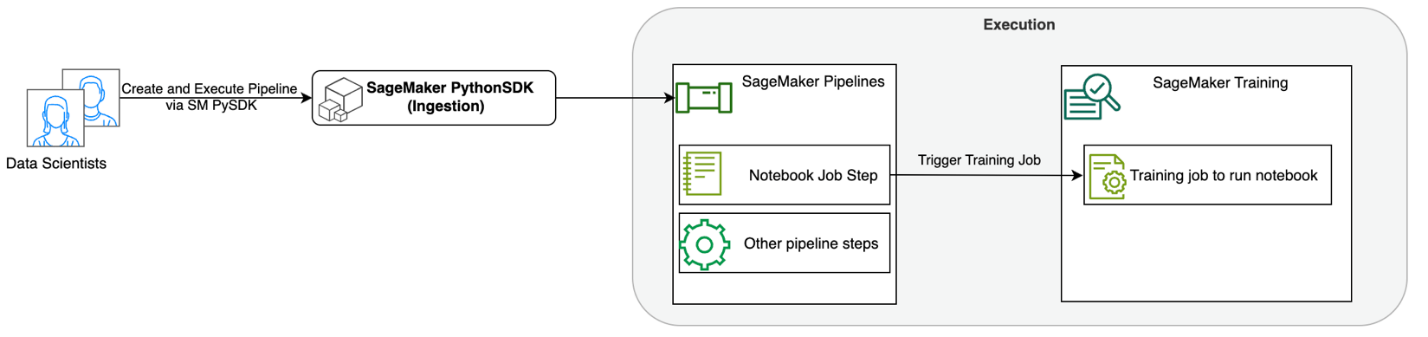
أمازون ساجميكر ستوديو يوفر حلاً مُدارًا بالكامل لعلماء البيانات لإنشاء نماذج التعلم الآلي (ML) وتدريبها ونشرها بشكل تفاعلي. وظائف الكمبيوتر الدفتري Amazon SageMaker السماح لعلماء البيانات بتشغيل دفاتر الملاحظات الخاصة بهم عند الطلب أو وفقًا لجدول زمني ببضع نقرات في SageMaker Studio. من خلال هذا الإطلاق، يمكنك تشغيل دفاتر الملاحظات برمجيًا كمهام باستخدام واجهات برمجة التطبيقات التي توفرها خطوط أنابيب Amazon SageMaker، ميزة تنسيق سير عمل ML الأمازون SageMaker. علاوة على ذلك، يمكنك إنشاء سير عمل تعلم الآلة متعدد الخطوات مع العديد من دفاتر الملاحظات التابعة باستخدام واجهات برمجة التطبيقات هذه.
SageMaker Pipelines عبارة عن أداة أصلية لتنسيق سير العمل لبناء مسارات تعلم الآلة التي تستفيد من تكامل SageMaker المباشر. يتكون كل خط أنابيب SageMaker من سلموالتي تتوافق مع المهام الفردية مثل المعالجة أو التدريب أو معالجة البيانات باستخدام أمازون EMR. تتوفر الآن مهام دفتر ملاحظات SageMaker كنوع خطوة مضمن في مسارات SageMaker. يمكنك استخدام خطوة مهمة دفتر الملاحظات هذه لتشغيل دفاتر الملاحظات بسهولة كمهام باستخدام بضعة أسطر فقط من التعليمات البرمجية باستخدام الأمازون SageMaker Python SDK. بالإضافة إلى ذلك، يمكنك دمج العديد من دفاتر الملاحظات التابعة معًا لإنشاء سير عمل في شكل رسوم بيانية غير دورية موجهة (DAGs). يمكنك بعد ذلك تشغيل مهام دفاتر الملاحظات أو DAGs هذه وإدارتها وتصورها باستخدام SageMaker Studio.
