خلال العقد 2010، بدأت فوائد قانون مور في الانهيار. نص قانون مور على أن كثافة الترانزستور تتضاعف كل عامين، وستنخفض تكلفة الحوسبة بنسبة 50%. يرجع التغيير في قانون مور إلى زيادة تعقيد التصميم في تطور بنية الترانزستور من الأجهزة المستوية إلى الأجهزة Finfets. تحتاج Finfets إلى أنماط متعددة للطباعة الحجرية لتحقيق أبعاد الأجهزة إلى أقل من 20 نانومتر.
في بداية هذا العقد، تزايدت احتياجات الحوسبة بشكل كبير، ويرجع ذلك في الغالب إلى انتشار مراكز البيانات وبسبب كمية البيانات التي يتم إنشاؤها ومعالجتها. في الواقع، يتم الآن استخدام الذكاء الاصطناعي (AI) وتقنيات مثل التعلم الآلي (ML) لمعالجة البيانات المتزايدة باستمرار، مما أدى إلى زيادة الخوادم بشكل كبير في قدرتها الحاسوبية.
أضافت الخوادم العديد من نوى وحدة المعالجة المركزية، ودمجت وحدات معالجة رسومات أكبر تستخدم حصريًا لتعلم الآلة، ولم تعد تستخدم للرسومات، وقد قامت بتضمين مسرعات ASIC AI مخصصة أو معالجة ذكاء اصطناعي تكميلية تعتمد على FPGA. تم تنفيذ تصميمات شرائح الذكاء الاصطناعي المبكرة باستخدام شرائح SoC متجانسة أكبر حجمًا، ووصل بعضها إلى الحد الأقصى للحجم الذي تفرضه الشبكة، وهو حوالي 700 ملم2.
في هذه المرحلة، يبدو أن الحل الصحيح هو التقسيم إلى شريحة SoC أصغر بالإضافة إلى شرائح الحوسبة وشرائح الإدخال/الإخراج المتنوعة. قام العديد من صانعي الرقائق، مثل Intel أو AMD أو Xilinx، بتحديد هذا الخيار للمنتجات التي تدخل مرحلة الإنتاج. في التقرير التمهيدي الممتاز الصادر عن مجموعة Linley Group، بعنوان "تكتسب الشرائح الصغيرة التبني السريع: لماذا أصبحت الرقائق الكبيرة أصغر حجمًا"، تبين أن هذا الخيار يؤدي إلى تكاليف أفضل مقارنةً بالشرائح SoC المتجانسة، نظرًا لتأثير العائد الأكبر.
التأثير الرئيسي لهذا الاتجاه على بائعي IP هو في الغالب على وظائف التوصيل البيني المستخدمة لربط SoCs والشرائح الصغيرة. في هذه المرحلة (الربع الثالث من عام 3)، هناك العديد من البروتوكولات المستخدمة، حيث تحاول الصناعة بناء معايير رسمية للعديد منها.
تتضمن معايير D2D الرائدة الحالية ما يلي: i) ناقل الواجهة المتقدم (AIB، AIB2) الذي تم تعريفه في البداية بواسطة شركة Intel، وهو يوفر الآن استخدامًا مجانيًا، ii) ذاكرة النطاق الترددي العالي (HBM) حيث يتم تكديس قوالب DRAM فوق بعضها البعض فوق وسيط من السيليكون ومتصلة باستخدام TSVs، iii) المجموعة الفرعية للهندسة المعمارية الخاصة بالمجال المفتوح (ODSA)، وهي مجموعة صناعية، حددت واجهتين أخريين، Bunch of Wires (BoW) وOpenHBI.
يتيح لنا تصميم الشرائح غير المتجانسة استهداف تطبيقات أو قطاعات سوقية مختلفة عن طريق تعديل أو إضافة الشرائح الصغيرة ذات الصلة فقط مع الحفاظ على بقية النظام دون تغيير. ويمكن إطلاق التطورات الجديدة بشكل أسرع في السوق، باستثمارات أقل بكثير، حيث أن إعادة التصميم لن تؤثر إلا على ركيزة الحزمة المستخدمة لإيواء الشرائح الصغيرة.
