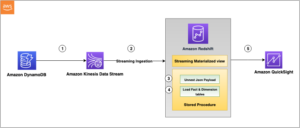
亚马逊EMR Studio 是一个集成开发环境 (IDE),使数据科学家和数据工程师能够轻松开发、可视化和调试用 R、Python、Scala 和 PySpark 编写的数据工程和数据科学应用程序。 EMR Studio 通过 EMR Studio 工作区提供完全托管的 Jupyter Notebook 和 Spark UI 和 YARN Timeline Server 等工具。 您可以将 EMR Studio 工作区附加到 EMR 集群,并使用 EMR 集群的计算能力并在集群上运行数据科学作业。 数据通常存储在由以下人员管理的数据湖中 AWS湖形成,使您能够通过简单的授予或撤销机制应用细粒度的访问控制。
我们很高兴向您介绍 运行时角色 适用于 EMR Studio 工作区。 现在,您可以定义运行时角色,并在附加 EMR Studio 工作区时将其分配给 EMR 集群。 EMR 集群上的作业将使用此运行时角色来访问 AWS 资源。 配置运行时角色后,您还可以使用 Lake Formation 并对 EMR Studio 工作区提交的作业应用细粒度的数据访问控制。
以前,将 EMR Studio 工作区附加到 EMR 集群时,所有工作区必须使用相同的 AWS身份和访问管理 (IAM) 角色——即集群的 亚马逊弹性计算云 (Amazon EC2) 实例配置文件。 因此,连接到同一 EMR 集群的所有工作区都具有相同的数据访问权限。 为了控制对数据源的访问,每个 EMR Studio 工作区必须使用不同的 EMR 集群,并且需要多个 EMR 实例配置文件。
从 Amazon EMR 6.11 版本开始,您现在可以在将 EMR Studio 工作区附加到 EMR 集群时选择运行时角色。 此运行时角色将访问范围限制在工作区级别。 从 EMR Studio 工作区运行的 Apache Livy 和 Apache Spark 作业将有权仅访问附加到运行时角色的策略允许的数据和资源。 此外,当从使用 Lake Formation 管理的数据湖访问数据时,您可以使用 Lake Formation 权限实施细粒度的数据访问控制。 这有助于您减少运营开销。
在这篇文章中,我们演示了如何为 EMR Studio 工作区配置运行时角色,并将工作区附加到具有运行时角色的 EMR 集群。 由于大型企业通常使用多个 AWS 账户,并且其中许多账户可能需要访问由单个 AWS 账户管理的数据湖,因此我们的示例使用两个 AWS 账户。 我们解释了如何控制对 EMR Studio 运行时角色的访问,通过 Lake Formation 管理数据湖中帐户之间的数据访问,以及对 EMR 运行时角色强制执行表级和列级权限。
解决方案概述
为了演示细粒度的访问控制,我们创建了一个示例 AWS胶水 数据库名称为company,并在Lake Formation中管理数据库权限。 该数据库由两个单独的表组成:
- 员工 – 该表存储公司员工的信息,包括员工ID、姓名、部门、工资
- 产品及技术 – 该表存储公司销售的产品信息,包括产品ID、名称、类别和价格
为了演示数据访问控制,我们考虑以下数据用户:
- Alice,销售团队的数据科学家 – 她应该对数据库中的所有列具有只读访问权限
products表和选定的列,包括 uID、名称和部门employees表 - Bob,人力资源团队的数据科学家 – 他应该具有对所有列的只读访问权限
employees表,并且不应该访问products表
为了演示跨账户数据共享,我们考虑两个账户:
- 数据生产者账户 – 我们将此帐户称为
123456789012在这篇文章中。 该帐户管理原始数据 亚马逊简单存储服务 (Amazon S3) 并将数据写入数据湖。 这company数据库和表应该在此帐户中。 - 数据消费账户 – 我们将此帐户称为
111122223333在这篇文章中。 该帐户由用户直接访问以进行数据分析,并且没有数据的写入权限。 Alice 和 Bob 应该可以访问此帐户。
架构实现如下:
- 数据生产者帐户管理数据湖。 原始数据存储在 S3 存储桶中并在 AWS Glue 数据目录中编目。
- 数据生产者账户中的Lake Formation通过数据目录管理数据访问,并提供与数据消费者账户的跨账户数据共享。
- 数据消费者账户中的 Lake Formation 管理表级别对数据湖的跨账户访问以及细粒度的 Lake Formation 权限。 欲了解更多信息,请参阅 细粒度访问控制的方法.
- 在 EMR 集群上运行作业时,数据使用者帐户中的 EMR Studio 工作区使用运行时角色。
- EMR集群连接数据消费者账户中的Glue Data Catalog,通过跨账户数据共享从数据湖中查询数据。
下图说明了此体系结构。
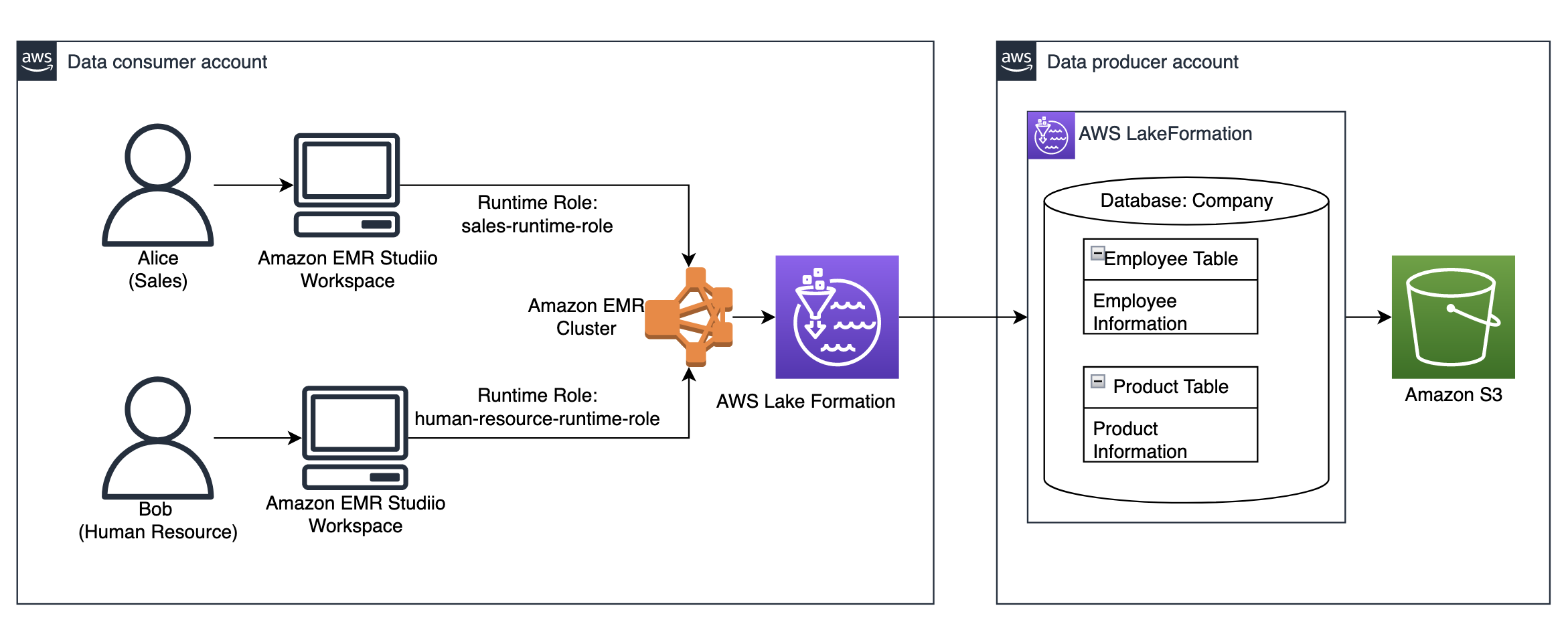
在以下部分中,我们将逐步介绍通过 Lake Formation 跨帐户共享数据、运行具有运行时角色的 EMR Studio 工作区,并演示细粒度的访问控制。
先决条件
您应该具备以下先决条件:
在数据生产者帐户中创建基础设施
完成以下步骤来创建基础架构资源:
- 登录数据生产者AWS账户(
123456789012). - 启动堆栈 部署 CloudFormation 模板以创建必要的资源。

- 针对 DataLakeBucket后缀,输入数据湖使用的 S3 存储桶的后缀。 要创建的整个 S3 存储桶名称将是
{AwsAccoundId}-{AwsRegion}-{DataLakeBucketSuffix}. - 创建 CloudFormation 堆栈后,导航到 输出 堆栈的选项卡并捕获值
DataLakeS3Bucket以在下一步中使用。
创建数据文件并将其上传到数据生产者账户中的 Amazon S3
将您的 AWS CLI 配置为使用有权上传到数据生产者 AWS 账户中的 DataLakeS3BucketName 的 IAM 身份 (123456789012),或者您可以使用以下方式登录 CloudShell AWS管理控制台. 完成以下步骤:
- 在本地计算机上,使用 cd 命令移动到您选择的目录,例如,
cd ~. - 运行 脚本
chmod 744 create_sample_data.sh && ./create_sample_data.sh <DataLakeS3BucketName>.
