আধুনিক বিশ্বে, বেশিরভাগ ব্যবসাগুলি তাদের বৃদ্ধি, কৌশলগত বিনিয়োগ এবং গ্রাহকদের সম্পৃক্ততা বাড়াতে বড় ডেটা এবং বিশ্লেষণের শক্তির উপর নির্ভর করে। বিগ ডেটা হল লক্ষ্যযুক্ত বিজ্ঞাপন, ব্যক্তিগতকৃত বিপণন, পণ্যের সুপারিশ, অন্তর্দৃষ্টি তৈরি, মূল্য অপ্টিমাইজেশান, অনুভূতি বিশ্লেষণ, ভবিষ্যদ্বাণীমূলক বিশ্লেষণ এবং আরও অনেক কিছুর অন্তর্নিহিত ধ্রুবক।
ডেটা প্রায়শই একাধিক উত্স থেকে সংগ্রহ করা হয়, রূপান্তরিত, সংরক্ষণ করা হয় এবং ডেটা লেকে অন-প্রেম বা অন-ক্লাউডগুলিতে প্রক্রিয়া করা হয়। যদিও প্রাথমিকভাবে ডেটা গ্রহণ করা তুলনামূলকভাবে তুচ্ছ এবং কাস্টম স্ক্রিপ্ট তৈরি করা ইন-হাউস বা ঐতিহ্যবাহী ETL (এক্সট্র্যাক্ট ট্রান্সফর্ম লোড) টুলের মাধ্যমে অর্জন করা যেতে পারে, সমস্যাটি দ্রুত জটিল এবং ব্যয়বহুল হয়ে ওঠে যার সমাধান কোম্পানিগুলিকে করতে হয়:
- সম্পূর্ণ ডাটা লাইফসাইকেল ম্যানেজ করুন – হাউসকিপিং এবং কমপ্লায়েন্সের উদ্দেশ্যে
- সঞ্চয়স্থান অপ্টিমাইজ করুন - সংশ্লিষ্ট খরচ কমাতে
- কম্পিউটিং পরিকাঠামোর পুনঃব্যবহারের মাধ্যমে আর্কিটেকচারকে সরলীকরণ করুন
- ক্রমবর্ধমানভাবে ডেটা প্রক্রিয়া করুন - শক্তিশালী রাষ্ট্র পরিচালনার মাধ্যমে
- ব্যাচ এবং স্ট্রিম ডেটাতে একই নীতি প্রয়োগ করুন - প্রচেষ্টার অনুলিপি ছাড়াই
- অন-প্রেম এবং ক্লাউড-এর মধ্যে মাইগ্রেট করুন – সর্বনিম্ন প্রচেষ্টায়
