تم نشر ورقة فنية بعنوان "حل الاستدلال الفعال LLM على Intel GPU" من قبل باحثين في شركة Intel.
المستخلص:
"تم استخدام نماذج اللغات الكبيرة القائمة على المحولات (LLMs) على نطاق واسع في العديد من المجالات، وأصبحت كفاءة استدلال LLM موضوعًا ساخنًا في التطبيقات الحقيقية. ومع ذلك، عادةً ما يتم تصميم LLMs بشكل معقد في هيكل النموذج مع عمليات ضخمة وإجراء الاستدلال في وضع الانحدار التلقائي، مما يجعل تصميم نظام بكفاءة عالية مهمة صعبة.
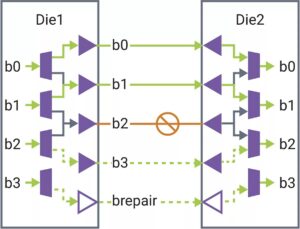
في هذه الورقة، نقترح حلًا فعالاً لاستدلال LLM مع زمن وصول منخفض وإنتاجية عالية. أولاً، نقوم بتبسيط طبقة فك تشفير LLM من خلال دمج حركة البيانات والعمليات الحكيمة لتقليل تردد الوصول إلى الذاكرة وتقليل زمن وصول النظام. نقترح أيضًا سياسة ذاكرة التخزين المؤقت لقطعة KV للاحتفاظ بمفتاح/قيمة رموز الطلب والاستجابة في ذاكرة فعلية منفصلة لإدارة ذاكرة الجهاز بشكل فعال، مما يساعد على تكبير حجم دفعة وقت التشغيل وتحسين إنتاجية النظام. تم تصميم نواة Scaled-Dot-Product-Attention المخصصة لتتوافق مع سياسة الدمج الخاصة بنا استنادًا إلى حل ذاكرة التخزين المؤقت لقطاع KV. نحن ننفذ حل الاستدلال LLM الخاص بنا على Intel GPU وننشره للعامة. بالمقارنة مع تطبيق HuggingFace القياسي، يحقق الحل المقترح زمن وصول رمزي أقل بما يصل إلى 7x وإنتاجية أعلى بمقدار 27x لبعض حاملي شهادات LLM المشهورين على وحدة معالجة الرسومات Intel."
أعثر على ورقة فنية هنا. نُشرت في ديسمبر 2023 (نسخة ما قبل الطباعة).
وو، هوي، يي غان، فنغ يوان، جينغ ما، وي تشو، يوتاو شو، هونغ تشو، يوهوا تشو، شياولي ليو، وجينغوي غو. "حل استدلال LLM فعال على Intel GPU." arXiv طبعة أولية arXiv:2401.05391 (2023).
القراءة ذات الصلة
LLM الاستدلال على وحدات المعالجة المركزية (إنتل)
تم نشر ورقة فنية بعنوان "استدلال LLM الفعال على وحدات المعالجة المركزية" من قبل باحثين في شركة إنتل.
سباقات الذكاء الاصطناعي إلى الحافة
يتم دفع الاستدلال وبعض التدريب إلى الأجهزة الأصغر حجمًا مع انتشار الذكاء الاصطناعي إلى التطبيقات الجديدة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://semiengineering.com/llm-inference-on-gpus-intel/
- :يكون
- $ UP
- 2023
- a
- الوصول
- يحقق
- AI
- أيضا
- an
- و
- التطبيقات
- هي
- AS
- At
- على أساس
- يصبح
- كان
- يجري
- by
- مخبأ
- تحدي
- مقارنة
- مؤسسة
- حسب الطلب
- البيانات
- ديسمبر
- تصميم
- تصميم
- جهاز
- الأجهزة
- الطُرق الفعّالة
- كفاءة
- فعال
- تكبير
- مجال
- في حالة
- تردد
- الصهر
- انصهار
- وحدة معالجة الرسوميات:
- وحدات معالجة الرسومات
- يملك
- مساعدة
- هنا
- مرتفع
- أعلى
- كونغ
- أفضل العروض
- لكن
- HTTPS
- تعانق الوجه
- تنفيذ
- التنفيذ
- تحسن
- in
- إنتل
- IT
- JPG
- احتفظ
- لغة
- كبير
- كمون
- طبقة
- ماجستير في القانون
- منخفض
- خفض
- القيام ب
- إدارة
- كثير
- هائل
- مباراة
- مكبر الصوت : يدعم، مع دعم ميكروفون مدمج لمنع الضوضاء
- موضة
- نموذج
- عارضات ازياء
- حركة
- جديد
- of
- on
- جاكيت
- عمليات
- لنا
- ورق
- نفذ
- مادي
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- سياسة
- الرائج
- اقترح
- المقترح
- علانية
- نشر
- نشرت
- دفع
- سباقات
- حقيقي
- تخفيض
- طلب
- الباحثين
- استجابة
- قطعة
- مستقل
- تبسيط
- المقاس
- الأصغر
- حل
- بعض
- ينتشر
- معيار
- بناء
- نظام
- مهمة
- تقني
- •
- الإنتاجية
- بعنوان
- إلى
- رمز
- الرموز
- موضوع
- قادة الإيمان
- مستعمل
- عادة
- وكان
- we
- على نحو واسع
- مع
- يوان
- زفيرنت