تعمل العديد من المؤسسات، الصغيرة والكبيرة، على ترحيل وتحديث أعباء عمل التحليلات الخاصة بها على Amazon Web Services (AWS). هناك العديد من الأسباب التي تدفع العملاء إلى الانتقال إلى AWS، ولكن أحد الأسباب الرئيسية هو القدرة على استخدام الخدمات المُدارة بالكامل بدلاً من قضاء الوقت في صيانة البنية التحتية والتصحيح والمراقبة والنسخ الاحتياطي والمزيد. يمكن لفرق القيادة والتطوير قضاء المزيد من الوقت في تحسين الحلول الحالية وحتى تجربة حالات الاستخدام الجديدة، بدلاً من الحفاظ على البنية التحتية الحالية.
مع القدرة على التحرك بسرعة على AWS، يتعين عليك أيضًا أن تكون مسؤولاً عن البيانات التي تتلقاها وتعالجها مع استمرارك في التوسع. تشمل هذه المسؤوليات الامتثال لقوانين ولوائح خصوصية البيانات وعدم تخزين أو الكشف عن البيانات الحساسة مثل معلومات التعريف الشخصية (PII) أو المعلومات الصحية المحمية (PHI) من المصادر الأولية.
في هذا المنشور، نستعرض بنية عالية المستوى وحالة استخدام محددة توضح كيف يمكنك الاستمرار في توسيع نطاق النظام الأساسي لبيانات مؤسستك دون الحاجة إلى قضاء قدر كبير من وقت التطوير لمعالجة مخاوف خصوصية البيانات. نحن نستخدم غراء AWS لاكتشاف بيانات تحديد الهوية الشخصية وإخفائها وتنقيحها قبل تحميلها خدمة Amazon OpenSearch.
حل نظرة عامة
يوضح الرسم البياني التالي بنية الحلول عالية المستوى. لقد حددنا جميع طبقات ومكونات تصميمنا بما يتماشى مع AWS Well-Architured Framework Data Analytics Lens.
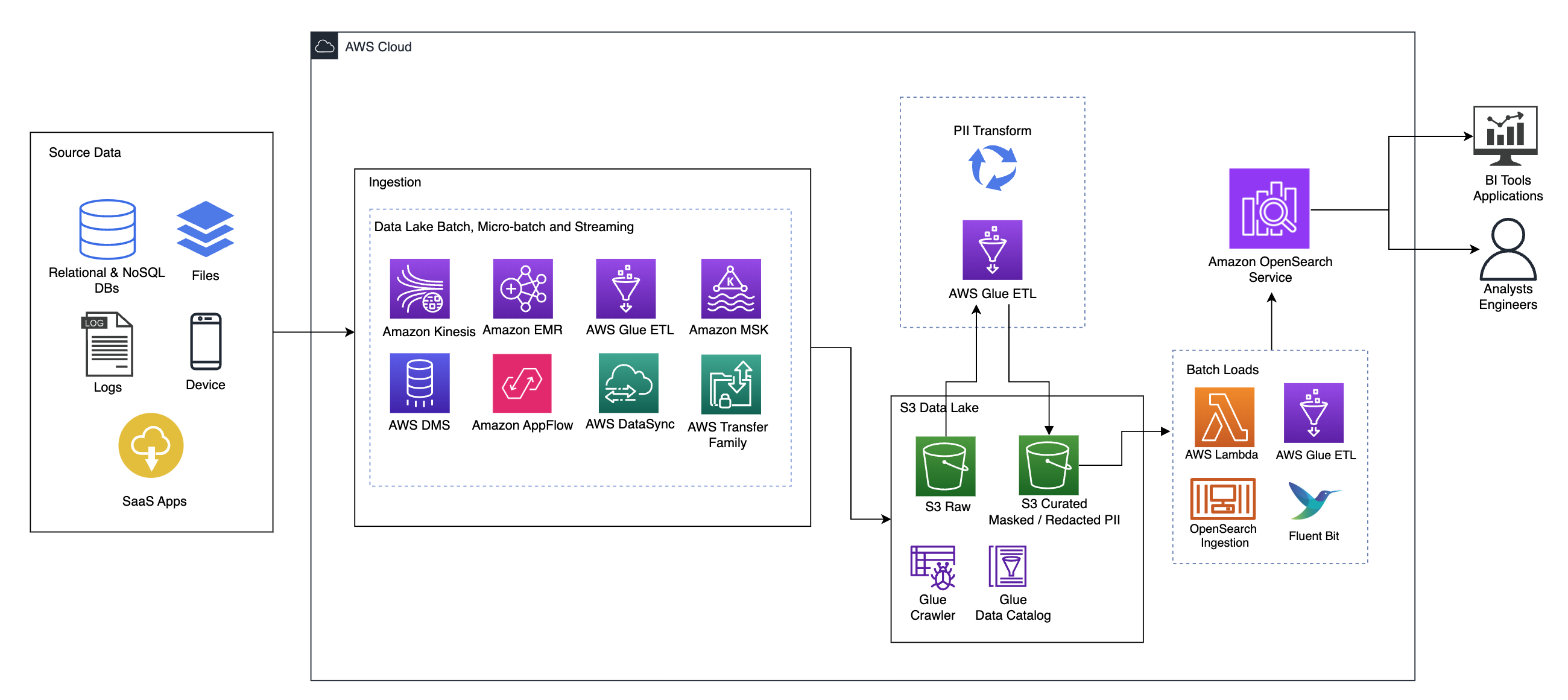
تتكون البنية من عدد من العناصر:
مصدر البيانات
قد تأتي البيانات من عشرات إلى مئات المصادر، بما في ذلك قواعد البيانات وعمليات نقل الملفات والسجلات وتطبيقات البرامج كخدمة (SaaS) والمزيد. قد لا تتمكن المؤسسات دائمًا من التحكم في البيانات التي تأتي عبر هذه القنوات وإلى وحدات التخزين والتطبيقات النهائية الخاصة بها.
الاستيعاب: دفعة بحيرة البيانات، دفعة صغيرة، والتدفق
تقوم العديد من المؤسسات بإدخال بيانات المصدر الخاصة بها إلى بحيرة البيانات الخاصة بها بطرق مختلفة، بما في ذلك الوظائف المجمعة والدُفعات الصغيرة والتدفق. على سبيل المثال، أمازون EMR, غراء AWSو خدمة ترحيل قاعدة بيانات AWS يمكن استخدام (AWS DMS) جميعًا لتنفيذ عمليات الدُفعات و/أو الدفق التي تغرق في بحيرة البيانات خدمة تخزين أمازون البسيطة (أمازون S3). الأمازون AppFlow يمكن استخدامها لنقل البيانات من تطبيقات SaaS المختلفة إلى بحيرة البيانات. أوس داتا سينك و عائلة AWS Transfer يمكن أن تساعد في نقل الملفات من وإلى بحيرة البيانات عبر عدد من البروتوكولات المختلفة. أمازون كينسيس وتتمتع Amazon MSK أيضًا بقدرات على دفق البيانات مباشرةً إلى مستودع البيانات على Amazon S3.
