المُقدّمة
اندماج الذكاء الاصطناعي (الذكاء الاصطناعي) والفن يكشفان عن طرق جديدة في الفن الرقمي الإبداعي، بشكل بارز من خلال نماذج الانتشار. تبرز هذه النماذج في جيل فن الذكاء الاصطناعي الإبداعي، حيث تقدم نهجًا متميزًا عن الشبكات العصبية التقليدية. تأخذك هذه المقالة في رحلة استكشافية إلى أعماق نماذج الانتشار، وتوضح آليتها الفريدة في صياغة أعمال فنية مذهلة بصريًا وغنية بشكل إبداعي. افهم الفروق الدقيقة في نماذج الانتشار واكتسب نظرة ثاقبة لدورها في إعادة تعريف التعبير الفني من خلال عدسة تقنيات الذكاء الاصطناعي المتقدمة.

أهداف التعلم
- فهم المفاهيم الأساسية لنماذج الانتشار في الذكاء الاصطناعي.
- اكتشف الفرق بين نماذج الانتشار والشبكات العصبية التقليدية في توليد الفن.
- تحليل عملية خلق الفن باستخدام نماذج الانتشار.
- تقييم الآثار الإبداعية والجمالية للذكاء الاصطناعي في الفن الرقمي.
- ناقش الاعتبارات الأخلاقية في الأعمال الفنية التي ينشئها الذكاء الاصطناعي.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
فهم نماذج الانتشار

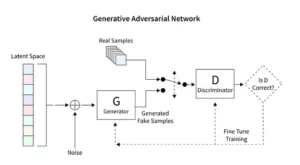
تُحدث نماذج الانتشار ثورة في الذكاء الاصطناعي التوليدي، حيث تقدم طريقة فريدة لإنشاء الصور تختلف عن التقنيات التقليدية مثل شبكات الخصومة التوليدية (GANs). بدءًا من الضوضاء العشوائية، تعمل هذه النماذج على تحسينها تدريجيًا، لتشبه فنانًا يضبط لوحة فنية، مما ينتج عنه صور معقدة ومتماسكة.
تعكس عملية التحسين الإضافية هذه الطبيعة المنهجية للنشر. هنا، يقوم كل تكرار بتغيير الضجيج بمهارة، مما يجعله أقرب إلى الرؤية الفنية النهائية. إن الإخراج ليس مجرد نتاج عشوائي، بل هو قطعة فنية متطورة، متميزة في تطورها ونهايتها.
يتطلب ترميز نماذج الانتشار فهمًا عميقًا للشبكات العصبية وأطر التعلم الآلي مثل TensorFlow أو PyTorch. الكود الناتج معقد، ويتطلب تدريبًا مكثفًا على مجموعات البيانات الموسعة لتحقيق التأثيرات الدقيقة التي لوحظت في الفن الناتج عن الذكاء الاصطناعي.
تطبيق الانتشار المستقر في الفن
يتطلب ظهور المولدات الفنية المعتمدة على الذكاء الاصطناعي، مثل نماذج الانتشار المستقرة، ترميزًا متطورًا داخل منصات مثل TensorFlow أو PyTorch. تتميز هذه النماذج بقدرتها على تحويل العشوائية إلى بنية بشكل منهجي، تمامًا مثل الفنان الذي يحول رسمًا أوليًا إلى تحفة فنية مفعمة بالحيوية.
تعمل نماذج الانتشار المستقرة على إعادة تشكيل المشهد الفني للذكاء الاصطناعي من خلال نحت صور منظمة من العشوائية، وتجنب الديناميكيات التنافسية المميزة لشبكات GAN. إنهم يتفوقون في تفسير المطالبات المفاهيمية في الفن البصري، مما يعزز الرقص التآزري بين قدرات الذكاء الاصطناعي والإبداع البشري. ومن خلال تسخير PyTorch، نلاحظ كيف تعمل هذه النماذج على تحويل الفوضى بشكل متكرر إلى وضوح، مما يعكس رحلة الفنان من فكرة وليدة إلى إبداع مصقول.
