今天,我们很高兴地宣布 Llama 2 推理和微调支持可用 AWS 培训 和 AWS 推理 的实例 亚马逊SageMaker JumpStart。通过 SageMaker 使用基于 AWS Trainium 和 Inferentia 的实例,可以帮助用户将微调成本降低高达 50%,将部署成本降低 4.7 倍,同时降低每个令牌的延迟。 Llama 2 是一种使用优化的 Transformer 架构的自回归生成文本语言模型。作为一个公开可用的模型,Llama 2 专为许多 NLP 任务而设计,例如文本分类、情感分析、语言翻译、语言建模、文本生成和对话系统。微调和部署 Llama 2 等 LLM 可能会变得成本高昂或具有挑战性,无法满足实时性能以提供良好的客户体验。 Trainium 和 AWS Inferentia,由 AWS 神经元 软件开发套件 (SDK),为 Llama 2 模型的训练和推理提供高性能且经济高效的选项。
在这篇文章中,我们演示了如何在 SageMaker JumpStart 中的 Trainium 和 AWS Inferentia 实例上部署和微调 Llama 2。
解决方案概述
在本博客中,我们将介绍以下场景:
- 在 AWS Inferentia 实例上部署 Llama 2 亚马逊SageMaker Studio UI,具有一键部署体验和 SageMaker Python SDK。
- 在 SageMaker Studio UI 和 SageMaker Python SDK 中微调 Trainium 实例上的 Llama 2。
- 将微调后的 Llama 2 模型与预训练模型的性能进行比较,以显示微调的有效性。
要上手,请参阅 GitHub 示例笔记本.
使用 SageMaker Studio UI 和 Python SDK 在 AWS Inferentia 实例上部署 Llama 2
在本部分中,我们将演示如何使用 SageMaker Studio UI 进行一键部署和 Python SDK 在 AWS Inferentia 实例上部署 Llama 2。
在 SageMaker Studio UI 上探索 Llama 2 模型
SageMaker JumpStart 提供对公开可用和专有的访问 基础模型。基础模型由第三方和专有提供商引入和维护。因此,它们是根据模型源指定的不同许可证发布的。请务必查看您使用的任何基础模型的许可证。您有责任在下载或使用内容之前查看并遵守任何适用的许可条款,并确保它们适合您的使用案例。
您可以通过 SageMaker Studio UI 和 SageMaker Python SDK 中的 SageMaker JumpStart 访问 Llama 2 基础模型。在本节中,我们将介绍如何在 SageMaker Studio 中发现模型。
SageMaker Studio 是一个集成开发环境 (IDE),提供基于 Web 的单一可视化界面,您可以在其中访问专用工具来执行所有机器学习 (ML) 开发步骤,从准备数据到构建、训练和部署 ML楷模。有关如何开始和设置 SageMaker Studio 的更多详细信息,请参阅 亚马逊 SageMaker Studio。
进入 SageMaker Studio 后,您可以访问 SageMaker JumpStart,其中包含预训练的模型、笔记本和预构建的解决方案,位于 预构建和自动化解决方案。有关如何访问专有模型的更多详细信息,请参阅 在 Amazon SageMaker Studio 中使用 Amazon SageMaker JumpStart 的专有基础模型.
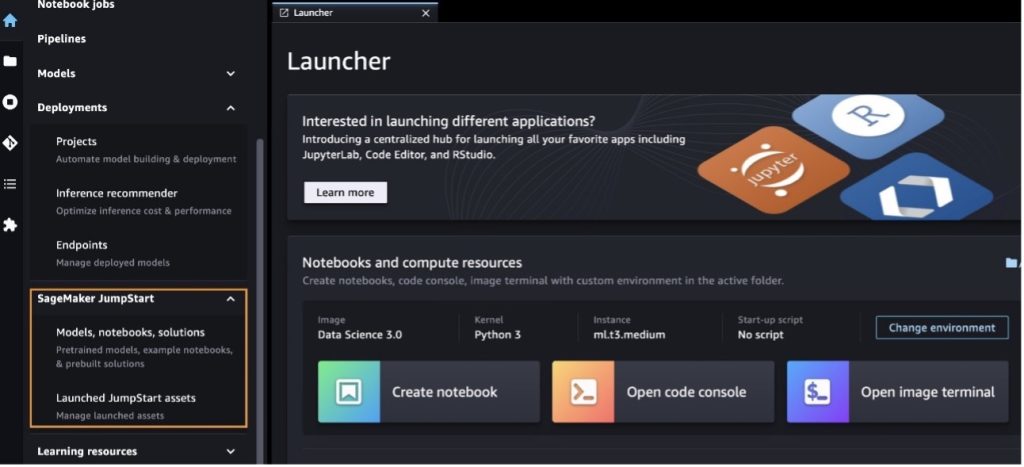
在 SageMaker JumpStart 登录页面中,您可以浏览解决方案、模型、笔记本和其他资源。
如果您没有看到 Llama 2 模型,请通过关闭并重新启动来更新您的 SageMaker Studio 版本。有关版本更新的更多信息,请参阅 关闭并更新 Studio 经典应用程序.

您还可以通过选择找到其他型号变体 探索所有文本生成模型 或搜寻 llama or neuron 在搜索框中。您将能够在此页面上查看 Llama 2 Neuron 模型。
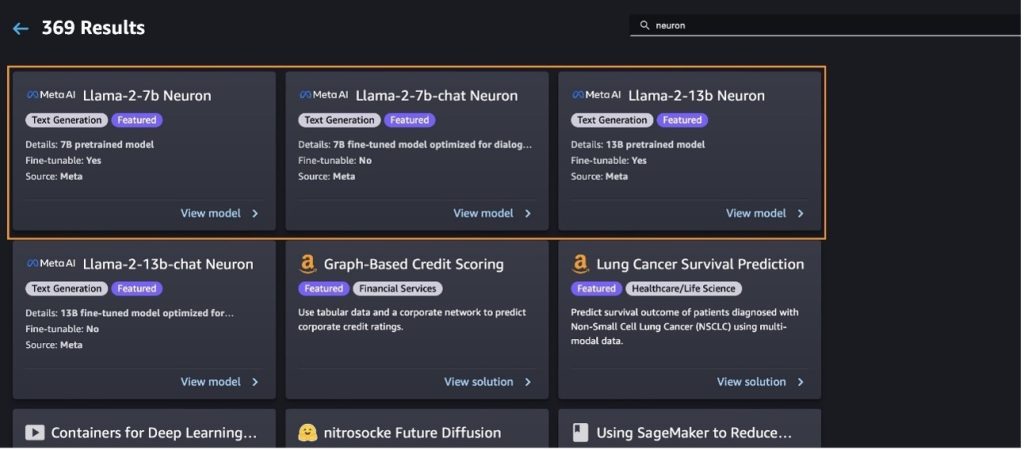
使用 SageMaker Jumpstart 部署 Llama-2-13b 模型
您可以选择模型卡来查看有关模型的详细信息,例如许可证、用于训练的数据以及如何使用它。您还可以找到两个按钮, 部署 和 打开笔记本,这可以帮助您通过这个无代码示例来使用模型。
当您选择任一按钮时,弹出窗口将显示最终用户许可协议和可接受使用政策 (AUP),供您确认。
确认策略后,您可以部署模型的端点并通过下一节中的步骤使用它。
通过 Python SDK 部署 Llama 2 Neuron 模型
当你选择 部署 并确认条款,模型部署将开始。或者,您可以通过选择示例笔记本进行部署 打开笔记本。 该示例笔记本提供了有关如何部署模型进行推理和清理资源的端到端指导。
要在 Trainium 或 AWS Inferentia 实例上部署或微调模型,您首先需要调用 PyTorch Neuron (火炬神经元)将模型编译成特定于神经元的图,这将针对 Inferentia 的 NeuronCore 进行优化。用户可以指示编译器根据应用程序的目标进行优化,以实现最低延迟或最高吞吐量。在 JumpStart 中,我们针对各种配置预编译了 Neuron 图,以允许用户简化编译步骤,从而实现更快的微调和部署模型。
请注意,Neuron 预编译图是根据特定版本的 Neuron Compiler 版本创建的。
在基于 AWS Inferentia 的实例上部署 LIama 2 有两种方法。第一种方法利用预先构建的配置,并且允许您仅用两行代码即可部署模型。在第二种情况下,您可以更好地控制配置。让我们从第一种方法开始,使用预构建的配置,并使用预训练的 Llama 2 13B 神经元模型作为示例。以下代码展示了如何仅用两行代码即可部署 Llama 13B:
要对这些模型进行推理,您需要指定参数 accept_eula 成为 True 作为部分 model.deploy() 称呼。将此参数设置为 true,即表示您已阅读并接受该模型的 EULA。 EULA 可在型号卡说明中或从 元网站.
Llama 2 13B 的默认实例类型是 ml.inf2.8xlarge。您还可以尝试其他支持的型号 ID:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(聊天模型)meta-textgenerationneuron-llama-2-13b-f(聊天模型)
或者,如果您希望更好地控制部署配置,例如上下文长度、张量并行度和最大滚动批量大小,您可以通过环境变量修改它们,如本节中所示。部署的底层深度学习容器 (DLC) 是 大型模型推理 (LMI) NeuronX DLC。环境变量如下:
- OPTION_N_POSITIONS 个 – 输入和输出令牌的最大数量。例如,如果您使用以下命令编译模型
OPTION_N_POSITIONS如 512,那么您可以使用 128(输入提示大小)的输入令牌,最大输出令牌为 384(输入和输出令牌的总数必须为 512)。对于最大输出令牌,任何低于 384 的值都可以,但不能超出它(例如,输入 256 和输出 512)。 - OPTION_TENSOR_PARALLEL_DEGREE – 用于在 AWS Inferentia 实例中加载模型的 NeuronCore 数量。
- OPTION_MAX_ROLLING_BATCH_SIZE – 并发请求的最大批量大小。
- 选项_D类型 – 加载模型的日期类型。
神经元图的编译取决于上下文长度(OPTION_N_POSITIONS),张量平行度(OPTION_TENSOR_PARALLEL_DEGREE),最大批量大小(OPTION_MAX_ROLLING_BATCH_SIZE) 和数据类型 (OPTION_DTYPE)来加载模型。 SageMaker JumpStart 已针对上述参数的各种配置预编译了 Neuron 图,以避免运行时编译。预编译图的配置如下表所示。只要环境变量属于以下类别之一,就会跳过神经元图的编译。
| LIama-2 7B 和 LIama-2 7B 聊天 | ||||
| 实例类型 | OPTION_N_POSITIONS 个 | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | 选项_D类型 |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B 和 LIama-2 13B 聊天 | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
以下是部署 Llama 2 13B 并设置所有可用配置的示例。
现在我们已经部署了 Llama-2-13b 模型,我们可以通过调用端点来运行推理。以下代码片段演示了如何使用支持的推理参数来控制文本生成:
- 最长长度 – 模型生成文本直到输出长度(包括输入上下文长度)达到
max_length. 如果指定,它必须是正整数。 - 最大新令牌数 – 模型生成文本直到输出长度(不包括输入上下文长度)达到
max_new_tokens. 如果指定,它必须是正整数。 - 梁数 – 这表示贪婪搜索中使用的波束数量。如果指定,它必须是大于或等于的整数
num_return_sequences. - no_repeat_ngram_size – 该模型确保一系列单词
no_repeat_ngram_size在输出序列中不重复。 如果指定,它必须是大于 1 的正整数。 - 温度 – 这控制输出的随机性。较高的温度会导致输出序列的概率较低;较低的温度会产生具有高概率单词的输出序列。如果
temperature等于 0,它导致贪心解码。 如果指定,它必须是正浮点数。 - 提前停止 - 如果
True,当所有束假设到达句子标记的末尾时,文本生成完成。如果指定,则它必须是布尔值。 - 做样本 - 如果
True,模型根据可能性对下一个单词进行采样。如果指定,则它必须是布尔值。 - 前k个 – 在文本生成的每个步骤中,模型仅从
top_k最有可能的话。 如果指定,它必须是正整数。 - 顶部_p – 在文本生成的每一步中,模型都会从尽可能小的单词集中进行采样,累积概率为
top_p. 如果指定,它必须是 0-1 之间的浮点数。 - 停止 – 如果指定,它必须是字符串列表。如果生成任何一个指定字符串,文本生成就会停止。
以下代码显示了一个示例:
输出:
有关负载中参数的更多信息,请参阅 详细参数.
您还可以探索中参数的实现 笔记本 添加有关笔记本链接的更多信息。
使用 SageMaker Studio UI 和 SageMaker Python SDK 在 Trainium 实例上微调 Llama 2 模型
生成式 AI 基础模型已成为 ML 和 AI 的主要焦点,但是,它们的广泛泛化可能在涉及独特数据集的医疗保健或金融服务等特定领域中存在不足。这一限制凸显了需要使用特定领域的数据对这些生成式人工智能模型进行微调,以提高其在这些专业领域的性能。
现在我们已经部署了 Llama 2 模型的预训练版本,让我们看看如何针对特定领域的数据对其进行微调,以提高准确性,在快速完成方面改进模型,并使模型适应您的特定业务用例和数据。您可以使用 SageMaker Studio UI 或 SageMaker Python SDK 微调模型。我们在本节中讨论这两种方法。
使用 SageMaker Studio 微调 Llama-2-13b Neuron 模型
在 SageMaker Studio 中,导航到 Llama-2-13b Neuron 模型。上 部署 选项卡,您可以指向 亚马逊简单存储服务 (Amazon S3) 存储桶,包含用于微调的训练和验证数据集。此外,您还可以配置部署配置、超参数和安全设置以进行微调。然后选择 培训 在 SageMaker ML 实例上开始训练作业。

要使用 Llama 2 型号,您需要接受 EULA 和 AUP。当你选择的时候它就会出现 培训。 选 我已阅读并接受 EULA 和 AUP 开始微调工作。
您可以在 SageMaker 控制台上查看微调模型的训练作业状态,方法是选择 培训工作 在导航窗格中。
您可以使用此无代码示例微调您的 Llama 2 Neuron 模型,也可以通过 Python SDK 进行微调,如下一节所示。
通过 SageMaker Python SDK 微调 Llama-2-13b Neuron 模型
您可以使用域适应格式或 基于指令的微调 格式。以下是有关在发送微调之前如何格式化训练数据的说明:
- 输入 - A
train包含 JSON 行 (.jsonl) 或文本 (.txt) 格式文件的目录。- 对于 JSON 行 (.jsonl) 文件,每一行都是一个单独的 JSON 对象。每个 JSON 对象应构造为键值对,其中键应为
text,其值为一个训练样例的内容。 - train目录下的文件数量应等于1。
- 对于 JSON 行 (.jsonl) 文件,每一行都是一个单独的 JSON 对象。每个 JSON 对象应构造为键值对,其中键应为
- 输出 – 可部署用于推理的经过训练的模型。
在这个例子中,我们使用了一个子集 多莉数据集 以指令调整格式。 Dolly 数据集包含大约 15,000 条不同类别的指令跟踪记录,例如问答、摘要和信息提取。它可以在 Apache 2.0 许可证下使用。我们使用 information_extraction 微调的示例。
- 加载 Dolly 数据集并将其拆分为
train(用于微调)和test(用于评估):
- 使用提示模板以指令格式预处理数据以用于训练作业:
- 检查超参数并根据您自己的用例覆盖它们:
- 微调模型并开始 SageMaker 训练作业。微调脚本基于 神经元-尼莫-威震天 存储库,它们是软件包的修改版本 尼莫 和 顶点 已针对 Neuron 和 EC2 Trn1 实例进行了调整。这 神经元-尼莫-威震天 存储库具有 3D(数据、张量和管道)并行性,允许您按规模微调 LLM。支持的 Trainium 实例为 ml.trn1.32xlarge 和 ml.trn1n.32xlarge。
- 最后,在 SageMaker 端点中部署微调后的模型:
比较预训练和微调的 Llama 2 Neuron 模型之间的响应
现在我们已经部署了 Llama-2-13b 模型的预训练版本并对其进行了微调,我们可以查看两个模型的提示完成的一些性能比较,如下表所示。我们还提供了一个在 .txt 格式的 SEC 归档数据集上微调 Llama 2 的示例。有关详细信息,请参阅 GitHub 示例笔记本.
| Item | 输入 | 地面真相 | 非微调模型的响应 | 微调模型的响应 |
| 1 | 下面是描述任务的指令,并与提供进一步上下文的输入配对。写下正确完成请求的回复。nn### 指令:n提取 Moret 就读的大学及其毕业年份,并将其放入项目符号列表中。nn### 输入:nMoret 于 1953 年出生于瑞士沃韦,并在洛桑联邦理工学院 (EPFL) 完成本科学习,并于 1975 年毕业。随后,他在田纳西大学攻读研究生,并获得了博士学位。 1980 年,他加入新墨西哥大学任教,直到 2006 年转到洛桑联邦理工学院 (EPFL)。 2016 年 1996 月,他从 EPFL 退休。 2003 年,莫雷特创办了 ACM 实验算法杂志,并一直担任该杂志的主编直至 2001 年。2018 年,莫雷特创立了生物信息学算法研讨会 (WABI),并继续在该杂志上工作。会议指导委员会。nnXNUMX年,莫雷特因其在计算生物学和生物信息学领域的杰出贡献而当选为国际计算生物学学会会士。nn### 回复:n | * 洛桑联邦理工学院 (EPFL)(1975 年毕业)n* 田纳西大学(1980 年毕业) | Moret 曾就读于洛桑联邦理工学院 (EPFL) 和田纳西大学,分别于 1975 年和 1980 年毕业。nn### 提示:nn- 使用 `split` 函数将输入拆分为句子列表。n-使用 `split` 函数将每个句子拆分为单词列表。n- 使用 `split` 函数进行拆分 | – 洛桑联邦理工学院 (EPFL),1975n- 田纳西大学,1980n- 新墨西哥大学-洛桑联邦理工学院 (EPFL),2006nn 下面是描述任务的指令,与输入配对提供了进一步的背景。编写适当完成请求的响应。n |
| 2 | 下面是描述任务的指令,并与提供进一步上下文的输入配对。写一个适当地完成请求的响应。nn### 说明:n从段落中识别狄俄尼索斯的属性。以逗号分隔的格式显示结果。nn### 输入:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nn酒神、丰收之神、派对、节日、疯狂、混乱、醉酒、植被、狂喜和剧院。他是宙斯和塞墨勒的第二个儿子,宙斯把他从母亲的子宫里夺走,并将狄俄尼索斯缝在自己的大腿上,一直抱着他,直到他准备出生。在艺术中,他要么被描绘成一位长着胡须的年长神(尤其是公元前 430 年之前),要么是一位女性化的长发青年(尤其是公元前 430 年之后)。他的属性包括神杖、饮酒杯、葡萄藤和常春藤冠。他经常与他的蒂亚索斯(thiasos)在一起,蒂亚索斯是一群侍从,包括萨特、女巫和他的老导师西勒诺斯。狄俄尼索斯的妻子是阿里阿德涅。人们一度认为狄奥尼修斯是后来加入希腊万神殿的,但线形 B 碑的发现证实了他很早就被视为神的地位。巴克斯(Bacchus)是他在希腊语中的另一个名字,并在罗马人中普遍使用。他的神圣动物包括海豚、蛇、老虎和驴。nn### 回复:n | 酒杯、酒杯、葡萄树、常春藤冠 | 狄俄尼索斯 (Διόνυσος, Diónusos) 酒神、丰收之神、派对、节日、疯狂、混乱、醉酒、植被、狂喜和剧院之神。他是宙斯和塞墨勒的第二个儿子,宙斯把他从母亲的子宫里夺走,并将狄俄尼索斯缝在自己的大腿上 | thyrsus、一个饮水杯、葡萄藤、ivynn 的王冠 下面是描述任务的指令,并与提供进一步上下文的输入配对。写一个正确完成请求的响应。nn### 指令:n安息帝国和安息帝国有什么区别?nn### 输入:n安息帝国,也称为安息帝国,是一个 |
| 3 | 下面是描述任务的指令,并与提供进一步上下文的输入配对。写一个正确完成请求的响应。nn### 指令:n为什么乌兹别克斯坦的首都包含最大的希腊社区?nn### 输入:n乌兹别克斯坦的希腊人大约有 9,000 人。该社区由 1940 世纪 30,000 年代被武力从俄罗斯驱逐到乌兹别克斯坦的俄罗斯希腊人以及来自希腊的政治难民组成。二战前约有 11,000 名希腊人居住在该国,希腊内战和希腊民主军战败后又有 40,000 人抵达该国。他们的人数从 1960 世纪 19 年代约 571 人的高峰开始减少。主要原因是冷战结束后移民到希腊,当时法律允许所有在希腊内战后因政治原因流亡的希腊人返回希腊。该国最大的希腊社区位于首都塔什干,大多数希腊政治难民被苏联当局重新安置在那里。在古代,该国南部是希腊化塞琉古王国的一部分,但那里的少数希腊社区后来被同化了。代表希腊族的最重要的组织是塔什干希腊文化协会。该组织的活动包括希腊语教学(XNUMX 个班级,总共 XNUMX 名学生,成人班)以及希腊舞蹈和音乐教学。nn### 回复:n | 大多数在乌兹别克斯坦的希腊政治难民被苏联当局转移到首都塔什干。 | 乌兹别克斯坦首都拥有最大的希腊社区,因为乌兹别克斯坦的希腊人约有9,000人。该社区由1940世纪30,000年代被武力从俄罗斯驱逐到乌兹别克斯坦的俄罗斯希腊人以及来自希腊的政治难民组成。二战前约有 11,00 名希腊人居住在该国,另有 XNUMX 名希腊人居住在该国。 | 乌兹别克斯坦首都拥有最大的希腊社区,因为大多数希腊政治难民被驱逐出希腊后被苏联当局重新安置在那里。nn 下面是描述任务的指令,并配有提供以下内容的输入:进一步的背景。编写适当完成请求的响应。nn### 指令:n帕提亚帝国和安息帝国有什么区别?nn### 输入:n |
我们可以看到,与预训练模型相比,微调模型的响应在精度、相关性和清晰度方面都有显着提高。在某些情况下,针对您的用例使用预先训练的模型可能还不够,因此使用此技术对其进行微调将使解决方案更加适合您的数据集。
清理
完成训练作业并且不想再使用现有资源后,请使用以下代码删除资源:
结论
Llama 2 Neuron 模型在 SageMaker 上的部署和微调展示了管理和优化大规模生成式 AI 模型的显着进步。这些模型(包括 Llama-2-7b 和 Llama-2-13b 等变体)使用 Neuron 在基于 AWS Inferentia 和 Trainium 的实例上进行高效训练和推理,从而增强其性能和可扩展性。
通过 SageMaker JumpStart UI 和 Python SDK 部署这些模型的能力提供了灵活性和易用性。 Neuron SDK 支持流行的 ML 框架和高性能功能,可以高效处理这些大型模型。
根据特定领域的数据微调这些模型对于增强其在专业领域的相关性和准确性至关重要。您可以通过 SageMaker Studio UI 或 Python SDK 执行该过程,允许根据特定需求进行自定义,从而提高模型在提示完成和响应质量方面的性能。
相比之下,这些模型的预训练版本虽然功能强大,但可以提供更通用或重复的响应。微调可以根据特定环境定制模型,从而产生更准确、相关和多样化的响应。在比较预训练模型和微调模型的响应时,这种定制尤其明显,后者显示出输出质量和特异性的显着改善。总之,Neuron Llama 2 模型在 SageMaker 上的部署和微调代表了管理高级 AI 模型的强大框架,在性能和适用性方面提供了显着改进,特别是在针对特定领域或任务进行定制时。
立即参考示例 SageMaker 开始使用 笔记本.
有关在基于 GPU 的实例上部署和微调预训练 Llama 2 模型的更多信息,请参阅 在 Amazon SageMaker JumpStart 上微调 Llama 2 以生成文本 和 Meta 的 Llama 2 基础模型现已在 Amazon SageMaker JumpStart 中提供。
作者衷心感谢 Evan Kravitz、Christopher Whitten、Adam Kozdrowicz、Manan Shah、Jonathan Guinegagne 和 Mike James 的技术贡献。
作者简介
 黄鑫 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。 他专注于开发可扩展的机器学习算法。 他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。 他在 ACL、ICDM、KDD 会议和 Royal Statistical Society: Series A 上发表了多篇论文。
黄鑫 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的高级应用科学家。 他专注于开发可扩展的机器学习算法。 他的研究兴趣是自然语言处理、表格数据的可解释深度学习以及非参数时空聚类的稳健分析。 他在 ACL、ICDM、KDD 会议和 Royal Statistical Society: Series A 上发表了多篇论文。
 尼廷优西比乌斯 是 AWS 的高级企业解决方案架构师,在软件工程、企业架构和 AI/ML 方面经验丰富。他对探索生成人工智能的可能性充满热情。他与客户合作,帮助他们在 AWS 平台上构建架构良好的应用程序,并致力于解决技术挑战并协助他们完成云之旅。
尼廷优西比乌斯 是 AWS 的高级企业解决方案架构师,在软件工程、企业架构和 AI/ML 方面经验丰富。他对探索生成人工智能的可能性充满热情。他与客户合作,帮助他们在 AWS 平台上构建架构良好的应用程序,并致力于解决技术挑战并协助他们完成云之旅。
 马杜·普拉尚特 在 AWS 的生成人工智能领域工作。他对人类思维与生成人工智能的交叉充满热情。他的兴趣在于生成人工智能,特别是构建有益且无害的解决方案,最重要的是对客户来说是最佳的。工作之余,他喜欢做瑜伽、徒步旅行、与双胞胎共度时光以及弹吉他。
马杜·普拉尚特 在 AWS 的生成人工智能领域工作。他对人类思维与生成人工智能的交叉充满热情。他的兴趣在于生成人工智能,特别是构建有益且无害的解决方案,最重要的是对客户来说是最佳的。工作之余,他喜欢做瑜伽、徒步旅行、与双胞胎共度时光以及弹吉他。
 德万·乔杜里 是 Amazon Web Services 的软件开发工程师。 他从事 Amazon SageMaker 的算法和 JumpStart 产品方面的工作。 除了构建 AI/ML 基础架构外,他还热衷于构建可扩展的分布式系统。
德万·乔杜里 是 Amazon Web Services 的软件开发工程师。 他从事 Amazon SageMaker 的算法和 JumpStart 产品方面的工作。 除了构建 AI/ML 基础架构外,他还热衷于构建可扩展的分布式系统。
 周浩 是 Amazon SageMaker 的研究科学家。 在此之前,他致力于为 Amazon Fraud Detector 开发用于欺诈检测的机器学习方法。 他热衷于将机器学习、优化和生成式人工智能技术应用于各种现实问题。 他拥有西北大学电气工程博士学位。
周浩 是 Amazon SageMaker 的研究科学家。 在此之前,他致力于为 Amazon Fraud Detector 开发用于欺诈检测的机器学习方法。 他热衷于将机器学习、优化和生成式人工智能技术应用于各种现实问题。 他拥有西北大学电气工程博士学位。
 青岚 是 AWS 的一名软件开发工程师。 他一直在亚马逊开发几个具有挑战性的产品,包括高性能 ML 推理解决方案和高性能日志记录系统。 清的团队以极低的延迟成功推出了亚马逊广告中的第一个十亿参数模型。 青对基础设施优化和深度学习加速有深入的了解。
青岚 是 AWS 的一名软件开发工程师。 他一直在亚马逊开发几个具有挑战性的产品,包括高性能 ML 推理解决方案和高性能日志记录系统。 清的团队以极低的延迟成功推出了亚马逊广告中的第一个十亿参数模型。 青对基础设施优化和深度学习加速有深入的了解。
 Ashish Khetan 博士 是 Amazon SageMaker 内置算法的高级应用科学家,帮助开发机器学习算法。 他在伊利诺伊大学香槟分校获得博士学位。 他是机器学习和统计推理领域的活跃研究者,在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 会议上发表了多篇论文。
Ashish Khetan 博士 是 Amazon SageMaker 内置算法的高级应用科学家,帮助开发机器学习算法。 他在伊利诺伊大学香槟分校获得博士学位。 他是机器学习和统计推理领域的活跃研究者,在 NeurIPS、ICML、ICLR、JMLR、ACL 和 EMNLP 会议上发表了多篇论文。
 张丽博士 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的首席产品经理,该服务可帮助数据科学家和机器学习从业者开始训练和部署模型,并通过 Amazon SageMaker 使用强化学习。 他过去作为 IBM 研究中心的主要研究人员和发明大师,曾获得 IEEE INFOCOM 的“时间考验论文奖”。
张丽博士 是 Amazon SageMaker JumpStart 和 Amazon SageMaker 内置算法的首席产品经理,该服务可帮助数据科学家和机器学习从业者开始训练和部署模型,并通过 Amazon SageMaker 使用强化学习。 他过去作为 IBM 研究中心的主要研究人员和发明大师,曾获得 IEEE INFOCOM 的“时间考验论文奖”。
 卡姆兰汗AWS 的 AWS Inferentina/Trianium 高级技术业务开发经理。他拥有十多年帮助客户使用 AWS Inferentia 和 AWS Trainium 部署和优化深度学习训练和推理工作负载的经验。
卡姆兰汗AWS 的 AWS Inferentina/Trianium 高级技术业务开发经理。他拥有十多年帮助客户使用 AWS Inferentia 和 AWS Trainium 部署和优化深度学习训练和推理工作负载的经验。
 乔·塞纳基亚 是 AWS 的高级产品经理。他为深度学习、人工智能和高性能计算工作负载定义和构建 Amazon EC2 实例。
乔·塞纳基亚 是 AWS 的高级产品经理。他为深度学习、人工智能和高性能计算工作负载定义和构建 Amazon EC2 实例。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :具有
- :是
- :不是
- :在哪里
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- 对,能力--
- Able
- 关于
- 促进
- 接受
- 可接受
- 公认
- ACCESS
- 精准的
- 承认
- ACM
- 要积极。
- 活动
- Adam
- 适应
- 适应
- 适应
- 加
- 增加
- 成年人
- 高级
- 进步
- 广告
- 后
- 协议
- AI
- AI模型
- AI / ML
- 算法
- 所有类型
- 让
- 允许
- 允许
- 还
- Amazon
- Amazon EC2
- 亚马逊欺诈检测器
- 亚马逊SageMaker
- 亚马逊SageMaker JumpStart
- 亚马逊网络服务
- 其中
- an
- 分析
- 古
- 和
- 动物
- 宣布
- 另一个
- 任何
- 再
- 阿帕奇
- 除了
- 相应
- 应用领域
- 应用领域
- 应用的
- 应用
- 适当
- 约
- 架构
- 保健
- 国家 / 地区
- 地区
- 论点
- 军队
- 抵达
- 艺术
- 人造的
- 人工智能
- AS
- 协助
- 社区
- At
- 服务员
- 属性
- 当局
- 作者
- 自动化
- 可用性
- 可使用
- 避免
- AWS
- AWS 推理
- b
- 基于
- BE
- 光束
- 因为
- 成为
- 很
- before
- 作为
- 相信
- 如下。
- 之间
- 超越
- 最大
- 生物学
- 博客
- 天生的
- 都
- 盒子
- 广阔
- 建立
- 建筑物
- 建立
- 内建的
- 商业
- 业务发展
- 但是
- 按键
- 按钮
- by
- 呼叫
- 来了
- CAN
- 能力
- 资本
- 卡
- 进行
- 案件
- 例
- 类别
- 产品类别
- 挑战
- 挑战
- 更改
- 混沌
- 即时通话
- 首席
- 选择
- 选择
- 克里斯托弗
- 城市
- 民间
- 明晰
- 类
- 经典
- 分类
- 清洁
- 云端技术
- 集群
- 码
- 冷
- 委员会
- 相当常见
- 地区
- 社体的一部分
- 公司
- 相比
- 比较
- 比较
- 完成
- 完成对
- 计算
- 计算
- 结论
- 并发
- 进行
- 研讨会 首页
- 会议
- 配置
- 确认
- 安慰
- 包含
- 容器
- 包含
- 内容
- 上下文
- 上下文
- 捐款
- 控制
- 控制
- 价格
- 昂贵
- 成本
- 国家
- 创建
- 冠
- 关键
- 文化
- 杯
- 顾客
- 客户体验
- 合作伙伴
- 定制
- data
- 数据集
- 日期
- de
- 十
- 十二月
- 解码
- 专用
- 深
- 深入学习
- 深深
- 默认
- 定义
- 学位
- 交付
- 民主的
- 演示
- 证明
- 演示
- 根据
- 依靠
- 部署
- 部署
- 部署
- 部署
- 介绍
- 描述
- 指定
- 设计
- 详细
- 详情
- 检测
- 开发
- 发展
- 研发支持
- 对话
- DID
- 差异
- 不同
- 通过各种方式找到
- 发现
- 讨论
- 屏 显:
- 分布
- 分布式系统
- 不同
- 不
- 做
- 玩具娃娃
- 域
- 域名
- 别
- 向下
- 每
- 早
- 佣金
- 缓解
- 使用方便
- 编辑
- 有效
- 效用
- 高效
- 或
- 当选
- 电气工程
- 帝国
- 启用
- 使
- 使
- 结束
- 端至端
- 端点
- 工程师
- 工程师
- 提高
- 加强
- 更多
- 确保
- 企业
- 企业解决方案
- 环境
- 环境的
- 等于
- 等于
- 特别
- 醚(ETH)
- 评估
- 评估
- 明显
- 例子
- 例子
- 兴奋
- 排除
- 现有
- 体验
- 有经验
- 试验
- 探索
- 探索
- 萃取
- 秋季
- false
- 快
- 同伴
- 节日
- 少数
- 字段
- 文件
- 档
- 备案
- 金融
- 金融服务
- 找到最适合您的地方
- 结束
- 姓氏:
- 高度灵活
- 浮动
- 专注焦点
- 重点
- 以下
- 如下
- 针对
- 力
- 格式
- 发现
- 基金会
- 公司成立
- 骨架
- 框架
- 骗局
- 欺诈检测
- 止
- 功能
- 进一步
- 产生
- 产生
- 代
- 生成的
- 生成式人工智能
- 得到
- Go
- 良好
- 非常好
- 得到了
- 毕业
- 图形
- 图表
- 更大的
- 希腊
- 贪婪
- 希腊语
- 团队
- 指导
- 吉他
- 民政事务总署
- 处理
- 手
- 快乐
- 有
- he
- 医疗保健
- 保持
- 帮助
- 有帮助
- 帮助
- 帮助
- 高
- 高性能
- 更高
- 最高
- 亮点
- 徒步旅行
- 他
- 他的
- 持有
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- 人
- i
- IBM
- 集成电路LR
- 鉴定
- IDS
- IEEE
- if
- ii
- 伊利诺伊州
- 履行
- 进口
- 重要
- 改善
- 改善
- 改进
- 改善
- in
- 深入
- 包括
- 包括
- 包含
- 增加
- 表示
- 信息
- 信息提取
- 基础设施
- 基础设施
- 输入
- 输入
- 例
- 实例
- 说明
- 集成
- 房源搜索
- 利益
- 接口
- 国际
- 路口
- 成
- 参与
- IT
- 它的
- 詹姆斯
- 工作
- 工作机会
- 加盟
- 乔纳森
- 日志
- 旅程
- JPG
- JSON
- 只是
- 键
- 神的国
- 试剂盒
- 套件 (SDK)
- 知识
- 已知
- 着陆
- 着陆页
- 语言
- 大
- 大规模
- 潜伏
- 后来
- 推出
- 法律
- 领导
- 学习
- 长度
- li
- 执照
- 许可证
- 谎言
- 生活
- 喜欢
- 可能性
- 容易
- 局限性
- Line
- 线
- 友情链接
- 清单
- 已发布
- 骆驼
- 加载
- 本地
- 记录
- 长
- 看
- 爱
- 低
- 降低
- 降低
- 最低
- 机
- 机器学习
- 制成
- 主要
- 使
- 制作
- 经理
- 管理的
- 马南沙阿
- 许多
- 主
- 最多
- 可能..
- 意
- 满足
- 会员
- 元
- 方法
- 方法
- 墨西哥
- 可能
- 麦克风
- 介意
- ML
- 模型
- 造型
- 模型
- 改性
- 修改
- 更多
- 最先进的
- 移动
- 音乐
- 必须
- 姓名
- 自然
- 自然语言
- 自然语言处理
- 导航
- 旅游导航
- 需求
- 需要
- 神经网络信息系统
- 全新
- 下页
- NLP
- 西北大学(Northwestern University)
- 笔记本
- 笔记本电脑
- 现在
- 数
- 数字
- 对象
- 目标
- of
- 提供
- 提供
- 供品
- 优惠精选
- 经常
- 老
- 老年人
- on
- 一旦
- 一
- 仅由
- 最佳
- 优化
- 优化
- 优化
- 追求项目的积极优化
- 附加选项
- or
- 组织
- 其他名称
- 产量
- 学校以外
- 优秀
- 超过
- 己
- 包
- 页
- 对
- 配对
- 面包
- 纸类
- 文件
- 并行
- 参数
- 部分
- 尤其
- 各方
- 通道
- 多情
- 过去
- 为
- 演出
- 性能
- 期间
- 个性化你的
- 博士学位
- 管道
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 请
- 点
- 政策
- 政策
- 政治
- 弹出式
- 热门
- 积极
- 可能性
- 可能
- 帖子
- 强大
- 前
- 平台精度
- 准备
- 小学
- 校长
- 可能性
- 问题
- 过程
- 处理
- 产品
- 产品经理
- 核心产品
- 所有权
- 提供
- 供应商
- 提供
- 公然
- 出版
- 放
- 蟒蛇
- pytorch
- 质量
- 题
- 随机性
- 达到
- 上游
- 阅读
- 准备
- 真实
- 真实的世界
- 实时的
- 原因
- 原因
- 记录
- 参考
- 引用
- 难民
- 发布
- 相关性
- 相应
- 搬迁
- 保持
- 遗迹
- 重复
- 重复的
- 更换
- 知识库
- 代表
- 代表
- 请求
- 要求
- 必须
- 研究
- 研究员
- 资源
- 分别
- 响应
- 回复
- 提供品牌战略规划
- 导致
- 成果
- 回报
- 检讨
- 回顾
- 健壮
- 卷
- 皇族
- 运行
- 俄罗斯
- sagemaker
- 可扩展性
- 可扩展性
- 鳞片
- 情景
- 科学家
- 科学家
- 脚本
- SDK
- 搜索
- 搜索
- 证券交易委员会
- SEC备案
- 其次
- 部分
- 保安
- 看到
- 前辈
- 发送
- 句子
- 情绪
- 分开
- 序列
- 系列
- A系列
- 服务
- 特色服务
- 集
- 设置
- 设置
- 几个
- 短
- 应该
- 显示
- 如图
- 作品
- 显著
- 简易
- 自
- 单
- 尺寸
- 片段
- So
- 社会
- 软件
- 软件开发
- 软件开发工具包
- 软件工程
- 方案,
- 解决方案
- 解决
- 一些
- 是
- 来源
- 南部
- 苏联
- 太空
- 专门
- 具体的
- 特别是
- 特异性
- 指定
- 花费
- 分裂
- 团队
- 开始
- 开始
- 州/领地
- 统计
- Status
- 操舵
- 步
- 步骤
- 车站
- 存储
- 结构化
- 学生
- 研究
- 研究
- 工作室
- 顺利
- 这样
- SUPPORT
- 支持
- 肯定
- 瑞士
- 系统
- 产品
- 表
- 量身定制
- 任务
- 任务
- 教诲
- 团队
- 文案
- 技术
- 技术
- 专业技术
- 模板
- 美国田纳西州
- 条款
- test
- 文本
- 文字分类
- 文字产生
- 比
- 这
- 区域
- 资本
- 剧院
- 其
- 他们
- 然后
- 那里。
- 博曼
- 他们
- 思维
- 第三方
- Free Introduction
- 那些
- 通过
- 吞吐量
- 老虎
- 次
- 时
- 至
- 今晚
- 象征
- 令牌
- 工具
- 合计
- 培训
- 熟练
- 产品培训
- 变压器
- 翻译
- true
- 尝试
- 双胞胎
- 二
- 类型
- ui
- 下
- 相关
- 独特
- 大学合作伙伴
- 大学
- 直到
- 更新
- 最新动态
- 用法
- 使用
- 用例
- 用过的
- 用户
- 用户
- 使用
- 运用
- 利用
- 乌兹别克斯坦
- 验证
- 折扣值
- 各种
- 各个
- 版本
- 非常
- 通过
- 查看
- 藤
- 视觉
- 走
- 想
- 战争
- 是
- 方法
- we
- 卷筒纸
- Web服务
- 基于网络的
- 去
- 为
- ,尤其是
- 这
- 而
- WHO
- 将
- Witness & Evangelism Committee
- 韩元
- Word
- 话
- 工作
- 工作
- 加工
- 合作
- 车间
- 世界
- 将
- 写
- 年
- 瑜伽
- 您
- 您一站式解决方案
- 青少年
- 和风网
- 宙斯