بحيرة بيانات S3
إن استخدام Amazon S3 لمستودع البيانات الخاص بك يتماشى مع استراتيجية البيانات الحديثة. فهو يوفر مساحة تخزين منخفضة التكلفة دون التضحية بالأداء أو الموثوقية أو التوفر. باستخدام هذا النهج، يمكنك توفير الحوسبة لبياناتك حسب الحاجة والدفع فقط مقابل السعة التي تحتاجها للتشغيل.
في هذه البنية، يمكن أن تأتي البيانات الأولية من مجموعة متنوعة من المصادر (الداخلية والخارجية)، والتي قد تحتوي على بيانات حساسة.
باستخدام برامج زحف AWS Glue، يمكننا اكتشاف البيانات وفهرستها، مما سينشئ مخططات الجدول لنا، ويجعل في النهاية من السهل استخدام AWS Glue ETL مع تحويل PII لاكتشاف وإخفاء أو تنقيح أي بيانات حساسة قد تكون وصلت في بحيرة البيانات.
سياق الأعمال ومجموعات البيانات
لتوضيح قيمة النهج الذي نتبعه، لنتخيل أنك جزء من فريق هندسة البيانات في مؤسسة خدمات مالية. تتمثل متطلباتك في اكتشاف البيانات الحساسة وإخفائها عند استيعابها في البيئة السحابية لمؤسستك. سيتم استهلاك البيانات من خلال العمليات التحليلية النهائية. في المستقبل، سيتمكن المستخدمون لديك من البحث بأمان في معاملات الدفع التاريخية استنادًا إلى تدفقات البيانات المجمعة من الأنظمة المصرفية الداخلية. يجب إخفاء نتائج البحث من فرق التشغيل والعملاء وتطبيقات الواجهة في الحقول الحساسة.
يوضح الجدول التالي بنية البيانات المستخدمة للحل. من أجل الوضوح، قمنا بتعيين أسماء الأعمدة الأولية إلى أسماء الأعمدة المنسقة. ستلاحظ أن الحقول المتعددة ضمن هذا المخطط تعتبر بيانات حساسة، مثل الاسم الأول واسم العائلة ورقم الضمان الاجتماعي (SSN) والعنوان ورقم بطاقة الائتمان ورقم الهاتف والبريد الإلكتروني وعنوان IPv4.
| اسم العمود الخام | اسم العمود المنسق | النوع |
| c0 | الاسم الاول | سلسلة |
| c1 | الكنية | سلسلة |
| c2 | SSN | سلسلة |
| c3 | العنوان | سلسلة |
| c4 | الرمز البريدي | سلسلة |
| c5 | البلد | سلسلة |
| c6 | buy_site | سلسلة |
| c7 | رقم البطاقة الائتمانية | سلسلة |
| c8 | Credit_card_provider | سلسلة |
| c9 | عملة | سلسلة |
| c10 | buy_value | عدد صحيح |
| c11 | تاريخ الصفقة | تاريخ |
| c12 | رقم الهاتف | سلسلة |
| c13 | البريد الإلكتروني | سلسلة |
| c14 | ipv4 | سلسلة |
حالة الاستخدام: اكتشاف دفعة معلومات تحديد الهوية الشخصية (PII) قبل التحميل إلى خدمة OpenSearch
العملاء الذين يقومون بتنفيذ البنية التالية قاموا ببناء بحيرة البيانات الخاصة بهم على Amazon S3 لتشغيل أنواع مختلفة من التحليلات على نطاق واسع. يعد هذا الحل مناسبًا للعملاء الذين لا يحتاجون إلى استيعاب خدمة OpenSearch في الوقت الفعلي ويخططون لاستخدام أدوات تكامل البيانات التي تعمل وفقًا لجدول زمني أو يتم تشغيلها من خلال الأحداث.
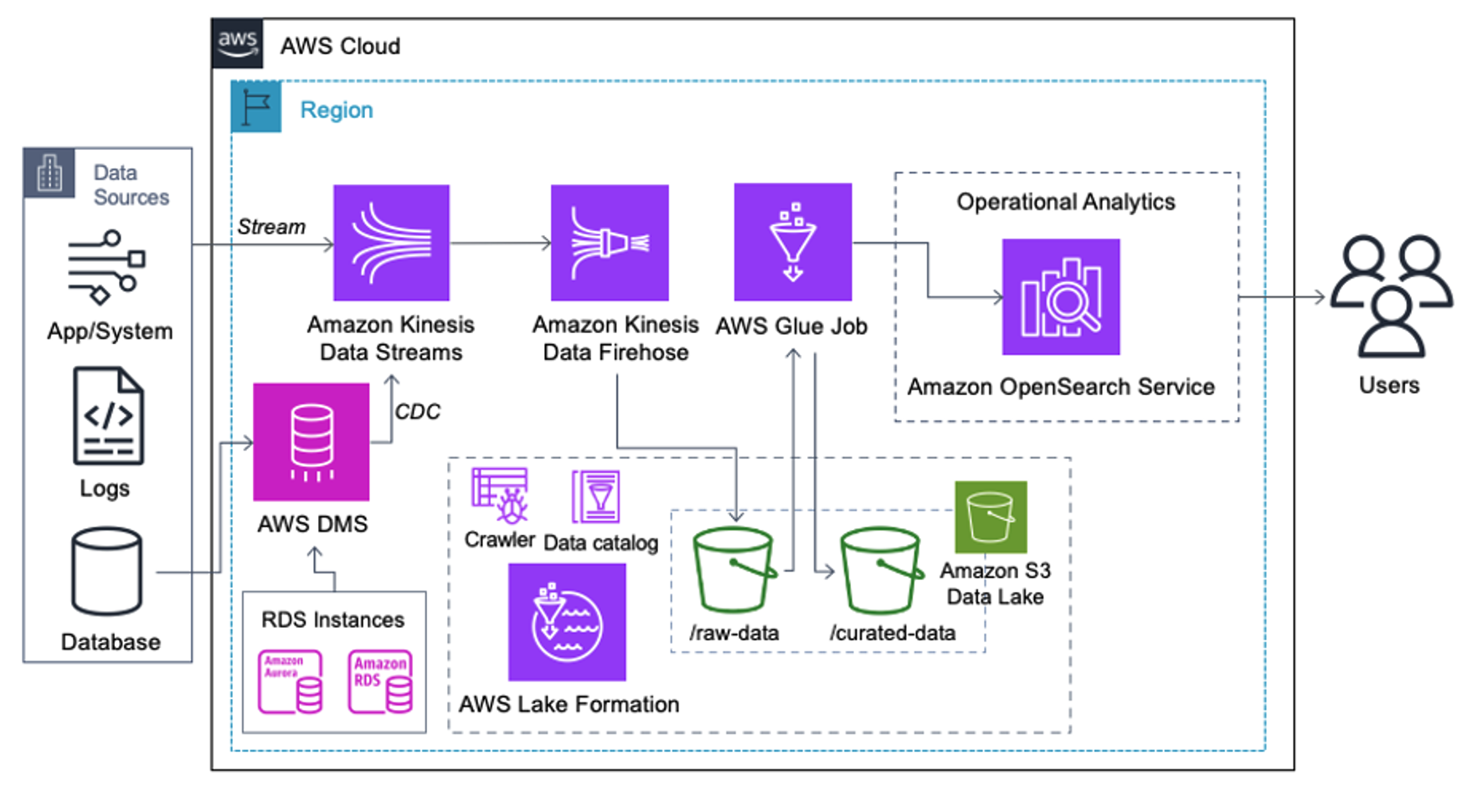
قبل وصول سجلات البيانات إلى Amazon S3، نقوم بتنفيذ طبقة استيعاب لجلب جميع تدفقات البيانات بشكل موثوق وآمن إلى مستودع البيانات. يتم نشر Kinesis Data Streams كطبقة استيعاب لتسريع استيعاب تدفقات البيانات المنظمة وشبه المنظمة. ومن الأمثلة على ذلك تغييرات قاعدة البيانات العلائقية، أو التطبيقات، أو سجلات النظام، أو تدفقات النقر. بالنسبة لحالات استخدام التقاط بيانات التغيير (CDC)، يمكنك استخدام Kinesis Data Streams كهدف لـ AWS DMS. يتم إرسال التطبيقات أو الأنظمة التي تولد تدفقات تحتوي على بيانات حساسة إلى تدفق بيانات Kinesis عبر إحدى الطرق الثلاث المدعومة: Amazon Kinesis Agent، أو AWS SDK لـ Java، أو مكتبة Kinesis Producer Library. كخطوة أخيرة، أمازون كينسيس داتا فايرهاوس يساعدنا على تحميل دفعات من البيانات في الوقت الفعلي تقريبًا بشكل موثوق إلى وجهة مستودع البيانات S3 الخاص بنا.