يستخدم علماء البيانات حاليًا SageMaker Studio لتطوير دفاتر ملاحظات Jupyter الخاصة بهم بشكل تفاعلي ثم استخدام مهام دفاتر ملاحظات SageMaker لتشغيل دفاتر الملاحظات هذه كمهام مجدولة. يمكن تشغيل هذه الوظائف على الفور أو وفقًا لجدول زمني متكرر دون الحاجة إلى عمال البيانات لإعادة بناء التعليمات البرمجية كوحدات Python. تتضمن بعض حالات الاستخدام الشائعة للقيام بذلك ما يلي:
- تشغيل أجهزة الكمبيوتر المحمولة طويلة الأمد في الخلفية
- تشغيل نموذج الاستدلال بانتظام لإنشاء التقارير
- الارتقاء من إعداد مجموعات بيانات العينات الصغيرة إلى العمل مع بيانات ضخمة بحجم بيتابايت
- إعادة تدريب ونشر النماذج على بعض الإيقاع
- جدولة المهام لجودة النموذج أو مراقبة انجراف البيانات
- استكشاف مساحة المعلمة للحصول على نماذج أفضل
على الرغم من أن هذه الوظيفة تجعل من السهل على العاملين في مجال البيانات أتمتة دفاتر الملاحظات المستقلة، إلا أن سير عمل تعلم الآلة غالبًا ما يتكون من عدة دفاتر ملاحظات، يؤدي كل منها مهمة محددة ذات تبعيات معقدة. على سبيل المثال، يجب أن يحتوي دفتر الملاحظات الذي يراقب انحراف بيانات النموذج على خطوة مسبقة تسمح باستخراج البيانات الجديدة وتحويلها وتحميلها (ETL) ومعالجتها وخطوة لاحقة لتحديث النموذج والتدريب في حالة ملاحظة انحراف كبير . علاوة على ذلك، قد يرغب علماء البيانات في تشغيل سير العمل بأكمله وفقًا لجدول زمني متكرر لتحديث النموذج بناءً على البيانات الجديدة. لتمكينك من أتمتة دفاتر الملاحظات الخاصة بك بسهولة وإنشاء مهام سير العمل المعقدة، تتوفر الآن مهام دفتر ملاحظات SageMaker كخطوة في خطوط أنابيب SageMaker. في هذا المنشور، نعرض كيف يمكنك حل حالات الاستخدام التالية باستخدام بضعة أسطر من التعليمات البرمجية:
- قم بتشغيل دفتر ملاحظات مستقل برمجيًا على الفور أو وفقًا لجدول زمني متكرر
- قم بإنشاء مهام سير عمل متعددة الخطوات لأجهزة الكمبيوتر المحمولة مثل DAGs لأغراض التكامل المستمر والتسليم المستمر (CI/CD) التي يمكن إدارتها عبر SageMaker Studio UI
حل نظرة عامة
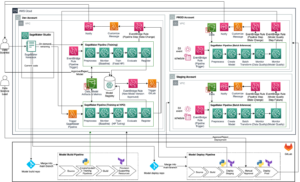
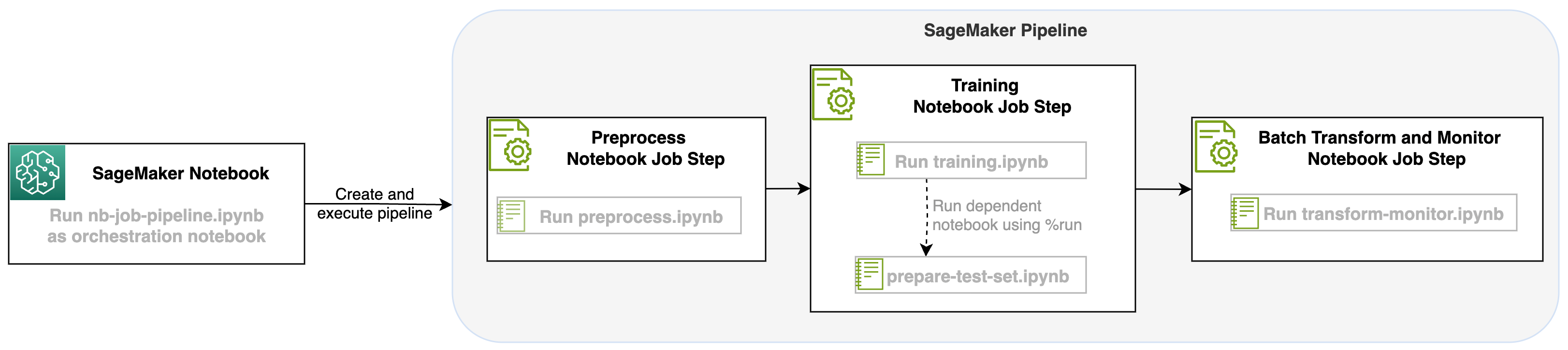
يوضح الرسم البياني التالي بنية الحل لدينا. يمكنك استخدام SageMaker Python SDK لتشغيل مهمة دفتر ملاحظات واحدة أو سير عمل. تقوم هذه الميزة بإنشاء مهمة تدريب SageMaker لتشغيل دفتر الملاحظات.
في الأقسام التالية، نستعرض نموذجًا لحالة استخدام تعلم الآلة ونعرض الخطوات اللازمة لإنشاء سير عمل لمهام دفتر الملاحظات، وتمرير المعلمات بين خطوات دفتر الملاحظات المختلفة، وجدولة سير العمل، ومراقبته عبر SageMaker Studio.
بالنسبة لمشكلة ML الخاصة بنا في هذا المثال، نقوم ببناء نموذج تحليل المشاعر، وهو نوع من مهام تصنيف النص. تشمل التطبيقات الأكثر شيوعًا لتحليل المشاعر مراقبة وسائل التواصل الاجتماعي وإدارة دعم العملاء وتحليل تعليقات العملاء. مجموعة البيانات المستخدمة في هذا المثال هي مجموعة بيانات Stanford Sentiment Treebank (SST2)، والتي تتكون من مراجعات الأفلام بالإضافة إلى عدد صحيح (0 أو 1) يشير إلى المشاعر الإيجابية أو السلبية للمراجعة.
