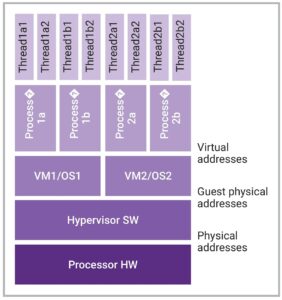
يحيط الكثير من الإثارة، وقدر لا بأس به من الضجيج، بما يمكن أن يفعله الذكاء الاصطناعي (AI) لصناعة EDA. ولكن يجب التغلب على العديد من التحديات قبل أن يتمكن الذكاء الاصطناعي من البدء في تصميم الرقائق والتحقق منها وتنفيذها لصالحنا. هل ينبغي للذكاء الاصطناعي أن يحل محل الخوارزميات المستخدمة اليوم، أم أن له دوراً مختلفاً ليلعبه؟
At the end of the day, AI is a technique that has strengths and weaknesses, and it has to be compared against those already in use. Existing algorithms and tools have decades of data and experience that have been encapsulated in them, and little of that knowledge is available in a form that could train new AI models. That puts these data-hungry techniques at a serious disadvantage — one that will take time to overcome. But AI does not need that type of data for all tasks. Some tasks produce copious amounts of relevant data, and those are the ones in which early results are showing a lot of promise.
وكان السؤال دائمًا هو ما مدى فائدة البيانات المتاحة؟ يقول دان يو، مدير المنتجات في ML Solutions في التحقق من تصميم IC في شركة "هناك ملايين الطرق لتطبيق التعلم الآلي". سيمنز EDA. “Machine learning is a generic technology, and it really depends on how people perceive the problem, how people want to use data to solve a problem. Once we have more data, and once we pay attention to the quality of data, then later we will get smarter and smarter AI models. It takes time.”
إن دور جمعية الإمارات للغوص في صناعة الرقائق واضح إلى حد ما، وقد قامت جمعية الإمارات للغوص بذلك احتضنت التعلم الآلي, which is a subset of EDA. But how the broader AI fits into EDA is far less obvious. “We turn to EDA when it can help you get your job done, or get the task done faster or better,” says Dean Drako, president and CEO of IC Manage. “The two things that we want from the EDA industry are to design faster and make it better. We’re all human, and we make mistakes. People have issues, they get sick, and they only want to work 8 or 10 hours a day. If you can have AI do something either better, or make the person more productive, then that’s a big win. It’s about productivity. If AI makes me productive, that’s where I win.”
يتعين على صناعة EDA العثور على المهام المناسبة التي توفر تلك الفوائد، والتي يمكن تحقيقها باستخدام البيانات المتاحة اليوم. يقول توماس أندرسن، نائب رئيس الذكاء الاصطناعي والتعلم الآلي في شركة "إن الذكاء الاصطناعي لديه فرصة جيدة للنجاح عندما يحاول تكرار مهمة يجيدها الإنسان". سينوبسيس. "إن تحديد المكان والطريق ليس بالمهمة التي يجيدها الإنسان. أي خوارزمية بسيطة من شأنها أن تتفوق على الإنسان لأن الإنسان ليس جيدًا في وضع الأشياء بهذه الكمية، بنفس الطريقة التي تتفوق بها الآلة الحاسبة البسيطة على معظم البشر. يمكن للإنسان أن يتفوق عليه في مهام أكثر إبداعًا ومهام أكثر تعقيدًا، مثل الأنواع المعرفية من الأشياء.
الذكاء الاصطناعي هو مجرد خوارزمية أخرى في الترسانة، والتعلم الآلي هو مجموعة فرعية من ذلك. يقول ميشال سيوينسكي، كبير مسؤولي التسويق بشركة "يُنظر الآن إلى الانحدار الخطي على أنه تعلم آلي، لكن الناس يستخدمون الانحدار لفترة طويلة". أرتيريس إب. “It’s a statistical concept that goes back a long time. Fundamentally, these are different types of algorithms, and it is a matter of finding which algorithm becomes more efficient for a given task. Before we had convolution neural networks, it was really hard to effectively address aspects of vision and aspects of large language models.”
