এই পোস্টটি LSEG-এর লো লেটেন্সি গ্রুপ থেকে প্রমোদ নায়ক, লক্ষ্মীকান্ত মাননেম এবং বিবেক আগারওয়ালের সাথে লেখা।
লেনদেন খরচ বিশ্লেষণ (TCA) ব্যাপকভাবে ব্যবসায়ী, পোর্টফোলিও ম্যানেজার এবং ব্রোকাররা প্রি-ট্রেড এবং পোস্ট-ট্রেড বিশ্লেষণের জন্য ব্যবহার করে এবং তাদের লেনদেনের খরচ এবং তাদের ট্রেডিং কৌশলগুলির কার্যকারিতা পরিমাপ ও অপ্টিমাইজ করতে সাহায্য করে। এই পোস্টে, আমরা থেকে বিড-আস্ক স্প্রেডের বিকল্পগুলি বিশ্লেষণ করি LSEG টিক ইতিহাস – PCAP ডেটাসেট ব্যবহার করে Apache Spark এর জন্য Amazon Athena. আমরা আপনাকে দেখাই যে কীভাবে ডেটা অ্যাক্সেস করতে হয়, ডেটাতে প্রয়োগ করার জন্য কাস্টম ফাংশনগুলিকে সংজ্ঞায়িত করতে হয়, ডেটাসেটটি অনুসন্ধান করতে এবং ফিল্টার করতে হয় এবং বিশ্লেষণের ফলাফলগুলি কল্পনা করতে হয়, এমনকি বড় ডেটাসেটের জন্যও পরিকাঠামো সেট আপ বা স্পার্ক কনফিগার করার বিষয়ে চিন্তা না করেই৷
পটভূমি
অপশন প্রাইস রিপোর্টিং অথরিটি (OPRA) একটি গুরুত্বপূর্ণ সিকিউরিটিজ ইনফরমেশন প্রসেসর হিসেবে কাজ করে, ইউএস অপশনের জন্য শেষ বিক্রয় রিপোর্ট, উদ্ধৃতি এবং প্রাসঙ্গিক তথ্য সংগ্রহ, একত্রীকরণ এবং প্রচার করে। 18টি সক্রিয় ইউএস অপশন এক্সচেঞ্জ এবং 1.5 মিলিয়নেরও বেশি যোগ্য চুক্তির সাথে, OPRA ব্যাপক বাজার তথ্য প্রদানে একটি গুরুত্বপূর্ণ ভূমিকা পালন করে।
5 ফেব্রুয়ারী, 2024-এ, সিকিউরিটিজ ইন্ডাস্ট্রি অটোমেশন কর্পোরেশন (SIAC) OPRA ফিডকে 48 থেকে 96 মাল্টিকাস্ট চ্যানেলে আপগ্রেড করতে প্রস্তুত। এই বর্ধিতকরণের লক্ষ্য মার্কিন বিকল্প বাজারে ক্রমবর্ধমান ট্রেডিং কার্যকলাপ এবং অস্থিরতার প্রতিক্রিয়া হিসাবে প্রতীক বিতরণ এবং লাইন ক্ষমতা ব্যবহারকে অপ্টিমাইজ করা। SIAC সুপারিশ করেছে যে সংস্থাগুলি প্রতি সেকেন্ডে 37.3 জিবিট পর্যন্ত সর্বোচ্চ ডেটা হারের জন্য প্রস্তুত।
আপগ্রেড হওয়া সত্ত্বেও প্রকাশিত ডেটার মোট ভলিউম অবিলম্বে পরিবর্তন না করা সত্ত্বেও, এটি OPRA কে উল্লেখযোগ্যভাবে দ্রুত হারে ডেটা ছড়িয়ে দিতে সক্ষম করে। গতিশীল বিকল্প বাজারের চাহিদা পূরণের জন্য এই রূপান্তরটি অত্যন্ত গুরুত্বপূর্ণ।
OPRA 150.4 সালের 3 ত্রৈমাসিকে এক দিনে সর্বোচ্চ 2023 বিলিয়ন বার্তা এবং এক দিনে 400 বিলিয়ন বার্তার সক্ষমতা হেডরুমের প্রয়োজন সহ সবচেয়ে বড় ফিড হিসাবে দাঁড়িয়েছে। প্রতিটি একক বার্তা ক্যাপচার করা লেনদেনের খরচ বিশ্লেষণ, বাজারের তারল্য পর্যবেক্ষণ, ট্রেডিং কৌশল মূল্যায়ন এবং বাজার গবেষণার জন্য গুরুত্বপূর্ণ।
তথ্য সম্পর্কে
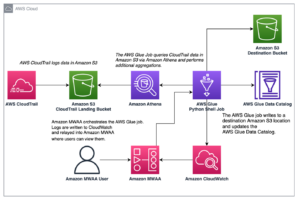
