图片作者
作为软件开发人员,您可能听说过这句话 “过早的优化是万恶之源”——在你的职业生涯中不止一次。 虽然优化对于小型项目可能不是很有帮助(或绝对必要),但分析通常很有帮助。
完成模块编码后,最好对代码进行分析以测量每个部分执行所需的时间。 这可以帮助识别代码异味并指导优化以提高代码质量。 因此,在优化之前一定要分析您的代码!
为了迈出第一步,本指南将帮助您开始使用 Python 进行分析——使用内置的 时间 和 个人资料 模块。 您将学习如何使用命令行界面和 Python 脚本中的等效可调用函数。
timeit 模块是 Python 标准库的一部分,提供了一些方便的函数,可用于对短代码片段进行计时。
让我们举一个反转 Python 列表的简单示例。 我们将使用以下方法测量获取列表反向副本的执行时间:
- 此
reversed()功能,以及 - 列表切片。
>>> nums=[6,9,2,3,7]
>>> list(reversed(nums))
[7, 3, 2, 9, 6]
>>> nums[::-1]
[7, 3, 2, 9, 6]
在命令行运行 timeit
你可以跑 timeit 在命令行中使用以下语法:
$ python -m timeit -s 'setup-code' -n 'number' -r 'repeat' 'stmt'
您需要提供声明 stmt 其执行时间是要测量的。
您可以指定 setup 需要时编写代码 - 使用短选项 -s 或长选项 –setup。 设置代码将仅运行一次。
number 运行该语句的次数:短选项 -n 或长选项 –number 是可选的。 重复此循环的次数:短选项 -r 或长选项 –repeat 也是可选的。
让我们看看上面的示例的实际效果:
这里创建列表是 setup 代码和反转列表是要计时的语句:
$ python -m timeit -s 'nums=[6,9,2,3,7]' 'list(reversed(nums))'
500000 loops, best of 5: 695 nsec per loop
当您不指定值时 repeat,使用默认值 5。 当你不指定时 number,代码根据需要运行多次,以达到总时间 至少0.2秒.
此示例显式设置执行语句的次数:
$ python -m timeit -s 'nums=[6,9,2,3,7]' -n 100Bu000 'list(reversed(nums))'
100000 loops, best of 5: 540 nsec per loop
默认值为 repeat 是 5,但我们可以将其设置为任何合适的值:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' -r 3 'list(reversed(nums))'
500000 loops, best of 3: 663 nsec per loop
我们还对列表切片方法进行计时:
$ python3 -m timeit -s 'nums=[6,9,2,3,7]' 'nums[::-1]'
1000000 loops, best of 5: 142 nsec per loop
列表切片方法似乎更快(所有示例均在 Ubuntu 3.10 上的 Python 22.04 中)。
在 Python 脚本中运行 timeit
以下相当于在 Python 脚本中运行 timeit:
import timeit setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]' t1 = timeit.timeit(setup=setup,stmt=stmt1,number=number)
t2 = timeit.timeit(setup=setup,stmt=stmt2,number=number) print(f"Using reversed() fn.: {t1}")
print(f"Using list slicing: {t2}")
timeit() callable 返回执行时间 stmt number 次。 请注意,我们可以明确提及要运行的次数,或者使 number 取默认值 1000000。
Output >>
Using reversed() fn.: 0.08982690000000002
Using list slicing: 0.015550800000000004
这将针对指定的时间运行语句(而不重复计时器函数) number 次数并返回执行时间。 用起来也很普遍 time.repeat() 并取最短时间,如下所示:
import timeit setup = 'nums=[9,2,3,7,6]'
number = 100000
stmt1 = 'list(reversed(nums))'
stmt2 = 'nums[::-1]' t1 = min(timeit.repeat(setup=setup,stmt=stmt1,number=number))
t2 = min(timeit.repeat(setup=setup,stmt=stmt2,number=number)) print(f"Using reversed() fn.: {t1}")
print(f"Using list slicing: {t2}")