فيما يلي مثال على ملف data.csv الملف المطابق لمجموعة بيانات SST2، ويعرض القيم في أول عمودين له. لاحظ أن الملف يجب ألا يحتوي على أي رأس.
| عمود 1 | عمود 2 |
| 0 | إخفاء الإفرازات الجديدة من الوحدات الأبوية |
| 0 | لا يحتوي على أي ذكاء، فقط الكمامات المجهدة |
| 1 | يحب شخصياته وينقل شيئًا جميلًا عن الطبيعة البشرية |
| 0 | يظل راضيًا تمامًا عن البقاء على حاله طوال الوقت |
| 0 | حول أسوأ الكليشيهات المتعلقة بالانتقام من المهووسين التي يمكن لصانعي الأفلام أن يتخلصوا منها |
| 0 | وهذا أمر مأساوي للغاية بحيث لا يستحق مثل هذه المعاملة السطحية |
| 1 | يوضح أن مخرج أفلام هوليوود الرائجة مثل "الألعاب الوطنية" لا يزال بإمكانه إنتاج فيلم شخصي صغير ذو تأثير عاطفي. |
في مثال ML هذا، يجب علينا تنفيذ عدة مهام:
- قم بإجراء هندسة الميزات لإعداد مجموعة البيانات هذه بتنسيق يمكن لنموذجنا فهمه.
- هندسة ما بعد الميزة، قم بتشغيل خطوة تدريبية تستخدم المحولات.
- قم بإعداد الاستدلال الدفعي باستخدام النموذج المضبوط بدقة للمساعدة في التنبؤ بميول المراجعات الجديدة الواردة.
- قم بإعداد خطوة مراقبة البيانات حتى نتمكن من مراقبة بياناتنا الجديدة بانتظام بحثًا عن أي انحراف في الجودة قد يتطلب منا إعادة تدريب أوزان النموذج.
مع إطلاق مهمة دفتر الملاحظات كخطوة في مسارات SageMaker، يمكننا تنسيق سير العمل هذا، والذي يتكون من ثلاث خطوات متميزة. يتم تطوير كل خطوة من خطوات سير العمل في دفتر ملاحظات مختلف، والتي يتم بعد ذلك تحويلها إلى خطوات مهام دفتر ملاحظات مستقلة ويتم توصيلها كمسار:
- تجهيزها - قم بتنزيل مجموعة بيانات SST2 العامة من خدمة تخزين أمازون البسيطة (Amazon S3) وقم بإنشاء ملف CSV للدفتر في الخطوة 2 لتشغيله. مجموعة بيانات SST2 عبارة عن مجموعة بيانات لتصنيف النص تحتوي على علامتين (0 و1) وعمود نصي لتصنيفه.
- قادة الإيمان - خذ ملف CSV ذو الشكل وقم بإجراء الضبط الدقيق باستخدام BERT لتصنيف النص باستخدام مكتبات Transformers. نستخدم دفترًا لإعداد بيانات الاختبار كجزء من هذه الخطوة، وهو عبارة عن تبعية لخطوة الضبط الدقيق والاستدلال الدفعي. عند اكتمال الضبط الدقيق، يتم تشغيل هذا الكمبيوتر الدفتري باستخدام Run Magic وإعداد مجموعة بيانات اختبار لاستنتاج العينة باستخدام النموذج الذي تم ضبطه بدقة.
- تحويل ومراقبة – إجراء استنتاج دفعة وإعداد جودة البيانات من خلال مراقبة النموذج للحصول على اقتراح مجموعة بيانات أساسية.
قم بتشغيل دفاتر الملاحظات
نموذج التعليمات البرمجية لهذا الحل متاح على GitHub جيثب:.
يشبه إنشاء خطوة مهمة دفتر ملاحظات SageMaker إنشاء خطوات SageMaker Pipeline الأخرى. في مثال دفتر الملاحظات هذا، نستخدم SageMaker Python SDK لتنظيم سير العمل. لإنشاء خطوة دفتر ملاحظات في SageMaker Pipelines، يمكنك تحديد المعلمات التالية:
- دفتر الإدخال – اسم دفتر الملاحظات الذي ستقوم خطوة دفتر الملاحظات هذه بتنسيقه. هنا يمكنك تمرير المسار المحلي إلى دفتر الإدخال. بشكل اختياري، إذا كان دفتر الملاحظات هذا يحتوي على دفاتر ملاحظات أخرى قيد التشغيل، فيمكنك تمريرها في ملف
AdditionalDependenciesمعلمة خطوة مهمة دفتر الملاحظات. - صورة URI – صورة Docker خلف خطوة مهمة دفتر الملاحظات. يمكن أن تكون هذه هي الصور المحددة مسبقًا التي يوفرها SageMaker بالفعل أو صورة مخصصة قمت بتحديدها ودفعتها إليها سجل الأمازون المرنة للحاويات (أمازون إي سي آر). ارجع إلى قسم الاعتبارات في نهاية هذا المنشور للحصول على الصور المدعومة.
- اسم النواة – اسم النواة التي تستخدمها في SageMaker Studio. تم تسجيل مواصفات النواة هذه في الصورة التي قدمتها.
- نوع المثيل (اختياري) - و الأمازون الحوسبة المرنة السحابية (Amazon EC2) نوع المثيل الموجود خلف مهمة دفتر الملاحظات التي حددتها والتي سيتم تشغيلها.
- المعلمات (اختياري) – المعلمات التي يمكنك تمريرها والتي ستكون متاحة لجهاز الكمبيوتر المحمول الخاص بك. يمكن تعريفها في أزواج القيمة الرئيسية. بالإضافة إلى ذلك، يمكن تعديل هذه المعلمات بين عمليات تشغيل مهام دفتر الملاحظات المختلفة أو عمليات تشغيل المسارات.
يحتوي مثالنا على إجمالي خمسة دفاتر ملاحظات:
- ملحوظة-الوظيفة-pipeline.ipynb – هذا هو دفتر ملاحظاتنا الرئيسي حيث نحدد خط الأنابيب وسير العمل لدينا.
- preprocess.ipynb - يعد هذا الدفتر الخطوة الأولى في سير العمل لدينا ويحتوي على الكود الذي سيسحب مجموعة بيانات AWS العامة وينشئ ملف CSV منها.
- Training.ipynb – يعد هذا الدفتر الخطوة الثانية في سير العمل لدينا ويحتوي على رمز لأخذ ملف CSV من الخطوة السابقة وإجراء التدريب المحلي والضبط الدقيق. تحتوي هذه الخطوة أيضًا على تبعية من
prepare-test-set.ipynbدفتر ملاحظات لسحب مجموعة بيانات اختبارية لاستدلال العينة باستخدام النموذج المضبوط بدقة. - إعداد اختبار set.ipynb - يقوم هذا الدفتر بإنشاء مجموعة بيانات اختبارية سيستخدمها دفتر التدريب الخاص بنا في خطوة خط الأنابيب الثانية ويستخدم لاستنتاج العينة باستخدام النموذج المضبوط بدقة.
- تحويل مراقب.ipynb - يمثل هذا الكمبيوتر الدفتري الخطوة الثالثة في سير العمل لدينا ويأخذ نموذج BERT الأساسي ويقوم بتشغيل مهمة تحويل دفعة SageMaker، مع إعداد جودة البيانات أيضًا من خلال مراقبة النموذج.
بعد ذلك، نسير عبر دفتر الملاحظات الرئيسي nb-job-pipeline.ipynb، الذي يجمع كافة أجهزة الكمبيوتر المحمولة الفرعية في مسار ويدير سير العمل الشامل. لاحظ أنه على الرغم من أن المثال التالي يقوم بتشغيل دفتر الملاحظات مرة واحدة فقط، إلا أنه يمكنك أيضًا جدولة المسار لتشغيل دفتر الملاحظات بشكل متكرر. تشير إلى وثائق SageMaker للحصول على تعليمات مفصلة.
في الخطوة الأولى لمهمة الكمبيوتر الدفتري، قمنا بتمرير معلمة باستخدام حاوية S3 الافتراضية. يمكننا استخدام هذه المجموعة لتفريغ أي عناصر نريدها متاحة لخطوات خطوط الأنابيب الأخرى. للمفكرة الأولى (preprocess.ipynb)، نقوم بسحب مجموعة بيانات قطار SST2 العامة لـ AWS وإنشاء ملف CSV للتدريب منها وندفعه إلى مجموعة S3 هذه. انظر الكود التالي:
يمكننا بعد ذلك تحويل هذا الكمبيوتر الدفتري إلى ملف NotebookJobStep مع الكود التالي في دفترنا الرئيسي:
الآن بعد أن أصبح لدينا نموذج لملف CSV، يمكننا البدء في تدريب نموذجنا في دفتر التدريب الخاص بنا. يأخذ دفتر التدريب الخاص بنا نفس المعلمة مع مجموعة S3 ويسحب مجموعة بيانات التدريب من ذلك الموقع. ثم نقوم بإجراء الضبط الدقيق باستخدام كائن تدريب المحولات مع مقتطف التعليمات البرمجية التالي:
بعد الضبط الدقيق، نريد تشغيل بعض الاستدلالات المجمعة لمعرفة كيفية أداء النموذج. ويتم ذلك باستخدام دفتر ملاحظات منفصل (prepare-test-set.ipynb) في نفس المسار المحلي الذي ينشئ مجموعة بيانات اختبارية لإجراء الاستدلال على استخدام نموذجنا المدرب. يمكننا تشغيل دفتر الملاحظات الإضافي في دفتر التدريب الخاص بنا باستخدام الخلية السحرية التالية:
نحدد هذه التبعية الإضافية للكمبيوتر الدفتري في ملف AdditionalDependencies المعلمة في خطوة مهمة دفتر الملاحظات الثانية لدينا:
يجب علينا أيضًا تحديد أن خطوة مهمة دفتر الملاحظات التدريبي (الخطوة 2) تعتمد على خطوة مهمة دفتر الملاحظات المسبق (الخطوة 1) باستخدام add_depends_on استدعاء API على النحو التالي:
خطوتنا الأخيرة، هي أن يقوم نموذج BERT بتشغيل تحويل دفعة SageMaker، مع إعداد التقاط البيانات والجودة أيضًا عبر SageMaker Model Monitor. لاحظ أن هذا يختلف عن استخدام المدمج في تحول or إنها تقوم بالتسجيل خطوات عبر خطوط الأنابيب. سيقوم دفتر الملاحظات الخاص بنا لهذه الخطوة بتنفيذ واجهات برمجة التطبيقات نفسها، ولكن سيتم تعقبه كخطوة مهمة دفتر الملاحظات. تعتمد هذه الخطوة على خطوة مهمة التدريب التي قمنا بتحديدها مسبقًا، لذا فإننا نلتقطها أيضًا باستخدام العلامةdependent_on.
بعد تحديد الخطوات المختلفة لسير العمل لدينا، يمكننا إنشاء وتشغيل المسار الشامل:
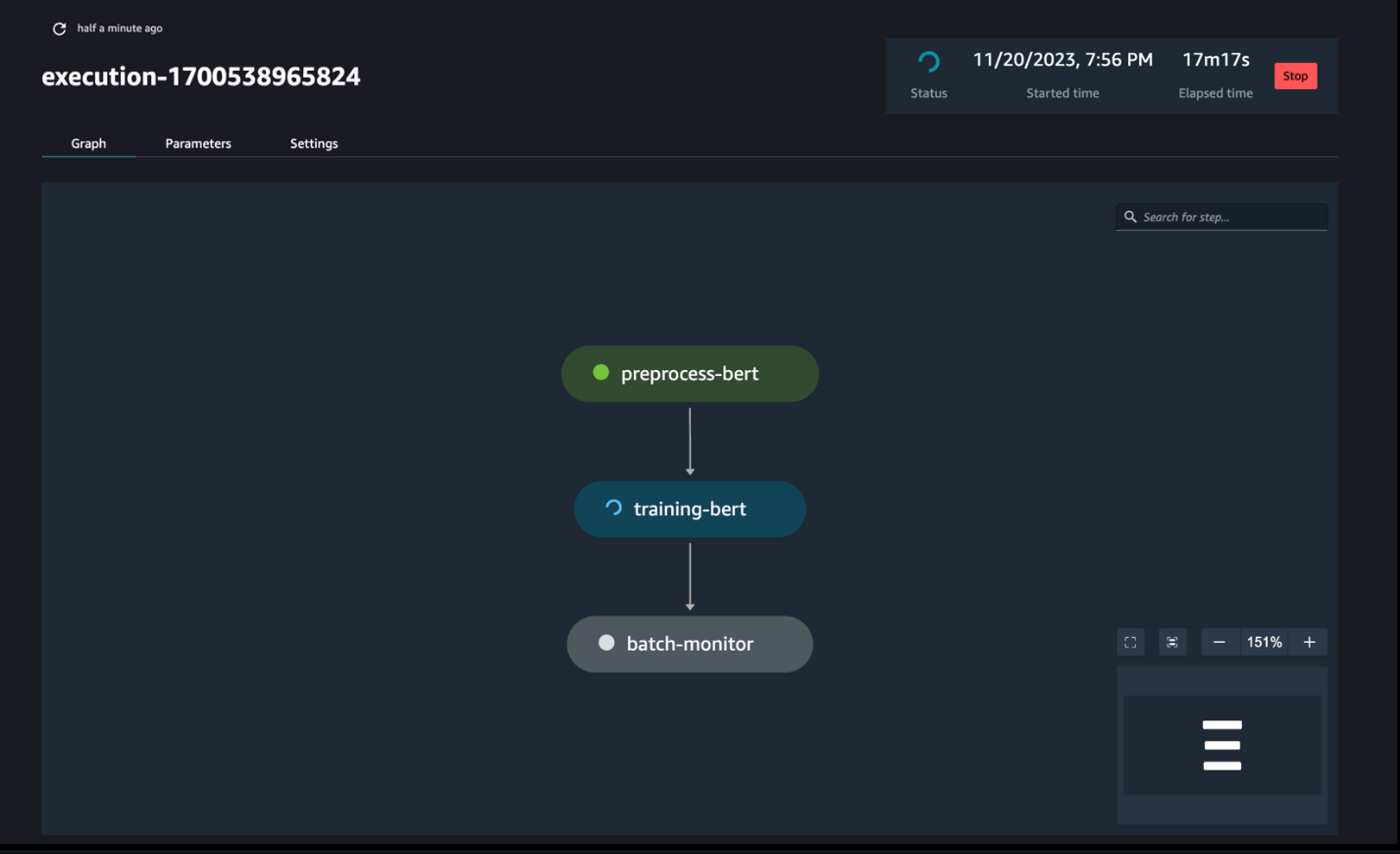
مراقبة تشغيل خط الأنابيب
يمكنك تتبع ومراقبة خطوات تشغيل دفتر الملاحظات عبر SageMaker Pipelines DAG، كما هو موضح في لقطة الشاشة التالية.
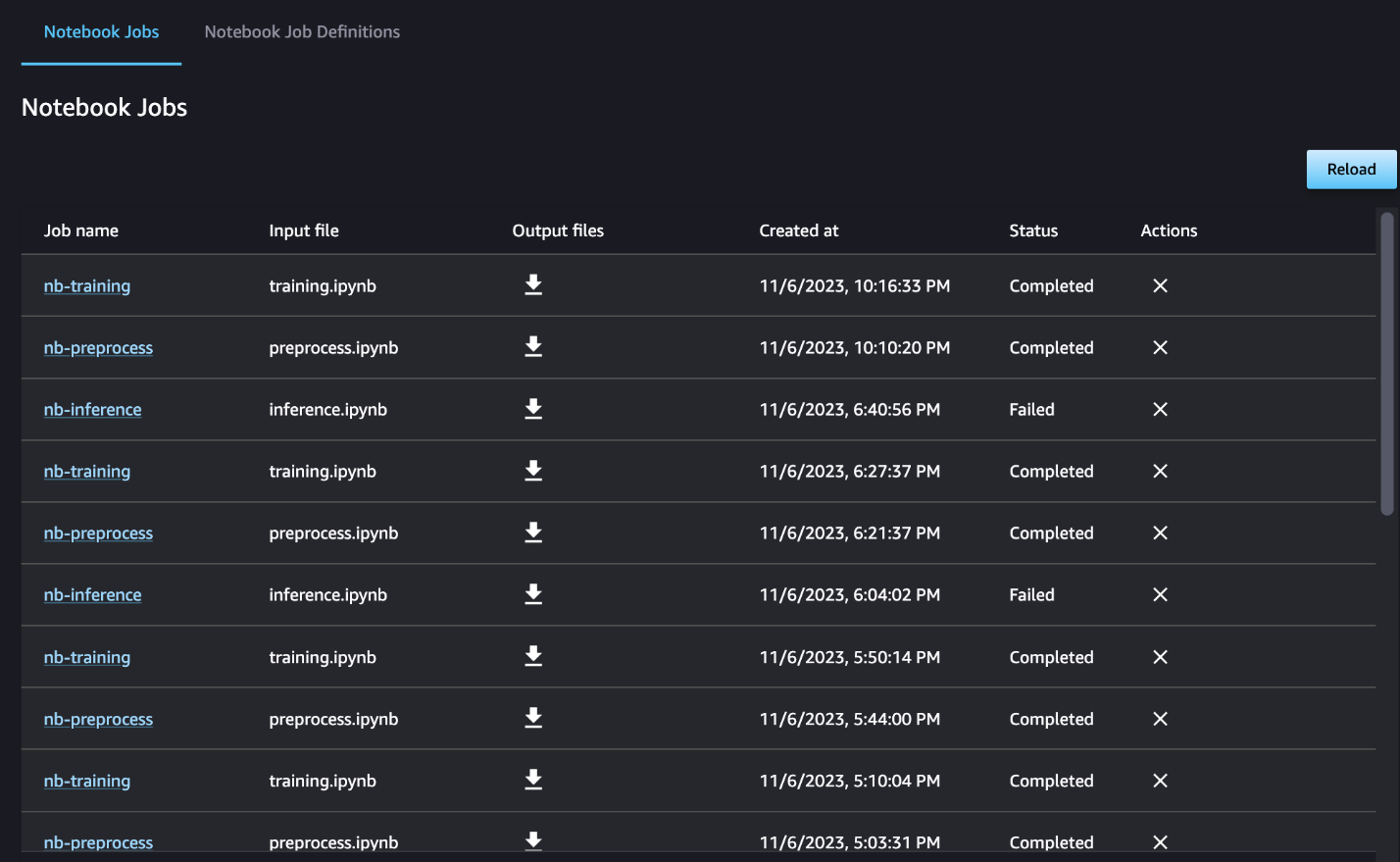
يمكنك أيضًا مراقبة تشغيل دفتر الملاحظات الفردي بشكل اختياري على لوحة معلومات مهمة دفتر الملاحظات وتبديل ملفات الإخراج التي تم إنشاؤها عبر واجهة مستخدم SageMaker Studio. عند استخدام هذه الوظيفة خارج SageMaker Studio، يمكنك تحديد المستخدمين الذين يمكنهم تتبع حالة التشغيل على لوحة معلومات مهمة دفتر الملاحظات باستخدام العلامات. لمزيد من التفاصيل حول العلامات المراد تضمينها، راجع اعرض مهام الكمبيوتر الدفتري الخاص بك وقم بتنزيل المخرجات في لوحة معلومات Studio UI.
في هذا المثال، نقوم بإخراج مهام دفتر الملاحظات الناتجة إلى دليل يسمى outputs في المسار المحلي الخاص بك باستخدام رمز تشغيل خط الأنابيب الخاص بك. كما هو موضح في لقطة الشاشة التالية، يمكنك هنا رؤية مخرجات دفتر الإدخال الخاص بك وأيضًا أي معلمات قمت بتحديدها لهذه الخطوة.
تنظيف
إذا اتبعت المثال الخاص بنا، فتأكد من حذف المسار الذي تم إنشاؤه ووظائف دفتر الملاحظات وبيانات s3 التي تم تنزيلها بواسطة نماذج دفاتر الملاحظات.
الاعتبارات
وفيما يلي بعض الاعتبارات الهامة لهذه الميزة:
- قيود SDK - لا يمكن إنشاء خطوة مهمة دفتر الملاحظات إلا عبر SageMaker Python SDK.
- قيود الصورة -خطوة مهمة دفتر الملاحظات تدعم الصور التالية:
وفي الختام
مع هذا الإطلاق، يمكن للعاملين في مجال البيانات الآن تشغيل دفاتر ملاحظاتهم برمجيًا باستخدام بضعة أسطر من التعليمات البرمجية باستخدام SageMaker بيثون SDK. بالإضافة إلى ذلك، يمكنك إنشاء عمليات سير عمل معقدة متعددة الخطوات باستخدام أجهزة الكمبيوتر المحمولة الخاصة بك، مما يقلل بشكل كبير من الوقت اللازم للانتقال من جهاز الكمبيوتر المحمول إلى مسار CI/CD. بعد إنشاء المسار، يمكنك استخدام SageMaker Studio لعرض وتشغيل DAGs لخطوط الأنابيب الخاصة بك وإدارة عمليات التشغيل ومقارنتها. سواء كنت تقوم بجدولة سير عمل التعلم الآلي الشامل أو جزء منه، فإننا نشجعك على المحاولة سير العمل القائم على دفتر الملاحظات.
عن المؤلفين
 أنشيت جوبتا هو مدير منتج أول في Amazon SageMaker Studio. وهي تركز على تمكين سير عمل علوم البيانات التفاعلية وهندسة البيانات من داخل SageMaker Studio IDE. تستمتع في أوقات فراغها بالطهي ولعب ألعاب الطاولة/البطاقات والقراءة.
أنشيت جوبتا هو مدير منتج أول في Amazon SageMaker Studio. وهي تركز على تمكين سير عمل علوم البيانات التفاعلية وهندسة البيانات من داخل SageMaker Studio IDE. تستمتع في أوقات فراغها بالطهي ولعب ألعاب الطاولة/البطاقات والقراءة.
 رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
رام فيجيراجو هو مهندس ML مع فريق خدمة SageMaker. يركز على مساعدة العملاء في بناء حلول الذكاء الاصطناعي / التعلم الآلي وتحسينها على Amazon SageMaker. يحب السفر والكتابة في أوقات فراغه.
 إدوارد صن هو أحد كبار SDE يعمل في SageMaker Studio في Amazon Web Services. يركز على بناء حل ML تفاعلي وتبسيط تجربة العملاء لدمج SageMaker Studio مع التقنيات الشائعة في هندسة البيانات والنظام البيئي ML. في أوقات فراغه ، يعتبر إدوارد من أشد المعجبين بالتخييم والمشي لمسافات طويلة وصيد الأسماك ويستمتع بقضاء الوقت مع أسرته.
إدوارد صن هو أحد كبار SDE يعمل في SageMaker Studio في Amazon Web Services. يركز على بناء حل ML تفاعلي وتبسيط تجربة العملاء لدمج SageMaker Studio مع التقنيات الشائعة في هندسة البيانات والنظام البيئي ML. في أوقات فراغه ، يعتبر إدوارد من أشد المعجبين بالتخييم والمشي لمسافات طويلة وصيد الأسماك ويستمتع بقضاء الوقت مع أسرته.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :لديها
- :يكون
- :أين
- $ UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- من نحن
- يمكن الوصول
- اسيكليك
- إضافي
- وبالإضافة إلى ذلك
- مميزات
- بعد
- AI / ML
- الكل
- يسمح
- على طول
- سابقا
- أيضا
- بالرغم ان
- أمازون
- Amazon EC2
- الأمازون SageMaker
- أمازون ساجميكر ستوديو
- أمازون ويب سيرفيسز
- an
- تحليل
- تحليل
- و
- أي وقت
- API
- واجهات برمجة التطبيقات
- التطبيقات
- هندسة معمارية
- هي
- AS
- At
- أتمتة
- متاح
- AWS
- قاعدة
- على أساس
- خط الأساس
- BE
- جميل
- كان
- وراء
- يجري
- أفضل
- ما بين
- كبير
- نساعدك في بناء
- ابني
- مدمج
- لكن
- by
- دعوة
- تسمى
- معدات التخييم
- CAN
- أسر
- حقيبة
- الحالات
- الخلية
- الأحرف
- تصنيف
- الكود
- عمود
- الأعمدة
- يجمع بين
- تأتي
- مشترك
- قارن
- إكمال
- مجمع
- تتألف
- تتألف
- إحصاء
- إدارة
- متصل
- الاعتبارات
- يتكون
- وعاء
- يحتوي
- متواصل
- تحول
- تحويلها
- الطهي
- المقابلة
- استطاع
- خلق
- خلق
- يخلق
- خلق
- حاليا
- على
- زبون
- تجربة العملاء
- دعم العملاء
- العملاء
- DAG
- لوحة أجهزة القياس
- البيانات
- مراقبة البيانات
- تحضير البيانات
- معالجة المعلومات
- جودة البيانات
- علم البيانات
- قواعد البيانات
- الترتيب
- حدد
- تعريف
- التوصيل
- الطلب
- التبعيات
- التبعية
- تابع
- يعتمد
- نشر
- نشر
- مفصلة
- تفاصيل
- تطوير
- المتقدمة
- مختلف
- مباشرة
- توجه
- مدير المدارس
- خامد
- عامل في حوض السفن
- فعل
- فعل
- إلى أسفل
- بإمكانك تحميله
- تفريغ
- كل
- بسهولة
- النظام الإيكولوجي
- إدوارد
- تمكين
- تمكين
- شجع
- النهاية
- النهائي إلى نهاية
- الهندسة
- كامل
- عصر
- الأثير (ETH)
- مثال
- تنفيذ
- الخبره في مجال الغطس
- احتفل على
- استخراج
- للعائلات
- مروحة
- بعيدا
- الميزات
- ردود الفعل
- قليل
- قم بتقديم
- ملفات
- افلام
- صناع السينما
- الاسم الأول
- صيد السمك
- خمسة
- ركز
- ويركز
- يتبع
- متابعيك
- متابعات
- في حالة
- النموذج المرفق
- شكل
- تبدأ من
- تماما
- وظيفة
- علاوة على ذلك
- ألعاب
- توليد
- الرسوم البيانية
- يملك
- he
- مساعدة
- مساعدة
- لها
- هنا
- المشي لمسافات طويلة
- له
- هوليوود
- كيفية
- HTML
- HTTP
- HTTPS
- الانسان
- if
- يوضح
- صورة
- صور
- فورا
- استيراد
- أهمية
- in
- تتضمن
- مستقل
- يشير
- فرد
- إدخال
- مثل
- تعليمات
- دمج
- التكامل
- التفاعلية
- إلى
- IT
- انها
- وظيفة
- المشــاريــع
- JPG
- م
- تُشير
- ملصقات
- اسم العائلة
- إطلاق
- تعلم
- المكتبات
- خط
- خطوط
- تحميل
- محلي
- موقع
- طويل
- يحب
- آلة
- آلة التعلم
- سحر
- الرئيسية
- يصنع
- إدارة
- تمكن
- إدارة
- مدير
- الوسائط
- جدارة
- ربما
- ML
- نموذج
- عارضات ازياء
- تم التعديل
- الوحدات
- مراقبة
- مراقبة
- شاشات
- الأكثر من ذلك
- أكثر
- خطوة
- فيلم
- متعدد
- يجب
- الاسم
- محلي
- حاجة
- بحاجة
- سلبي
- جديد
- لا
- لاحظ
- مفكرة
- أجهزة الكمبيوتر المحمولة
- الآن
- موضوع
- of
- غالبا
- on
- ONE
- فقط
- الأمثل
- or
- تزامن
- أخرى
- لنا
- خارج
- الناتج
- النتائج
- في الخارج
- أزواج
- المعلمة
- المعلمات
- جزء
- pass
- مرور
- مسار
- نفذ
- أداء
- الشخصية
- خط أنابيب
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- لعب
- الرائج
- إيجابي
- منشور
- تنبأ
- إعداد
- يستعد
- إعداد
- سابق
- سابقا
- المشكلة
- معالجة
- المنتج
- مدير المنتج
- تزود
- المقدمة
- ويوفر
- جمهور
- تسحب
- أغراض
- دفع
- دفع
- بايثون
- جودة
- أسرع
- R
- بدلا
- عرض
- نادي القراءة
- متكرر
- تقليص
- ريفاكتور
- الرجوع
- مسجل
- بانتظام
- لا تزال
- مرارا وتكرارا
- تطلب
- مما أدى
- مراجعة
- التعليقات
- يجري
- تشغيل
- يدير
- sagemaker
- خطوط الأنابيب SageMaker
- نفسه
- راض
- جدول
- المقرر
- الوظائف المجدولة
- جدولة
- علوم
- العلماء
- الإستراحة
- الثاني
- القسم
- أقسام
- انظر تعريف
- رأيت
- كبير
- عاطفة
- مستقل
- الخدمة
- خدماتنا
- الجلسة
- طقم
- ضبط
- عدة
- شكل
- هي
- ينبغي
- إظهار
- عرض
- أظهرت
- يظهر
- هام
- بشكل ملحوظ
- مماثل
- الاشارات
- تبسيط
- عزباء
- صغير
- الأصغر
- قصاصة
- So
- منصات التواصل
- وسائل التواصل الاجتماعي
- حل
- الحلول
- حل
- بعض
- شيء
- الفضاء
- محدد
- الإنفاق
- مستقل
- ستانفورد
- بداية
- الحالة
- خطوة
- خطوات
- لا يزال
- تخزين
- صريح
- ستوديو
- هذه
- تعرض جيد للشمس
- الدعم
- مدعومة
- الدعم
- بالتأكيد
- أخذ
- يأخذ
- مهمة
- المهام
- فريق
- التكنولوجيا
- تجربه بالعربي
- نص
- تصنيف النص
- أن
- •
- من مشاركة
- منهم
- then
- تشبه
- الثالث
- هؤلاء
- ثلاثة
- عبر
- الوقت
- إلى
- سويا
- جدا
- أداة
- الإجمالي
- مسار
- قطار
- متدرب
- قادة الإيمان
- تحول
- محولات
- السفر
- يثير
- منعطف أو دور
- اثنان
- نوع
- ui
- فهم
- تحديث
- us
- تستخدم
- حالة الاستخدام
- مستعمل
- المستخدمين
- يستخدم
- استخدام
- استخدام
- القيم
- مختلف
- بواسطة
- المزيد
- تصور
- سير
- تريد
- we
- الويب
- خدمات ويب
- متى
- سواء
- التي
- في حين
- من الذى
- سوف
- مع
- في غضون
- بدون
- العمال
- سير العمل
- سير العمل
- عامل
- أسوأ
- جاري الكتابة
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت