亚马逊Redshift是一种广泛使用的云数据仓库,已经发生了显着的发展,可以满足最苛刻的工作负载的性能要求。这篇文章介绍了这样一个新功能——多维数据布局排序键。
Amazon Redshift 现在通过支持多维数据布局排序键来提高您的查询性能,多维数据布局排序键是一种新型排序键,可通过筛选谓词而不是表的物理列对表数据进行排序。 多维数据布局排序键将显着提高表扫描的性能,特别是当您的查询工作负载包含重复的扫描过滤器时。
Amazon Redshift 已经提供了以下功能 自动表优化 (ATO),它通过应用排序和分布键自动优化表的设计,无需管理员干预。 在这篇文章中,我们将介绍多维数据布局排序键,作为 ATO 提供的附加功能,并通过 Amazon Redshift 的排序键顾问算法进行强化。
多维数据布局排序键
当您使用 AUTO 排序键定义表时,Amazon Redshift ATO 将分析您的查询历史记录,并根据哪个选项更适合您的工作负载,自动为您的表选择单列排序键或多维数据布局排序键。 选择多维数据布局时,Amazon Redshift 将构建一个多维排序函数,该函数将通常由相同查询访问的行放在一起,并且随后在查询运行期间使用该排序函数来跳过数据块,甚至跳过扫描单个谓词列。
考虑以下用户查询,它是用户工作负载中的主要查询模式:
Amazon Redshift 将每列的数据存储在 1 MB 磁盘块中,并将每个块中的最小值和最大值存储为表元数据的一部分。 如果查询使用 范围限制谓词,Amazon Redshift 可以使用最小值和最大值在表扫描期间快速跳过大量块。 但是,此查询对子区域列的过滤器无法用于根据最小值和最大值确定要跳过哪些块,因此,Amazon Redshift 会扫描标题表中的所有行:
当用户的查询运行时 titles 使用单列排序键 subregion,上面的查询结果如下:
这表明表扫描读取了 2,164,081,640 行。
为了改善扫描 titles 表中,Amazon Redshift 可能会自动决定使用多维数据布局排序键。 所有满足条件的行 lower(subregion) like '%United States%' 谓词将位于表的专用区域,因此 Amazon Redshift 将仅扫描满足谓词的数据块。
当用户的查询运行时 titles 使用多维数据布局排序键,其中包括 lower(subregion) like '%United States%' 作为谓词,结果 sys_query_detail 查询如下:
这表明表扫描读取了 152,324,046 行,仅为原始的 7%,并且它使用了多维数据布局排序键。
请注意,此示例使用单个查询来展示多维数据布局功能,但 Amazon Redshift 将考虑针对表运行的所有查询,并且可以创建多个区域来满足最常运行的谓词。
让我们再举一个例子,这次有更复杂的谓词和多个查询。
想象一下有一张桌子 items (cost int, available int, demand int) 有四行,如下例所示。
| #ID | 成本 | 可使用 | 需求 |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
您的主要工作负载由两个查询组成:
- 70% 查询模式:
- 20% 查询模式:
使用传统的排序技术,您可以选择根据成本列对表进行排序,以便评估 cost > 3 将从排序中受益。 因此,使用单个排序后的项目表 cost 列将如下所示。
| #ID | 成本 | 可使用 | 需求 |
| 区域 #1,成本 <= 3 | |||
| 区域 #2,成本 > 3 | |||
| #ID | 成本 | 可使用 | 需求 |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
通过使用这种传统排序,我们可以立即排除 ID 为 4 和 ID 2 的前两行(蓝色),因为它们不满足 cost > 3.