该脚本将创建一个子目录 tmp 在当前工作目录中,以 CSV 文件形式创建测试数据,并将文件上传到 DataLakeS3BucketName S3斗。
在数据生产者帐户中设置 Lake Formation
在本节中,我们将逐步介绍在数据生产者帐户中设置 Lake Formation 的步骤。
设置 Lake Formation 跨账户数据共享版本设置
Lake Formation 支持多种数据共享版本。 对于本文,我们使用版本 3。要了解有关数据共享版本之间的差异的更多信息,请参阅 更新跨账户数据共享版本设置。 要更改数据共享版本,请参阅 启用新版本.
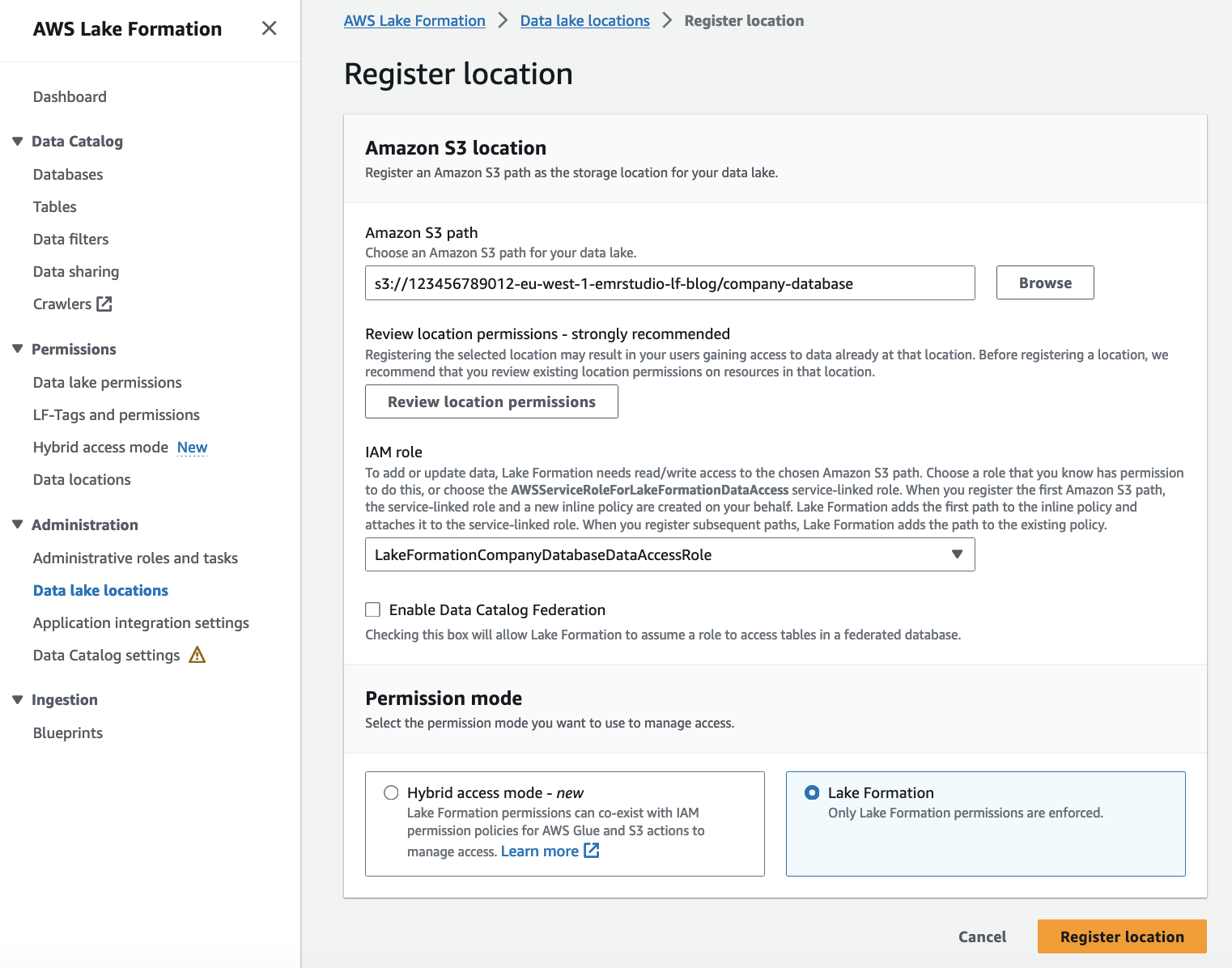
将 Amazon S3 位置注册为数据湖位置
当你 注册 Amazon S3 位置 使用 Lake Formation,您可以指定一个对该位置具有读/写权限的 IAM 角色。 注册后,当 EMR 集群请求访问此 Amazon S3 位置时,Lake Formation 将提供所提供角色的临时凭证以访问数据。 我们已经创建了角色 LakeFormationCompanyDatabaseDataAccessRole 为此目的,在上一步中。 要将 Amazon S3 位置注册为数据湖位置,请完成以下步骤:
- 使用数据生产者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台 (
123456789012). - 在导航窗格中,选择 数据湖位置 下 行政和支持部门.
- 注册地点.
- 针对 Amazon S3路径,输入
s3://<DataLakeS3BucketName>/company-database. - 针对 IAM角色,输入
LakeFormationCompanyDatabaseDataAccessRole. - 针对 权限模式, 选择 湖形成.
- 注册地点.
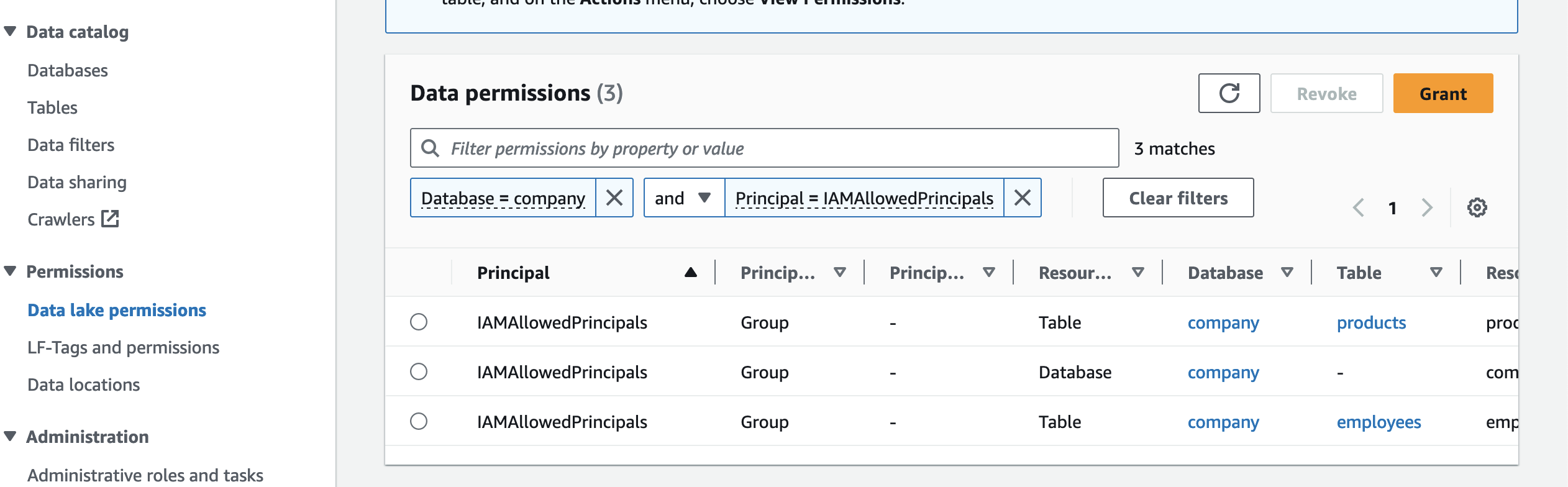
撤销授予 IAMAllowedPrincipals 的权限
IAMAllowedPrincipals 组包括 IAM 策略允许访问您的数据目录资源的任何 IAM 用户和角色。 到 实施湖泊形成模型, 我们要 撤销 IAMAllowedPrincipals 的权限 使用以下步骤:
- 使用数据生产者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 权限下的数据湖权限.