এটা যেখানে অ্যাপাচি গবলিন, একটি ওপেন-সোর্স ডেটা ম্যানেজমেন্ট, এবং ইন্টিগ্রেশন সিস্টেম আসে। Apache Gobblin অতুলনীয় ক্ষমতা প্রদান করে যা ব্যবসার প্রয়োজনের উপর নির্ভর করে সম্পূর্ণ বা অংশে ব্যবহার করা যেতে পারে।
এই বিভাগে, আমরা Apache Gobblin-এর বিভিন্ন ক্ষমতার সন্ধান করব যা পূর্বে বর্ণিত চ্যালেঞ্জ মোকাবেলায় সহায়তা করে।
সম্পূর্ণ ডেটা লাইফসাইকেল পরিচালনা করা
Apache Gobblin ডেটাসেটগুলিতে ডেটা লাইফসাইকেল ক্রিয়াকলাপগুলির সম্পূর্ণ স্যুটকে সমর্থন করে এমন ডেটা পাইপলাইনগুলি তৈরি করতে সক্ষমতার একটি স্বরগ্রাম সরবরাহ করে।
- ডেটাবেস, রেস্ট এপিআই, এফটিপি/এসএফটিপি সার্ভার, ফাইলার, সেলসফোর্স এবং ডায়নামিক্সের মতো সিআরএম এবং আরও অনেক কিছু থেকে বহু উৎস থেকে সিঙ্ক পর্যন্ত ডেটা ইনজেস্ট করুন।
- ডাটা রেপ্লিকেট করুন - Discp-NG এর মাধ্যমে Hadoop ডিস্ট্রিবিউটেড ফাইল সিস্টেমের জন্য বিশেষ ক্ষমতা সহ একাধিক ডেটা লেকের মধ্যে।
- ডেটা শুদ্ধ করুন - সময়-ভিত্তিক, নতুন কে, সংস্করণ বা নীতিগুলির সংমিশ্রণের মতো ধরে রাখার নীতিগুলি ব্যবহার করে৷
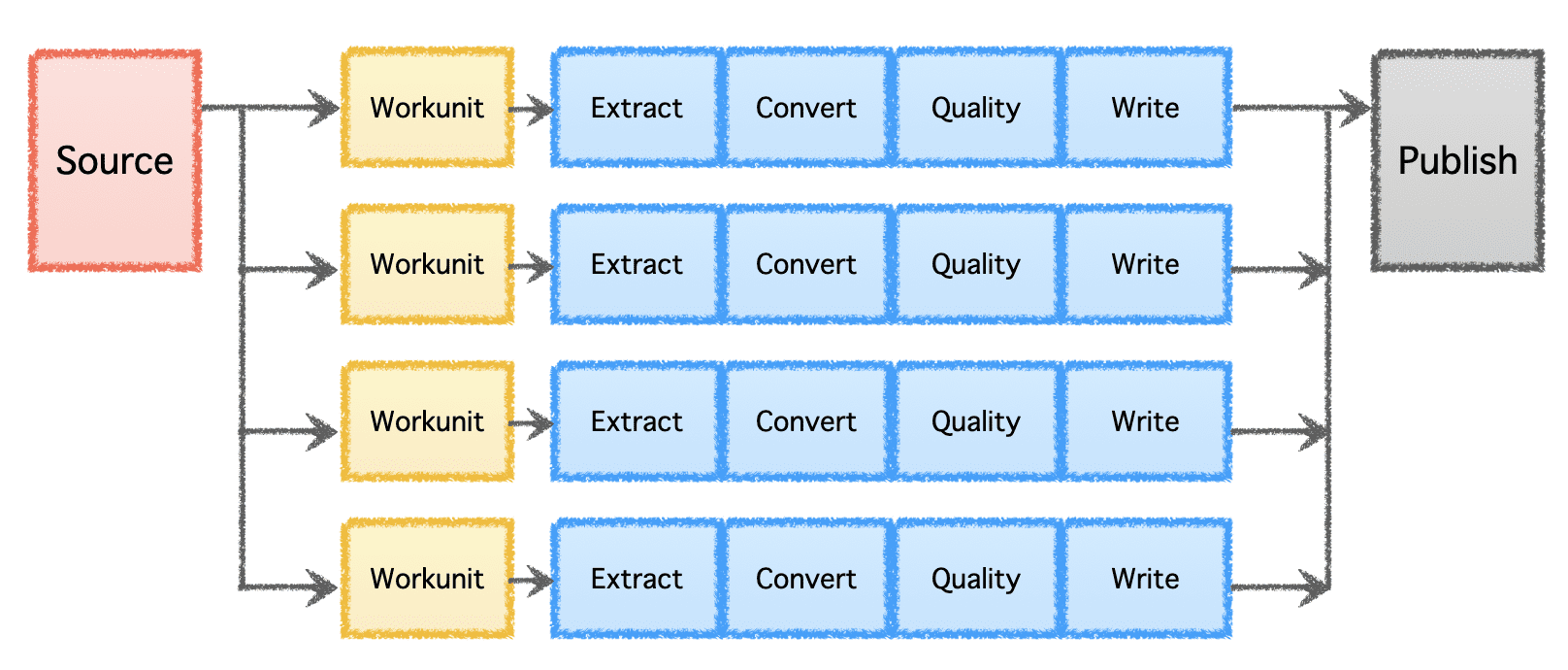
গবলিনের লজিক্যাল পাইপলাইনে একটি 'উৎস' রয়েছে যা কাজের বন্টন নির্ধারণ করে এবং 'ওয়ার্কুনিট' তৈরি করে। এই 'ওয়ার্কুনিট'গুলিকে তারপর 'টাস্ক' হিসাবে সম্পাদনের জন্য বাছাই করা