على سبيل المثال، يمكن إعادة تصميم شريحة الحوسبة من TSMC 5nm إلى TSMC 3nm لدمج ذاكرة تخزين مؤقت L1 أكبر أو أنوية وحدة المعالجة المركزية ذات الأداء العالي، مع الحفاظ على بقية النظام دون تغيير. على الجانب الآخر من الطيف، يمكن فقط إعادة تصميم الشريحة الصغيرة التي تدمج SerDes للحصول على معدلات أسرع على عقد المعالجة الجديدة التي توفر المزيد من عرض النطاق الترددي للإدخال/الإخراج لتحسين وضع السوق.
يعد Intel PVC مثالاً مثاليًا للتكامل غير المتجانس (شرائح وظيفية مختلفة، ووحدة المعالجة المركزية، والمحولات، وما إلى ذلك) الذي يمكن أن نطلق عليه التكامل الرأسي، عندما يمتلك نفس صانع الرقائق مكونات الشرائح المختلفة (باستثناء أجهزة الذاكرة).
من المرجح أن يكون صانع الرقائق الذي يقوم بتطوير SoCs للتطبيقات المتطورة، مثل HPC أو مراكز البيانات أو الذكاء الاصطناعي أو الشبكات، من أوائل المستخدمين لبنيات الشرائح الصغيرة. يجب أن تكون الوظائف المحددة، مثل SRAMs لذاكرة التخزين المؤقت L3 الأكبر حجمًا، أو مسرعات الذكاء الاصطناعي، سواء معايير Ethernet أو PCIe أو CXL هي الواجهة الأولى المرشحة لتصميمات الشرائح الصغيرة.
عندما أثبت هؤلاء المتبنون الأوائل صحة الشرائح الصغيرة غير المتجانسة التي تستفيد من نماذج أعمال مختلفة متعددة، ومن الواضح جدوى التصنيع للاختبار والتعبئة، فسيؤدي ذلك إلى إنشاء نظام بيئي سيكون بالغ الأهمية لدعم هذه التكنولوجيا الجديدة. عند هذه النقطة، يمكننا أن نتوقع اعتمادًا أوسع في السوق، وليس فقط للتطبيقات عالية الأداء.
يمكننا أن نتخيل أن المنتجات غير المتجانسة يمكن أن تذهب إلى أبعد من ذلك، إذا أطلق صانع الرقائق في السوق نظامًا مصنوعًا من شرائح مختلفة تستهدف وظائف الحوسبة والإدخال والإخراج. يجعل هذا النهج التقارب على بروتوكول D2D أمرًا إلزاميًا، نظرًا لأن بائع IP الذي يقدم شرائح صغيرة مع بروتوكول D2D داخليًا لا يعد جذابًا للصناعة.
وقياسًا على ذلك، يوجد مبنى SoC في العقد الأول من القرن الحادي والعشرين، حيث تنتقل شركات أشباه الموصلات إلى دمج عناوين IP للتصميم المختلفة القادمة من مصادر مختلفة. سيصبح بائعو IP في العقد الأول من القرن الحادي والعشرين حتمًا بائعي الشرائح الصغيرة في عشرينيات القرن الحادي والعشرين. بالنسبة لوظائف معينة، مثل SerDes المتقدمة أو البروتوكولات المعقدة، مثل PCIe أو Ethernet أو CXL، يتمتع موردو IP بأفضل المعرفة لتنفيذها على السيليكون.
بالنسبة إلى تصميم IP المعقد، حتى لو تم تشغيل التحقق من المحاكاة قبل الشحن إلى العملاء، يجب على البائعين التحقق من صحة IP على السيليكون لضمان الأداء. بالنسبة لعنوان IP الرقمي، يمكن تنفيذ الوظيفة في FPGA لأنها أسرع وأقل تكلفة بكثير من صنع شريحة اختبار. بالنسبة لـ IP للإشارة المختلطة، مثل PHY القائم على SerDes، يحدد البائعون خيار شريحة الاختبار (TC) الذي يسمح لهم بالسيليكون لتمكينهم من تمييز IP في السيليكون قبل الشحن إلى العميل.
على الرغم من أن الشريحة الصغيرة ليست مجرد TC، لأنه سيتم اختبارها وتأهيلها على نطاق واسع قبل استخدامها في الميدان، فإن مقدار العمل الإضافي الذي يتعين على البائع القيام به لتطوير شريحة الإنتاج أقل بكثير. وبعبارة أخرى، فإن بائع IP هو في وضع أفضل لإصدار شريحة صغيرة مبنية من IP الخاص به بسرعة وتقديم أفضل TTM ممكن وتقليل المخاطر.
يميل نموذج الأعمال الخاص بالتكامل غير المتجانس إلى تفضيل الشرائح الصغيرة المتنوعة التي يصنعها مورد IP المعني (على سبيل المثال، ARM لشرائح وحدة المعالجة المركزية المستندة إلى ARM، وSi-Five لرقائق الحوسبة المستندة إلى Risc-V، وAlphawave لرقائق SerDes عالية السرعة) منذ إنهم مالكو Design IP.
لا شيء من هذا يمنع صانعي الرقائق من تصميم شرائحهم الخاصة وعناوين IP الخاصة بتصميم مجمع المصدر لحماية بنياتهم الفريدة أو تنفيذ وصلات داخلية محلية الصنع. على غرار SoC Design IP في العقد الأول من القرن الحادي والعشرين، سيتم ترجيح قرار الشراء أو اتخاذ القرار بشأن الشرائح الصغيرة بين حماية الكفاءة الأساسية وتحديد مصادر الوظائف غير المتمايزة.
لقد رأينا أن النمو التاريخي والحديث لأعمال تصميم IP IP منذ العقد الأول من القرن الحادي والعشرين قد تم الحفاظ عليه من خلال الاعتماد المستمر على المصادر الخارجية. سوف يتعايش كلا النموذجين (تم تصميم شريحة صغيرة داخليًا أو بواسطة بائع IP) ولكن التاريخ أظهر أن قرار الشراء في النهاية هو الذي يتخذ القرار.
يوجد الآن إجماع في الصناعة على أن التركيز الجنوني على تحقيق قانون مور لم يعد صالحًا بعد الآن بالنسبة لعقد التكنولوجيا المتقدمة، على سبيل المثال. 7 نانومتر وأدناه. لا يزال تكامل الرقائق يحدث، مع إضافة المزيد من الترانزستورات لكل ملم مربع في كل عقدة تقنية جديدة. ومع ذلك، فإن تكلفة كل ترانزستور تزداد ارتفاعًا مع كل عقدة جديدة أيضًا.
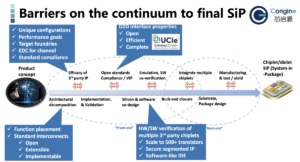
تعد تقنية Chiplet مبادرة رئيسية لتعزيز التكامل المتزايد لـ SoC الرئيسية أثناء استخدام العقد القديمة لوظائف أخرى. تعمل هذه الإستراتيجية المختلطة على تقليل التكلفة ومخاطر التصميم المرتبطة بدمج عناوين IP الخاصة بالتصميم الأخرى مباشرة في شركة نفط الجنوب الرئيسية.
تعتقد IPnest أن هذا الاتجاه سيكون له تأثيران رئيسيان في أعمال IP للواجهة، أحدهما سيكون النمو القوي لإيرادات IP D2D قريبًا (2021-2025)، والآخر هو إنشاء سوق شرائح غير متجانسة لزيادة السيليكون المتطور. سوق الملكية الفكرية.
ومن المتوقع أن يتكون هذا السوق من وظائف بروتوكولات معقدة مثل PCIe أو CXL أو Ethernet. قد يقرر بائعو IP الذين يقدمون واجهة IP مدمجة في I/O SoCs (USB وHDMI وDP وMIPI وما إلى ذلك) تقديم شرائح الإدخال/الإخراج بدلاً من ذلك.
ستكون فئات IP الأخرى المتأثرة بهذه الثورة هي بائعي IP لمترجمي ذاكرة SRAM، لذاكرة التخزين المؤقت L3. وبطبيعة الحال، من المتوقع أن يختلف حجم ذاكرة التخزين المؤقت اعتمادًا على المعالج. ومع ذلك، فإن تصميم شرائح ذاكرة التخزين المؤقت L3 يمكن أن يكون وسيلة لموردي IP لزيادة إيرادات Design IP من خلال تقديم نوع منتج جديد.
بالإضافة إلى ذلك، يمكن أن تتأثر فئة NVM IP بشكل إيجابي، حيث لم تعد NVM IP مدمجة في SoCs المصممة على عقد العملية المتقدمة. ستكون هذه طريقة لموردي NVM IP لإنشاء أعمال جديدة من خلال تقديم شرائح صغيرة.
نعتقد أن شرائح تسريع FPGA والذكاء الاصطناعي ستكون مصدرًا جديدًا للإيرادات لصانعي شرائح ASSP، لكننا لا نعتقد أنه يمكن تصنيفها بشكل صارم كبائعي IP.
إذا كان بائعو Interface IP هم الجهات الفاعلة الرئيسية في ثورة السيليكون هذه، فإن مسابك السيليكون التي تعالج العقد الأكثر تقدمًا مثل TSMC وSamsung ستلعب أيضًا دورًا رئيسيًا. لا نعتقد أن المسابك ستصمم شرائح صغيرة، لكن يمكنها اتخاذ قرار بدعم بائعي IP ودفعهم لتصميم شرائح صغيرة لاستخدامها مع SoCs بتقنية 3 نانومتر، كما يفعلون اليوم عند دعم بائعي IP المتقدمين لتسويق منتجات SerDes المتطورة الخاصة بهم كما IP الثابت في 7nm و5nm.
انتقال إنتل الأخير إلى 3rd ومن المتوقع أيضًا أن تستفيد المسابك التابعة لجهات خارجية من عناوين IP التابعة لجهات خارجية، بالإضافة إلى اعتماد الشرائح غير المتجانسة من قبل شركات أشباه الموصلات ذات الوزن الثقيل. في هذه الحالة، لا شك أن Hyperscalars مثل Microsoft وAmazon وGoogle ستتبنى أيضًا بنيات الشرائح الصغيرة... إذا لم تسبق شركة Intel في اعتماد الشرائح الصغيرة.
By إريك إستيف (دكتوراه) محلل ، مالك IPnest
شارك هذا المنشور عبر: المصدر: https://semiwiki.com/semiconductor-services/ipnest/303790-chiplet-are-you-ready-for-next-semiconductor-revolution/
- 2021
- مسرع
- المعجلات
- تبني
- تكنولوجيا متقدمة
- AI
- السماح
- أمازون
- AMD
- المحلل
- التطبيقات
- هندسة معمارية
- ARM
- الذكاء الاصطناعي
- الذكاء الاصطناعي (منظمة العفو الدولية)
- ASIC
- أفضل
- نساعدك في بناء
- ابني
- باقة
- حافلة
- الأعمال
- نموذج الأعمال
- يشترى
- دعوة
- الطاقة الإنتاجية
- تغيير
- رقاقة
- شيبس
- آت
- الشركات
- إحصاء
- الحوسبة
- إجماع
- التكاليف
- العملاء
- البيانات
- تقديم
- تصميم
- تطوير
- الأجهزة
- رقمي
- في وقت مبكر
- الأوائل
- النظام الإيكولوجي
- إلخ
- تطور
- الاسم الأول
- تركز
- FPGA
- مجانا
- وظيفة
- شراء مراجعات جوجل
- وحدات معالجة الرسومات
- تجمع
- متزايد
- التسويق
- مرتفع
- تاريخ
- منـزل
- HTTPS
- مهجنة
- التأثير
- القيمة الاسمية
- العالمية
- مبادرة
- التكامل
- إنتل
- رؤيتنا
- استثمار
- IP
- IT
- حفظ
- القفل
- إطلاق
- القانون
- قيادة
- تعلم
- ليد
- الرافعة المالية
- LINK
- لينكدين:
- آلة التعلم
- رائد
- صانع
- القيام ب
- تصنيع
- تجارة
- مایکروسافت
- ML
- نموذج
- الشبكات
- منتج جديد
- العقد
- عرض
- الوهب
- جاكيت
- خيار
- أخرى
- كاتوا ديلز
- التعبئة والتغليف
- ورق
- أداء
- المنتج
- الإنتــاج
- المنتجات
- حماية
- الحماية
- الأجور
- إعادة تصميم
- REST
- المخاطرة
- يجري
- سامسونج
- أشباه الموصلات
- الشحن
- محاكاة
- المقاس
- المعايير
- الإستراتيجيات
- الدعم
- مفاتيح
- نظام
- الهدف
- تقنيات
- تكنولوجيا
- تجربه بالعربي
- تيشرت
- us
- USB
- الباعة
- التحقق
- ورقة بيضاء
- كلمات
- للعمل
- سنوات
- التوزيعات للسهم الواحد