另一方面,使用多维数据布局排序键,表将根据用户工作负载中两个常见谓词的组合进行排序,这两个谓词是 cost > 3 和 available < demand。 结果,表的行被分类到四个区域中。
| #ID | 成本 | 可使用 | 需求 |
| 区域 #1,成本 <= 3 并且可用 < 需求 | |||
| 区域 #2,成本 <= 3 并且可用 >= 需求 | |||
| 区域 #3,成本 > 3 并且可用 < 需求 | |||
| 区域 #4,成本 > 3 并且可用 >= 需求 | |||
| #ID | 成本 | 可使用 | 需求 |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
当应用于整个块而不是单行时,当应用于使用不适合传统排序技术的运算符的复杂谓词时(例如 like),以及应用于两个以上谓词时。
系统表
以下 Amazon Redshift 系统表将向用户显示其表和查询是否使用多维数据布局:
- 要确定特定表是否使用多维数据布局排序键,您可以检查是否
sortkey1in svv_表_信息 等于AUTO(SORTKEY(padb_internal_mddl_key_col)). - 要确定特定查询是否使用多维数据布局来加速表扫描,您可以检查
step_attribute,在 系统查询详细信息 看法。 该值将等于multi-dimensional扫描期间是否使用了表的多维数据布局排序键。
性能基准
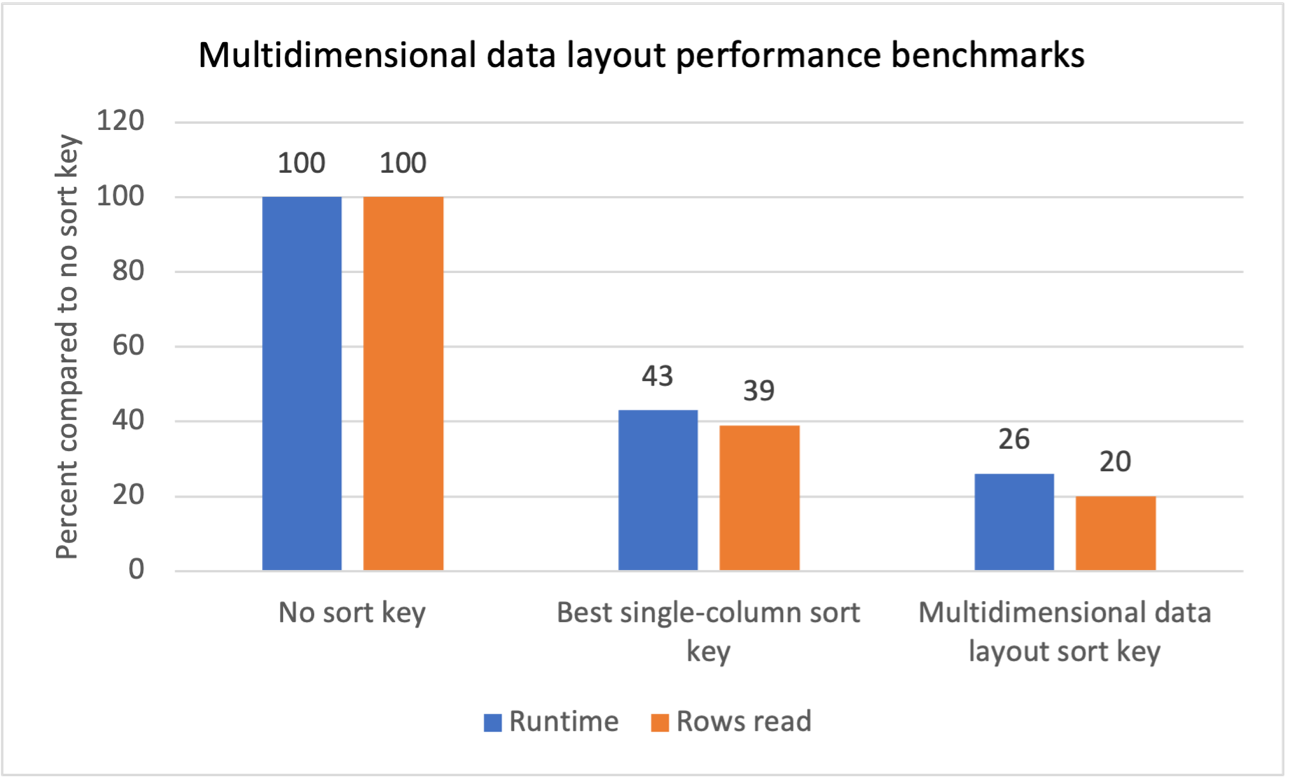
我们使用重复扫描过滤器对多个工作负载进行了内部基准测试,发现引入多维数据布局排序键产生了以下结果:
- 与没有排序键相比,总运行时间减少了 74%。
- 与在每个表上使用最佳单列排序键相比,总运行时间减少了 40%。
- 与没有排序键相比,从表读取的总行数减少了 80%。
- 与在每个表上使用最佳单列排序键相比,从表读取的总行数减少了 47%。
功能比较
通过引入多维数据布局排序键,您的表现在可以根据工作负载中常见的过滤谓词按表达式进行排序。 下表提供了 Amazon Redshift 与两个竞争对手的功能比较。
| 专栏 | 亚马逊Redshift | 竞争对手甲 | 竞争对手乙 |
| 支持按列排序 | 有 | 有 | 有 |
| 支持按表达式排序 | 有 | 有 | 没有 |
| 自动选择列进行排序 | 有 | 没有 | 有 |
| 自动选择表达式进行排序 | 有 | 没有 | 没有 |
| 在列排序或表达式排序之间自动选择 | 有 | 没有 | 没有 |
| 在扫描期间自动使用表达式的排序属性 | 有 | 没有 | 没有 |
需要考虑的事项
使用多维数据布局时请记住以下几点:
- 当您将表设置为 SORTKEY AUTO 时,将启用多维数据布局。
- Amazon Redshift Advisor 将通过分析您的历史工作负载自动为表选择单列排序键或多维数据布局。
- Amazon Redshift ATO 根据正在进行的查询与工作负载交互的方式调整多维数据布局排序结果。
- Amazon Redshift ATO 维护多维数据布局排序键的方式与当前维护现有排序键的方式相同。 参考 使用自动表优化 有关 ATO 的更多详细信息。
- 多维数据布局排序键将适用于配置的集群和无服务器工作组。
- 只要在表上启用了 AUTO SORTKEY 并且检测到具有重复扫描过滤器的工作负载,多维数据布局排序键就可以使用您的现有数据。 该表将根据多维排序功能的结果重新组织。
- 要禁用表的多维数据布局排序键,请使用 alter table:
ALTER TABLE table_name ALTER SORTKEY NONE。 这会禁用表上的自动排序键功能。 - 将配置的集群恢复或迁移到无服务器集群时,会保留多维数据布局排序键,反之亦然。
结论
在这篇文章中,我们展示了多维数据布局排序键可以显着提高主要查询具有重复扫描过滤器的工作负载的查询运行时性能。
要从 Amazon Redshift 控制台创建预览集群,请导航到 集群 页面并选择 创建预览集群。 您可以在美国东部(俄亥俄)、美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、亚太地区(东京)、欧洲(爱尔兰)和欧洲(斯德哥尔摩)区域创建集群并测试您的工作负载。
我们很乐意听到您对这一新功能的反馈,并期待您对这篇文章的评论。
关于作者
 米林德·奥克 是驻纽约的数据仓库专家解决方案架构师。 他构建数据仓库解决方案已超过 15 年,专攻 Amazon Redshift。
米林德·奥克 是驻纽约的数据仓库专家解决方案架构师。 他构建数据仓库解决方案已超过 15 年,专攻 Amazon Redshift。
 丁家琳 是 Learned Systems Group 的应用科学家,专门研究应用机器学习和优化技术来提高 Amazon Redshift 等数据系统的性能。
丁家琳 是 Learned Systems Group 的应用科学家,专门研究应用机器学习和优化技术来提高 Amazon Redshift 等数据系统的性能。
 烟珠机 是 Amazon Redshift 团队的产品经理。 她在行业领先的数据产品和平台的产品愿景和战略方面拥有经验。 她在使用 Web 开发、系统设计、数据库和分布式编程技术构建大量软件产品方面拥有出色的技能。 个人生活中,艳珠喜欢绘画、摄影和打网球。
烟珠机 是 Amazon Redshift 团队的产品经理。 她在行业领先的数据产品和平台的产品愿景和战略方面拥有经验。 她在使用 Web 开发、系统设计、数据库和分布式编程技术构建大量软件产品方面拥有出色的技能。 个人生活中,艳珠喜欢绘画、摄影和打网球。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :具有
- :是
- :不是
- :在哪里
- 1
- 100
- 15 年
- 15%
- 152
- 7
- 8
- 9
- a
- 加快
- 访问
- 额外
- 顾问
- 后
- 驳
- 算法
- 所有类型
- 已经
- Amazon
- 亚马逊网络服务
- an
- 分析
- 分析
- 和
- 另一个
- 应用的
- 应用
- 保健
- AS
- 亚洲
- 亚太
- 汽车
- 自动表
- 自动
- 可使用
- AWS
- 基于
- BE
- 因为
- 很
- 基准
- 得益
- 最佳
- 更好
- 之间
- 阻止
- 吹氣梢
- 蓝色
- 都
- 建筑物
- 但是
- by
- CAN
- 能力
- 查
- 云端技术
- 簇
- 柱
- 列
- 组合
- 注释
- 常用
- 相比
- 对照
- 竞争对手
- 复杂
- 概念
- 考虑
- 由
- 安慰
- 建设
- 包含
- 价格
- 占地面积
- 创建信息图
- 目前
- data
- 数据仓库
- 数据库
- 决定
- 专用
- 定义
- 需求
- 严格
- 设计
- 详情
- 检测
- 确定
- 研发支持
- 分布
- 分配
- 不
- 优势
- 别
- ,我们将参加
- 每
- 东部
- 或
- 启用
- 整个
- 等于
- 特别
- 醚(ETH)
- 欧洲
- 评估
- 甚至
- 进化
- 例子
- 现有
- 体验
- 表达式
- 专栏
- 反馈
- 过滤
- 过滤器
- 以下
- 如下
- 针对
- 向前
- 四
- 止
- 功能
- 团队
- 手
- 有
- 有
- he
- 听
- 这里
- 历史的
- 历史
- 但是
- HTML
- HTTPS
- ID
- if
- 立即
- 改善
- 提高
- in
- 包括
- 个人
- 行业领先
- 代替
- 相互作用
- 内部
- 介入
- 成
- 介绍
- 介绍
- 介绍
- 爱尔兰
- IT
- 项目
- 键
- 键
- 大
- 布局
- 知道
- 学习
- 生活
- 喜欢
- 喜欢
- 长
- 看
- 看起来像
- 爱
- 机
- 机器学习
- 维护
- 经理
- 方式
- 最多
- 满足
- 元数据
- 可能
- 迁移
- 介意
- 最低限度
- 更多
- 最先进的
- 多
- 导航
- 需求
- 全新
- 新功能
- 纽约
- 没有
- 现在
- 数字
- 发生
- of
- 折扣
- 最多线路
- 俄亥俄州
- on
- 一
- 正在进行
- 仅由
- 运营商
- 优化
- 优化
- 附加选项
- or
- 秩序
- 俄勒冈
- 原版的
- 其他名称
- 输出
- 优秀
- 超过
- 太平洋
- 画
- 部分
- 特别
- 模式
- 性能
- 执行
- 个人
- 摄影
- 的
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 帖子
- 强大
- 罐头
- 预览
- 生成
- 产品
- 产品经理
- 核心产品
- 代码编程
- 提供
- 查询
- 急速
- 阅读
- 减少
- 参考
- 地区
- 地区
- 重复的
- 岗位要求
- 恢复
- 导致
- 成果
- 运行
- 运行
- 运行
- 同
- 浏览
- 扫描
- 扫描
- 科学家
- 季节
- 看到
- 选择
- 选
- 选择
- 无服务器
- 特色服务
- 集
- 她
- 显示
- 展示
- 显示
- 如图
- 作品
- 显著
- 单
- 技能
- So
- 软件
- 解决方案
- 专家
- 专业
- 专业
- 商店
- 策略
- 后来
- 大量
- 这样
- 合适的
- 支持
- 系统
- 产品
- 表
- 采取
- 团队
- 技术
- 网球
- test
- 测试
- 比
- 这
- 其
- 因此
- 他们
- Free Introduction
- 次
- 标题
- 至
- 东京
- 最佳
- 合计
- 传统
- 二
- 类型
- 一般
- us
- 使用
- 用过的
- 用户
- 用户
- 使用
- 运用
- 折扣值
- 价值观
- 副
- 查看
- 弗吉尼亚州
- 愿景
- 仓库保管
- 是
- 方法..
- we
- 卷筒纸
- Web开发
- Web服务
- 西部
- ,尤其是
- 是否
- 这
- 广泛
- 将
- 也完全不需要
- 工作
- 将
- 年
- 纽约
- 您
- 您一站式解决方案
- 和风网