在这篇文章中,我们将学习 如何在只有 CPU 的计算机上部署和使用 GPT4All 模型 (我正在使用 Macbook Pro 没有 GPU!)

在您的计算机上使用 GPT4All — 图片由作者提供
在本文中,我们将在我们的本地计算机上安装 GPT4All(一个功能强大的 LLM),我们将发现如何使用 Python 与我们的文档进行交互。 PDF 或在线文章的集合将成为我们问题/答案的知识库。
来自 官网GPT4All 它被描述为 免费使用、本地运行、隐私感知的聊天机器人。 无需 GPU 或互联网。
GTP4All 是一个用于训练和部署的生态系统 强大 和 定制 运行的大型语言模型 当地 在消费级 CPU 上。
我们的 GPT4All 模型是一个 4GB 的文件,您可以下载该文件并将其插入 GPT4All 开源生态系统软件。 智能人工智能 促进高质量和安全的软件生态系统,推动使个人和组织能够毫不费力地在本地训练和实施他们自己的大型语言模型。
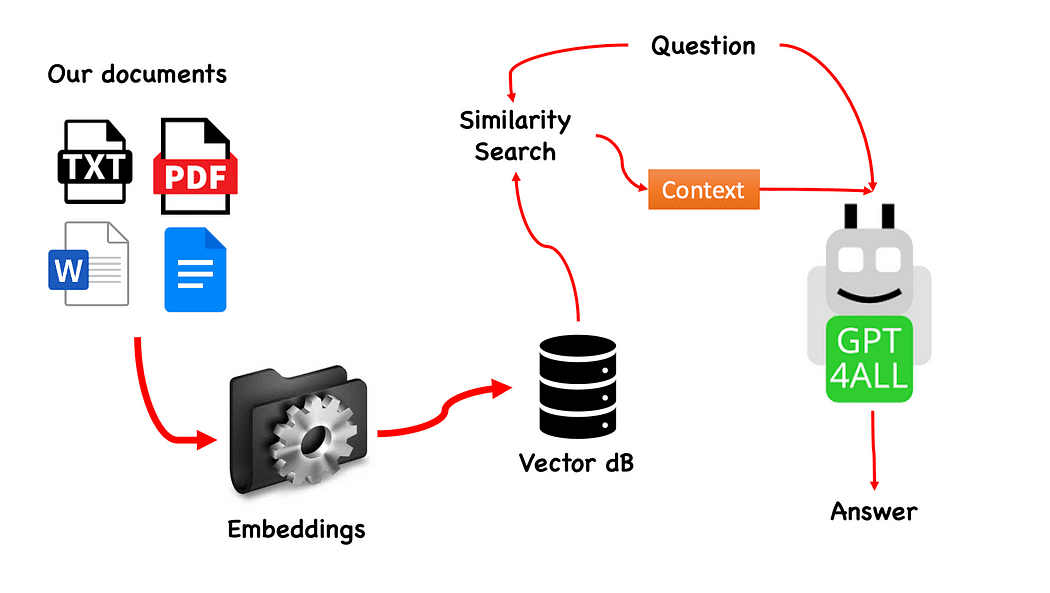
使用 GPT4All 的 QnA 工作流程——由作者创建
这个过程真的很简单(当你知道的时候)并且也可以用其他模型重复。 步骤如下:
- 加载 GPT4All 模型
- 使用 浪链 检索我们的文件并加载它们
- 将文档分成可被嵌入消化的小块
- 使用 FAISS 创建带有嵌入的矢量数据库
- 根据我们要传递给 GPT4All 的问题对我们的矢量数据库执行相似性搜索(语义搜索):这将用作 上下文 对于我们的问题
- 将问题和上下文提供给 GPT4All 浪链 并等待答案。
所以我们需要的是 Embeddings。 嵌入是一段信息的数字表示,例如文本、文档、图像、音频等。该表示捕获了所嵌入内容的语义,这正是我们所需要的。 对于这个项目,我们不能依赖重型 GPU 模型:因此我们将下载 Alpaca 原生模型并使用 浪链 此 LlamaCpp嵌入. 不用担心! 一切都一步一步解释
创建虚拟环境
为您的新 Python 项目创建一个新文件夹,例如 GPT4ALL_Fabio(输入您的名字……):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabio接下来,创建一个新的 Python 虚拟环境。 如果您安装了多个 python 版本,请指定您想要的版本:在这种情况下,我将使用与 python 3.10 关联的主要安装。
python3 -m venv .venv命令 python3 -m venv .venv 创建一个名为的新虚拟环境 .venv (点将创建一个名为 venv 的隐藏目录)。
虚拟环境提供了一个隔离的 Python 安装,它允许您仅为特定项目安装包和依赖项,而不会影响系统范围的 Python 安装或其他项目。 这种隔离有助于保持一致性并防止不同项目需求之间的潜在冲突。
创建虚拟环境后,您可以使用以下命令激活它:
source .venv/bin/activate 
激活的虚拟环境
要安装的库
