In 2021 和 2020,我们告诉过您有关中的新功能 亚马逊Redshift 这使得分析您的所有数据并找到丰富而强大的见解变得更加容易、快速和更具成本效益。 2022 年,我们很高兴地报告 Amazon Redshift 团队的辛勤工作。 我们从客户需求出发,推出多项新功能,让您更轻松、更快速、更经济高效地分析所有数据。 这篇文章涵盖了其中的一些新功能。
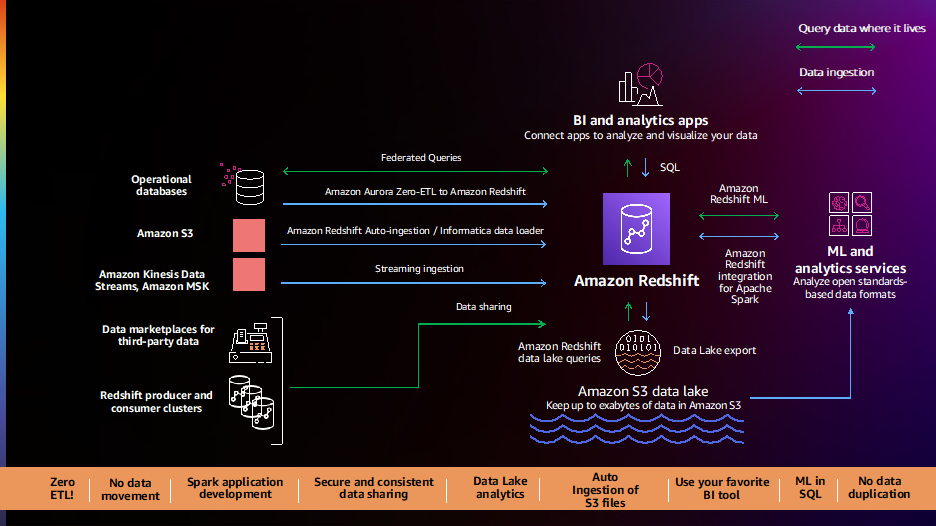
在 AWS,对于数据和分析,我们的策略是为您提供 现代数据架构 帮助您摆脱数据孤岛; 拥有专门构建的数据、分析、机器学习 (ML) 和人工智能服务,以使用正确的工具完成正确的工作; 并拥有开放、受监管、安全和完全托管的服务,使每个人都可以使用分析。 在 AWS 的现代数据架构中,作为云数据仓库的 Amazon Redshift 仍然是一个关键组件,使您能够对 TB 到 PB 级结构化和非结构化数据进行大规模和高性能的复杂 SQL 分析,并通过流行的商业智能广泛提供见解( BI) 和分析工具。 我们继续从客户需求出发进行逆向工作,并于 2022 年在 Amazon Redshift 中推出了 40 多项功能,以帮助客户处理他们最重要的数据仓库用例,包括:
- 自助分析