توضح لقطة الشاشة التالية كيفية تدفق البيانات عبر Kinesis Data Streams عبر عارض البيانات ويسترد بيانات العينة التي تصل إلى بادئة S3 الأولية. بالنسبة لهذه البنية، اتبعنا دورة حياة البيانات لبادئات S3 على النحو الموصى به في مؤسسة بحيرة البيانات.
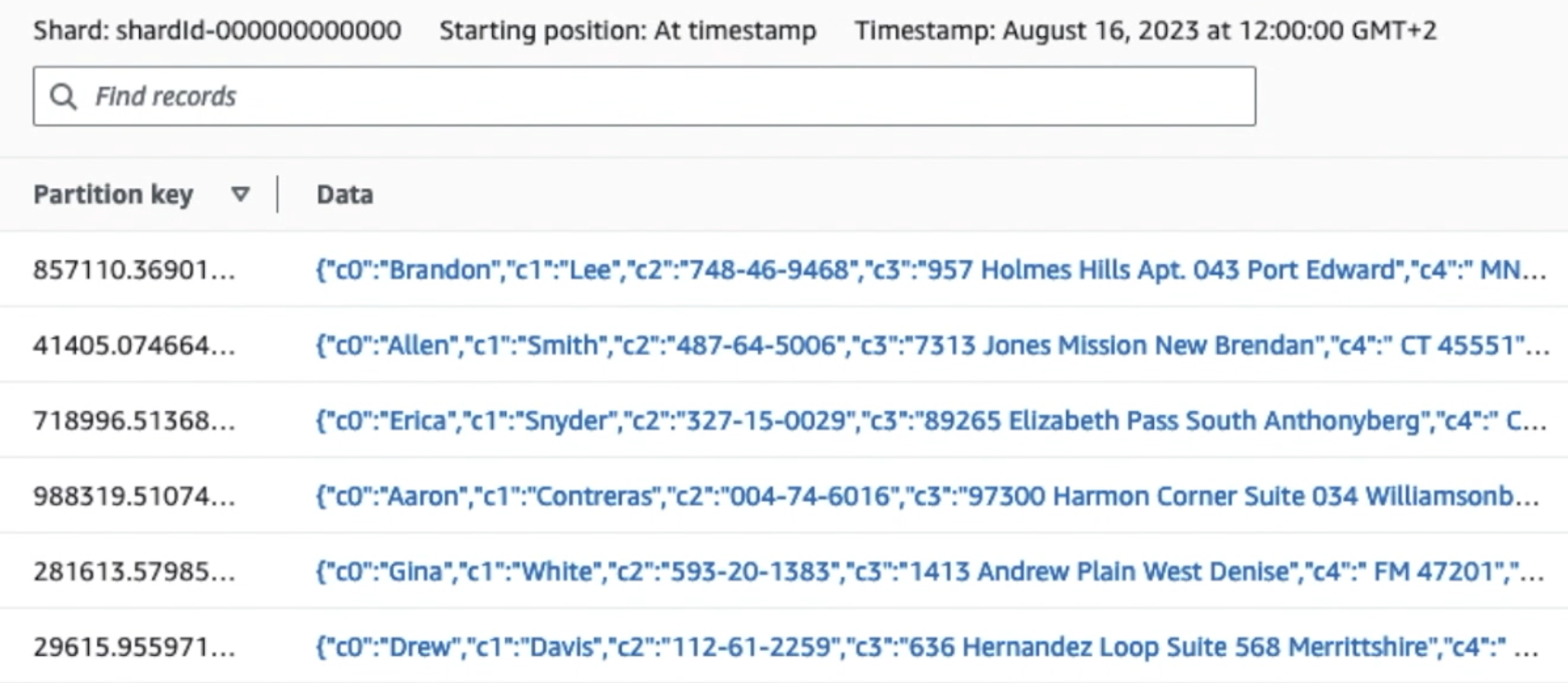
كما ترون من تفاصيل السجل الأول في لقطة الشاشة التالية، تتبع حمولة JSON نفس المخطط كما في القسم السابق. يمكنك رؤية البيانات غير المنقحة تتدفق إلى تدفق بيانات Kinesis، والتي سيتم تعتيمها لاحقًا في المراحل اللاحقة.