হয়, যার মধ্যে রয়েছে নিষ্কাশন, রূপান্তর, গুণমান পরীক্ষা এবং গন্তব্যে ডেটা লেখা। চূড়ান্ত পদক্ষেপ, 'ডেটা প্রকাশ', পাইপলাইনের সফল সম্পাদনকে বৈধ করে এবং গন্তব্য এটিকে সমর্থন করলে আউটপুট ডেটাকে পারমাণবিকভাবে কমিট করে।
লেখকের ছবি
স্টোরেজ অনুকূলিতকরণ
Apache Gobblin কম্প্যাকশন বা ফরম্যাট রূপান্তরের মাধ্যমে ইনজেশন বা প্রতিলিপি করার পরে পোস্ট-প্রসেসিং ডেটার মাধ্যমে ডেটার জন্য প্রয়োজনীয় স্টোরেজের পরিমাণ কমাতে সাহায্য করতে পারে।
- কমপ্যাকশন - রেকর্ডের সমস্ত ক্ষেত্র বা মূল ক্ষেত্রগুলির উপর ভিত্তি করে অনুলিপি করার জন্য পোস্ট-প্রসেসিং ডেটা, একই কী সহ সর্বশেষ টাইমস্ট্যাম্প সহ শুধুমাত্র একটি রেকর্ড রাখার জন্য ডেটা ছাঁটাই করা।
- অভ্র থেকে ORC – জনপ্রিয় সারি-ভিত্তিক অভ্র ফরম্যাটকে একটি হাইপার-অপ্টিমাইজড কলাম-ভিত্তিক ORC ফর্ম্যাটে রূপান্তর করার জন্য একটি বিশেষ ফর্ম্যাট রূপান্তর প্রক্রিয়া হিসাবে।
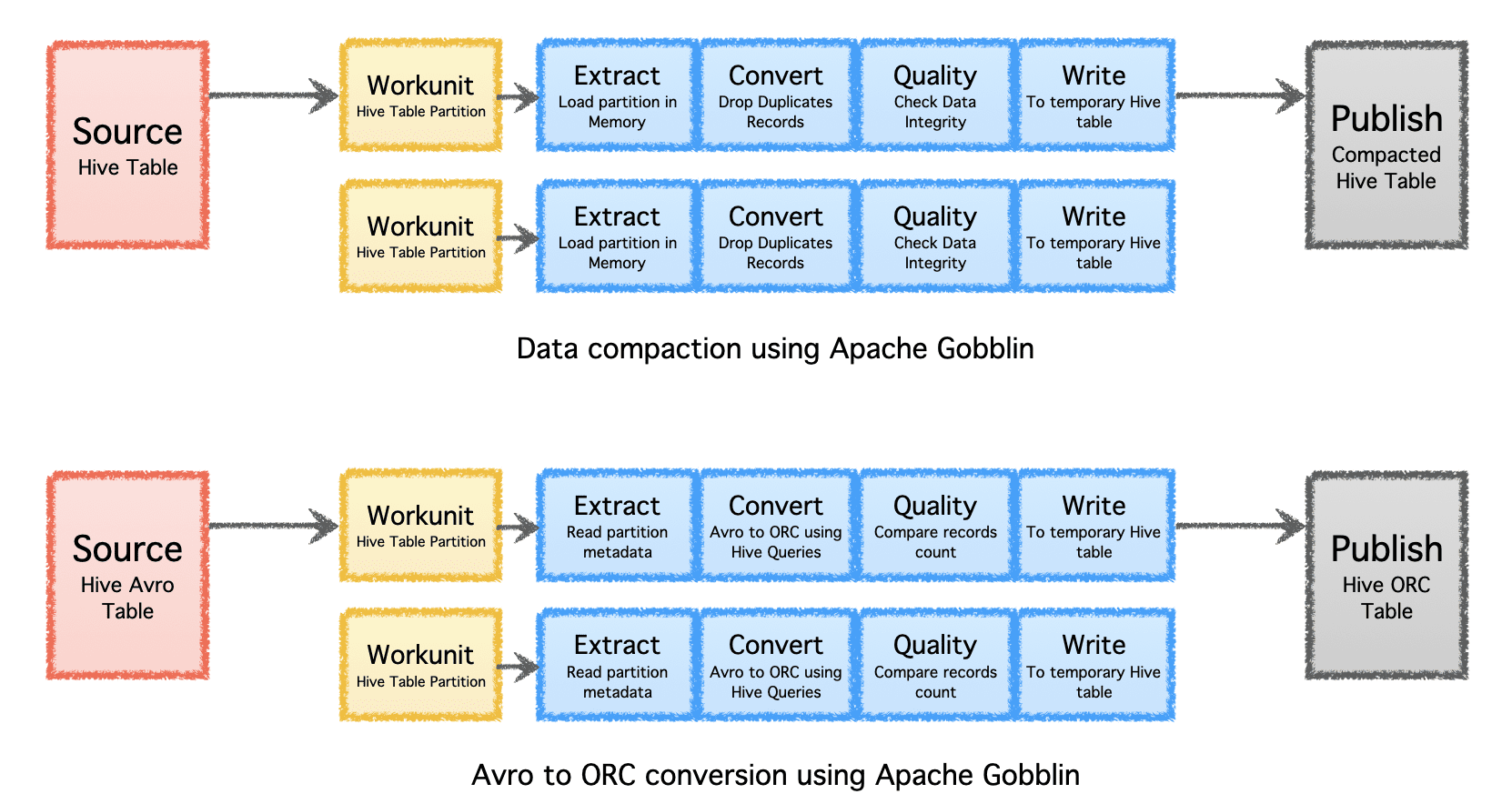
লেখকের ছবি
স্থাপত্য সহজীকরণ
কোম্পানির পর্যায়ে (স্টার্টআপ টু এন্টারপ্রাইজ), স্কেল প্রয়োজনীয়তা এবং তাদের নিজ নিজ আর্কিটেকচারের উপর নির্ভর করে, কোম্পানিগুলি তাদের ডেটা পরিকাঠামো সেট আপ বা বিকাশ করতে পছন্দ করে। Apache Gobblin খুবই নমনীয় এবং একাধিক এক্সিকিউশন মডেল সমর্থন করে।
