最近两种基于软件的算法技术——自动驾驶 (ADAS/AD) 和生成式人工智能 (GenAI)——让半导体工程界夜不能寐。
虽然2级和3级的ADAS已步入正轨,但4级和5级的AD与现实相去甚远,导致风险投资热情和资金下降。如今,GenAI 受到关注,风投们纷纷投资数十亿美元。
这两种技术都基于现代复杂的算法。他们的训练和推理的处理有一些共同的属性,一些是关键的,另一些是重要但不是必需的:见表一。

迄今为止,这些技术中显着的软件进步尚未被算法硬件的进步所复制,以加速其执行。例如,最先进的算法处理器不具备在每次查询成本为 4 欧元(Google 搜索建立的基准)的情况下在一两秒内回答 ChatGPT-2 查询的性能,也无法处理海量数据AD 传感器在不到 20 毫秒的时间内收集到数据。
直到法国初创公司 VSORA 投入人力来解决被称为内存墙的内存瓶颈。
记忆墙
CPU 的内存墙由 Wulf 和 McKee 于 1994 年首次描述。从那时起,内存访问就成为计算性能的瓶颈。处理器性能的进步并未反映在内存访问进度上,导致处理器等待内存传送的数据的时间越来越长。最终,处理器效率下降到 100% 以下。
为了解决这个问题,半导体行业创建了一种多级分层内存结构,在靠近处理器的地方有多层高速缓存,可以减少较慢的主内存和外部内存的流量。
AD 和 GenAI 处理器的性能比其他类型的计算设备更依赖于宽内存带宽。
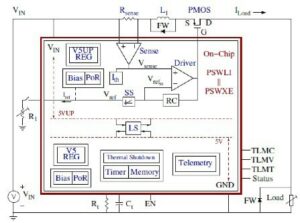
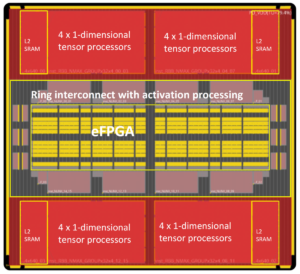
VSORA 成立于 2015 年,面向 5G 应用,发明了一种专利架构,可将分层内存结构折叠成一个可在一个时钟周期内访问的大型高带宽、紧耦合内存 (TCM)。
从处理器内核的角度来看,TCM 的外观和行为就像是大量以 MB 为单位的寄存器,而实际物理寄存器以千字节为单位。在一个周期内访问 TMC 中的任何存储单元的能力可带来高执行速度、低延迟和低功耗。它还需要更少的硅面积。在处理当前数据的同时将新数据从外部存储器加载到 TCM 中不会影响系统吞吐量。基本上,该架构通过其设计允许处理单元的利用率达到 80% 以上。尽管如此,如果系统设计者愿意,仍然可以添加高速缓存和暂存器存储器。参见图 1。
")
通过在所有应用程序的几乎所有存储器中实现类似寄存器的存储器结构,VSORA 存储器方法的优势怎么强调都不为过。通常,尖端的 GenAI 处理器可提供个位数百分比的效率。例如,标称吞吐量为 5 Petaflops 标称性能但效率低于 50% 的 GenAI 处理器可提供低于 10 Teraflops 的可用性能。相反,VSORA 架构的效率提高了 XNUMX 倍以上。
VSORA 的算法加速器
VSORA 推出了两类算法加速器——用于 AD 应用的 Tyr 系列和用于 GenAI 加速的 Jotunn 系列。两者都在较小的硅占用空间中提供出色的吞吐量、最小的延迟和低功耗。
它们的标称性能高达 50 Petaflops,无论算法类型如何,典型实现效率均为 80-30%,峰值功耗为 XNUMX 瓦/Petaflops。这些都是出色的属性,尚未被任何竞争性人工智能加速器报道过。
Tyr 和 Jotunn 是完全可编程的,并集成了 AI 和 DSP 功能(尽管数量不同),并支持从 8 位到 64 位整数或浮点的即时算术选择。它们的可编程性适应了多种算法,使它们与算法无关。还支持几种不同类型的稀疏性。
VSORA 处理器的特性使它们处于竞争算法处理领域的最前沿。
VSORA 支持软件
VSORA 专门针对其硬件架构设计了独特的编译/验证平台,以确保其复杂的高性能 SoC 器件拥有充足的软件支持。
为了让算法设计师进入驾驶舱,一系列分层验证/验证级别(ESL、混合、RTL 和门)向算法工程师提供按钮反馈,以响应设计空间探索。这有助于他或她在性能、延迟、功耗和面积之间选择最佳折衷方案。以高级抽象编写的编程代码可以对用户透明地映射到不同的处理核心。
