الصورة عن طريق com.frimufilms on Freepik
هذا عصر يأتي فيه اختراقات الذكاء الاصطناعي يوميًا. لم يكن لدينا الكثير من الذكاء الاصطناعي الذي تم إنشاؤه في الأماكن العامة قبل بضع سنوات ، ولكن التكنولوجيا الآن في متناول الجميع. إنه ممتاز للعديد من المبدعين أو الشركات الفردية التي ترغب في الاستفادة بشكل كبير من التكنولوجيا لتطوير شيء معقد ، والذي قد يستغرق وقتًا طويلاً.
يعد إصدار نموذج GPT-3.5 بواسطة OpenAI. ما هو نموذج GPT-3.5؟ إذا تركت النموذج يتحدث عن نفسه. في هذه الحالة ، الجواب هو "نموذج ذكاء اصطناعي متقدم للغاية في مجال معالجة اللغة الطبيعية ، مع تحسينات كبيرة في إنشاء نصوص دقيقة وذات صلة بالسياقر ".
يوفر OpenAI واجهة برمجة تطبيقات لنموذج GPT-3.5 يمكننا استخدامها لتطوير تطبيق بسيط ، مثل مُلخص النص. للقيام بذلك ، يمكننا استخدام Python لدمج API النموذجي في تطبيقنا المقصود بسلاسة. كيف تبدو العملية؟ دعنا ندخله.
هناك بعض المتطلبات الأساسية قبل اتباع هذا البرنامج التعليمي ، بما في ذلك:
- معرفة لغة Python ، بما في ذلك معرفة استخدام المكتبات الخارجية و IDE
- فهم واجهات برمجة التطبيقات والتعامل مع نقطة النهاية مع بايثون
- الوصول إلى واجهات برمجة تطبيقات OpenAI
للحصول على وصول OpenAI APIs ، يجب علينا التسجيل في منصة مطور OpenAI وقم بزيارة عرض مفاتيح API في ملف التعريف الخاص بك. على الويب ، انقر فوق الزر "إنشاء مفتاح سري جديد" للحصول على وصول إلى واجهة برمجة التطبيقات (انظر الصورة أدناه). تذكر حفظ المفاتيح ، حيث لن تظهر المفاتيح بعد ذلك.

صورة المؤلف
مع كل الاستعدادات جاهزة ، دعنا نحاول فهم أساسيات نموذج OpenAI APIs.
• طراز عائلة GPT-3.5 تم تحديده للعديد من المهام اللغوية ، ويتفوق كل نموذج في الأسرة في بعض المهام. في هذا المثال التعليمي ، سنستخدم ملحق gpt-3.5-turbo حيث كان النموذج الحالي الموصى به عندما تمت كتابة هذه المقالة لقدرته وكفاءته من حيث التكلفة.
غالبًا ما نستخدم ملف text-davinci-003 في البرنامج التعليمي OpenAI ، لكننا سنستخدم النموذج الحالي لهذا البرنامج التعليمي. سوف نعتمد على إتمام الدردشة نقطة النهاية بدلاً من الإكمال لأن النموذج الحالي الموصى به هو نموذج محادثة. حتى لو كان الاسم نموذج دردشة ، فإنه يعمل مع أي مهمة لغوية.
دعنا نحاول فهم كيفية عمل API. أولاً ، نحتاج إلى تثبيت حزم OpenAI الحالية.
pip install openai
بعد أن ننتهي من تثبيت الحزمة ، سنحاول استخدام API عن طريق الاتصال عبر نقطة نهاية ChatCompletion. ومع ذلك ، نحن بحاجة إلى تهيئة البيئة قبل أن نواصل.
في IDE المفضل لديك (بالنسبة لي ، إنه رمز VS) ، قم بإنشاء ملفين يسمى .env و summarizer_app.py، على غرار الصورة أدناه.
صورة المؤلف
• summarizer_app.py هو المكان الذي سنبني فيه تطبيق الملخص البسيط ، و .env الملف هو المكان الذي سنخزن فيه مفتاح API الخاص بنا. لأسباب أمنية ، يُنصح دائمًا بفصل مفتاح API الخاص بنا في ملف آخر بدلاً من ترميزه في ملف Python.
في مجلة .env وضع ملف بناء الجملة التالي وحفظ الملف. استبدل your_api_key_here بمفتاح API الفعلي. لا تقم بتغيير مفتاح API إلى كائن سلسلة ؛ دعهم كما هو.