LSEG টিক ইতিহাস – PCAP এটি একটি ক্লাউড-ভিত্তিক সংগ্রহস্থল, যা 30 পিবি-র বেশি, অতি-উচ্চ-মানের বৈশ্বিক বাজার ডেটা হাউজিং। বিশ্বব্যাপী প্রধান প্রাইমারি এবং ব্যাকআপ এক্সচেঞ্জ ডেটা সেন্টারে কৌশলগতভাবে অবস্থানরত অপ্রয়োজনীয় ক্যাপচার প্রসেস নিযুক্ত করে, এই ডেটাটি সরাসরি এক্সচেঞ্জ ডেটা সেন্টারের মধ্যে ধারণ করা হয়। LSEG-এর ক্যাপচার প্রযুক্তি ক্ষতিহীন ডেটা ক্যাপচার নিশ্চিত করে এবং ন্যানোসেকেন্ড টাইমস্ট্যাম্প নির্ভুলতার জন্য একটি GPS টাইম-সোর্স ব্যবহার করে। অতিরিক্তভাবে, অত্যাধুনিক ডেটা সালিসি কৌশলগুলি নির্বিঘ্নে কোনও ডেটা ফাঁক পূরণ করতে নিযুক্ত করা হয়। ক্যাপচার করার পরে, তথ্যটি যত্ন সহকারে প্রক্রিয়াকরণ এবং সালিশের মধ্য দিয়ে যায়, এবং তারপর ব্যবহার করে Parquet ফরম্যাটে স্বাভাবিক করা হয় LSEG এর রিয়েল টাইম আল্ট্রা ডাইরেক্ট (RTUD) ফিড হ্যান্ডলার।
স্বাভাবিকীকরণ প্রক্রিয়া, যা বিশ্লেষণের জন্য ডেটা প্রস্তুত করার অবিচ্ছেদ্য অংশ, প্রতিদিন 6 টিবি পর্যন্ত সংকুচিত Parquet ফাইল তৈরি করে। প্রচুর পরিমাণে ডেটার জন্য দায়ী করা হয় OPRA-এর অন্তর্নিহিত প্রকৃতি, একাধিক এক্সচেঞ্জ বিস্তৃত, এবং বিভিন্ন বৈশিষ্ট্য দ্বারা চিহ্নিত অসংখ্য বিকল্প চুক্তির বৈশিষ্ট্য। বর্ধিত বাজারের অস্থিরতা এবং বিকল্প এক্সচেঞ্জগুলিতে বাজার তৈরির কার্যকলাপ OPRA-তে প্রকাশিত ডেটার পরিমাণে আরও অবদান রাখে।
টিক ইতিহাসের বৈশিষ্ট্য - PCAP সংস্থাগুলিকে নিম্নলিখিতগুলি সহ বিভিন্ন বিশ্লেষণ পরিচালনা করতে সক্ষম করে:
- প্রাক-বাণিজ্য বিশ্লেষণ - সম্ভাব্য বাণিজ্য প্রভাব মূল্যায়ন করুন এবং ঐতিহাসিক তথ্যের উপর ভিত্তি করে বিভিন্ন কার্যকরী কৌশল অন্বেষণ করুন
- পোস্ট ট্রেড মূল্যায়ন - কার্যকরী কৌশলগুলির কার্যকারিতা মূল্যায়ন করতে বেঞ্চমার্কের বিপরীতে প্রকৃত নির্বাহের ব্যয় পরিমাপ করুন
- অপ্টিমাইজ ফাঁসি - বাজারের প্রভাব কমাতে এবং সামগ্রিক ট্রেডিং খরচ কমাতে ঐতিহাসিক বাজারের নিদর্শনগুলির উপর ভিত্তি করে সূক্ষ্মভাবে কার্যকরী কৌশলগুলি
- ঝুকি ব্যবস্থাপনা - স্লিপেজ প্যাটার্ন সনাক্ত করুন, বহিরাগতদের সনাক্ত করুন এবং ব্যবসায়িক ক্রিয়াকলাপের সাথে সম্পর্কিত ঝুঁকিগুলি সক্রিয়ভাবে পরিচালনা করুন
- পারফরম্যান্স অ্যাট্রিবিউশন - পোর্টফোলিও কর্মক্ষমতা বিশ্লেষণ করার সময় বিনিয়োগের সিদ্ধান্ত থেকে ট্রেডিং সিদ্ধান্তের প্রভাবকে আলাদা করুন
LSEG টিক ইতিহাস – PCAP ডেটাসেট পাওয়া যায় AWS ডেটা এক্সচেঞ্জ এবং অ্যাক্সেস করা যেতে পারে AWS মার্কেটপ্লেস। সঙ্গে Amazon S3 এর জন্য AWS ডেটা এক্সচেঞ্জ, আপনি সরাসরি LSEG-এর থেকে PCAP ডেটা অ্যাক্সেস করতে পারেন আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) বালতি, তথ্যের নিজস্ব কপি সংরক্ষণ করার জন্য সংস্থাগুলির প্রয়োজনীয়তা দূর করে। এই পদ্ধতিটি ডেটা ম্যানেজমেন্ট এবং স্টোরেজকে স্ট্রীমলাইন করে, ক্লায়েন্টদের তাৎক্ষণিকভাবে উচ্চ-মানের PCAP বা স্বাভাবিক ডেটা ব্যবহারের সুবিধা, একীকরণ এবং সহজে অ্যাক্সেস প্রদান করে। যথেষ্ট তথ্য সঞ্চয় সঞ্চয়.