تجربة الفن الناتج عن الذكاء الاصطناعي
يتعمق هذا العرض التوضيحي في العالم الرائع للفن الناتج عن الذكاء الاصطناعي باستخدام شبكة عصبية تلافيفية تسمى نموذج ConvDiffusion. يتم تدريب هذا النموذج على صور فنية متنوعة تشمل الرسومات واللوحات والمنحوتات والنقوش، كما هو مصدرها مجموعة بيانات Kaggle هذه. هدفنا هو استكشاف قدرة النموذج على التقاط وإعادة إنتاج الجماليات المعقدة لهذه الأعمال الفنية.
الهندسة النموذجية والتدريب
التصميم المعماري
يُعد نموذج ConvDiffusionModel، في جوهره، أعجوبة من الهندسة العصبية، ويتميز ببنية تشفير وفك تشفير متطورة مصممة خصيصًا لتلبية متطلبات جيل الفن. هيكل النموذج عبارة عن شبكة عصبية معقدة، تدمج آليات التشفير وفك التشفير المحسّنة خصيصًا لتوليد الفن. من خلال طبقات تلافيفية إضافية وتخطي الروابط التي تحاكي الحدس الفني، يمكن للنموذج تشريح الفن وإعادة تجميعه بفهم ذكي للتكوين والأسلوب.
- التشفير: المشفر هو العين التحليلية للنموذج، حيث يقوم بفحص التفاصيل الدقيقة لكل صورة مدخلة. أثناء مرور الصور عبر الطبقات التلافيفية لجهاز التشفير، يتم ضغطها تدريجيًا في مساحة كامنة - وهو تمثيل مدمج ومشفر للعمل الفني الأصلي. لا يقوم برنامج التشفير الخاص بنا بفحص الصور المدخلة فحسب، بل يقوم بذلك الآن من خلال عمق إدراك معزز، بفضل الطبقات الإضافية وتقنيات تسوية الدُفعات. يسمح هذا الفحص الموسع بتمثيل أكثر ثراءً ومكثفًا داخل المساحة الكامنة، مما يعكس تأمل الفنان العميق للموضوع.
- فك: في المقابل، تعمل وحدة فك التشفير بمثابة اليد الإبداعية للنموذج، حيث تأخذ الرسومات التجريدية من وحدة التشفير وتبث الحياة فيها. فهو يعيد بناء العمل الفني من المساحة الكامنة، طبقة بعد طبقة، وتفاصيل بعد تفاصيل، حتى تظهر صورة كاملة. يستفيد جهاز فك التشفير الخاص بنا من تخطي الاتصالات ويمكنه إعادة بناء العمل الفني بدقة أكبر. إنه يعيد النظر في الجوهر المجرد للمدخلات ويزينها تدريجيًا، مما يحقق عرضًا أكثر إخلاصًا للمادة المصدر. تعمل الطبقات المحسنة بشكل متناغم للتأكد من أن الصورة النهائية هي قطعة حية ومعقدة تعكس براعة الإدخال الفنية.
عملية التدريب
التدريب على ConvDiffusionModel هو رحلة عبر مشهد فني يمتد لـ 150 حقبة. يمثل كل عصر تمريرة كاملة عبر مجموعة البيانات بأكملها، حيث يسعى النموذج جاهداً لتحسين فهمه وتحسين دقة الصور التي تم إنشاؤها.
- وظيفة الخسارة الهجينة: في قلب التدريب تكمن وظيفة خسارة الخطأ التربيعي المتوسط (MSE). تحدد هذه الوظيفة الفرق بين التحفة الفنية الأصلية وإعادة إنتاج النموذج، مما يوفر مقياسًا واضحًا لتقليله. سوف نقدم مكونًا للخسارة الإدراكية مشتقًا من شبكة VGG المدربة مسبقًا والتي تكمل مقياس متوسط الخطأ التربيعي (MSE). تدفع إستراتيجية الخسارة المزدوجة هذه النموذج إلى احترام السلامة الفنية للأصول الأصلية مع إتقان إعادة الإنتاج الفني لتفاصيلها.