内核之间的接口可以在同一芯片内、同一 PCB 上的芯片之间或通过 IP 连接来实现。内核之间的同步在编译时自动管理,不需要实时软件操作。
L4/L5 自动驾驶和边缘生成式 AI 推理的障碍
成功的解决方案还应包括现场可编程性。在新思想的推动下,算法迅速发展,而昨天的最先进技术在一夜之间就被淘汰了。现场升级算法的能力是一个值得注意的优势。
虽然超大规模公司一直在组装拥有大量最高性能处理器的大型计算场来处理高级软件算法,但该方法仅适用于训练,不适用于边缘推理。
训练通常基于生成大量数据的 32 位或 64 位浮点算法。它不会施加严格的延迟,并且可以承受高功耗和大量成本。
边缘推理通常在 8 位浮点算术上执行,该算术生成的数据量稍少,但要求不妥协的延迟、低能耗和低成本。
能源消耗对延迟和效率的影响
CMOS IC 中的功耗主要由数据移动而非数据处理决定。
斯坦福大学马克·霍洛维茨教授领导的一项研究表明,内存访问的功耗比基本数字逻辑计算消耗的能量多几个数量级。见表二。

AD 和 GenAI 加速器是以数据移动为主的设备的主要示例,对控制功耗构成了挑战。
结论
AD 和 GenAI 推理对成功实施提出了不小的挑战。 VSORA 可以提供全面的硬件解决方案和支持软件,以满足以商业上可行的成本处理 AD L4/L5 和 GenAI(如 GPT-4 加速)的所有关键要求。
有关 VSORA 及其 Tyr 和 Jotunn 的更多详细信息,请访问 www.vsora.com.
关于劳罗·里扎蒂
劳罗·里扎蒂 (Lauro Rizzatti) 是以下公司的商业顾问 维索拉是一家提供硅 IP 解决方案和硅芯片的创新型初创公司,也是一位著名的硬件仿真验证顾问和行业专家。此前,他曾担任管理、产品营销、技术营销和工程职位。
另请参阅:
通过以下方式分享此帖子:
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- :具有
- :是
- :不是
- $UP
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- 对,能力--
- 关于
- 抽象化
- 加快
- 促进
- 加速器
- 加速器
- ACCESS
- 访问
- 访问
- 实现
- 横过
- 行为
- 实际
- Ad
- ADA
- 加
- 地址
- 高级
- 进步
- 优点
- 顾问
- 影响
- AI
- 算法
- 算法
- 算法
- 所有类型
- 允许
- 还
- 量
- 量
- an
- 和
- 回答
- 任何
- 应用领域
- 的途径
- 架构
- 保健
- 国家 / 地区
- 艺术
- AS
- At
- 关注我们
- 属性
- 自动
- 汽车
- 自主性
- 带宽
- 基于
- 基本包
- 基本上
- BE
- 成为
- 很
- 如下。
- 基准
- 最佳
- 之间
- 十亿美元
- 都
- 商业
- 但是
- by
- 缓存
- CAN
- 不能
- 能力
- 资本
- 造成
- 细胞
- 挑战
- 挑战
- 碎屑
- 类
- 时钟
- 座舱
- 码
- 倒塌
- 商业
- 社体的一部分
- 公司
- 竞争的
- 复杂
- 复杂
- 全面
- 妥协
- 计算
- 计算
- 计算
- 地都
- 顾问
- 消费
- 包含
- 上下文
- 价格
- 成本
- 再加
- 中央处理器
- 创建
- 危急
- 电流
- 前沿
- 周期
- data
- 数据处理
- 交付
- 提升
- 提供
- 密
- 依靠
- 描述
- 设计
- 设计
- 设计师
- 详情
- 设备
- 不同
- 数字
- 数字
- do
- 不
- 美元
- 驱动
- 驾驶
- 下降
- 滴
- 眼巴巴
- 边缘
- 效率
- 或
- 结束
- 能源
- 能源消费
- 工程师
- 工程师
- 确保
- 热情
- ESL
- 必要
- 成熟
- EVER
- 发展
- 例子
- 例子
- 执行
- 技术专家
- 外部
- 家庭
- 远
- 个农场
- 反馈
- 少数
- 部分
- 数字
- 姓氏:
- 漂浮的
- Footprint
- 针对
- 第一线
- 发现
- 公司成立
- 法语
- 止
- 充分
- 实用
- 未来
- 产生
- 生成的
- 生成式人工智能
- 谷歌
- 谷歌搜索
- 更大的
- 处理
- 硬件
- 有
- he
- 保持
- 帮助
- 这里
- 高
- 高性能
- 最高
- 他
- 霍洛维茨
- HTTP
- HTTPS
- 巨大
- 杂交种
- i
- ICS
- 思路
- if
- ii
- 履行
- 实现
- 实施
- 重要
- 征收
- in
- 包括
- 行业中的应用:
- 行业专家
- 创新
- 例
- 代替
- 整合
- 成
- 介绍
- 发明
- 投资
- 投资
- IP
- IT
- 它的
- JPG
- 跳跃
- 保持
- 已知
- 景观
- 大
- 潜伏
- 导致
- 减
- Level
- 各级
- 喜欢
- 装载
- 逻辑
- 由来已久
- 不再
- LOOKS
- 低
- 主要
- 保养
- 制作
- 管理
- 颠覆性技术
- 任务
- 标记
- 营销
- 大规模
- 最大宽度
- 满足
- 回忆
- 内存
- 毫秒
- 最小
- 现代
- 钱
- 更多
- 运动
- 多
- 众多的
- 全新
- 夜
- 注意到
- 值得一提的
- 现在
- 过时的
- of
- 提供
- on
- 一
- 仅由
- 运营
- or
- 秩序
- 订单
- 其他名称
- 其它
- 超过
- 过夜
- 夸大其词
- 专利
- 高峰
- 为
- 百分比
- 性能
- 执行
- 透视
- 的
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 大量
- 点
- 职位
- 可能性
- 帖子
- 功率
- 实用
- 先前
- 总理
- 市场问题
- 过程
- 处理
- 处理
- 处理器
- 处理器
- 产品
- 教授
- 可编程
- 代码编程
- 进展
- 推进
- 放
- 查询
- 范围
- 急速
- 阅读
- 实时的
- 现实
- 最近
- 减少
- 而不管
- 寄存器
- 卓越
- 复制
- 报道
- 要求
- 岗位要求
- 需要
- 响应
- 同
- SEA
- 搜索
- 秒
- 看到
- 选择
- 半导体
- 传感器
- 几个
- Share
- 分享
- 应该
- 显示
- 硅
- 自
- 单
- 小
- So
- 软件
- 方案,
- 解决方案
- 解决
- 一些
- 有些
- 来源
- 太空
- 速度
- 花费
- 斯坦福
- 斯坦福大学
- 启动
- 州/领地
- 国家的最先进的
- 恒星
- 仍
- 精简
- 严格
- 结构体
- 学习
- 大量
- 成功
- SUPPORT
- 支持
- 支持
- 同步
- 系统
- 表
- 量身定制
- 目标
- 瞄准
- 文案
- 技术
- 比
- 这
- 未来
- 其
- 他们
- 那里。
- 博曼
- 他们
- Free Introduction
- 三
- 通过
- 吞吐量
- 紧紧
- 次
- 时
- 至
- 今晚
- 跟踪时
- 传统
- 交通
- 产品培训
- 透明地
- 二
- 类型
- 类型
- 普遍
- 一般
- 独特
- 单位
- 宇宙
- 大学
- 直到
- 升级
- 可用
- 用户
- 运用
- 风险投资
- 冒险
- 创投
- 企业验证
- 与
- 通过
- 可行
- 实质上
- 卷
- 等待
- 墙
- 是
- 方法..
- 井
- ,尤其是
- 而
- 宽
- 祝愿
- 中
- 书面
- 但
- 产量
- 和风网