- স্বতন্ত্র মোড - একটি খালি ধাতব বাক্সে একটি স্বতন্ত্র প্রক্রিয়া হিসাবে চালানোর জন্য, অর্থাৎ, সাধারণ ব্যবহারের ক্ষেত্রে এবং কম-চাহিদার পরিস্থিতিতে জন্য একক হোস্ট।
- MapReduce মোড – পেটাবাইট স্কেলে ডেটাসেটগুলি পরিচালনা করার জন্য বড় ডেটা কেসগুলির জন্য Hadoop পরিকাঠামোতে একটি MapReduce কাজ হিসাবে চালানোর জন্য৷
- ক্লাস্টার মোড: স্ট্যান্ডঅ্যালোন – Hadoop MR ফ্রেমওয়ার্ক থেকে স্বাধীনভাবে বৃহৎ পরিসরে হ্যান্ডেল করার জন্য বেয়ার মেটাল মেশিন বা হোস্টের সেটে Apache Helix এবং Apache Zookeeper দ্বারা সমর্থিত একটি ক্লাস্টার হিসাবে চালানোর জন্য।
- ক্লাস্টার মোড: সুতা – Hadoop MR ফ্রেমওয়ার্ক ছাড়াই নেটিভ ইয়ার্নে একটি ক্লাস্টার হিসাবে চালানোর জন্য।
- ক্লাস্টার মোড: AWS – অ্যামাজনের পাবলিক ক্লাউড অফারে একটি ক্লাস্টার হিসাবে চালানোর জন্য, যেমন। AWS-এ হোস্ট করা অবকাঠামোর জন্য AWS।
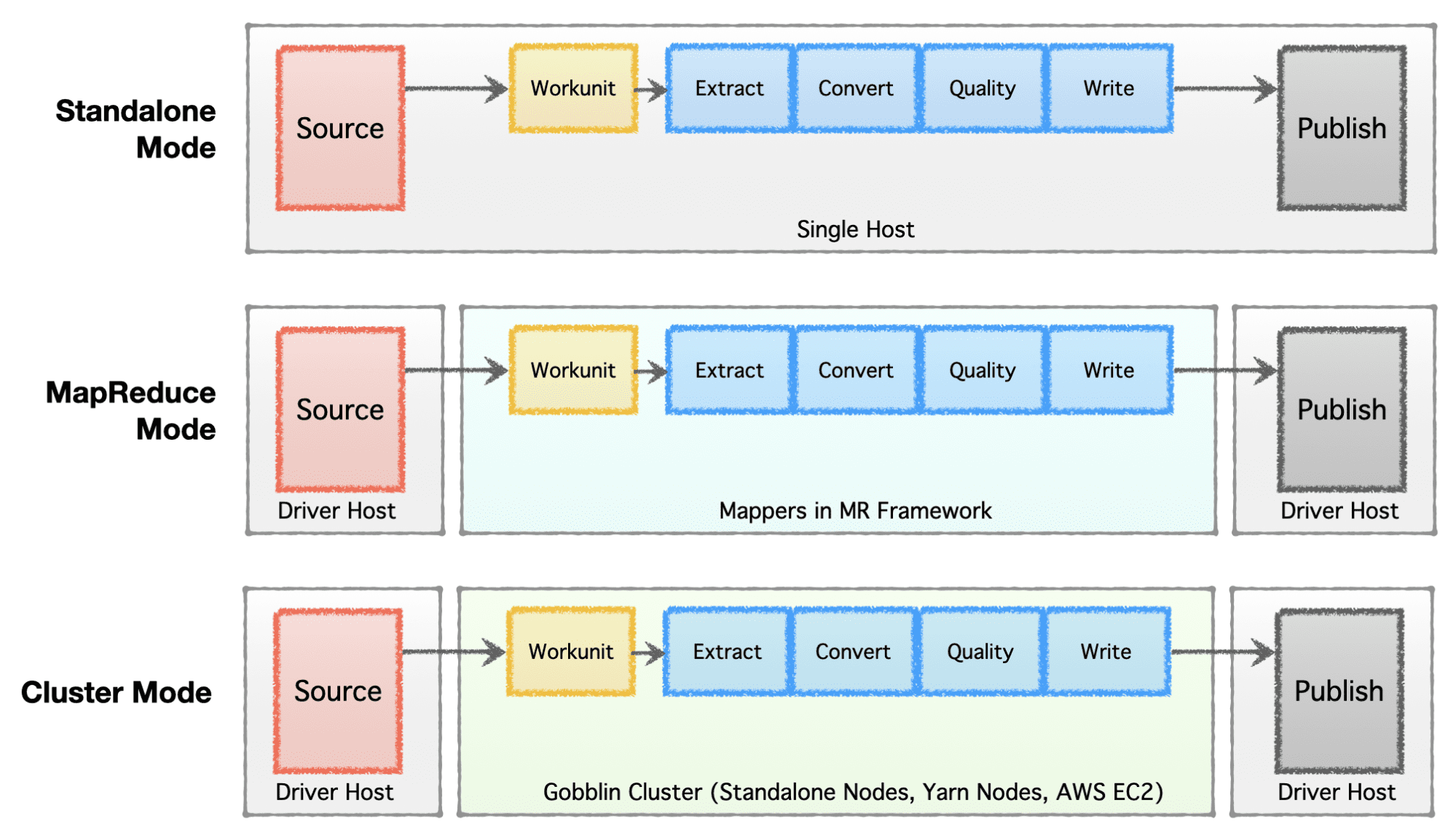
লেখকের ছবি
ক্রমবর্ধমান ডেটা প্রক্রিয়া করুন
একাধিক ডেটা পাইপলাইন এবং উচ্চ ভলিউম সহ একটি উল্লেখযোগ্য স্কেলে, ডেটা ব্যাচে এবং সময়ের সাথে প্রক্রিয়া করা দরকার। অতএব, এটির জন্য চেকপয়েন্টিং করা প্রয়োজন যাতে ডেটা পাইপলাইনগুলি শেষবার যেখান থেকে ছেড়ে গিয়েছিল সেখান থেকে পুনরায় শুরু করতে পারে এবং এর পরে চালিয়ে যেতে পারে। Apache Gobblin কম এবং উচ্চ ওয়াটারমার্ক সমর্থন করে এবং HDFS, AWS S3, MySQL এবং আরও স্বচ্ছভাবে স্টেট স্টোরের মাধ্যমে শক্তিশালী স্টেট ম্যানেজমেন্ট শব্দার্থকে সমর্থন করে।