অ্যাপাচি স্পার্কের জন্য এথেনা
বিশ্লেষণাত্মক প্রচেষ্টার জন্য, অ্যাপাচি স্পার্কের জন্য এথেনা Athena কনসোল বা Athena API-এর মাধ্যমে অ্যাক্সেসযোগ্য একটি সরলীকৃত নোটবুক অভিজ্ঞতা অফার করে, যা আপনাকে ইন্টারেক্টিভ অ্যাপাচি স্পার্ক অ্যাপ্লিকেশন তৈরি করতে দেয়। একটি অপ্টিমাইজড স্পার্ক রানটাইম সহ, অ্যাথেনা গতিশীলভাবে স্পার্ক ইঞ্জিনের সংখ্যা এক সেকেন্ডেরও কম স্কেল করে পেটাবাইট ডেটা বিশ্লেষণে সহায়তা করে৷ তাছাড়া, সাধারণ পাইথন লাইব্রেরি যেমন পান্ডা এবং NumPy নির্বিঘ্নে একত্রিত করা হয়েছে, যা জটিল অ্যাপ্লিকেশন লজিক তৈরির অনুমতি দেয়। নমনীয়তা নোটবুকে ব্যবহারের জন্য কাস্টম লাইব্রেরি আমদানি পর্যন্ত প্রসারিত। স্পার্কের জন্য এথেনা বেশিরভাগ ওপেন-ডেটা ফর্ম্যাটগুলিকে মিটমাট করে এবং এর সাথে নির্বিঘ্নে একত্রিত হয় এডাব্লুএস আঠালো ডেটা ক্যাটালগ।
ডেটা সেটটি
এই বিশ্লেষণের জন্য, আমরা 17 মে, 2023 থেকে LSEG টিক ইতিহাস – PCAP OPRA ডেটাসেট ব্যবহার করেছি৷ এই ডেটাসেটে নিম্নলিখিত উপাদানগুলি রয়েছে:
- সেরা বিড এবং অফার (BBO) - প্রদত্ত এক্সচেঞ্জে সর্বোচ্চ বিড এবং সর্বনিম্ন নিরাপত্তার জন্য অনুরোধ জানায়
- জাতীয় সেরা বিড এবং অফার (NBBO) - সমস্ত এক্সচেঞ্জ জুড়ে সর্বোচ্চ বিড এবং সর্বনিম্ন নিরাপত্তার জন্য অনুরোধ জানায়
- ট্রেডস - সমস্ত এক্সচেঞ্জ জুড়ে রেকর্ড সম্পন্ন ট্রেড
ডেটাসেটে নিম্নলিখিত ডেটা ভলিউম রয়েছে:
- ট্রেডস - প্রায় 160টি সংকুচিত Parquet ফাইল জুড়ে 60 MB বিতরণ করা হয়েছে
- BBO - 2.4 টিবি প্রায় 300টি সংকুচিত Parquet ফাইল জুড়ে বিতরণ করা হয়েছে
- NBBO - 2.8 টিবি প্রায় 200টি সংকুচিত Parquet ফাইল জুড়ে বিতরণ করা হয়েছে
বিশ্লেষণ ওভারভিউ
লেনদেন খরচ বিশ্লেষণ (TCA) এর জন্য OPRA টিক হিস্ট্রি ডেটা বিশ্লেষণ করার জন্য একটি নির্দিষ্ট ট্রেড ইভেন্টের আশেপাশে বাজারের উদ্ধৃতি এবং ট্রেডগুলি যাচাই করা জড়িত। আমরা এই গবেষণার অংশ হিসাবে নিম্নলিখিত মেট্রিক্স ব্যবহার করি:
- উদ্ধৃত স্প্রেড (QS) - BBO জিজ্ঞাসা এবং BBO বিডের মধ্যে পার্থক্য হিসাবে গণনা করা হয়
- কার্যকরী স্প্রেড (ES) - ট্রেড মূল্য এবং BBO এর মধ্যবিন্দুর মধ্যে পার্থক্য হিসাবে গণনা করা হয় (BBO বিড + (BBO জিজ্ঞাসা - BBO বিড)/2)
- কার্যকর/উদ্ধৃত স্প্রেড (EQF) – হিসাবে গণনা করা হয়েছে (ES / QS) * 100
আমরা ট্রেডের আগে এই স্প্রেডগুলি গণনা করি এবং ট্রেডের পরে চারটি ব্যবধানে (শুধুমাত্র, 1 সেকেন্ড, 10 সেকেন্ড, এবং 60 সেকেন্ড ট্রেডের পরে)।
Apache Spark এর জন্য Athena কনফিগার করুন
Apache Spark এর জন্য Athena কনফিগার করতে, নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- এথেনা কনসোলে, নীচে এবার শুরু করা যাক, নির্বাচন করুন PySpark এবং Spark SQL ব্যবহার করে আপনার ডেটা বিশ্লেষণ করুন.
- যদি এটি আপনার প্রথমবার অ্যাথেনা স্পার্ক ব্যবহার করে থাকে তবে বেছে নিন ওয়ার্কগ্রুপ তৈরি করুন.

- জন্য ওয়ার্কগ্রুপের নামওয়ার্কগ্রুপের জন্য একটি নাম লিখুন, যেমন
tca-analysis. - মধ্যে বিশ্লেষণ ইঞ্জিন অধ্যায়, নির্বাচন করুন আপা স্পার্ক.
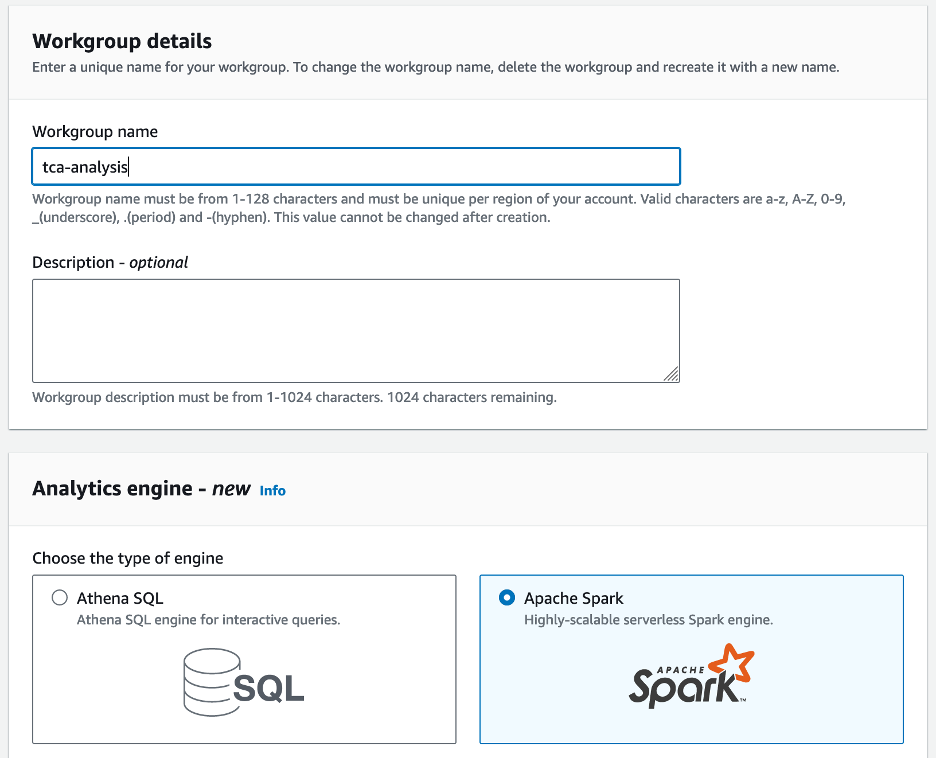
- মধ্যে অতিরিক্ত কনফিগারেশন বিভাগ, আপনি চয়ন করতে পারেন ডিফল্ট ব্যবহার করুন অথবা একটি কাস্টম প্রদান এডাব্লুএস আইডেন্টিটি এবং অ্যাক্সেস ম্যানেজমেন্ট (IAM) ভূমিকা এবং গণনার ফলাফলের জন্য Amazon S3 অবস্থান।
- বেছে নিন ওয়ার্কগ্রুপ তৈরি করুন.
