许多大大小小的组织都在努力将其分析工作负载迁移到 Amazon Web Services (AWS) 上并实现现代化。客户迁移到 AWS 的原因有很多,但主要原因之一是能够使用完全托管的服务,而不是花时间维护基础设施、修补、监控、备份等。领导和开发团队可以花更多的时间来优化当前的解决方案,甚至尝试新的用例,而不是维护当前的基础设施。
由于能够在 AWS 上快速发展,您还需要在不断扩展的过程中对接收和处理的数据负责。这些责任包括遵守数据隐私法律和法规,不存储或泄露来自上游来源的个人身份信息 (PII) 或受保护的健康信息 (PHI) 等敏感数据。
在这篇文章中,我们将介绍一个高级架构和一个特定的用例,演示如何继续扩展组织的数据平台,而无需花费大量的开发时间来解决数据隐私问题。我们用 AWS胶水 在将 PII 数据加载到之前检测、屏蔽和编辑 亚马逊开放搜索服务.
解决方案概述
下图说明了高级解决方案架构。我们已经根据设计定义了所有层和组件 AWS 架构完善的框架数据分析视角.
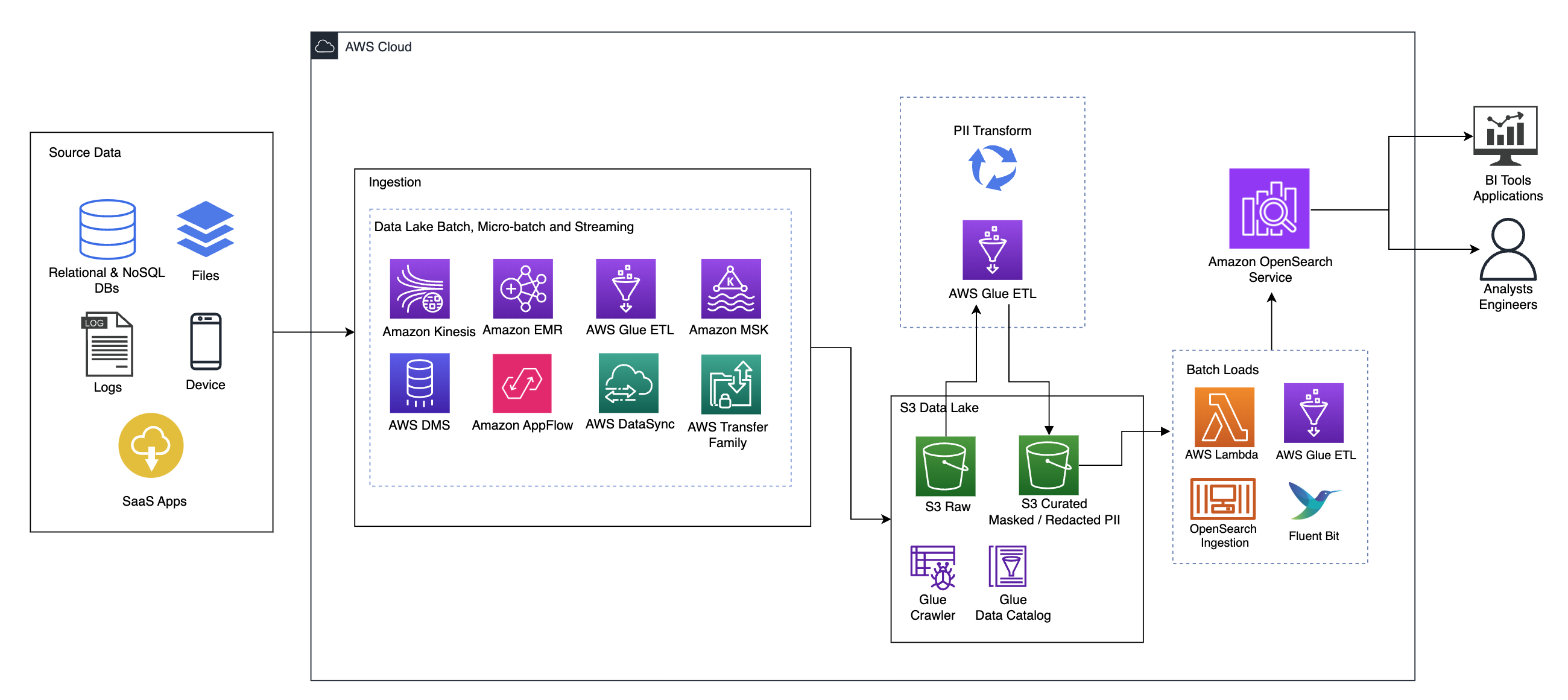
该架构由许多组件组成:
数据来源
数据可能来自数十到数百个来源,包括数据库、文件传输、日志、软件即服务 (SaaS) 应用程序等。组织可能并不总是能够控制哪些数据通过这些渠道进入其下游存储和应用程序。
摄取:数据湖批处理、微批处理和流式传输