- محسن: من خلال معدل التعلم الذي يتم تعديله ديناميكيًا بواسطة برنامج جدولة، يقوم مُحسِّن Adam بتوجيه تعلم النموذج بحكمة متزايدة. يضمن هذا النهج التكيفي أن يكون تقدم النموذج في تعلم تكرار الفن وابتكاره ثابتًا وقويًا.
- التكرار والصقل: التكرارات التدريبية عبارة عن رقصة بين الحفاظ على الجوهر الفني ومتابعة التكرار الفني. مع كل دورة، يقترب النموذج من مزيج من الإخلاص والإبداع.
- تصور التقدم: يتم حفظ الصور على فترات منتظمة أثناء التدريب لتصور تقدم النموذج. توفر هذه اللقطات نافذة على منحنى التعلم الخاص بالنموذج، وتعرض كيفية تطور الفن الناتج عنه، ويصبح أكثر وضوحًا وتفصيلاً وأكثر تماسكًا فنيًا مع كل عصر.



يتم توضيح ما سبق من خلال الكود التالي:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')
تصور العمل الفني الذي تم إنشاؤه
إظهار الفن المبتكر بالذكاء الاصطناعي
مع تدريب ConvDiffusionModel بشكل كامل، يتحول التركيز من المجرد إلى الملموس - من الإمكانية إلى تحقيق الفن المصنوع بواسطة الذكاء الاصطناعي. ويجسد مقتطف الكود اللاحق القدرات الفنية المكتسبة للنموذج، ويحول البيانات المدخلة إلى لوحة رقمية للتعبير.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()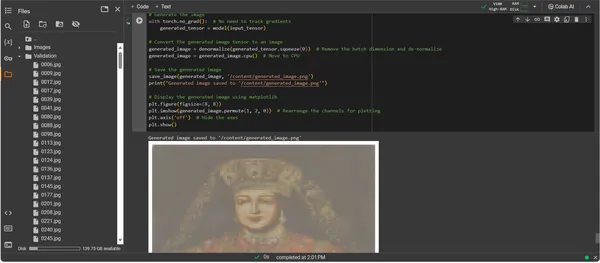

تجول في كود إنشاء العمل الفني
- القيامة النموذجية: الخطوة الأولى في إنشاء العمل الفني هي إحياء نموذج ConvDiffusionModel الذي تم تدريبه. يتم تحميل الأوزان التي تم تعلمها للنموذج وإدخالها في وضع التقييم، مما يمهد الطريق للإنشاء دون إجراء مزيد من التغيير على معلماته.
- تحويل الصورة: ولضمان الاتساق مع نظام التدريب، تتم معالجة الصور المدخلة من خلال نفس تسلسل التحولات. يتضمن ذلك تغيير الحجم ليتوافق مع أبعاد إدخال النموذج، وتحويل الموتر لتوافق PyTorch، والتطبيع بناءً على الملف الإحصائي لبيانات التدريب.
- فائدة إزالة التطبيع: تعمل الوظيفة المخصصة على عكس تأثيرات المعالجة المسبقة، وإعادة قياس الموتر إلى نطاق ألوان الصورة الأصلية. هذه الخطوة ضرورية لتحويل المخرجات التي تم إنشاؤها إلى تمثيل دقيق بصريًا.
- إعداد الإدخال: يتم تحميل الصورة وإخضاعها للتحويلات المذكورة أعلاه. من المهم أن نلاحظ أن هذه الصورة هي بمثابة الإلهام الذي سيستمد منه الذكاء الاصطناعي الإلهام - فالهمس الصامت يشعل الخيال الاصطناعي للنموذج.
