ
- আমরা একটি
- কি
- কখন
- যখনই
- যে
- যখন
- ইচ্ছা
- সঙ্গে
- শব্দ
- শব্দ
- হয়া যাই ?
- কাজ করছে
- would
- লেখা
- লিখিত
- ভুল
- বছর
- আপনি
- আপনার
- zephyrnet