تمت كتابة هذا المنشور بالاشتراك مع برامود ناياك، ولاكشمي كانث مانيم، وفيفيك أغاروال من مجموعة Low Latency Group في LSEG.
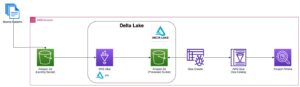
يستخدم تحليل تكاليف المعاملات (TCA) على نطاق واسع من قبل التجار ومديري المحافظ والوسطاء لتحليل ما قبل التجارة وما بعد التجارة، ويساعدهم على قياس وتحسين تكاليف المعاملات وفعالية استراتيجيات التداول الخاصة بهم. في هذا المنشور، نقوم بتحليل فروق أسعار عروض الأسعار والطلبات من سجل القراد LSEG – PCAP مجموعة البيانات باستخدام أمازون أثينا لأباتشي سبارك. نوضح لك كيفية الوصول إلى البيانات، وتحديد الوظائف المخصصة لتطبيقها على البيانات، والاستعلام عن مجموعة البيانات وتصفيتها، وتصور نتائج التحليل، كل ذلك دون الحاجة إلى القلق بشأن إعداد البنية التحتية أو تكوين Spark، حتى بالنسبة لمجموعات البيانات الكبيرة.
خلفيّة
تعمل هيئة الإبلاغ عن أسعار الخيارات (OPRA) كمعالج معلومات الأوراق المالية الهامة، حيث تقوم بجمع وتوحيد ونشر تقارير البيع الأخيرة وعروض الأسعار والمعلومات ذات الصلة لخيارات الولايات المتحدة. من خلال 18 بورصة خيارات أمريكية نشطة وأكثر من 1.5 مليون عقد مؤهل، تلعب OPRA دورًا محوريًا في توفير بيانات السوق الشاملة.
في 5 فبراير 2024، تم تعيين شركة Securities Industry Automation Corporation (SIAC) لترقية تغذية OPRA من 48 إلى 96 قناة بث متعدد. ويهدف هذا التحسين إلى تحسين توزيع الرموز واستخدام سعة الخط استجابة لتصاعد نشاط التداول والتقلبات في سوق الخيارات الأمريكية. أوصت SIAC بأن تستعد الشركات لذروة معدلات البيانات التي تصل إلى 37.3 جيجابت في الثانية.
على الرغم من أن الترقية لا تغير على الفور الحجم الإجمالي للبيانات المنشورة، إلا أنها تمكن OPRA من نشر البيانات بمعدل أسرع بكثير. يعد هذا التحول أمرًا بالغ الأهمية لتلبية متطلبات سوق الخيارات الديناميكية.
تبرز OPRA كواحدة من أكثر الخلاصات ضخامة، حيث تبلغ ذروتها 150.4 مليار رسالة في يوم واحد في الربع الثالث من عام 3 ومتطلبات سعة تبلغ 2023 مليار رسالة خلال يوم واحد. يعد التقاط كل رسالة أمرًا بالغ الأهمية لتحليلات تكلفة المعاملات ومراقبة سيولة السوق وتقييم استراتيجية التداول وأبحاث السوق.
حول البيانات
سجل القراد LSEG – PCAP هو مستودع قائم على السحابة، يتجاوز 30 بيتا بايت، ويحتوي على بيانات السوق العالمية فائقة الجودة. يتم التقاط هذه البيانات بدقة مباشرة داخل مراكز بيانات التبادل، وذلك باستخدام عمليات التقاط متكررة موضوعة بشكل استراتيجي في مراكز بيانات التبادل الرئيسية والاحتياطية الرئيسية في جميع أنحاء العالم. تضمن تقنية الالتقاط الخاصة بـ LSEG التقاط البيانات دون فقدان البيانات وتستخدم مصدرًا زمنيًا لنظام تحديد المواقع العالمي (GPS) للحصول على دقة الطابع الزمني بالنانو ثانية. بالإضافة إلى ذلك، يتم استخدام تقنيات تحكيم البيانات المتطورة لملء أي فجوات في البيانات بسلاسة. بعد التقاط البيانات، تخضع البيانات للمعالجة الدقيقة والتحكيم، ثم يتم تطبيعها إلى تنسيق Parquet باستخدام LSEG في الوقت الحقيقي الترا المباشر (RTUD) معالجات التغذية.