- 轻松的数据摄取
- 数据共享与协作
- 数据科学和机器学习
- 安全可靠的分析
- 最佳性价比分析
让我们深入探讨并讨论这些领域的新 Amazon Redshift 功能。
自助分析
客户不断告诉我们,数据和分析正变得无处不在,他们组织中的每个人都需要分析。 我们宣布 Amazon Redshift 无服务器 (预览版)于 2021 年发布,无需配置和管理数据仓库基础设施,即可在几秒钟内轻松运行和扩展分析。 2022 年 XNUMX 月,我们宣布了 Redshift Serverless 的普遍可用性,从那时起,包括 Peloton、Broadridge Financials 和 NextGen Healthcare 在内的成千上万的客户都使用它来快速轻松地分析他们的数据。 Amazon Redshift Serverless 自动预置并智能扩展数据仓库容量,为您的所有分析提供高性能,并且您只需按秒为工作负载期间使用的计算付费。 自 GA 以来,我们添加了一些功能,例如 资源标签、简化的监控和在其他 AWS 区域的可用性,以进一步简化计费并扩大全球更多区域的覆盖范围。
2021 年,我们推出了 Amazon Redshift Query Editor V2,这是一款基于 Web 的免费工具,供数据分析师、数据科学家和开发人员探索、分析 Amazon Redshift 数据仓库和数据湖中的数据并就数据进行协作。 2022 年,Query Editor V2 获得了额外的增强功能,例如 笔记本支持 用于改进编写、组织和注释查询的协作; 用户访问通过 身份提供者 (IdP) 凭据 用于单点登录; 以及同时运行多个查询以提高开发人员生产力的能力。
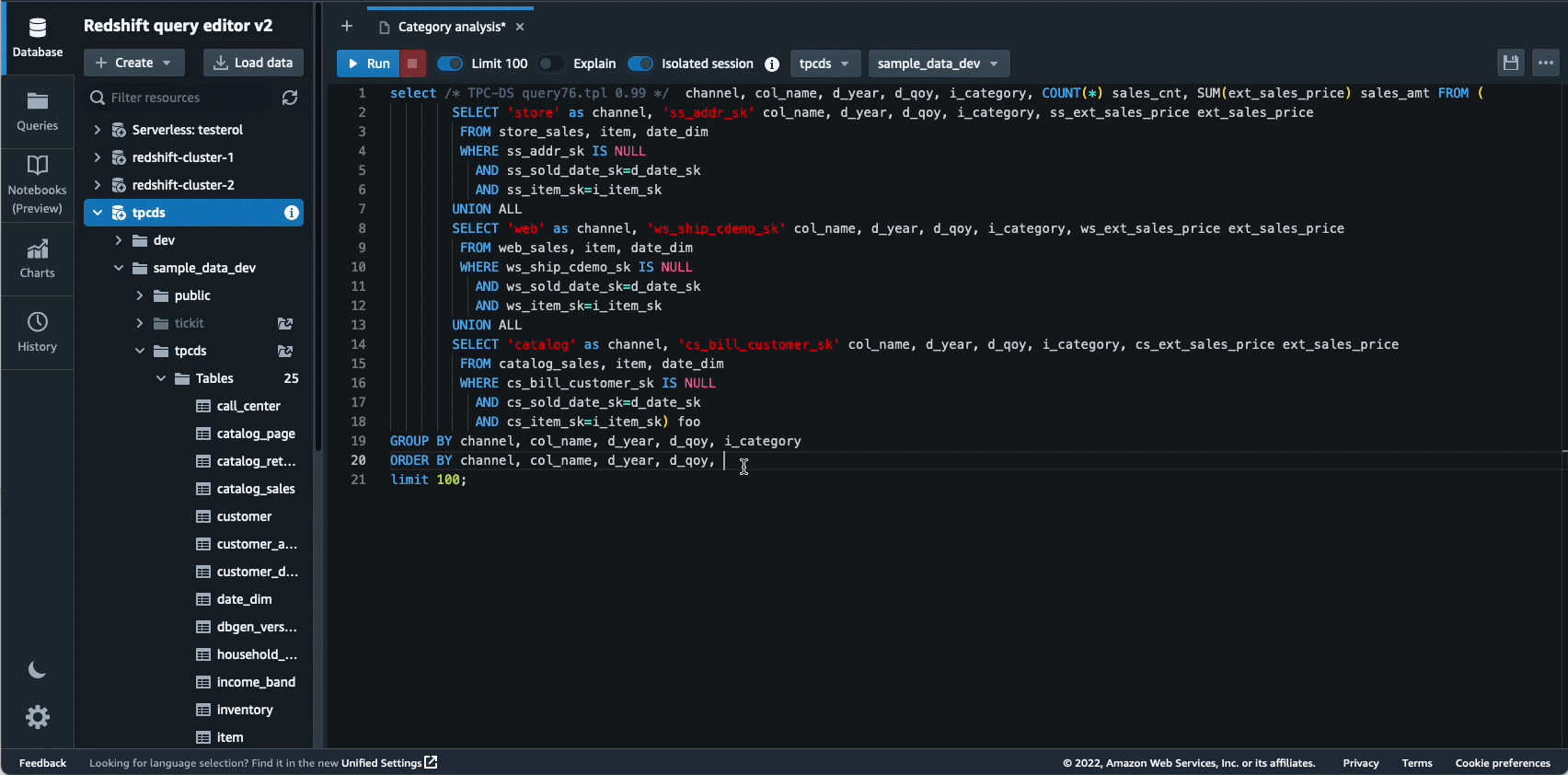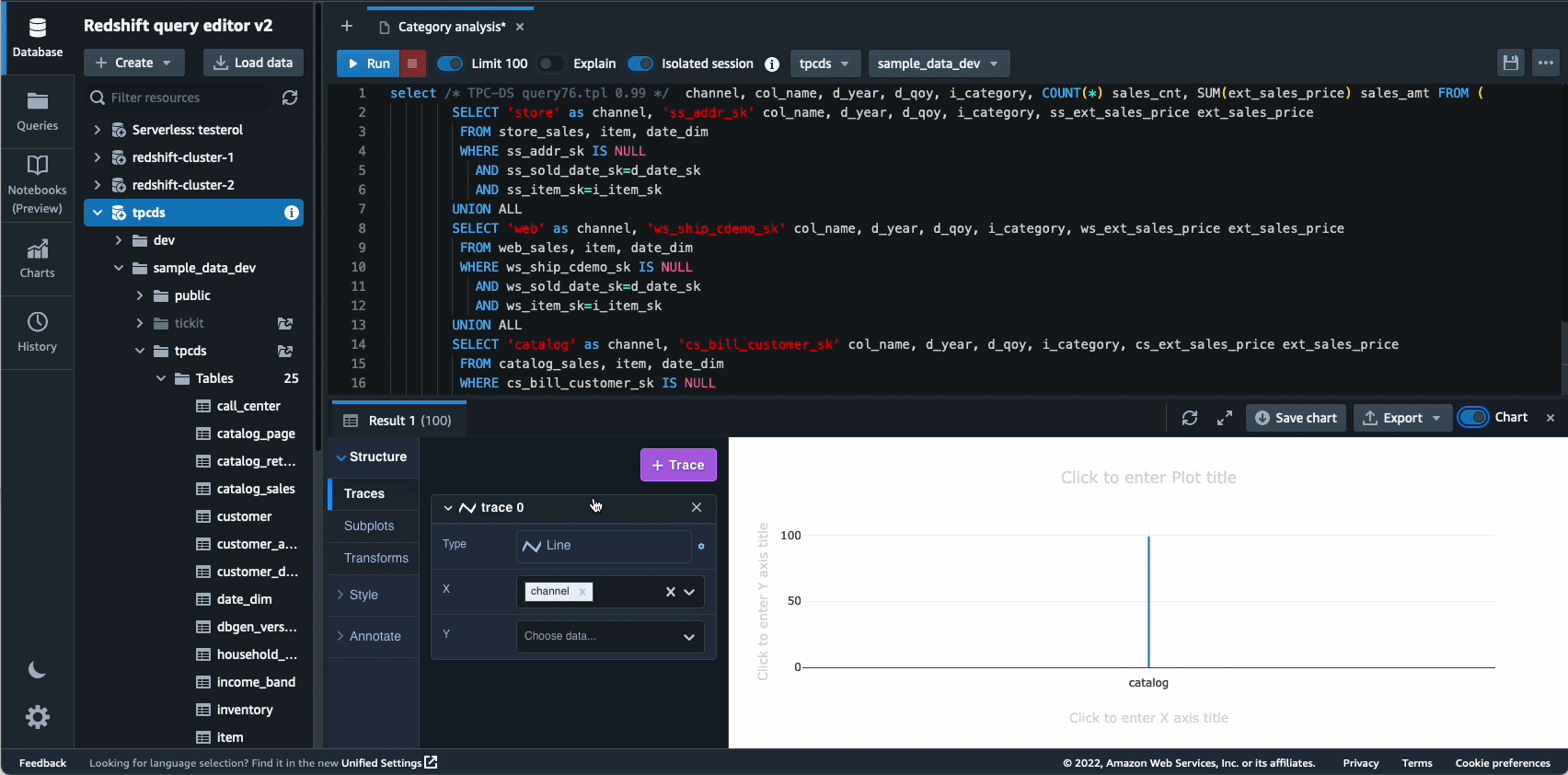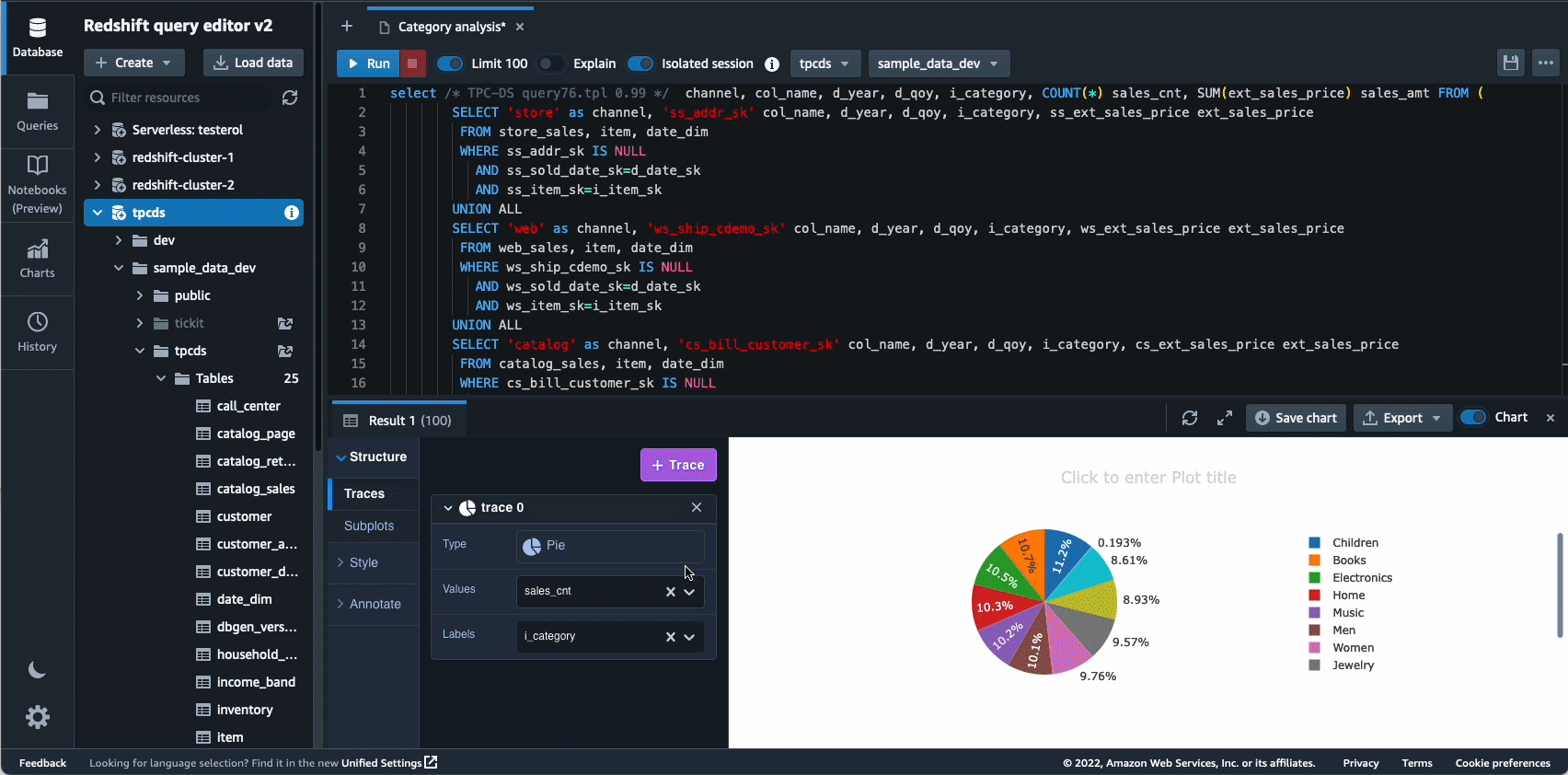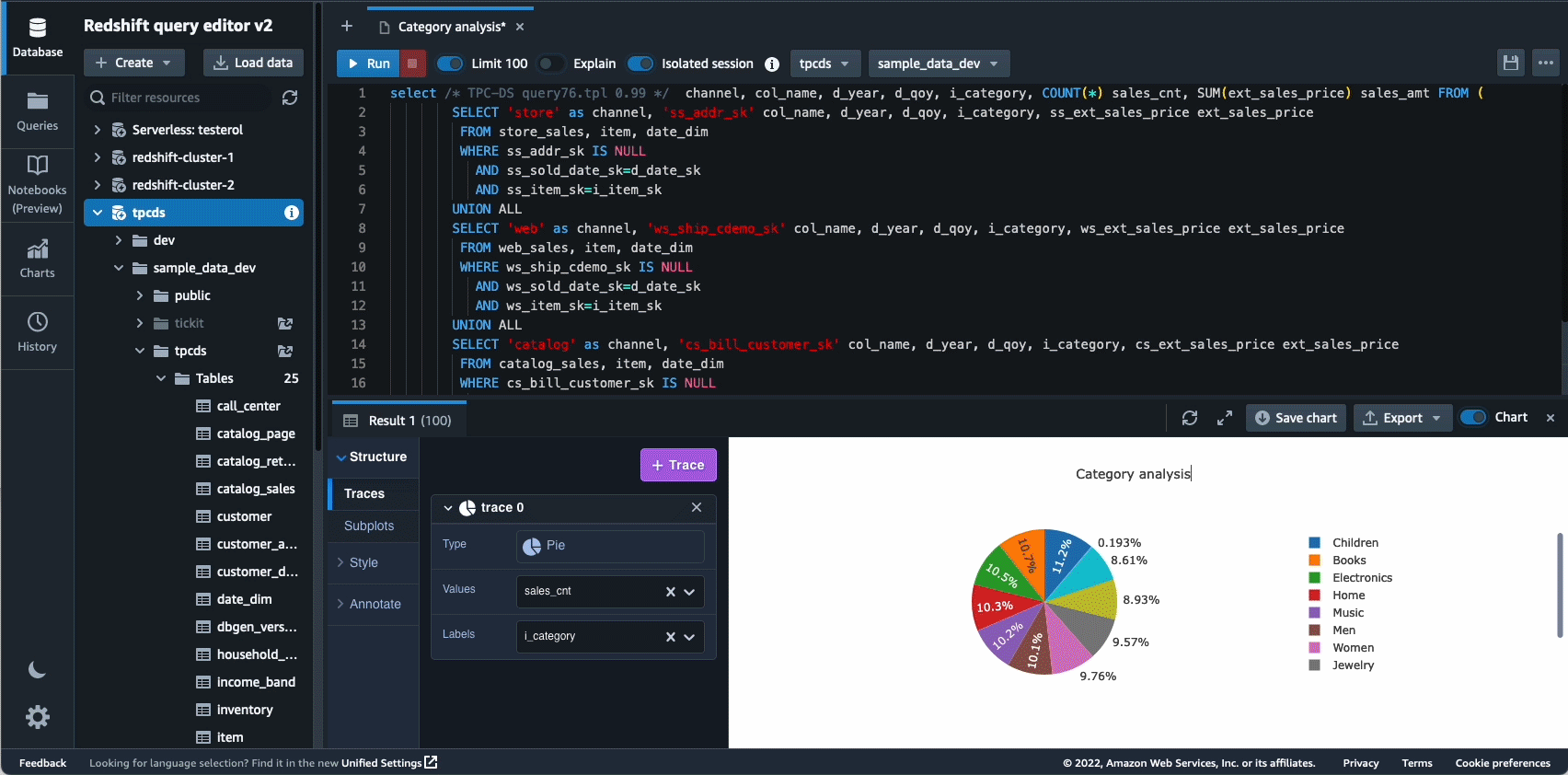
Autonomics 是我们积极致力于使用基于 ML 的优化并为客户提供自我学习和自我优化的数据仓库的另一个领域。 2022 年,我们宣布全面推出 自动物化视图 (AutoMVs) 通过自动创建和维护物化视图来提高查询性能(减少总运行时间),而无需任何用户的努力。 AutoMV 与物化视图的自动刷新、增量刷新和自动查询重写相结合,使物化视图无需维护,自动为您提供更快的性能。 除此之外 自动表优化 (ATO) 模式优化能力和 自动工作负载管理 (自动 WLM)工作负载优化功能得到进一步改进,以获得更好的查询性能。
轻松的数据摄取
客户告诉我们,他们的数据分布在多个数据源上,例如事务数据库、数据仓库、数据湖和大数据系统。 他们希望能够灵活地将这些数据与无代码/低代码、零 ETL 数据管道集成,或者在不移动数据的情况下就地分析这些数据。 客户告诉我们,他们当前的数据管道复杂、手动、僵化且缓慢,导致数据视图不完整、不一致和陈旧,限制了洞察力。 客户要求我们提供更好的前进方式,我们很高兴地宣布推出一系列新功能来简化和自动化数据管道。
Amazon Aurora 零 ETL 与 Amazon Redshift 集成(预览) 使您能够对数 PB 的交易数据运行近乎实时的分析和机器学习。 它提供了一种无代码解决方案,用于从多个 亚马逊极光 Amazon Redshift 数据仓库中的数据库在写入 Aurora 后几秒钟内可用,无需构建和维护复杂的数据管道。 借助此功能,Aurora 客户还可以访问 Amazon Redshift 功能,例如复杂的 SQL 分析、内置 ML、数据共享以及对多个数据存储和数据湖的联合访问。 此功能现在可用于预览 Amazon Aurora MySQL 兼容版 版本 3(与 MySQL 8.0 兼容),您可以 请求访问预览.