- আপনি ওয়ার্কগ্রুপ তৈরি করার পরে, নেভিগেট করুন নোটবুক ট্যাব এবং চয়ন করুন নোটবুক তৈরি করুন.
- আপনার নোটবুকের জন্য একটি নাম লিখুন, যেমন
tca-analysis-with-tick-history. - বেছে নিন সৃষ্টি আপনার নোটবুক তৈরি করতে।
আপনার নোটবুক চালু করুন
আপনি ইতিমধ্যে একটি স্পার্ক ওয়ার্কগ্রুপ তৈরি করে থাকলে, নির্বাচন করুন নোটবুক সম্পাদক চালু করুন অধীনে এবার শুরু করা যাক.
![]()
আপনার নোটবুক তৈরি হওয়ার পরে, আপনাকে ইন্টারেক্টিভ নোটবুক সম্পাদকে পুনঃনির্দেশিত করা হবে।
![]()
এখন আমরা আমাদের নোটবুকে নিম্নলিখিত কোড যোগ করতে এবং চালাতে পারি।
একটি বিশ্লেষণ তৈরি করুন
একটি বিশ্লেষণ তৈরি করতে নিম্নলিখিত পদক্ষেপগুলি সম্পূর্ণ করুন:
- সাধারণ লাইব্রেরি আমদানি করুন:
- BBO, NBBO, এবং ট্রেডের জন্য আমাদের ডেটা ফ্রেম তৈরি করুন:
- এখন আমরা লেনদেন খরচ বিশ্লেষণের জন্য ব্যবহার করার জন্য একটি ট্রেড সনাক্ত করতে পারি:
আমরা নিম্নলিখিত আউটপুট পেতে:
আমরা ট্রেড প্রোডাক্ট (tp), ট্রেড প্রাইস (tpr), এবং ট্রেড টাইম (tt) এর জন্য হাইলাইট করা ট্রেড তথ্য ব্যবহার করি।
- এখানে আমরা আমাদের বিশ্লেষণের জন্য বেশ কয়েকটি সহায়ক ফাংশন তৈরি করি
- নিম্নলিখিত ফাংশনে, আমরা একটি ডেটাসেট তৈরি করি যাতে ট্রেডের আগে এবং পরে সমস্ত উদ্ধৃতি থাকে। Athena Spark স্বয়ংক্রিয়ভাবে নির্ধারণ করে যে আমাদের ডেটাসেট প্রক্রিয়াকরণের জন্য কতগুলি DPU চালু করতে হবে।
- এখন আমাদের নির্বাচিত ট্রেড থেকে তথ্য সহ TCA বিশ্লেষণ ফাংশন কল করা যাক:
বিশ্লেষণ ফলাফল কল্পনা করুন
এখন আমরা আমাদের ভিজ্যুয়ালাইজেশনের জন্য যে ডেটা ফ্রেমগুলি ব্যবহার করি তা তৈরি করা যাক। প্রতিটি ডেটা ফ্রেমে প্রতিটি ডেটা ফিডের (BBO, NBBO) জন্য পাঁচটি সময়ের ব্যবধানের একটির জন্য উদ্ধৃতি রয়েছে:
নিম্নলিখিত বিভাগে, আমরা বিভিন্ন ভিজ্যুয়ালাইজেশন তৈরি করার জন্য উদাহরণ কোড প্রদান করি।
ব্যবসার আগে প্লট QS এবং NBBO
ট্রেড করার আগে উদ্ধৃত স্প্রেড এবং NBBO প্লট করতে নিম্নলিখিত কোড ব্যবহার করুন:
![]()
প্রতিটি বাজারের জন্য প্লট QS এবং বাণিজ্যের পরে NBBO
ট্রেডের পরপরই প্রতিটি বাজার এবং NBBO-এর জন্য উদ্ধৃত স্প্রেড প্লট করতে নিম্নলিখিত কোড ব্যবহার করুন:
![]()
প্রতিটি সময়ের ব্যবধান এবং BBO এর জন্য প্রতিটি বাজারের জন্য QS প্লট করুন
প্রতিটি সময়ের ব্যবধান এবং BBO-এর জন্য প্রতিটি বাজারের জন্য উদ্ধৃত স্প্রেড প্লট করতে নিম্নলিখিত কোডটি ব্যবহার করুন:
![]()
প্রতিটি সময়ের ব্যবধানের জন্য প্লট ES এবং BBO-এর জন্য বাজার
BBO-এর জন্য প্রতিটি সময়ের ব্যবধান এবং বাজারের জন্য কার্যকর স্প্রেড প্লট করতে নিম্নলিখিত কোড ব্যবহার করুন:
প্রতিটি সময়ের ব্যবধানের জন্য EQF প্লট করুন এবং BBO-এর জন্য বাজার করুন
BBO এর জন্য প্রতিটি সময়ের ব্যবধান এবং বাজারের জন্য কার্যকর/উদ্ধৃত স্প্রেড প্লট করতে নিম্নলিখিত কোড ব্যবহার করুন:
এথেনা স্পার্ক গণনা কর্মক্ষমতা
