Pandas هي مكتبة مفتوحة المصدر قوية ومستخدمة على نطاق واسع لمعالجة البيانات وتحليلها باستخدام Python. تتمثل إحدى ميزاته الرئيسية في القدرة على تجميع البيانات باستخدام وظيفة groupby عن طريق تقسيم DataFrame إلى مجموعات بناءً على عمود واحد أو أكثر ثم تطبيق وظائف التجميع المختلفة على كل واحدة منها.

صورة من Unsplash
• groupby وظيفة قوية بشكل لا يصدق ، لأنها تسمح لك بسرعة تلخيص وتحليل مجموعات البيانات الكبيرة. على سبيل المثال ، يمكنك تجميع مجموعة بيانات حسب عمود معين وحساب متوسط أو مجموع أو عدد الأعمدة المتبقية لكل مجموعة. يمكنك أيضًا التجميع حسب عدة أعمدة للحصول على فهم أكثر دقة لبياناتك. بالإضافة إلى ذلك ، يسمح لك بتطبيق وظائف التجميع المخصصة ، والتي يمكن أن تكون أداة قوية جدًا لمهام تحليل البيانات المعقدة.
في هذا البرنامج التعليمي ، ستتعلم كيفية استخدام وظيفة groupby في Pandas لتجميع أنواع مختلفة من البيانات وتنفيذ عمليات تجميع مختلفة. بنهاية هذا البرنامج التعليمي ، يجب أن تكون قادرًا على استخدام هذه الوظيفة لتحليل البيانات وتلخيصها بطرق مختلفة.
يتم استيعاب المفاهيم عند ممارستها جيدًا وهذا ما سنفعله بعد ذلك ، أي التدريب العملي على وظيفة Pandas groupby. يوصى باستخدام أ مفكرة Jupyter لهذا البرنامج التعليمي حيث يمكنك رؤية الإخراج في كل خطوة.
توليد بيانات العينة
قم باستيراد المكتبات التالية:
- Pandas: لإنشاء إطار بيانات وتطبيق المجموعة حسب
- عشوائي - لتوليد بيانات عشوائية
- طباعة - لطباعة القواميس
import pandas as pd
import random
import pprint
بعد ذلك ، سنقوم بتهيئة إطار بيانات فارغ ونملأ القيم لكل عمود كما هو موضح أدناه:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
نصيحة إضافية - تتمثل الطريقة الأنظف للقيام بالمهمة نفسها في إنشاء قاموس لجميع المتغيرات والقيم وتحويله لاحقًا إلى إطار بيانات.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
يشبه إطار البيانات الإطار الموضح أدناه. عند تشغيل هذا الرمز ، لن تتطابق بعض القيم لأننا نستخدم عينة عشوائية.
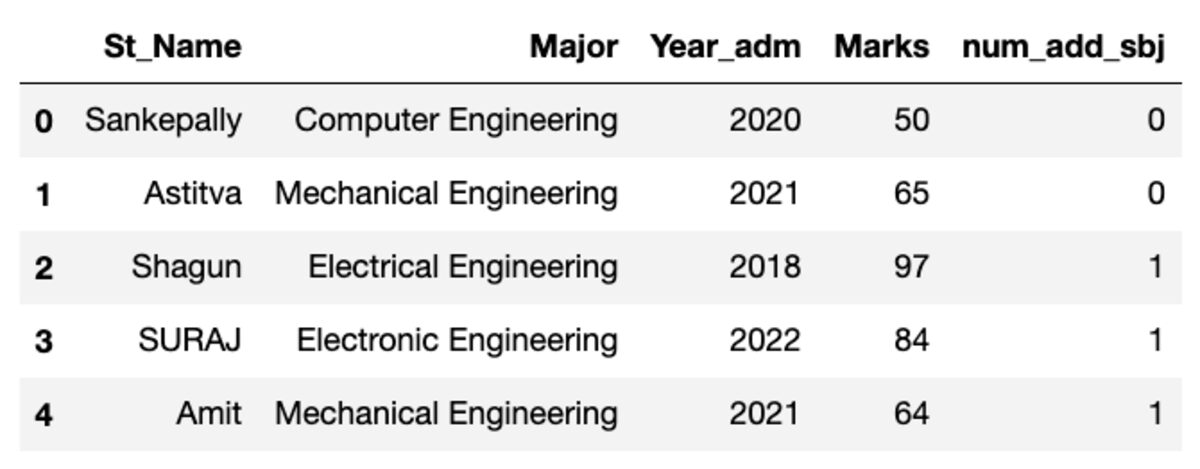
صنع المجموعات
دعنا نجمع البيانات حسب الموضوع "الرئيسي" ونطبق مرشح المجموعة لمعرفة عدد السجلات التي تقع في هذه المجموعة.