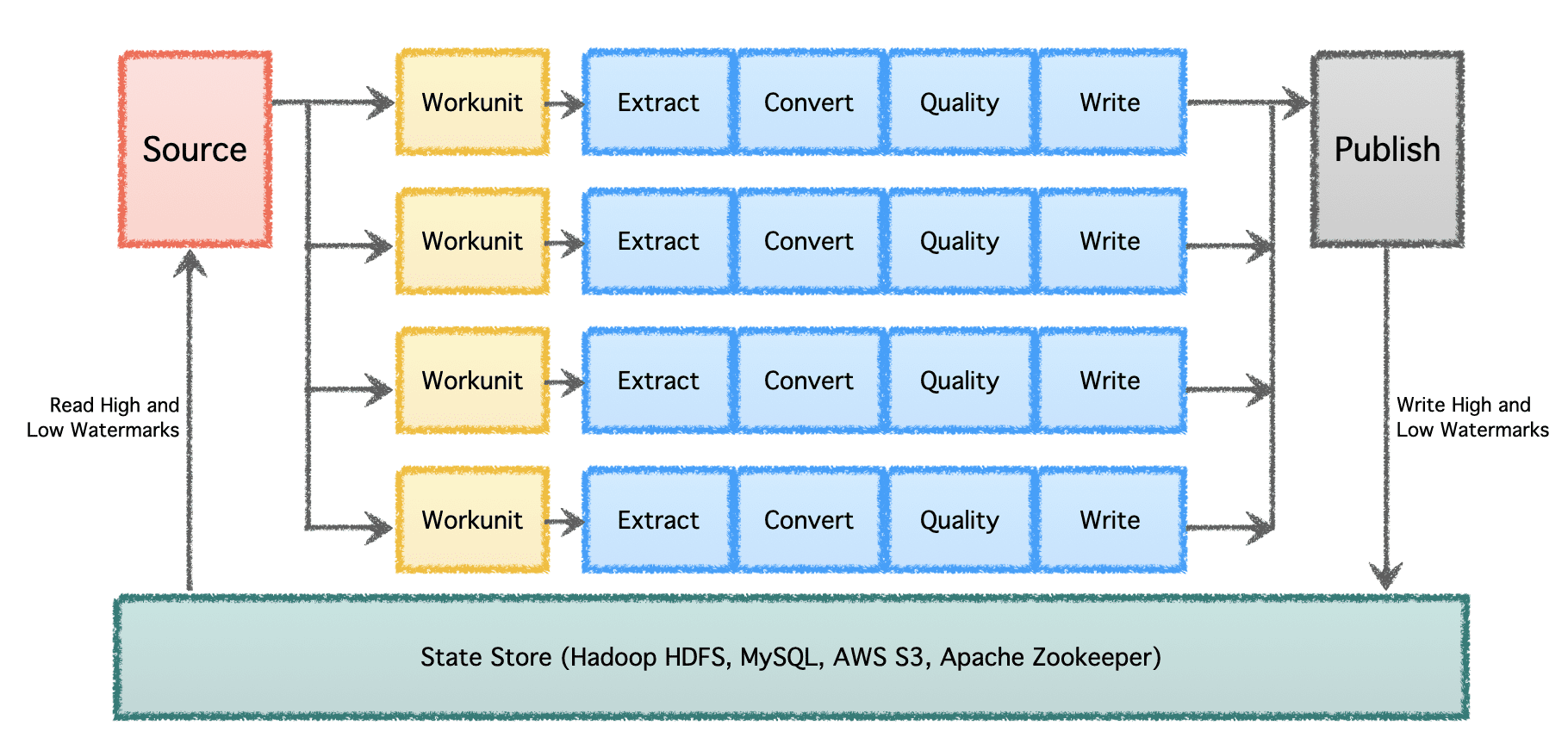
লেখকের ছবি
ব্যাচ এবং স্ট্রিম ডেটাতে একই নীতি
বেশিরভাগ ডেটা পাইপলাইনগুলিকে আজ দুবার লিখতে হবে, একবার ব্যাচ ডেটার জন্য এবং আবার কাছাকাছি-লাইন বা স্ট্রিমিং ডেটার জন্য। এটি প্রচেষ্টাকে দ্বিগুণ করে এবং বিভিন্ন ধরনের পাইপলাইনে প্রয়োগ করা নীতি এবং অ্যালগরিদমের অসঙ্গতি প্রবর্তন করে। Apache Gobblin ব্যবহারকারীদের একবার একটি পাইপলাইন লিখতে এবং Gobblin ক্লাস্টার মোডে, AWS মোডে Gobblin, অথবা Yarn মোডে গবলিন ব্যবহার করা হলে উভয় ব্যাচ এবং স্ট্রিম ডেটাতে চালানোর অনুমতি দিয়ে এর সমাধান করে।
অন-প্রেম এবং ক্লাউডের মধ্যে স্থানান্তর করুন
এর বহুমুখী মোডগুলির কারণে যা একটি একক বাক্সে অন-প্রিম চালাতে পারে, নোডের একটি ক্লাস্টার, বা ক্লাউড - অ্যাপাচি গবলিনকে স্থাপন করা যেতে পারে এবং অন-প্রিম এবং ক্লাউডে ব্যবহার করা যেতে পারে। অতএব, ব্যবহারকারীদের তাদের ডেটা পাইপলাইন একবার লিখতে এবং নির্দিষ্ট প্রয়োজনের ভিত্তিতে অন-প্রেম এবং ক্লাউডের মধ্যে সহজেই গবলিন স্থাপনার সাথে স্থানান্তরিত করার অনুমতি দেয়।