- توليف العمل الفني: وفي رقصة دقيقة من الانتشار إلى الأمام، يفسر النموذج موتر الإدخال، مما يسمح لطبقاته بالتعاون في إنتاج رؤية فنية جديدة. قم بإجراء هذه العملية دون تتبع التدرجات، لأننا الآن في عالم التطبيق، وليس التدريب.
- تحويل الصورة: إن الناتج الموتر للنموذج، الذي يحمل الآن العمل الفني المولد رقميًا، غير طبيعي، مما يترجم إنشاء النموذج مرة أخرى إلى المساحة المألوفة من اللون والضوء التي يمكن لأعيننا تقديرها.
- الكشف عن العمل الفني: يتم وضع الموتر المحول على لوحة رقمية، ويبلغ ذروته في ملف صورة محفوظ. هذا الملف هو نافذة على الروح الإبداعية للذكاء الاصطناعي، وهو صدى ثابت للعملية الديناميكية التي منحته الحياة.
- استرجاع العمل الفني: ويختتم البرنامج النصي بحفظ الصورة التي تم إنشاؤها في المسار المحدد والإعلان عن اكتمالها. الصورة المحفوظة، وهي عبارة عن توليفة من المبادئ الفنية المكتسبة والإبداع الناشئ، جاهزة للعرض والتأمل.
تحليل الإخراج
يقدم ناتج ConvDiffusionModel شخصية ذات إشارة واضحة إلى الفن التاريخي. تعكس الصورة المعروضة بتقنية الذكاء الاصطناعي، المغطاة بملابس متقنة، عظمة الصور الكلاسيكية مع لمسة عصرية مميزة. ملابس الشخص غنية بالملمس، وتمزج بين أنماط العارضة المستفادة وتفسير جديد. تُظهر ملامح الوجه الدقيقة والتفاعل الدقيق بين الضوء والظل فهم الذكاء الاصطناعي الدقيق لتقنيات الفن التقليدي. يعد هذا العمل الفني بمثابة شهادة على التدريب المتطور للنموذج، مما يعكس توليفًا أنيقًا للفن التاريخي من خلال منظور التعلم الآلي المتقدم. في جوهرها، إنها تحية رقمية للماضي، تم تصميمها باستخدام خوارزميات الحاضر.
التحديات والاعتبارات الأخلاقية
إن تنفيذ نماذج الانتشار لتوليد الفن يجلب معه العديد من التحديات والاعتبارات الأخلاقية التي يجب عليك مراعاتها:
- مصدر البيانات: يجب تنظيم مجموعات بيانات التدريب بطريقة مسؤولة. من الضروري التحقق من أن البيانات المستخدمة لتدريب نماذج النشر لا تحتوي على أعمال محمية بحقوق الطبع والنشر أو محمية دون الحصول على إذن مناسب.
- التحيز والتمثيل: يمكن لنماذج الذكاء الاصطناعي إدامة التحيزات في بيانات التدريب الخاصة بها. يعد ضمان مجموعات البيانات المتنوعة والشاملة أمرًا مهمًا لتجنب تعزيز الصور النمطية في الفن الناتج عن الذكاء الاصطناعي.
- التحكم في الإخراج: وبما أن نماذج الانتشار يمكن أن تولد نطاقًا واسعًا من المخرجات، فمن الضروري وضع حدود لمنع إنشاء محتوى غير مناسب أو مسيء.
- إطار قانوني: إن الافتقار إلى إطار قانوني قوي لمعالجة الفروق الدقيقة في الذكاء الاصطناعي في العملية الإبداعية يمثل تحديًا. ويجب أن تتطور التشريعات لحماية حقوق جميع الأطراف المعنية.
