图片由 杰康普 on Freepik
时间序列是数据科学领域内独一无二的数据集。 数据按时间-频率(例如每天、每周、每月等)记录,并且每个观察值都相互关联。 当您想要分析数据随时间发生的变化并创建未来预测时,时间序列数据很有价值。
时间序列预测是一种基于历史时间序列数据来创建未来预测的方法。 时间序列预测的统计方法有很多,例如 有马 or 指数平滑.
业务中经常会遇到时间序列预测,因此了解如何开发时间序列模型对数据科学家大有裨益。 在本文中,我们将学习如何使用两个流行的预测 Python 包来预测时间序列; 统计模型和先知。 让我们开始吧。
统计模型 Python包是一个开源包,提供各种统计模型,包括时间序列预测模型。 让我们使用示例数据集试用该包。 本文将使用 数字货币时间序列 来自 Kaggle 的数据(CC0:公共领域)。
让我们清理数据并查看我们拥有的数据集。
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
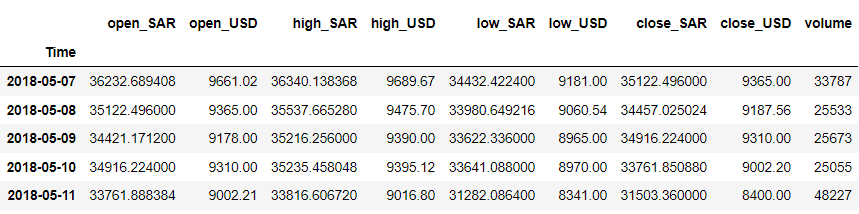
对于我们的示例,假设我们要预测“close_USD”变量。 让我们看看数据如何随时间变化。
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
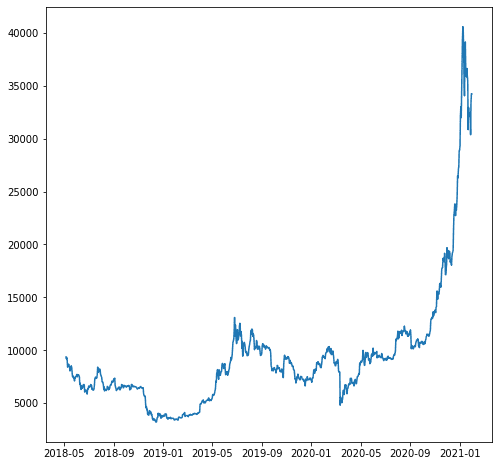
让我们根据上述数据构建预测模型。 在建模之前,让我们将数据分成训练数据和测试数据。
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
我们不会随机拆分数据,因为它是时间序列数据,我们需要保留顺序。 相反,我们尝试使用较早的训练数据和最新数据的测试数据。
让我们使用 statsmodels 创建一个预测模型。 这 统计模型 提供了许多时间序列模型 API,但我们将使用 ARIMA 模型作为示例。
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
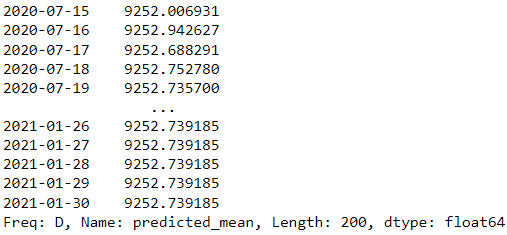
在我们上面的示例中,我们使用来自 statsmodels 的 ARIMA 模型作为预测模型并尝试预测接下来的 200 天。
模型结果好吗? 让我们尝试评估它们。 时间序列模型评估通常使用可视化图表将实际和预测与回归指标(如平均绝对误差 (MAE)、均方根误差 (RMSE) 和 MAPE(平均绝对百分比误差))进行比较。
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
上面的分数看起来不错,但让我们看看当我们将它们形象化时它是怎样的。
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
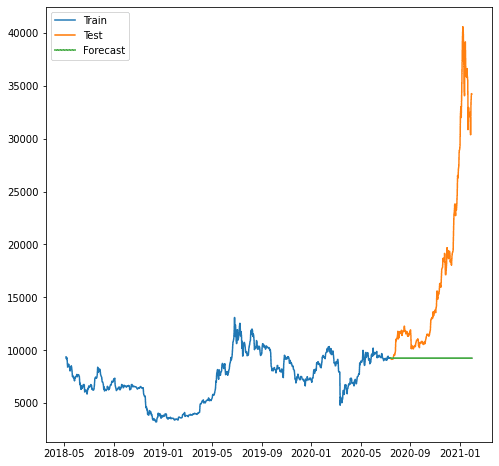
正如我们所见,由于我们的模型无法预测增长趋势,因此预测更糟。 我们使用的模型 ARIMA 对于预测来说似乎太简单了。
如果我们尝试使用 statsmodels 之外的其他模型,也许会更好。 让我们试试来自 Facebook 的著名先知包。
先知 是一个时间序列预测模型包,最适用于具有季节性影响的数据。 Prophet 也被认为是一个强大的预测模型,因为它可以处理缺失数据和异常值。
让我们试试 Prophet 包。 首先,我们需要安装包。
pip install prophet
之后,我们必须为预测模型训练准备数据集。 Prophet 有一个特定的要求:时间列需要命名为“ds”,值命名为“y”。
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
准备好数据后,让我们尝试根据数据创建预测预测。
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
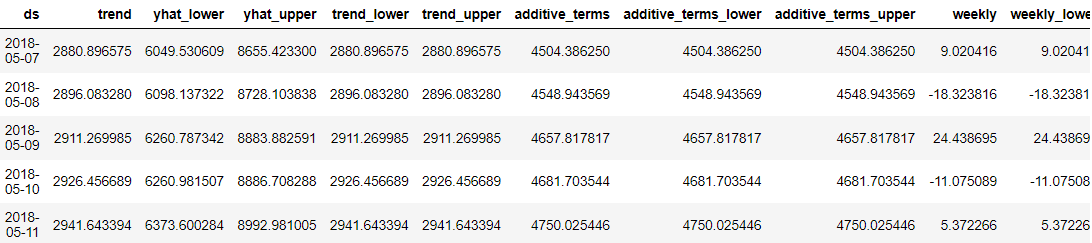
Prophet 的优点在于,每个预测数据点都非常详细,便于我们用户理解。 然而,仅从数据中很难理解结果。 因此,我们可以尝试使用 Prophet 将它们可视化。
model.plot(predictions)
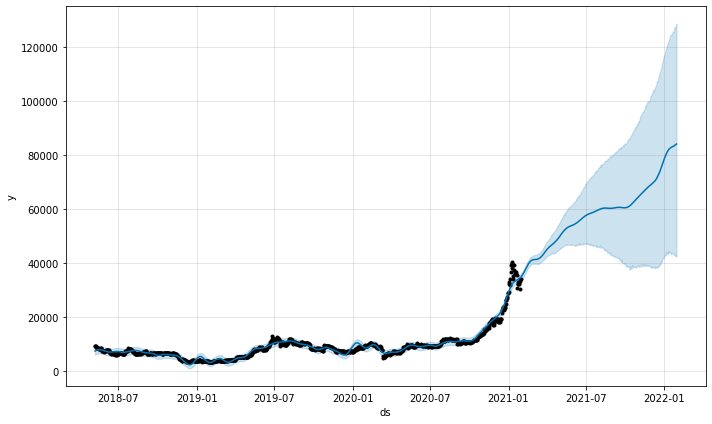
模型的预测图函数将为我们提供预测的置信度。 从上图中,我们可以看到预测有上升趋势,但随着不确定性的增加,预测时间越长。
也可以使用以下函数检查预测组件。
model.plot_components(predictions)
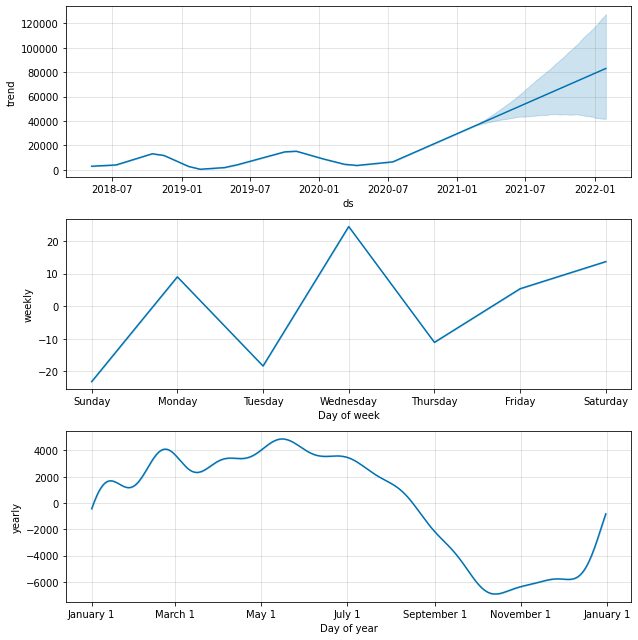
默认情况下,我们将获取具有年度和每周季节性的数据趋势。 这是解释我们的数据发生了什么的好方法。
是否也可以评估 Prophet 模型? 绝对地。 Prophet 包括一个我们可以使用的诊断测量: 时间序列交叉验证. 该方法使用部分历史数据,每次使用直到截止点的数据来拟合模型。 然后先知会将预测与实际进行比较。 让我们尝试使用代码。
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
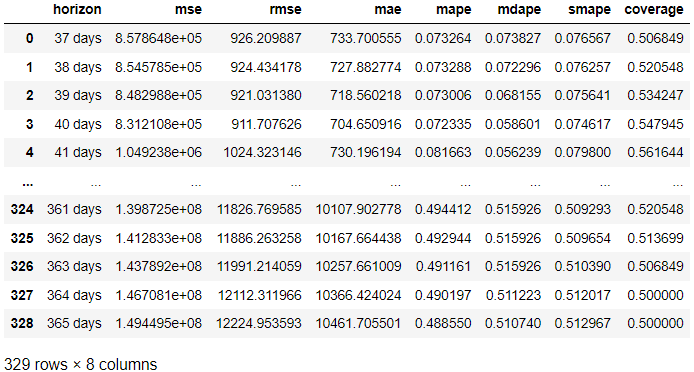
在上面的结果中,我们从每个预测日的实际结果与预测的比较中获得了评估结果。 也可以使用以下代码可视化结果。
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
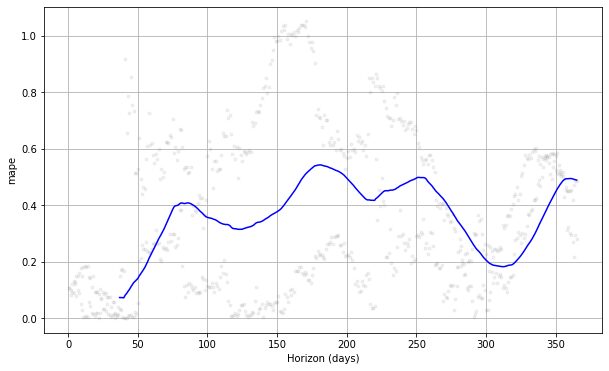
如果我们看到上面的图,我们可以看到预测误差随着时间的推移而变化,并且在某些时候可能达到 50% 的误差。 这样,我们可能希望进一步调整模型以修复错误。 你可以检查 文件 以供进一步探索。
预测是业务中发生的常见情况之一。 开发预测模型的一种简单方法是使用 statsforecast 和 Prophet Python 包。 在本文中,我们将学习如何创建预测模型并使用 statsforecast 和 Prophet 对其进行评估。
科尼利厄斯·尤达·维贾亚 是一名数据科学助理经理和数据作家。 在 Allianz Indonesia 全职工作期间,他喜欢通过社交媒体和写作媒体分享 Python 和数据技巧。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :是
- $UP
- 1
- 11
- 7
- 8
- 9
- a
- 关于
- 以上
- 绝对
- 绝对
- 后天
- 安联
- 分析
- 和
- 另一个
- APIs
- 保健
- 刊文
- AS
- 助理
- At
- 基于
- BE
- 因为
- before
- 有利
- 最佳
- 更好
- 之间
- 建立
- 商业
- by
- 计算
- CAN
- 例
- CC0
- 查
- 码
- 柱
- 列
- 相当常见
- 比较
- 相比
- 组件
- 信心
- 考虑
- 可以
- 覆盖
- 创建信息图
- 货币
- 每天
- data
- 数据科学
- 数据科学家
- 日期
- 天
- 一年中的
- dc
- 默认
- 详细
- 开发
- 域
- 别
- e
- 每
- 此前
- 影响
- 错误
- 等
- 评估
- 评估
- 所有的
- 例子
- 说明
- 勘探
- 著名
- 部分
- 结束
- 姓氏:
- 适合
- 固定
- 以下
- 针对
- 收益预测
- 止
- 功能
- 进一步
- 未来
- 得到
- GitHub上
- 非常好
- 图形
- 大
- 处理
- 发生
- 硬
- 有
- 历史的
- 地平线
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- 进口
- in
- 包括
- 包含
- 增加
- 增加
- 指数
- 印度尼西亚
- 初始
- 安装
- 代替
- IT
- JPG
- 掘金队
- 知道
- 最新
- 学习用品
- 不再
- 看
- LOOKS
- 使
- 经理
- 许多
- matplotlib
- 媒体
- 方法
- 方法
- 指标
- 可能
- 失踪
- 模型
- 造型
- 模型
- 每月一次
- 命名
- 需求
- 需要
- 下页
- 麻木
- 获得
- of
- 提供
- on
- 一
- 开放源码
- 秩序
- 其他名称
- 学校以外
- 包
- 包
- 大熊猫
- 参数
- 部分
- 模式
- 百分比
- 演出
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 点
- 热门
- 可能
- 预测
- 预测
- 预测
- Prepare
- 提供
- 提供
- 国家
- 蟒蛇
- 准备
- 记录
- 回归
- 有关
- 需求
- 导致
- 成果
- 健壮
- 根
- 科学
- 科学家
- 似乎
- 系列
- 集
- Share
- 简易
- So
- 社会
- 社会化媒体
- 一些
- 具体的
- 分裂
- 广场
- 统计
- 这样
- 采取
- test
- 这
- 他们
- 次
- 时间序列
- 秘诀
- 至
- 也有
- 培训
- 产品培训
- 趋势
- 不确定
- 理解
- 独特
- 无名
- 向上
- us
- 使用
- 用户
- 平时
- 有价值
- 折扣值
- 各个
- 通过
- 可视化
- 方法..
- 每周
- 井
- 什么是
- 而
- 维基百科上的数据
- 将
- 中
- 加工
- 合作
- 将
- 作家
- 写作
- 您一站式解决方案
- 和风网