এটির অত্যন্ত নমনীয় স্থাপত্য, শক্তিশালী বৈশিষ্ট্য এবং ডেটা ভলিউমের চরম মাত্রার কারণে যা এটি সমর্থন এবং প্রক্রিয়া করতে পারে, অ্যাপাচি গবলিন এর উত্পাদন পরিকাঠামোতে ব্যবহৃত হয় প্রধান প্রযুক্তি কোম্পানি এবং আজ যেকোন বড় ডেটা পরিকাঠামো স্থাপনের জন্য এটি একটি আবশ্যক।
Apache Gobblin এবং এটি কীভাবে ব্যবহার করবেন সে সম্পর্কে আরও বিশদ এখানে পাওয়া যাবে https://gobblin.apache.org
অভিষেক তিওয়ারি লিংকডইনের একজন সিনিয়র ম্যানেজার, কোম্পানির বিগ ডেটা পাইপলাইন সংস্থার নেতৃত্ব দিচ্ছেন। এছাড়াও তিনি অ্যাপাচি সফটওয়্যার ফাউন্ডেশনে অ্যাপাচি গবলিনের ভাইস প্রেসিডেন্ট এবং ব্রিটিশ কম্পিউটার সোসাইটির একজন ফেলো।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/2023/01/scaling-data-management-apache-gobblin.html?utm_source=rss&utm_medium=rss&utm_campaign=scaling-data-management-through-apache-gobblin
- a
- অর্জন
- সম্ভাষণ
- ভি .আই. পি বিজ্ঞাপন
- পর
- চিকিত্সা
- আলগোরিদিম
- সব
- অনুমতি
- পরিমাণ
- বিশ্লেষণ
- বৈশ্লেষিক ন্যায়
- এবং
- এ্যাপাচি
- API গুলি
- ফলিত
- স্থাপত্য
- যুক্ত
- লেখক
- ডেস্কটপ AWS
- সাহায্যপ্রাপ্ত
- ভিত্তি
- হয়ে
- মধ্যে
- বিশাল
- বড় ডেটা
- বক্স
- ব্রিটিশ
- ব্যবসায়
- ব্যবসা
- ক্ষমতা
- মামলা
- চ্যালেঞ্জ
- পরীক্ষণ
- মেঘ
- গুচ্ছ
- সমাহার
- কোম্পানি
- কোম্পানি
- জটিল
- সম্মতি
- কম্পিউটার
- কম্পিউটিং
- ধ্রুব
- গঠন করা
- অবিরত
- পরিবর্তন