- 过滤权限
Database = company和Principle=IAMAllowedPrinciples. - 选择授予主体的所有权限
IAMAllowedPrincipals并选择 撤消.
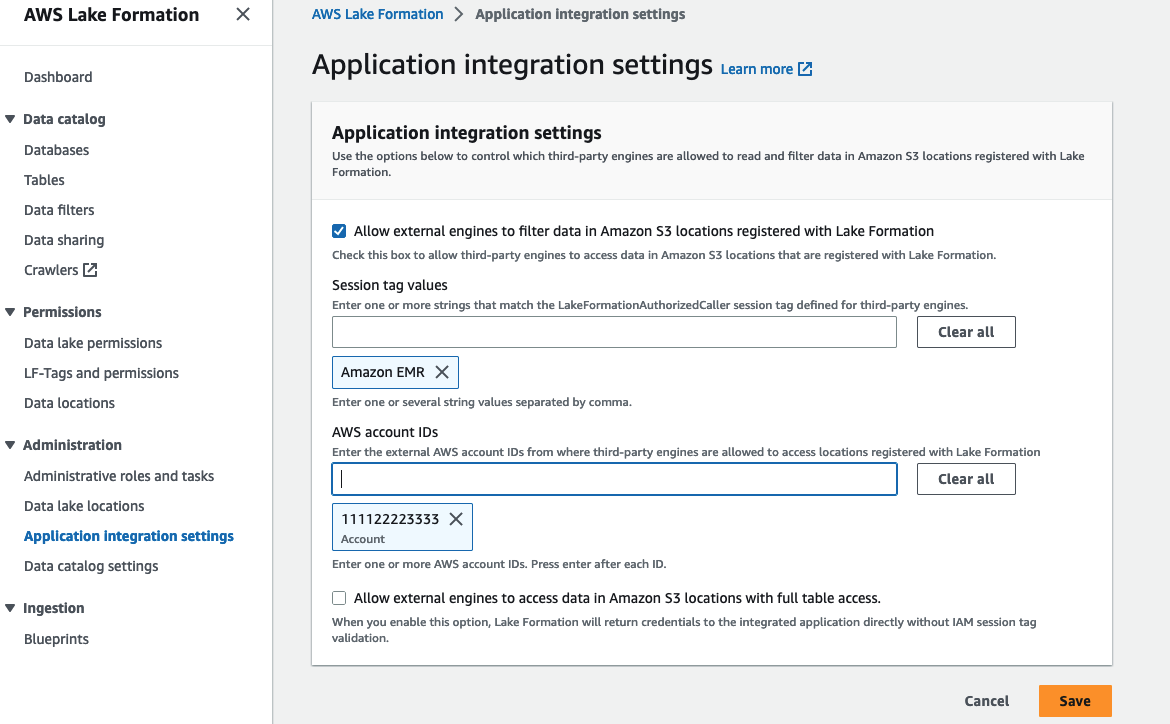
设置应用程序集成设置
要强制执行 EMR 集群的权限,您需要向 Lake Formation 注册会话标签值。 Lake Formation 使用此会话标签来授权调用者并提供对数据湖的访问。 我们注册 Amazon EMR 作为会话标记值。 该值将在 安全配置 创建EMR集群时。
使用以下步骤设置会话标记:
- 使用数据生产者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 应用程序集成设置 下 行政和支持部门 在导航窗格中。
- 选择 允许外部引擎过滤在 Lake Formation 中注册的 Amazon S3 位置中的数据.
- 针对 会话标签值,输入
Amazon EMR. - 针对 AWS 账户 ID,输入数据使用者 AWS 账户 ID (
111122223333). - 保存.
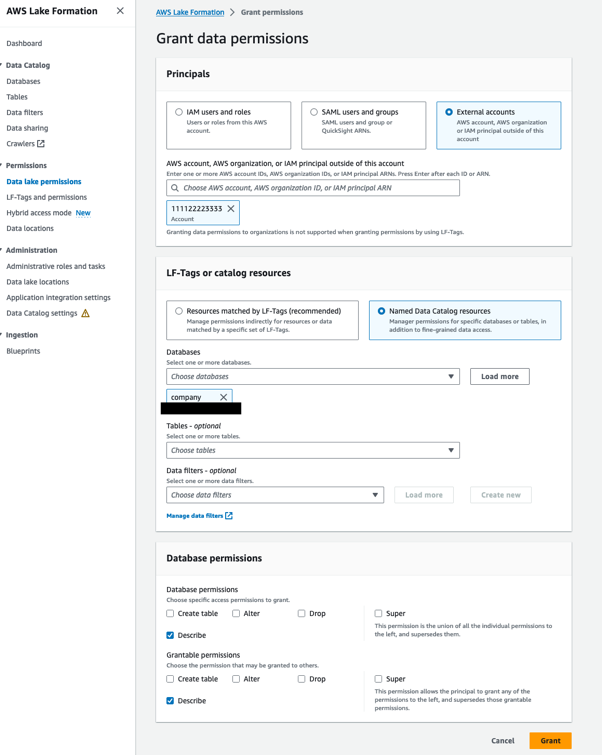
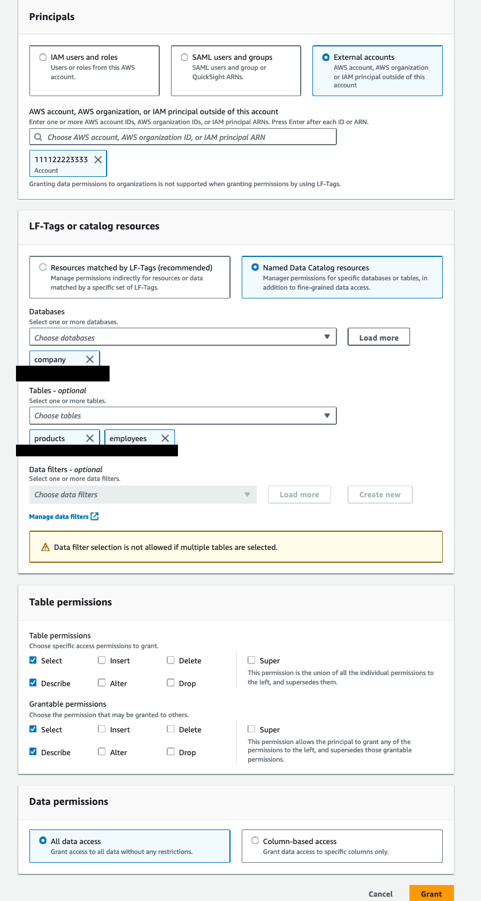
将数据库和表共享给数据消费者账户
我们现在向数据使用者 AWS 账户授予权限,包括可授予的权限。 这允许数据消费者帐户中的 Lake Formation 数据湖管理员控制对该帐户内数据的访问。
向数据使用者帐户授予数据库权限
完成以下步骤:
- 使用数据生产者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择数据库
company,以及 行动 菜单,在 权限,选择 格兰特. - 在 Luxinar|罗悉激光 部分,选择 外部帐户 并输入数据消费者AWS账户(
111122223333). - 在 LF-Tags 或目录资源 部分中,选择
company数据库. - 在 数据库权限 部分,选择 描述 为 数据库权限 和 授予的权限.
这允许数据消费者帐户中的数据湖管理员描述数据库并向数据消费者帐户中的其他主体授予描述权限。
- 格兰特.
向数据消费者帐户授予表权限
完成以下步骤:
- 使用数据生产者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 表.
- 点击
products表,属于company数据库,并在 行动 菜单,在 权限,选择 格兰特. - 在 Luxinar|罗悉激光 部分,选择 外部帐户 并输入数据消费者AWS帐户(
111122223333). - 在 LF-Tags 或目录资源 部分,选择 命名数据目录资源 并指定以下内容:
- 针对 数据库,选择
company. - 针对 表,选择
products和employees.
- 针对 数据库,选择
- 在 表权限 部分中,选择 选择 和 描述 为 表权限 和 授予的权限.
这允许数据使用者帐户中的数据湖管理员选择和描述表,并向数据使用者帐户中的其他主体授予选择和描述表权限。
- 在 数据权限 部分,选择 所有数据访问.
- 格兰特.
现在我们已经完成了数据生产者帐户的设置。
在数据消费者帐户中设置基础设施
完成以下步骤来创建基础架构资源:
- 登录数据消费账户(
111122223333). - 启动堆栈 部署 CloudFormation 模板以创建必要的资源。

- 针对 发布标签,输入要使用的 Amazon EMR 版本标签,只能是 emr-6.11 或更高版本。
- 针对 实例类型,选择EMR集群的实例类型,例如r4.4xlarge。
- 针对 EMRS3Bucket名称后缀,输入S3存储桶后缀,用于存储EMR集群日志和EMR笔记本文件。 要创建的完整 S3 存储桶名称将为
{AWSAccoundId}-{AWSRegion}-{EMRS3BucketNameSuffix}. - 针对 S3路径到运输证书,输入包含用于传输中加密的 .pem 文件的 .zip 文件的 S3 路径。
有关创建包含 .pem 文件的 .zip 文件并将其上传到 S3 存储桶的说明,请参阅 提供用于使用 Amazon EMR 加密对传输中的数据进行加密的证书.
- 创建 CloudFormation 堆栈后,导航到 输出 堆栈的标签。
- 捕捉价值
EMRStudioLink用于登录 EMR Studio。
接受数据消费者帐户中的资源共享
要访问共享资源,您必须先接受邀请。
- 使用具有 AWS RAM 访问权限的 IAM 身份打开数据使用者账户的 AWS RAM 控制台。
- 在导航窗格中,选择 资源份额 下 与我分享.
您应该会看到来自数据生产者帐户的两个待处理资源共享。
- 接受两个资源共享。
你应该看到 company 数据库, employees 表,和 products 数据目录中的表。
在数据消费者帐户中设置 Lake Formation
在本节中,我们将逐步介绍在数据使用者帐户中设置 Lake Formation 的步骤。
设置应用程序集成设置
与数据生产者账户中的设置类似,您需要将 Amazon EMR 注册为会话标签。 该值在 安全配置 在 CloudFormation 堆栈中创建 EMR 集群时。
为此,请完成以下步骤:
- 使用数据消费者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台 (
111122223333). - 应用程序集成设置 下 行政和支持部门 在导航窗格中。
- 选择 允许外部引擎过滤在 Lake Formation 中注册的 Amazon S3 位置中的数据.
- 针对 会话标签值,输入
Amazon EMR. - 针对 AWS 账户 ID,输入数据使用者 AWS 账户 ID (
111122223333). - 保存.
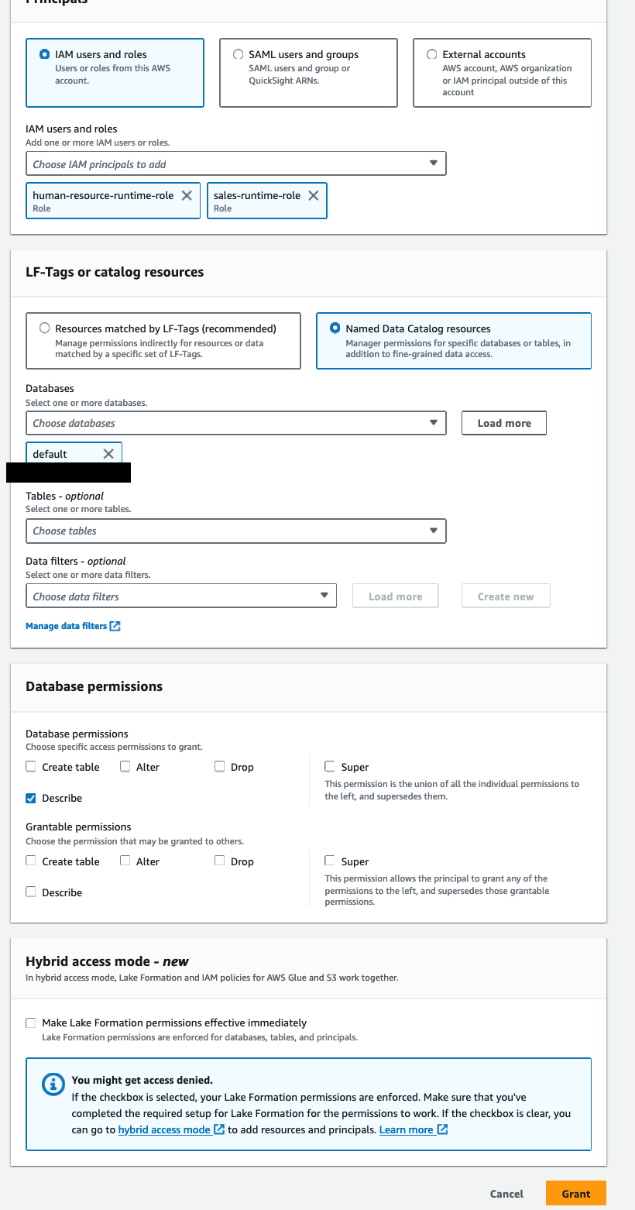
向默认数据库上的运行时角色授予描述权限
如果您在 Lake Formation 中没有默认数据库,或者您的默认数据库已具有授予的权限 IAMAllowedPrinciples, 你可以跳过这一步。
默认情况下,Amazon EMR 将检查默认数据库。 如果您的 Lake Formation 中已有默认数据库,请通过完成以下步骤向默认数据库上的运行时角色授予描述权限:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员用户打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择默认数据库,验证所有者账户ID是否为数据消费账户(
111122223333), 而在 行动 菜单中选择 格兰特. - 在 原理部分, 选择 IAM用户和角色.
- 针对 IAM用户和角色,选择
sales-runtime-role和human-resource-runtime-role. - 针对 LF-Tags 或目录资源, 选择 命名数据目录资源 并选择默认值 数据库.
- 在 数据库权限 部分,用于 数据库权限,选择 描述.
- 格兰特.
为共享数据库创建资源链接
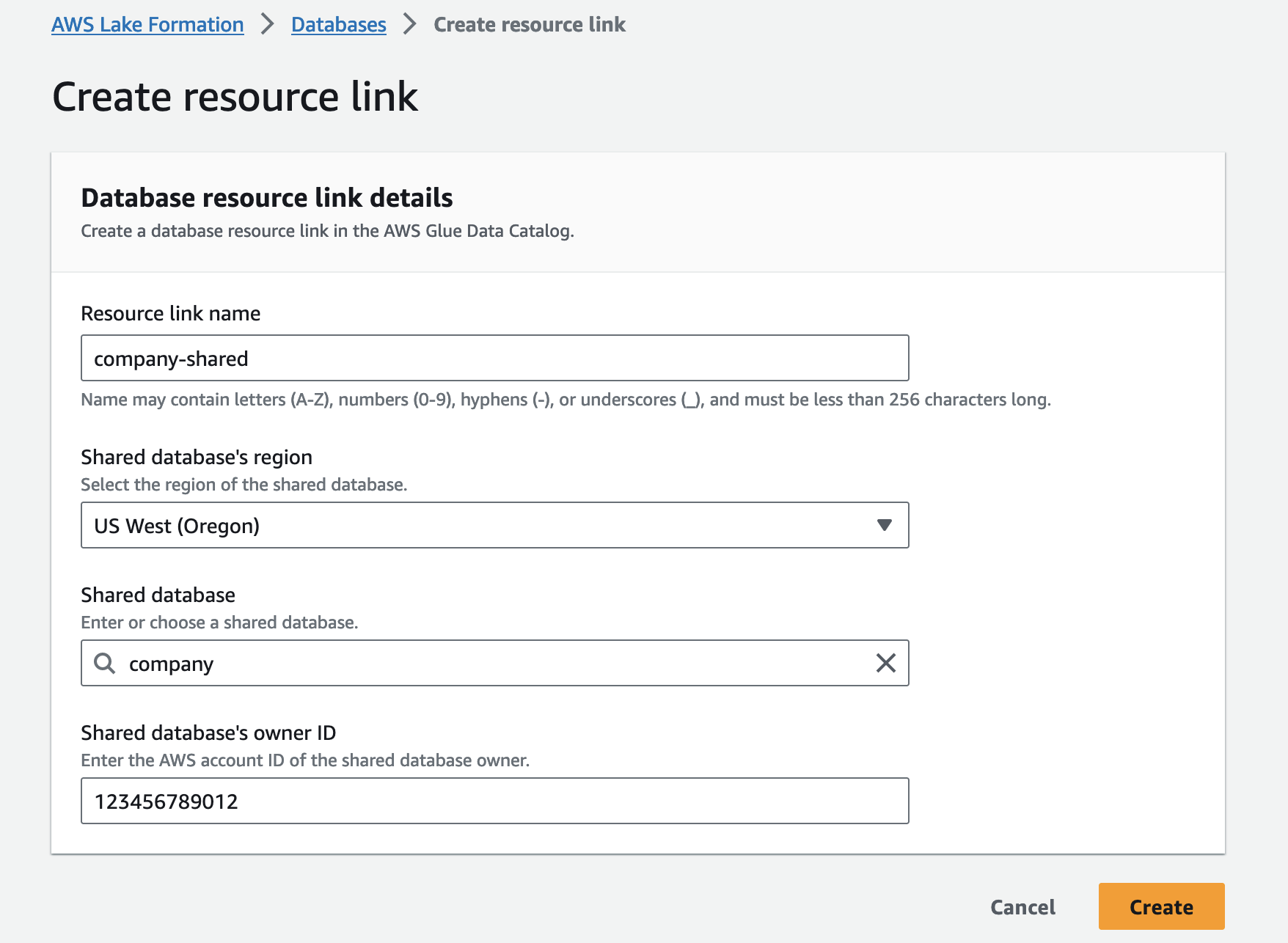
要访问数据生产者AWS账户共享的数据库和表资源,您需要创建一个 资源链接 在数据消费者 AWS 账户中。 资源链接是一个数据目录对象,它是到本地或共享数据库或表的链接。 创建到数据库或表的资源链接后,您可以在任何要使用数据库或表名称的地方使用资源链接名称。 在此步骤中,您将资源链接的权限授予运行时角色原则。 然后,运行时角色将通过资源链接访问共享数据库和基础表中的数据。
要创建资源链接,请完成以下步骤:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 点击
company数据库,验证所有者帐户 ID 是数据生产者帐户(123456789012), 而在 行动 菜单中选择 创建资源链接. - 针对 资源链接名称,输入资源链接的名称(例如,
company-shared). - 针对 共享数据库的区域,选择区域
company数据库。 - 针对 共享数据库,选择公司数据库。
- 针对 共享数据库的所有者 ID,输入数据生产者账户的账户ID(
123456789012). - 创建.
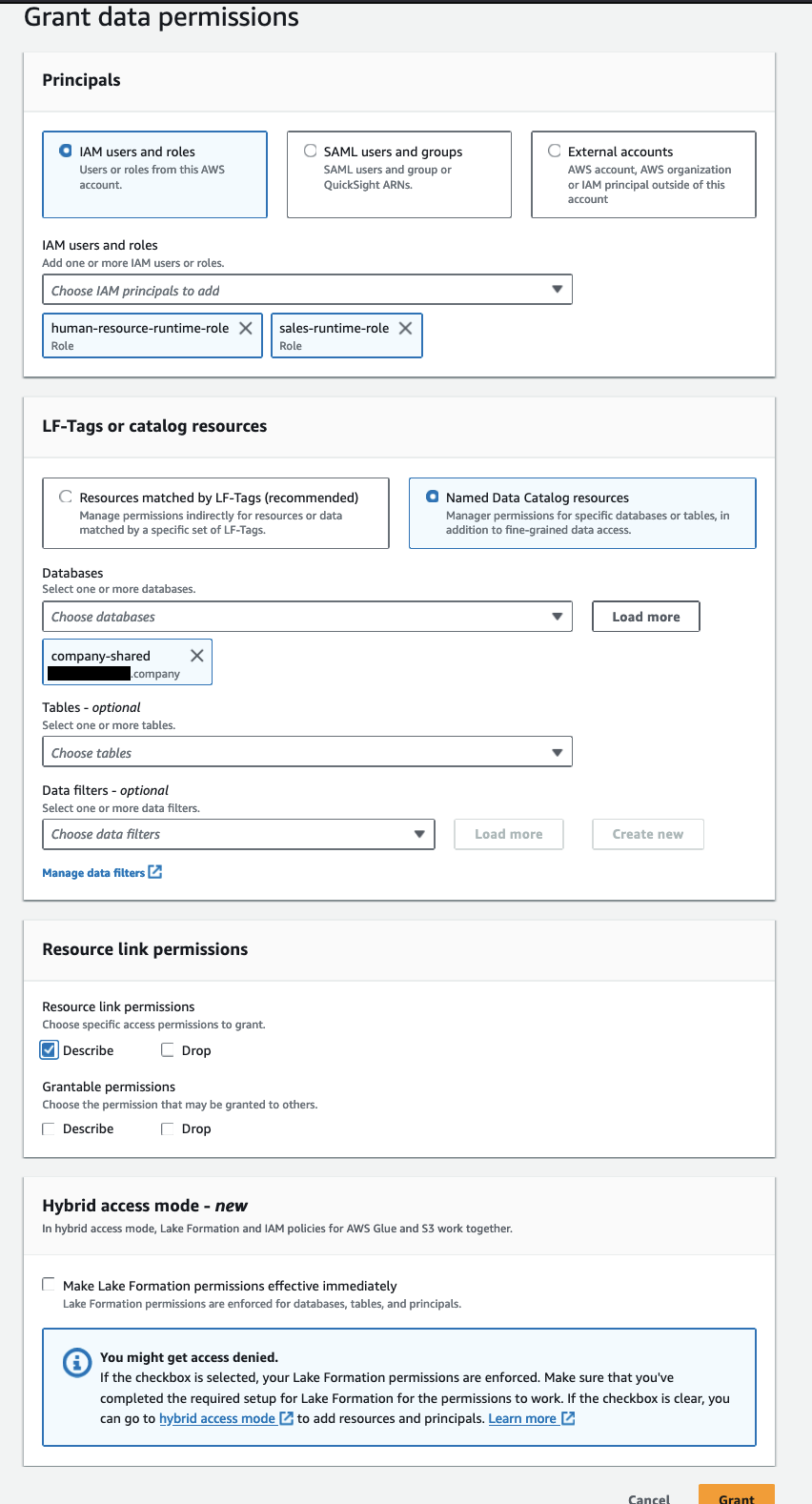
将资源链接的权限授予运行时角色原理
使用以下步骤向 sales-runtime-role 和 human-resource-runtime-role 授予对资源链接的权限:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择资源链接(
company-shared)和 行动 菜单中选择 格兰特. - 在 Luxinar|罗悉激光 部分,选择 IAM用户和角色,并选择
sales-runtime-role和human-resource-runtime-role. - 在 LF-Tags 或目录资源 部分,用于 数据库,选择
company-shared. - 在 资源链接权限 部分,选择 描述.
这允许运行时角色描述资源链接。 我们不会对可授予的权限进行任何选择,因为运行时角色不应该能够向其他原则授予权限。
- 格兰特.
将表的权限授予运行时角色原则
您需要授予对表的权限 sales-runtime-role 和 human-resource-runtime-role 允许数据访问:
Human-resource-runtime-role应该对所有列具有描述和选择权限employees表,并且没有权限products表。Sales-runtime-role应该对列有选择权限uid,name及department,在employees表,并描述和选择表中所有列的权限products表。
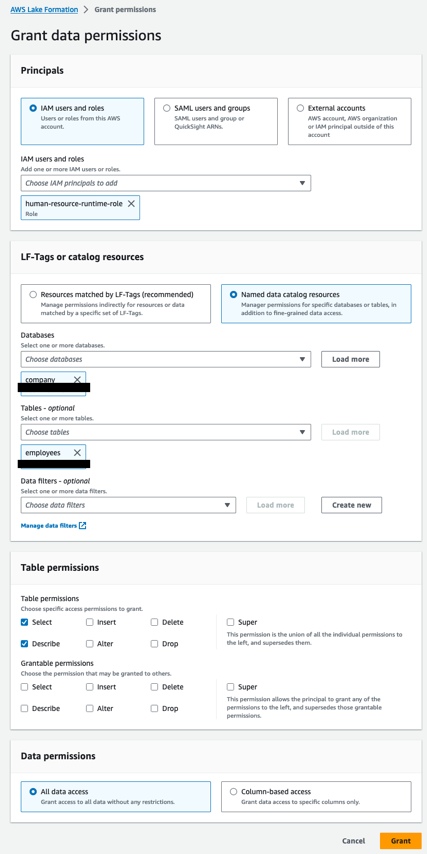
将员工表的权限授予 human-resource-runtime-role
完成以下步骤:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择资源链接(
company-shared)和 行动 菜单中选择 授予目标. - 在 原理部分, 选择 IAM用户和角色,然后选择
human-resource-runtime-role. - 在 LF-Tags 或目录资源 部分,选择 命名数据目录资源 并指定以下内容:
- 针对 数据库,选择
company. - 针对 表¸选择
employees.
- 针对 数据库,选择
- 在 表权限 部分,用于 表权限, 选择 描述 和 选择.
- 在 数据权限 部分,选择 所有数据访问.
- 格兰特.
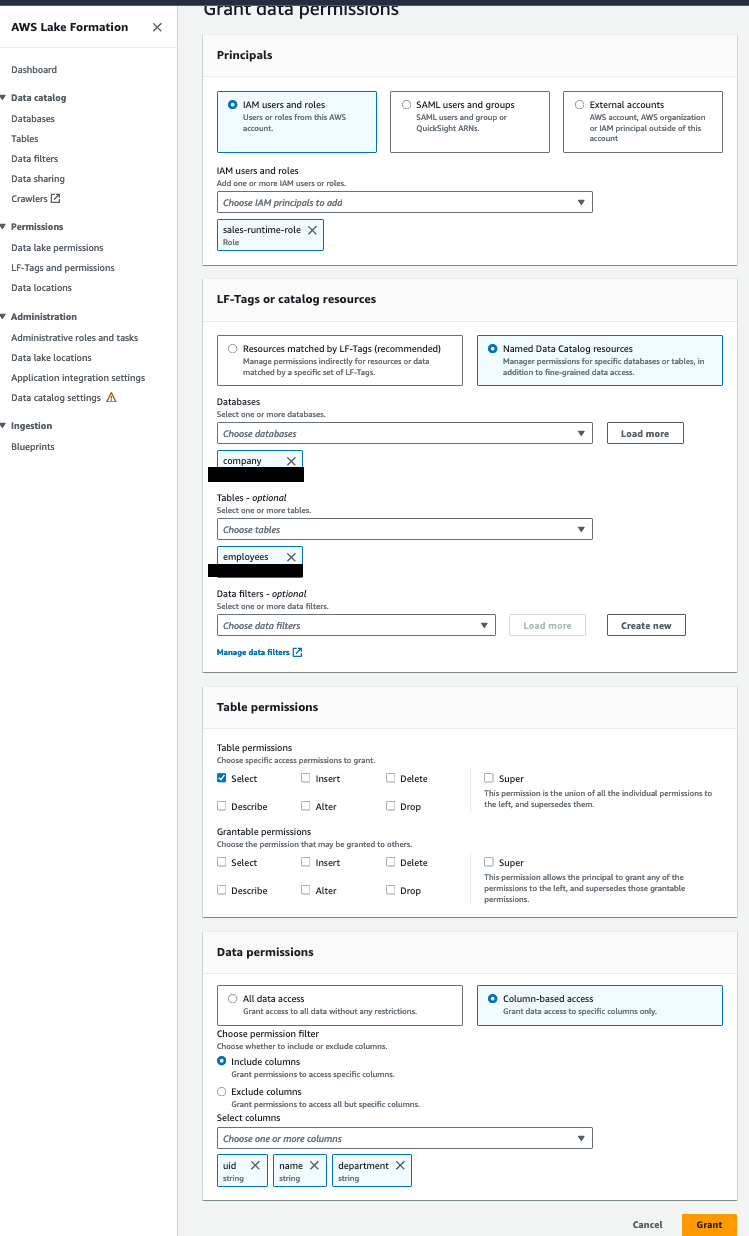
向 sales-runtime-role 授予员工表的权限
完成以下步骤:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择资源链接(
company-shared)和 行动 菜单中选择 授予目标. - 在 原理部分, 选择 IAM用户和角色,然后选择
sales-runtime-role. - 在 LF-Tags 或目录资源 部分,选择 命名数据目录资源 并指定以下内容:
- 针对 数据库,选择
company. - 针对 表,选择
employees.
- 针对 数据库,选择
- 在 表权限 部分,用于 表权限, 选择 选择.
- 在 数据权限 部分,选择 基于列的访问.
- 选择 包括栏 并选择
uid,name及department列。 - 格兰特.
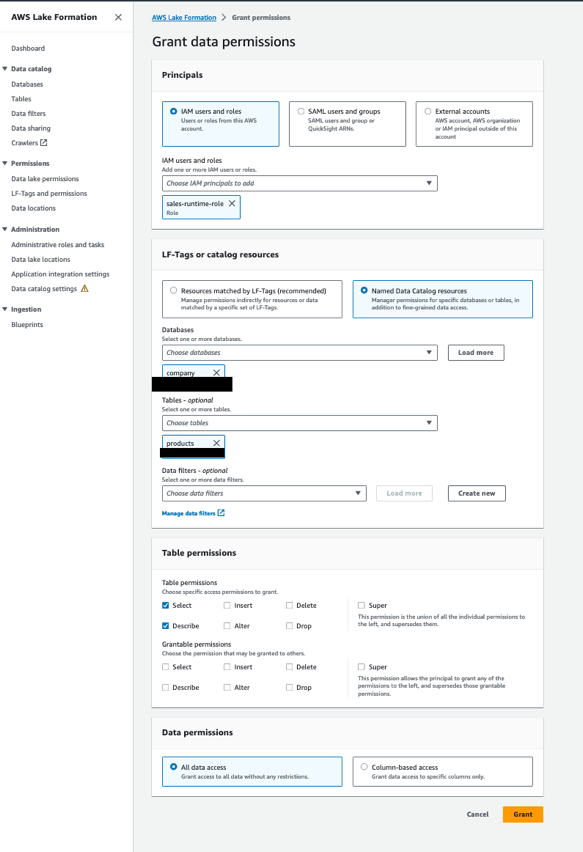
将产品表的权限授予 sales-runtime-role
完成以下步骤:
- 使用数据使用者帐户中的 Lake Formation 数据湖管理员打开 Lake Formation 控制台。
- 在导航窗格中,选择 数据库.
- 选择资源链接(
company-shared)和 行动 菜单中选择 授予目标. - 在 原理部分, 选择 IAM用户和角色,然后选择
sales-runtime-role. - 在 LF-Tags 或目录资源 部分,选择 命名数据目录资源 并指定以下内容:
- 针对 数据库,选择
company. - 针对 表,选择
products.
- 针对 数据库,选择
- 在 表权限 部分,用于 表权限, 选择 选择 和 描述.
- 在 数据权限 部分,选择 所有数据访问.
- 格兰特.
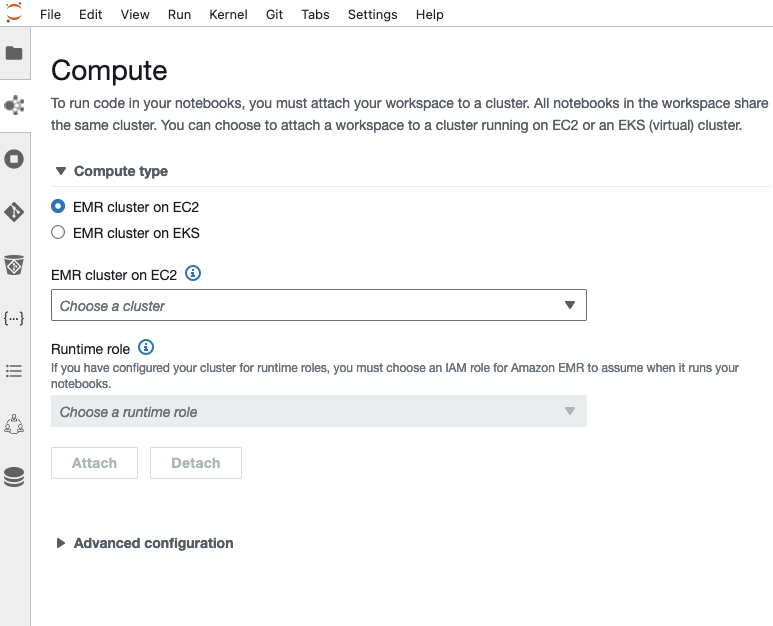
登录 EMR Studio 并使用 EMR Studio 工作区
切换你的角色 至 alice-role or bob-role 在控制台上使用不同的Web浏览器来测试访问。 打开 EMRStudioLink CloudFormation 堆栈输出中的 URL,用于使用每个角色登录 EMR Studio,然后完成以下步骤:
- 工作区 在导航窗格中并选择 创建工作区.
- 输入工作区的名称和描述。
- 创建工作区.
当工作区准备就绪时,包含 JupyterLab 的新选项卡将自动打开。 如有必要,请在浏览器中启用弹出窗口。
- 选择了 计算 导航窗格中的 图标将 EMR Studio 工作区与计算引擎连接。
- 选择 EC2 上的 EMR 集群 计算类型.
- 选择您使用 AWS CloudFormation 创建的 EMR 集群 ID。
- 针对 运行时角色,选择
sales-runtime-role如果登录为alice-role。 选human-resource-runtime-role如果登录为bob-role. - 附.
在 EMR Studio 工作区中运行代码并验证数据访问
使用 alice-role 或 bob-role 登录后,在具有 PySpark 内核的 EMR Studio 工作区中运行以下代码:
使用不同的角色时,您应该会看到不同的结果。
根据我们在 Lake Formation 中的数据访问配置,Alice 将拥有对 products 桌子。 她可以查看除工资之外的所有列 employees 表。
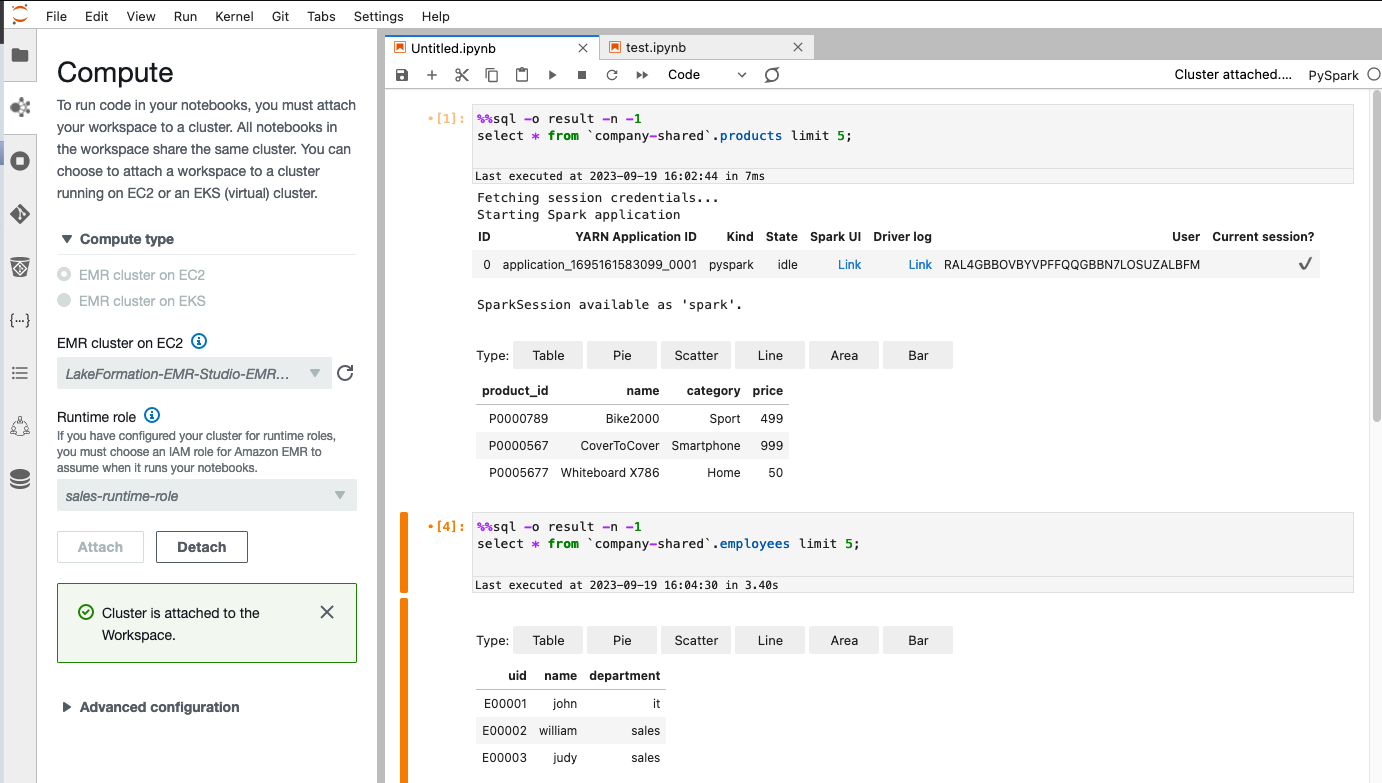
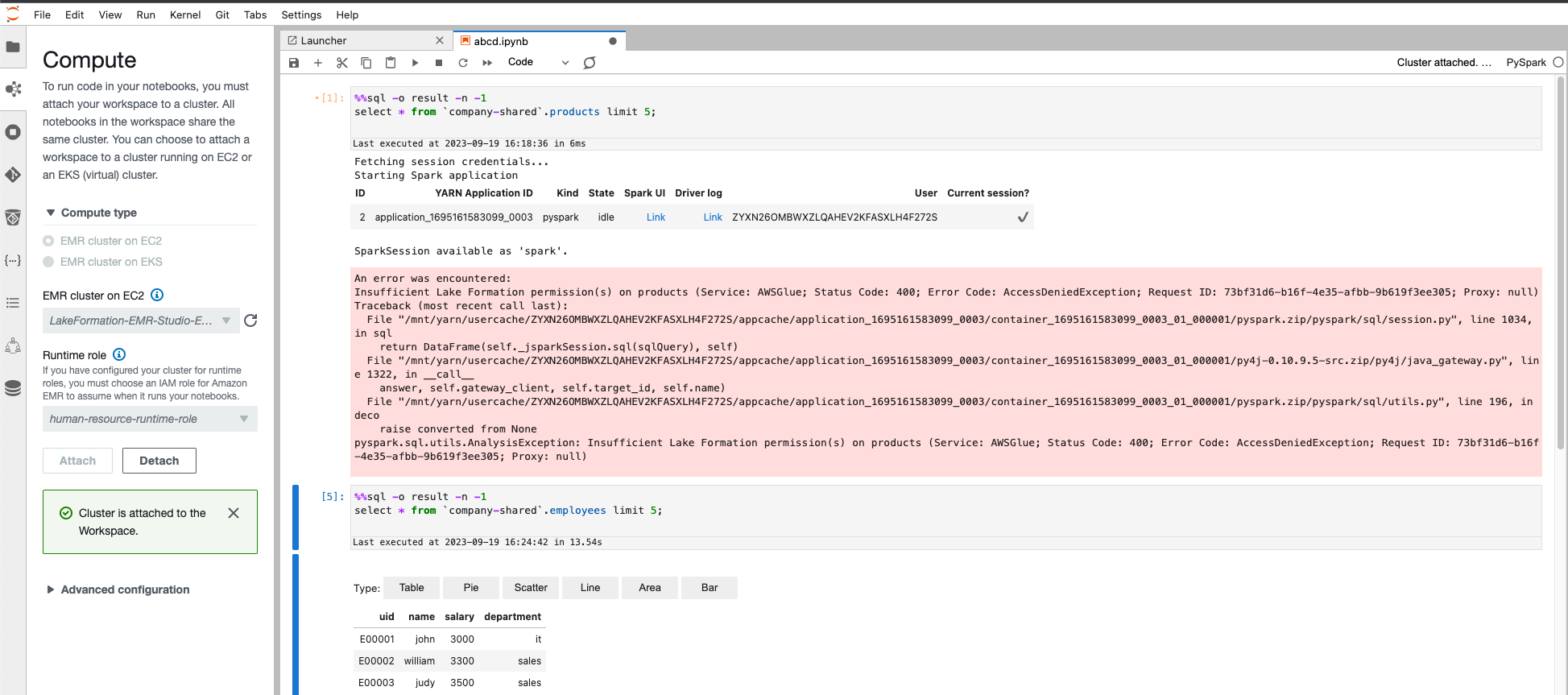
对于 Bob 来说,根据我们在 Lake Formation 中的数据访问配置,他将拥有对 Lake Formation 的完整数据访问权限 employees 表,但他无权访问 products 表。
清理
当您完成此解决方案的试验后,请清理您的资源:
- 停止并删除在数据使用者 AWS 账户中创建的 EMR Studio 工作区。
- 删除S3存储桶中的所有内容
EMRS3Bucket在数据消费者 AWS 账户中。 - 删除数据使用者 AWS 账户中的 CloudFormation 堆栈。
- 删除S3存储桶中的所有内容
DataLakeS3Bucket在数据生产者 AWS 账户中。 - 删除数据生产者 AWS 账户中的 CloudFormation 堆栈。
结论
本文展示了如何使用运行时角色通过 Amazon EMR 连接到 EMR Studio 工作区,以通过 Lake Formation 应用跨账户细粒度数据访问控制。 我们还演示了多个 EMR Studio 用户如何连接到同一个 EMR 集群,每个用户都使用一个运行时角色,其权限范围与其各自的数据访问级别相匹配。
要了解有关将 EMR Studio 工作区与 Lake Formation 结合使用的更多信息,请参阅 使用运行时角色运行 EMR Studio 工作区。 我们鼓励您尝试此新功能,如果您有任何问题或反馈,请与我们联系!
作者简介
 阿什莉·周 是 AWS 的软件开发工程师。 她对数据分析和分布式系统感兴趣。
阿什莉·周 是 AWS 的软件开发工程师。 她对数据分析和分布式系统感兴趣。
 斯里维迪亚·帕塔萨拉蒂 是 AWS Lake Formation 团队的高级大数据架构师。 她喜欢在 AWS 上构建分析和数据网格解决方案并与社区分享。
斯里维迪亚·帕塔萨拉蒂 是 AWS Lake Formation 团队的高级大数据架构师。 她喜欢在 AWS 上构建分析和数据网格解决方案并与社区分享。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/use-iam-runtime-roles-with-amazon-emr-studio-workspaces-and-aws-lake-formation-for-cross-account-fine-grained-access-control/
- :具有
- :是
- :不是
- $UP
- 100
- 107
- 11
- 20
- 7
- 8
- a
- Able
- 关于
- 接受
- ACCESS
- 访问数据
- 访问
- 无障碍
- 根据
- 账号管理
- 账户
- 横过
- 后
- 爱丽丝
- 所有类型
- 让
- 允许
- 允许
- 已经
- 还
- Amazon
- Amazon EC2
- 亚马逊电子病历
- 亚马逊网络服务
- an
- 分析
- 分析
- 和
- 任何
- 阿帕奇
- Apache Spark
- 应用领域
- 应用领域
- 使用
- 架构
- 保健
- AS
- At
- 连接
- 授权
- 自动
- AWS
- AWS CloudFormation
- AWS胶水
- AWS湖形成
- BE
- 因为
- 属于
- 之间
- 大
- 大数据运用
- 粮食
- 都
- 浏览器
- 浏览器
- 建筑物
- 但是
- by
- CAN
- 捕获
- 检索目录
- 产品类别
- CD
- 证书
- 更改
- 查
- 选择
- 清洁
- 簇
- 码
- 列
- 社体的一部分
- 公司
- 公司的
- 完成
- 完成
- 计算
- 配置
- 分享链接
- 所连接
- 考虑
- 由
- 安慰
- 消费者
- 包含
- 内容
- 控制
- 创建信息图
- 创建
- 创造
- 资历
- 电流
- data
- 数据访问
- 数据分析
- 数据分析
- 数据湖
- 数据科学
- 数据科学家
- 数据共享
- 数据库
- 数据库
- 默认
- 定义
- 演示
- 证明
- 问题类型
- 部署
- 描述
- 描述
- 开发
- 研发支持
- 差异
- 不同
- 直接
- 分布
- 分布式系统
- do
- 不会
- 别
- 向下
- 每
- 员工
- 员工
- enable
- 使
- 鼓励
- 加密
- 执行
- 发动机
- 工程师
- 工程师
- 工程师
- 引擎
- 输入
- 企业
- 环境
- 醚(ETH)
- 例子
- 除
- 说明
- 外部
- 文件
- 档
- 过滤
- 姓氏:
- 以下
- 如下
- 针对
- 训练
- 止
- ,
- 充分
- 功能
- 特定
- Go
- 统治
- 授予
- 授予
- 团队
- 民政事务总署
- 快乐
- 有
- he
- 帮助
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- 人
- 人力资源
- 人力资源
- IAM
- ID
- 身分
- if
- 说明
- 实施
- in
- 包括
- 包含
- 个人
- 信息
- 基础设施
- 例
- 说明
- 集成
- 积分
- 有兴趣
- 介绍
- 请帖
- IT
- 工作机会
- JPG
- 标签
- 湖泊
- 湖泊
- 大
- 大企业
- 发射
- 学习用品
- Level
- 极限
- 友情链接
- 链接
- 本地
- 圖書分館的位置
- 地点
- 机
- 使
- 制作
- 管理
- 管理
- 颠覆性技术
- 管理
- 许多
- 匹配
- 机制
- 菜单
- 网格
- 可能
- 更多
- 移动
- 多
- 必须
- 姓名
- 命名
- 导航
- 旅游导航
- 必要
- 需求
- 打印车票
- 全新
- 下页
- 没有
- 笔记本
- 笔记本电脑
- 现在
- 对象
- of
- 经常
- on
- 仅由
- 打开
- 操作
- or
- 其他名称
- 我们的
- 输出
- 产量
- 业主
- 面包
- 径
- 有待
- 允许
- 权限
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 政策
- 帖子
- 功率
- 先决条件
- 以前
- 校长
- 校长
- 原理
- 原则
- 制片人
- 产品
- 核心产品
- 本人简介
- 简介
- 提供
- 提供
- 提供
- 目的
- 蟒蛇
- 查询
- 有疑问吗?
- R
- 内存
- 原
- 原始数据
- 准备
- 减少
- 参考
- 地区
- 寄存器
- 在相关机构注册的
- 注册
- 释放
- 请求
- 资源
- 资源
- 导致
- 成果
- 角色
- 角色
- 运行
- 运行
- 薪水
- 销售
- 同
- 斯卡拉
- 科学
- 科学家
- 科学家
- 脚本
- 部分
- 部分
- 看到
- 选
- 前辈
- 分开
- 服务器
- 特色服务
- 会议
- 集
- 设置
- 设置
- 格局
- Share
- 共用的,
- 分享
- 共享
- 她
- 应该
- 显示
- 签署
- 签
- 签约
- 简易
- 单
- 软件
- 软件开发
- 出售
- 方案,
- 解决方案
- 来源
- 火花
- 堆
- 步
- 步骤
- 存储
- 商店
- 存储
- 商店
- 简单的
- 工作室
- 提交
- 这样
- 供应
- 支持
- 产品
- 表
- 行李牌
- 团队
- 模板
- 临时
- test
- 这
- 其
- 他们
- 然后
- 因此
- Free Introduction
- 那些
- 通过
- 时间表
- 至
- 工具
- 过境
- 尝试
- 二
- 类型
- 一般
- ui
- 下
- 相关
- 上传
- 网址
- us
- 使用
- 用过的
- 用户
- 用户
- 使用
- 运用
- 折扣值
- 确认
- 版本
- 通过
- 查看
- 想像
- 走
- we
- 卷筒纸
- 网页浏览器
- Web服务
- 为
- ,尤其是
- 这
- 全
- 将
- 中
- 加工
- 将
- 写
- 书面
- 雅姆
- 您
- 您一站式解决方案
- 和风网
- 压缩