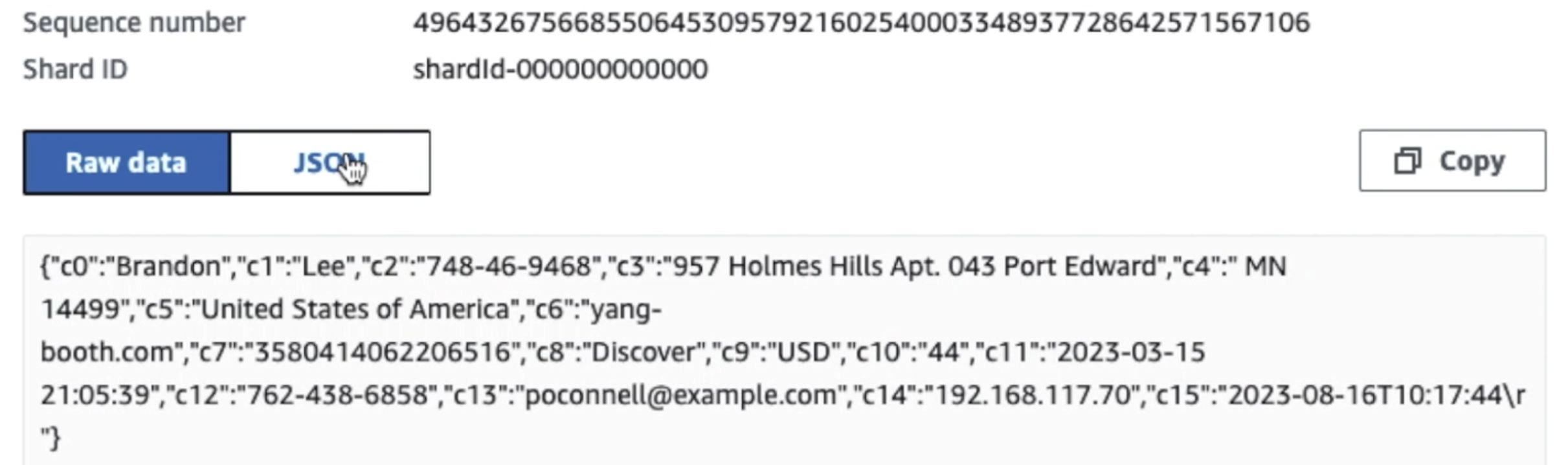
بعد أن يتم جمع البيانات واستيعابها في Kinesis Data Streams وتسليمها إلى حاوية S3 باستخدام Kinesis Data Firehose، تتولى طبقة المعالجة الخاصة بالبنية. نحن نستخدم تحويل AWS Glue PII لأتمتة اكتشاف البيانات الحساسة وإخفائها في مسارنا. كما هو موضح في مخطط سير العمل التالي، اتبعنا منهج ETL مرئي بدون تعليمات برمجية لتنفيذ مهمة التحويل الخاصة بنا في AWS Glue Studio.
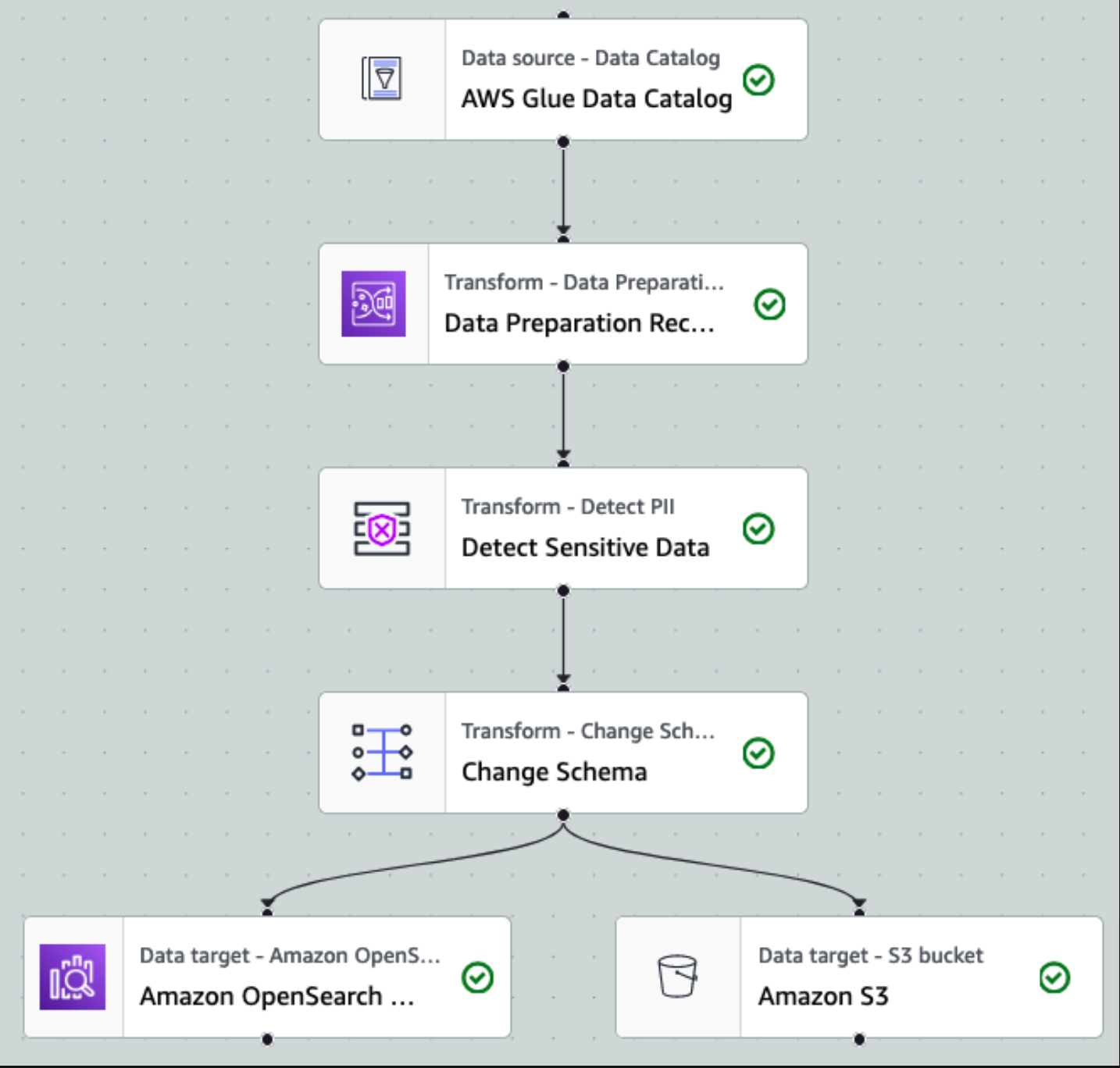
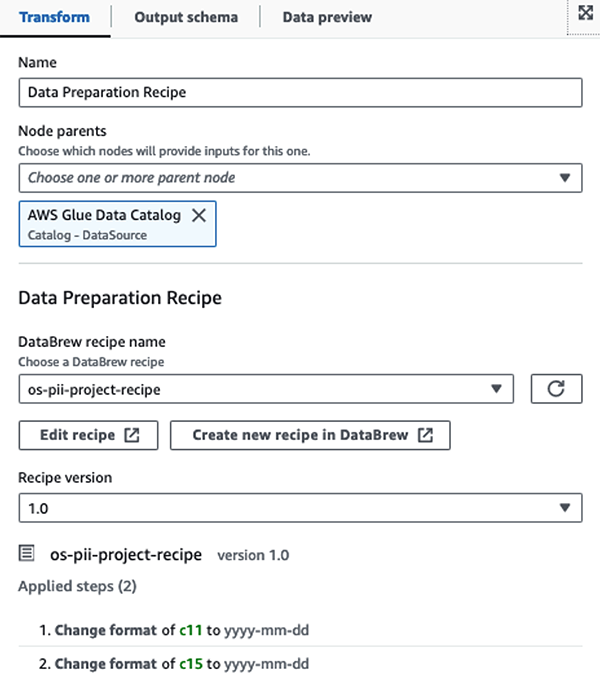
أولاً، نقوم بالوصول إلى جدول كتالوج البيانات المصدر الخام من ملف pii_data_db قاعدة البيانات. يحتوي الجدول على بنية المخطط الموضحة في القسم السابق. لتتبع البيانات المعالجة الخام، استخدمنا إشارات مرجعية للوظيفة.

نستخدم وصفات AWS Glue DataBrew في مهمة ETL المرئية لـ AWS Glue Studio لتحويل سمتين للتاريخ لتتوافقا مع OpenSearch المتوقع صيغ. وهذا يسمح لنا بالحصول على تجربة كاملة بدون كود.
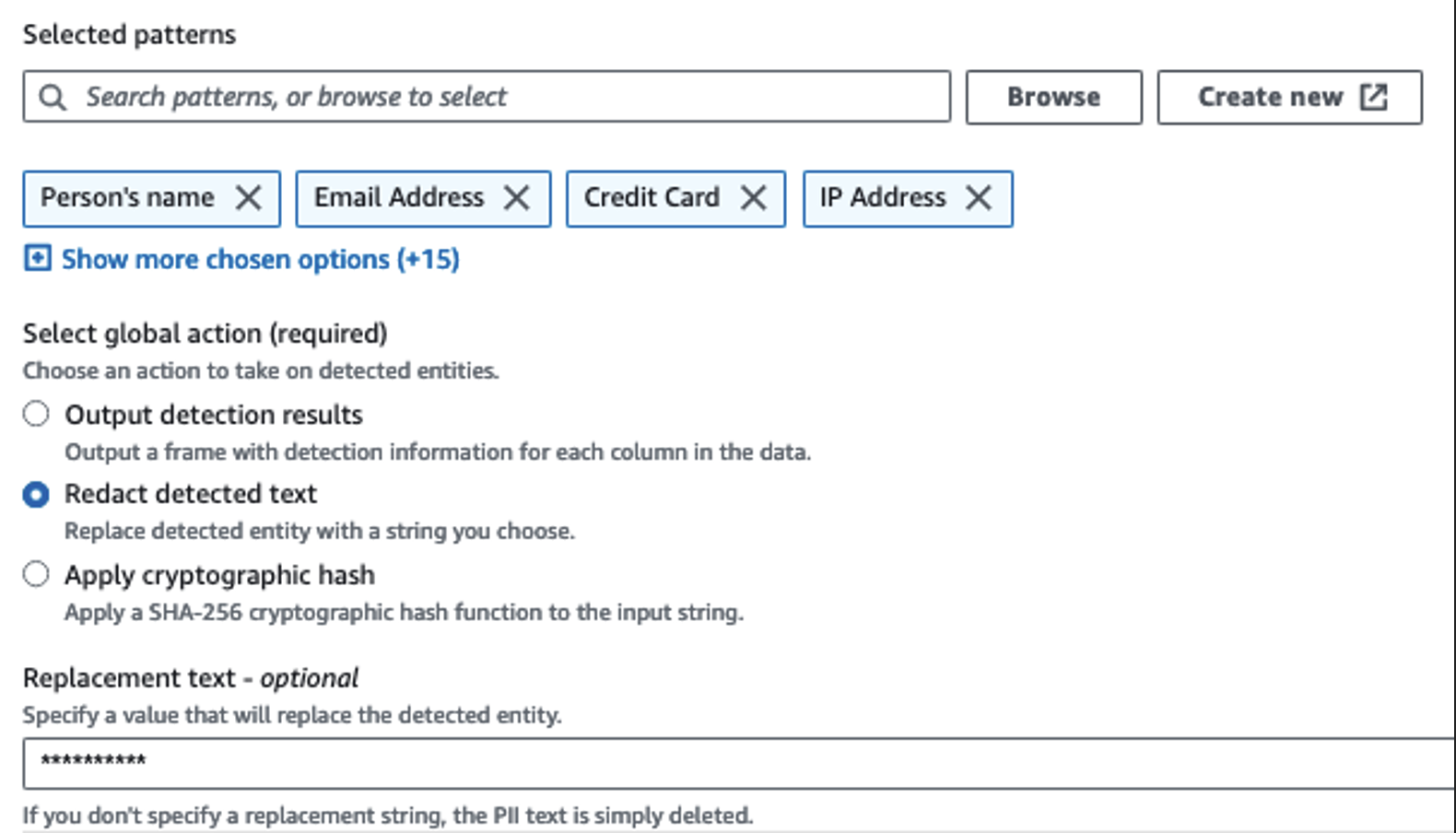
نستخدم الإجراء Detect PII لتحديد الأعمدة الحساسة. لقد سمحنا لـ AWS Glue بتحديد ذلك بناءً على الأنماط المحددة وعتبة الاكتشاف وجزء العينة من الصفوف من مجموعة البيانات. في مثالنا، استخدمنا أنماطًا تنطبق تحديدًا على الولايات المتحدة (مثل شبكات الأمان الاجتماعي) وقد لا تكتشف البيانات الحساسة من بلدان أخرى. يمكنك البحث عن الفئات والمواقع المتاحة التي تنطبق على حالة الاستخدام الخاصة بك أو استخدام التعبيرات العادية (regex) في AWS Glue لإنشاء كيانات الكشف عن البيانات الحساسة من بلدان أخرى.
من المهم تحديد طريقة أخذ العينات الصحيحة التي تقدمها AWS Glue. في هذا المثال، من المعروف أن البيانات الواردة من الدفق تحتوي على بيانات حساسة في كل صف، لذلك ليس من الضروري أخذ عينات 100% من الصفوف في مجموعة البيانات. إذا كان لديك متطلب يقضي بعدم السماح بوصول أي بيانات حساسة إلى المصادر النهائية، ففكر في أخذ عينات بنسبة 100% من البيانات للأنماط التي اخترتها، أو قم بمسح مجموعة البيانات بالكامل والتصرف على كل خلية على حدة لضمان اكتشاف جميع البيانات الحساسة. إن الفائدة التي تحصل عليها من أخذ العينات هي انخفاض التكاليف لأنك لا تحتاج إلى مسح أكبر قدر ممكن من البيانات.

يتيح لك إجراء اكتشاف معلومات تحديد الهوية الشخصية (PII) تحديد سلسلة افتراضية عند إخفاء البيانات الحساسة. في مثالنا، نستخدم السلسلة **********.