- রূপান্তর
- সৃষ্টি
- প্রথা
- ক্রেতা
- ক্রেতা প্রবৃত্তি
- উপাত্ত
- ডেটা অবকাঠামো
- ডাটা ব্যাবস্থাপনা
- ডাটাবেস
- ডেটাসেট
- নির্ভর করে
- মোতায়েন
- বিস্তৃতি
- স্থাপনার
- গন্তব্য
- বিস্তারিত
- নির্ধারণ করে
- উন্নত
- বিভিন্ন
- বণ্টিত
- বিতরণ
- গতিবিদ্যা
- সহজে
- প্রচেষ্টা
- প্রবৃত্তি
- উদ্যোগ
- থার (eth)
- গজান
- ফাঁসি
- ব্যয়বহুল
- নির্যাস
- নিষ্কাশন
- চরম
- বৈশিষ্ট্য
- সহকর্মী
- ক্ষেত্রসমূহ
- ফাইল
- চূড়ান্ত
- নমনীয়
- বিন্যাস
- পাওয়া
- ভিত
- ফ্রেমওয়ার্ক
- থেকে
- জ্বালানি
- সম্পূর্ণ
- প্রজন্ম
- উন্নতি
- Hadoop
- হাতল
- সাহায্য
- উচ্চ
- অত্যন্ত
- নিমন্ত্রণকর্তা
- হোস্ট
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- in
- অন্তর্ভুক্ত করা
- স্বাধীন
- পরিকাঠামো
- অবকাঠামো
- প্রারম্ভিক
- অর্ন্তদৃষ্টি
- ইন্টিগ্রেশন
- পরিচয় করিয়ে দেয়
- ইনভেস্টমেন্টস
- IT
- কাজ
- কেডনুগেটস
- রাখা
- চাবি
- বড়
- গত
- সর্বশেষ
- নেতৃত্ব
- লিঙ্কডইন
- বোঝা
- কম
- মেশিন
- ব্যবস্থাপনা
- পরিচালক
- Marketing
- পদ্ধতি
- ধাতু
- মাইগ্রেট
- মোড
- মডেল
- আধুনিক
- মোড
- অধিক
- সেতু
- বহু
- আছে-আবশ্যক
- মাইএসকিউএল
- স্থানীয়
- প্রয়োজন
- চাহিদা
- নতুন
- নোড
- নৈবেদ্য
- ONE
- ওপেন সোর্স
- অপারেশনস
- সংগঠন
- রূপরেখা
- যন্ত্রাংশ
- ব্যক্তিগতকৃত
- অবচিত
- পাইপলাইন
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- নীতি
- জনপ্রিয়
- ক্ষমতা
- ক্ষমতাশালী
- আনুমানিক বিশ্লেষণ
- পছন্দ করা
- সভাপতি
- পূর্বে
- মূল্য
- সমস্যা
- প্রক্রিয়া
- পণ্য
- উত্পাদনের
- উপলব্ধ
- প্রকাশ্য
- পাবলিক মেঘ
- প্রকাশ করা
- গুণ
- দ্রুত
- রেঞ্জিং
- সুপারিশ
- নথি
- রেকর্ড
- হ্রাস করা
- অপেক্ষাকৃতভাবে
- প্রতিলিপি
- আবশ্যকতা
- নিজ নিজ
- বিশ্রাম
- জীবনবৃত্তান্ত
- স্মৃতিশক্তি
- শক্তসমর্থ
- চালান
- বিক্রয় বল
- একই
- স্কেল
- আরোহী
- স্ক্রিপ্ট
- অধ্যায়
- শব্দার্থবিদ্যা
- জ্যেষ্ঠ
- অনুভূতি
- সেট
- গুরুত্বপূর্ণ
- সহজ
- একক
- পরিস্থিতিতে
- So
- সমাজ
- সফটওয়্যার
- সমাধান
- solves
- উৎস
- সোর্স
- বিশেষজ্ঞ
- নির্দিষ্ট
- পর্যায়
- স্বতন্ত্র
- প্রারম্ভকালে
- রাষ্ট্র
- ধাপ
- স্টোরেজ
- দোকান
- সঞ্চিত
- কৌশলগত
- প্রবাহ
- স্ট্রিমিং
- সফল
- অনুসরণ
- সমর্থন
- সমর্থন
- পদ্ধতি
- লক্ষ্যবস্তু
- কাজ
- প্রযুক্তিঃ
- সার্জারির
- তাদের
- অতএব
- দ্বারা
- সময়
- টাইমস্ট্যাম্প
- থেকে
- আজ
- সরঞ্জাম
- ঐতিহ্যগত
- রুপান্তর
- রুপান্তরিত
- ধরনের
- নিম্নাবস্থিত
- অনুপম
- ব্যবহার
- ব্যবহারকারী
- বিভিন্ন
- বহুমুখ কর্মশক্তিসম্পন্ন
- মাধ্যমে
- উপরাষ্ট্রপতি
- আয়তন
- ভলিউম
- যে
- যখন
- ইচ্ছা
- ছাড়া
- হয়া যাই ?
- বিশ্ব
- লেখা
- লেখা
- লিখিত
- zephyrnet