OPENAI_API_KEY=your_api_key_here
لفهم GPT-3.5 API بشكل أفضل ؛ سنستخدم الكود التالي لتوليد كلمة ملخّص.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
الكود أعلاه هو كيفية تفاعلنا مع نموذج OpenAI APIs GPT-3.5. باستخدام ChatCompletion API ، نقوم بإنشاء محادثة وسنحصل على النتيجة المرجوة بعد تمرير المطالبة.
دعونا نقسم كل جزء لفهمهم بشكل أفضل. في السطر الأول ، نستخدم openai.ChatCompletion.create رمز لإنشاء الاستجابة من المطالبة التي سنقوم بتمريرها إلى واجهة برمجة التطبيقات.
في السطر التالي ، لدينا المعامِلات الفائقة التي نستخدمها لتحسين مهامنا النصية. فيما يلي ملخص لكل وظيفة معلمة تشعبية:
model: عائلة الطراز التي نريد استخدامها. في هذا البرنامج التعليمي ، نستخدم النموذج الحالي الموصى به (gpt-3.5-turbo).max_tokens: الحد الأعلى للكلمات التي تم إنشاؤها بواسطة النموذج. يساعد على تحديد طول النص الذي تم إنشاؤه.temperature: عشوائية ناتج النموذج ، مع ارتفاع درجة الحرارة ، تعني نتيجة أكثر تنوعًا وإبداعًا. يتراوح نطاق القيم بين 0 إلى ما لا نهاية ، على الرغم من أن القيم التي تزيد عن 2 ليست شائعة.top_p: يعتبر أخذ عينات أعلى P أو top-k أو أخذ عينات النواة معلمة للتحكم في تجمع العينات من توزيع المخرجات. على سبيل المثال ، القيمة 0.1 تعني أن النموذج يأخذ عينات فقط من الناتج من أعلى 10٪ من التوزيع. كان نطاق القيمة بين 0 و 1 ؛ القيم الأعلى تعني نتيجة أكثر تنوعًا.frequency_penalty: عقوبة رمز التكرار من الإخراج. نطاق القيمة بين -2 إلى 2 ، حيث تمنع القيم الموجبة النموذج من تكرار الرمز المميز بينما تشجع القيم السالبة النموذج على استخدام كلمات أكثر تكرارًا. 0 يعني عدم وجود عقوبة.messages: المعلمة التي نمرر فيها مطالبة النص لتتم معالجتها مع النموذج. نقوم بتمرير قائمة من القواميس حيث يكون المفتاح هو كائن الدور (إما "النظام" أو "المستخدم" أو "المساعد") التي تساعد النموذج على فهم السياق والهيكل بينما القيم هي السياق.- دور "النظام" هو المبادئ التوجيهية المحددة لسلوك "المساعد" النموذجي ،
- يمثل دور "المستخدم" الموجه من الشخص الذي يتفاعل مع النموذج ،
- دور "المساعد" هو الرد على موجه "المستخدم"
بعد شرح المعلمة أعلاه ، يمكننا أن نرى أن ملف messages المعلمة أعلاه لها اثنين من وجوه القاموس. القاموس الأول هو كيف قمنا بتعيين النموذج كمُلخص للنص. والثاني هو المكان الذي سنمرر فيه النص ونحصل على ناتج التلخيص.
في القاموس الثاني ، سترى أيضًا المتغير person_type و prompt. person_type هو متغير استخدمته للتحكم في النمط الملخص ، والذي سأعرضه في البرنامج التعليمي. بينما ال prompt هو المكان الذي نمرر فيه نصنا ليتم تلخيصه.
استمرارًا للدرس التعليمي ، ضع الكود أدناه في ملف summarizer_app.py ملف وسنحاول تشغيل كيفية عمل الوظيفة أدناه.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
الكود أعلاه هو المكان الذي نقوم فيه بإنشاء دالة Python التي تقبل العديد من المعلمات التي ناقشناها سابقًا وإرجاع إخراج ملخص النص.
جرب الوظيفة أعلاه مع المعلمة الخاصة بك وانظر الإخراج. ثم دعنا نكمل البرنامج التعليمي لإنشاء تطبيق بسيط باستخدام الحزمة المتدفقة.
انسيابي عبارة عن حزمة Python مفتوحة المصدر مصممة لإنشاء تطبيقات الويب للتعلم الآلي وعلوم البيانات. إنه سهل الاستخدام وبديهي ، لذلك يوصى به للعديد من المبتدئين.
