赞助商后

从头开始构建多模式模型的挑战
对于许多机器学习用例,组织仅依赖表格数据和基于树的模型,例如 XGBoost 和 LightGBM。 这是因为深度学习对于大多数机器学习团队来说太难了。 常见的挑战包括:
- 缺乏开发复杂深度学习模型所需的专业知识
- PyTorch 和 Tensorflow 等框架要求团队编写数千行代码,这些代码很容易出现人为错误
- 训练分布式深度学习管道需要深入了解基础设施,并且可能需要数周时间来训练模型
因此,团队会错过隐藏在文本和图像等非结构化数据中的有价值的信号。
使用声明性系统进行快速模型开发
新的声明式机器学习系统(例如 Uber 推出的开源 Ludwig)提供了一种低代码方法来实现 ML 自动化,使数据团队能够通过简单的配置文件更快地构建和部署最先进的模型。 具体来说,Predibase(领先的低代码声明式 ML 平台)和 Ludwig 一起可以轻松地用 < 15 行代码构建多模式深度学习模型。
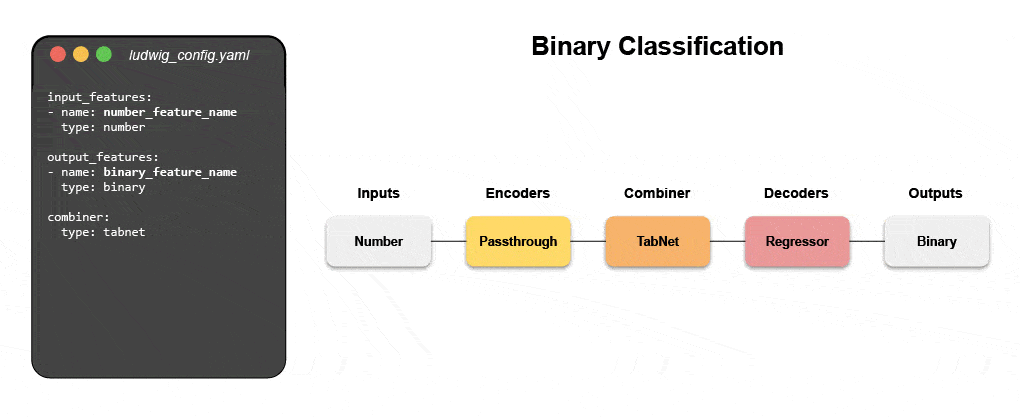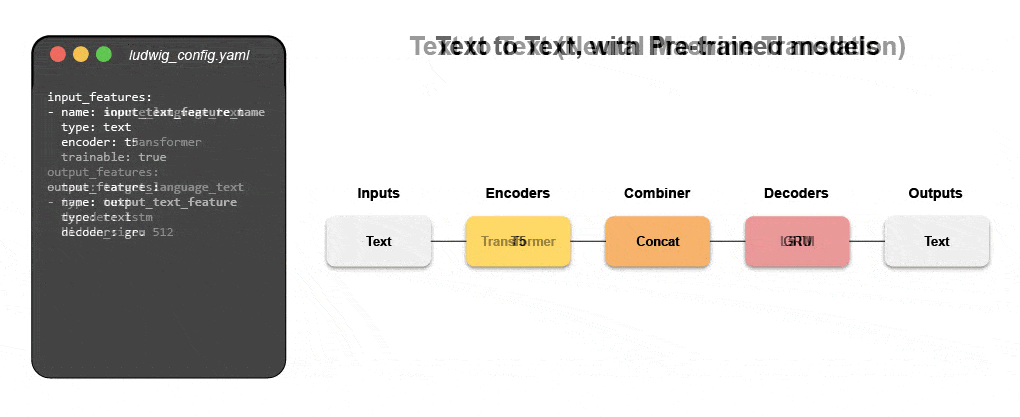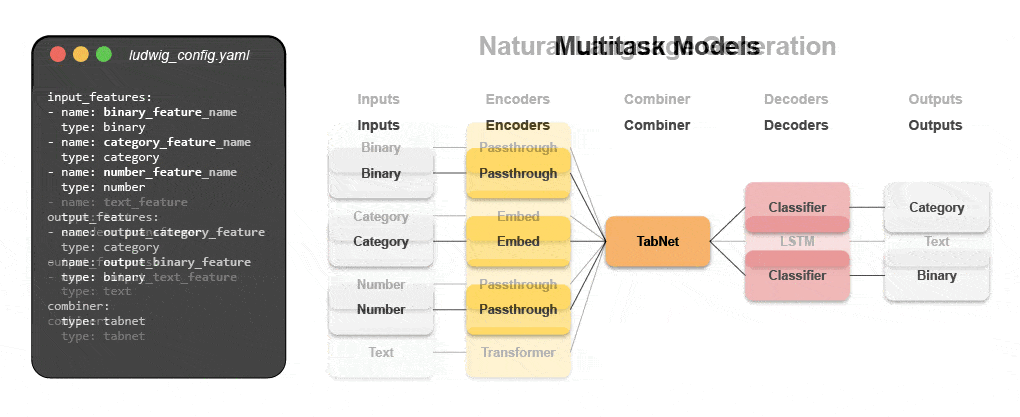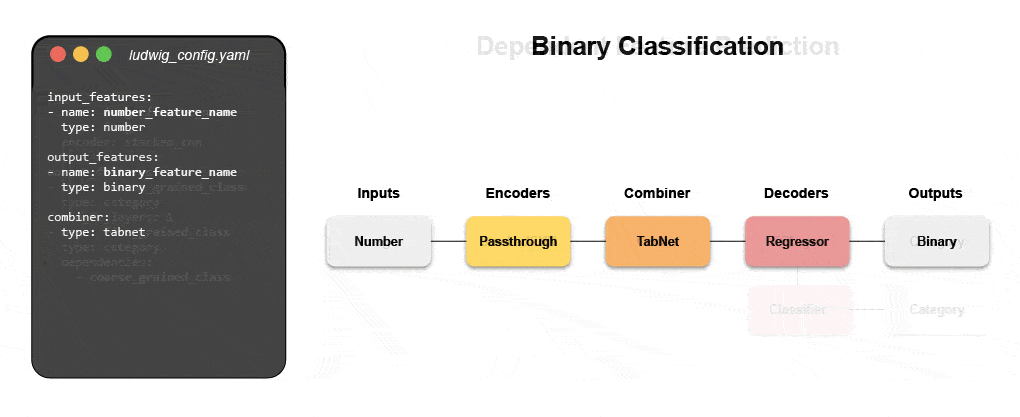
了解如何使用声明式 ML 构建多模式模型
加入我们即将举行的网络研讨会 以及实时教程,了解 Ludwig 等声明性系统,并按照分步说明使用文本和表格数据构建多模式客户评论预测模型。
在本课程中,您将学习如何:
- 快速训练、迭代和部署用于客户评论预测的多模式模型,
- 使用低代码声明性 ML 工具显着减少构建多个 ML 模型所需的时间,
- 通过开源 Ludwig 和 Predibase,像利用结构化数据一样轻松地利用非结构化数据
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code