نحن نستخدم عملية تطبيق التعيين لإعادة تسمية وإزالة الأعمدة غير الضرورية مثل ingestion_year, ingestion_monthو ingestion_day. تسمح لنا هذه الخطوة أيضًا بتغيير نوع بيانات أحد الأعمدة (purchase_value) من السلسلة إلى عدد صحيح.

من هذه النقطة فصاعدًا، تنقسم المهمة إلى وجهتي إخراج: OpenSearch Service وAmazon S3.
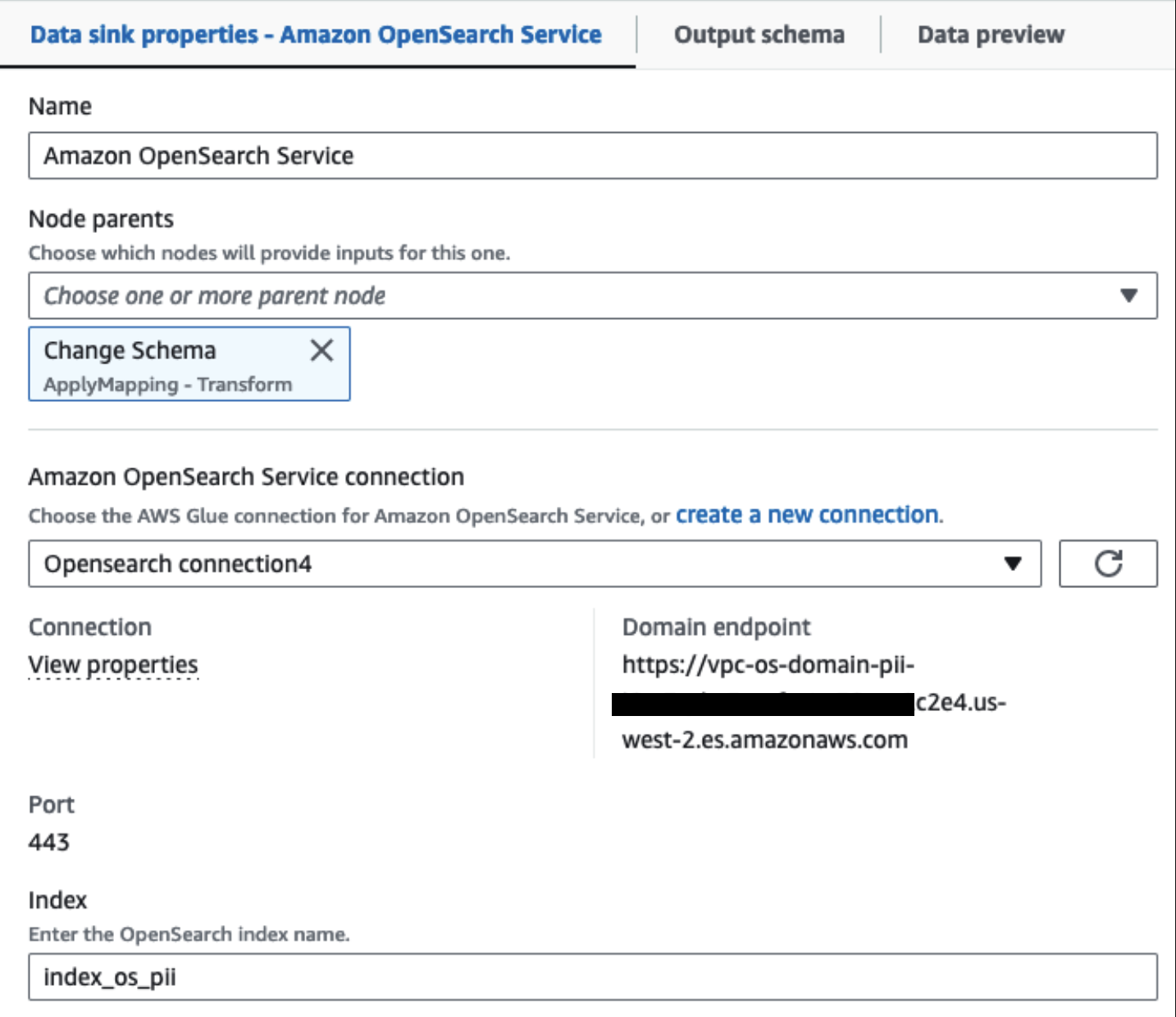
يتم توصيل مجموعة خدمة OpenSearch المتوفرة لدينا عبر موصل OpenSearch المدمج للغراء. نحدد فهرس OpenSearch الذي نرغب في الكتابة إليه ويتعامل الموصل مع بيانات الاعتماد والمجال والمنفذ. في لقطة الشاشة أدناه، نكتب إلى الفهرس المحدد index_os_pii.
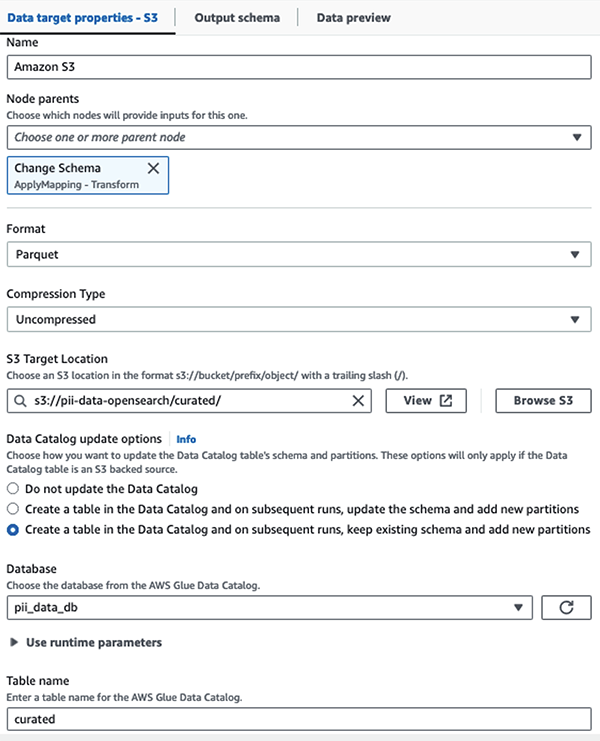
نقوم بتخزين مجموعة البيانات المقنعة في بادئة S3 المنسقة. هناك، لدينا بيانات تم تطبيعها وفقًا لحالة استخدام محددة والاستهلاك الآمن من قبل علماء البيانات أو لاحتياجات إعداد التقارير المخصصة.
للحصول على حوكمة موحدة والتحكم في الوصول ومسارات التدقيق لجميع مجموعات البيانات وجداول كتالوج البيانات، يمكنك استخدامها تكوين بحيرة AWS. يساعدك هذا على تقييد الوصول إلى جداول AWS Glue Data Catalog والبيانات الأساسية بحيث يقتصر فقط على المستخدمين والأدوار الذين تم منحهم الأذونات اللازمة للقيام بذلك.
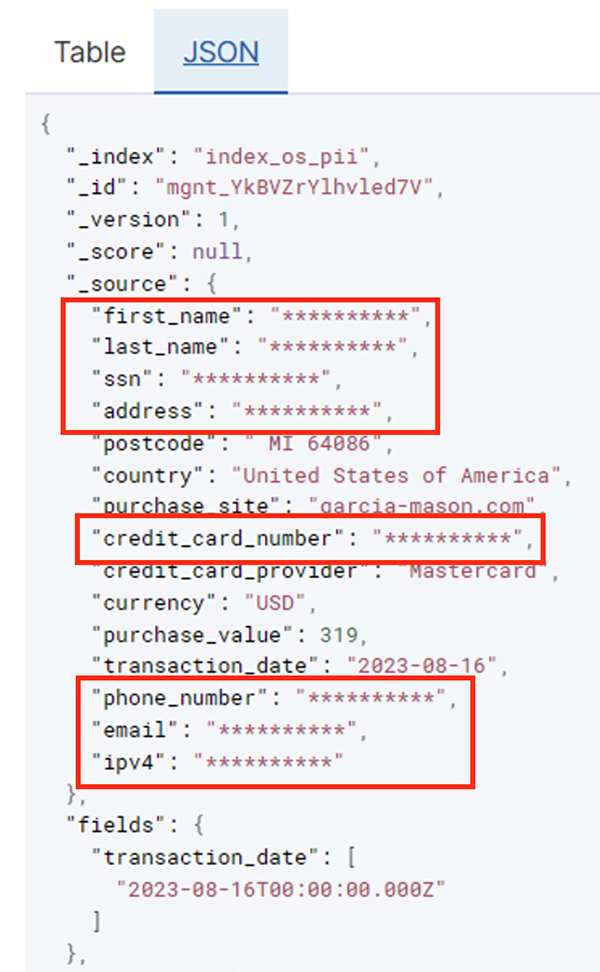
بعد تشغيل المهمة المجمعة بنجاح، يمكنك استخدام خدمة OpenSearch لتشغيل استعلامات البحث أو التقارير. كما هو موضح في لقطة الشاشة التالية، يقوم المسار بإخفاء الحقول الحساسة تلقائيًا دون بذل جهود لتطوير التعليمات البرمجية.

يمكنك تحديد الاتجاهات من البيانات التشغيلية، مثل مقدار المعاملات يوميًا التي تمت تصفيتها بواسطة مزود بطاقة الائتمان، كما هو موضح في لقطة الشاشة السابقة. يمكنك أيضًا تحديد المواقع والمجالات التي يجري فيها المستخدمون عمليات شراء. ال transaction_date تساعدنا السمة على رؤية هذه الاتجاهات بمرور الوقت. تعرض لقطة الشاشة التالية سجلاً يحتوي على جميع معلومات المعاملة التي تم تنقيحها بشكل مناسب.
للحصول على طرق بديلة حول كيفية تحميل البيانات في Amazon OpenSearch، راجع تحميل البيانات المتدفقة إلى Amazon OpenSearch Service.
علاوة على ذلك، يمكن أيضًا اكتشاف البيانات الحساسة وإخفائها باستخدام حلول AWS الأخرى. على سبيل المثال، يمكنك استخدام أمازون ماسي لاكتشاف البيانات الحساسة داخل حاوية S3، ثم استخدمها فهم الأمازون لتنقيح البيانات الحساسة التي تم اكتشافها. لمزيد من المعلومات، راجع التقنيات الشائعة لاكتشاف بيانات PHI وPII باستخدام خدمات AWS.
وفي الختام
ناقش هذا المنشور أهمية التعامل مع البيانات الحساسة داخل بيئتك والأساليب والبنيات المختلفة لتظل متوافقة مع السماح أيضًا لمؤسستك بالتوسع بسرعة. يجب أن يكون لديك الآن فهم جيد لكيفية اكتشاف بياناتك أو إخفائها أو تنقيحها وتحميلها إلى Amazon OpenSearch Service.
عن المؤلفين
 مايكل هاملتون هو مهندس حلول Sr Analytics الذي يركز على مساعدة عملاء المؤسسات على تحديث وتبسيط أعباء عمل التحليلات الخاصة بهم على AWS. يستمتع بركوب الدراجات الجبلية وقضاء الوقت مع زوجته وأطفاله الثلاثة عندما لا يعمل.
مايكل هاملتون هو مهندس حلول Sr Analytics الذي يركز على مساعدة عملاء المؤسسات على تحديث وتبسيط أعباء عمل التحليلات الخاصة بهم على AWS. يستمتع بركوب الدراجات الجبلية وقضاء الوقت مع زوجته وأطفاله الثلاثة عندما لا يعمل.
 دانيال روزو هو أحد كبار مهندسي الحلول لدى AWS لدعم العملاء في هولندا. شغفه هو هندسة حلول البيانات والتحليلات البسيطة ومساعدة العملاء على الانتقال إلى بنيات البيانات الحديثة. وخارج العمل، يستمتع بلعب التنس وركوب الدراجات.