To make any of this work requires the right data. “AI and machine learning are basically learning from historical data, from the data we have accumulated,” says Siemens’ Yu. “It condenses knowledge from the data. What is important is the data you feed into your AI model to train it, to extract the knowledge effectively. You use that knowledge to predict what would happen if I’m given a new case. AI is basically saving us the effort to replicate unnecessary work.”
ولكن نقص البيانات يمكن أن يخلق مشاكل. يقول مارك سوينن، مدير تسويق المنتجات في شركة: "يجب توخي الحذر فيما يتعلق بالذكاء الاصطناعي لأنه يعاني من مشكلة تتعلق بالقيم المتطرفة ومواطن الخلل". ANSYS. "لا يمكنك الاعتماد عليه ليعطيك إجابة جيدة دائمًا. قد تكون مهام التصميم أكثر قبولًا لأنك تحتاج إلى تنفيذ سريع وحسابات متكررة أثناء التنسيب أو التوجيه. يمكنك ترك القيم المتطرفة حتى مراحل التحقق اللاحقة، حيث يكون من الأسهل إصلاحها باستخدام أمر ECO بدلاً من محاولة النظر في جميع الحالات الأساسية في كل مرة يتم فيها اتخاذ قرار - خاصة عندما نادرًا ما تكون قابلة للتطبيق. عند تسجيل الخروج، بيت القصيد هو القبض على القيم المتطرفة.
Optimization functions rely on a cost function. “Deep learning, or any other machine learning techniques, are basically minimizing a given cost function,” says Arteris’ Siwinski. “That’s how the math behind it works. The cost function is constrained by how you defined what success is, and what the parameters look like.”
مشكلة البيانات
The number one problem is not computing power or the model. It’s the data. “If you only train your model on the current design, then AI’s knowledge is very limited,” says Yu. “Your success rate depends on how much data you have accumulated. If you have a series of design, incremental or derivative designs, that will help. Maybe you are a design house, and you design for many customers. If you have trained a model for design A and you know design B will only have slight modification, then you can re-use the model. Now your success rate would be much higher. Some verification engineers are more experienced and can transfer what they learned from previous projects to a new project. The same is true here. We need the data to train the right model.”
باستخدام الذكاء الاصطناعي، يتم تدريب الخوارزمية عادةً باستخدام مجموعة واسعة من البيانات لإنشاء نموذج، والذي يمكن بعد ذلك تحسينه بشكل كبير من أجل الأداء والقوة في الجانب الاستدلالي. وقال بول كارازوبا، نائب رئيس التسويق في شركة "إننا نأخذ نماذج مدربة بالكامل، وبعضها مملوك للعميل، ومصممة لحالات الاستخدام المحددة التي يريدها". إكسبيديرا. “So rather than just using a general-purpose device, the customers have specific things they want to do, and they’re looking to us to process them as optimally as it can be done. Our architecture was designed with the intention of being scalable, but also to be optimized.”
التحدي الأكبر الذي تواجهه جمعية الإمارات للغوص هو كيفية الحصول على البيانات التي تغطي الصناعة بأكملها من أجل أتمتة بعض هذه الخطوات. يقول دراكو، من IC Manage: "ستكون صناعة تصميم أشباه الموصلات واحدة من الصناعات التي تجد صعوبة في ذلك". "التصاميم محمية بشدة ومرغوبة. حتى قواعد التصميم في TSMC هي أسرار تخضع لحراسة مشددة، ويحاولون تشفيرها. لا أحد يريد أن تذهب أي من بيانات التصميم الخاصة به إلى أي مكان خارج شركته. سنواجه تحديًا صعبًا كصناعة. وأعتقد أننا في نهاية المطاف سوف نتغلب عليه. لقد فعلنا ذلك من أجل التوليف والمكان والطريق. لقد شهدت الأدوات العديد من التصميمات لأنه في كل مرة يكون هناك خطأ، نقدم البيانات إلى شركة EDA حتى يتمكنوا من إصلاح الخطأ.
بعضها أكثر إيجابية، خاصة عندما يتعلق الأمر بالتعلم الآلي. يقول سيوينسكي: "إن صناعة أشباه الموصلات غنية جدًا بالبيانات". "لديك الكثير من التصميمات، والعديد من مثيلات SoCs التي يتم تصميمها كل عام، وأجيال جديدة، ومشتقات، وأشياء مماثلة ذات بنيات مختلفة، وملايين وملايين من ناقلات الاختبار التي تعمل عبر مئات الحالات الزاوية ليتم فحصها. وهذا يعني أنه مكان رائع للتعلم الآلي، لأن التعلم الآلي لا يتعلق حقًا بالخوارزميات. هذا هو الجزء السهل. يتعلق الأمر بالقدرة على صياغة بيان المشكلة الذي تحاول حله باستخدام البيانات الصحيحة لدعمه. إذا تمكنت من تأطير ذلك بشكل صحيح، فيمكنك بالتأكيد استخدام التعلم الآلي.
That also can be done using less data and data sharing, which is more of a problem with AI than its machine learning subset. “I cannot imagine that because then there would be no competitive advantage for anybody anymore,” says Arvind Narayanan, senior director for product line management within Synopsys. “Across all industries, there are sometimes a number of players that create a consortium to share technology. Will the whole industry come together to essentially combine all the information they have? I just don’t see it. I don’t see that coming because everybody is extremely protective of their IP, and I understand why they are.”
مشاركة البيانات تجعل الجميع متوترين. يقول دراكو: "هناك الكثير من التعاون المستمر". "لم يتم الحديث عن هذا الأمر كثيرًا، لأنه يجعل جميع شركات الرقائق متوترة للغاية. وفي حالة تدريب النماذج، يصبح الأمر أكثر صعوبة لأن البائع يطلب الاحتفاظ بالبيانات لفترة زمنية أطول. سيكون هناك الكثير من المشاكل معها."
هناك أيضًا مشكلات تتعلق بصحة البيانات واتساقها التي يجب مراعاتها. يقول أندرسن من سينوبسيس: "إذا قمت بتطبيق نفس العملية المستخدمة لإنشاء ChatGPT على عالم تصميم الرقائق، فلا يمكنني استخدام أي RTL كتبه شخص ما من قبل". "يجب أن يكون هناك عنصر الجودة فيه. أريد أن أعرف ليس فقط ما إذا كان هذا الاتجاه من اليمين إلى اليسار (RTL) جيدًا، ولكن أيضًا ما إذا كان RTL جيدًا لأي غرض. قد تكون هناك متطلبات مختلفة فيما يتعلق بـ QR أو الوظيفة.
العزوف عن المخاطرة
كانت صناعة أشباه الموصلات دائما تتجنب المخاطرة. يقول دراكو: "سوف يرتكب الذكاء الاصطناعي الكثير من الأخطاء لأن بيانات التدريب أو النموذج والحل جديدان وغير مثبتين". "ومع ذلك، فإن الذكاء الاصطناعي سوف يعطي نفس الإجابة، سواء كانت صحيحة أو خاطئة، باستمرار. البشر لا يفعلون ذلك. بمجرد أن أحصل على النموذج الخاص بي وأثبت أنه دقيق بدرجة كافية لمهمتي، يمكنني التأكد من أنه سيكون دقيقًا بدرجة كافية من الآن فصاعدًا. المشكلة مع الإنسان هي أنه إذا قمت بتدريب شخص ما وكان دقيقًا بدرجة كافية في الشهر الأول من السنة الأولى، فسوف أظل أرتكب أخطاء في السنة الثانية والثالثة والرابعة. ربما الحديث عن الأخطاء ليس هو الشيء الصحيح. ربما يكون الاتساق هو الطريقة الصحيحة للتفكير في الأمر.
إحدى الطرق لتجنب المشكلة في البداية هي التركيز على التحسين. يقول أندرسن: "من حيث التصميم، لا يمكن لنظام التحسين أن يكون أسوأ من التصميم المرجعي الخاص بك". "قد ترسله في الاتجاه الخاطئ بمدخلات خاطئة، ثم يبحث في المساحة الخطأ ولن يجد لك نتيجة أفضل أبدًا. سيتم تجاهل جميع النتائج الأسوأ تلقائيًا.