تولد عملية التطبيع، والتي تعد جزءًا لا يتجزأ من إعداد البيانات للتحليل، ما يصل إلى 6 تيرابايت من ملفات الباركيه المضغوطة يوميًا. ويعزى الحجم الهائل من البيانات إلى الطبيعة الشاملة لـ OPRA، التي تغطي بورصات متعددة، وتضم العديد من عقود الخيارات التي تتميز بسمات متنوعة. تساهم زيادة تقلبات السوق ونشاط صناعة السوق في بورصات الخيارات في زيادة حجم البيانات المنشورة على OPRA.
سمات سجل القراد - PCAP تمكن الشركات من إجراء تحليلات مختلفة، بما في ذلك ما يلي:
- تحليل ما قبل التجارة – تقييم التأثير التجاري المحتمل واستكشاف استراتيجيات التنفيذ المختلفة بناءً على البيانات التاريخية
- تقييم ما بعد التجارة – قياس تكاليف التنفيذ الفعلية مقابل المعايير لتقييم أداء استراتيجيات التنفيذ
- الأمثل - تحسين استراتيجيات التنفيذ بناءً على أنماط السوق التاريخية لتقليل تأثير السوق وتقليل تكاليف التداول الإجمالية
- إدارة المخاطر - تحديد أنماط الانزلاق، وتحديد القيم المتطرفة، وإدارة المخاطر المرتبطة بأنشطة التداول بشكل استباقي
- إسناد الأداء – فصل تأثير قرارات التداول عن قرارات الاستثمار عند تحليل أداء المحفظة
تتوفر مجموعة بيانات LSEG Tick History – PCAP في تبادل بيانات AWS ويمكن الوصول إليها على سوق AWS. مع تبادل بيانات AWS لـ Amazon S3، يمكنك الوصول إلى بيانات PCAP مباشرة من LSEG خدمة تخزين أمازون البسيطة (Amazon S3)، مما يلغي حاجة الشركات إلى تخزين نسختها الخاصة من البيانات. يعمل هذا النهج على تبسيط إدارة البيانات وتخزينها، مما يوفر للعملاء إمكانية الوصول الفوري إلى PCAP عالي الجودة أو البيانات المعيارية مع سهولة الاستخدام والتكامل والتكامل. وفورات كبيرة في تخزين البيانات.
أثينا لأباتشي سبارك
للمساعي التحليلية ، أثينا لأباتشي سبارك يقدم تجربة مبسطة للكمبيوتر المحمول يمكن الوصول إليها من خلال وحدة تحكم Athena أو Athena APIs، مما يسمح لك ببناء تطبيقات Apache Spark التفاعلية. من خلال وقت تشغيل Spark الأمثل، تساعد Athena في تحليل بيتابايت من البيانات عن طريق زيادة عدد محركات Spark ديناميكيًا في أقل من ثانية. علاوة على ذلك، يتم دمج مكتبات Python الشائعة مثل Pandas وNumPy بسلاسة، مما يسمح بإنشاء منطق تطبيق معقد. تمتد المرونة إلى استيراد المكتبات المخصصة لاستخدامها في دفاتر الملاحظات. يستوعب Athena for Spark معظم تنسيقات البيانات المفتوحة ويتم دمجه بسلاسة مع غراء AWS كتالوج البيانات.