Amazon Redshift 现在支持 从 Amazon S3 自动复制 (预览)以简化数据加载 亚马逊简单存储服务 (Amazon S3) 到 Amazon Redshift。 您现在可以设置连续文件摄取规则(复制作业)来跟踪您的 Amazon S3 路径并自动加载新文件,而无需额外的工具或自定义解决方案。 复制作业可以通过系统表进行监控,它们会自动跟踪以前加载的文件并将它们从摄取过程中排除,以防止数据重复。 此功能现在可以预览; 您可以通过使用预览轨道创建新集群来尝试此功能。
客户不断告诉我们他们需要即时、即时、实时的分析,我们很高兴地宣布 流媒体摄取支持的普遍可用性 在 Amazon Redshift 中 Amazon Kinesis数据流 和 适用于Apache Kafka的Amazon托管流 (亚马逊 MSK)。 此功能消除了在将流数据引入 Amazon Redshift 之前在 Amazon S3 中暂存流数据的需要,使您能够实现以秒为单位的低延迟,同时每秒将数百兆字节的流数据引入您的数据仓库。 您可以在 Amazon Redshift 中使用 SQL 连接到多个 Kinesis 数据流或 MSK 主题并直接从中提取数据,创建自动刷新流式实体化视图,并直接在流之上进行转换以访问流式数据,并将实时数据与历史数据相结合数据以获得更好的洞察力。 例如,Adobe 已将 Amazon Redshift 流式摄取作为其 Adobe Experience Platform 的一部分进行集成,以实时摄取和分析 Web 和应用程序点击流以及各种应用程序(如 CRM 和客户支持应用程序)的会话数据。
客户告诉我们,他们希望 Amazon Redshift、BI 和 ETL(提取、转换和加载)工具与 Salesforce 和 Marketo 等业务应用程序之间进行简单、开箱即用的集成。 我们很高兴地宣布全面上市 适用于 Amazon Redshift 的 Informatica 数据加载器,它使您能够免费使用 Informatica Data Loader 将高速和大量数据加载到 Amazon Redshift 中。 您只需在 Amazon Redshift 控制台上选择 Informatica Data Loader 选项即可。 进入 Informatica Data Loader 后,您可以连接到 Salesforce 或 Marketo 等来源,选择 Amazon Redshift 作为目标,然后开始加载您的数据。
数据共享与协作
客户不断告诉我们,他们希望分析他们所有的第一方和第三方数据,并向他们的客户、合作伙伴和供应商提供丰富的数据驱动的见解。 我们在 2021 年推出了新功能,例如 数据共享 和 AWS 数据交换集成,使您可以更轻松地分析所有数据并在组织内外共享这些数据。
使用数据共享的客户的一个很好的例子是 Orion。 Orion 为财富管理、资产管理和投资管理提供商等金融服务行业的客户提供实时数据即服务 (DaaS) 解决方案。 他们拥有 2,500 多个数据源,主要是位于本地和 AWS 中的 SQL Server 数据库。 使用 Kafka 连接器将数据流式传输到 Amazon Redshift。 他们有一个生产者集群,接收所有这些数据,然后使用数据共享实时共享数据以进行协作。 这是一个服务于多个客户端的多租户架构。 鉴于数据的敏感性,数据共享是一种在集群之间提供工作负载隔离并安全地将数据共享给最终用户的方法。
2022 年,我们继续在这一领域进行投资,以通过新功能提高性能、治理和开发人员生产力,使数据共享和协作变得更容易、更简单、更快速。
随着客户构建大规模数据共享配置,他们要求简化共享数据的治理和安全性,我们正在添加 使用 AWS Lake Formation 进行集中访问控制 适用于 Amazon Redshift 数据共享,支持跨多个 Amazon Redshift 数据仓库共享实时数据。 借助此功能,Amazon Redshift 现在支持通过使用简化的 Amazon Redshift 数据共享管理 AWS湖形成 作为单一管理平台集中管理数据或数据共享权限。 您可以使用 Lake Formation API 和 AWS管理控制台,并允许其他 Amazon Redshift 数据仓库发现和使用 Amazon Redshift 数据共享。
数据科学和机器学习
客户不断告诉我们,他们希望他们的数据和分析系统能够帮助他们回答范围广泛的问题,从他们的业务中正在发生的事情(描述性分析)到为什么会发生(诊断分析)以及未来会发生什么(预测分析)。 Amazon Redshift 提供诸如复杂 SQL 分析、数据湖分析和 亚马逊红移机器学习 供客户分析他们的数据并发现强大的见解。 红移机器学习 将 Amazon Redshift 与 亚马逊SageMaker,一种完全托管的 ML 服务,使您能够使用熟悉的 SQL 命令创建、训练和部署 ML 模型。