الأخطاء تحدث. يقول سيوينسكي: "النتائج التي تحصل عليها مرتبطة بحجم الجهد الذي تبذله في بنائها". "إنه جهد مكثف للغاية للقيام بذلك بشكل صحيح. إذا كنت تطرح أسئلة خاطئة، أو إذا قدمت بيانات خاطئة، فلن تكون النتائج جيدة جدًا. عليك أن تفهم ذلك فقط لطرح الأسئلة الصحيحة. كيف تنظر إلى مجموعات البيانات؟ كيف يمكنك تقسيم كيف تفعل ذلك؟ إن القيام بذلك بشكل صحيح هو فن وعلم.
You have to understand when errors cannot be tolerated. “There is a limit to how much we can rely on AI,” says Ansys’ Swinnen. “It does play a significant role in things like optimization, but also in things like thermal analysis. For example, when working with variable size meshing, we need an algorithm that quickly determines where the likely hot spots are, and then we can build meshes that are much tighter where we know we need them and looser where not required. That allows us to speed up the whole process significantly by using AI intelligence to identify which areas need to be concentrated upon, but at the end — the calculations have to be exact.”
EDA التوليدية
في حين أن موضوع الذكاء الاصطناعي يحظى بشعبية كبيرة، إلا أن الذكاء الاصطناعي التوليدي هو التكنولوجيا الساخنة اليوم. يتساءل الناس متى سيكون الذكاء الاصطناعي قادرًا على إنشاء Verilog أو استبدال إنشاء نمط اختبار عشوائي مقيد. يقول دراكو: "يستخدم الناس الذكاء الاصطناعي لكتابة البرامج". "إنها تعمل على تحسين إنتاجيتهم لأنها تزيل بعض الكدح منها. أحتاج إلى كتابة برنامج للقيام بـ X، وهذا ليس ما أردته تمامًا، لكن إذا قمت بتغيير هذا، أصلحته، انقله هنا، ثم انفجر، إنه جيد جدًا. لذا فهو يزيد الإنتاجية، وسنرى أنه يستخدم بفعالية كبيرة بهذه الطريقة أو بهذه الطريقة فيما سأسميه التصميم أو الصناعة الإبداعية.
لكن صناعة أشباه الموصلات لا تعتمد على الإنتاجية بقدر ما تعتمد على البرمجيات. يقول: "على الرغم من كونها مثيرة ومثيرة، وبقدر ما تكون بعض هذه الأشياء ملفتة للنظر في الوقت الحالي - وكانت الضجة على مدى الشهرين الماضيين عالية جدًا - فالحقيقة هي أن الكثير من هذه العارضات أمامها طريق طويل لتقطعه". سيوينسكي. "هل يمكننا الحصول على بعض التلاعب بالصور وإنشاءها؟ قطعاً. الموسيقى والأشياء الأخرى المتعلقة بنماذج اللغة، نعم، أصبحت متطورة جدًا. هل هذا هو نفس القدرة على إنشاء تعليمات برمجية متقدمة ستكون آمنة، وستكون آمنة، ولن تواجه بعض التحديات مثل إعادة استخدام IP؟ هناك أماكن يمكن للأشخاص فيها الحصول على مكتبات من الأشياء، وهو أمر رائع، ولكنها ليست بالضرورة ما أود نشره في البرامج عالية الأداء، حيث تحتاج إلى درجة عالية من الموثوقية والأمان.
مرة أخرى، يعود الأمر إلى التدريب. "من أين تأتي هذه القوة؟" يسأل يو. "تأتي القوة من الكثير من البيانات التي يتم إدخالها في التدريب. لم تكشف OpenAI عن كمية البيانات التي استخدمتها لتدريب أحدث GPT-4، لكنني أعلم أنهم استخدموا عدة مليارات من الرموز المميزة لـ GPT-3، وهذا يعني أنهم جمعوا جميع البيانات من ويكيبيديا، من مصادر يمكن الوصول إليها بشكل مفتوح صفحات الويب، ومن العديد من الكتب والمنشورات. ومن هنا يأتي الذكاء. لقد تدرب على GitHub أيضًا. لذا فقد تم تغذية الكثير من GitHub في نموذج اللغة. عندما تنظر إلى مشكلة EDA، هل لدينا إمكانية الوصول إلى الكثير من البيانات لتدريب نموذج قوي بشكل صحيح؟
Yu recently published a paper that provides the figures shown below. As a comparison in August 2022, there were 14,197,122 images in 21,841 categories used to train ImageNet.
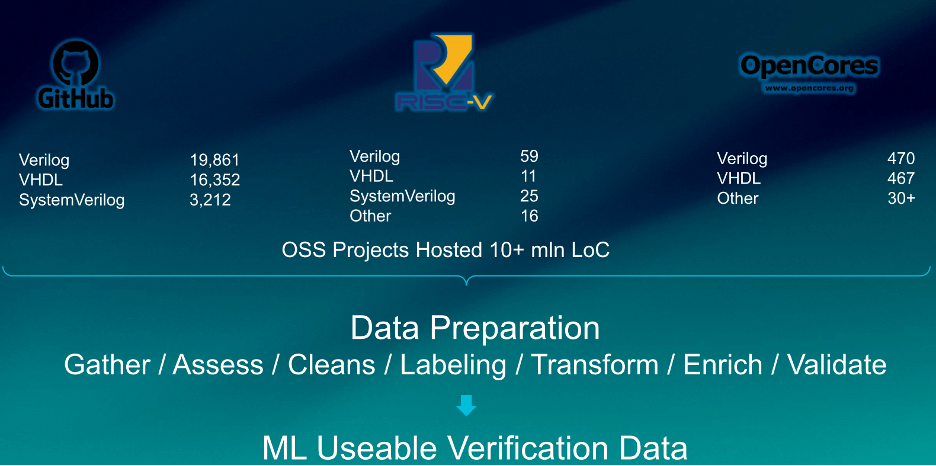
Fig. 1: Data from “A Survey of Machine Learning Applications in Functional Verification” by Dan Yu, Harry Foster, and Tom Fitzpatrick of Siemens EDA. Source: DVCon 2023
هناك بعض المحاولات المبكرة. "يمكنك إخبار الذكاء الاصطناعي بإنشاء RTL ولكن هل سيكون RTL هو الأكثر تحسينًا والذي يلبي متطلبات PPA؟" يسأل نارايانان. "لم نصل هناك بعد. سوف يقوم بإظهار الوظيفة المنطقية التي تبحث عنها، ولكن الخطوة الثانية هي كيفية تحسينها. كيف تأخذه إلى المستوى التالي؟ وهذا العمل جار."
كصناعة، لدينا بعض الخبرة في هذا بالفعل. يشير أندرسن إلى أن "الخطر في أشياء مثل نماذج اللغة هو أنك قد تقضي وقتًا أطول في تصحيح أخطاء RTL المكتوبة بشكل سيء أكثر مما كنت ستستغرقه في كتابتها".
وهذا مشابه للأيام الأولى لإعادة استخدام IP حيث غمرت السوق كميات هائلة من RTL الضعيفة. يقول يو: "حتى لو أعطانا الذكاء الاصطناعي إمكانية الرجوع إلى اليمين، فلا يزال يتعين علينا إجراء فحص الجودة". "وربما يمكن أيضًا تشغيل ذلك تلقائيًا في المستقبل. يتعين علينا أيضًا دمج هذا التصميم مع القطع الأخرى والتأكد من أن التصميم الجديد يعمل ككل. هناك العديد من الخطوات حتى يتمكن أحد النماذج من إنتاج تصميم كامل.
وفي الختام
قال آرثر سي. كلارك ذات مرة: "لا يمكن تمييز أي تكنولوجيا متقدمة بما فيه الكفاية عن السحر".
يقول سيوينسكي: "قد يكون الذكاء الاصطناعي عجيبًا، لكنه ليس سحرًا". "إنها مجرد علوم ورياضيات. التعلم الآلي هو مجرد أداة أخرى تعتمد بشكل كبير على البيانات، وعليك أن تطرح الأسئلة الصحيحة. ولكن هذا شيء يجب على الجميع أن يتبناه لأنه سيكون منتشرًا بنسبة 100٪.
While EDA is adopting machine learning and other pieces of true AI, it is not ready to throw away many of the existing algorithms. “Machine learning is not a drop-in replacement for our existing algorithms or tools,” says Yu. “They are helping us to accelerate thing that were not very efficiently. They are helping to automate some processes where people were in the loop. Those are tasks where machine learning can help. Sometimes machine learning also can improve our previous primitive algorithms, make them more accurate.”
وفي الوقت نفسه، قد يتعين على EDA التوليدي الانتظار لفترة أطول قليلاً. يقول دراكو: "من غير الواضح كيف سيسير هذا الأمر في صناعتنا التي تتجنب المخاطرة بشدة". "سيتم استخدام الذكاء الاصطناعي في عناصر التصميم حيث يتم فحصه من قبل البشر ويعطي البشر نموذجًا للبدء به، ومن ثم يمكنهم المضي قدمًا بشكل أكثر فعالية وبسرعة أكبر. صناعتنا تريد الضمان. في نهاية المطاف، سنحصل على نماذج تم تدريبها بشكل جيد بما فيه الكفاية حيث سنحصل على هذا الضمان.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- أفلاطونايستريم. ذكاء بيانات Web3. تضخيم المعرفة. الوصول هنا.
- سك المستقبل مع أدرين أشلي. الوصول هنا.
- المصدر https://semiengineering.com/slow-ai-adoption-within-eda/
- :لديها
- :يكون
- :ليس
- :أين
- $ UP
- 1
- 10
- 14
- 2022
- 2023
- 8
- a
- ماهرون
- من نحن
- حوله
- إطلاقا
- تسريع
- مقبول
- الوصول
- يمكن الوصول
- متراكم
- دقيق
- العنوان
- اعتماد
- تبني
- متقدم
- تكنولوجيا متقدمة
- مميزات
- ضد
- AI
- اعتماد منظمة العفو الدولية
- خوارزمية
- خوارزميات
- الكل
- يسمح
- سابقا
- أيضا
- دائما
- كمية
- المبالغ
- an
- تحليل
- و
- أندرسون
- آخر
- إجابة
- أي وقت
- بعد الآن
- في أى مكان
- ذو صلة
- التطبيقات
- التقديم
- هندسة معمارية
- هي
- المناطق
- ارسنال
- فنـون
- مصطنع
- الذكاء الاصطناعي
- الذكاء الاصطناعي (منظمة العفو الدولية)
- AS
- الجوانب
- مؤكد
- At
- محاولات
- اهتمام
- أغسطس
- أتمتة
- الآلي
- تلقائيا
- متاح
- تجنب
- بعيدا
- الى الخلف
- في الأساس
- BE
- لان
- يصبح
- كان
- قبل
- وراء
- يجري
- اعتقد
- أقل من
- الفوائد
- أفضل
- كبير
- أكبر
- مليار
- مليار توكينز
- كُتُب
- ازدهار
- واسع
- أوسع
- علة
- نساعدك في بناء
- ابني
- لكن
- by
- دعوة
- CAN
- يستطيع الحصول على
- لا تستطيع
- حقيبة
- الحالات
- يو كاتش
- الفئات
- الرئيس التنفيذي
- تحدى
- التحديات
- فرصة
- تغيير
- شات جي بي تي
- التحقق
- التحقق
- رقاقة
- شيبس
- واضح
- عن كثب
- CMO
- الكود
- المعرفية
- دمج
- تأتي
- يأتي
- آت
- الشركات
- حول الشركة
- مقارنة
- مقارنة
- تنافسي
- إكمال
- تماما
- مجمع
- عنصر
- الحوسبة
- القدرة الحاسوبية
- تركز
- مركز
- مفهوم
- نظر
- نظرت
- جمعية
- تعاون
- زاوية
- التكلفة
- استطاع
- مرغوب
- خلق
- خلق
- الإبداع
- حالياًّ
- زبون
- العملاء
- DANGER
- البيانات
- مجموعات البيانات
- تبادل البيانات
- يوم
- أيام
- عقود
- القرار
- تعريف
- يعتمد
- نشر
- المشتقات
- تصميم
- تصميم
- تصميم
- تصاميم
- يحدد
- جهاز
- فعل
- مختلف
- اتجاه
- مدير المدارس
- مساوئ
- كشف
- do
- هل
- فعل
- لا
- مدفوع
- أثناء
- في وقت مبكر
- أسهل
- سهل
- على نحو فعال
- فعال
- بكفاءة
- جهد
- إما
- احتضان
- مغلفة
- النهاية
- المهندسين
- كاف
- كامل
- أخطاء
- خاصة
- أساسيا
- حتى
- في النهاية
- كل
- كل شخص
- مثال
- إثارة
- المثيره
- القائمة
- الخبره في مجال الغطس
- تمكنت
- استخراج
- جدا
- عين
- عادل
- بإنصاف
- بعيدا
- FAST
- أسرع
- بنك الاحتياطي الفيدرالي
- تين
- الأرقام
- العثور على
- ويرى
- الأول
- فيتزباتريك
- حل
- في حالة
- النموذج المرفق
- إلى الأمام
- فوستر
- رابع
- FRAME
- تبدأ من
- وظيفة
- وظيفي
- وظيفة
- وظائف
- في الأساس
- مستقبل
- هدف عام
- توليد
- جيل
- أجيال
- توليدي
- الذكاء الاصطناعي التوليدي
- دولار فقط واحصل على خصم XNUMX% على جميع
- الحصول على
- GitHub جيثب:
- منح
- معطى
- يعطي
- Go
- يذهب
- الذهاب
- خير
- عظيم
- كان
- يحدث
- الثابت
- يملك
- مساعدة
- مساعدة
- هنا
- مرتفع
- أداء عالي
- أعلى
- جدا
- تاريخي
- أفضل العروض
- ساعات العمل
- منـزل
- كيفية
- كيفية
- HTTPS
- ضخم
- الانسان
- البشر
- مئات
- الضجيج
- i
- سوف
- تحديد
- if
- صورة
- IMAGEnet
- صور
- تخيل
- تحقيق
- أهمية
- تحسن
- تحسين
- in
- الزيادات
- الصناعات
- العالمية
- معلومات
- في البداية
- دمج
- رؤيتنا
- نية
- إلى
- IP
- مسائل
- IT
- انها
- وظيفة
- م
- علم
- المعرفة
- نقص
- لغة
- كبير
- والأخير
- الى وقت لاحق
- تعلم
- تعلم
- يترك
- مستوى
- المكتبات
- مثل
- على الأرجح
- مما سيحدث
- محدود
- خط
- القليل
- طويل
- وقت طويل
- يعد
- بحث
- يبدو مثل
- أبحث
- الكثير
- آلة
- آلة التعلم
- تقنيات التعلم الآلي
- صنع
- سحر
- جعل
- يصنع
- إدارة
- إدارة
- مدير
- تلاعب
- أسلوب
- كثير
- تجارة
- التسويق
- الرياضيات
- أمر
- ماكس العرض
- مايو..
- يعني
- في غضون
- طريقة
- ربما
- ملايين
- التقليل
- الأخطاء
- ML
- نموذج
- عارضات ازياء
- شهر
- المقبلة.