许多组织以各种方式将源数据放入数据湖中,包括批处理、微批处理和流作业。例如, 亚马逊电子病历, AWS胶水及 AWS 数据库迁移服务 (AWS DMS) 均可用于执行批处理和/或流式操作,这些操作沉入数据湖 亚马逊简单存储服务 (亚马逊S3)。 亚马逊AppFlow 可用于将数据从不同的 SaaS 应用程序传输到数据湖。 AWS 数据同步 和 AWS Transfer系列 可以帮助通过多种不同的协议将文件移入和移出数据湖。 亚马逊Kinesis Amazon MSK 还能够将数据直接流式传输到 Amazon S3 上的数据湖。
S3数据湖
将 Amazon S3 用于数据湖符合现代数据策略。它提供低成本存储,而不牺牲性能、可靠性或可用性。通过这种方法,您可以根据需要对数据进行计算,并且只需为其运行所需的容量付费。
在此架构中,原始数据可以来自各种来源(内部和外部),其中可能包含敏感数据。
使用 AWS Glue 爬网程序,我们可以发现数据并对其进行编目,这将为我们构建表架构,并最终使使用 AWS Glue ETL 与 PII 转换来检测、屏蔽或编辑可能已到达的任何敏感数据变得简单在数据湖中。
业务背景和数据集
为了展示我们方法的价值,让我们假设您是一家金融服务组织的数据工程团队的一员。您的要求是在敏感数据被引入组织的云环境时检测并屏蔽这些数据。数据将被下游分析过程消耗。将来,您的用户将能够根据从内部银行系统收集的数据流安全地搜索历史支付交易。来自运营团队、客户和接口应用程序的搜索结果必须在敏感字段中进行屏蔽。
下表显示了该解决方案所使用的数据结构。为了清楚起见,我们已将原始列名称映射到精选列名称。您会注意到,此架构中的多个字段被视为敏感数据,例如名字、姓氏、社会安全号码 (SSN)、地址、信用卡号、电话号码、电子邮件和 IPv4 地址。
| 原始列名称 | 策划栏名称 | Type |