对于我们正在构建的项目,我们不需要太多包。 我们只需要:
- GPT4All 的 python 绑定
- Langchain 与我们的文档进行交互
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。 它不仅允许您通过 API 调用语言模型,还可以将语言模型连接到其他数据源,并允许语言模型与其环境进行交互。
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4对于 LangChain,您会看到我们还指定了版本。 这个库最近收到了很多更新,所以为了确定我们的设置明天也能正常工作,最好指定一个我们知道工作正常的版本。 非结构化是 pdf 加载器的必需依赖项,并且 pytesseract 和 pdf2图片 以及。
注意:在 GitHub 存储库上有一个 requirements.txt 文件(由 杰尔阿德罗) 以及与此项目关联的所有版本。 在使用以下命令将其下载到主项目文件目录后,您可以一次性完成安装:
pip install -r requirements.txt在文章的最后我创建了一个 故障排除部分. GitHub 存储库还有一个包含所有这些信息的更新 READ.ME。
请记住,一些 库有可用的版本,具体取决于 python 版本 您正在虚拟环境中运行。
在您的 PC 上下载模型
这是非常重要的一步。
对于这个项目,我们当然需要 GPT4All。 Nomic AI 上描述的过程非常复杂,需要并非所有人(像我)都拥有的硬件。 所以 这是模型的链接 已经转换并可以使用。 只需点击下载。
下载 GPT4All 模型
正如简介中简要描述的那样,我们还需要嵌入模型,一个我们可以在 CPU 上运行而不会崩溃的模型。 点击 此处链接下载 alpaca-native-7B-ggml 已经转换为 4 位并准备好用作我们的嵌入模型。

点击旁边的下载箭头 ggml-模型-q4_0.bin
为什么我们需要嵌入? 如果您还记得流程图,在我们为知识库收集文档后,第一步是 嵌 他们。 这个羊驼模型的 LLamaCPP 嵌入非常适合这项工作,而且这个模型也非常小(4 Gb)。 顺便说一句,您也可以为您的 QnA 使用羊驼模型!
更新 2023.05.25:Mani Windows 用户在使用 llamaCPP 嵌入时遇到问题。 这主要是因为在安装 python 包 llama-cpp-python 期间:
pip install llama-cpp-pythonpip 包将从库的源代码编译。 Windows 通常不会在机器上默认安装 CMake 或 C 编译器。 但不要担心有一个解决方案
在 Windows 上运行 llama-cpp-python 的安装,LangChain 需要使用 llamaEmbeddings,默认情况下未安装 CMake C 编译器,因此您无法从源代码构建。
在使用 Xtools 的 Mac 用户和 Linux 上,通常 C 编译器已经在操作系统上可用。
为了避免这个问题 你必须使用预编译的轮子.
去这里 https://github.com/abetlen/llama-cpp-python/releases
并为您的体系结构和 python 版本寻找兼容的 wheel — 你必须使用 Weels 版本 0.1.49 因为更高版本不兼容。
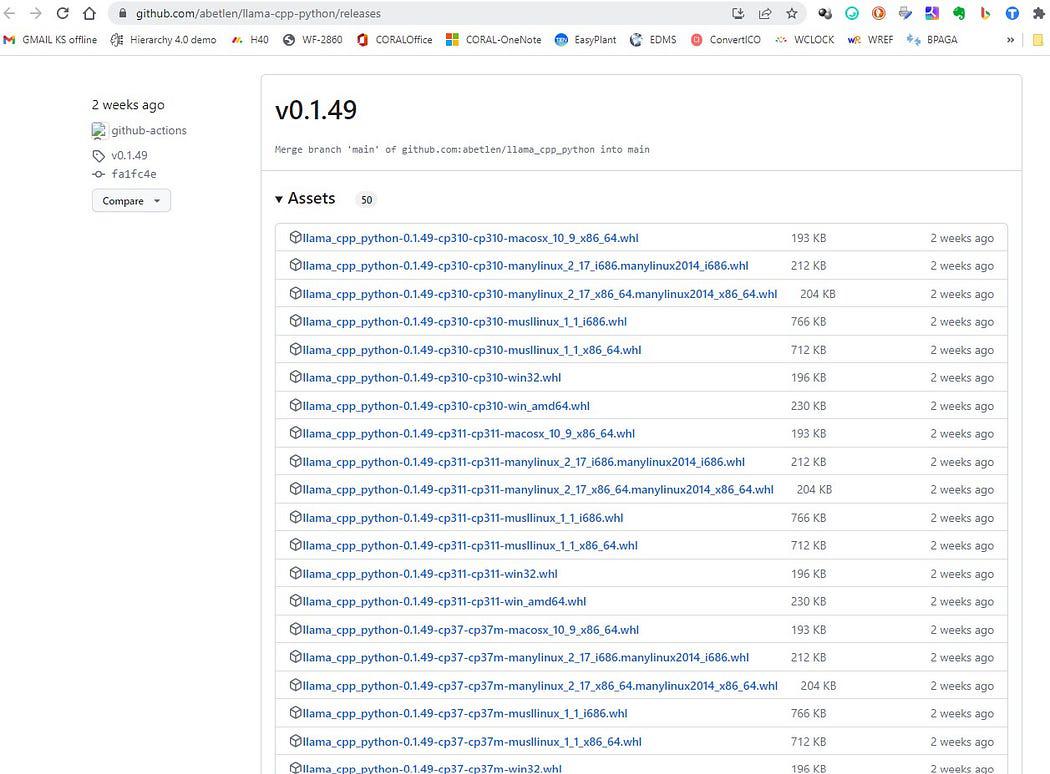
屏幕截图 https://github.com/abetlen/llama-cpp-python/releases
就我而言,我有 Windows 10、64 位、python 3.10
所以我的文件是 llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
下载后需要将两个模型放到models目录下,如下图。

目录结构和放置模型文件的位置
由于我们想控制我们与 GPT 模型的交互,我们必须创建一个 python 文件(我们称之为 pygpt4all_test.py), 导入依赖项并向模型提供指令。 你会发现这很容易。
from pygpt4all.models.gpt4all import GPT4All这是我们模型的 python 绑定。 现在我们可以调用它并开始询问了。 让我们尝试一个有创意的。
我们创建了一个从模型中读取回调的函数,我们要求 GPT4All 完成我们的句子。
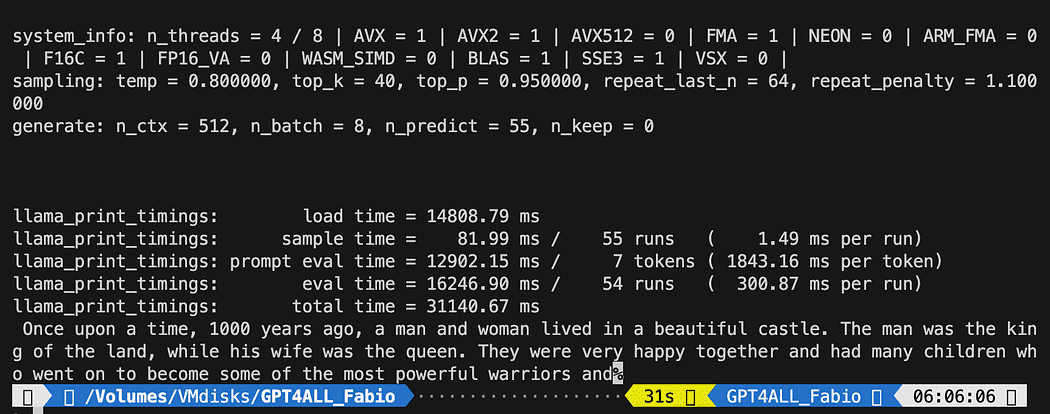
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)第一条语句告诉我们的程序在哪里可以找到模型(记住我们在上一节中所做的)
第二条语句要求模型生成响应并完成我们的提示“从前”。
要运行它,请确保虚拟环境仍处于激活状态并只需运行:
python3 pygpt4all_test.py您应该看到模型的加载文本和句子的完成。 根据您的硬件资源,这可能需要一些时间。
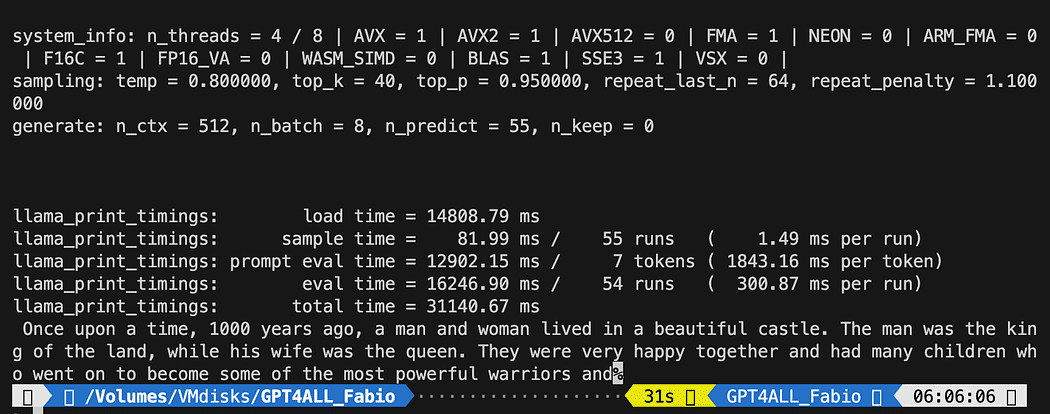
结果可能与您的不同……但对我们来说重要的是它正在运行,我们可以继续使用 LangChain 来创建一些高级的东西。
注意(更新于 2023.05.23):如果您遇到与 pygpt4all 相关的错误,请使用由给出的解决方案查看有关此主题的故障排除部分 拉杰尼什·阿加瓦尔 or 奥斯卡·郑。
LangChain 框架是一个非常棒的库。 它提供 平台组件 以易于使用的方式使用语言模型,它还提供 链条. 链可以被认为是以特定方式组装这些组件,以便最好地完成特定用例。 这些旨在成为一个更高级别的界面,人们可以通过它轻松地开始使用特定的用例。 这些链条还设计为可定制。
在我们的下一个 python 测试中,我们将使用 提示模板. 语言模型将文本作为输入——该文本通常被称为提示。 通常这不是简单的硬编码字符串,而是模板、一些示例和用户输入的组合。 LangChain 提供了几个类和函数来简化提示的构建和使用。 让我们看看我们也可以怎么做。
创建一个新的python文件并调用它 my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])我们从 LangChain 导入了 Prompt Template and Chain 和 GPT4All llm 类,以便能够直接与我们的 GPT 模型进行交互。
然后,在设置我们的 llm 路径之后(就像我们之前所做的那样),我们实例化回调管理器,以便我们能够捕获对查询的响应。
创建模板非常简单:按照 文档教程 我们可以使用这样的东西......
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])模板 variable 是一个多行字符串,包含我们与模型的交互结构:在大括号中我们将外部变量插入到模板中,在我们的场景中是我们的 题.
由于它是一个变量,您可以决定它是硬编码问题还是用户输入问题:这里有两个示例。
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")对于我们的测试运行,我们将评论用户输入的一个。 现在我们只需要将我们的模板、问题和语言模型链接在一起。
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)请记住验证您的虚拟环境是否仍处于激活状态并运行命令:
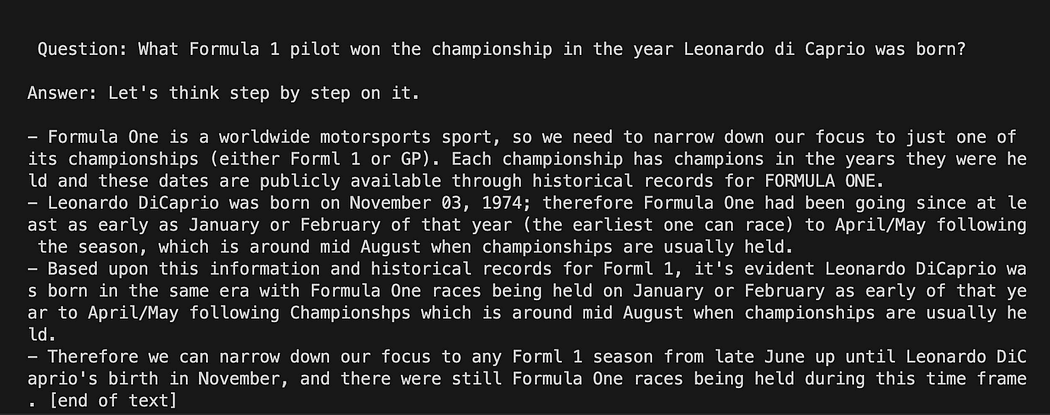
python3 my_langchain.py你可能会得到与我不同的结果。 令人惊奇的是,你可以看到 GPT4All 试图为你得到答案的整个推理过程。 调整问题也可能会给您带来更好的结果。
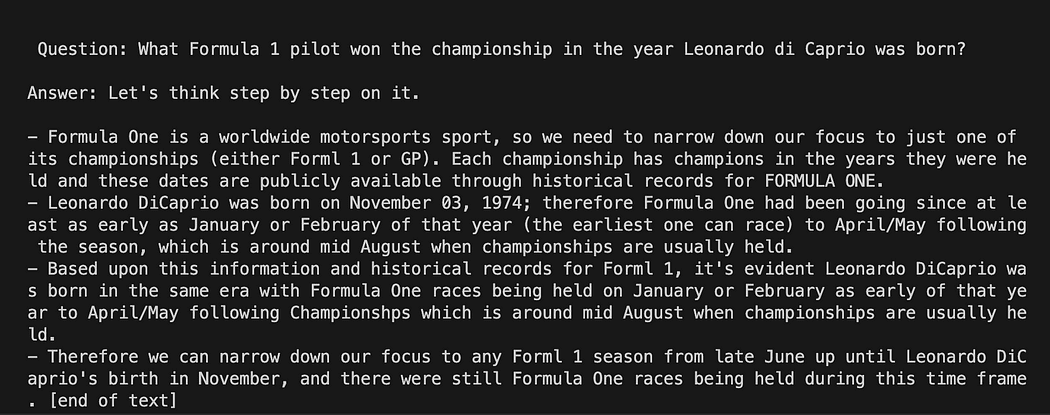
GPT4All 上带有提示模板的 Langchain
在这里,我们开始了令人惊奇的部分,因为我们将使用 GPT4All 作为回答我们问题的聊天机器人来讨论我们的文档。
步骤顺序,参考 使用 GPT4All 的 QnA 工作流程,就是加载我们的pdf文件,把它们分块。 之后,我们将需要一个 Vector Store 用于我们的嵌入。 我们需要将分块文档放入向量存储中以进行信息检索,然后将它们与相似性搜索一起嵌入到该数据库中,作为我们的 LLM 查询的上下文。
为此,我们将直接使用 FAISS 浪链 图书馆。 FAISS 是 Facebook AI Research 的一个开源库,旨在快速找到大量高维数据中的相似项目。 它提供了索引和搜索方法,可以更轻松、更快速地发现数据集中最相似的项目。 这对我们来说特别方便,因为它简化了 信息检索 并允许我们在本地保存创建的数据库:这意味着在第一次创建后,它将非常快速地加载以供进一步使用。
创建矢量索引数据库
创建一个新文件并调用它 my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetime第一个库与我们之前使用的相同:此外我们正在使用 浪链 对于矢量存储索引创建, LlamaCpp嵌入 与我们的羊驼模型(量化为 4 位并使用 cpp 库编译)和 PDF 加载器进行交互。
让我们也用它们自己的路径加载我们的 LLM:一个用于嵌入,一个用于文本生成。
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)为了进行测试,让我们看看我们是否设法读取了所有 pfd 文件:第一步是声明要在每个文档上使用的 3 个函数。 第一个是将提取的文本分成块,第二个是使用元数据(如页码等)创建矢量索引,最后一个是用于测试相似性搜索(我稍后会更好地解释)。
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources现在我们可以测试文档中的索引生成 文档 目录:我们需要把所有的 pdf 放在那里。 浪链 还有一种加载整个文件夹的方法,无论文件类型如何:由于后期过程复杂,我将在下一篇关于 LaMini 模型的文章中介绍。

我的文档目录包含 4 个 pdf 文件
我们将把我们的功能应用到列表中的第一个文档
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)在第一行中,我们使用 os 库来获取 pdf文件列表 在文档目录中。 然后我们加载第一个文档(文档列表[0]) 从 docs 文件夹中 浪链,分成块,然后我们用 骆驼 嵌入。
如您所见,我们正在使用 pyPDF方法. 这个使用起来有点长,因为你必须一个一个地加载文件,但是加载 PDF 使用 pypdf into array of documents 允许你有一个数组,其中每个文档包含页面内容和元数据 page 数字。 当您想知道我们将通过查询提供给 GPT4All 的上下文来源时,这真的很方便。 这是 readthedocs 中的示例:
屏幕截图 浪链文档
我们可以使用终端命令运行 python 文件:
python3 my_knowledge_qna.py加载嵌入模型后,您将看到用于索引的令牌:不要惊慌,因为这需要时间,特别是如果您只在 CPU 上运行,就像我一样(花了 8 分钟)。
完成第一个向量 db
正如我所解释的,pyPDF 方法速度较慢,但为我们提供了用于相似性搜索的额外数据。 为了遍历我们所有的文件,我们将使用 FAISS 的一种方便的方法,它允许我们将不同的数据库合并在一起。 我们现在要做的是使用上面的代码生成第一个数据库(我们称它为 db0) 和 for 循环我们创建列表中下一个文件的索引并立即将其合并 db0.
这是代码:请注意,我添加了一些日志来为您提供使用进度的状态 日期时间.日期时间.现在() 并打印结束时间和开始时间的增量以计算操作花费的时间(如果不喜欢可以删除它)。
合并指令是这样的
# merge dbi with the existing db0
db0.merge_from(dbi)最后的说明之一是在本地保存我们的数据库:整个生成可能需要几个小时(取决于您有多少文档)所以我们只需要做一次真的很好!
# Save the databasae locally
db0.save_local("my_faiss_index")这里是整个代码。 当我们与直接从我们的文件夹加载索引的 GPT4All 交互时,我们将评论其中的许多部分。
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  运行 python 文件耗时 22 分钟
运行 python 文件耗时 22 分钟
就您的文件向 GPT4All 提问
现在我们在这里。 我们有我们的索引,我们可以加载它,我们可以使用提示模板让 GPT4All 回答我们的问题。 我们从一个硬编码的问题开始,然后循环遍历我们的输入问题。
将以下代码放入 python 文件中 db_loading.py 并使用终端命令运行它 python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])打印的文本是与查询最匹配的 3 个来源的列表,还为我们提供了文档名称和页码。
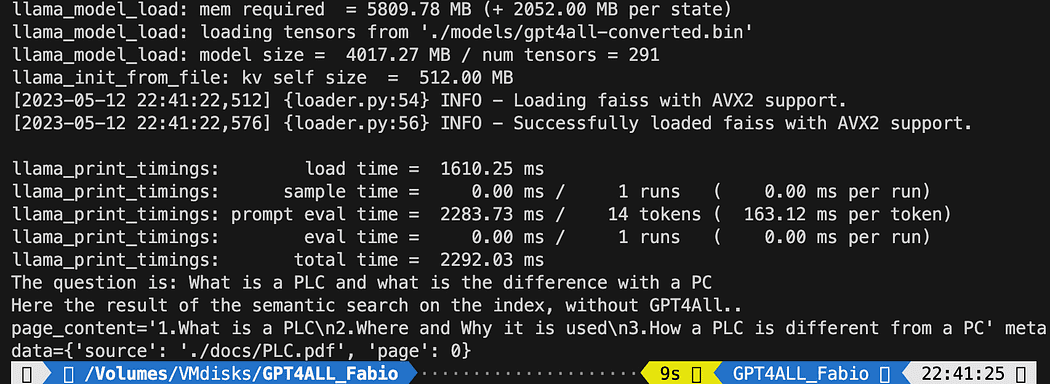
运行文件的语义搜索结果 db_loading.py
现在我们可以使用提示模板将相似性搜索用作查询的上下文。 在这 3 个函数之后,只需将所有代码替换为以下内容:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))运行后你会得到这样的结果(但可能会有所不同)。 惊人的不!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.如果你想要一个用户输入的问题来替换行
question = "What is a PLC and what is the difference with a PC"像这样:
question = input("Your question: ")现在是您进行实验的时候了。 针对与您的文档相关的所有主题提出不同的问题,然后查看结果。 有很大的改进空间,肯定是在提示和模板上:你可以看看 在这里获得一些灵感。但是品牌对其自身难以衡量的部分,无法做出有效提升 浪链 文档真的很棒(我可以跟着它!!)。
您可以按照文章中的代码进行操作或查看 我的 github 仓库.
法比奥·马特里卡尔迪 教育家、教师、工程师和学习爱好者。 他已经为年轻学生教授了 15 年,现在他在 Key Solution Srl. 培训新员工。 他于 2010 年开始我的职业生涯,担任工业自动化工程师。他从十几岁起就对编程充满热情,他发现了构建软件和人机界面以将事物带入生活的美妙之处。 教学和辅导是我日常工作的一部分,同时我也在学习如何成为一名拥有最新管理技能的充满激情的领导者。 和我一起踏上更好的设计之旅,在整个工程生命周期中使用机器学习和人工智能进行预测系统集成。
原版。 经许可重新发布。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- EVM财务。 去中心化金融的统一接口。 访问这里。
- 量子传媒集团。 IR/PR 放大。 访问这里。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 年
- 15%
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- 对,能力--
- Able
- 关于
- 以上
- 完成
- 法案
- 活性
- 添加
- 增加
- 额外
- 高级
- 影响
- 后
- AI
- 研究
- 所有类型
- 让
- 允许
- 已经
- 还
- am
- 惊人
- an
- 分析
- 和
- 回答
- 任何
- API
- 应用领域
- 使用
- 架构
- 保健
- 排列
- 刊文
- 刊文
- 人造的
- 人工智能
- AS
- 相关
- At
- 音频
- 自动化
- 自动
- 自动化和干细胞工程
- 可使用
- 避免
- 基地
- 基于
- BE
- 美容
- 因为
- 很
- before
- 作为
- 如下。
- 最佳
- 更好
- 之间
- 超越
- 大
- BIN
- 捆绑
- 位
- 天生的
- 简要地
- 带来
- 建立
- 建筑物
- 内建的
- 公共汽车
- 但是
- by
- 计算
- 呼叫
- 被称为
- 呼叫
- CAN
- 不能
- 容量
- 捕获
- 寻找工作
- 携带
- 案件
- 摔角
- CD
- 一定
- 当然
- 链
- 链
- 冠军
- 聊天机器人
- ChatGPT
- 查
- 化学
- 程
- 类
- 点击
- 教练
- 码
- 代码
- 收集
- 采集
- 收藏
- 组合
- 评论
- 常用
- 通信
- 沟通
- 兼容
- 完成
- 完成
- 完成
- 复杂
- 复杂
- 组件
- 一台
- 电脑
- 分享链接
- 已联繫
- 构建
- 消费者
- 包含
- 内容
- 上下文
- 控制
- 调节器
- 控制
- 便捷
- 转换
- 可以
- 外壳
- 中央处理器
- 创建信息图
- 创建
- 创建
- 创造
- 创建
- 创意奖学金
- 危急
- 定制
- 每天
- data
- 数据库
- 数据库
- 日期
- 日期时间
- 决定
- 默认
- 定义
- Delta
- 依赖
- 根据
- 依靠
- 部署
- 描述
- 设计
- 设计
- 期望
- 发展
- 设备
- 设备
- DID
- 差异
- 不同
- 可消化的
- 数字
- 直接
- 通过各种方式找到
- 发现
- do
- 文件
- 文件
- 文件
- 不
- 不会
- 完成
- 别
- DOT
- 下载
- 驾驶
- ,我们将参加
- 每
- 更容易
- 容易
- 易
- 生态系统
- 生态系统
- 努力
- 嵌
- 嵌入式
- 嵌入
- 员工
- enable
- 结束
- 工程师
- 工程师
- 输入
- 爱好者
- 整个
- 环境
- 错误
- 特别
- 等
- 醚(ETH)
- 甚至
- 一切
- 究竟
- 例子
- 例子
- 执行
- 现有
- 实验
- 说明
- 解释
- 说明
- 外部
- 面部彩妆
- 功能有助于
- 面对
- 高效率
- 快
- 文件
- 档
- 找到最适合您的地方
- 结束
- 姓氏:
- 适合
- 流
- 遵循
- 其次
- 以下
- 如下
- 针对
- 申请
- 格式
- 公式
- 公式1
- 骨架
- 止
- 功能
- 功能
- 进一步
- 生成
- 发电
- 代
- 得到
- GitHub上
- 给
- 特定
- 给
- 给予
- 去
- 非常好
- GPU
- 经验
- 处理
- 发生
- 硬
- 硬件
- 有
- he
- 重
- 帮助
- 此处
- 老旧房屋
- 高
- 更高
- HOURS
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- 人
- i
- ICS
- if
- 图片
- 立即
- 实施
- 进口
- 重要
- 改进
- in
- 包括
- 指数
- 指标
- 个人
- 产业
- 工业自动化
- 行业
- 信息
- 输入
- 输入输出
- 输入
- 安装
- 安装
- 例
- 说明
- 积分
- 房源搜索
- 拟
- 相互作用
- 相互作用
- 接口
- 接口
- 网络
- 成
- 介绍
- 孤立
- 隔离
- IT
- 项目
- 迭代
- 它的
- 工作
- 加入
- 旅程
- 只是
- 掘金队
- 键
- 知道
- 知识
- 语言
- 大
- 名:
- 后来
- 领导者
- 学习
- Level
- 库
- 自学资料库
- 生活
- 生命周期
- 喜欢
- 线
- 友情链接
- Linux的
- 清单
- 小
- 加载
- 装载机
- 装载
- 本地
- 当地
- 逻辑
- 长
- 不再
- 看
- 占地
- MAC
- 机
- 机器学习
- 机械
- 主要
- 主要
- 保持
- 使
- 管理
- 颠覆性技术
- 经理
- 经理
- 制造业
- 许多
- 可能..
- 意
- 手段
- 内存
- 合并
- 合并
- 元数据
- 方法
- 方法
- 介意
- 分钟
- 模型
- 模型
- 更多
- 最先进的
- 多
- 必须
- my
- 姓名
- 本地人
- 需求
- 网络
- 全新
- 下页
- 现在
- 数
- 数字
- 对象
- of
- 优惠精选
- on
- 一旦
- 一
- 在线
- 仅由
- 开放源码
- 操作
- 运营
- or
- 秩序
- 组织
- OS
- 其他名称
- 我们的
- 输出
- 产量
- 超过
- 己
- 包
- 包
- 页
- 并行
- 部分
- 特别
- 尤其
- 通过
- 多情
- 径
- PC
- 员工
- 演出
- 允许
- 个人
- 图片
- 片
- 飞行员
- 工厂
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- PLC的
- 请
- 插头
- 港口
- 位置
- 帖子
- 潜力
- 功率
- 发电厂
- 供电
- 强大
- 预
- 防止
- 打印
- 印刷
- 问题
- 过程
- 处理
- 过程
- 曲目
- 程序
- 代码编程
- 进展
- 项目
- 项目
- 协议
- 提供
- 目的
- 放
- 蟒蛇
- 质量
- 题
- 有疑问吗?
- 很快
- 宁
- 阅读
- 准备
- 真
- 接收
- 最近
- 简称
- 指
- 而不管
- 寄存器
- 有关
- 可靠性
- 依靠
- 纪念
- 去掉
- 重复
- 更换
- 报告
- 知识库
- 表示
- 必须
- 岗位要求
- 需要
- 研究
- 资源
- 响应
- 回复
- 导致
- 成果
- 回报
- Room
- 运行
- 运行
- s
- 实现安全
- 同
- 保存
- 保存
- 脚本
- 搜索
- 搜索
- 其次
- 部分
- 安全
- 看到
- 传感器
- 句子
- 序列
- 串行
- 设置
- 格局
- 几个
- 射击
- 应该
- 如图
- 类似
- 简易
- 只是
- 自
- 单
- 技能
- 小
- So
- 软件
- 方案,
- 一些
- 东西
- 来源
- 来源
- 专门
- 特别
- 具体的
- 指定
- 分裂
- Spot
- 开始
- 开始
- 开始
- 个人陈述
- Status
- 步
- 步骤
- 仍
- 商店
- 串
- 结构体
- 学生
- 留学
- 这样
- 系统
- 采取
- 谈论
- 任务
- 老师
- 教诲
- 青少年
- 模板
- 终端
- test
- 试运行
- 测试
- 文字产生
- 比
- 这
- 其
- 他们
- 然后
- 那里。
- 博曼
- 他们
- 认为
- Free Introduction
- 思想
- 通过
- 始终
- 次
- 至
- 一起
- 令牌
- 明天
- 也有
- 了
- 主题
- Topics
- 对于
- 培训
- 尝试
- 二
- 类型
- 普遍
- 一般
- 更新
- 最新动态
- 上
- us
- 用法
- USB
- 使用
- 用例
- 用过的
- 用户
- 用户
- 运用
- 平时
- 利用
- 各个
- 确认
- 版本
- 非常
- 通过
- 在线会议
- W3
- 等待
- 想
- 是
- 方法..
- 方法
- we
- 您的网站
- 井
- 什么是
- 什么是
- 轮
- ,尤其是
- 这
- WHO
- 为什么
- 广泛
- 将
- 窗户
- Windows用户
- 中
- 也完全不需要
- 韩元
- 工作
- 加工
- 年
- 年
- 您
- 年轻
- 您一站式解决方案
- 和风网