بيانات
في هذا التحليل، استخدمنا مجموعة بيانات LSEG Tick History – PCAP OPRA اعتبارًا من 17 مايو 2023. وتتكون مجموعة البيانات هذه من المكونات التالية:
- أفضل عرض وعطاء (BBO) – يُبلغ عن أعلى عرض وأدنى طلب للأوراق المالية في بورصة معينة
- أفضل عرض وعرض وطني (NBBO) – تقارير أعلى عرض وأدنى طلب للأمن في جميع البورصات
- الصفقات – سجلات الصفقات المكتملة في جميع البورصات
تتضمن مجموعة البيانات أحجام البيانات التالية:
- الصفقات – 160 ميجابايت موزعة على حوالي 60 ملف باركيه مضغوط
- BBO – 2.4 تيرابايت موزعة على حوالي 300 ملف باركيه مضغوط
- البنك الوطني العماني – 2.8 تيرابايت موزعة على حوالي 200 ملف باركيه مضغوط
نظرة عامة على التحليل
يتضمن تحليل بيانات سجل OPRA Tick History لتحليل تكلفة المعاملات (TCA) فحص أسعار السوق والتداولات حول حدث تجاري محدد. نستخدم المقاييس التالية كجزء من هذه الدراسة:
- انتشار مقتبس (QS) – يتم حسابه على أنه الفرق بين طلب BBO وعرض BBO
- الانتشار الفعال (ES) – يتم حسابه على أنه الفرق بين سعر التداول ونقطة المنتصف لـ BBO (عرض BBO + (طلب BBO – عرض BBO)/2)
- الانتشار الفعال/المقتبس (EQF) – يتم حسابه كـ (ES / QS) * 100
نقوم بحساب هذه الفروق قبل التداول بالإضافة إلى ذلك على أربع فترات بعد التداول (بعد ثانية واحدة و1 ثوانٍ و10 ثانية بعد التداول مباشرة).
قم بتكوين أثينا لـ Apache Spark
لتكوين Athena لـ Apache Spark، أكمل الخطوات التالية:
- على وحدة تحكم أثينا ، تحت إبداء الأن، حدد قم بتحليل بياناتك باستخدام PySpark وSpark SQL.
- إذا كانت هذه هي المرة الأولى التي تستخدم فيها Athena Spark، فاختر قم بإنشاء مجموعة عمل.

- في حالة اسم مجموعة العمل¸ أدخل اسمًا لمجموعة العمل، مثل
tca-analysis. - في مجلة محرك التحليلات القسم، حدد أباتشي سبارك.
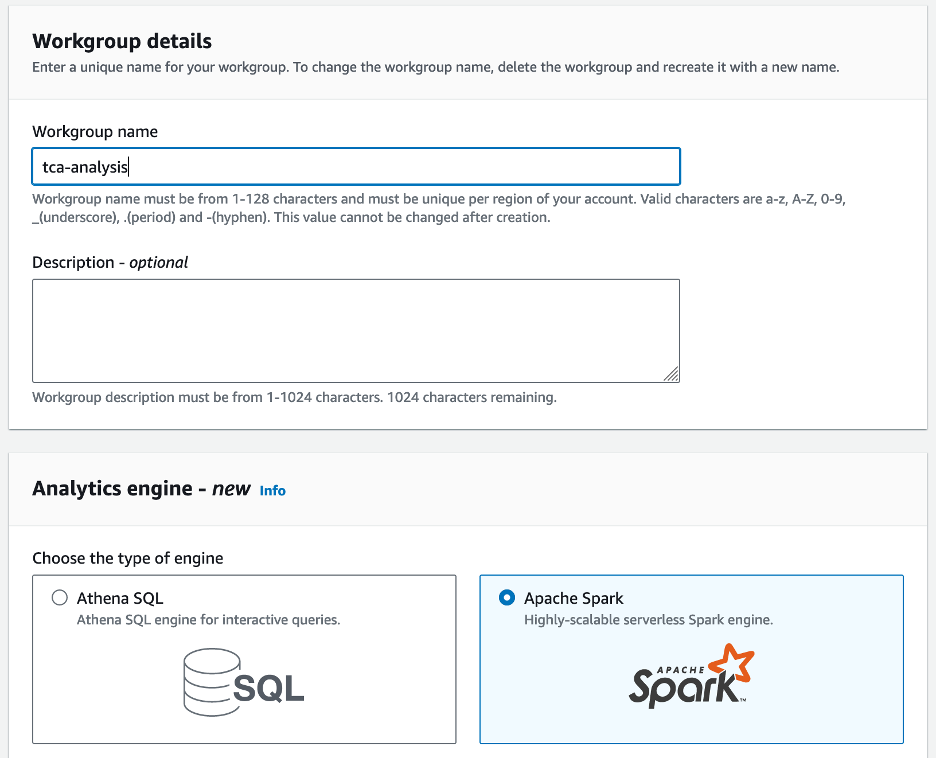
- في مجلة تكوينات إضافية القسم، يمكنك الاختيار التخلف عن استخدام أو تقديم العرف إدارة الهوية والوصول AWS دور (IAM) وموقع Amazon S3 لنتائج الحساب.
