我最近与 Stelios Diamantidis(杰出架构师,自主设计解决方案战略主管)谈到了 Synopsys 在 100 上的公告th 客户流片使用他们的 DSO.ai 解决方案。 我对 AI 相关文章的关注是避免围绕 AI 的一般炒作,相反,对这种炒作的怀疑促使一些人将所有 AI 声明视为万金油。 我很高兴听到 Stelios 大笑并全心全意地同意。 我们就 DSO.ai 今天可以做什么、他们的参考客户在解决方案中看到了什么(基于它今天可以做什么)以及他可以告诉我有关该技术的内容进行了非常深入的讨论。
DSO.ai 做什么
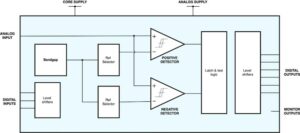
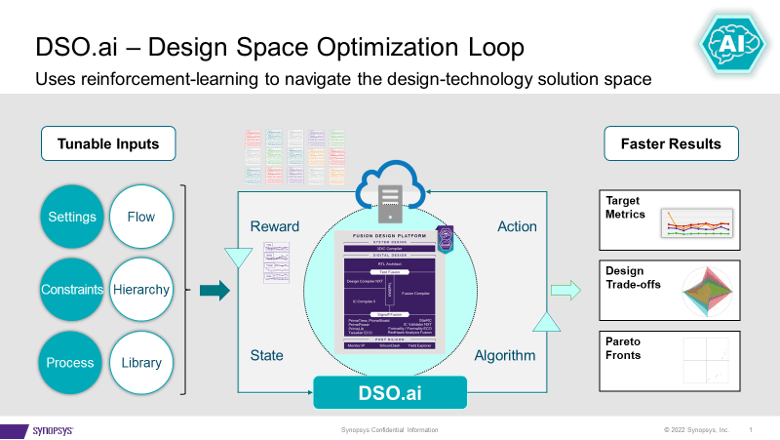
DSO.ai 与 Fusion Compiler 和 IC Compiler II 相结合,正如 Stelios 小心强调的那样,这意味着这是一个块级优化解决方案; 完整的 SoC 还不是目标。 这符合当前的设计实践,正如 Stelios 所说的一个重要目标是轻松融入现有流程。 该技术的目的是使实施工程师(通常是单个工程师)能够提高他们的工作效率,同时探索更大的设计空间以获得比其他方式可能发现的更好的 PPA。
Synopsys 于 2021 年夏季宣布首次流片,目前已宣布 100 次流片。 这很好地说明了对此类解决方案的需求和有效性。 Stelios 补充说,对于必须多次实例化一个块的应用程序,其价值变得更加明显。 想想多核服务器、GPU 或网络交换机。 一次优化块,多次实例化——这可以显着改进 PPA。
我问这样做的客户是否都在 7nm 及以下工作。 令人惊讶的是,一直到 40nm 都有积极使用。 一个有趣的例子是闪存控制器,这是一种对性能不是很敏感但可以运行到数千万到数亿个单元的设计。 在这里,即使将尺寸缩小 5%,也会对利润率产生重大影响。
内幕是什么
DSO.ai 基于强化学习,这是最近的热门话题,但我保证不会在本文中大肆宣传。 我要求斯泰利奥斯再深入一点,但当他说他不能透露太多时,我并不感到惊讶。 他能告诉我的就足够有趣了。 他指出,在更一般的应用中,通过训练集(一个时期)的一个循环假设一种快速(几秒到几分钟)的方法来评估下一步可能的步骤,例如通过梯度比较。
但严重的块设计无法通过快速估算进行优化。 每个试验都必须贯穿整个生产流程,映射到真实的制造过程。 可能需要数小时才能运行的流程。 鉴于此约束,有效强化学习的部分策略是并行性。 剩下的就是 DSO.ai 的秘方。 当然,您可以想象,如果秘方能够根据给定的时代提出有效的改进,那么并行性将加速下一个时代的进步。
为此,此功能确实必须在云中运行以支持并行性。 私有本地云是一种选择。 微软宣布他们将在 Azure 上托管 DSO.ai,并且 ST 在 DSO.ai 新闻稿中报告说他们使用此功能来优化 Arm 核心的实施。 我想如果减少面积是值得的话,可能会围绕在公共云中跨 1000 台服务器运行优化的利弊展开一些有趣的辩论。
客户的反馈意见
Synopsys 声称客户(包括本公告中的 ST 和 SK Hynix)报告说生产力提高了 3 倍以上,总功耗降低了 25%,芯片尺寸显着减小,所有这些都减少了整体资源的使用。 鉴于 Stelios 的描述,这对我来说听起来很合理。 该工具允许在给定的时间表内探索设计状态空间中的更多点,而不是手动探索。 只要搜索算法(秘诀)有效,当然会找到比手动搜索更好的最优解。
简而言之,既不是 AI 炒作也不是万金油。 DSO.ai 建议人工智能作为现有流程的可靠工程扩展进入主流。 您可以从 新闻稿 从 本博客.