groups = df.groupby('Major')
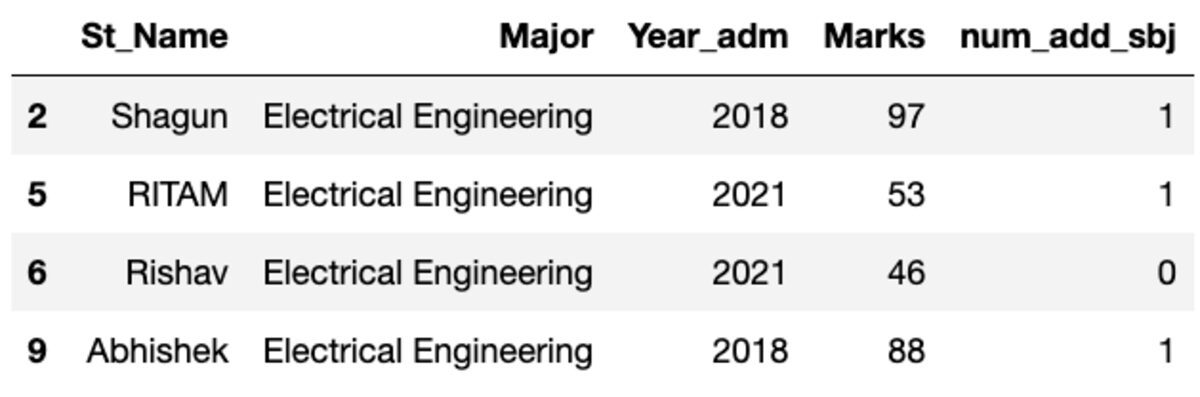
groups.get_group('Electrical Engineering')
إذن ، أربعة طلاب ينتمون إلى تخصص الهندسة الكهربائية.
يمكنك أيضًا التجميع حسب أكثر من عمود واحد (رئيسي و num_add_sbj في هذه الحالة).
groups = df.groupby(['Major', 'num_add_sbj'])
لاحظ أنه يمكن تطبيق جميع الوظائف التجميعية التي يمكن تطبيقها على مجموعات ذات عمود واحد على مجموعات ذات أعمدة متعددة. بالنسبة لبقية البرنامج التعليمي ، دعنا نركز على الأنواع المختلفة من التجميعات باستخدام عمود واحد كمثال.
لنقم بإنشاء مجموعات باستخدام groupby في عمود "Major".
groups = df.groupby('Major')تطبيق الوظائف المباشرة