- اختار قم بإنشاء مجموعة عمل.
- بعد إنشاء مجموعة العمل، انتقل إلى دفاتر علامة التبويب واختيار إنشاء دفتر ملاحظات.
- أدخل اسمًا لدفتر ملاحظاتك، مثل
tca-analysis-with-tick-history. - اختار إنشاء لإنشاء دفتر الملاحظات الخاص بك.
إطلاق دفتر الملاحظات الخاص بك
إذا قمت بالفعل بإنشاء مجموعة عمل Spark، فحدد إطلاق محرر دفتر الملاحظات مع إبداء الأن.
![]()
بعد إنشاء دفتر الملاحظات الخاص بك، ستتم إعادة توجيهك إلى محرر دفتر الملاحظات التفاعلي.
![]()
يمكننا الآن إضافة وتشغيل الكود التالي إلى دفتر ملاحظاتنا.
قم بإنشاء تحليل
أكمل الخطوات التالية لإنشاء التحليل:
- استيراد المكتبات المشتركة:
- قم بإنشاء إطارات البيانات الخاصة بنا لـ BBO وNBBO والصفقات:
- يمكننا الآن تحديد التجارة لاستخدامها في تحليل تكلفة المعاملة:
نحصل على الناتج التالي:
نحن نستخدم المعلومات التجارية المميزة للمضي قدمًا للمنتج التجاري (tp)، وسعر التداول (tpr)، ووقت التداول (tt).
- هنا نقوم بإنشاء عدد من الوظائف المساعدة لتحليلنا
- في الوظيفة التالية، نقوم بإنشاء مجموعة البيانات التي تحتوي على جميع عروض الأسعار قبل وبعد التداول. تحدد Athena Spark تلقائيًا عدد وحدات DPU التي سيتم تشغيلها لمعالجة مجموعة البيانات الخاصة بنا.
- الآن دعنا نستدعي وظيفة تحليل TCA بالمعلومات من التجارة المحددة لدينا:
تصور نتائج التحليل
لنقم الآن بإنشاء إطارات البيانات التي نستخدمها لتصورنا. يحتوي كل إطار بيانات على علامات اقتباس لواحدة من الفواصل الزمنية الخمس لكل خلاصة بيانات (BBO، NBBO):
في الأقسام التالية، نقدم نموذجًا للتعليمات البرمجية لإنشاء تصورات مختلفة.
ارسم QS وNBBO قبل التداول
استخدم الكود التالي لرسم السبريد المقتبس وبنك NBBO قبل التداول:
![]()
ارسم QS لكل سوق وNBBO بعد التداول
استخدم الكود التالي لرسم الفارق السعري لكل سوق ولدى البنك الوطني العماني مباشرة بعد التداول:
![]()
ارسم QS لكل فترة زمنية ولكل سوق لـ BBO
استخدم الكود التالي لرسم الفارق المقتبس لكل فترة زمنية وكل سوق لـ BBO:
![]()
ارسم ES لكل فترة زمنية وسوق لـ BBO
استخدم الكود التالي لرسم السبريد الفعال لكل فترة زمنية وسوق لـ BBO:
ارسم EQF لكل فترة زمنية وسوق لـ BBO
استخدم الكود التالي لرسم السبريد الفعال/المقتبس لكل فترة زمنية وسوق لـ BBO:
أداء حساب أثينا سبارك
عند تشغيل كتلة تعليمات برمجية، تحدد Athena Spark تلقائيًا عدد وحدات DPU المطلوبة لإكمال الحساب. في كتلة التعليمات البرمجية الأخيرة، حيث نسميها tca_analysis وظيفة، نحن في الواقع نطلب من Spark معالجة البيانات، ثم نقوم بعد ذلك بتحويل إطارات بيانات Spark الناتجة إلى إطارات بيانات Pandas. يشكل هذا الجزء الأكثر كثافة للمعالجة في التحليل، وعندما تقوم Athena Spark بتشغيل هذه الكتلة، فإنها تعرض شريط التقدم والوقت المنقضي وعدد وحدات DPU التي تعالج البيانات حاليًا. على سبيل المثال، في الحساب التالي، تستخدم Athena Spark 18 وحدة DPU.