通过以下方式分享此帖子:
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://semiwiki.com/artificial-intelligence/324430-synopsys-design-space-optimization-hits-a-milestone/
- 100
- 2021
- a
- 关于
- 加快
- 横过
- 要积极。
- 添加
- AI
- 算法
- 所有类型
- 允许
- 和
- 公布
- 公告
- 应用领域
- 国家 / 地区
- ARM
- 围绕
- 刊文
- 刊文
- 自主性
- 避免
- Azure
- 基于
- 成为
- 如下。
- 更好
- 大
- 位
- 阻止
- 小心
- 当然
- 索赔
- 云端技术
- 如何
- 关心
- 缺点
- 调节器
- 核心
- 可以
- 课程
- 可信的
- 电流
- 顾客
- 合作伙伴
- 周期
- 一年中的
- 辩论
- 需求
- 描述
- 设计
- 死
- 讨论
- 解除此信息
- 杰出的
- 做
- 向下
- 每
- 容易
- 有效
- 效用
- 强调
- enable
- 工程师
- 工程师
- 工程师
- 更多
- 时代
- 估计
- 甚至
- 例子
- 现有
- 勘探
- 探索
- 延期
- 高效率
- 找到最适合您的地方
- 姓氏:
- 适合
- Flash
- 流
- 流动
- 止
- ,
- 聚变
- 其他咨询
- 特定
- 目标
- GPU
- 快乐
- 头
- 此处
- 点击
- 托管
- 热卖
- HOURS
- HTTPS
- 炒作
- 影响力故事
- 履行
- 重要
- 改善
- 改进
- in
- 包含
- 增加
- 有趣
- IT
- 大
- 笑
- 学习用品
- 学习
- 长
- 制成
- 主流
- 手册
- 制造业
- 许多
- 制图
- 利润率
- 最大宽度
- 手段
- 方法
- 微软
- 可能
- 里程碑
- 百万
- 分钟
- 更多
- 也不
- 网络
- 下页
- 明显
- 油
- 一
- 优化
- 优化
- 优化
- 最佳
- 附加选项
- 除此以外
- 最划算
- 部分
- 性能
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 点
- 点
- 可能
- 帖子
- 功率
- 做法
- express
- 新闻报道
- 私立
- 过程
- 生产
- 生产率
- 进展
- 许诺
- PROS
- 国家
- 公共云
- 目的
- 快速
- 反应
- 真实
- 合理
- 最近
- 减少
- 减少
- 强化学习
- 释放
- 报告
- 报告
- 资源
- REST的
- 揭示
- 运行
- 运行
- 说
- 始你
- 搜索
- 秒
- 秘密
- 敏感
- 严重
- 集
- 短
- 显著
- 单
- 尺寸
- 怀疑论
- 方案,
- 解决方案
- 一些
- 太空
- 说
- 州/领地
- 步骤
- 策略
- 提示
- 夏季
- SUPPORT
- 感到惊讶
- Switch 开关
- 采取
- 目标
- 专业技术
- 区域
- 其
- 通过
- 时
- 至
- 今晚
- 也有
- 工具
- 主题
- 合计
- 产品培训
- 试用
- 下
- 单位
- 使用
- 折扣值
- 通过
- 什么是
- 这
- 而
- 将
- 中
- 加工
- 价值
- 将
- 和风网