客户还要求我们更好地集成 Amazon Redshift 和 Apache Spark,因此我们很高兴地宣布 适用于 Apache Spark 的 Amazon Redshift 集成 使基于 Spark 的应用程序可以轻松访问数据仓库。 现在,开发人员使用 AWS 分析和 ML 服务,例如 亚马逊电子病历, AWS胶水,并且 SageMaker 可以毫不费力地构建 Apache Spark 应用程序,这些应用程序可以读取和写入其 Amazon Redshift 数据仓库。 Amazon EMR 和 AWS Glue 封装了 Redshift-Spark 连接器,因此您可以轻松地从基于 Spark 的应用程序连接到数据仓库。 您可以对排序、聚合、限制、连接和标量函数等操作使用多种下推功能,以便仅将相关数据从您的 Amazon Redshift 数据仓库移动到消费 Spark 应用程序。 您还可以通过利用 AWS身份和访问管理 (IAM) 凭证以连接到 Amazon Redshift。
安全可靠的分析
客户不断告诉我们,他们的数据仓库是关键任务系统,需要高可用性、可靠性和安全性。 我们在 2022 年在这方面推出了许多新功能。
Amazon Redshift 现在支持 多可用区部署 (预览版)适用于基于 RA3 实例的集群,它支持在多个 AWS 可用区同时运行您的数据仓库,并在不可预见的可用区范围内的故障场景中持续运行。 多可用区支持已可用于 Redshift Serverless。 Amazon Redshift 多可用区部署允许您在可用区出现故障时进行恢复,而无需任何用户干预。 Amazon Redshift 多可用区数据仓库作为具有一个端点的单个数据仓库进行访问,并通过在多个可用区之间自动分配工作负载处理来帮助您最大限度地提高性能。 在意外中断期间无需更改应用程序即可保持业务连续性。
2022 年,我们推出了基于角色的访问控制、行级安全性和数据屏蔽(预览版)等功能,让您更轻松地管理访问权限并决定谁可以访问哪些数据,包括混淆个人身份信息 (PII) ) 比如信用卡号。
您可以使用 基于角色的访问控制 (RBAC) 根据最终用户的工作角色和权限,在广泛或精细的级别上控制最终用户对数据的访问。 借助 RBAC,您可以使用 SQL 创建一个角色,向该角色授予一系列精细权限,然后将该角色分配给最终用户。 角色可以被授予对象级、列级和系统级权限。 此外,RBAC 还为 DBA、操作员、安全管理员或自定义角色引入了开箱即用的系统角色。
行级安全性(RLS) 简化了对表中行的细粒度访问的设计和实现。 使用 RLS,您可以根据用户的工作角色或 SQL 权限限制对表中行子集的访问。
Amazon Redshift 支持 动态数据屏蔽 (DDM),现在提供预览版,可让您简化对 Amazon Redshift 数据仓库中 PII 的保护,例如社会保险号、信用卡号和电话号码。 借助动态数据屏蔽,您可以通过简单的基于 SQL 的屏蔽策略来控制对数据的访问,这些策略确定 Amazon Redshift 如何在查询时将敏感数据返回给用户。 您可以创建屏蔽策略来定义一致的、保留格式的和不可逆的屏蔽数据值。 您可以对表中的特定列或列列表应用屏蔽策略。 此外,您还可以灵活地选择如何显示屏蔽数据。 例如,您可以完全隐藏数据,用通配符替换部分实数值,或者定义您自己的方式来使用 SQL 表达式、Python 或 AWS Lambda 用户定义的函数。 此外,您可以应用基于其他列的条件屏蔽策略,该策略根据一个或多个不同列中的值有选择地保护表中的列数据。
我们还宣布了增强功能 审计日志, 本机集成 Microsoft Azure活动目录,并支持 默认 IAM 角色 在其他区域进一步简化安全管理。
最佳性价比分析
客户不断告诉我们,他们需要快速且经济高效的数据仓库,以在任何规模下提供高性能,同时保持低成本。 从第一天起 Amazon Redshift 于 2012 年推出,我们采用了数据驱动的方法,并使用车队遥测技术构建了云数据仓库服务,可为您提供任何规模的最佳性价比。 这些年,我们进化了 Amazon Redshift 的架构 并推出了诸如 红移托管存储 (RMS) 用于存储和计算的分离, 亚马逊红移频谱 对于数据湖查询, 自动表优化 用于物理模式优化, 自动工作负载管理 确定工作负载的优先级并分配正确的计算和内存, 集群调整大小 垂直扩展计算和存储,以及 并发扩展 动态扩展或扩展计算。我们的 绩效基准 继续展示 Amazon Redshift 的性价比领先地位。
2022 年,我们添加了新功能,例如 写入操作的并发扩展 例如 COPY、INSERT、UPDATE 和 DELETE,以支持几乎无限的并发用户和查询。 我们还通过对轻型、CPU 高效、字典编码的字符串列进行矢量化扫描,为基于字符串的数据处理引入了性能改进,这允许数据库引擎直接对压缩数据进行操作。
我们还添加了对 SQL 运算符的支持,例如 合并 (用于插入或更新的单个操作员); 联系方式 (用于分层查询); 分组集、汇总和多维数据集 (用于多维报告); 并将 SUPER 数据类型的大小增加到 16 MB,使您可以更轻松地从旧数据仓库迁移到 Amazon Redshift。
结论
我们的客户继续告诉我们,数据和分析仍然是他们的首要任务,并且在这些时期以经济高效的方式从他们的数据中提取更多商业价值的需求比过去任何时候都更加明显。 Amazon Redshift 作为您的云数据仓库,使您能够以 TB 到 PB 级结构化和非结构化数据的规模和性能运行复杂的 SQL 分析,并通过流行的 BI 和分析工具广泛提供见解。
尽管我们在 40 年推出了 2022 多项功能并且创新的步伐继续加快,但这仍然是第一天,我们期待收到您的来信,了解这些功能如何帮助您为您的组织释放更多价值。 我们邀请您试用这些新功能,如果您有进一步的意见,请通过您的 AWS 客户团队与我们联系。
关于作者
 马南高尔 是 AWS 分析服务(包括 AWS 的 Amazon Redshift)的产品上市领导者。 他拥有超过 25 年的经验,精通数据库、数据仓库、商业智能和分析。 Manan 拥有杜克大学的 MBA 学位和电子与通信工程学士学位。
马南高尔 是 AWS 分析服务(包括 AWS 的 Amazon Redshift)的产品上市领导者。 他拥有超过 25 年的经验,精通数据库、数据仓库、商业智能和分析。 Manan 拥有杜克大学的 MBA 学位和电子与通信工程学士学位。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- 对,能力--
- 关于
- 加快
- ACCESS
- 访问数据
- 访问
- 无障碍
- 账号管理
- 横过
- 要积极。
- 积极地
- 添加
- 增加
- 额外
- 另外
- 土砖
- 所有类型
- 允许
- 已经
- Amazon
- 亚马逊电子病历
- 分析师
- 分析
- 分析
- 分析
- 和
- 宣布
- 公布
- 另一个
- 回答
- 阿帕奇
- Apache Spark
- APIs
- 应用领域
- 应用领域
- 使用
- 的途径
- 架构
- 国家 / 地区
- 地区
- 人造的
- 人工智能
- 财富
- 资产管理
- 审计
- Aurora
- 作者
- 汽车
- 自动化
- 自动表
- 自动
- 可用性
- 可使用
- AWS
- AWS胶水
- Azure
- 基于
- 基础
- 成为
- before
- 作为
- 最佳
- 更好
- 之间
- 大
- 大数据运用
- 计费
- 午休
- 广阔
- Broadridge的
- 建立
- 建筑物
- 内建的
- 商业
- 商业应用
- 业务连续性
- 商业智能
- 能力
- 容量
- 卡
- 案件
- 例
- 更改
- 字符
- 选择
- 客户
- 云端技术
- 簇
- 合作
- 合作
- 采集
- 柱
- 列
- 结合
- 结合
- 注释
- 通信
- 兼容性
- 完全
- 复杂
- 元件
- 计算
- 并发
- 分享链接
- 一贯
- 安慰
- 消费
- 继续
- 持续
- 继续
- 连续
- 控制
- 经济有效
- 成本
- 占地面积
- 创建信息图
- 创造
- 资历
- 信用
- 信用卡
- 积分
- 客户关系管理
- 电流
- 习俗
- 顾客
- 客户支持
- 合作伙伴
- 定制
- data
- 数据交换
- 数据湖
- 数据处理
- 数据共享
- 数据仓库
- 数据仓库
- 数据驱动
- 数据库
- 数据库
- 天
- 更深
- 交付
- 演示
- 部署
- 部署
- 设计
- 确定
- 开发商
- 开发
- 不同
- 直接
- 通过各种方式找到
- 发现
- 讨论
- 分布
- 分布
- 公爵
- 杜克大学
- ,我们将参加
- 动态
- 更容易
- 容易
- 编辑
- 努力
- 电子
- 消除
- 消除
- enable
- 使
- 使
- 端点
- 发动机
- 工程师
- 醚(ETH)
- 每个人
- 进化
- 例子
- 交换
- 兴奋
- 扩大
- 体验
- 探索
- 表达式
- 提取
- 失败
- 熟悉
- 高效率
- 快
- 专栏
- 特征
- 文件
- 档