这将重复运行代码的过程 number 时间 repeat 次数并返回最小执行时间。 这里我们有 5 次重复,每次 100000 次。
Output >>
Using reversed() fn.: 0.055375300000000016
Using list slicing: 0.015101400000000043我们已经了解了如何使用 timeit 来测量短代码片段的执行时间。 然而,在实践中,分析整个 Python 脚本会更有帮助。
这将为我们提供所有函数和方法调用的执行时间,包括内置函数和方法。 因此我们可以更好地了解更昂贵的函数调用并确定优化机会。 例如:API 调用可能太慢。 或者一个函数可能有一个循环,可以用更 Pythonic 的理解表达式替换。
让我们学习如何使用 cProfile 模块(也是 Python 标准库的一部分)来分析 Python 脚本。
考虑以下 Python 脚本:
# main.py
import time def func(num): for i in range(num): print(i) def another_func(num): time.sleep(num) print(f"Slept for {num} seconds") def useful_func(nums, target): if target in nums: return nums.index(target) if __name__ == "__main__": func(1000) another_func(20) useful_func([2, 8, 12, 4], 12)
这里我们有三个函数:
func()循环遍历一系列数字并将其打印出来。another func()其中包含对sleep()功能。useful_func()返回列表中目标编号的索引(如果目标存在于列表中)。
每次运行 main.py 脚本时都会调用上面列出的函数。
在命令行运行 cProfile
使用以下命令在命令行运行 cProfile:
python3 -m file-name.py
这里我们将文件命名为 main.py:
python3 -m main.py
运行它应该会给出以下输出:
Output >> 0 ... 999 Slept for 20 seconds
以及以下简介:
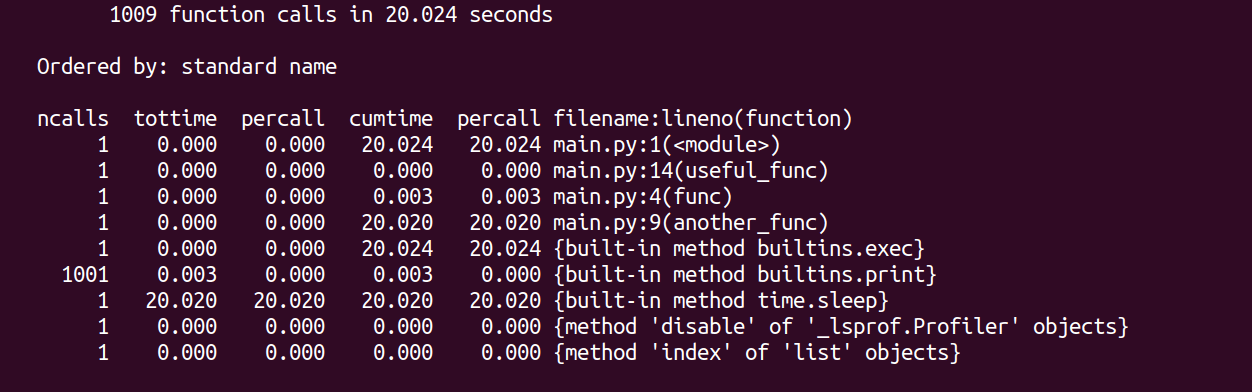
在这里, ncalls 指的是函数的调用次数, percall 指的是每个函数调用的时间。 如果值 ncalls 大于一,那么 percall 是所有调用的平均时间。
脚本的执行时间主要由 another_func 使用内置的 sleep 函数调用(休眠 20 秒)。 我们看到 print 函数调用也相当昂贵。
在 Python 脚本中使用 cProfile
虽然在命令行运行 cProfile 工作正常,但您还可以将分析功能添加到 Python 脚本中。 您可以将 cProfile 与 pstats模块 用于分析和访问统计数据。
作为更好地处理资源设置和拆卸的最佳实践,请使用 with 语句并创建一个用作上下文管理器的配置文件对象:
# main.py
import pstats
import time
import cProfile def func(num): for i in range(num): print(i) def another_func(num): time.sleep(num) print(f"Slept for {num} seconds") def useful_func(nums, target): if target in nums: return nums.index(target) if __name__ == "__main__": with cProfile.Profile() as profile: func(1000) another_func(20) useful_func([2, 8, 12, 4], 12) profile_result = pstats.Stats(profile) profile_result.print_stats()
让我们仔细看看生成的输出配置文件:
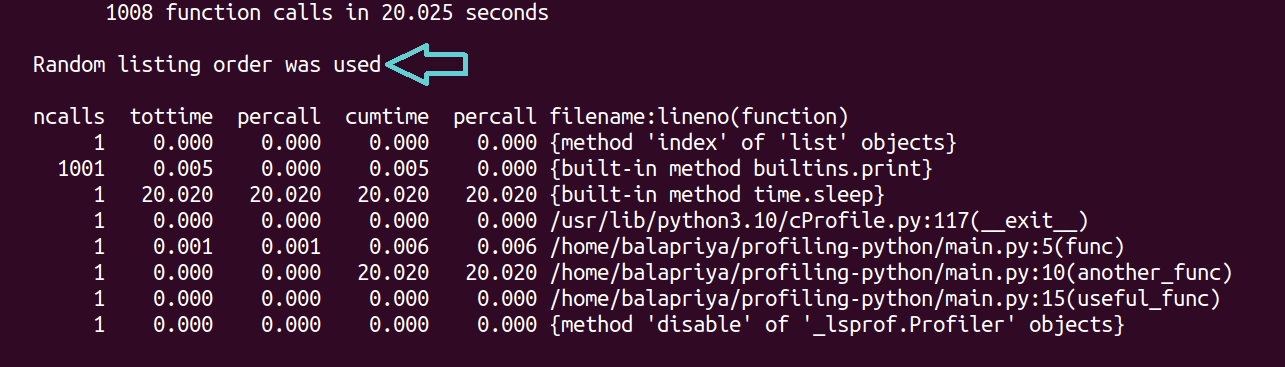
当您分析大型脚本时,这会很有帮助 按执行时间对结果进行排序。 为此,您可以致电 sort_stats 在配置文件对象上并根据执行时间排序:
...
if __name__ == "__main__": with cProfile.Profile() as profile: func(1000) another_func(20) useful_func([2, 8, 12, 4], 12) profile_result = pstats.Stats(profile) profile_result.sort_stats(pstats.SortKey.TIME) profile_result.print_stats()
现在运行脚本时,您应该能够看到按时间排序的结果:

我希望本指南可以帮助您开始使用 Python 进行分析。 永远记住,优化永远不应该以牺牲可读性为代价。 如果您有兴趣了解其他分析器,包括第三方 Python 包,请查看此内容 关于 Python 分析器的文章.
巴拉普里亚 C 是来自印度的开发人员和技术作家。 她喜欢在数学、编程、数据科学和内容创作的交叉领域工作。 她的兴趣和专长领域包括 DevOps、数据科学和自然语言处理。 她喜欢阅读、写作、编码和咖啡! 目前,她致力于通过编写教程、操作指南、评论文章等方式学习并与开发人员社区分享她的知识。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 汽车/电动汽车, 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- 图表Prime。 使用 ChartPrime 提升您的交易游戏。 访问这里。
- 块偏移量。 现代化环境抵消所有权。 访问这里。
- Sumber: https://www.kdnuggets.com/profiling-python-code-using-timeit-and-cprofile?utm_source=rss&utm_medium=rss&utm_campaign=profiling-python-code-using-timeit-and-cprofile
- :是
- :不是
- 10
- 100000
- 12
- 13
- 15%
- 17
- 19
- 20
- 22
- 7
- 8
- 9
- a
- Able
- 关于
- 以上
- 绝对
- 访问
- ACM
- 横过
- 操作
- 加
- 所有类型
- 还
- 时刻
- an
- 和
- 任何
- API
- 的途径
- 保健
- 地区
- AS
- At
- 创作
- 基于
- BE
- before
- 最佳
- 更好
- 都
- 内建的
- 但是
- by
- 呼叫
- 被称为
- 呼叫
- CAN
- 可以得到
- 寻找工作
- CFM
- 查
- 接近
- 码
- 编码
- 如何
- 相当常见
- 社体的一部分
- 包含
- 内容
- 内容创造
- 上下文
- 方便
- 价格
- 再加
- 创建信息图
- 创造
- 创建
- 目前
- 周期
- data
- 数据科学
- 默认
- 开发商
- DevOps的
- do
- 别
- 每
- 整个
- 例子
- 例子
- 执行
- 执行
- 昂贵
- 专门知识
- 表达
- 快
- 少数
- 文件
- 结束
- 姓氏:
- 第一步
- 以下
- 针对
- 止
- 功能
- 功能
- 功能
- 产生
- 得到
- 给
- 非常好
- 更大的
- 指南
- 指南
- 处理
- 有
- 听说
- 帮助
- 有帮助
- 帮助
- 这里
- 此处
- 抱有希望
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- i
- 主意
- 鉴定
- if
- 进口
- 改善
- in
- 包括
- 包含
- 指数
- 印度
- 内
- 兴趣
- 有兴趣
- 接口
- 路口
- IT
- 掘金队
- 知识
- 语言
- 大
- 学习用品
- 学习
- 最少
- 自学资料库
- 容易
- 喜欢
- Line
- 清单
- 长
- 看
- 主要
- 使
- 经理
- 许多
- 数学
- 可能..
- 衡量
- 测量
- 提到
- 方法
- 方法
- 可能
- 最低限度
- 模块
- 模块
- 更多
- 命名
- 自然
- 自然语言
- 自然语言处理
- 必要
- 打印车票
- 决不要
- 注意..
- 现在
- 数
- 数字
- 对象
- 获得
- of
- 优惠精选
- 经常
- on
- 一旦
- 一
- 仅由
- 检讨
- 机会
- 优化
- 附加选项
- or
- 其他名称
- 我们的
- 输出
- 产量
- 包
- 部分
- 为
- 件
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 在练习上
- 当下
- 打印
- 过程
- 处理
- 本人简介
- 剖析
- 代码编程
- 项目
- 提供
- 蟒蛇
- 质量
- 报价
- 范围
- 达到
- 阅读
- 指
- 纪念
- 重复
- 更换
- 必须
- 资源
- 成果
- 回报
- 回报
- 根
- 运行
- 运行
- 运行
- s
- 科学
- 脚本
- 脚本
- 秒
- 部分
- 看到
- 似乎
- 看到
- 集
- 套数
- 格局
- 共享
- 她
- 短
- 应该
- 如图
- 简易
- 放慢
- 小
- So
- 软件
- 指定
- 标准
- 开始
- 个人陈述
- 统计
- 步骤
- 合适的
- 超级
- 句法
- T1
- 采取
- 需要
- 目标
- 拆除
- 文案
- 比
- 这
- 他们
- 然后
- 那里。
- 第三方
- Free Introduction
- 三
- 通过
- 次
- 时控
- 时
- 至
- 也有
- 合计
- 教程
- Ubuntu
- us
- 使用
- 用过的
- 使用
- 运用
- 折扣值
- 价值观
- we
- ,尤其是
- 而
- 谁的
- 将
- 加工
- 合作
- 作家
- 写作
- 您
- 您一站式解决方案
- 和风网