| c0 | 名字 | 绳子 |
| c1 | 姓 | 绳子 |
| c2 | SSN | 绳子 |
| c3 | 地址 | 绳子 |
| c4 | 邮编 | 绳子 |
| c5 | 国家 | 绳子 |
| c6 | 购买网站 | 绳子 |
| c7 | 信用卡号码 | 绳子 |
| c8 | 信用卡提供商 | 绳子 |
| c9 | 货币 | 绳子 |
| c10 | 购买价值 | 整数 |
| c11 | 交易日期 | 日期 |
| c12 | 电话号码 | 绳子 |
| c13 | 邮箱地址 | 绳子 |
| c14 | ipv4 | 绳子 |
使用案例:加载到 OpenSearch 服务之前批量检测 PII
实施以下架构的客户已在 Amazon S3 上构建了数据湖,以大规模运行不同类型的分析。该解决方案适合不需要实时摄取 OpenSearch Service 并计划使用按计划运行或通过事件触发的数据集成工具的客户。
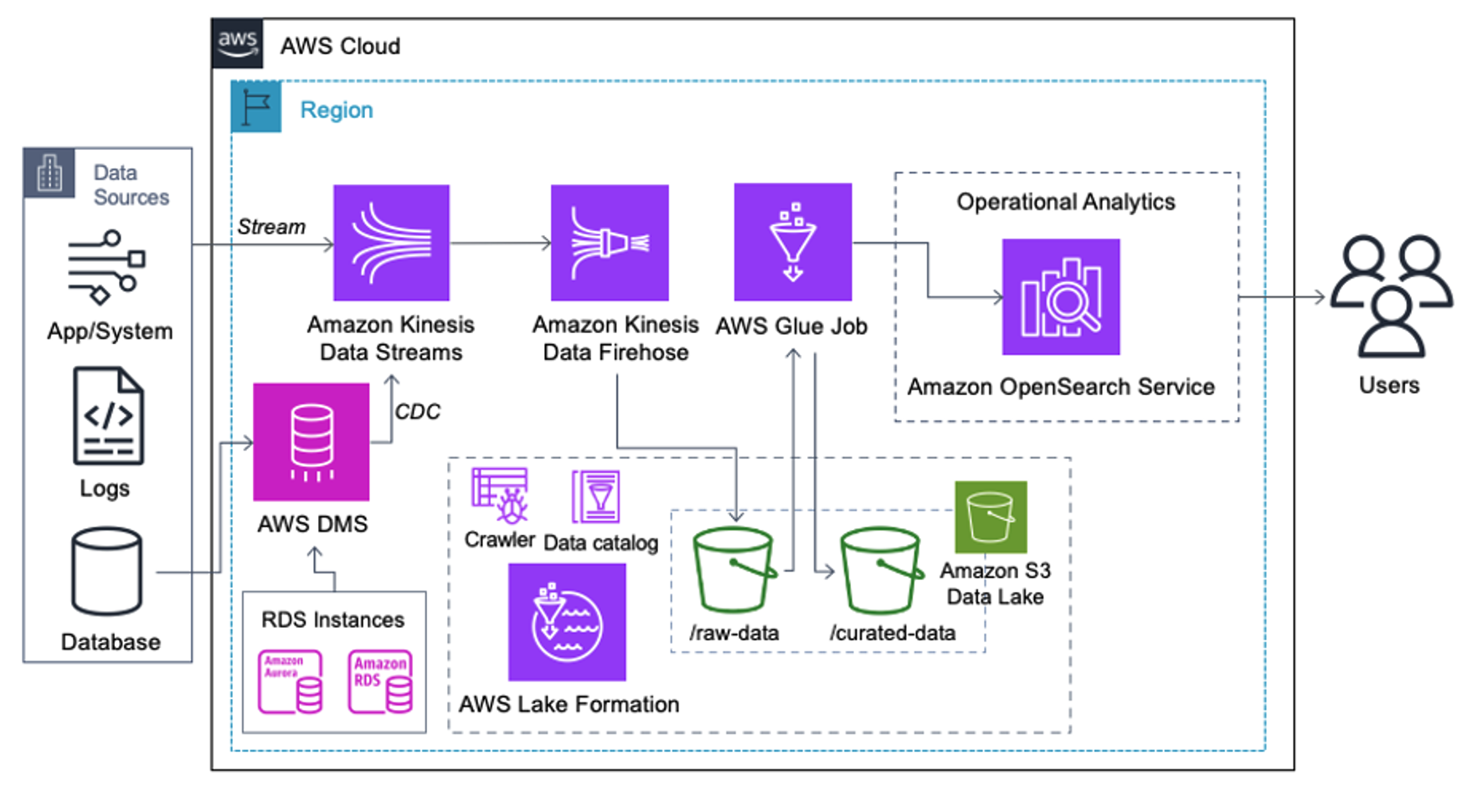
在数据记录到达 Amazon S3 之前,我们实施了一个摄取层,将所有数据流可靠且安全地引入数据湖。 Kinesis Data Streams 部署为摄取层,用于加速结构化和半结构化数据流的摄取。例如关系数据库更改、应用程序、系统日志或点击流。对于变更数据捕获 (CDC) 使用案例,您可以使用 Kinesis Data Streams 作为 AWS DMS 的目标。生成包含敏感数据的流的应用程序或系统将通过以下三种受支持的方法之一发送到 Kinesis 数据流:Amazon Kinesis Agent、AWS SDK for Java 或 Kinesis Producer Library。作为最后一步, 亚马逊 Kinesis 数据流水线 帮助我们可靠地将近乎实时的批量数据加载到我们的 S3 数据湖目的地中。
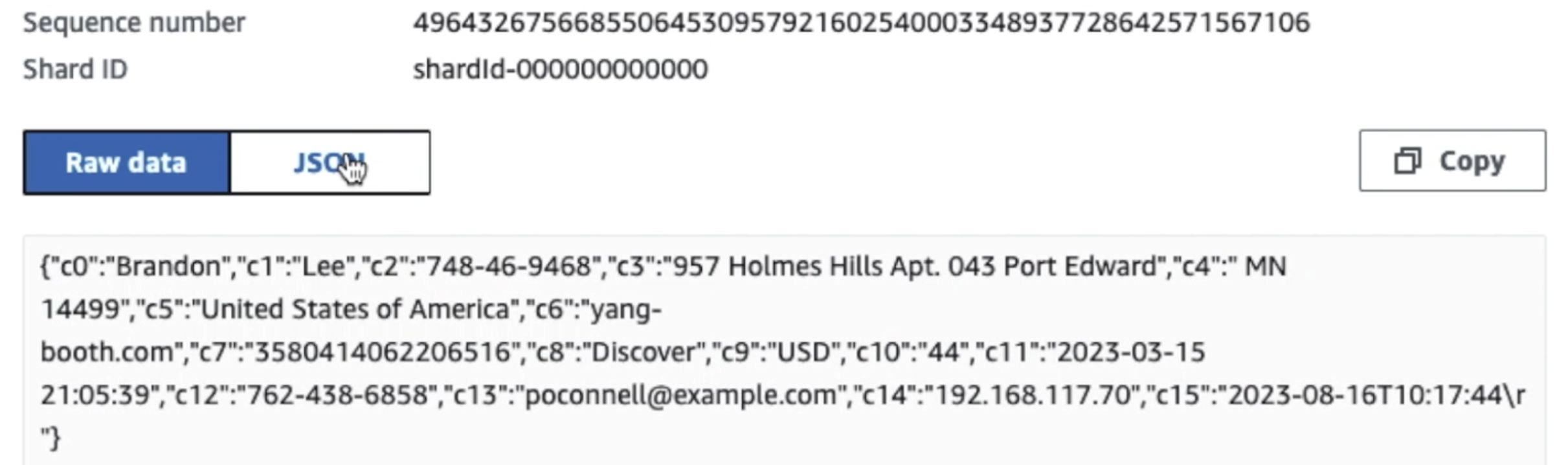
以下屏幕截图显示了数据如何通过 Kinesis Data Streams 通过 资料检视器 并检索位于原始 S3 前缀的样本数据。对于此架构,我们遵循 S3 前缀的数据生命周期,如 数据湖基础.
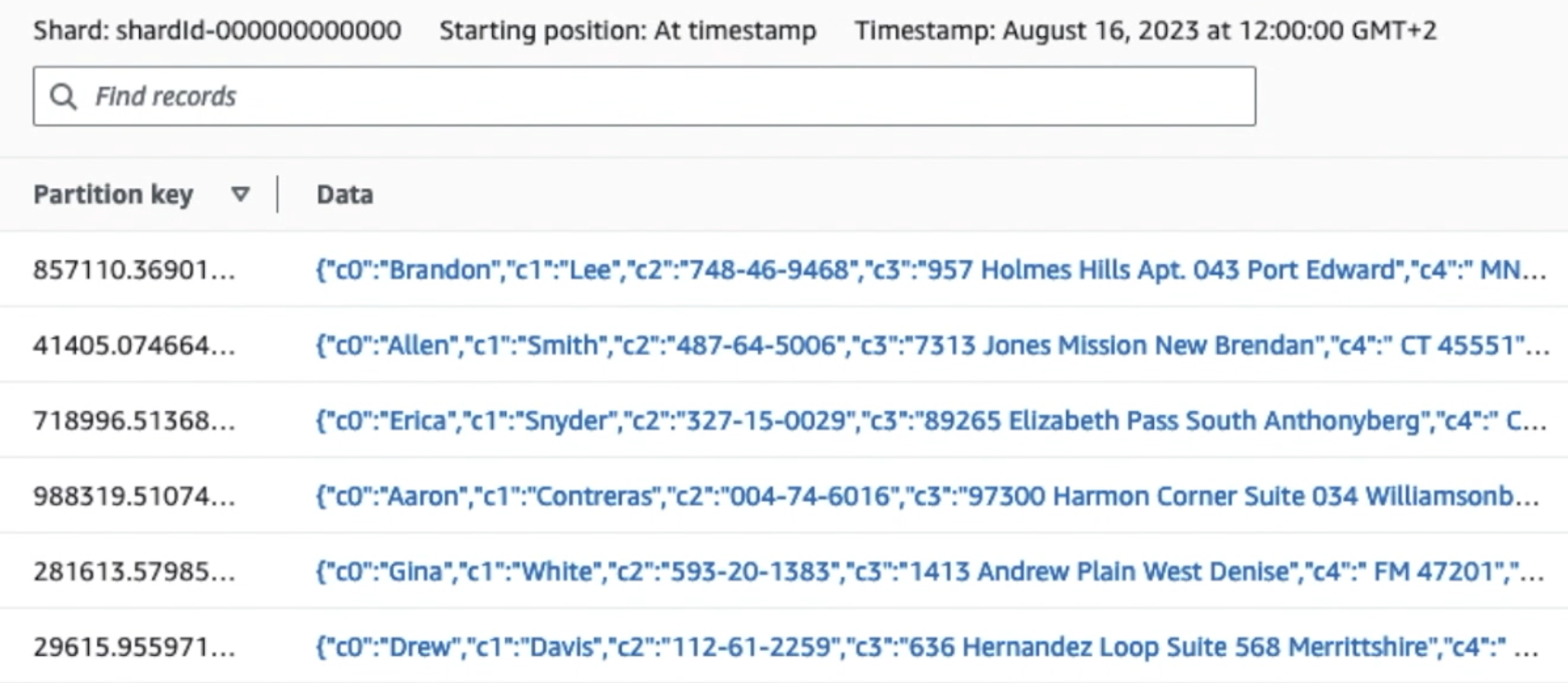
正如您从以下屏幕截图中第一条记录的详细信息中看到的,JSON 负载遵循与上一节相同的架构。您可以看到未编辑的数据流入 Kinesis 数据流,这些数据将在后续阶段进行混淆。
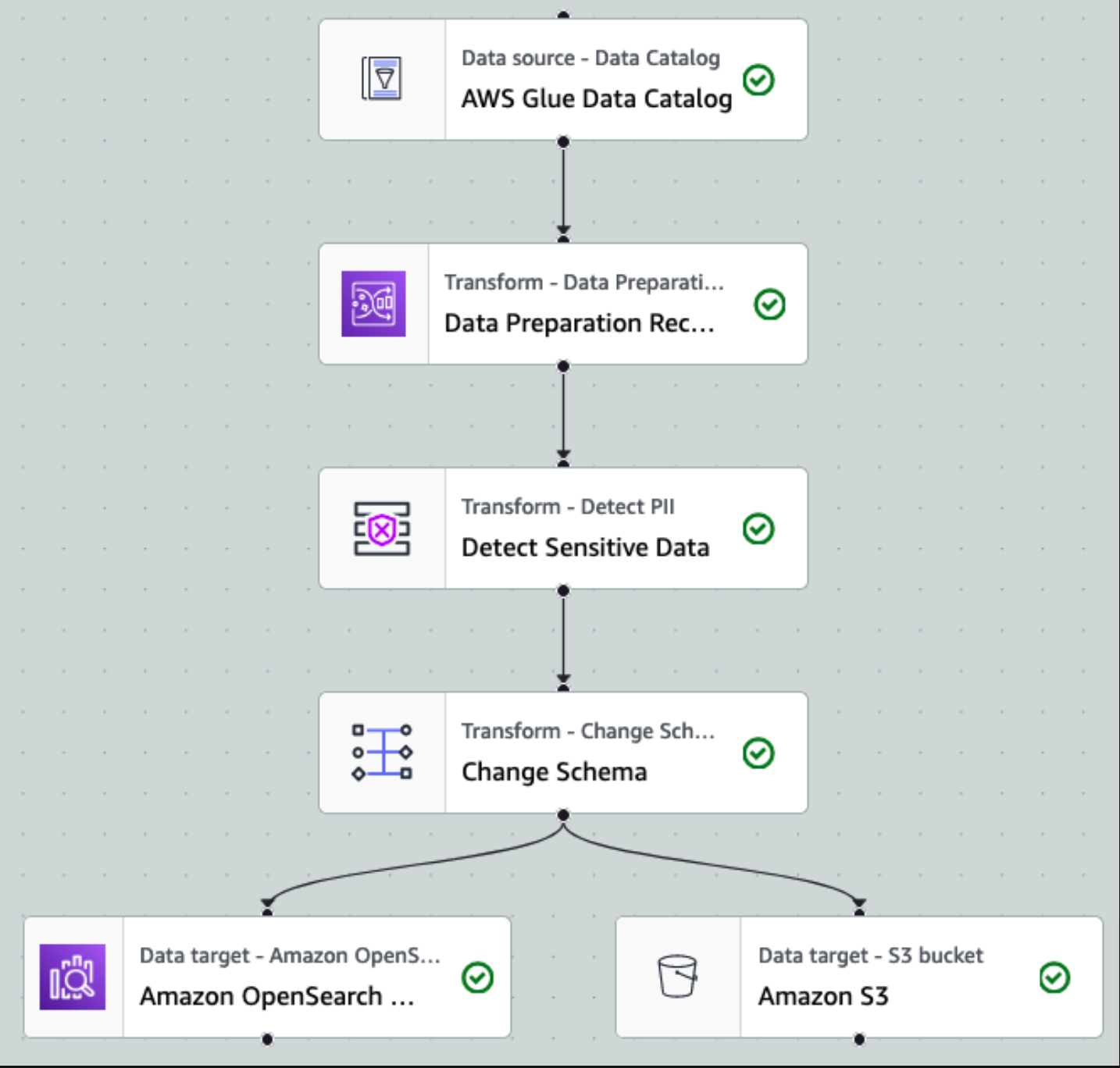
数据被收集并引入 Kinesis Data Streams 并使用 Kinesis Data Firehose 传送到 S3 存储桶后,架构的处理层将接管。我们使用 AWS Glue PII 转换来自动检测和屏蔽管道中的敏感数据。如下工作流程图所示,我们采用无代码、可视化 ETL 方法在 AWS Glue Studio 中实施转换作业。
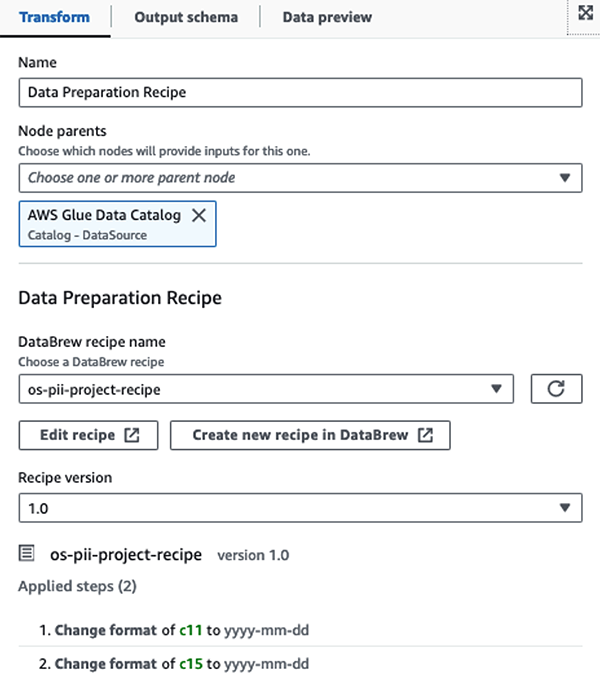
首先,我们从以下位置访问源数据目录表: pii_data_db 数据库。该表具有上一节中介绍的模式结构。为了跟踪原始处理数据,我们使用 工作书签.

我们使用 AWS Glue Studio 可视化 ETL 作业中的 AWS Glue DataBrew 配方 转换两个日期属性以与 OpenSearch 预期兼容 格式。这使我们能够获得完整的无代码体验。
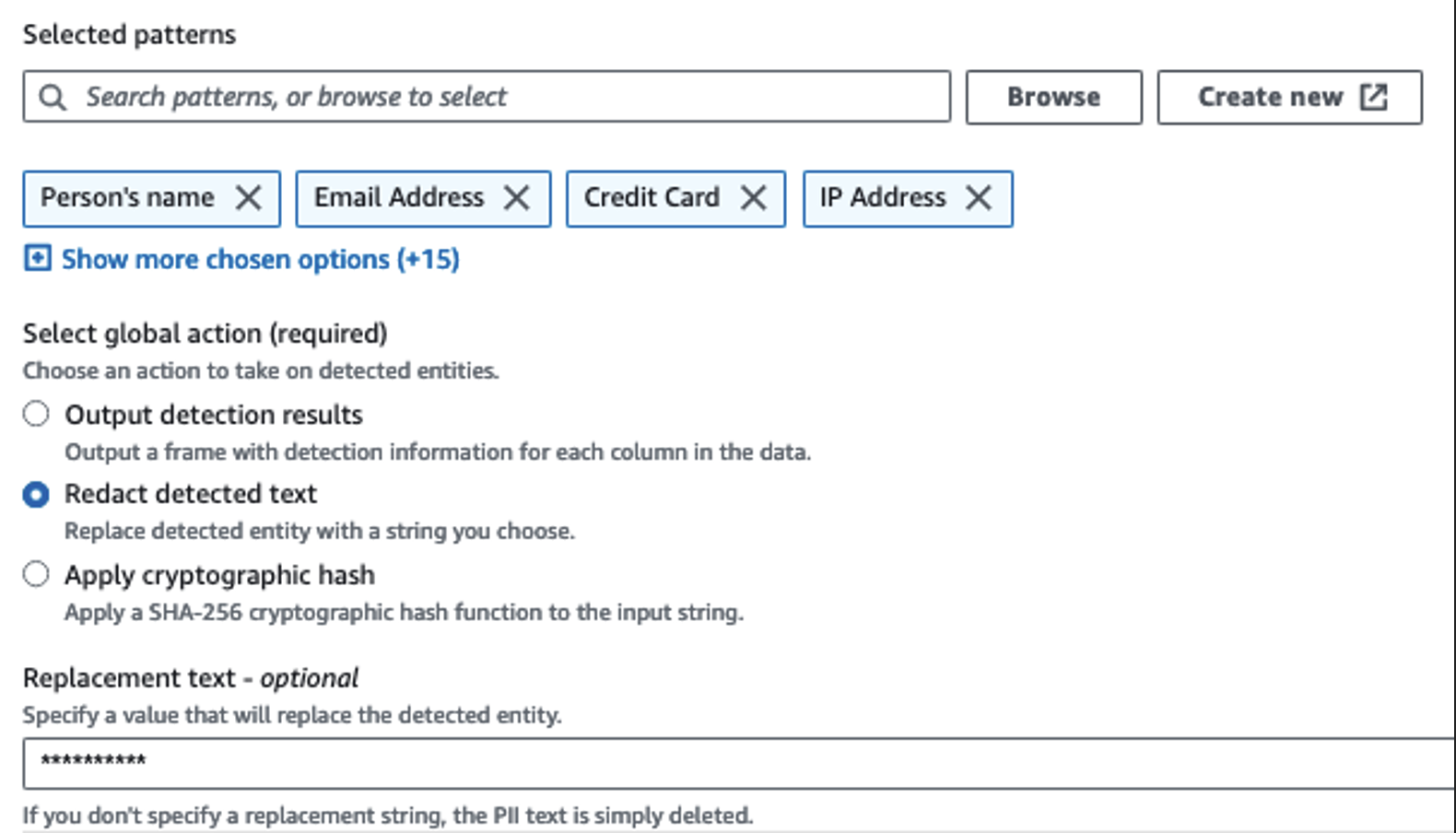
我们使用检测 PII 操作来识别敏感列。我们让 AWS Glue 根据选定的模式、检测阈值和数据集中行的样本部分来确定这一点。在我们的示例中,我们使用了专门适用于美国的模式(例如 SSN),并且可能无法检测来自其他国家/地区的敏感数据。您可以查找适用于您的使用案例的可用类别和位置,或使用 AWS Glue 中的正则表达式 (regex) 为来自其他国家/地区的敏感数据创建检测实体。
选择 AWS Glue 提供的正确采样方法非常重要。在此示例中,已知从流中传入的数据的每一行都包含敏感数据,因此无需对数据集中的 100% 的行进行采样。如果您有不允许敏感数据流入下游源的要求,请考虑对您选择的模式的数据进行 100% 采样,或者扫描整个数据集并对每个单独的单元格进行操作,以确保检测到所有敏感数据。您从采样中获得的好处是降低了成本,因为您不必扫描那么多数据。

检测 PII 操作允许您在屏蔽敏感数据时选择默认字符串。在我们的示例中,我们使用字符串 **********。
我们使用应用映射操作来重命名和删除不必要的列,例如 ingestion_year, ingestion_month及 ingestion_day. 此步骤还允许我们更改其中一列的数据类型(purchase_value) 从字符串到整数。

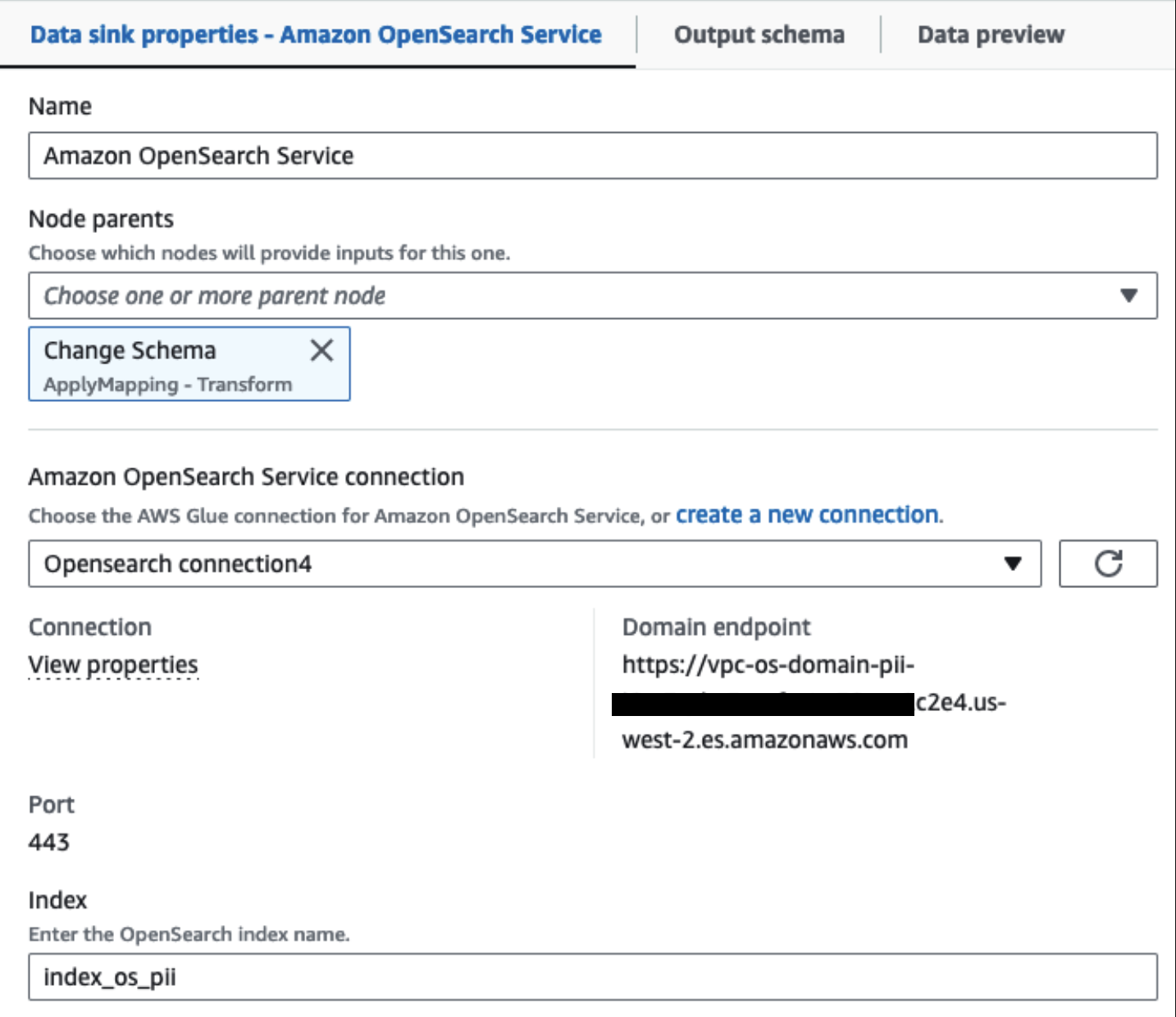
从此时起,作业分为两个输出目标:OpenSearch Service 和 Amazon S3。
我们配置的 OpenSearch 服务集群通过 用于 Glue 的 OpenSearch 内置连接器。我们指定要写入的 OpenSearch 索引,连接器处理凭据、域和端口。在下面的屏幕截图中,我们写入指定的索引 index_os_pii.
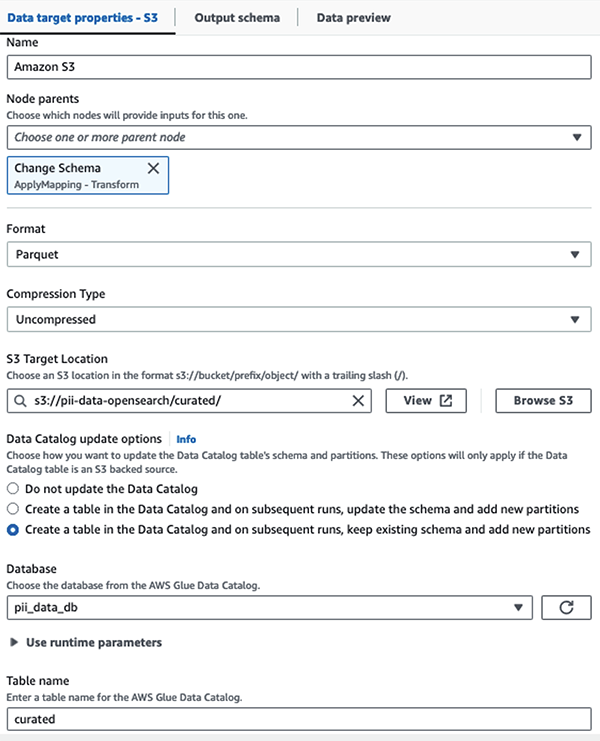
我们将屏蔽数据集存储在精选的 S3 前缀中。在那里,我们将数据标准化为特定用例,并供数据科学家安全使用或满足临时报告需求。
对于所有数据集和数据目录表的统一治理、访问控制和审计跟踪,您可以使用 AWS湖形成。这有助于您将对 AWS Glue 数据目录表和基础数据的访问权限限制为仅限已被授予必要权限的用户和角色。
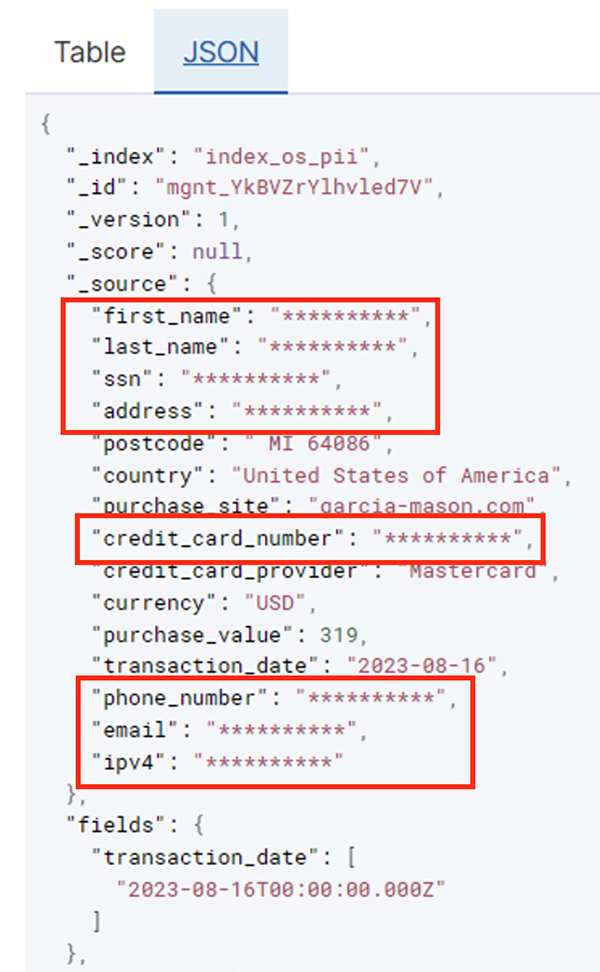
批处理作业成功运行后,您可以使用 OpenSearch Service 运行搜索查询或报告。如下图所示,管道自动屏蔽了敏感字段,无需任何代码开发工作。

您可以从运营数据中识别趋势,例如信用卡提供商过滤的每天交易量,如前面的屏幕截图所示。您还可以确定用户进行购买的位置和域。这 transaction_date 属性可以帮助我们了解这些随时间变化的趋势。以下屏幕截图显示了一条记录,其中所有交易信息均经过适当编辑。
有关如何将数据加载到 Amazon OpenSearch 的替代方法,请参阅 将流数据加载到 Amazon OpenSearch Service 中.
此外,还可以使用其他 AWS 解决方案发现和屏蔽敏感数据。例如,您可以使用 亚马逊梅西 检测 S3 存储桶内的敏感数据,然后使用 亚马逊领悟 编辑检测到的敏感数据。欲了解更多信息,请参阅 使用 AWS 服务检测 PHI 和 PII 数据的常用技术.
结论
这篇文章讨论了在您的环境中处理敏感数据的重要性以及保持合规性同时允许您的组织快速扩展的各种方法和架构。您现在应该很好地了解如何检测、屏蔽或编辑数据并将其加载到 Amazon OpenSearch Service 中。
关于作者
 迈克尔·汉密尔顿 是一名高级分析解决方案架构师,专注于帮助企业客户实现 AWS 上的分析工作负载现代化并简化。他喜欢骑山地自行车,并在工作之余与妻子和三个孩子共度时光。
迈克尔·汉密尔顿 是一名高级分析解决方案架构师,专注于帮助企业客户实现 AWS 上的分析工作负载现代化并简化。他喜欢骑山地自行车,并在工作之余与妻子和三个孩子共度时光。
 丹尼尔·罗佐 是 AWS 的高级解决方案架构师,为荷兰客户提供支持。他的热情是设计简单的数据和分析解决方案,并帮助客户转向现代数据架构。工作之余,他喜欢打网球和骑自行车。
丹尼尔·罗佐 是 AWS 的高级解决方案架构师,为荷兰客户提供支持。他的热情是设计简单的数据和分析解决方案,并帮助客户转向现代数据架构。工作之余,他喜欢打网球和骑自行车。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :具有
- :是
- :不是
- :在哪里
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- 对,能力--
- Able
- 加速
- ACCESS
- 法案
- 操作
- Ad
- 地址
- 经纪人
- 所有类型
- 允许
- 允许
- 允许
- 还
- 时刻
- Amazon
- 亚马逊Kinesis
- 亚马逊网络服务
- 亚马逊网络服务(AWS)
- 量
- 量
- an
- 分析
- 分析
- 和
- 任何
- 相应
- 应用领域
- 使用
- 的途径
- 适当
- 架构
- 保健
- AS
- At
- 属性
- 审计
- 自动化
- 自动
- 可用性
- 可使用
- AWS
- AWS胶水
- 备份
- 银行业
- 银行系统
- 基于
- BE
- 因为
- 很
- before
- 作为
- 如下。
- 得益
- 带来
- 建立
- 建
- 内建的
- 但是
- by
- CAN
- 能力
- 容量
- 捕获
- 卡
- 案件
- 例
- 检索目录
- 类别
- 疾病预防控制中心
- 细胞
- 更改
- 更改
- 通道
- 儿童
- 选择
- 明晰
- 云端技术
- 簇
- 码
- 柱
- 列
- 如何
- 购买的订单均
- 未来
- 兼容
- 兼容
- 组件
- 包含
- 计算
- 关注
- 已联繫
- 考虑
- 考虑
- 消费
- 消费
- 包含
- 上下文
- 继续
- 控制
- 正确
- 成本
- 可以
- 国家
- 创建信息图
- 资历
- 信用
- 信用卡
- 策划
- 电流
- 合作伙伴
- data
- 数据分析
- 数据集成
- 数据湖
- 数据平台
- 数据隐私
- 数据策略
- 数据库
- 数据库
- 数据集
- 日期
- 天
- 默认
- 定义
- 提升
- 演示
- 演示
- 部署
- 设计
- 目的地
- 旅游目的地
- 详情
- 检测
- 检测
- 检测
- 确定
- 研发支持
- 开发团队
- 不同
- 直接
- 通过各种方式找到
- 发现
- 讨论
- do
- 域
- 域名
- 别
- 每
- 工作的影响。
- 邮箱地址
- 工程师
- 确保
- 企业
- 企业客户
- 整个
- 实体
- 环境
- 醚(ETH)
- 甚至
- 事件
- 所有的
- 例子
- 例子
- 预期
- 体验
- 表达式
- 外部
- 高效率
- 字段
- 文件
- 档
- 金融
- 金融服务
- 姓氏:
- 流动
- 流动
- 聚焦
- 其次
- 以下
- 如下
- 针对
- 骨架
- 止
- ,
- 充分
- 未来
- 发电
- 得到
- 非常好
- 治理
- 授予
- 手柄
- 处理
- 有
- he
- 健康管理
- 健康资讯
- 帮助
- 帮助
- 帮助
- 高水平
- 他的
- 历史的
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- 数百
- 鉴定
- if
- 说明
- 想像
- 实施
- 重要性
- 重要
- in
- 包括
- 包含
- 指数
- 个人
- 信息
- 基础设施
- 内
- 积分
- 内部
- 成
- IT
- 爪哇岛
- 工作
- 工作机会
- JPG
- JSON
- 保持
- Kinesis 数据流水线
- Kinesis 数据流
- 已知
- 湖泊
- 土地
- 土地
- 大
- 名:
- 后来
- 法律
- 法律法规
- 层
- 层
- 领导团队
- 让
- 自学资料库
- 生命周期
- 喜欢
- Line
- 加载
- 装载
- 地点
- 看
- 廉价
- 主要
- 维持
- 使
- 管理
- 许多
- 制图
- 面膜
- 可能..
- 方法
- 方法
- 迁移
- 移民
- 现代
- 现代化
- 监控
- 更多
- 山
- 移动
- 移动
- 许多
- 多
- 必须
- 姓名
- 名称
- 必要
- 需求
- 打印车票
- 需要
- 需要
- 荷兰
- 全新
- 没有
- 节点
- 注意..
- 现在
- 数
- of
- 优惠精选
- on
- 一
- 仅由
- 操作
- 操作
- 运营
- 追求项目的积极优化
- 附加选项
- or
- 组织
- 组织
- 其他名称
- 我们的
- 产量
- 学校以外
- 超过
- 部分
- 情
- 修补
- 模式
- 付款
- 为
- 演出
- 性能
- 权限
- 亲自
- 电话
- ii
- 管道
- 计划
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 点
- 一部分
- 帖子
- 前
- 呈现
- 以前
- 隐私
- 隐私法
- 处理
- 过程
- 处理
- 制片人
- 保护
- 协议
- 提供者
- 提供
- 购买
- 查询
- 很快
- 宁
- 原
- 原始数据
- 实时的
- 原因
- 接收
- 食谱
- 建议
- 记录
- 记录
- 减少
- 参考
- 定期
- 法规
- 可靠性
- 留
- 去掉
- 报告
- 业务报告
- 要求
- 需求
- 岗位要求
- 责任
- 提供品牌战略规划
- 限制
- 成果
- 角色
- 行
- 运行
- 运行
- SaaS的
- 牺牲
- 安全
- 安然
- 同
- 鳞片
- 浏览
- 始你
- 科学家
- 屏风
- SDK
- 搜索
- 部分
- 安全
- 保安
- 看到
- 选择
- 选
- 前辈
- 敏感
- 发送
- 服务
- 特色服务
- 射击
- 应该
- 如图
- 作品
- 简易
- 简化
- 小
- So
- 社会
- 软件
- 软件作为一种服务
- 方案,
- 解决方案
- 来源
- 来源
- 具体的
- 特别是
- 指定
- 花
- 花费
- 拆分
- 实习
- 州
- 步
- 存储
- 商店
- 简单的
- 策略
- 流
- 流
- 流
- 串
- 结构体
- 结构化
- 工作室
- 随后
- 顺利
- 这样
- 合适的
- 支持
- 支持
- 系统
- 产品
- 表
- 需要
- 目标
- 团队
- 队
- 技术
- 网球
- HAST
- 比
- 这
- 未来
- 荷兰人
- 其
- 然后
- 那里。
- 博曼
- Free Introduction
- 那些
- 三
- 门槛
- 通过
- 次
- 至
- 了
- 工具
- 跟踪时
- 交易
- 转让
- 转让
- 改造
- 转型
- 趋势
- 引发
- 二
- 类型
- 类型
- 最终
- 相关
- 理解
- 统一
- 联合的
- 美国
- us
- 使用
- 用例
- 用过的
- 用户
- 运用
- 折扣值
- 各种
- 各个
- 通过
- 视觉
- 走
- 是
- 方法
- we
- 卷筒纸
- Web服务
- 什么是
- ,尤其是
- 这
- 而
- WHO
- 妻子
- 将
- 中
- 也完全不需要
- 工作
- 工作流程
- 加工
- 写
- 您
- 您一站式解决方案
- 和风网