وفي الختام
يمثل ظهور نماذج الانتشار في الذكاء الاصطناعي والفن حقبة تحويلية، حيث تدمج الدقة الحسابية مع الاستكشاف الجمالي. تسلط رحلتهم في عالم الفن الضوء على إمكانات الابتكار الكبيرة ولكنها تأتي مصحوبة بالتعقيدات. يعد تحقيق التوازن بين الأصالة والتأثير والإبداع الأخلاقي واحترام الأعمال الحالية جزءًا لا يتجزأ من العملية الفنية.
الوجبات السريعة الرئيسية
- نماذج الانتشار هي في طليعة التحول التحويلي في الإبداع الفني. إنها توفر أدوات رقمية جديدة تعمل على توسيع نطاق التعبير الفني إلى ما هو أبعد من الحدود التقليدية.
- في الفن المعزز بالذكاء الاصطناعي، يعد إعطاء الأولوية للتجميع الأخلاقي لبيانات التدريب واحترام الملكية الفكرية للمبدعين أمرًا ضروريًا للحفاظ على النزاهة في الفن الرقمي.
- إن التقارب بين الرؤية الفنية والابتكار التكنولوجي يفتح الأبواب أمام علاقة تكافلية بين الفنانين ومطوري الذكاء الاصطناعي. تعزيز بيئة تعاونية يمكن أن تؤدي إلى ظهور فن رائد.
- يعد التأكد من أن الفن الناتج عن الذكاء الاصطناعي يمثل نطاقًا واسعًا من وجهات النظر أمرًا حيويًا. دمج مجموعة متنوعة من البيانات التي تعكس ثراء الثقافات ووجهات النظر المختلفة، وبالتالي تعزيز الشمولية.
- إن الاهتمام المتزايد بالفن المصنوع بواسطة الذكاء الاصطناعي يستلزم إنشاء أطر قانونية قوية. يجب أن توضح هذه الأطر قضايا حقوق الطبع والنشر، وتعترف بالمساهمات، وتحكم الاستخدام التجاري للأعمال الفنية التي ينشئها الذكاء الاصطناعي.
يقدم فجر هذا التطور الفني طريقًا مليئًا بالإمكانات الإبداعية ولكنه يتطلب رعاية مدروسة. ويتعين علينا أن نزرع مشهدًا يزدهر فيه اندماج الذكاء الاصطناعي والفن، مسترشدين بممارسات مسؤولة وحساسة ثقافيًا.
الأسئلة الشائعة
ج: نماذج الانتشار هي خوارزميات ML توليدية تقوم بإنشاء صور عن طريق البدء بنمط من الضوضاء العشوائية وتشكيله تدريجيًا في صورة متماسكة. تشبه هذه العملية فنانًا يبدأ بلوحة قماشية فارغة ويضيف ببطء طبقات من التفاصيل.
أ. شبكات GAN، لا تتطلب نماذج الانتشار شبكة منفصلة للحكم على المخرجات. وهي تعمل عن طريق إضافة الضوضاء وإزالتها بشكل متكرر، مما يؤدي غالبًا إلى الحصول على صور أكثر تفصيلاً ودقة.
ج: نعم، يمكن لنماذج الانتشار إنشاء قطع فنية أصلية من خلال التعلم من مجموعة بيانات من الصور. ومع ذلك، فإن الأصالة تتأثر بتنوع ونطاق بيانات التدريب. هناك جدل مستمر حول أخلاقيات استخدام الأعمال الفنية الموجودة لتدريب هذه النماذج.
أ. تشمل المخاوف الأخلاقية تجنب انتهاك حقوق النشر الفنية الناتجة عن الذكاء الاصطناعي. احترام أصالة الفنانين البشر، ومنع استمرار التحيز، وضمان الشفافية في العملية الإبداعية للذكاء الاصطناعي.
ج: يبدو مستقبل الفن الناتج عن الذكاء الاصطناعي واعداً، حيث توفر نماذج الانتشار أدوات جديدة للفنانين والمبدعين. يمكننا أن نتوقع رؤية أعمال فنية أكثر تطورًا وتعقيدًا مع تقدم التكنولوجيا. ومع ذلك، يجب على المجتمع الإبداعي أن يتعامل مع الاعتبارات الأخلاقية وأن يعمل على وضع مبادئ توجيهية واضحة وأفضل الممارسات.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :يكون
- :ليس
- :أين
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- القدرة
- من نحن
- فوق
- الملخص
- دقيق
- التأهيل
- تحقيق
- ادم
- على التكيف
- مضيفا
- إضافي
- العنوان
- تعديل
- متقدم
- السلف
- مجيء
- الخصومة
- AI
- ai الفن
- قريب
- خوارزميات
- الكل
- السماح
- يسمح
- an
- تحليلية
- تحليلات
- تحليلات Vidhya
- و
- اعلان
- تطبيق
- نقدر
- نهج
- هندسة معمارية
- هي
- فنـون
- البند
- فنان
- فني
- فنيا
- الفنية
- الفنانين
- العمل الفني
- الأعمال الفنية
- AS
- At
- المعزز
- ترخيص
- متاح
- السبل
- تجنب
- تجنب
- محاور
- الى الخلف
- سيئة
- موازنة
- على أساس
- BE
- أن تصبح
- الفوائد
- أفضل
- أفضل الممارسات
- ما بين
- Beyond
- انحياز
- التحيزات
- فارغة
- مزج
- blogathon
- مولود
- على حد سواء
- الحدود
- تنفس
- امتلاء
- يجلب
- واسع
- جلبت
- المزدهرة
- لكن
- by
- حساب
- تسمى
- CAN
- قماش
- قدرات
- قدرة
- أسر
- تحدى
- التحديات
- قنوات
- فوضى
- مميز
- التحقق
- تدقيق
- المشبك
- وضوح
- فئة
- واضح
- أكثر وضوحا
- أقرب
- الكود
- البرمجة
- متماسك
- تعاون
- متعاون
- اللون
- يأتي
- تجاري
- مجتمع
- اتفاق
- التوافق
- تنافسي
- إكمال
- إكمال
- مجمع
- التعقيدات
- عنصر
- تركيب
- الحسابية
- إحصاء
- المفاهيم
- المفاهيمي
- اهتمامات
- حفلة موسيقية
- ويخلص
- التواصل
- نظر
- الاعتبارات
- تحتوي على
- محتوى
- تباين
- مساهمات
- تقليدي
- التقاء
- تحويل
- التحول
- شبكة عصبية تلافيفية
- حقوق الطبع والنشر
- التعدي على حق المؤلف
- جوهر
- فاسد
- وحدة المعالجة المركزية:
- وضعت
- خلق
- خلق
- خلق
- الإبداع
- بشكل خلاق
- الإبداع
- المبدعين
- حاسم
- وبلغت ذروتها
- زرع
- ثقافيا
- من تنسيق
- منحنى
- على
- دورة
- رقص
- البيانات
- قواعد البيانات
- مناقشة
- عميق
- تحديد
- مطالب
- تظاهر
- عمق
- أعماق
- مستمد
- محدد
- التفاصيل
- مفصلة
- تفاصيل
- المطورين
- جهاز
- اختلف
- فرق
- مختلف
- التوزيع
- رقمي
- الفن الرقمي
- رقميا
- بعد
- الأبعاد
- حرية التصرف
- العرض
- عرض
- خامد
- Различие
- عدة
- تنوع
- do
- هل
- الأبواب
- رسم
- المخططات
- أثناء
- ديناميكي
- حيوي
- دينامية
- e
- كل
- صدى
- أصداء
- الآثار
- توضيح
- آخر
- يظهر
- المشفرة
- شمل
- يشمل
- الهندسة
- تعزيز
- ضمان
- يضمن
- ضمان
- كامل
- البيئة
- عصر
- عهود
- عصر
- خطأ
- جوهر
- أساسي
- تأسيس
- الأثير (ETH)
- أخلاقي
- أخلاق
- تقييم
- كل
- تطور
- يتطور
- تطورت
- يتطور
- فحص
- Excel
- إلا
- القائمة
- وسع
- توسعية
- توقع
- استكشاف
- اكتشف
- التعبير
- مدد
- واسع
- عين
- العيون
- تجميل الوجه
- مخلص
- زائف
- مألوف
- ساحر
- المميزات
- ويتميز
- إخلاص
- الشكل
- قم بتقديم
- ملفات
- نهائي
- نهاية
- الاسم الأول
- تركز
- متابعيك
- في حالة
- طليعة
- إلى الأمام
- فوستر
- تعزيز
- الإطار
- الأطر
- تبدأ من
- تماما
- وظيفة
- وظيفي
- أساسي
- إضافي
- انصهار
- مستقبل
- ربح
- شبكات GAN
- جمع
- أعطى
- توليد
- ولدت
- توليد
- جيل
- توليدي
- شبكات التزوج التوليدية
- الذكاء الاصطناعي التوليدي
- مولدات
- منح
- هدف
- وحدة معالجة الرسوميات:
- التدرجات
- تدريجيا
- عظمة
- يفهم، يمسك، يقبض
- أكبر
- الرائد
- موجه
- المبادئ التوجيهية
- دليل
- يد
- تسخير
- قلب
- هنا
- إخفاء
- ويبرز
- تاريخي
- عقد
- إجلال
- شرف
- كيفية
- لكن
- HTTPS
- الانسان
- i
- فكرة
- if
- يشعل
- صورة
- صور
- خيال
- صيغة الامر
- تحقيق
- آثار
- استيراد
- أهمية
- تحسن
- in
- يشمل
- شامل
- الشمولية
- دمج
- زيادة
- الإضافية
- مايجب في الوضع الراهن
- تأثير
- تأثر
- انتهاك
- براعة
- الابتكار
- الابتكار
- إدخال
- المدخلات
- تبصر
- متكامل
- دمج
- سلامة
- فكري
- الملكية الفكرية
- مصلحة
- ترجمة
- إلى
- معقد
- تقديم
- حدس
- المشاركة
- مسائل
- IT
- تكرير
- التكرارات
- انها
- رحلة
- JPG
- القاضي
- نقص
- المشهد
- طبقة
- طبقات
- تعلم
- تعلم
- شروط وأحكام
- إطار قانوني
- تشريع
- العدسات
- يكمن
- الحياة
- ضوء
- مثل
- جار التحميل
- تبدو
- خسارة
- خسائر
- آلة
- آلة التعلم
- المحافظة
- أعجوبة
- تحفة
- مباراة
- مادة
- matplotlib
- تعني
- آلية
- آليات
- الوسائط
- مجرد
- دمج
- طريقة
- المنهجي او نظامى
- متري
- تقليل
- دقيقة
- يعكس
- ML
- خوارزميات ML
- موضة
- نموذج
- عارضات ازياء
- تقدم
- وحدة
- الأكثر من ذلك
- خطوة
- كثيرا
- ميوز
- يجب
- أسماء
- ناشئ
- الطبيعة
- التنقل
- ضروري
- إحتياجات
- شبكة
- الشبكات
- عصبي
- الهندسة العصبية
- الشبكة العصبية
- الشبكات العصبية
- جديد
- ضجيج
- لاحظ
- رواية
- الآن
- تظليل
- رصد
- ملاحظ
- of
- خصم
- هجومي
- عرض
- الوهب
- عروض
- غالبا
- on
- جارية
- فقط
- يفتح
- الأمثل
- or
- أصلي
- أصالة
- أصول
- OS
- أخرى
- لنا
- خارج
- الناتج
- النتائج
- على مدى
- مملوكة
- اللوحة
- لوحات
- المعلمة
- المعلمات
- جزء
- الأحزاب
- pass
- الماضي
- مسار
- نمط
- أنماط
- الإدراك
- استكمال
- نفذ
- وجهات نظر
- صورة
- قطعة
- قطعة
- بلاتفورم
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- صور
- محتمل
- الممارسات
- دقة
- تمهيدي
- يقدم
- الهدايا
- الحفاظ على
- منع
- منع
- مبادئ
- الطباعة
- ترتيب الاولويات
- عملية المعالجة
- معالجة
- إنتاج
- المنتج
- ملفي الشخصي
- عميق
- التقدّم
- تقدم
- تدريجيا
- واعد
- تعزيز
- مطالبات
- نشر
- لائق
- الملكية
- حماية
- محمي
- مصدر
- توفير
- نشرت
- متابعة
- pytorch
- يحسب
- عشوائية
- العشوائية
- نطاق
- معدل
- استعداد
- مملكة
- الاعتراف
- إعادة تعريف
- صقل
- مكرر
- يعكس
- يعكس
- النظام الحاكم
- منتظم
- صلة
- إزالة
- أداء
- تكرار
- التمثيل
- يمثل
- استنساخ
- تطلب
- يتطلب
- تشبه
- إعادة تشكيل
- احترام
- فيما يتعلق
- مسؤول
- مسؤول
- مما أدى
- عائد أعلى
- وحي
- إحياء
- ثور
- RGB
- النوادي الثرية
- حقوق
- ارتفاع
- قوي
- النوع
- نفسه
- تم الحفظ
- إنقاذ
- مشهد
- علوم
- نطاق
- سيناريو
- انظر تعريف
- SELF
- حساس
- مستقل
- تسلسل
- يخدم
- طقم
- ضبط
- الإعداد
- عدة
- شادو
- تشكيل
- نقل
- التحولات
- ينبغي
- عرض
- التفضيل
- أظهرت
- هام
- منذ
- ببطء
- قصاصة
- So
- متطور
- روح
- مصدر
- المصدر
- الفضاء
- توتر
- على وجه التحديد
- طيف
- مربع
- مستقر
- المسرح
- موقف
- ابتداء
- إحصائي
- ثابت
- خطوة
- الإستراتيجيات
- سعي
- بناء
- مذهل
- نمط
- موضوع
- لاحق
- هذه
- التكافلية
- متآزر
- تركيب
- اصطناعي
- تناسب
- يأخذ
- مع الأخذ
- الهدف
- تقني
- تقنيات
- التكنولوجية
- التكنولوجيا
- تكنولوجيا
- tensorflow
- عهد
- أن
- •
- المستقبل
- المصدر
- من مشاركة
- منهم
- هناك.
- تشبه
- هم
- يزدهر
- عبر
- وهكذا
- إلى
- أدوات
- شعلة
- تورشفيجن
- تواصل
- نحو
- تتبع الشحنة
- تقليدي
- قطار
- متدرب
- قادة الإيمان
- تحول
- تحول
- التحولات
- التحويلية
- تحول
- تحويل
- التحويلات
- الشفافية
- صحيح
- محاولة
- فهم
- فهم
- فريد من نوعه
- حتى
- تكشف عن
- تحديث
- بناء على
- us
- تستخدم
- مستعمل
- استخدام
- سهل حياتك
- صالح
- التحقق
- بواسطة
- الاطلاع على
- وجهات النظر
- رؤيتنا
- بصري
- الفنون البصرية
- التصور
- تصور
- بصريا
- حيوي
- وكان
- we
- ويب بي
- ابحث عن
- ما هي تفاصيل
- التي
- في حين
- همس
- من الذى
- واسع
- مدى واسع
- سوف
- نافذة
- مع
- في غضون
- بدون
- للعمل
- أعمال
- العالم
- X
- نعم فعلا
- حتى الآن
- لصحتك!
- زفيرنت
- صفر