دعنا نثبِّت الحزمة المتدفقة قبل أن نواصل البرنامج التعليمي.
pip install streamlit
بعد انتهاء التثبيت ، ضع الكود التالي في ملف summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
حاول تشغيل التعليمات البرمجية التالية في موجه الأوامر لبدء التطبيق.
streamlit run summarizer_app.py
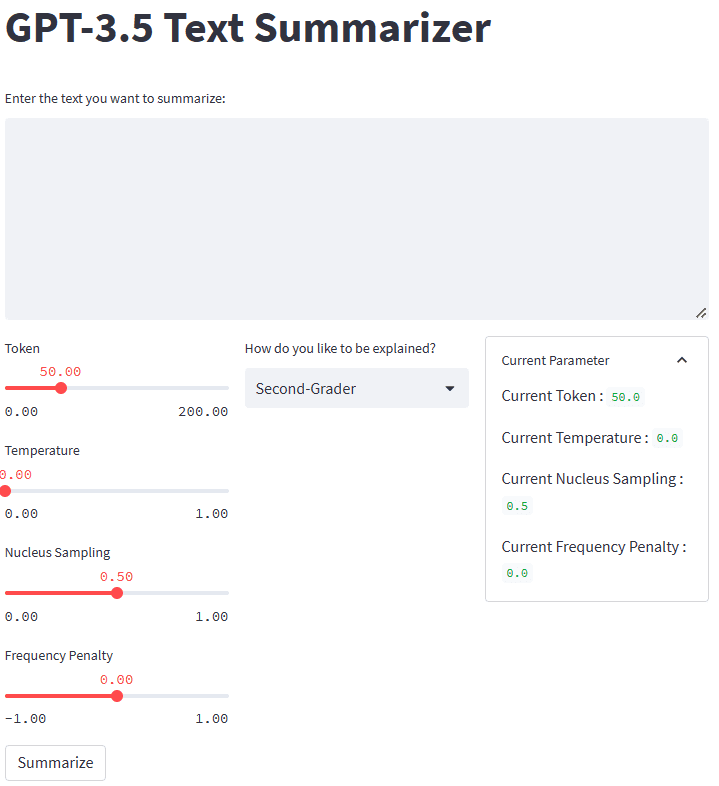
إذا كان كل شيء يعمل بشكل جيد ، فسترى التطبيق التالي في متصفحك الافتراضي.
صورة المؤلف
إذن ، ماذا حدث في الكود أعلاه؟ اسمحوا لي أن أشرح بإيجاز كل وظيفة استخدمناها:
.st.title: أدخل نص عنوان تطبيق الويب..st.write: يكتب الحجة في التطبيق ؛ يمكن أن يكون أي شيء سوى نص سلسلة..st.text_area: توفير مساحة لإدخال النص يمكن تخزينها في المتغير واستخدامها للمطالبة لملخص النص الخاص بنا.st.columns: حاويات الكائنات لتوفير التفاعل جنبًا إلى جنب..st.slider: توفير عنصر واجهة مستخدم منزلق بقيم محددة يمكن للمستخدم التفاعل معها. يتم تخزين القيمة في متغير يستخدم كمعامل نموذج..st.selectbox: توفير أداة تحديد للمستخدمين لتحديد نمط التلخيص الذي يريدونه. في المثال أعلاه ، نستخدم خمسة أنماط مختلفة..st.expander: توفير حاوية يمكن للمستخدمين توسيعها والاحتفاظ بالعديد من الكائنات..st.button: توفير زر يقوم بتشغيل الوظيفة المقصودة عندما يضغط عليها المستخدم.
نظرًا لأن الانسيابية ستصمم تلقائيًا واجهة المستخدم باتباع الكود المحدد من أعلى إلى أسفل ، فيمكننا التركيز بشكل أكبر على التفاعل.
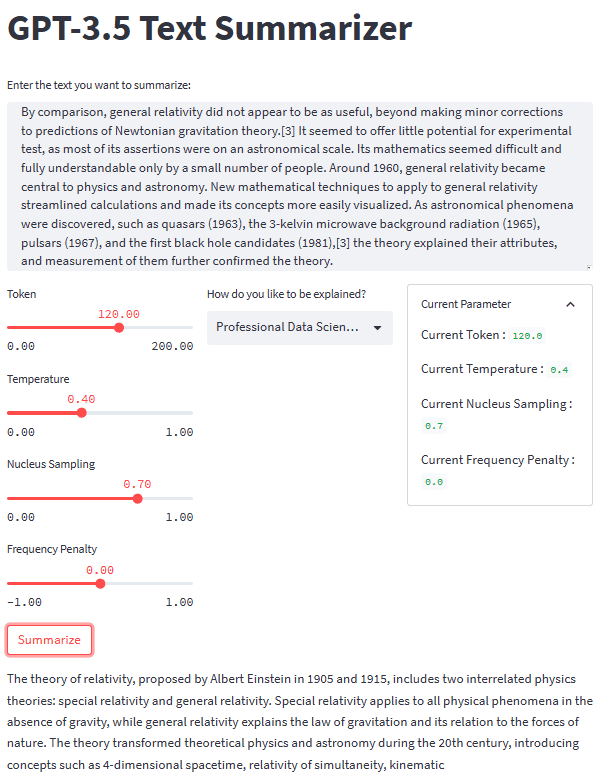
بعد وضع كل الأجزاء في مكانها الصحيح ، دعنا نجرب تطبيق التلخيص الخاص بنا بمثال نصي. على سبيل المثال لدينا ، سأستخدم صفحة نظرية النسبية في ويكيبيديا تلخيص النص. باستخدام المعلمة الافتراضية ونمط الصف الثاني ، نحصل على النتيجة التالية.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
قد تحصل على نتيجة مختلفة عن النتيجة أعلاه. لنجرب أسلوب ربات البيوت ونقوم بتعديل المعلمة قليلاً (الرمز 100 ، درجة الحرارة 0.5 ، أخذ عينات النواة 0.5 ، عقوبة التردد 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
كما نرى ، هناك اختلاف في أسلوب نفس النص الذي نقدمه. مع موجه التغيير والمعلمة ، يمكن أن يكون تطبيقنا أكثر فاعلية.
يمكن رؤية المظهر العام لتطبيقنا لملخص النص في الصورة أدناه.
صورة المؤلف
هذا هو البرنامج التعليمي حول إنشاء تطوير تطبيق ملخّص النص باستخدام GPT-3.5. يمكنك تعديل التطبيق بشكل أكبر ونشر التطبيق.
الذكاء الاصطناعي التوليدي آخذ في الازدياد ، ويجب علينا الاستفادة من هذه الفرصة من خلال إنشاء تطبيق رائع. في هذا البرنامج التعليمي ، سوف نتعلم كيفية عمل GPT-3.5 OpenAI APIs وكيفية استخدامها لإنشاء تطبيق مُلخص للنص بمساعدة Python وحزمة الانسيابية.
كورنليوس يودا ويجايا هو مدير مساعد لعلوم البيانات وكاتب بيانات. أثناء عمله بدوام كامل في Allianz Indonesia ، يحب مشاركة نصائح حول Python و Data عبر وسائل التواصل الاجتماعي وكتابة الوسائط.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- بلاتوبلوكشين. Web3 Metaverse Intelligence. تضخيم المعرفة. الوصول هنا.
- المصدر https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- :يكون
- ] [ص
- $ UP
- 1
- 100
- 28
- 7
- a
- من نحن
- فوق
- استمر
- الوصول
- يمكن الوصول
- دقيق
- كسب
- متقدم
- مميزات
- بعد
- AI
- الكل
- أليانز
- بالرغم ان
- دائما
- و
- آخر
- إجابة
- API
- الوصول إلى واجهة برمجة التطبيقات
- واجهات برمجة التطبيقات
- التطبيق
- تطبيق
- تطوير التطبيقات
- التطبيقات
- هي
- المنطقة
- حجة
- البند
- AS
- المساعد
- علم الفلك
- At
- تلقائيا
- الأساسية
- BE
- لان
- قبل
- مبتدئين
- أقل من
- أفضل
- ما بين
- قطعة
- اسود
- الثقوب السوداء
- الملابس السفلية
- صندوق
- استراحة
- اختراق
- اختراقات
- موجز
- المتصفح
- نساعدك في بناء
- زر
- by
- تسمى
- CAN
- حقيبة
- قرن
- تغيير
- الخيارات
- انقر
- الكود
- الأعمدة
- آت
- مشترك
- الشركات
- إكمال
- مجمع
- المفاهيم
- الرابط
- وعاء
- حاويات
- محتوى
- سياق الكلام
- استمر
- مراقبة
- محادثة
- استطاع
- خلق
- خلق
- الإبداع
- المبدعين
- حالياًّ
- يوميا
- البيانات
- علم البيانات
- عالم البيانات
- الترتيب
- نشر
- تصميم
- تصميم
- تطوير
- المطور
- التطوير التجاري
- فرق
- مختلف
- اكتشف
- ناقش
- توزيع
- عدة
- لا
- إلى أسفل
- كل
- إما
- شجع
- نقطة النهاية
- أدخل
- البيئة
- عصر
- الأثير (ETH)
- حتى
- كل شخص
- كل شىء
- مثال
- ممتاز
- تنفيذ
- وسع
- شرح
- شرح
- ويوضح
- خارجي