![]()
عندما تقوم بتكوين دفتر Athena Spark الخاص بك، يكون لديك خيار تعيين الحد الأقصى لعدد وحدات DPU التي يمكنه استخدامها. الافتراضي هو 20 وحدة معالجة بيانات، لكننا اختبرنا هذه العملية الحسابية باستخدام 10 و20 و40 وحدة معالجة بيانات لتوضيح كيفية قياس Athena Spark تلقائيًا لتشغيل تحليلنا. لاحظنا أن مقياس Athena Spark خطيًا، حيث يستغرق 15 دقيقة و21 ثانية عندما تم تكوين الكمبيوتر الدفتري باستخدام 10 وحدات معالجة بيانات كحد أقصى، و8 دقائق و23 ثانية عندما تم تكوين الكمبيوتر الدفتري باستخدام 20 وحدة معالجة بيانات، و4 دقائق و44 ثانية عندما تم تكوين الكمبيوتر المحمول تم تكوينه مع 40 وحدة معالجة البيانات (DPUs). نظرًا لأن Athena Spark تفرض رسومًا بناءً على استخدام DPU، وبدقة في الثانية، فإن تكلفة هذه الحسابات متشابهة، ولكن إذا قمت بتعيين حد أقصى أعلى لقيمة DPU، فيمكن لـ Athena Spark إرجاع نتيجة التحليل بشكل أسرع بكثير. لمزيد من التفاصيل حول أسعار Athena Spark برجاء النقر هنا.
وفي الختام
في هذا المنشور، أوضحنا كيف يمكنك استخدام بيانات OPRA عالية الدقة من Tick History-PCAP الخاص بـ LSEG لإجراء تحليلات تكلفة المعاملات باستخدام Athena Spark. إن توفر بيانات OPRA في الوقت المناسب، بالإضافة إلى ابتكارات إمكانية الوصول الخاصة بـ AWS Data Exchange لـ Amazon S3، يقلل بشكل استراتيجي من الوقت اللازم لإجراء التحليلات بالنسبة للشركات التي تتطلع إلى إنشاء رؤى قابلة للتنفيذ لقرارات التداول المهمة. تولد OPRA حوالي 7 تيرابايت من بيانات Parquet الطبيعية كل يوم، كما أن إدارة البنية التحتية لتوفير التحليلات بناءً على بيانات OPRA تمثل تحديًا.
إن قابلية التوسع التي تتمتع بها Athena في التعامل مع معالجة البيانات واسعة النطاق لـ Tick History – PCAP لبيانات OPRA تجعلها خيارًا مقنعًا للمؤسسات التي تبحث عن حلول تحليلية سريعة وقابلة للتطوير في AWS. يوضح هذا المنشور التفاعل السلس بين نظام AWS البيئي وبيانات Tick History-PCAP وكيف يمكن للمؤسسات المالية الاستفادة من هذا التآزر لدفع عملية صنع القرار المستندة إلى البيانات لاستراتيجيات التداول والاستثمار المهمة.