- الأكثر من ذلك
- أكثر فعالية
- أكثر
- خطوة
- تقدم إلى الأمام
- كثيرا
- موسيقى
- بالضرورة
- حاجة
- إحتياجات
- الشبكات
- عصبي
- الشبكات العصبية
- جديد
- التالي
- لا
- ملاحظة
- الآن
- عدد
- واضح
- of
- on
- مرة
- ONE
- فقط
- OpenAI
- بصراحة
- التحسين
- الأمثل
- الأمثل
- or
- طلب
- أخرى
- لنا
- خارج
- في الخارج
- على مدى
- تغلب
- ورق
- المعلمات
- جزء
- خاصة
- نمط
- بول
- مجتمع
- أداء
- فترة
- شخص
- قطعة
- المكان
- وجهات
- وضع
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- بلايستشن
- لاعبين
- البوينت
- فقير
- الرائج
- إيجابي
- ممكن
- قوة
- قوي
- تنبأ
- رئيس
- جميل
- سابق
- بدائي
- المشكلة
- مشاكل
- عملية المعالجة
- العمليات
- إنتاج
- المنتج
- مدير المنتج
- مثمر
- إنتاجية
- البرنامج
- البرامج
- التقدّم
- تنفيذ المشاريع
- مشروع ناجح
- وعد
- بصورة صحيحة
- الملكية
- محمي
- الحماية والوقاية
- إثبات
- تزود
- ويوفر
- المنشورات
- نشرت
- غرض
- وضع
- يضع
- جودة
- كمية
- سؤال
- الأسئلة المتكررة
- بسرعة
- عشوائية
- معدل
- بدلا
- استعداد
- واقع
- في الحقيقة
- الأخيرة
- مؤخرا
- التصميم المرجعي
- تراجع
- ذات صلة
- ذات الصلة
- الموثوقية
- يحل محل
- مطلوب
- المتطلبات الأساسية
- يتطلب
- نتيجة
- النتائج
- إعادة استخدام
- النوادي الثرية
- النوع
- التوجيه
- القواعد
- تشغيل
- خزنة
- قال
- نفسه
- إنقاذ
- يقول
- تحجيم
- علوم
- الثاني
- تأمين
- أمن
- انظر تعريف
- رأيت
- أشباه الموصلات
- إرسال
- كبير
- مسلسلات
- جدي
- طقم
- باكجات
- عدة
- بقسوة
- مشاركة
- مشاركة
- ينبغي
- أظهرت
- جانب
- سيمنز
- هام
- بشكل ملحوظ
- مماثل
- الاشارات
- المقاس
- بطيء
- أكثر ذكاء
- So
- تطبيقات الكمبيوتر
- حل
- الحلول
- حل
- بعض
- شيء
- متطور
- مصدر
- الفضاء
- يمتد
- محدد
- سرعة
- أنفق
- مراحل
- بداية
- ملخص الحساب
- إحصائي
- خطوة
- خطوات
- لا يزال
- نقاط القوة
- موضوع
- تحقيق النجاح
- تعرض جيد للشمس
- الدعم
- الدراسة الاستقصائية
- نظام
- أخذ
- يأخذ
- مع الأخذ
- الحديث
- مهمة
- المهام
- تقنيات
- تكنولوجيا
- اقول
- قالب
- سياسة الحجب وتقييد الوصول
- تجربه بالعربي
- من
- أن
- •
- المستقبل
- المعلومات
- من مشاركة
- منهم
- then
- هناك.
- حراري
- تشبه
- هم
- شيء
- الأشياء
- اعتقد
- الثالث
- هؤلاء
- عبر
- أكثر تشددا
- الوقت
- إلى
- اليوم
- سويا
- الرموز
- أداة
- أدوات
- قطار
- متدرب
- قادة الإيمان
- تحويل
- صحيح
- TSMC
- منعطف أو دور
- اثنان
- نوع
- أنواع
- عادة
- مع
- فهم
- بناء على
- us
- تستخدم
- مستعمل
- استخدام
- بائع
- التحقق
- التحقق
- جدا
- Vice President
- رؤيتنا
- انتظر
- تريد
- مطلوب
- يريد
- وكان
- طريق..
- طرق
- we
- الويب
- حسن
- كان
- ابحث عن
- ما هي تفاصيل
- متى
- التي
- لماذا
- ويكيبيديا
- سوف
- كسب
- مع
- في غضون
- للعمل
- عامل
- أعمال
- العالم
- أسوأ
- سوف
- اكتب
- مكتوب
- خاطئ
- X
- عام
- حتى الآن
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت