基于深度强化学习 (DRL) 的新创建的人工智能 (AI) 系统可以在模拟环境中对攻击者做出反应,并在网络攻击升级之前阻止 95%。
这是根据能源部太平洋西北国家实验室的研究人员的说法,他们对网络中攻击者和防御者之间的数字冲突进行了抽象模拟,并训练了四种不同的 DRL 神经网络,以在防止妥协和最大限度地减少网络中断的基础上最大化奖励。
模拟攻击者使用了一系列基于 斜接 框架的分类从最初的访问和侦察阶段转移到其他攻击阶段,直到他们达到他们的目标:影响和渗透阶段。
AI 系统在简化的攻击环境中的成功训练表明,AI 模型可以实时处理对攻击的防御响应,数据科学家 Samrat Chatterjee 说,他在该协会年会上介绍了该团队的工作14 月 XNUMX 日在华盛顿特区推进人工智能。
“如果你甚至不能展示这些技术的前景,你就不想进入更复杂的架构,”他说。 “在继续前进之前,我们想首先证明我们实际上可以成功地训练 DRL 并展示一些良好的测试结果。”
从早期将机器学习集成到电子邮件安全网关中,将机器学习和人工智能技术应用于网络安全的不同领域已成为过去十年的热门趋势 在早期的2010中 最近的努力 使用 ChatGPT 分析代码 或进行取证分析。 现在, 大多数安全产品都有 - 或者声称拥有 - 一些由在大型数据集上训练的机器学习算法提供支持的功能。
然而,创建一个能够主动防御的人工智能系统仍然是一种理想,而不是实际的。 尽管研究人员仍面临各种障碍,但 PNNL 的研究表明,人工智能防御者在未来是可能的。
“评估在不同对抗设置下训练的多个 DRL 算法是迈向实用自主网络防御解决方案的重要一步,”PNNL 研究团队 在他们的论文中说. “我们的实验表明,无模型 DRL 算法可以在具有不同技能和持久性水平的多阶段攻击配置文件下进行有效训练,在有争议的环境中产生有利的防御结果。”
系统如何使用 MITRE ATT&CK
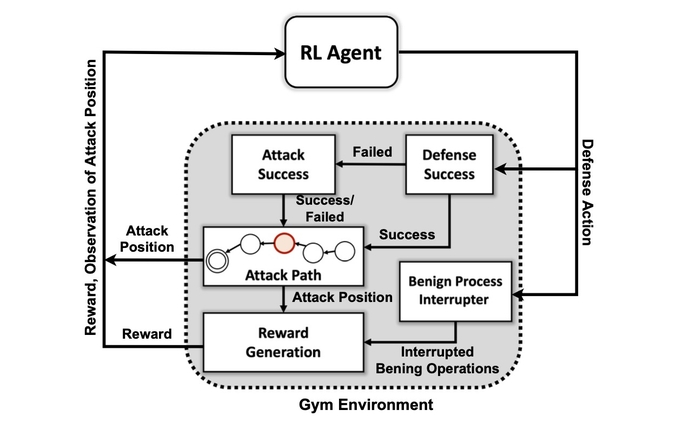
研究团队的第一个目标是创建一个基于开源工具包的自定义模拟环境,称为 打开人工智能健身房. 使用该环境,研究人员创建了具有不同技能和持久性级别的攻击者实体,能够使用 MITRE ATT&CK 框架中的 7 种策略和 15 种技术的子集。
攻击者代理的目标是通过攻击链的七个步骤,从初始访问到执行,从持久性到命令和控制,从收集到影响。
PNNL 的 Chatterjee 说,对于攻击者而言,根据环境状况和防御者当前的行动调整他们的策略可能很复杂。
“对手必须从最初的侦察状态一路导航到某种渗透或影响状态,”他说。 “我们并没有试图创建一种模型来阻止对手进入环境——我们假设系统已经受到威胁。”
研究人员使用了四种基于强化学习的神经网络方法。 强化学习 (RL) 是一种模拟人脑奖励系统的机器学习方法。 神经网络通过加强或削弱单个神经元的某些参数来学习,以奖励更好的解决方案,这是通过表明系统性能如何的分数来衡量的。
PNNL 研究员兼该论文的作者 Mahantesh Halappanavar 说,强化学习本质上允许计算机创建一个好的但不是完美的方法来解决手头的问题。
“如果不使用任何强化学习,我们仍然可以做到,但这将是一个非常大的问题,没有足够的时间来真正提出任何好的机制,”他说。 “我们的研究……为我们提供了一种机制,在这种机制中,深度强化学习在某种程度上模仿了人类的某些行为本身,并且它可以非常有效地探索这个非常广阔的空间。”
还没准备好迎接黄金时段
实验发现,一种称为深度 Q 网络的特定强化学习方法为防御问题创建了一个强有力的解决方案, 捕获 97% 的攻击者 在测试数据集中。 然而,这项研究仅仅是个开始。 安全专业人员不应该很快寻找 AI 伴侣来帮助他们进行事件响应和取证。
在仍有待解决的众多问题中,有一个是让强化学习和深度神经网络来解释影响他们决策的因素,这个研究领域称为可解释强化学习 (XRL)。
此外,PNNL 的 Chatterjee 表示,人工智能算法的稳健性和寻找训练神经网络的有效方法都是需要解决的问题。
“创造一种产品——这不是这项研究的主要动机,”他说。 “这更多是关于科学实验和算法发现。”
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- 对,能力--
- 关于
- 摘要
- ACCESS
- 根据
- 行动
- 通
- 增加
- 进步
- 对抗
- 中介代理
- AI
- AI供电
- 算法
- 算法
- 所有类型
- 允许
- 已经
- 分析
- 分析
- 和
- 全年
- 应用领域
- 的途径
- 方法
- 国家 / 地区
- 人造的
- 人工智能
- 人工智能(AI)
- 社区
- 攻击
- 攻击
- 作者
- 自主性
- 基于
- 成为
- before
- 更好
- 之间
- 大
- 阻止
- 大脑
- 建
- 被称为
- 不能
- 能力
- 一定
- 链
- ChatGPT
- 要求
- 分类
- 采集
- 如何
- 复杂
- 妥协
- 一台
- 进行
- 冲突
- 继续
- 控制
- 可以
- 创建信息图
- 创建
- 创造
- 电流
- 习俗
- 网络
- 网络攻击
- 网络安全
- data
- 数据科学家
- 数据集
- 数据集
- dc
- 十
- 决定
- 决定
- 深
- 深度神经网络
- 捍卫者
- 国防
- 防卫
- 演示
- 演示
- 问题类型
- 能源部
- 不同
- 数字
- 发现
- 瓦解
- 不同
- 美国能源部
- 早
- 只
- 高效
- 有效
- 工作的影响。
- 邮箱地址
- 电子邮件安全
- 能源
- 更多
- 实体
- 环境
- 本质上
- 醚(ETH)
- 评估
- 甚至
- 执行
- 渗出
- 说明
- 探索
- 因素
- 特征
- 少数
- 字段
- 寻找
- (名字)
- 流
- 法医
- 取证
- 向前
- 发现
- 骨架
- 止
- 未来
- 得到
- 越来越
- 给
- 目标
- 理想中
- 非常好
- 手
- 帮助
- 热卖
- 创新中心
- HTTPS
- 人
- 跨栏
- 影响力故事
- 重要
- in
- 事件
- 事件响应
- 说明
- 个人
- 影响
- 初始
- 积分
- 房源搜索
- IT
- 本身
- 类
- 已知
- 实验室
- 大
- 学习
- 各级
- 看
- 机
- 机器学习
- 主要
- 许多
- 最大宽度
- 生产力
- 机制
- 会议
- 方法
- 最小化
- 模型
- 更多
- 动机
- 移动
- 移动
- 多
- National
- 导航
- 需求
- 网络
- 网络
- 神经
- 神经网络
- 神经网络
- 神经元
- 打开
- 开放源码
- 其他名称
- 太平洋
- 纸类
- 参数
- 过去
- 施行
- 坚持
- 相
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 可能
- 供电
- 实用
- 呈现
- 预防
- 总理
- 主动
- 市场问题
- 问题
- 核心产品
- 专业人士
- 简介
- 承诺
- RE
- 达到
- 应对
- 反应
- 准备
- 真实
- 实时的
- 最近
- 强化学习
- 留
- 研究
- 研究员
- 研究人员
- 响应
- 积分
- 奖励
- 稳健性
- 说
- 科学家
- 保安
- 系列
- 集
- 设置
- XNUMX所
- 应该
- 显示
- 作品
- 简
- 模拟
- 技能
- 方案,
- 解决方案
- 一些
- 不久
- 来源
- 太空
- 具体的
- 开始
- 州/领地
- 步
- 步骤
- 仍
- Stop 停止
- 强化
- 强烈
- 成功
- 顺利
- 系统
- 策略
- 团队
- 技术
- 测试
- 未来
- 国家
- 其
- 通过
- 次
- 至
- 工具箱
- 对于
- 培训
- 熟练
- 产品培训
- 趋势
- 下
- us
- 使用
- 各种
- 广阔
- 通缉
- 华盛顿
- 方法
- 而
- WHO
- 将
- 中
- 也完全不需要
- 工作
- 将
- 生产
- 和风网