- للعائلات
- خيالي
- المفضلة—الحقيبة
- قليل
- حقل
- قم بتقديم
- ملفات
- الاسم الأول
- تركز
- متابعيك
- في حالة
- القوات
- تردد
- تبدأ من
- وظيفة
- وظيفي
- إضافي
- العلاجات العامة
- توليد
- ولدت
- توليد
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- الجاذبية
- موجات الجاذبية
- خطورة
- المبادئ التوجيهية
- معالجة
- حدث
- يملك
- وجود
- مساعدة
- ساعد
- مفيد
- يساعد
- هنا
- أعلى
- جدا
- عقد
- ثقوب
- كيفية
- كيفية
- كيف نعمل
- لكن
- HTTPS
- i
- الأفكار
- صورة
- استيراد
- أهمية
- تحسن
- تحسينات
- in
- يشمل
- بما فيه
- لا يصدق
- فرد
- أندونيسيا
- اللامحدودية
- بدء
- إدخال
- تثبيت
- تركيب
- بدلًا من ذلك
- دمج
- تفاعل
- التفاعل
- تفاعل
- إدخال
- حدسي
- IT
- انها
- JPG
- KD nuggets
- القفل
- مفاتيح
- المعرفة
- لغة
- القانون
- تعلم
- تعلم
- الطول
- المكتبات
- مثل
- مما سيحدث
- خط
- لينكدين:
- قائمة
- طويل
- وقت طويل
- بحث
- يبدو مثل
- آلة
- آلة التعلم
- مدير
- كثير
- يعني
- الوسائط
- الرسالة
- ربما
- نموذج
- الأكثر من ذلك
- أكثر
- خطوة
- متعدد
- الاسم
- طبيعي
- اللغة الطبيعية
- معالجة اللغات الطبيعية
- الطبيعة
- حاجة
- سلبي
- جديد
- التالي
- موضوع
- الأجسام
- تحصل
- of
- on
- ONE
- المصدر المفتوح
- OpenAI
- الفرصة
- خيار
- OS
- أخرى
- الناتج
- الكلي
- صفقة
- حزم
- المعلمة
- المعلمات
- جزء
- مرور
- شخص
- مادي
- فيزياء
- قطعة
- المكان
- الكواكب
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- تجمع
- إيجابي
- توقع
- الشروط
- سابقا
- عملية المعالجة
- معالجة
- محترف
- ملفي الشخصي
- المقترح
- تزود
- ويوفر
- جمهور
- وضع
- بايثون
- العشوائية
- نطاق
- بدلا
- استعداد
- الأسباب
- موصى به
- تسجيل جديد
- علاقة
- الافراج عن
- ذات الصلة
- تذكر
- تكرارية
- يحل محل
- يمثل
- استجابة
- نتيجة
- عائد أعلى
- ارتفاع
- النوع
- يجري
- نفسه
- حفظ
- علوم
- عالم
- بسلاسة
- الثاني
- سيكريت
- القسم
- أمن
- اختيار
- مستقل
- طقم
- مشاركة
- ينبغي
- إظهار
- أظهرت
- بشكل ملحوظ
- مماثل
- الاشارات
- المنزلق
- سمارت
- So
- العدالة
- وسائل التواصل الاجتماعي
- بعض
- شيء
- الفضاء
- تختص
- محدد
- نجوم
- متجر
- تخزين
- خيط
- بناء
- طالب
- نمط
- أنماط
- هذه
- تلخيص
- ملخص
- بناء الجملة
- نظام
- أخذ
- حديث
- محادثات
- مهمة
- المهام
- تكنولوجيا
- أن
- •
- القانون
- العالم
- منهم
- أنفسهم
- نظري
- تشبه
- الأشياء
- ثلاثة
- عبر
- الوقت
- نصائح
- عنوان
- إلى
- رمز
- تيشرت
- تحول
- البرنامج التعليمي
- ui
- فهم
- فهم
- جامعة
- us
- تستخدم
- مستخدم
- المستخدمين
- الاستفادة من
- قيمنا
- القيم
- مختلف
- كبير
- بواسطة
- المزيد
- قم بزيارتنا
- vs
- مقابل كود
- أمواج
- الويب
- تطبيق ويب
- حسن
- ابحث عن
- ما هي تفاصيل
- التي
- في حين
- من الذى
- ويكيبيديا
- سوف
- مع
- في غضون
- بدون
- كلمة
- كلمات
- للعمل
- عامل
- أعمال
- العالم
- سوف
- كاتب
- جاري الكتابة
- مكتوب
- سنوات
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت