在当今世界,客户管理着自己的大量数据 亚马逊简单存储服务 (Amazon S3) 数据湖,需要复杂的数据管道来持续了解数据布局的变化并将其提供给消费系统。 AWS胶水 爬网程序提供了一种在 AWS Glue 数据目录中对数据进行编目的简单方法,从而消除了架构管理和数据分类方面的繁重工作。 AWS Glue 爬网程序从 Amazon S3 中提取数据架构和分区,以自动填充数据目录,从而保持元数据最新。
但随着数据随着时间的推移呈指数增长,给定表中的分区数量可能会显着增加。 因为分析服务例如 亚马逊雅典娜 查询包含数百万个分区的表时,检索分区所需的时间会增加,并可能导致查询运行时间增加。
如今,AWS Glue 爬网程序支持已扩展为自动为新发现的表添加分区索引,以优化分区数据集的查询处理。 现在,当爬网程序在爬网程序运行期间创建新的数据目录表时,它还会默认创建一个分区索引,并以所有数字和字符串类型分区列的最大排列作为键。 然后,数据目录根据这些键创建可搜索索引,从而减少在具有数百万个分区的表上检索和过滤分区元数据所需的时间。 分区索引的创建有利于 Athena 上运行的分析工作负载, 亚马逊电子病历, 亚马逊红移频谱和 AWS Glue。
在本文中,我们介绍如何使用 AWS Glue 爬网程序创建分区索引,并比较使用和不使用 Athena 分区索引访问爬网数据时的查询性能改进。
解决方案概述
我们使用 AWS CloudFormation 模板来创建我们的解决方案资源。 在以下步骤中,我们演示如何配置 AWS Glue 爬网程序以使用 AWS Glue 控制台或 AWS命令行界面 (AWS CLI)。 然后我们比较使用 Athena 的查询性能改进。
先决条件
要跟随这篇文章,您必须有权访问 AWS身份和访问管理 (IAM) 管理员角色,使用 AWS CloudFormation 创建资源。
设置您的解决方案资源
CloudFormation 模板生成以下资源:
- IAM角色和政策
- 用于保存架构的 AWS Glue 数据库
- 指向高度分区数据集的 AWS Glue 爬网程序
- 用于存储查询结果的 Athena 工作组和存储桶
请完成以下步骤来设置解决方案资源:
- 登录到 AWS管理控制台 作为 IAM 管理员。
- 启动堆栈 部署 CloudFormation 模板:

- 针对 数据库名称,保留默认值
blog_partition_index_crawlerdb.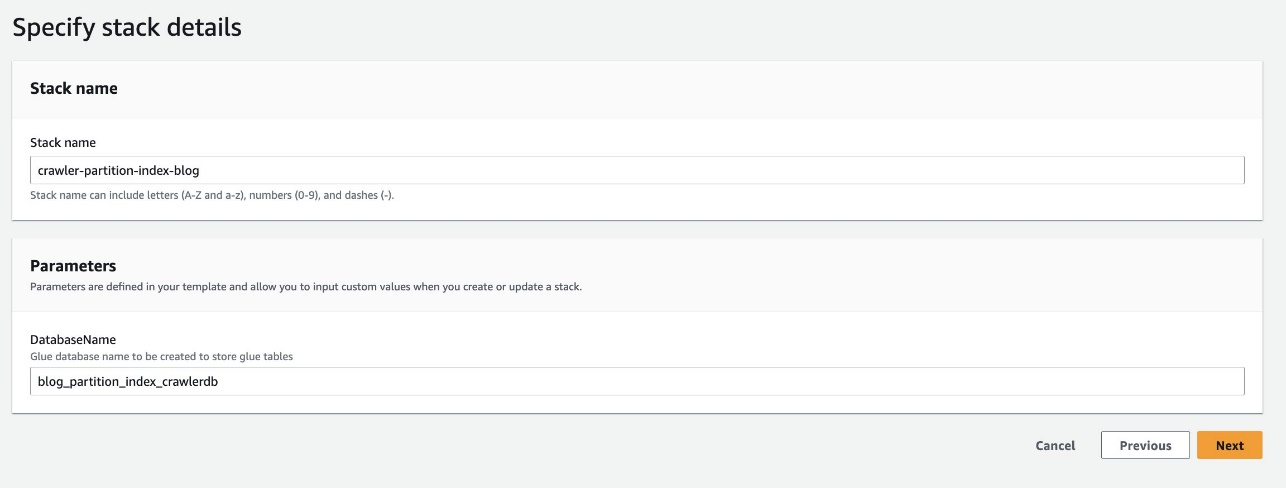
- 下一页.
- 查看最后一页上的详细信息并选择 我承认AWS CloudFormation可能会创建IAM资源.
- 创建堆栈.
- 堆栈完成后,在 AWS CloudFormation 控制台上,导航到 输出 堆栈的标签。
- 记下以下值
DatabaseName和GlueCrawlerName.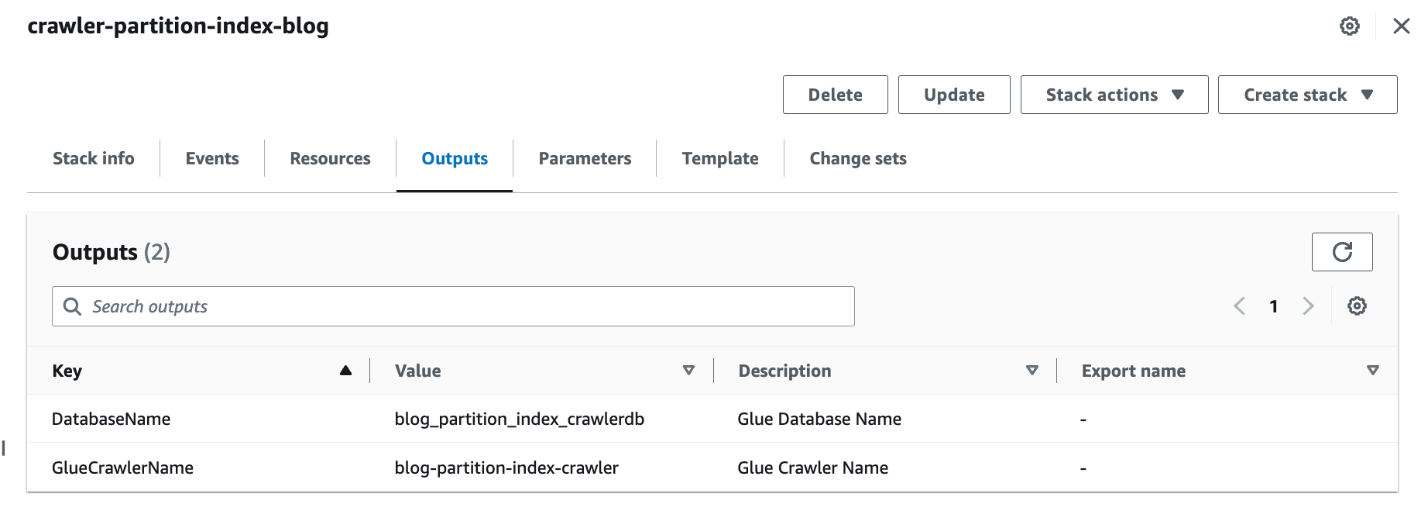
该堆栈部署的某些资源在使用时会产生成本。
编辑并运行 AWS Glue 爬虫
要配置和运行 AWS Glue 爬网程序,请完成以下步骤:
- 在 AWS Glue 控制台上,选择 爬行 在导航窗格中。
- 找到
crawler blog-partition-index-crawler并选择 编辑.
- 在 设置输出和调度 部分,下 高级选项, 选择 自动创建分区索引.
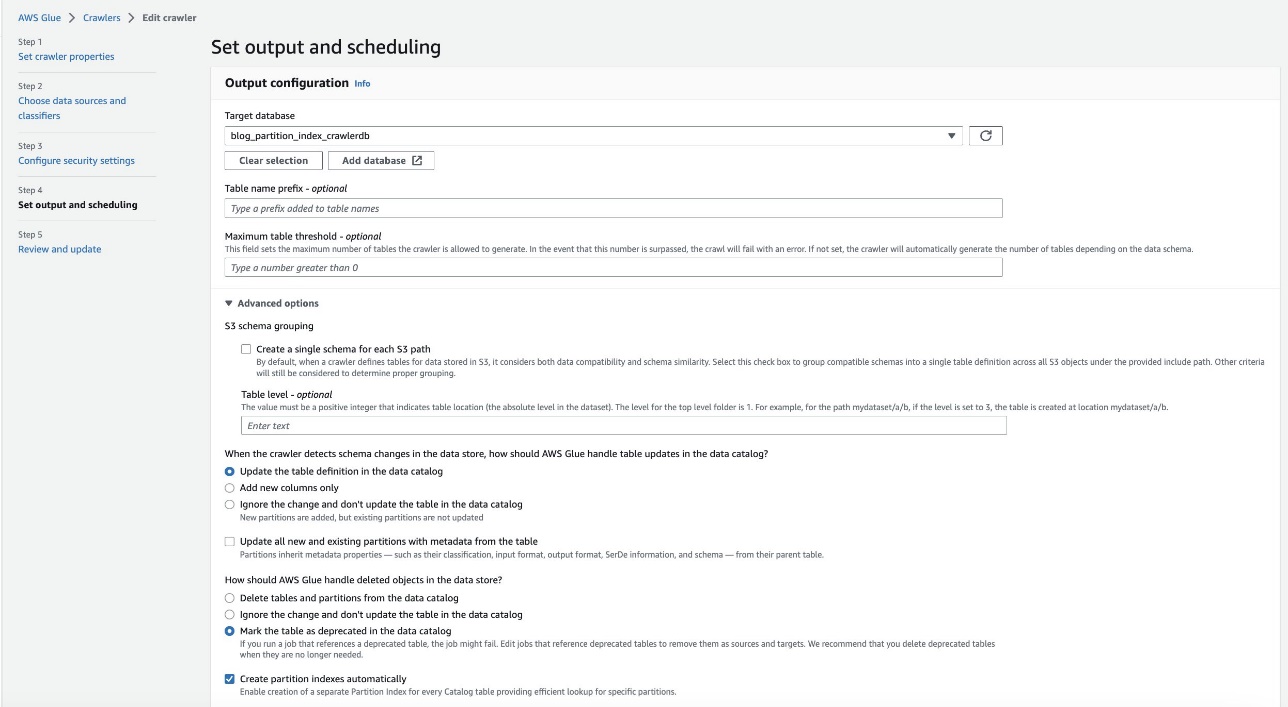
- 查看并更新爬网程序设置。
或者,您可以使用 AWS CLI 配置爬网程序(提供您的 IAM 角色和区域):
- 现在运行爬网程序并验证爬网程序运行是否已完成。
这是高度分区的数据集,大约需要 90 分钟才能完成。
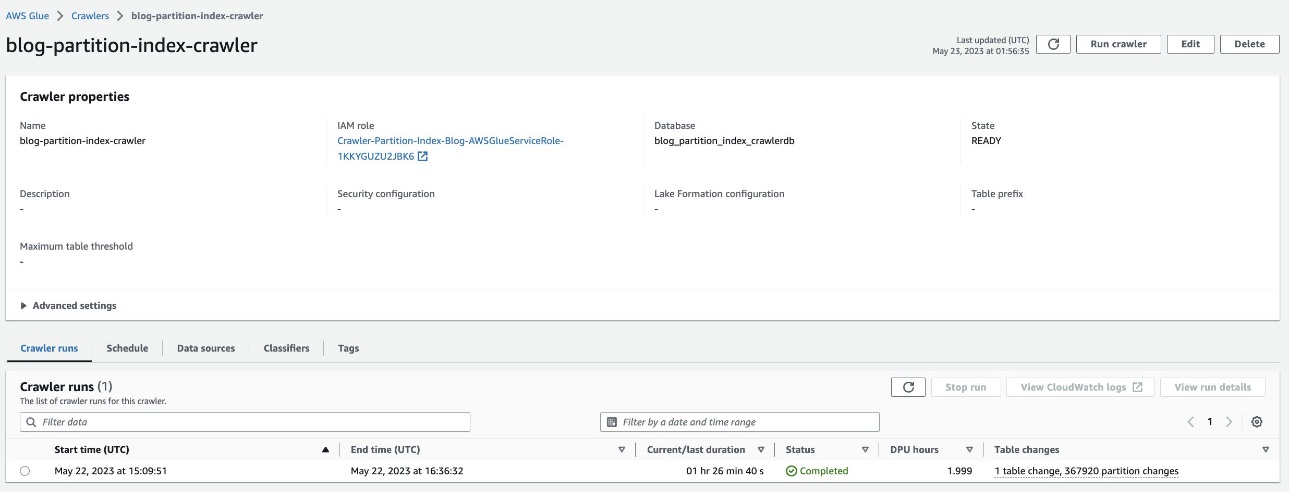
验证分区表
在 AWS Glue 数据库中 blog_partition_index_crawlerdb,验证该表 highly_partitioned_table 。
默认情况下,爬网程序根据有效列类型的分区列的最大排列(与分区列的顺序相同)来确定索引,分区列可以是数字或字符串。 对于爬虫创建的表(highly_partitioned_table),我们有分区列 year (串), month (串), day (字符串),和 hour (细绳)。
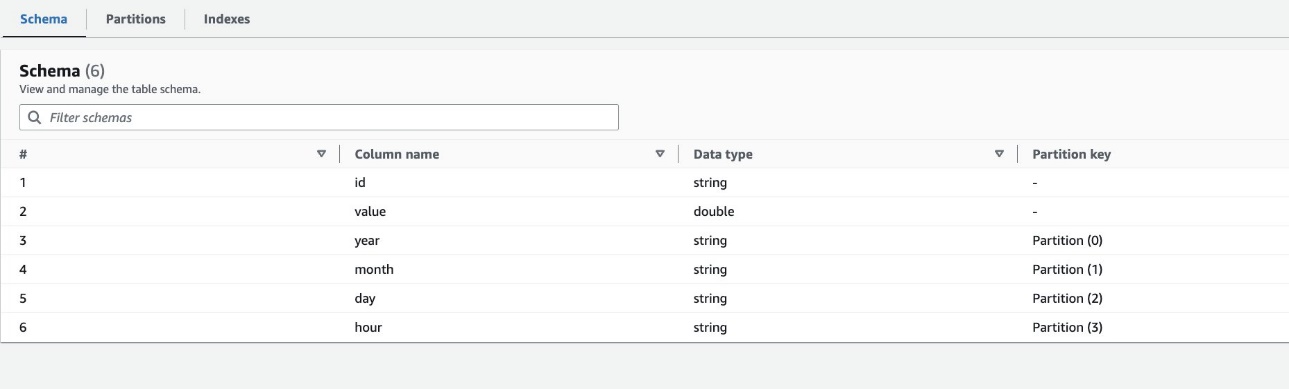
根据这个定义,爬虫创建了年、月、日、小时排列的索引。 爬虫创建了前缀为的索引 crawler_ 在默认创建的任何分区索引上。
通过导航到表来验证相同的内容 highly_partitioned_table 在 AWS Glue 控制台上并选择 指数 标签。
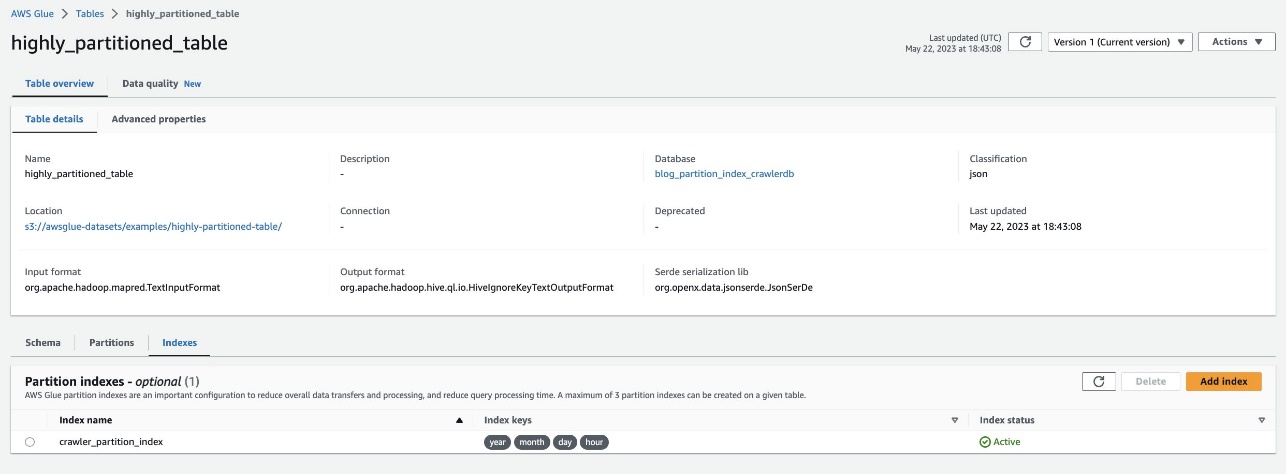
爬网程序能够爬网 S3 数据源并成功填充表的分区索引。
比较使用 Athena 的查询性能改进
首先,我们在 Athena 中查询表,不使用分区索引。 要使用 Athena 验证表,请完成以下步骤:
- 在Athena控制台上,选择
crawler-primary-workgroup作为 Athena 工作组并选择 确认.
- 运行以下查询:
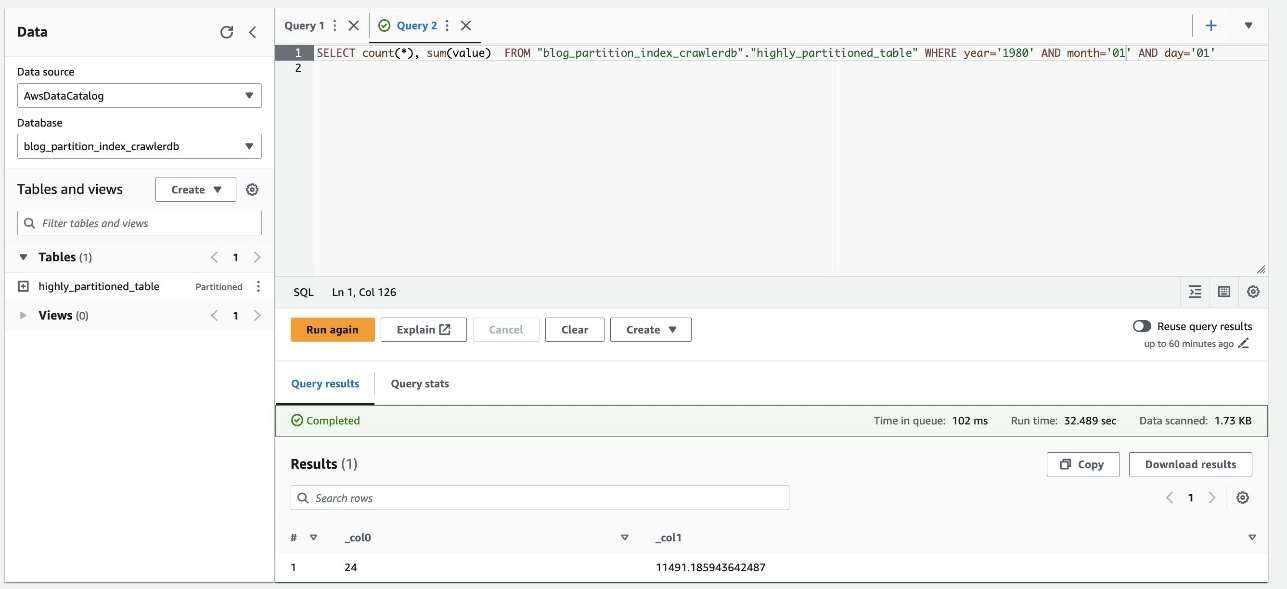
以下屏幕截图显示,在未使用分区索引启用过滤的情况下,查询大约花费了 32 秒。
- 现在我们在 Athena 查询上启用分区索引:
- 再次运行以下查询并记下运行时间:
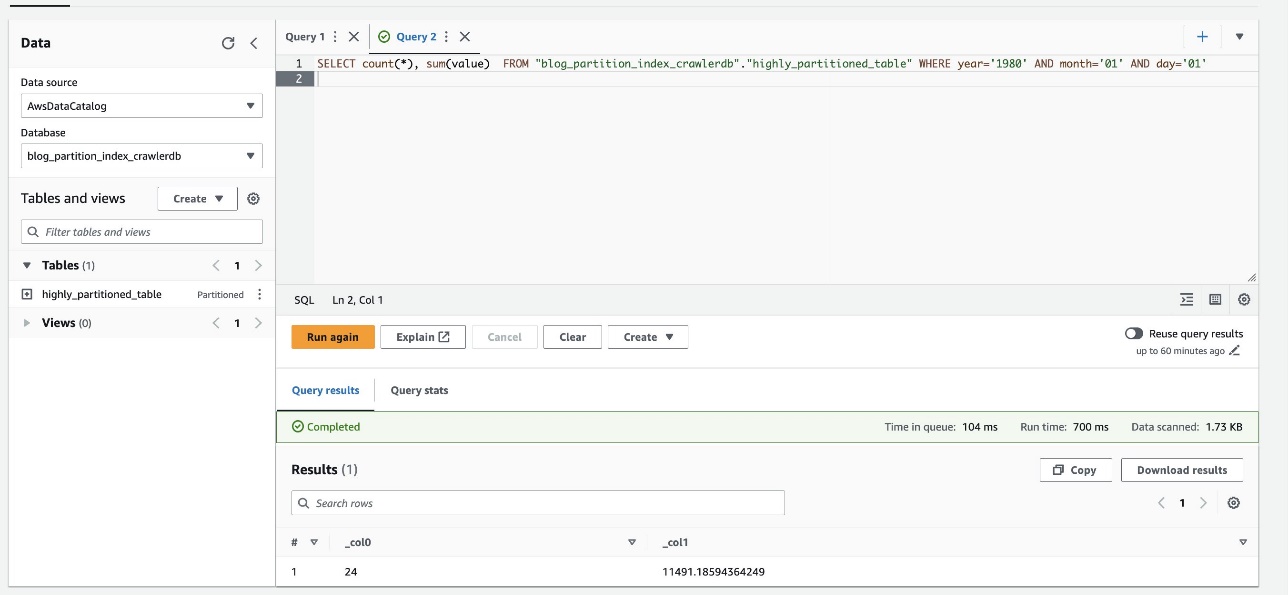
下面的屏幕截图显示查询仅花费了 700 毫秒,使用分区索引启用过滤后速度要快得多。
清理
为避免对您的 AWS 账户产生不必要的费用,您可以删除 AWS 资源:
- 以用于创建 CloudFormation 堆栈的 IAM 管理员身份登录到 CloudFormation 控制台。
- 删除您创建的 CloudFormation 堆栈。
结论
在这篇文章中,我们解释了如何配置 AWS 爬网程序来创建分区索引,并比较了使用 Athena 索引访问数据时的查询性能。
如果表上不存在分区索引,AWS Glue 会加载表的所有分区,然后筛选加载的分区,这会导致元数据检索效率低下。 Redshift Spectrum、Amazon EMR 和 AWS Glue ETL Spark DataFrames 等分析服务现在可以利用索引来获取分区,从而显着提高查询性能。
有关跨各种分析引擎的分区索引和查询性能的更多信息,请参阅 使用 AWS Glue 数据目录分区索引提高 Amazon Athena 查询性能 和 使用 AWS Glue 分区索引提高查询性能.
特别感谢为本次爬虫功能发布做出贡献的所有人:Yuhang Chen、Kyle Duong 和 Mita Gavade。
关于作者
 斯里维迪亚·帕塔萨拉蒂 是 AWS Lake Formation 团队的高级大数据架构师。 她喜欢构建数据网格解决方案并与社区分享。
斯里维迪亚·帕塔萨拉蒂 是 AWS Lake Formation 团队的高级大数据架构师。 她喜欢构建数据网格解决方案并与社区分享。
 桑迪普·阿德万卡尔 是 AWS 的高级技术产品经理。 他在加利福尼亚湾区工作,与全球客户合作,将业务和技术要求转化为产品,使客户能够改进他们管理、保护和访问数据的方式。
桑迪普·阿德万卡尔 是 AWS 的高级技术产品经理。 他在加利福尼亚湾区工作,与全球客户合作,将业务和技术要求转化为产品,使客户能够改进他们管理、保护和访问数据的方式。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- EVM财务。 去中心化金融的统一接口。 访问这里。
- 量子传媒集团。 IR/PR 放大。 访问这里。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :具有
- :是
- :在哪里
- $UP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Able
- ACCESS
- 访问
- 账号管理
- 承认
- 横过
- 加
- 管理员
- 再次
- 所有类型
- 沿
- 还
- Amazon
- 亚马逊雅典娜
- 亚马逊电子病历
- 亚马逊网络服务
- 量
- an
- 分析
- 分析
- 和
- 任何
- 约
- 保健
- 国家 / 地区
- 围绕
- AS
- At
- 自动
- 可使用
- 避免
- AWS
- AWS CloudFormation
- AWS胶水
- AWS湖形成
- 基于
- 海湾
- 因为
- 很
- 好处
- 大
- 大数据运用
- 建筑物
- 商业
- by
- 加州
- CAN
- 检索目录
- 原因
- 更改
- 收费
- 陈
- 选择
- 分类
- 柱
- 列
- 购买的订单均
- 社体的一部分
- 比较
- 相比
- 完成
- 安慰
- 一直
- 贡献
- 成本
- 履带
- 创建信息图
- 创建
- 创建
- 创造
- 创建
- 电流
- 合作伙伴
- data
- 数据访问
- 数据湖
- 数据库
- 天
- 默认
- 演示
- 部署
- 部署
- 描述
- 详情
- 确定
- 发现
- 向下
- ,我们将参加
- 有效
- 或
- enable
- 启用
- 引擎
- 醚(ETH)
- 每个人
- 扩大
- 解释
- 成倍
- 提取
- 提取数据
- 快
- 专栏
- 过滤
- 过滤
- 过滤器
- 最后
- 遵循
- 以下
- 针对
- 训练
- 止
- 产生
- 特定
- 地球
- 增长
- 成长
- 有
- he
- 重
- 举重
- 高度
- 举行
- 小时
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- IAM
- 身分
- 改善
- 改进
- 改善
- in
- 增加
- 增加
- 指数
- 指标
- 低效
- 信息
- 成
- IT
- JPG
- 保持
- 保持
- 键
- 湖泊
- 最大
- 发射
- 布局
- 翻新
- 喜欢
- Line
- 负载
- 使
- 管理
- 颠覆性技术
- 经理
- 网格
- 元数据
- 可能
- 百万
- 分钟
- 月
- 更多
- 许多
- 必须
- 导航
- 导航
- 旅游导航
- 打印车票
- 全新
- 新
- 没有
- 现在
- 数
- of
- on
- 仅由
- 优化
- or
- 秩序
- 我们的
- 产量
- 超过
- 页
- 面包
- 径
- 性能
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 帖子
- 当下
- 处理
- 产品
- 产品经理
- 核心产品
- 提供
- 减少
- 地区
- 必须
- 岗位要求
- 需要
- 资源
- 导致
- 成果
- 角色
- 角色
- 运行
- 运行
- 同
- 秒
- 部分
- 安全
- 前辈
- 特色服务
- 集
- 设置
- 共享
- 她
- 作品
- 显著
- 显著
- 简易
- 方案,
- 解决方案
- 来源
- 火花
- 光谱
- 堆
- 步骤
- 存储
- 商店
- 简单的
- 串
- 顺利
- SUPPORT
- 产品
- 表
- 采取
- 团队
- 文案
- 模板
- 谢谢
- 这
- 其
- 他们
- 然后
- 博曼
- 他们
- Free Introduction
- 次
- 至
- 今天的
- 了
- 翻译
- true
- 类型
- 类型
- 下
- 理解
- 无用
- 更新
- 使用
- 用过的
- 运用
- 利用
- 折扣值
- 价值观
- 各个
- 广阔
- 确认
- 版本
- 是
- 方法..
- we
- 卷筒纸
- Web服务
- ,尤其是
- 这
- WHO
- 将
- 也完全不需要
- 工作组
- 合作
- 世界
- 雅姆
- 年
- 您
- 您一站式解决方案
- 和风网