دانيال روزو هو أحد كبار مهندسي الحلول لدى AWS لدعم العملاء في هولندا. شغفه هو هندسة حلول البيانات والتحليلات البسيطة ومساعدة العملاء على الانتقال إلى بنيات البيانات الحديثة. وخارج العمل، يستمتع بلعب التنس وركوب الدراجات.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :لديها
- :يكون
- :ليس
- :أين
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- القدرة
- ماهرون
- معجل
- الوصول
- عمل
- اكشن
- Ad
- العنوان
- الوكيل
- الكل
- سمح
- السماح
- يسمح
- أيضا
- دائما
- أمازون
- أمازون كينسيس
- أمازون ويب سيرفيسز
- أمازون ويب سيرفيسز (أوس)
- كمية
- المبالغ
- an
- تحليلية
- تحليلات
- و
- أي وقت
- ذو صلة
- التطبيقات
- التقديم
- نهج
- بشكل مناسب
- هندسة معمارية
- هي
- AS
- At
- سمات
- التدقيق
- أتمتة
- تلقائيا
- توفر
- متاح
- AWS
- غراء AWS
- النسخ الاحتياطي
- البنوك والمصارف
- النظم المصرفية
- على أساس
- BE
- لان
- كان
- قبل
- يجري
- أقل من
- تستفيد
- جلب
- نساعدك في بناء
- بنيت
- مدمج
- لكن
- by
- CAN
- قدرات
- الطاقة الإنتاجية
- أسر
- فيزا وماستركارد
- حقيبة
- الحالات
- الأقسام
- الفئات
- CDC
- الخلية
- تغيير
- التغييرات
- قنوات
- أطفال
- اختار
- وضوح
- سحابة
- كتلة
- الكود
- عمود
- الأعمدة
- تأتي
- يأتي
- آت
- متوافق
- متوافقة
- مكونات
- تتألف
- إحصاء
- اهتمامات
- متصل
- نظر
- نظرت
- مستهلك
- استهلاك
- تحتوي على
- سياق الكلام
- استمر
- مراقبة
- تصحيح
- التكاليف
- استطاع
- دولة
- خلق
- أوراق اعتماد
- ائتمان
- بطاقة إئتمان
- من تنسيق
- حالياًّ
- العملاء
- البيانات
- تحليلات البيانات
- تكامل البيانات
- بحيرة البيانات
- منصة البيانات
- خصوصية البيانات
- استراتيجية البيانات
- قاعدة البيانات
- قواعد البيانات
- قواعد البيانات
- التاريخ
- يوم
- الترتيب
- تعريف
- تم التوصيل
- شرح
- يوضح
- نشر
- تصميم
- افضل الرحلات السياحية
- لأفضل الأماكن السياحية
- تفاصيل
- بكشف أو
- الكشف عن
- كشف
- حدد
- التطوير التجاري
- فرق التطوير
- مختلف
- مباشرة
- اكتشف
- اكتشف
- ناقش
- do
- نطاق
- المجالات
- لا
- كل
- جهود
- البريد الإلكتروني
- الهندسة
- ضمان
- مشروع
- عملاء المؤسسة
- كامل
- الكيانات
- البيئة
- الأثير (ETH)
- حتى
- أحداث
- كل
- مثال
- أمثلة
- متوقع
- الخبره في مجال الغطس
- التعبيرات
- خارجي
- FAST
- مجال
- قم بتقديم
- ملفات
- مالي
- الخدمات المالية
- الاسم الأول
- تدفق
- يطفو
- التركيز
- يتبع
- متابعيك
- متابعات
- في حالة
- الإطار
- تبدأ من
- بالإضافة إلى
- تماما
- مستقبل
- توليد
- دولار فقط واحصل على خصم XNUMX% على جميع
- خير
- الحكم
- منح
- مقابض
- معالجة
- يملك
- he
- صحة الإنسان
- معلومات صحية
- مساعدة
- مساعدة
- يساعد
- رفيع المستوى
- له
- تاريخي
- كيفية
- كيفية
- HTML
- HTTP
- HTTPS
- مئات
- تحديد
- if
- يوضح
- تخيل
- تنفيذ
- أهمية
- أهمية
- in
- تتضمن
- بما فيه
- مؤشر
- فرد
- معلومات
- البنية التحتية
- في الداخل
- التكامل
- داخلي
- إلى
- IT
- جافا
- وظيفة
- المشــاريــع
- JPG
- جسون
- احتفظ
- Kinesis Data Firehose
- تيارات بيانات Kinesis
- معروف
- بحيرة
- البلد
- الأراضي
- كبير
- اسم العائلة
- الى وقت لاحق
- القوانين
- القوانين واللوائح
- طبقة
- طبقات
- القيادة
- اسمحوا
- المكتبة
- دورة حياة
- مثل
- خط
- تحميل
- جار التحميل
- المواقع
- بحث
- منخفضة التكلفة
- الرئيسية
- المحافظة
- جعل
- تمكن
- كثير
- رسم الخرائط
- قناع
- مايو..
- طريقة
- طرق
- الهجرة
- هجرة
- تقدم
- تحديث
- مراقبة
- الأكثر من ذلك
- جبل
- خطوة
- يتحرك
- كثيرا
- متعدد
- يجب
- الاسم
- أسماء
- ضروري
- حاجة
- بحاجة
- الحاجة
- إحتياجات
- هولندا
- جديد
- لا
- العقد
- يلاحظ..
- الآن
- عدد
- of
- عروض
- on
- ONE
- فقط
- عملية
- تشغيل
- عمليات
- تحسين
- مزيد من الخيارات
- or
- منظمة
- المنظمات
- أخرى
- لنا
- الناتج
- في الخارج
- على مدى
- جزء
- شغف
- الترقيع
- أنماط
- وسائل الدفع
- إلى
- نفذ
- أداء
- أذونات
- شخصيا
- للهواتف
- PII
- خط أنابيب
- خطة
- المنصة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- لعب
- البوينت
- جزء
- منشور
- السابقة
- قدم
- سابق
- خصوصية
- قوانين الخصوصية
- معالجة
- العمليات
- معالجة
- منتج
- محمي
- البروتوكولات
- مزود
- ويوفر
- مشتريات
- الاستفسارات
- بسرعة
- بدلا
- الخام
- مسودة بيانات
- في الوقت الحقيقي
- الأسباب
- يستلم
- وصفات
- موصى به
- سجل
- تسجيل
- عقار مخفض
- الرجوع
- منتظم
- قوانين
- الموثوقية
- لا تزال
- إزالة
- التقارير
- التقارير
- تطلب
- المتطلبات
- المتطلبات الأساسية
- المسؤوليات
- مسؤول
- بتقييد
- النتائج
- الأدوار
- صف
- يجري
- يدير
- ادارة العلاقات مع
- التضحية
- خزنة
- بسلام
- نفسه
- حجم
- تفحص
- جدول
- العلماء
- شاشة
- الإستراحة
- بحث
- القسم
- آمن
- أمن
- انظر تعريف
- حدد
- مختار
- كبير
- حساس
- أرسلت
- الخدمة
- خدماتنا
- اطلاق النار
- ينبغي
- أظهرت
- يظهر
- الاشارات
- تبسيط
- صغير
- So
- العدالة
- تطبيقات الكمبيوتر
- البرمجيات كخدمة
- حل
- الحلول
- مصدر
- مصادر
- محدد
- على وجه التحديد
- محدد
- أنفق
- الإنفاق
- الإنشقاقات
- مراحل
- المحافظة
- خطوة
- تخزين
- متجر
- صريح
- الإستراتيجيات
- مجرى
- متدفق
- تيارات
- خيط
- بناء
- منظم
- ستوديو
- لاحق
- بنجاح
- هذه
- مناسب
- مدعومة
- دعم
- نظام
- أنظمة
- جدول
- يأخذ
- الهدف
- فريق
- فريق
- تقنيات
- كرة المضرب
- عشرات
- من
- أن
- •
- المستقبل
- هولندا
- المصدر
- من مشاركة
- then
- هناك.
- تشبه
- هؤلاء
- ثلاثة
- عتبة
- عبر
- الوقت
- إلى
- استغرق
- أدوات
- مسار
- المعاملات
- تحويل
- التحويلات
- تحول
- تحول
- جديد الموضة
- أثار
- اثنان
- نوع
- أنواع
- في النهاية
- التي تقوم عليها
- فهم
- موحد
- متحد
- الولايات المتحدة
- us
- تستخدم
- حالة الاستخدام
- مستعمل
- المستخدمين
- استخدام
- قيمنا
- تشكيلة
- مختلف
- بواسطة
- بصري
- سير
- وكان
- طرق
- we
- الويب
- خدمات ويب
- ابحث عن
- متى
- التي
- في حين
- من الذى
- زوجة
- سوف
- مع
- في غضون
- بدون
- للعمل
- سير العمل
- عامل
- اكتب
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت