অ্যামাজন সেজমেকার স্টুডিও তথ্য বিজ্ঞানীদের ইন্টারেক্টিভভাবে মেশিন লার্নিং (ML) মডেল তৈরি, প্রশিক্ষণ এবং স্থাপন করার জন্য একটি সম্পূর্ণরূপে পরিচালিত সমাধান প্রদান করে। অ্যামাজন সেজমেকার নোটবুকের চাকরি ডেটা সায়েন্টিস্টদের সেজমেকার স্টুডিওতে কয়েকটি ক্লিকের মাধ্যমে চাহিদা অনুযায়ী বা সময়সূচীতে তাদের নোটবুক চালানোর অনুমতি দেয়। এই লঞ্চের মাধ্যমে, আপনি প্রদত্ত এপিআই ব্যবহার করে কাজ হিসাবে নোটবুকগুলি প্রোগ্রামে চালাতে পারেন৷ অ্যামাজন সেজমেকার পাইপলাইন, ML ওয়ার্কফ্লো অর্কেস্ট্রেশন বৈশিষ্ট্য আমাজন সেজমেকার. উপরন্তু, আপনি এই APIগুলি ব্যবহার করে একাধিক নির্ভরশীল নোটবুকের সাথে একটি মাল্টি-স্টেপ এমএল ওয়ার্কফ্লো তৈরি করতে পারেন।
SageMaker Pipelines হল ML পাইপলাইন তৈরির জন্য একটি নেটিভ ওয়ার্কফ্লো অর্কেস্ট্রেশন টুল যা সরাসরি SageMaker ইন্টিগ্রেশনের সুবিধা নেয়। প্রতিটি SageMaker পাইপলাইন গঠিত হয় ধাপ, যা প্রক্রিয়াকরণ, প্রশিক্ষণ, বা ডেটা প্রসেসিং ব্যবহার করার মতো পৃথক কাজের সাথে সামঞ্জস্যপূর্ণ আমাজন ইএমআর. SageMaker নোটবুকের কাজগুলি এখন সেজমেকার পাইপলাইনে অন্তর্নির্মিত ধাপের ধরন হিসাবে উপলব্ধ। আপনি এই নোটবুক কাজের ধাপটি ব্যবহার করে সহজে কয়েক লাইনের কোড সহ নোটবুকগুলিকে কাজ হিসাবে চালাতে পারেন অ্যামাজন সেজমেকার পাইথন এসডিকে. উপরন্তু, আপনি নির্দেশিত অ্যাসাইক্লিক গ্রাফ (DAGs) আকারে একটি ওয়ার্কফ্লো তৈরি করতে একাধিক নির্ভরশীল নোটবুক একসাথে সেলাই করতে পারেন। তারপরে আপনি এই নোটবুকের কাজগুলি বা DAGগুলি চালাতে পারেন এবং সেজমেকার স্টুডিও ব্যবহার করে সেগুলি পরিচালনা এবং কল্পনা করতে পারেন৷
ডেটা বিজ্ঞানীরা বর্তমানে সেজমেকার স্টুডিও ব্যবহার করে ইন্টারেক্টিভভাবে তাদের জুপিটার নোটবুকগুলি বিকাশ করে এবং তারপরে এই নোটবুকগুলিকে নির্ধারিত কাজ হিসাবে চালানোর জন্য সেজমেকার নোটবুক কাজগুলি ব্যবহার করে৷ পাইথন মডিউল হিসাবে রিফ্যাক্টর কোডে ডেটা কর্মীদের প্রয়োজন ছাড়াই এই কাজগুলি অবিলম্বে বা পুনরাবৃত্ত সময়সূচীতে চালানো যেতে পারে। এটি করার জন্য কিছু সাধারণ ব্যবহারের ক্ষেত্রে অন্তর্ভুক্ত:
- ব্যাকগ্রাউন্ডে লম্বা চলমান-নোটবুক চলছে
- রিপোর্ট তৈরি করতে নিয়মিতভাবে মডেল ইনফারেন্স চলছে
- ছোট নমুনা ডেটাসেট তৈরি করা থেকে শুরু করে পেটাবাইট-স্কেল বড় ডেটা নিয়ে কাজ করা পর্যন্ত স্কেল করা
- কিছু ক্যাডেন্সে মডেলদের পুনরায় প্রশিক্ষণ এবং স্থাপন করা
- মডেলের গুণমান বা ডেটা ড্রিফ্ট নিরীক্ষণের জন্য কাজের সময় নির্ধারণ করা
- ভালো মডেলের জন্য পরামিতি স্থান অন্বেষণ
যদিও এই কার্যকারিতা ডেটা কর্মীদের জন্য স্বয়ংক্রিয়ভাবে স্বয়ংক্রিয় নোটবুকগুলিকে সহজ করে তোলে, এমএল ওয়ার্কফ্লোগুলি প্রায়শই বেশ কয়েকটি নোটবুকের সমন্বয়ে গঠিত, প্রতিটি জটিল নির্ভরতা সহ একটি নির্দিষ্ট কাজ সম্পাদন করে। উদাহরণ স্বরূপ, মডেল ডেটা ড্রিফ্টের জন্য নিরীক্ষণকারী একটি নোটবুকে একটি প্রাক-পদক্ষেপ থাকা উচিত যা এক্সট্র্যাক্ট, ট্রান্সফর্ম এবং লোড (ETL) এবং নতুন ডেটা প্রক্রিয়াকরণ এবং উল্লেখযোগ্য ড্রিফ্ট লক্ষ্য করা গেলে মডেল রিফ্রেশ এবং প্রশিক্ষণের একটি পোস্ট-স্টেপ মঞ্জুরি দেয়। . তদ্ব্যতীত, ডেটা বিজ্ঞানীরা নতুন ডেটার উপর ভিত্তি করে মডেল আপডেট করার জন্য একটি পুনরাবৃত্ত সময়সূচীতে এই সম্পূর্ণ ওয়ার্কফ্লোটিকে ট্রিগার করতে চাইতে পারেন। আপনি সহজেই আপনার নোটবুকগুলিকে স্বয়ংক্রিয় করতে এবং এই ধরনের জটিল ওয়ার্কফ্লো তৈরি করতে সক্ষম করতে, সেজমেকার নোটবুক কাজগুলি এখন সেজমেকার পাইপলাইনে একটি পদক্ষেপ হিসাবে উপলব্ধ। এই পোস্টে, আমরা দেখাই কিভাবে আপনি কোডের কয়েকটি লাইন দিয়ে নিম্নলিখিত ব্যবহারের ক্ষেত্রে সমাধান করতে পারেন:
- প্রোগ্রামগতভাবে অবিলম্বে বা একটি পুনরাবৃত্ত সময়সূচীতে একটি স্বতন্ত্র নোটবুক চালান
- ক্রমাগত ইন্টিগ্রেশন এবং ক্রমাগত ডেলিভারি (CI/CD) উদ্দেশ্যে DAG হিসাবে নোটবুকের মাল্টি-স্টেপ ওয়ার্কফ্লো তৈরি করুন যা SageMaker Studio UI এর মাধ্যমে পরিচালনা করা যেতে পারে
সমাধান ওভারভিউ
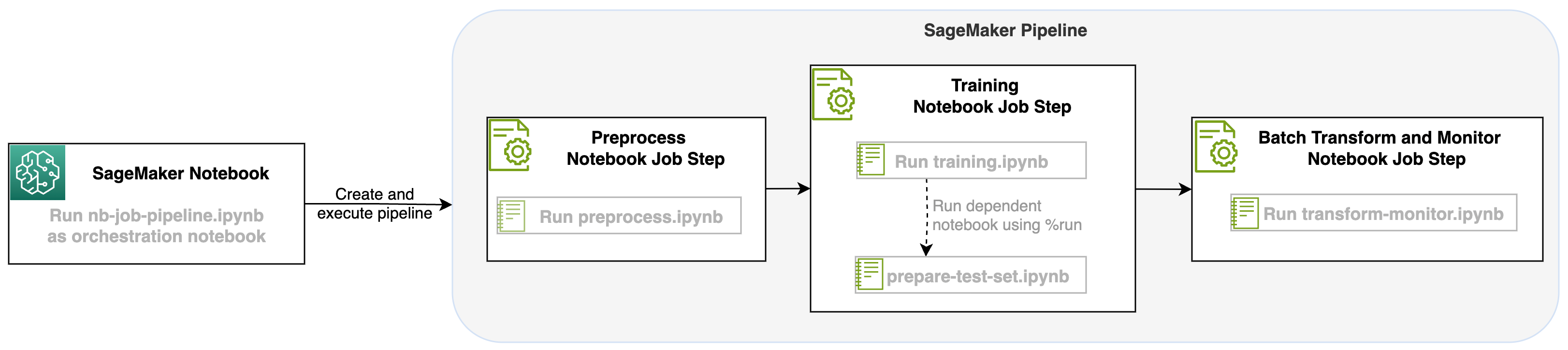
নিম্নলিখিত চিত্রটি আমাদের সমাধানের স্থাপত্যকে চিত্রিত করে। আপনি একটি একক নোটবুক কাজ বা একটি ওয়ার্কফ্লো চালানোর জন্য SageMaker Python SDK ব্যবহার করতে পারেন। এই বৈশিষ্ট্যটি নোটবুক চালানোর জন্য একটি সেজমেকার প্রশিক্ষণের কাজ তৈরি করে।
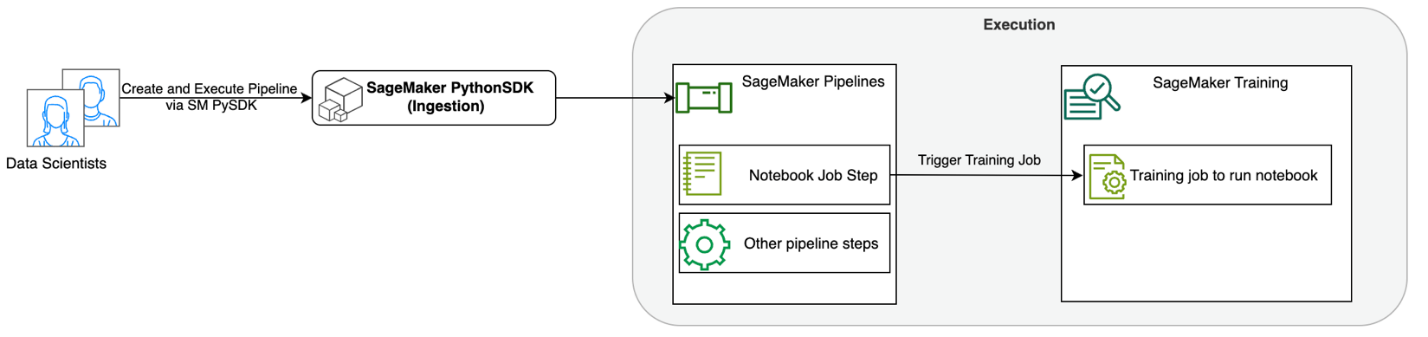
নিম্নলিখিত বিভাগে, আমরা একটি নমুনা ML ব্যবহারের ক্ষেত্রে এবং নোটবুক কাজের একটি ওয়ার্কফ্লো তৈরি করার পদক্ষেপগুলি প্রদর্শন করি, নোটবুকের বিভিন্ন ধাপের মধ্যে পরামিতিগুলি পাস করা, আপনার কর্মপ্রবাহের সময় নির্ধারণ করা এবং সেজমেকার স্টুডিওর মাধ্যমে এটি পর্যবেক্ষণ করা।
এই উদাহরণে আমাদের এমএল সমস্যার জন্য, আমরা একটি অনুভূতি বিশ্লেষণ মডেল তৈরি করছি, যা এক ধরনের পাঠ্য শ্রেণিবিন্যাস টাস্ক। অনুভূতি বিশ্লেষণের সবচেয়ে সাধারণ অ্যাপ্লিকেশনগুলির মধ্যে রয়েছে সোশ্যাল মিডিয়া মনিটরিং, গ্রাহক সহায়তা ব্যবস্থাপনা এবং গ্রাহক প্রতিক্রিয়া বিশ্লেষণ করা। এই উদাহরণে যে ডেটাসেটটি ব্যবহার করা হচ্ছে তা হল স্ট্যানফোর্ড সেন্টিমেন্ট ট্রিব্যাঙ্ক (SST2) ডেটাসেট, যেটিতে একটি পূর্ণসংখ্যা (0 বা 1) সহ মুভি পর্যালোচনা রয়েছে যা পর্যালোচনার ইতিবাচক বা নেতিবাচক অনুভূতি নির্দেশ করে।
নিম্নলিখিত একটি উদাহরণ data.csv ফাইল SST2 ডেটাসেটের সাথে সম্পর্কিত, এবং এর প্রথম দুটি কলামে মান দেখায়। নোট করুন যে ফাইলের কোনো হেডার থাকা উচিত নয়।
| কলাম 1 | কলাম 2 |
| 0 | প্যারেন্টাল ইউনিট থেকে নতুন নিঃসরণ লুকান |
| 0 | কোন বুদ্ধি নেই, শুধুমাত্র পরিশ্রমী গাগ |
| 1 | যে তার অক্ষর ভালবাসে এবং মানুষের প্রকৃতি সম্পর্কে বরং সুন্দর কিছু যোগাযোগ |
| 0 | সর্বত্র একই থাকতে সম্পূর্ণরূপে সন্তুষ্ট থাকে |
| 0 | সবচেয়ে খারাপ প্রতিশোধ-অফ-দ্য-নার্ডস ক্লিচের উপর চলচ্চিত্র নির্মাতারা ড্রেজিং করতে পারে |
| 0 | এটি এতটা দুঃখজনক যে এই ধরনের সুপারফিশিয়াল চিকিত্সার যোগ্যতা অর্জন করা যায় না |
| 1 | প্রদর্শন করে যে দেশপ্রেমিক গেমের মতো হলিউড ব্লকবাস্টারের পরিচালক এখনও একটি আবেগপূর্ণ ওয়ালপ সহ একটি ছোট, ব্যক্তিগত চলচ্চিত্র তৈরি করতে পারেন। |
এই এমএল উদাহরণে, আমাদের অবশ্যই বেশ কয়েকটি কাজ সম্পাদন করতে হবে:
- আমাদের মডেল বুঝতে পারে এমন বিন্যাসে এই ডেটাসেটটি প্রস্তুত করতে বৈশিষ্ট্য প্রকৌশল সম্পাদন করুন।
- পোস্ট-ফিচার ইঞ্জিনিয়ারিং, একটি প্রশিক্ষণ ধাপ চালান যা ট্রান্সফরমার ব্যবহার করে।
- সূক্ষ্ম-টিউন করা মডেলের সাথে ব্যাচ অনুমান সেট আপ করুন যাতে নতুন রিভিউ আসার অনুভূতির পূর্বাভাস দেওয়া যায়।
- একটি ডেটা মনিটরিং ধাপ সেট আপ করুন যাতে আমরা নিয়মিতভাবে আমাদের নতুন ডেটা নিরীক্ষণ করতে পারি গুণমানের যে কোনও প্রবাহের জন্য যার জন্য আমাদের মডেল ওজন পুনরায় প্রশিক্ষণের প্রয়োজন হতে পারে।
সেজমেকার পাইপলাইনে একটি পদক্ষেপ হিসাবে একটি নোটবুকের কাজ চালু করার সাথে, আমরা এই ওয়ার্কফ্লোকে সাজাতে পারি, যা তিনটি স্বতন্ত্র পদক্ষেপ নিয়ে গঠিত। কর্মপ্রবাহের প্রতিটি ধাপ একটি ভিন্ন নোটবুকে বিকশিত হয়, যা পরে স্বাধীন নোটবুকের কাজের ধাপে রূপান্তরিত হয় এবং একটি পাইপলাইন হিসাবে সংযুক্ত হয়:
- প্রাক প্রসেসিং – থেকে পাবলিক SST2 ডেটাসেট ডাউনলোড করুন আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) এবং চালানোর জন্য ধাপ 2-এ নোটবুকের জন্য একটি CSV ফাইল তৈরি করুন। SST2 ডেটাসেট হল দুটি লেবেল (0 এবং 1) এবং শ্রেণিবদ্ধ করার জন্য পাঠ্যের একটি কলাম সহ একটি পাঠ্য শ্রেণিবিন্যাসের ডেটাসেট।
- প্রশিক্ষণ - আকৃতির CSV ফাইল নিন এবং ট্রান্সফরমার লাইব্রেরি ব্যবহার করে পাঠ্য শ্রেণিবিন্যাসের জন্য BERT-এর সাথে ফাইন-টিউনিং চালান। আমরা এই ধাপের অংশ হিসাবে একটি পরীক্ষার ডেটা প্রস্তুতি নোটবুক ব্যবহার করি, যা ফাইন-টিউনিং এবং ব্যাচ ইনফারেন্স ধাপের জন্য নির্ভরতা। ফাইন-টিউনিং সম্পূর্ণ হলে, এই নোটবুকটি রান ম্যাজিক ব্যবহার করে চালানো হয় এবং সূক্ষ্ম-টিউন করা মডেলের সাথে নমুনা অনুমানের জন্য একটি পরীক্ষার ডেটাসেট প্রস্তুত করে।
- রূপান্তর এবং নিরীক্ষণ - একটি বেসলাইন ডেটাসেট সাজেশন পেতে ব্যাচ ইনফারেন্স সম্পাদন করুন এবং মডেল মনিটরিং সহ ডেটা গুণমান সেট আপ করুন।
নোটবুক চালান
এই সমাধানের জন্য নমুনা কোড পাওয়া যায় GitHub.
একটি সেজমেকার নোটবুক কাজের ধাপ তৈরি করা অন্যান্য সেজমেকার পাইপলাইন পদক্ষেপ তৈরি করার মতো। এই নোটবুকের উদাহরণে, আমরা ওয়ার্কফ্লো সাজানোর জন্য SageMaker Python SDK ব্যবহার করি। সেজমেকার পাইপলাইনে একটি নোটবুক ধাপ তৈরি করতে, আপনি নিম্নলিখিত পরামিতিগুলি সংজ্ঞায়িত করতে পারেন:
- ইনপুট নোটবুক - নোটবুকের নাম যে এই নোটবুক পদক্ষেপ অর্কেস্ট্রেটিং হবে। এখানে আপনি ইনপুট নোটবুকের স্থানীয় পথে যেতে পারেন। ঐচ্ছিকভাবে, যদি এই নোটবুকটিতে অন্যান্য নোটবুক থাকে তবে এটি চলমান, আপনি এগুলি পাস করতে পারেন৷
AdditionalDependenciesনোটবুক কাজের ধাপের জন্য পরামিতি। - ছবি URI - নোটবুক কাজের ধাপের পিছনে ডকার ইমেজ। এটি পূর্বনির্ধারিত চিত্র হতে পারে যা সেজমেকার ইতিমধ্যেই প্রদান করেছে বা একটি কাস্টম চিত্র যা আপনি সংজ্ঞায়িত করেছেন এবং পুশ করেছেন অ্যামাজন ইলাস্টিক কনটেইনার রেজিস্ট্রি (আমাজন ইসিআর)। সমর্থিত চিত্রগুলির জন্য এই পোস্টের শেষে বিবেচনার বিভাগটি পড়ুন।
- কার্নেলের নাম - কার্নেলের নাম যা আপনি সেজমেকার স্টুডিওতে ব্যবহার করছেন। এই কার্নেল বৈশিষ্ট্যটি আপনার দেওয়া ছবিতে নিবন্ধিত।
- উদাহরণ টাইপ (ঐচ্ছিক) - দ্য অ্যামাজন ইলাস্টিক কম্পিউট ক্লাউড (Amazon EC2) নোটবুক কাজের পিছনে উদাহরণ টাইপ যা আপনি সংজ্ঞায়িত করেছেন এবং চলবে।
- পরামিতি (ঐচ্ছিক) - আপনি যে প্যারামিটারগুলি পাস করতে পারেন তা আপনার নোটবুকের জন্য অ্যাক্সেসযোগ্য হবে৷ এগুলি কী-মান জোড়ায় সংজ্ঞায়িত করা যেতে পারে। উপরন্তু, এই পরামিতি বিভিন্ন নোটবুক কাজ রান বা পাইপলাইন রান মধ্যে পরিবর্তন করা যেতে পারে.
আমাদের উদাহরণে মোট পাঁচটি নোটবুক রয়েছে:
- nb-job-pipeline.ipynb - এটি আমাদের প্রধান নোটবুক যেখানে আমরা আমাদের পাইপলাইন এবং কর্মপ্রবাহকে সংজ্ঞায়িত করি।
- preprocess.ipynb – এই নোটবুকটি আমাদের কর্মপ্রবাহের প্রথম ধাপ এবং এতে এমন কোড রয়েছে যা সর্বজনীন AWS ডেটাসেটকে টেনে আনবে এবং এটি থেকে একটি CSV ফাইল তৈরি করবে৷
- training.ipynb - এই নোটবুকটি আমাদের কর্মপ্রবাহের দ্বিতীয় ধাপ এবং এতে পূর্ববর্তী ধাপ থেকে CSV নেওয়ার এবং স্থানীয় প্রশিক্ষণ এবং সূক্ষ্ম-টিউনিং পরিচালনা করার কোড রয়েছে৷ এই পদক্ষেপ থেকে একটি নির্ভরতা আছে
prepare-test-set.ipynbসূক্ষ্ম-টিউনড মডেলের সাথে নমুনা অনুমানের জন্য একটি পরীক্ষার ডেটাসেট টানতে নোটবুক। - প্রস্তুত-পরীক্ষা-set.ipynb – এই নোটবুকটি একটি পরীক্ষার ডেটাসেট তৈরি করে যা আমাদের প্রশিক্ষণ নোটবুক দ্বিতীয় পাইপলাইন ধাপে ব্যবহার করবে এবং সূক্ষ্ম-টিউনড মডেলের সাথে নমুনা অনুমানের জন্য ব্যবহার করবে।
- transform-monitor.ipynb – এই নোটবুকটি আমাদের কর্মপ্রবাহের তৃতীয় ধাপ এবং বেস BERT মডেল গ্রহণ করে এবং একটি SageMaker ব্যাচ ট্রান্সফর্ম কাজ চালায়, পাশাপাশি মডেল পর্যবেক্ষণের সাথে ডেটার গুণমান সেট আপ করে৷
এর পরে, আমরা প্রধান নোটবুকের মধ্য দিয়ে হেঁটে যাই nb-job-pipeline.ipynb, যা একটি পাইপলাইনে সমস্ত সাব-নোটবুককে একত্রিত করে এবং এন্ড-টু-এন্ড ওয়ার্কফ্লো চালায়। উল্লেখ্য যে যদিও নিম্নলিখিত উদাহরণটি নোটবুকটি শুধুমাত্র একবার চালায়, আপনি নোটবুকটি বারবার চালানোর জন্য পাইপলাইন নির্ধারণ করতে পারেন। নির্দেশ করে সেজমেকার ডকুমেন্টেশন বিস্তারিত নির্দেশাবলীর জন্য
আমাদের প্রথম নোটবুক কাজের ধাপের জন্য, আমরা একটি ডিফল্ট S3 বালতি সহ একটি প্যারামিটারে পাস করি। আমরা আমাদের অন্যান্য পাইপলাইন পদক্ষেপের জন্য উপলব্ধ যে কোনো শিল্পকর্ম ডাম্প করতে এই বালতি ব্যবহার করতে পারি। প্রথম নোটবুকের জন্য (preprocess.ipynb), আমরা AWS পাবলিক SST2 ট্রেনের ডেটাসেট নামিয়েছি এবং এটি থেকে একটি প্রশিক্ষণ CSV ফাইল তৈরি করি যা আমরা এই S3 বালতিতে পুশ করি। নিম্নলিখিত কোড দেখুন:
তারপরে আমরা এই নোটবুকটিকে a এ রূপান্তর করতে পারি NotebookJobStep আমাদের প্রধান নোটবুকে নিম্নলিখিত কোড সহ:
এখন যেহেতু আমাদের কাছে একটি নমুনা CSV ফাইল আছে, আমরা আমাদের প্রশিক্ষণ নোটবুকে আমাদের মডেলের প্রশিক্ষণ শুরু করতে পারি। আমাদের প্রশিক্ষণ নোটবুকটি S3 বালতির সাথে একই প্যারামিটারে নেয় এবং সেই অবস্থান থেকে প্রশিক্ষণ ডেটাসেটটি নামিয়ে দেয়। তারপরে আমরা নিম্নলিখিত কোড স্নিপেট সহ ট্রান্সফর্মার ট্রেনার অবজেক্ট ব্যবহার করে ফাইন-টিউনিং করি:
ফাইন-টিউনিংয়ের পরে, আমরা মডেলটি কীভাবে পারফর্ম করছে তা দেখতে কিছু ব্যাচের অনুমান চালাতে চাই। এটি একটি পৃথক নোটবুক ব্যবহার করে করা হয় (prepare-test-set.ipynb) একই স্থানীয় পাথে যা আমাদের প্রশিক্ষিত মডেল ব্যবহার করে অনুমান করার জন্য একটি পরীক্ষা ডেটাসেট তৈরি করে। আমরা নিম্নলিখিত ম্যাজিক সেল দিয়ে আমাদের প্রশিক্ষণ নোটবুকে অতিরিক্ত নোটবুক চালাতে পারি:
আমরা এই অতিরিক্ত নোটবুক নির্ভরতা সংজ্ঞায়িত AdditionalDependencies আমাদের দ্বিতীয় নোটবুক কাজের ধাপে পরামিতি:
আমাদের অবশ্যই উল্লেখ করতে হবে যে প্রশিক্ষণ নোটবুক কাজের ধাপ (ধাপ 2) প্রিপ্রসেস নোটবুক কাজের ধাপের (ধাপ 1) উপর নির্ভর করে add_depends_on API কল নিম্নরূপ:
আমাদের শেষ পদক্ষেপ, সেজমেকার মডেল মনিটরের মাধ্যমে ডেটা ক্যাপচার এবং গুণমান সেট আপ করার সাথে সাথে BERT মডেলটি একটি সেজমেকার ব্যাচ ট্রান্সফর্ম চালাবে। মনে রাখবেন যে এটি বিল্ট-ইন ব্যবহারের থেকে আলাদা রুপান্তর or গ্রেপ্তার পাইপলাইন মাধ্যমে পদক্ষেপ. এই ধাপের জন্য আমাদের নোটবুক সেই একই APIগুলি চালাবে, কিন্তু একটি নোটবুক কাজের ধাপ হিসাবে ট্র্যাক করা হবে। এই ধাপটি প্রশিক্ষণের কাজের ধাপের উপর নির্ভরশীল যা আমরা পূর্বে সংজ্ঞায়িত করেছি, তাই আমরা এটিকে ডিপেন্ডস_অন পতাকার সাথে ক্যাপচার করি।
আমাদের কর্মপ্রবাহের বিভিন্ন ধাপ সংজ্ঞায়িত হওয়ার পরে, আমরা শেষ থেকে শেষ পাইপলাইন তৈরি এবং চালাতে পারি:
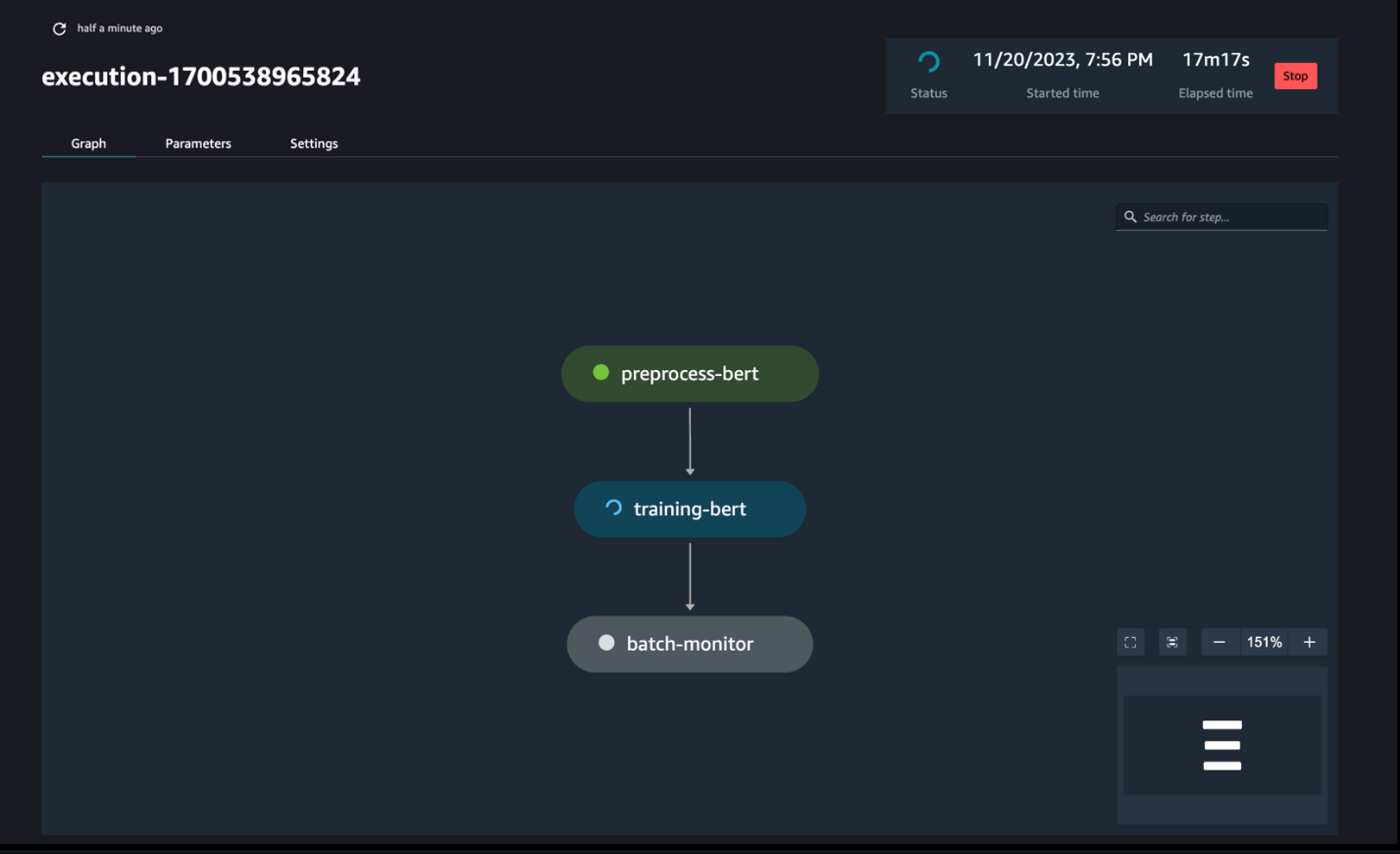
পাইপলাইন রান নিরীক্ষণ
নিচের স্ক্রিনশটে দেখা গেছে, আপনি SageMaker Pipelines DAG-এর মাধ্যমে নোটবুকের ধাপটি ট্র্যাক এবং নিরীক্ষণ করতে পারেন।
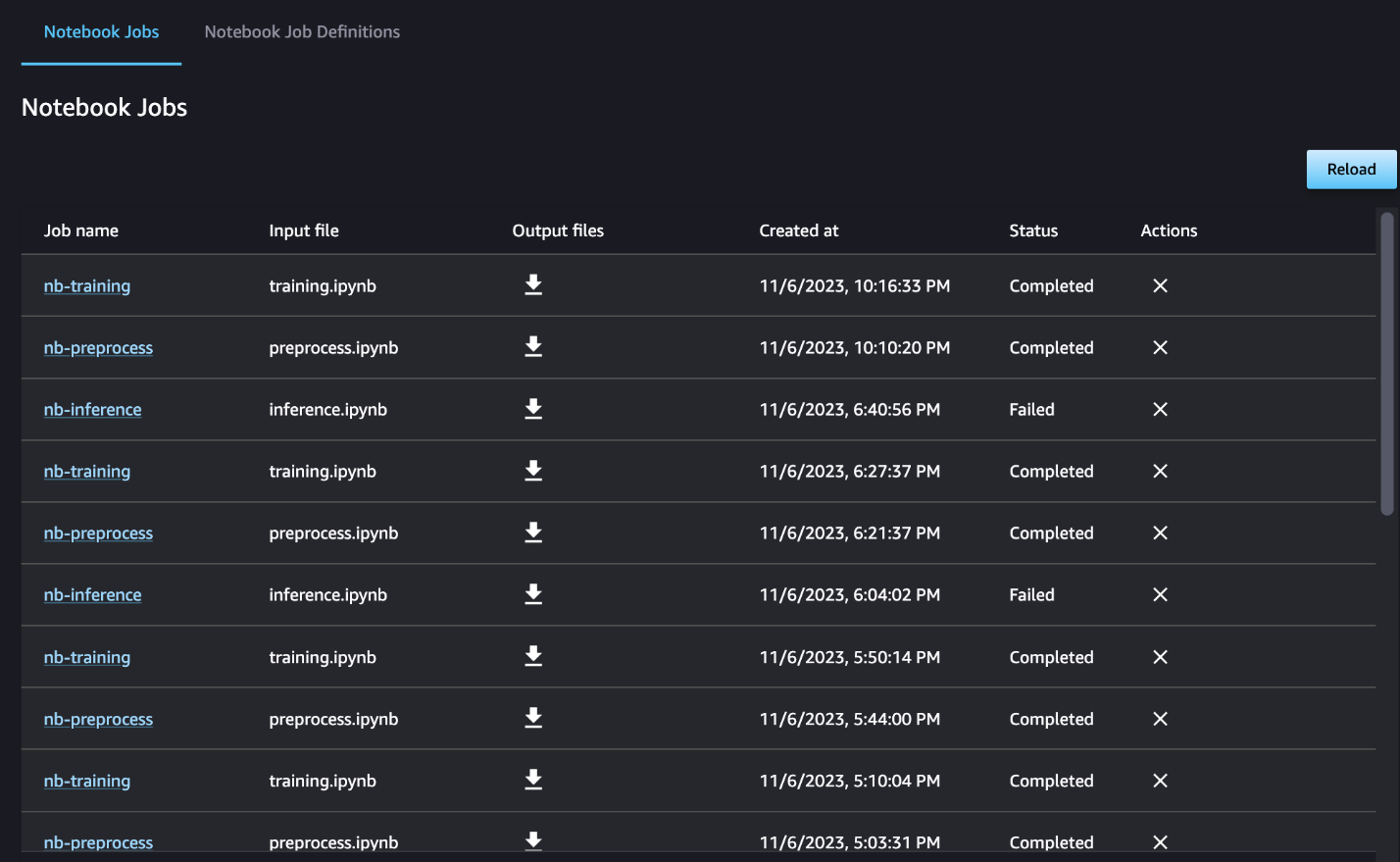
আপনি ঐচ্ছিকভাবে নোটবুক জব ড্যাশবোর্ডে চলা স্বতন্ত্র নোটবুকটি নিরীক্ষণ করতে পারেন এবং সেজমেকার স্টুডিও UI এর মাধ্যমে তৈরি করা আউটপুট ফাইলগুলিকে টগল করতে পারেন। SageMaker স্টুডিওর বাইরে এই কার্যকারিতা ব্যবহার করার সময়, আপনি ট্যাগ ব্যবহার করে নোটবুক কাজের ড্যাশবোর্ডে রান স্ট্যাটাস ট্র্যাক করতে পারেন এমন ব্যবহারকারীদের সংজ্ঞায়িত করতে পারেন। অন্তর্ভুক্ত করার জন্য ট্যাগ সম্পর্কে আরও বিশদ বিবরণের জন্য, দেখুন স্টুডিও UI ড্যাশবোর্ডে আপনার নোটবুকের কাজগুলি দেখুন এবং আউটপুট ডাউনলোড করুন৷.
এই উদাহরণের জন্য, আমরা ফলস্বরূপ নোটবুকের কাজগুলিকে নামক একটি ডিরেক্টরিতে আউটপুট করি outputs আপনার পাইপলাইন রান কোড সহ আপনার স্থানীয় পথে। নিম্নলিখিত স্ক্রিনশটে দেখানো হয়েছে, এখানে আপনি আপনার ইনপুট নোটবুকের আউটপুট এবং সেই ধাপের জন্য আপনার সংজ্ঞায়িত যে কোনো পরামিতি দেখতে পাবেন।
পরিষ্কার কর
আপনি যদি আমাদের উদাহরণটি অনুসরণ করেন, তাহলে তৈরি করা পাইপলাইন, নোটবুকের কাজ এবং নমুনা নোটবুক দ্বারা ডাউনলোড করা s3 ডেটা মুছে ফেলতে ভুলবেন না।
বিবেচ্য বিষয়
এই বৈশিষ্ট্যটির জন্য নিম্নলিখিত কিছু গুরুত্বপূর্ণ বিবেচনা রয়েছে:
- SDK সীমাবদ্ধতা - নোটবুক কাজের ধাপটি শুধুমাত্র SageMaker Python SDK-এর মাধ্যমে তৈরি করা যেতে পারে।
- ইমেজ সীমাবদ্ধতা -নোটবুক কাজের ধাপটি নিম্নলিখিত চিত্রগুলিকে সমর্থন করে:
উপসংহার
এই লঞ্চের সাথে, ডেটা কর্মীরা এখন প্রোগ্রামেটিকভাবে তাদের নোটবুকগুলিকে কয়েকটি লাইন কোড ব্যবহার করে চালাতে পারে৷ সেজমেকার পাইথন এসডিকে. অতিরিক্তভাবে, আপনি আপনার নোটবুকগুলি ব্যবহার করে জটিল বহু-পদক্ষেপের কর্মপ্রবাহ তৈরি করতে পারেন, একটি নোটবুক থেকে একটি CI/CD পাইপলাইনে যাওয়ার জন্য প্রয়োজনীয় সময়কে উল্লেখযোগ্যভাবে হ্রাস করে৷ পাইপলাইন তৈরি করার পরে, আপনি আপনার পাইপলাইনগুলির জন্য DAG দেখতে এবং চালাতে এবং রান পরিচালনা ও তুলনা করতে সেজমেকার স্টুডিও ব্যবহার করতে পারেন। আপনি এন্ড-টু-এন্ড ML ওয়ার্কফ্লো শিডিউল করছেন বা এর একটি অংশ, আমরা আপনাকে চেষ্টা করার জন্য উত্সাহিত করি নোটবুক ভিত্তিক কর্মপ্রবাহ.
লেখক সম্পর্কে
 অঞ্চিত গুপ্ত অ্যামাজন সেজমেকার স্টুডিওর একজন সিনিয়র প্রোডাক্ট ম্যানেজার। সে সেজমেকার স্টুডিও আইডিই-এর মধ্যে থেকে ইন্টারেক্টিভ ডেটা সায়েন্স এবং ডেটা ইঞ্জিনিয়ারিং ওয়ার্কফ্লো সক্রিয় করার উপর দৃষ্টি নিবদ্ধ করে। তার অবসর সময়ে, সে রান্না, বোর্ড/তাস গেম খেলতে এবং পড়া উপভোগ করে।
অঞ্চিত গুপ্ত অ্যামাজন সেজমেকার স্টুডিওর একজন সিনিয়র প্রোডাক্ট ম্যানেজার। সে সেজমেকার স্টুডিও আইডিই-এর মধ্যে থেকে ইন্টারেক্টিভ ডেটা সায়েন্স এবং ডেটা ইঞ্জিনিয়ারিং ওয়ার্কফ্লো সক্রিয় করার উপর দৃষ্টি নিবদ্ধ করে। তার অবসর সময়ে, সে রান্না, বোর্ড/তাস গেম খেলতে এবং পড়া উপভোগ করে।
 রাম ভেগিরাজু সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের Amazon SageMaker-এ তাদের AI/ML সমাধানগুলি তৈরি এবং অপ্টিমাইজ করতে সাহায্য করার দিকে মনোনিবেশ করেন৷ অবসর সময়ে তিনি ভ্রমণ এবং লেখালেখি পছন্দ করেন।
রাম ভেগিরাজু সেজমেকার সার্ভিস টিমের সাথে একজন এমএল আর্কিটেক্ট। তিনি গ্রাহকদের Amazon SageMaker-এ তাদের AI/ML সমাধানগুলি তৈরি এবং অপ্টিমাইজ করতে সাহায্য করার দিকে মনোনিবেশ করেন৷ অবসর সময়ে তিনি ভ্রমণ এবং লেখালেখি পছন্দ করেন।
 এডওয়ার্ড সান অ্যামাজন ওয়েব সার্ভিসে সেজমেকার স্টুডিওর জন্য কাজ করা একজন সিনিয়র এসডিই। ডেটা ইঞ্জিনিয়ারিং এবং এমএল ইকোসিস্টেমের জনপ্রিয় প্রযুক্তিগুলির সাথে সেজমেকার স্টুডিওকে একীভূত করার জন্য তিনি ইন্টারেক্টিভ এমএল সমাধান তৈরি করা এবং গ্রাহকের অভিজ্ঞতাকে সহজ করার দিকে মনোনিবেশ করেছেন। তার অবসর সময়ে, এডওয়ার্ড ক্যাম্পিং, হাইকিং এবং মাছ ধরার বড় অনুরাগী এবং তার পরিবারের সাথে সময় কাটাতে উপভোগ করেন।
এডওয়ার্ড সান অ্যামাজন ওয়েব সার্ভিসে সেজমেকার স্টুডিওর জন্য কাজ করা একজন সিনিয়র এসডিই। ডেটা ইঞ্জিনিয়ারিং এবং এমএল ইকোসিস্টেমের জনপ্রিয় প্রযুক্তিগুলির সাথে সেজমেকার স্টুডিওকে একীভূত করার জন্য তিনি ইন্টারেক্টিভ এমএল সমাধান তৈরি করা এবং গ্রাহকের অভিজ্ঞতাকে সহজ করার দিকে মনোনিবেশ করেছেন। তার অবসর সময়ে, এডওয়ার্ড ক্যাম্পিং, হাইকিং এবং মাছ ধরার বড় অনুরাগী এবং তার পরিবারের সাথে সময় কাটাতে উপভোগ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- PlatoData.Network উল্লম্ব জেনারেটিভ Ai. নিজেকে ক্ষমতায়িত করুন। এখানে প্রবেশ করুন.
- প্লেটোএআইস্ট্রিম। Web3 ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- প্লেটোইএসজি। কার্বন, ক্লিনটেক, শক্তি, পরিবেশ সৌর, বর্জ্য ব্যবস্থাপনা. এখানে প্রবেশ করুন.
- প্লেটো হেলথ। বায়োটেক এবং ক্লিনিক্যাল ট্রায়াল ইন্টেলিজেন্স। এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- : আছে
- : হয়
- :কোথায়
- $ ইউপি
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- সম্পর্কে
- প্রবেশযোগ্য
- অ্যাসাইক্লিক
- অতিরিক্ত
- উপরন্তু
- সুবিধা
- পর
- এআই / এমএল
- সব
- অনুমতি
- বরাবর
- ইতিমধ্যে
- এছাড়াও
- যদিও
- মর্দানী স্ত্রীলোক
- আমাজন EC2
- আমাজন সেজমেকার
- অ্যামাজন সেজমেকার স্টুডিও
- অ্যামাজন ওয়েব সার্ভিসেস
- an
- বিশ্লেষণ
- বিশ্লেষণ
- এবং
- কোন
- API
- API গুলি
- অ্যাপ্লিকেশন
- স্থাপত্য
- রয়েছি
- AS
- At
- স্বয়ংক্রিয় পদ্ধতি প্রয়োগ করা
- সহজলভ্য
- ডেস্কটপ AWS
- ভিত্তি
- ভিত্তি
- বেসলাইন
- BE
- সুন্দর
- হয়েছে
- পিছনে
- হচ্ছে
- উত্তম
- মধ্যে
- বিশাল
- নির্মাণ করা
- ভবন
- বিল্ট-ইন
- কিন্তু
- by
- কল
- নামক
- ক্যাম্পিং
- CAN
- গ্রেপ্তার
- কেস
- মামলা
- কোষ
- অক্ষর
- শ্রেণীবিন্যাস
- কোড
- স্তম্ভ
- কলাম
- সম্মিলন
- আসা
- সাধারণ
- তুলনা করা
- সম্পূর্ণ
- জটিল
- স্থিরীকৃত
- গঠিত
- গনা
- আচার
- সংযুক্ত
- বিবেচ্য বিষয়
- গঠিত
- আধার
- ধারণ
- একটানা
- রূপান্তর
- ধর্মান্তরিত
- রান্না
- অনুরূপ
- পারা
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- তৈরি করা হচ্ছে
- এখন
- প্রথা
- ক্রেতা
- গ্রাহক অভিজ্ঞতা
- গ্রাহক সমর্থন
- গ্রাহকদের
- DAG
- ড্যাশবোর্ড
- উপাত্ত
- তথ্য নিরীক্ষণ
- ডেটা প্রস্তুতি
- তথ্য প্রক্রিয়াজাতকরণ
- উপাত্ত গুণমান
- তথ্য বিজ্ঞান
- ডেটাসেট
- ডিফল্ট
- নির্ধারণ করা
- সংজ্ঞায়িত
- বিলি
- চাহিদা
- নির্ভরতা
- বশ্যতা
- নির্ভরশীল
- নির্ভর করে
- স্থাপন
- মোতায়েন
- বিশদ
- বিস্তারিত
- বিকাশ
- উন্নত
- বিভিন্ন
- সরাসরি
- পরিচালিত
- Director
- স্বতন্ত্র
- ডকশ্রমিক
- করছেন
- সম্পন্ন
- নিচে
- ডাউনলোড
- মনমরা ভাব
- প্রতি
- সহজে
- বাস্তু
- এডওয়ার্ড
- সক্ষম করা
- সক্রিয়
- উত্সাহিত করা
- শেষ
- সর্বশেষ সীমা
- প্রকৌশল
- সমগ্র
- কাল
- থার (eth)
- উদাহরণ
- এক্সিকিউট
- ফাঁসি
- অভিজ্ঞতা
- অতিরিক্ত
- নির্যাস
- পরিবার
- ফ্যান
- এ পর্যন্ত
- বৈশিষ্ট্য
- প্রতিক্রিয়া
- কয়েক
- ফাইল
- নথি পত্র
- চলচ্চিত্র
- চলচ্চিত্র নির্মাতাদের
- প্রথম
- মাছ ধরা
- পাঁচ
- দৃষ্টি নিবদ্ধ করা
- গুরুত্ত্ব
- অনুসৃত
- অনুসরণ
- অনুসরণ
- জন্য
- ফর্ম
- বিন্যাস
- থেকে
- সম্পূর্ণরূপে
- কার্যকারিতা
- তদ্ব্যতীত
- গেম
- উত্পাদন করা
- গ্রাফ
- আছে
- he
- সাহায্য
- সাহায্য
- তার
- এখানে
- হাইকিং
- তার
- হলিউড
- কিভাবে
- এইচটিএমএল
- HTTP
- HTTPS দ্বারা
- মানবীয়
- if
- প্রকাশ
- ভাবমূর্তি
- চিত্র
- অবিলম্বে
- আমদানি
- গুরুত্বপূর্ণ
- in
- অন্তর্ভুক্ত করা
- স্বাধীন
- ইঙ্গিত
- স্বতন্ত্র
- ইনপুট
- উদাহরণ
- নির্দেশাবলী
- সম্পূর্ণ
- ইন্টিগ্রেশন
- ইন্টারেক্টিভ
- মধ্যে
- IT
- এর
- কাজ
- জবস
- JPG
- মাত্র
- লেবেল
- লেবেলগুলি
- গত
- শুরু করা
- শিক্ষা
- লাইব্রেরি
- লাইন
- লাইন
- বোঝা
- স্থানীয়
- অবস্থান
- দীর্ঘ
- ভালবাসে
- মেশিন
- মেশিন লার্নিং
- জাদু
- প্রধান
- তৈরি করে
- পরিচালনা করা
- পরিচালিত
- ব্যবস্থাপনা
- পরিচালক
- মিডিয়া
- যোগ্যতা
- হতে পারে
- ML
- মডেল
- মডেল
- পরিবর্তিত
- মডিউল
- মনিটর
- পর্যবেক্ষণ
- মনিটর
- অধিক
- সেতু
- পদক্ষেপ
- চলচ্চিত্র
- বহু
- অবশ্যই
- নাম
- স্থানীয়
- প্রয়োজন
- প্রয়োজন
- নেতিবাচক
- নতুন
- না।
- বিঃদ্রঃ
- নোটবই
- নোটবুক
- এখন
- লক্ষ্য
- of
- প্রায়ই
- on
- ONE
- কেবল
- অপ্টিমিজ
- or
- অর্কেস্ট্রারচনা
- অন্যান্য
- আমাদের
- বাইরে
- আউটপুট
- আউটপুট
- বাহিরে
- জোড়া
- স্থিতিমাপ
- পরামিতি
- অংশ
- পাস
- পাসিং
- পথ
- সম্পাদন করা
- করণ
- ব্যক্তিগত
- পাইপলাইন
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- কেলি
- জনপ্রিয়
- ধনাত্মক
- পোস্ট
- ভবিষ্যদ্বাণী করা
- প্রস্তুতি
- প্রস্তুত করা
- প্রস্তুত করে
- প্রস্তুতি
- আগে
- পূর্বে
- সমস্যা
- প্রক্রিয়াজাতকরণ
- পণ্য
- পণ্য ব্যবস্থাপক
- প্রদান
- প্রদত্ত
- উপলব্ধ
- প্রকাশ্য
- pulls
- উদ্দেশ্য
- ধাক্কা
- ধাক্কা
- পাইথন
- গুণ
- দ্রুততর
- R
- বরং
- পড়া
- পড়া
- আবৃত্ত
- হ্রাস
- রিফ্যাক্টর
- পড়ুন
- নিবন্ধভুক্ত
- নিয়মিতভাবে
- থাকা
- পুনঃপুনঃ
- প্রয়োজন
- ফলে এবং
- এখানে ক্লিক করুন
- পর্যালোচনা
- চালান
- দৌড়
- রান
- ঋষি নির্মাতা
- সেজমেকার পাইপলাইন
- একই
- সন্তুষ্ট
- তফসিল
- তালিকাভুক্ত
- নির্ধারিত কাজ
- পূর্বপরিকল্পনা
- বিজ্ঞান
- বিজ্ঞানীরা
- SDK
- দ্বিতীয়
- অধ্যায়
- বিভাগে
- দেখ
- দেখা
- জ্যেষ্ঠ
- অনুভূতি
- আলাদা
- সেবা
- সেবা
- সেশন
- সেট
- বিন্যাস
- বিভিন্ন
- আকৃতির
- সে
- উচিত
- প্রদর্শনী
- গ্লাসকেস
- প্রদর্শিত
- শো
- গুরুত্বপূর্ণ
- উল্লেখযোগ্যভাবে
- অনুরূপ
- সহজ
- সরলীকরণ
- একক
- ছোট
- ক্ষুদ্রতর
- টুকিটাকি
- So
- সামাজিক
- সামাজিক মাধ্যম
- সমাধান
- সলিউশন
- সমাধান
- কিছু
- কিছু
- স্থান
- নির্দিষ্ট
- খরচ
- স্বতন্ত্র
- স্ট্যানফোর্ড
- শুরু
- অবস্থা
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- এখনো
- স্টোরেজ
- অকপট
- চিত্রশালা
- এমন
- সূর্য
- সমর্থন
- সমর্থিত
- সমর্থন
- নিশ্চিত
- গ্রহণ করা
- লাগে
- কার্য
- কাজ
- টীম
- প্রযুক্তি
- পরীক্ষা
- পাঠ
- পাঠ্য শ্রেণিবিন্যাস
- যে
- সার্জারির
- তাদের
- তাহাদিগকে
- তারপর
- এইগুলো
- তৃতীয়
- এই
- সেগুলো
- তিন
- দ্বারা
- সময়
- থেকে
- একসঙ্গে
- অত্যধিক
- টুল
- মোট
- পথ
- রেলগাড়ি
- প্রশিক্ষিত
- প্রশিক্ষণ
- রুপান্তর
- ট্রান্সফরমার
- ভ্রমণ
- ট্রিগার
- চালু
- দুই
- আদর্শ
- ui
- বোঝা
- আপডেট
- us
- ব্যবহার
- ব্যবহার ক্ষেত্রে
- ব্যবহৃত
- ব্যবহারকারী
- ব্যবহারসমূহ
- ব্যবহার
- ব্যবহার
- মানগুলি
- বিভিন্ন
- মাধ্যমে
- চেক
- ঠাহর করা
- পদব্রজে ভ্রমণ
- প্রয়োজন
- we
- ওয়েব
- ওয়েব সার্ভিস
- কখন
- কিনা
- যে
- যখন
- হু
- ইচ্ছা
- সঙ্গে
- মধ্যে
- ছাড়া
- শ্রমিকদের
- কর্মপ্রবাহ
- কর্মপ্রবাহ
- কাজ
- খারাপ
- লেখা
- আপনি
- আপনার
- zephyrnet