আপনি যখন একটি কোড ব্লক চালান, তখন Athena Spark স্বয়ংক্রিয়ভাবে নির্ধারণ করে যে গণনাটি সম্পূর্ণ করার জন্য কতগুলি DPU লাগবে। শেষ কোড ব্লক, যেখানে আমরা কল tca_analysis ফাংশন, আমরা আসলে ডাটা প্রক্রিয়া করার জন্য স্পার্ককে নির্দেশ দিচ্ছি, এবং তারপরে আমরা ফলস্বরূপ স্পার্ক ডেটাফ্রেমগুলিকে পান্ডাস ডেটাফ্রেমে রূপান্তর করি। এটি বিশ্লেষণের সবচেয়ে নিবিড় প্রক্রিয়াকরণ অংশ গঠন করে, এবং যখন এথেনা স্পার্ক এই ব্লকটি চালায়, তখন এটি অগ্রগতি বার, অতিবাহিত সময় এবং বর্তমানে কতগুলি ডিপিইউ ডেটা প্রক্রিয়া করছে তা দেখায়। উদাহরণস্বরূপ, নিম্নলিখিত গণনায়, এথেনা স্পার্ক 18টি ডিপিইউ ব্যবহার করছে।
![]()
আপনি যখন আপনার Athena Spark নোটবুক কনফিগার করেন, তখন আপনার কাছে এটি ব্যবহার করতে পারে এমন সর্বোচ্চ সংখ্যক DPU সেট করার বিকল্প থাকে। ডিফল্ট হল 20টি ডিপিইউ, কিন্তু আমরা 10, 20 এবং 40টি ডিপিইউ দিয়ে এই গণনাটি পরীক্ষা করেছি যে কীভাবে এথেনা স্পার্ক স্বয়ংক্রিয়ভাবে আমাদের বিশ্লেষণ চালানোর জন্য স্কেল করে। আমরা লক্ষ্য করেছি যে অ্যাথেনা স্পার্ক রৈখিকভাবে স্কেল করে, যখন নোটবুকটি সর্বাধিক 15টি ডিপিইউ দিয়ে কনফিগার করা হয়েছিল তখন 21 মিনিট এবং 10 সেকেন্ড সময় নেয়, যখন নোটবুকটি 8টি ডিপিইউ দিয়ে কনফিগার করা হয়েছিল তখন 23 মিনিট এবং 20 সেকেন্ড এবং নোটবুকটি যখন 4 মিনিট এবং 44 সেকেন্ড ছিল। 40 ডিপিইউ দিয়ে কনফিগার করা হয়েছে। কারণ এথেনা স্পার্ক DPU ব্যবহারের উপর ভিত্তি করে চার্জ করে, প্রতি-সেকেন্ড গ্রানুলারিটিতে, এই গণনার খরচ একই রকম, কিন্তু আপনি যদি একটি উচ্চতর সর্বোচ্চ DPU মান সেট করেন, তাহলে Athena Spark বিশ্লেষণের ফলাফল অনেক দ্রুত ফেরত দিতে পারে। এথেনা স্পার্ক মূল্য সম্পর্কে আরও বিস্তারিত জানার জন্য অনুগ্রহ করে ক্লিক করুন এখানে.
উপসংহার
এই পোস্টে, আমরা দেখিয়েছি কিভাবে আপনি এথেনা স্পার্ক ব্যবহার করে লেনদেনের খরচ বিশ্লেষণ করতে LSEG-এর টিক হিস্টোরি-PCAP থেকে উচ্চ-বিশ্বস্ত OPRA ডেটা ব্যবহার করতে পারেন। সময়মত OPRA ডেটার প্রাপ্যতা, Amazon S3-এর জন্য AWS ডেটা এক্সচেঞ্জের অ্যাক্সেসিবিলিটি উদ্ভাবনের সাথে পরিপূরক, কৌশলগতভাবে সেই সংস্থাগুলির বিশ্লেষণে সময় কমিয়ে দেয় যারা সমালোচনামূলক ট্রেডিং সিদ্ধান্তের জন্য কার্যকরী অন্তর্দৃষ্টি তৈরি করতে চাইছে। OPRA প্রতিদিন প্রায় 7 TB নরমালাইজড Parquet ডেটা তৈরি করে, এবং OPRA ডেটার উপর ভিত্তি করে বিশ্লেষণ প্রদানের জন্য পরিকাঠামো পরিচালনা করা চ্যালেঞ্জিং।
টিক হিস্ট্রির জন্য বৃহৎ-স্কেল ডেটা প্রসেসিং পরিচালনার ক্ষেত্রে এথেনার মাপযোগ্যতা - OPRA ডেটার জন্য PCAP এটিকে AWS-এ দ্রুত এবং মাপযোগ্য বিশ্লেষণ সমাধানের সন্ধানকারী সংস্থাগুলির জন্য একটি বাধ্যতামূলক পছন্দ করে তোলে। এই পোস্টটি AWS ইকোসিস্টেম এবং টিক হিস্ট্রি-PCAP ডেটার মধ্যে নিরবচ্ছিন্ন মিথস্ক্রিয়া দেখায় এবং কীভাবে আর্থিক প্রতিষ্ঠানগুলি সমালোচনামূলক ট্রেডিং এবং বিনিয়োগ কৌশলগুলির জন্য ডেটা-চালিত সিদ্ধান্ত নেওয়ার জন্য এই সমন্বয়ের সুবিধা নিতে পারে।
লেখক সম্পর্কে
![]() প্রমোদ নায়ক LSEG-এ লো লেটেন্সি গ্রুপের পণ্য ব্যবস্থাপনার পরিচালক। প্রমোদের আর্থিক প্রযুক্তি শিল্পে 10 বছরেরও বেশি অভিজ্ঞতা রয়েছে, সফ্টওয়্যার উন্নয়ন, বিশ্লেষণ এবং ডেটা ব্যবস্থাপনার উপর দৃষ্টি নিবদ্ধ করে। প্রমোদ একজন প্রাক্তন সফ্টওয়্যার প্রকৌশলী এবং বাজারের ডেটা এবং পরিমাণগত ট্রেডিং সম্পর্কে উত্সাহী।
প্রমোদ নায়ক LSEG-এ লো লেটেন্সি গ্রুপের পণ্য ব্যবস্থাপনার পরিচালক। প্রমোদের আর্থিক প্রযুক্তি শিল্পে 10 বছরেরও বেশি অভিজ্ঞতা রয়েছে, সফ্টওয়্যার উন্নয়ন, বিশ্লেষণ এবং ডেটা ব্যবস্থাপনার উপর দৃষ্টি নিবদ্ধ করে। প্রমোদ একজন প্রাক্তন সফ্টওয়্যার প্রকৌশলী এবং বাজারের ডেটা এবং পরিমাণগত ট্রেডিং সম্পর্কে উত্সাহী।
![]() লক্ষ্মীকান্ত মাননেম LSEG-এর লো লেটেন্সি গ্রুপের একজন প্রোডাক্ট ম্যানেজার। তিনি কম লেটেন্সি মার্কেট ডেটা ইন্ডাস্ট্রির জন্য ডেটা এবং প্ল্যাটফর্ম পণ্যগুলিতে মনোনিবেশ করেন। লক্ষ্মীকান্ত গ্রাহকদের তাদের বাজারের ডেটা চাহিদার জন্য সবচেয়ে অনুকূল সমাধান তৈরি করতে সাহায্য করে।
লক্ষ্মীকান্ত মাননেম LSEG-এর লো লেটেন্সি গ্রুপের একজন প্রোডাক্ট ম্যানেজার। তিনি কম লেটেন্সি মার্কেট ডেটা ইন্ডাস্ট্রির জন্য ডেটা এবং প্ল্যাটফর্ম পণ্যগুলিতে মনোনিবেশ করেন। লক্ষ্মীকান্ত গ্রাহকদের তাদের বাজারের ডেটা চাহিদার জন্য সবচেয়ে অনুকূল সমাধান তৈরি করতে সাহায্য করে।
![]() বিবেক আগরওয়াল LSEG-এর লো লেটেন্সি গ্রুপের একজন সিনিয়র ডেটা ইঞ্জিনিয়ার। বিবেক ক্যাপচার করা বাজারের ডেটা ফিড এবং রেফারেন্স ডেটা ফিডগুলির প্রক্রিয়াকরণ এবং বিতরণের জন্য ডেটা পাইপলাইনগুলি বিকাশ এবং বজায় রাখার বিষয়ে কাজ করে।
বিবেক আগরওয়াল LSEG-এর লো লেটেন্সি গ্রুপের একজন সিনিয়র ডেটা ইঞ্জিনিয়ার। বিবেক ক্যাপচার করা বাজারের ডেটা ফিড এবং রেফারেন্স ডেটা ফিডগুলির প্রক্রিয়াকরণ এবং বিতরণের জন্য ডেটা পাইপলাইনগুলি বিকাশ এবং বজায় রাখার বিষয়ে কাজ করে।
![]() আলকেত মেমুশাজ AWS-এ আর্থিক পরিষেবা বাজার উন্নয়ন দলের একজন প্রধান স্থপতি। Alket প্রযুক্তিগত কৌশলের জন্য দায়ী, অংশীদার এবং গ্রাহকদের সাথে কাজ করে এমনকি সবচেয়ে বেশি চাহিদাপূর্ণ পুঁজিবাজারের কাজের চাপগুলি AWS ক্লাউডে স্থাপন করতে।
আলকেত মেমুশাজ AWS-এ আর্থিক পরিষেবা বাজার উন্নয়ন দলের একজন প্রধান স্থপতি। Alket প্রযুক্তিগত কৌশলের জন্য দায়ী, অংশীদার এবং গ্রাহকদের সাথে কাজ করে এমনকি সবচেয়ে বেশি চাহিদাপূর্ণ পুঁজিবাজারের কাজের চাপগুলি AWS ক্লাউডে স্থাপন করতে।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- : আছে
- : হয়
- :না
- :কোথায়
- $ ইউপি
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- সম্পর্কে
- প্রবেশ
- অ্যাক্সেসড
- অভিগম্যতা
- প্রবেশযোগ্য
- দিয়ে
- সক্রিয়
- কার্যকলাপ
- আসল
- প্রকৃতপক্ষে
- যোগ
- উপরন্তু
- সম্ভাষণ
- সুবিধা
- পর
- বিরুদ্ধে
- আগরওয়াল
- লক্ষ্য
- সব
- অনুমতি
- ইতিমধ্যে
- মর্দানী স্ত্রীলোক
- অ্যামাজন অ্যাথেনা
- অ্যামাজন ওয়েব সার্ভিসেস
- an
- বিশ্লেষণ
- বিশ্লেষণ
- বিশ্লেষণাত্মক
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ করা
- বিশ্লেষণ
- এবং
- কোন
- এ্যাপাচি
- আপা স্পার্ক
- API গুলি
- আবেদন
- অ্যাপ্লিকেশন
- প্রয়োগ করা
- অভিগমন
- আন্দাজ
- সালিসি
- সালিসি
- রয়েছি
- কাছাকাছি
- AS
- জিজ্ঞাসা করা
- পরিমাপ করা
- যুক্ত
- At
- বৈশিষ্ট্যাবলী
- কর্তৃত্ব
- স্বয়ংক্রিয়ভাবে
- স্বয়ংক্রিয়তা
- উপস্থিতি
- সহজলভ্য
- ডেস্কটপ AWS
- ব্যাকআপ
- বার
- ভিত্তি
- BE
- কারণ
- আগে
- benchmarks
- সর্বোত্তম
- মধ্যে
- বিদার প্রস্তাব
- বিলিয়ন
- বাধা
- দালাল
- নির্মাণ করা
- কিন্তু
- by
- গণনা করা
- গণিত
- হিসাব
- কল
- CAN
- ধারণক্ষমতা
- রাজধানী
- পুজি বাজার
- গ্রেপ্তার
- আধৃত
- ক্যাপচার
- তালিকা
- সেন্টার
- চ্যালেঞ্জিং
- চ্যানেল
- ঘটায়,
- চার্জ
- পছন্দ
- বেছে নিন
- ক্লায়েন্ট
- মেঘ
- কোড
- সংগ্রহ
- সাধারণ
- বাধ্যকারী
- সম্পূর্ণ
- সম্পন্ন হয়েছে
- উপাদান
- ব্যাপক
- গঠিত
- আচার
- কনফিগার
- কনফিগার করার
- কনসোল
- সংহত
- ধারণ
- চুক্তি
- অবদান
- রূপান্তর
- কর্পোরেশন
- মূল্য
- খরচ
- cowritten
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- সংকটপূর্ণ
- কঠোর
- এখন
- প্রথা
- গ্রাহকদের
- হানাহানি
- উপাত্ত
- তথ্য কেন্দ্র
- ডেটা ইঞ্জিনিয়ার
- তথ্য বিনিময়
- ডাটা ব্যাবস্থাপনা
- তথ্য প্রক্রিয়াজাতকরণ
- তথ্য ভান্ডার
- তথ্য চালিত
- ডেটাসেট
- দিন
- সিদ্ধান্ত মেকিং
- সিদ্ধান্ত
- ডিফল্ট
- নির্ধারণ করা
- বিলি
- চাহিদা
- দাবি
- প্রদর্শন
- প্রদর্শিত
- স্থাপন
- বিস্তারিত
- নির্ধারণ করে
- উন্নয়নশীল
- উন্নয়ন
- উন্নয়ন দল
- পার্থক্য
- বিভিন্ন
- সরাসরি
- Director
- বণ্টিত
- বিতরণ
- বিচিত্র
- ডবল
- ড্রাইভ
- প্রগতিশীল
- পরিবর্তনশীল
- গতিবিদ্যা
- প্রতি
- আরাম
- ব্যবহারে সহজ
- বাস্তু
- সম্পাদক
- কার্যকর
- কার্যকারিতা
- উপযুক্ত
- দূর
- নিযুক্ত
- প্রয়োজক
- সক্ষম করা
- সম্ভব
- encompassing
- প্রচেষ্টা
- ইঞ্জিন
- প্রকৌশলী
- ইঞ্জিন
- বৃদ্ধি
- নিশ্চিত
- প্রবেশ করান
- বেড়ে উঠা
- থার (eth)
- মূল্যায়ন
- মূল্যায়ন
- এমন কি
- ঘটনা
- প্রতি
- উদাহরণ
- বিনিময়
- এক্সচেঞ্জ
- ফাঁসি
- অভিজ্ঞতা
- অন্বেষণ করুণ
- প্রকাশ করা
- প্রসারিত
- দ্রুত
- সমন্বিত
- ফেব্রুয়ারি
- ডুমুর
- নথি পত্র
- পূরণ করা
- ছাঁকনি
- আর্থিক
- আর্থিক প্রতিষ্ঠান সমূহ
- অর্থনৈতিক সেবা সমূহ
- আর্থিক প্রযুক্তি
- সংস্থাগুলো
- প্রথম
- প্রথমবার
- পাঁচ
- নমনীয়তা
- গুরুত্ত্ব
- মনোযোগ
- অনুসরণ
- জন্য
- বিন্যাস
- সাবেক
- অগ্রবর্তী
- চার
- ফ্রেম
- থেকে
- ক্রিয়া
- ক্রিয়াকলাপ
- অধিকতর
- ফাঁক
- উত্পন্ন
- পাওয়া
- প্রদত্ত
- বিশ্বব্যাপী
- বিশ্ব বাজারে
- Go
- চালু
- জিপিএস
- গ্রুপ
- হ্যান্ডলিং
- আছে
- জমিদারি
- he
- কাজে লাগতো
- সাহায্য
- উচ্চ গুনসম্পন্ন
- ঊর্ধ্বতন
- সর্বোচ্চ
- হাইলাইট করা
- ঐতিহাসিক
- ইতিহাস
- হাউজিং
- কিভাবে
- কিভাবে
- HTTP
- HTTPS দ্বারা
- আমি
- সনাক্ত করা
- পরিচয়
- if
- আশু
- অবিলম্বে
- প্রভাব
- আমদানি
- in
- সুদ্ধ
- বর্ধিত
- শিল্প
- তথ্য
- পরিকাঠামো
- প্রবর্তিত
- অর্ন্তদৃষ্টি
- প্রতিষ্ঠান
- অখণ্ড
- সংহত
- ইন্টিগ্রেশন
- মিথষ্ক্রিয়া
- ইন্টারেক্টিভ
- মধ্যে
- জটিল
- বিনিয়োগ
- জড়িত
- IT
- JPG
- মাত্র
- বড়
- বড় আকারের
- গত
- অদৃশ্যতা
- শুরু করা
- কম
- লাইব্রেরি
- লাইন
- তারল্য
- অবস্থান
- যুক্তিবিদ্যা
- খুঁজছি
- কম
- অধম
- বজায় রাখার
- মুখ্য
- তৈরি করে
- মেকিং
- পরিচালনা করা
- ব্যবস্থাপনা
- পরিচালক
- পরিচালকের
- পরিচালক
- পদ্ধতি
- অনেক
- বাজার
- মার্কেটের উপাত্ত
- বাজার প্রভাব
- বাজার গবেষণা
- বাজারের উদ্বায়ীতা
- বাজার তৈরি
- বাজার
- বৃহদায়তন
- নিয়ন্ত্রণ
- সর্বাধিক
- মে..
- মাপ
- বার্তা
- বার্তা
- সাবধানী
- সাবধানে
- ছন্দোবিজ্ঞান
- মিলিয়ন
- কমান
- মিনিট
- পর্যবেক্ষণ
- অধিক
- পরন্তু
- সেতু
- অনেক
- বহু
- নাম
- প্রকৃতি
- নেভিগেট করুন
- প্রয়োজন
- চাহিদা
- না
- নোটবই
- নোটবুক
- সংখ্যা
- অনেক
- অসাড়
- বিলোকিত
- of
- অর্পণ
- অফার
- on
- ONE
- অনুকূল
- অপ্টিমিজ
- অপ্টিমাইজ
- পছন্দ
- অপশন সমূহ
- or
- সংগঠন
- আমাদের
- বাইরে
- আউটপুট
- শেষ
- সামগ্রিক
- নিজের
- পান্ডাস
- অংশ
- অংশীদারদের
- কামুক
- নিদর্শন
- শিখর
- প্রতি
- সম্পাদন করা
- কর্মক্ষমতা
- কেঁদ্রগত
- মাচা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- নাটক
- দয়া করে
- চক্রান্ত
- দফতর
- পোর্টফোলিও পরিচালকরা
- স্থান
- পোস্ট
- পোস্ট ট্রেড
- সম্ভাব্য
- স্পষ্টতা
- প্রস্তুত করা
- প্রস্তুতি
- মূল্য
- মূল্য
- প্রাথমিক
- অধ্যক্ষ
- প্রক্রিয়া
- প্রসেস
- প্রক্রিয়াজাতকরণ
- প্রসেসর
- পণ্য
- পণ্য ব্যবস্থাপনা
- পণ্য ব্যবস্থাপক
- পণ্য
- উন্নতি
- প্রদান
- প্রদানের
- প্রকাশিত
- পাইথন
- Q3
- মাত্রিক
- পরিমাণ
- প্রশ্ন
- কোট
- হার
- হার
- পড়া
- বাস্তব
- প্রকৃত সময়
- সুপারিশ করা
- রেকর্ড
- লাল
- হ্রাস করা
- হ্রাস
- উল্লেখ
- পুনর্নবীকরণ
- প্রতিবেদন
- প্রতিবেদন
- সংগ্রহস্থলের
- প্রয়োজন
- প্রয়োজন
- গবেষণা
- প্রতিক্রিয়া
- দায়ী
- ফল
- ফলে এবং
- ফলাফল
- প্রত্যাবর্তন
- ঝুঁকি
- ভূমিকা
- চালান
- রান
- বিক্রয়
- স্কেলেবিলিটি
- মাপযোগ্য
- দাঁড়িপাল্লা
- আরোহী
- নির্বিঘ্ন
- নির্বিঘ্নে
- দ্বিতীয়
- সেকেন্ড
- অধ্যায়
- বিভাগে
- সিকিউরিটিজ
- নিরাপত্তা
- সচেষ্ট
- নির্বাচন করা
- নির্বাচিত
- জ্যেষ্ঠ
- আলাদা
- স্থল
- সেবা
- সেট
- বিন্যাস
- প্রদর্শনী
- শো
- উল্লেখযোগ্যভাবে
- অনুরূপ
- সহজ
- সরলীকৃত
- একক
- স্লিপেজ
- সফটওয়্যার
- সফটওয়্যার উন্নয়ন
- সফটওয়্যার ইঞ্জিনিয়ার
- সলিউশন
- বাস্তববুদ্ধিসম্পন্ন
- বিস্তৃত
- স্ফুলিঙ্গ
- নির্দিষ্ট
- বিস্তার
- স্প্রেড
- ব্রিদিং
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- স্টোরেজ
- দোকান
- কৌশলগতভাবে
- কৌশল
- কৌশল
- জীবন্ত চ্যাটে
- অধ্যয়ন
- পরবর্তী
- এমন
- স্যুইফ্ট
- প্রতীক
- Synergy
- গ্রহণ করা
- গ্রহণ
- টীম
- কারিগরী
- প্রযুক্তি
- প্রযুক্তিঃ
- প্রমাণিত
- চেয়ে
- যে
- সার্জারির
- তথ্য
- তাদের
- তাহাদিগকে
- তারপর
- এইগুলো
- এই
- দ্বারা
- টিক্ টিক্ শব্দ
- সময়
- সময়োপযোগী
- টাইমস্ট্যাম্প
- শিরনাম
- থেকে
- মোট
- tp
- TPR
- বাণিজ্য
- ব্যবসায়ীরা
- ব্যবসা
- লেনদেন
- ট্রেডিং কৌশল
- ট্রেডিং কৌশল
- লেনদেন
- লেনদেনের খরচ
- রূপান্তর
- রূপান্তর
- সীমাতিক্রান্ত
- অধীনে
- ক্ষয়ের
- আপগ্রেড
- us
- ব্যবহার
- ব্যবহার
- ব্যবহৃত
- ব্যবহারসমূহ
- ব্যবহার
- ব্যবহার
- মূল্য
- বিভিন্ন
- কল্পনা
- ঠাহর করা
- অবিশ্বাস
- আয়তন
- ভলিউম
- ছিল
- we
- ওয়েব
- ওয়েব সার্ভিস
- কখন
- যে
- ব্যাপকভাবে
- ইচ্ছা
- সঙ্গে
- মধ্যে
- ছাড়া
- ওয়ার্কগ্রুপ
- কাজ
- কাজ
- বিশ্বব্যাপী
- চিন্তা
- X
- বছর
- আপনি
- আপনার
- zephyrnet