- 金融
- 金融服务
- 金融
- 找到最适合您的地方
- 舰队
- 高度灵活
- 训练
- 向前
- 自由的
- 止
- 充分
- 功能
- 进一步
- 未来
- 其他咨询
- 得到
- GIF
- 给
- 特定
- 给
- 给予
- 玻璃
- 去市场
- 治理
- 授予
- 授予
- 大
- 发生
- 快乐
- 硬
- 有
- 医疗保健
- 听力
- 帮助
- 帮助
- 隐藏
- 高
- 历史的
- 持有
- 创新中心
- How To
- HTML
- HTTPS
- 数百
- IAM
- 身分
- 履行
- 改善
- 改善
- 改善
- in
- 包含
- 增加
- 行业中的应用:
- 信息
- 基础设施
- 創新
- 刀片
- 可行的洞见
- 整合
- 集成
- 集成
- 积分
- 房源搜索
- 介入
- 介绍
- 推出
- 投资
- 投资
- 邀请
- 隔离
- IT
- 工作
- 工作机会
- 加入
- 七月
- 卡夫卡
- 保持
- 保持
- 键
- Kinesis 数据流
- 湖泊
- 大规模
- 潜伏
- 发射
- 推出
- 领导者
- 领导团队
- 学习
- 遗产
- Level
- 轻巧
- 极限
- 清单
- 生活
- 实时数据
- 加载
- 装载机
- 装载
- 看
- 低
- 机
- 机器学习
- 制成
- 保持
- 保养
- 使
- 制作
- 管理
- 管理
- 颠覆性技术
- 手册
- Marketo
- 面膜
- 生产力
- 内存
- 迁移
- ML
- 模型
- 现代
- 修改
- 监控
- 监控
- 更多
- 移动
- 多
- MySQL的
- 本地人
- 需求
- 打印车票
- 需要
- 全新
- 新功能
- 数
- 数字
- 优惠精选
- 一
- 打开
- 操作
- 操作
- 运营
- 操作者
- 运营商
- 优化
- 附加选项
- 组织
- 组织
- 其他名称
- 停机
- 学校以外
- 己
- 步伐
- 包
- 面包
- 部分
- 伙伴
- 过去
- 大集团
- 性能
- 权限
- 亲自
- 电话
- 的
- ii
- 地方
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 满意
- 政策
- 政策
- 热门
- 帖子
- 强大
- 预测分析
- 防止
- 预览
- 先前
- 车资
- 主要
- 优先
- 优先
- 过程
- 处理
- 制片人
- 产品
- 生产率
- 保护
- 提供
- 提供者
- 供应商
- 提供
- 规定
- 蟒蛇
- 有疑问吗?
- 很快
- 范围
- 达到
- 阅读
- 真实
- 实时的
- 实时数据
- 接收
- 恢复
- 减少
- 地区
- 相应
- 可靠性
- 可靠
- 遗迹
- 更换
- 报告
- 报告
- 岗位要求
- 限制
- 导致
- 回报
- 检讨
- 重写
- 丰富
- 硬性
- 角色
- 角色
- 卷起
- 定位、竞价/采购和分析/优化数字媒体采购,但算法只不过是解决问题的操作和规则。
- 运行
- 运行
- sagemaker
- Salesforce的
- 鳞片
- 秤
- 缩放
- 情景
- 科学
- 科学家
- 其次
- 秒
- 安全
- 安全
- 保安
- 敏感
- 灵敏度
- 无服务器
- 服务
- 服务
- 特色服务
- 会议
- 集
- 套数
- 几个
- Share
- 共用的,
- 共享
- 显示
- 简易
- 简
- 简化
- 只是
- 同时
- 自
- 单
- 坐在
- 尺寸
- 放慢
- So
- 社会
- 方案,
- 解决方案
- 一些
- 来源
- 火花
- 具体的
- SQL
- 阶段
- 存储
- 商店
- 策略
- 流
- 流
- 流
- 结构化
- 结构化和非结构化数据
- 这样
- 超级
- 供销商
- SUPPORT
- 支持
- 系统
- 产品
- 表
- 目标
- 团队
- 未来
- 其
- 第三方
- 数千
- 通过
- 次
- 时
- 至
- 工具
- 工具
- 最佳
- Topics
- 合计
- 触摸
- 跟踪时
- 培训
- 交易
- 改造
- 转换
- 普及
- 意外
- 大学
- 无限
- 开锁
- 更新
- 最新动态
- us
- 使用
- 用户
- 用户
- 利用
- 折扣值
- 价值观
- 各个
- 版本
- 查看
- 意见
- 实质上
- 仓库保管
- 仓储服务
- 财富
- 财富管理
- 卷筒纸
- 基于网络的
- 什么是
- 什么是
- 这
- 而
- WHO
- 宽
- 大范围
- 广泛
- 将
- 中
- 也完全不需要
- 工作
- 工作
- 加工
- 全世界
- 写
- 书面
- 年
- 年
- 您一站式解决方案
- 和风网
- 区