لنفترض أنك تريد إيجاد متوسط العلامات في كل تخصص. ماذا كنت ستفعل؟
- اختر عمود العلامات
- تطبيق متوسط الوظيفة
- تطبيق دالة دائرية لتقريب العلامات إلى منزلتين عشريتين (اختياري)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
مجموع
هناك طريقة أخرى لتحقيق نفس النتيجة وهي استخدام دالة تجميعية كما هو موضح أدناه:
groups['Marks'].aggregate('mean').round(2)
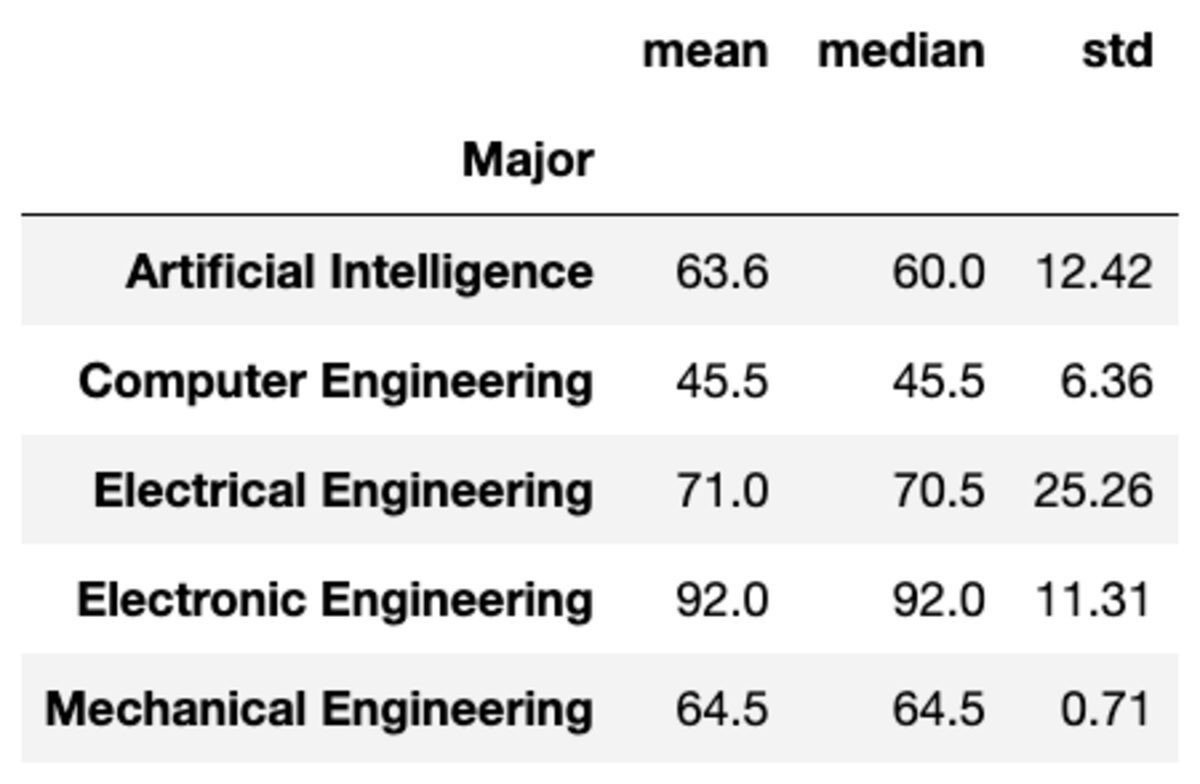
يمكنك أيضًا تطبيق مجموعات متعددة على المجموعات عن طريق تمرير الوظائف كقائمة سلاسل.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
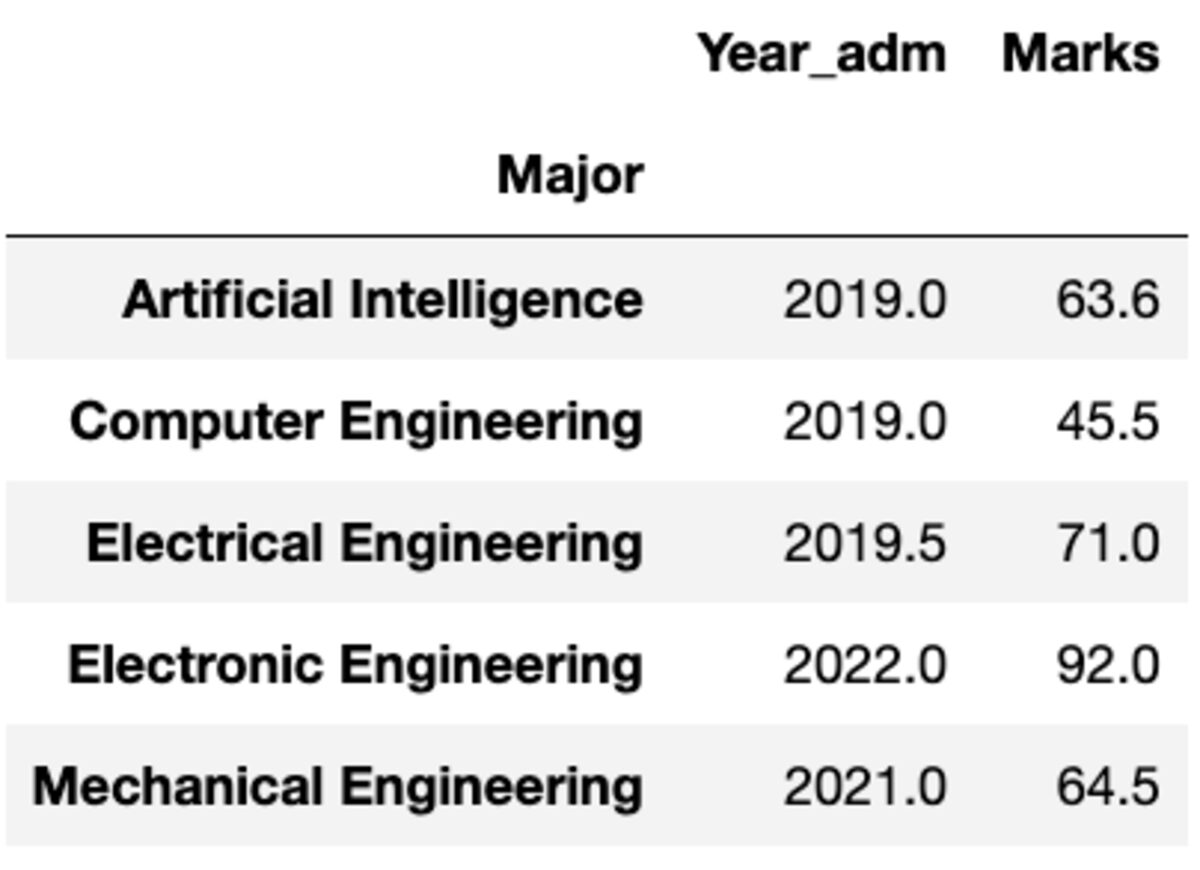
ولكن ماذا لو احتجت إلى تطبيق دالة مختلفة على عمود مختلف. لا تقلق. يمكنك أيضًا القيام بذلك عن طريق تمرير زوج {العمود: الوظيفة}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
التحويلات
قد تحتاج إلى إجراء تحويلات مخصصة إلى عمود معين والتي يمكن تحقيقها بسهولة باستخدام groupby (). دعنا نحدد عدديًا قياسيًا مشابهًا لذلك المتاح في وحدة المعالجة المسبقة في sklearn. يمكنك تحويل جميع الأعمدة عن طريق استدعاء طريقة التحويل وتمرير الوظيفة المخصصة.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
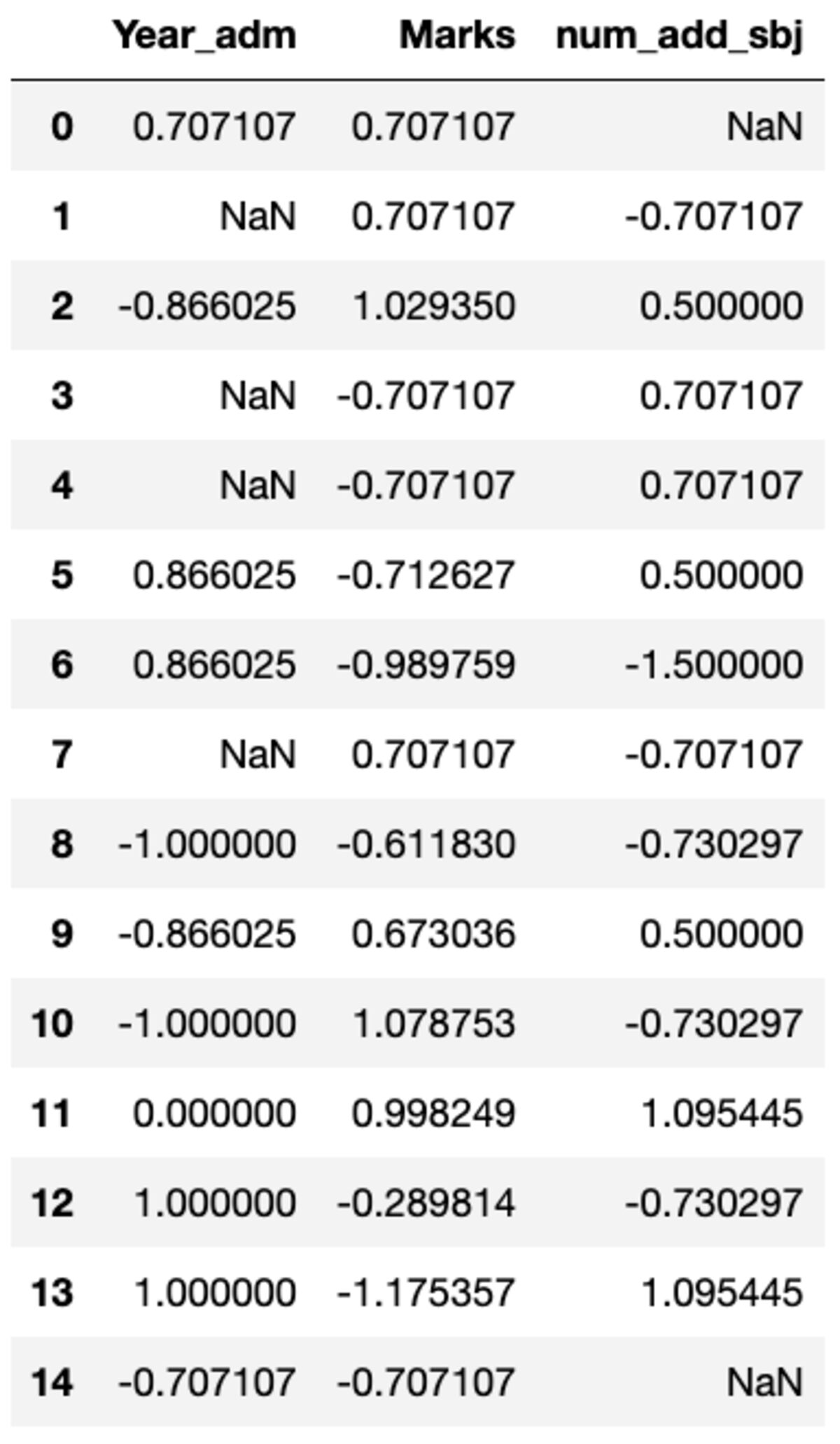
لاحظ أن "NaN" يمثل مجموعات ذات انحراف معياري صفري.
الفرز
قد ترغب في التحقق من "التخصص" الذي يكون أداءه ضعيفًا ، أي الذي يكون متوسط "علامات" الطالب فيه أقل من 60. يتطلب منك تطبيق طريقة التصفية على المجموعات التي تحتوي على وظيفة بداخلها. يستخدم الكود أدناه ملف وظيفة لامدا لتحقيق النتائج المصفاة.
groups.filter(lambda x: x['Marks'].mean() 60)

الاسم الأول
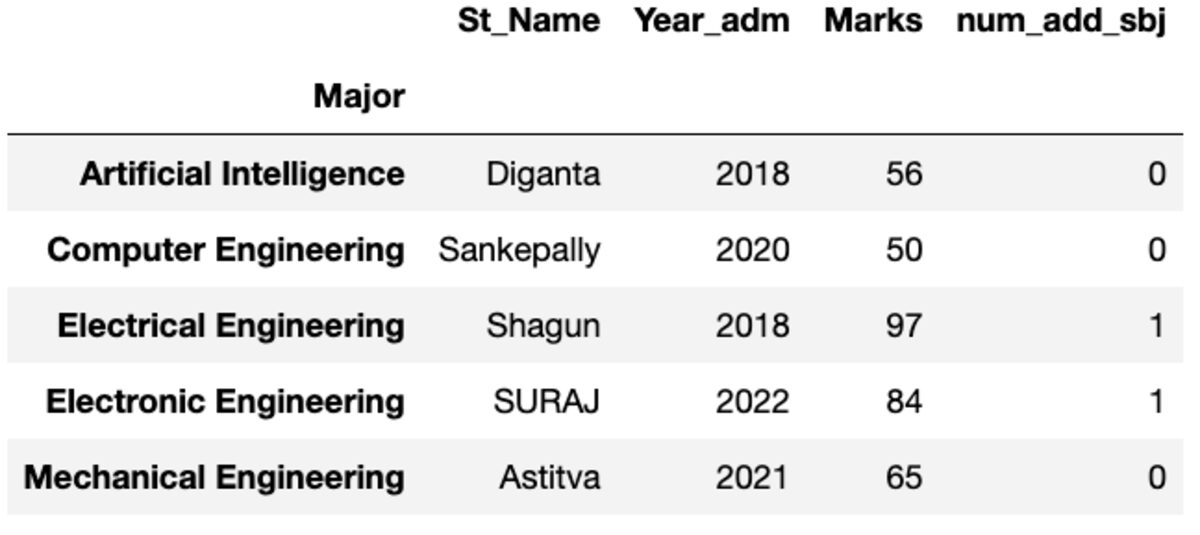
يمنحك أول مثيل له مرتبة حسب الفهرس.
groups.first()
وصف
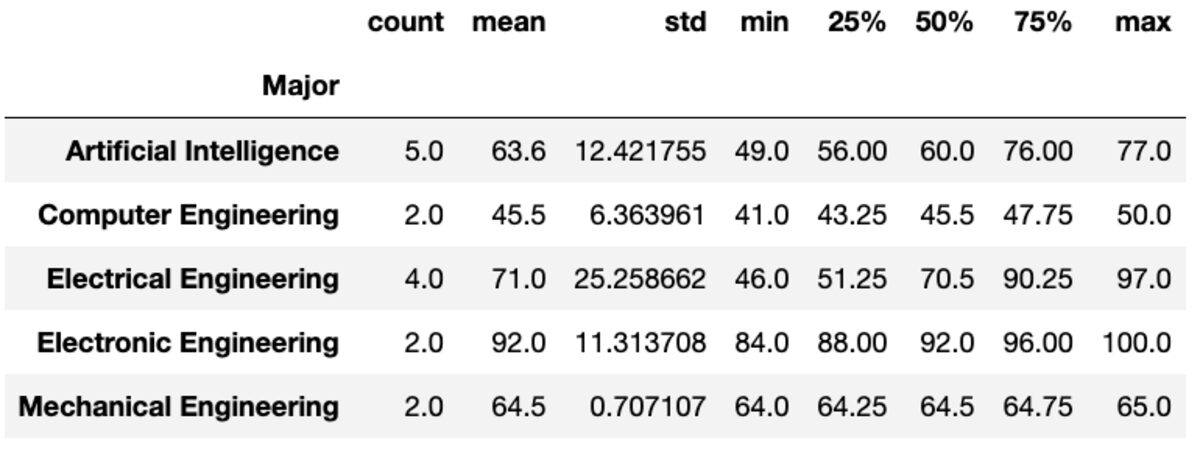
تقوم طريقة "description" بإرجاع إحصائيات أساسية مثل العدد ، والمتوسط ، والأرقام القياسية ، والدقيقة ، والحد الأقصى ، وما إلى ذلك للأعمدة المحددة.
groups['Marks'].describe()
المقاس
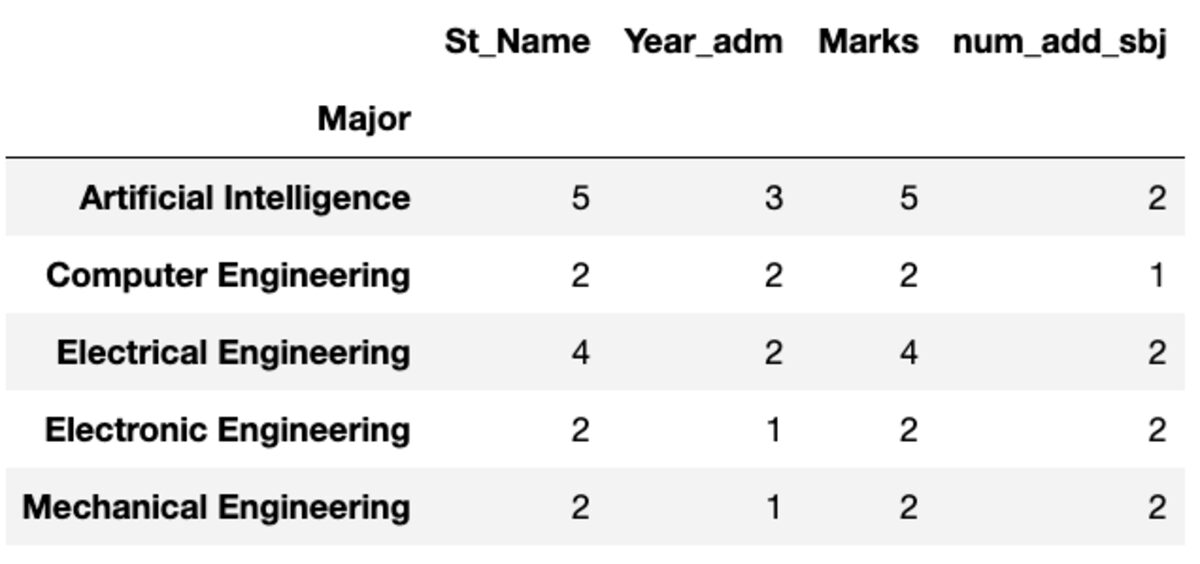
الحجم ، كما يوحي الاسم ، يُرجع حجم كل مجموعة من حيث عدد السجلات.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64كونت و نونيك
يقوم "Count" بإرجاع جميع القيم بينما يقوم "Nunique" بإرجاع القيم الفريدة فقط في تلك المجموعة.
groups.count()
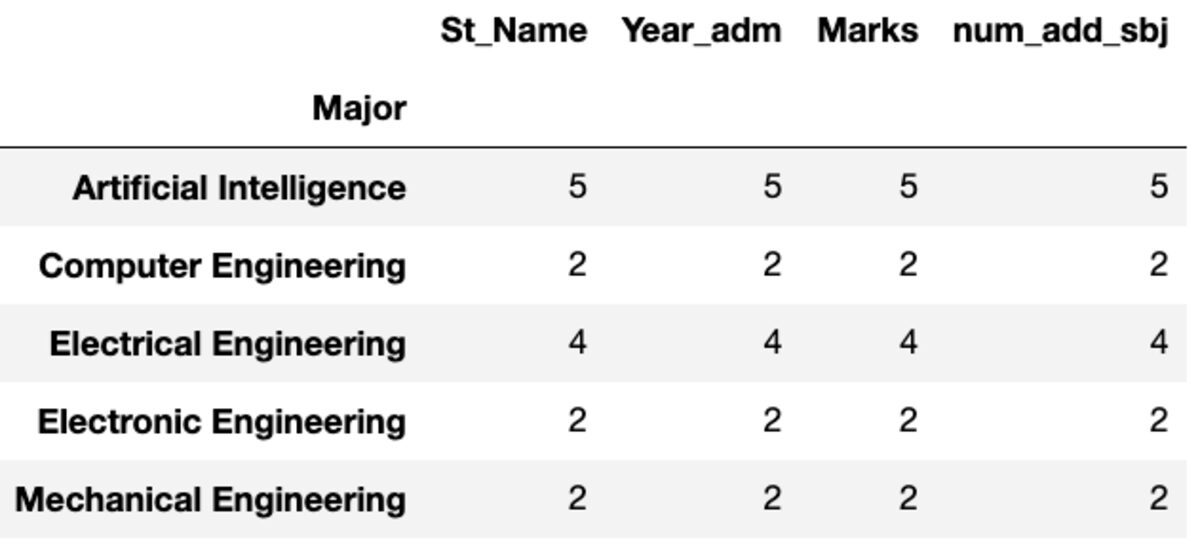
groups.nunique()
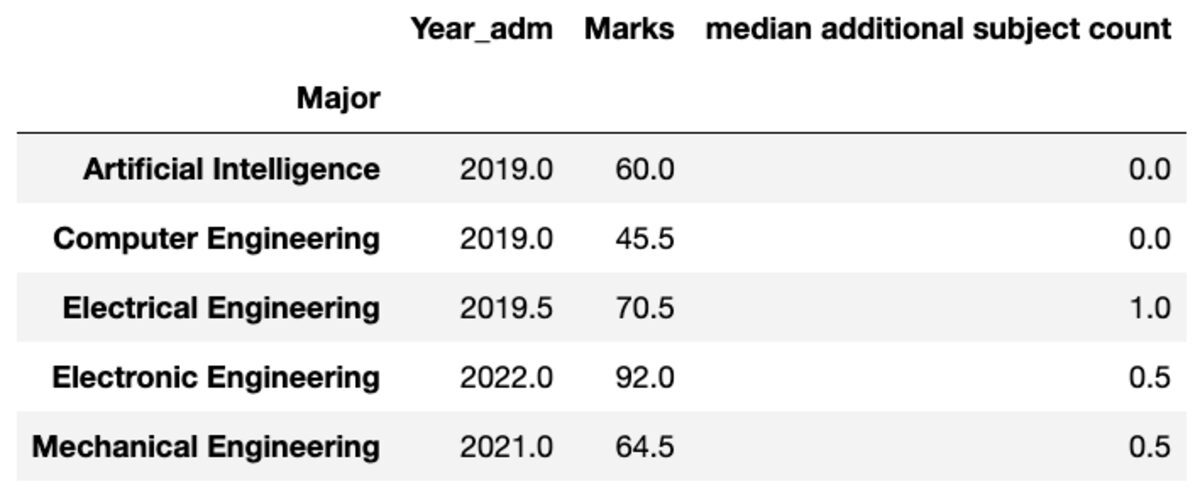
إعادة تسمية
يمكنك أيضًا إعادة تسمية اسم الأعمدة المجمعة حسب تفضيلاتك.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
- كن واضحا بشأن الغرض من groupby: هل تحاول تجميع البيانات حسب عمود واحد للحصول على متوسط عمود آخر؟ أم أنك تحاول تجميع البيانات حسب عدة أعمدة للحصول على عدد الصفوف في كل مجموعة؟
- افهم فهرسة إطار البيانات: تستخدم وظيفة groupby الفهرس لتجميع البيانات. إذا كنت تريد تجميع البيانات حسب عمود ، فتأكد من تعيين العمود كفهرس أو يمكنك استخدام .set_index ()
- استخدم دالة التجميع المناسبة: يمكن استخدامه مع وظائف التجميع المختلفة مثل المتوسط () ، المجموع () ، العدد () ، الحد الأدنى () ، الحد الأقصى ()
- استخدم المعلمة as_index: عند التعيين إلى False ، تخبر هذه المعلمة الباندا باستخدام الأعمدة المجمعة كأعمدة عادية بدلاً من الفهرس.
يمكنك أيضًا استخدام groupby () جنبًا إلى جنب مع وظائف الباندا الأخرى مثل pivot_table () و crosstab () و cut () لاستخراج المزيد من الأفكار من بياناتك.
تعد وظيفة groupby أداة قوية لتحليل البيانات ومعالجتها لأنها تتيح لك تجميع صفوف البيانات بناءً على عمود واحد أو أكثر ثم إجراء عمليات حسابية مجمعة على المجموعات. أظهر البرنامج التعليمي طرقًا مختلفة لاستخدام وظيفة groupby بمساعدة أمثلة التعليمات البرمجية. آمل أن يوفر لك فهمًا للخيارات المختلفة التي تأتي معها وأيضًا كيف تساعد في تحليل البيانات.
فيدي تشو هو استراتيجي للذكاء الاصطناعي وقائد للتحول الرقمي يعمل عند تقاطع المنتج والعلوم والهندسة لبناء أنظمة تعلم آلي قابلة للتطوير. هي قائدة ابتكار حائزة على جوائز ، ومؤلفة ، ومتحدثة دولية. إنها في مهمة لإضفاء الطابع الديمقراطي على التعلم الآلي وكسر المصطلحات اللغوية للجميع ليكونوا جزءًا من هذا التحول.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- القدرة
- ماهرون
- التأهيل
- تحقق
- إضافي
- وبالإضافة إلى ذلك
- تجميع
- AI
- الكل
- يسمح
- تحليل
- تحليل
- و
- آخر
- تطبيقي
- التقديم
- تطبيق
- مناسب
- مصطنع
- الذكاء الاصطناعي
- المؤلفة
- متاح
- المتوسط
- الحائز على جائزة
- على أساس
- الأساسية
- أقل من
- التكنولوجيا الحيوية
- استراحة
- نساعدك في بناء
- حساب
- دعوة
- حقيبة
- التحقق
- واضح
- الكود
- عمود
- الأعمدة
- تأتي
- مجمع
- الكمبيوتر
- هندسة الكمبيوتر
- خلق
- خلق
- على
- البيانات
- تحليل البيانات
- قواعد البيانات
- دمقرطة
- تظاهر
- الانحراف
- مختلف
- رقمي
- التحول الرقمي
- مباشرة
- لا
- كل
- بسهولة
- على نحو فعال
- الهندسة الكهربائية
- إلكتروني
- الهندسة
- إلخ
- كل شخص
- مثال
- أمثلة
- استخراج
- فال
- المميزات
- شغل
- تصفية
- الاسم الأول
- تركز
- متابعيك
- FRAME
- تبدأ من
- وظيفة
- وظائف
- توليد
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- يعطي
- الذهاب
- تجمع
- مجموعات
- تشابك الايدى
- مساعدة
- أمل
- كيفية
- كيفية
- HTML
- HTTPS
- استيراد
- in
- لا يصدق
- مؤشر
- الابتكار
- رؤى
- مثل
- بدلًا من ذلك
- رؤيتنا
- عالميا
- تقاطع طرق
- IT
- رطانة
- KD nuggets
- القفل
- كبير
- زعيم
- تعلم
- تعلم
- المكتبات
- المكتبة
- قائمة
- تبدو
- آلة
- آلة التعلم
- رائد
- جعل
- تلاعب
- كثير
- مباراة
- ماكس
- ميكانيكي
- الهندسة الميكانيكية
- متوسط
- طريقة
- الرسالة
- وحدة
- الأكثر من ذلك
- متعدد
- الاسم
- أسماء
- حاجة
- التالي
- عدد
- ONE
- المصدر المفتوح
- عمليات
- مزيد من الخيارات
- أخرى
- الباندا
- المعلمة
- جزء
- خاص
- مرور
- نفذ
- وجهات
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- قوي
- طباعة
- المنتج
- ويوفر
- غرض
- بايثون
- بسرعة
- عشوائية
- موصى به
- تسجيل
- منتظم
- المتبقية
- يمثل
- يتطلب
- REST
- نتيجة
- النتائج
- عائد أعلى
- عائدات
- ريتشارد
- دائري
- تشغيل
- نفسه
- تحجيم
- علوم
- طقم
- ينبغي
- أظهرت
- مماثل
- عزباء
- المقاس
- بعض
- مكبرات الصوت
- محدد
- معيار
- إحصائيات
- خطوة
- الاستراتيجيين
- طالب
- عدد الطلبة
- موضوع
- وتقترح
- تلخيص
- أنظمة
- مهمة
- المهام
- يروي
- سياسة الحجب وتقييد الوصول
- •
- معلومات سرية
- إلى
- أداة
- تحول
- تحول
- التحولات
- البرنامج التعليمي
- أنواع
- فهم
- فريد من نوعه
- تستخدم
- القيم
- مختلف
- طرق
- ابحث عن
- التي
- سوف
- عامل
- سوف
- X
- عام
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت
- صفر