حول المؤلف
![]() برامود ناياك هو مدير إدارة المنتجات لمجموعة Low Latency Group في LSEG. يتمتع برامود بخبرة تزيد عن 10 سنوات في مجال التكنولوجيا المالية، مع التركيز على تطوير البرمجيات والتحليلات وإدارة البيانات. برامود هو مهندس برمجيات سابق ومتحمس لبيانات السوق والتداول الكمي.
برامود ناياك هو مدير إدارة المنتجات لمجموعة Low Latency Group في LSEG. يتمتع برامود بخبرة تزيد عن 10 سنوات في مجال التكنولوجيا المالية، مع التركيز على تطوير البرمجيات والتحليلات وإدارة البيانات. برامود هو مهندس برمجيات سابق ومتحمس لبيانات السوق والتداول الكمي.
![]() لاكشمي كانث مانيم هو مدير المنتج في مجموعة Low Latency Group في LSEG. وهو يركز على منتجات البيانات والأنظمة الأساسية لصناعة بيانات السوق ذات زمن الوصول المنخفض. تساعد LakshmiKanth العملاء على بناء الحلول الأمثل لاحتياجات بيانات السوق الخاصة بهم.
لاكشمي كانث مانيم هو مدير المنتج في مجموعة Low Latency Group في LSEG. وهو يركز على منتجات البيانات والأنظمة الأساسية لصناعة بيانات السوق ذات زمن الوصول المنخفض. تساعد LakshmiKanth العملاء على بناء الحلول الأمثل لاحتياجات بيانات السوق الخاصة بهم.
![]() فيفيك أغاروال هو مهندس بيانات أول في مجموعة الكمون المنخفض في LSEG. تعمل Vivek على تطوير وصيانة خطوط أنابيب البيانات لمعالجة وتسليم خلاصات بيانات السوق التي تم التقاطها وخلاصات البيانات المرجعية.
فيفيك أغاروال هو مهندس بيانات أول في مجموعة الكمون المنخفض في LSEG. تعمل Vivek على تطوير وصيانة خطوط أنابيب البيانات لمعالجة وتسليم خلاصات بيانات السوق التي تم التقاطها وخلاصات البيانات المرجعية.
![]() الكيت مموشاج هو مهندس رئيسي في فريق تطوير سوق الخدمات المالية في AWS. تتولى Alket مسؤولية الإستراتيجية الفنية، والعمل مع الشركاء والعملاء لنشر حتى أحمال عمل أسواق رأس المال الأكثر تطلبًا إلى سحابة AWS.
الكيت مموشاج هو مهندس رئيسي في فريق تطوير سوق الخدمات المالية في AWS. تتولى Alket مسؤولية الإستراتيجية الفنية، والعمل مع الشركاء والعملاء لنشر حتى أحمال عمل أسواق رأس المال الأكثر تطلبًا إلى سحابة AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :لديها
- :يكون
- :ليس
- :أين
- $ UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- حول المستشفى
- الوصول
- الوصول
- إمكانية الوصول
- يمكن الوصول
- في
- نشط
- نشاط
- يقدم
- في الواقع
- تضيف
- وبالإضافة إلى ذلك
- معالجة
- مميزات
- بعد
- ضد
- أجروال
- وتهدف
- الكل
- السماح
- سابقا
- أمازون
- أمازون أثينا
- أمازون ويب سيرفيسز
- an
- تحليل
- تحليل
- تحليلية
- تحليلات
- تحليل
- تحليل
- و
- أي وقت
- أباتشي
- أباتشي سبارك
- واجهات برمجة التطبيقات
- تطبيق
- التطبيقات
- التقديم
- نهج
- ما يقرب من
- موازنة
- تحكيم
- هي
- حول
- AS
- تطلب
- تقييم
- أسوشيتد
- At
- سمات
- السلطة
- تلقائيا
- أتمتة
- توفر
- متاح
- AWS
- دعم
- شريط
- على أساس
- BE
- لان
- قبل
- المعايير
- أفضل
- ما بين
- محاولة
- مليار
- حظر
- وسطاء
- نساعدك في بناء
- لكن
- by
- حساب
- محسوب
- حساب
- دعوة
- CAN
- الطاقة الإنتاجية
- الموارد
- أسواق المال
- أسر
- القبض
- اسر
- الأقسام
- مراكز
- تحدي
- قنوات
- تتميز
- اسعارنا محددة من قبل وزارة العمل
- خيار
- اختار
- عميل
- سحابة
- الكود
- جمع
- مشترك
- قهري
- إكمال
- الطلب مكتمل
- مكونات
- شامل
- يتألف
- إدارة
- تكوين
- تكوين
- كنسولات
- تعزيز
- يحتوي
- عقود
- المساهمة
- تحول
- مؤسسة
- التكلفة
- التكاليف
- مكتوب
- خلق
- خلق
- خلق
- حرج
- حاسم
- حاليا
- على
- العملاء
- اندفاع
- البيانات
- مراكز البيانات
- مهندس بيانات
- تبادل البيانات
- إدارة البيانات
- معالجة المعلومات
- تخزين البيانات
- تعتمد على البيانات
- قواعد البيانات
- يوم
- اتخاذ القرار
- القرارات
- الترتيب
- حدد
- التوصيل
- يطالب
- مطالب
- شرح
- تظاهر
- نشر
- تفاصيل
- يحدد
- تطوير
- التطوير التجاري
- فريق التطوير
- فرق
- مختلف
- مباشرة
- مدير المدارس
- وزعت
- توزيع
- عدة
- مضاعفة
- قيادة
- ديناميكي
- حيوي
- دينامية
- كل
- سهولة
- سهولة الاستخدام
- النظام الإيكولوجي
- رئيس التحرير
- الطُرق الفعّالة
- فعالية
- مؤهل
- القضاء
- يعمل
- توظيف
- تمكين
- تمكن
- يشمل
- المساعي
- محرك
- مهندس
- محركات
- زيادة
- يضمن
- أدخل
- تصعيد
- الأثير (ETH)
- تقييم
- تقييم
- حتى
- الحدث/الفعالية
- كل
- مثال
- تبادل
- الاستبدال
- الخبره في مجال الغطس
- اكتشف
- التعبير
- يمتد
- أسرع
- ويتميز
- فبراير
- تين
- ملفات
- شغل
- تصفية
- مالي
- المؤسسات المالية
- الخدمات المالية
- التكنولوجيا المالية
- الشركات
- الاسم الأول
- لأول مرة
- خمسة
- مرونة
- ويركز
- التركيز
- متابعيك
- في حالة
- شكل
- سابق
- إلى الأمام
- أربعة
- FRAME
- تبدأ من
- وظيفة
- وظائف
- إضافي
- الفجوات
- يولد
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- العالمية
- متجر عالمي
- Go
- الذهاب
- نظام تحديد المواقع
- تجمع
- معالجة
- يملك
- وجود
- he
- الإرتفاع
- يساعد
- عالي الجودة
- أعلى
- أعلى
- سلط الضوء
- تاريخي
- تاريخ
- إسكان
- كيفية
- كيفية
- HTTP
- HTTPS
- IAM
- تحديد
- هوية
- if
- فوري
- فورا
- التأثير
- استيراد
- in
- بما فيه
- زيادة
- العالمية
- معلومات
- البنية التحتية
- الابتكارات
- رؤى
- المؤسسات
- متكامل
- المتكاملة
- التكامل
- تفاعل
- التفاعلية
- إلى
- معقد
- استثمار
- ينطوي
- IT
- JPG
- م
- كبير
- على نطاق واسع
- اسم العائلة
- كمون
- إطلاق
- أقل
- المكتبات
- خط
- سيولة
- موقع
- منطق
- أبحث
- منخفض
- أدنى
- المحافظة
- رائد
- يصنع
- القيام ب
- إدارة
- إدارة
- مدير
- مديرو
- إدارة
- أسلوب
- كثير
- تجارة
- بيانات السوق
- تأثير السوق
- أبحاث السوق
- تقلبات السوق
- صناعة السوق
- الأسواق
- هائل
- اتقان
- أقصى
- مايو..
- قياس
- الرسالة
- رسائل
- شديد التدقيق
- بدقة
- المقاييس
- مليون
- تقليل
- دقائق
- مراقبة
- الأكثر من ذلك
- علاوة على ذلك
- أكثر
- كثيرا
- متعدد
- الاسم
- الطبيعة
- التنقل
- حاجة
- إحتياجات
- بدون اضاءة
- مفكرة
- أجهزة الكمبيوتر المحمولة
- عدد
- كثير
- نمباي
- ملاحظ
- of
- عرض
- عروض
- on
- ONE
- الأمثل
- الأمثل
- الأمثل
- خيار
- مزيد من الخيارات
- or
- المنظمات
- لنا
- خارج
- الناتج
- على مدى
- الكلي
- الخاصة
- الباندا
- جزء
- شركاء
- عاطفي
- أنماط
- قمة
- إلى
- نفذ
- أداء
- محوري
- المنصة
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- يلعب
- من فضلك
- مؤامرة
- محفظة
- مديري المحافظ
- وضع
- منشور
- ما بعد التجارة
- محتمل
- دقة
- إعداد
- إعداد
- السعر
- التسعير
- ابتدائي
- رئيسي
- عملية المعالجة
- العمليات
- معالجة
- المعالج
- المنتج
- ادارة المنتج
- مدير المنتج
- المنتجات
- التقدّم
- تزود
- توفير
- نشرت
- بايثون
- Q3
- كمي
- كمية
- سؤال
- يقتبس
- معدل
- الأجور
- عرض
- حقيقي
- في الوقت الحقيقي
- موصى به
- تسجيل
- أحمر
- تخفيض
- يقلل
- مرجع
- refinitiv
- التقارير
- التقارير
- مستودع
- المتطلبات
- يتطلب
- بحث
- استجابة
- مسؤول
- نتيجة
- مما أدى
- النتائج
- عائد أعلى
- المخاطر
- النوع
- يجري
- يدير
- تخفيضات
- التدرجية
- تحجيم
- النطاقات
- التحجيم
- سلس
- بسلاسة
- الثاني
- ثواني
- القسم
- أقسام
- ضمانات
- أمن
- تسعى
- حدد
- مختار
- كبير
- مستقل
- يخدم
- خدماتنا
- طقم
- ضبط
- إظهار
- يظهر
- بشكل ملحوظ
- مماثل
- الاشارات
- مبسط
- عزباء
- انزلاق
- تطبيقات الكمبيوتر
- تطوير البرمجيات
- مهندس البرمجيات
- الحلول
- متطور
- توتر
- شرارة
- محدد
- انتشار
- ينتشر
- المدرجات
- خطوات
- تخزين
- متجر
- إستراتيجيا
- استراتيجيات
- الإستراتيجيات
- يبسط
- دراسة
- لاحق
- هذه
- سويفت
- رمز
- التآزر
- أخذ
- مع الأخذ
- فريق
- تقني
- تقنيات
- تكنولوجيا
- اختبار
- من
- أن
- •
- المعلومات
- من مشاركة
- منهم
- then
- تشبه
- عبر
- علامة
- الوقت
- في حينه
- الطابع الزمني
- عنوان
- إلى
- الإجمالي
- tp
- TPR
- تجارة
- التجار
- الصفقات
- تجارة
- استراتيجيات التداول
- استراتيجية التداول
- صفقة
- مصاريف التحويلات
- تحويل
- انتقال
- الترا
- مع
- يمر بها
- ترقية
- us
- الأستعمال
- تستخدم
- مستعمل
- يستخدم
- استخدام
- استخدام
- قيمنا
- مختلف
- التصور
- تصور
- تطاير
- حجم
- مجلدات
- وكان
- we
- الويب
- خدمات ويب
- متى
- التي
- على نحو واسع
- سوف
- مع
- في غضون
- بدون
- مجموعة العمل
- عامل
- أعمال
- في جميع أنحاء العالم
- قلق
- X
- سنوات
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت