
图片来自作者 | 必应图像创作者
多莉 2.0 是一种开源的、指令遵循的大型语言模型 (LLM),它在人工生成的数据集上进行了微调。 它可以用于研究和商业目的。
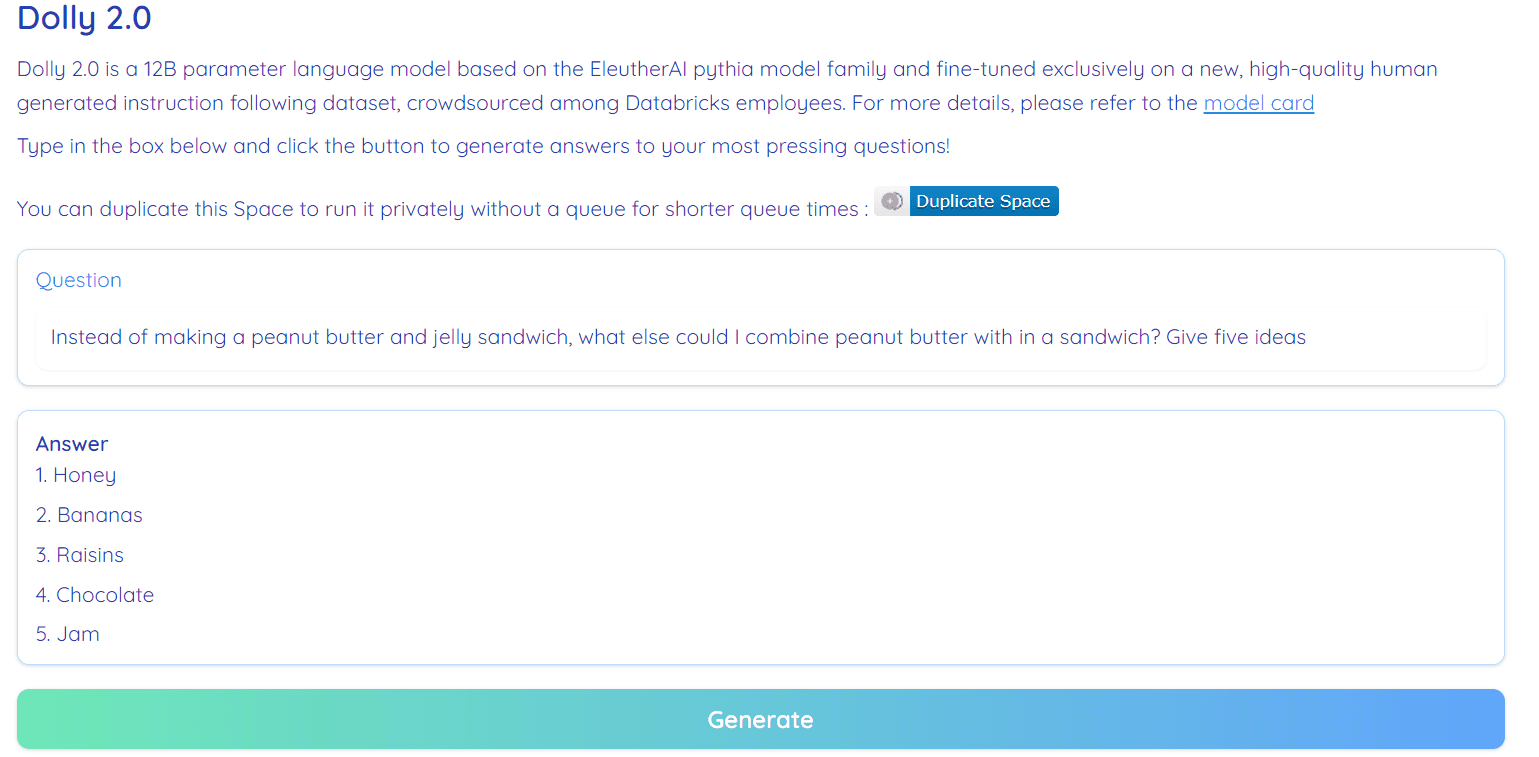
图片来源: RamAnanth1 的拥抱面空间
此前,Databricks 团队发布了 多莉 1.0, LLM,它展示了类似于 ChatGPT 的指令遵循能力,并且培训成本不到 30 美元。 它使用的是 Stanford Alpaca 团队数据集,该数据集受限制许可(仅限研究)。
Dolly 2.0 通过微调 12B 参数语言模型(皮提亚) 在以下数据集中的高质量人工生成指令上,由 Datbricks 员工标记。 模型和数据集均可用于商业用途。
Dolly 1.0 在 Stanford Alpaca 数据集上进行了训练,该数据集是使用 OpenAI API 创建的。 该数据集包含 ChatGPT 的输出,并防止任何人使用它与 OpenAI 竞争。 简而言之,您不能基于此数据集构建商业聊天机器人或语言应用程序。
过去几周发布的大多数最新型号都遇到了同样的问题,例如 羊驼, 考拉, GPT4全部及 骆马. 为了解决这个问题,我们需要创建可用于商业用途的新的高质量数据集,这就是 Databricks 团队对 databricks-dolly-15k 数据集所做的。
新数据集包含 15,000 个高质量的人工标记提示/响应对,可用于设计指令调优大型语言模型。 这 databricks-dolly-15k 数据集附带 知识共享署名-相同方式共享 3.0 未移植许可证,它允许任何人使用它、修改它并在其上创建商业应用程序。
他们是如何创建 databricks-dolly-15k 数据集的?
OpenAI 研究 纸 声明原始 InstructGPT 模型接受了 13,000 个提示和响应的训练。 通过使用这些信息,Databricks 团队开始研究它,结果证明生成 13k 个问题和答案是一项艰巨的任务。 他们不能使用合成数据或 AI 生成数据,他们必须对每个问题生成原始答案。 在这里,他们决定使用 Databricks 的 5,000 名员工来创建人工生成的数据。
Databricks 举办了一场比赛,前 20 名贴标签者将获得大奖。 本次大赛共有5,000名对LLM非常感兴趣的Databricks员工参与
dolly-v2-12b 不是最先进的模型。 它在某些评估基准中表现不及 dolly-v1-6b。 这可能是由于底层微调数据集的组成和大小。 Dolly 模型系列正在积极开发中,因此您将来可能会看到性能更好的更新版本。
简而言之,dolly-v2-12b 模型的表现优于 EleutherAI/gpt-neox-20b 和 EleutherAI/pythia-6.9b。

图片来源: 免费多莉
Dolly 2.0 是 100% 开源的。 它带有训练代码、数据集、模型权重和推理管道。 所有组件都适合商业用途。 您可以在 Hugging Face Spaces 上试用该模型 RamAnanth2 的 Dolly V1.
图片来源: 拥抱脸
资源:
多莉 2.0 演示: RamAnanth2 的 Dolly V1
阿比德·阿里·阿万 (@1abidaliawan) 是一名经过认证的数据科学家专业人士,他热爱构建机器学习模型。 目前,他专注于内容创建和撰写有关机器学习和数据科学技术的技术博客。 Abid 拥有技术管理硕士学位和电信工程学士学位。 他的愿景是使用图形神经网络为患有精神疾病的学生构建一个人工智能产品。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- 与 Adryenn Ashley 一起铸造未来。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :具有
- :是
- :不是
- $UP
- 000
- 1
- 20
- a
- 对,能力--
- 要积极。
- AI
- 所有类型
- 允许
- 替代
- an
- 和
- 答案
- 任何人
- API
- 应用领域
- 保健
- 围绕
- 作者
- 可使用
- 奖
- 基于
- BE
- 基准
- 伯克利
- 更好
- 大
- 兵
- 博客
- 都
- 建立
- 建筑物
- by
- CAN
- 不能
- 认证
- 聊天机器人
- ChatGPT
- 码
- 商业的
- 共享
- 竞争
- 组件
- 包含
- 内容
- 内容创造
- 比赛
- 成本
- 创建信息图
- 创建
- 创建
- 目前
- data
- 数据科学
- 数据科学家
- Databricks
- 数据集
- 决定
- 学位
- 演示
- 设计
- 研发支持
- DID
- 难
- 玩具娃娃
- 员工
- 员工
- 工程师
- 评估
- 所有的
- 展品
- 面部彩妆
- 家庭
- 少数
- 聚焦
- 以下
- 针对
- 止
- 未来
- 生成
- 发电
- 生成的
- 得到
- 图形
- 图神经网络
- 有
- he
- 高品质
- 持有
- HTML
- HTTPS
- 疾病
- 图片
- in
- 信息
- 有兴趣
- 问题
- 问题
- IT
- JPG
- 掘金队
- 语言
- 大
- 名:
- 最新
- 学习
- 执照
- 喜欢
- 机
- 机器学习
- 颠覆性技术
- 主
- 心理
- 精神疾病
- 可能
- 模型
- 模型
- 修改
- 需求
- 网络
- 神经
- 神经网络
- 全新
- of
- on
- 仅由
- 打开
- 开放源码
- OpenAI
- or
- 原版的
- 产量
- 对
- 参数
- 参加
- 性能
- 管道
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 产品
- 所以专业
- 目的
- 题
- 有疑问吗?
- 发布
- 研究
- 解决
- 受限
- s
- 同
- 科学
- 科学家
- 集
- 短
- 尺寸
- So
- 一些
- 来源
- 太空
- 剩余名额
- 斯坦福
- 开始
- 国家的最先进的
- 州
- 奋斗的
- 学生
- 合适的
- 合成的
- 综合数据
- 任务
- 团队
- 文案
- 技术
- 专业技术
- 电信
- 比
- 这
- 未来
- 他们
- Free Introduction
- 至
- 最佳
- 培训
- 熟练
- 产品培训
- 下
- 相关
- 更新
- 使用
- 用过的
- 运用
- 版本
- 愿景
- 是
- we
- 周
- 为
- 什么是
- 这
- WHO
- 工作
- 将
- 写作
- 您
- 和风网










