在当今数据驱动的业务环境中,组织面临着为分析和数据科学目的高效准备和转换大量数据的挑战。 企业需要基于运营数据构建数据仓库和数据湖。 这是由于需要集中和集成来自不同来源的数据。
同时,运营数据通常源自由遗留数据存储支持的应用程序。 应用程序现代化需要微服务架构,这反过来又需要整合来自多个来源的数据以构建可操作的数据存储。 如果不进行现代化改造,遗留应用程序可能会增加维护成本。 现代化应用程序涉及将底层数据库引擎更改为现代基于文档的数据库,如 MongoDB。
这两项任务(构建数据湖或数据仓库和应用程序现代化)涉及数据移动,它使用提取、转换和加载 (ETL) 过程。 ETL 作业是拥有结构良好的流程以取得成功的关键功能。
AWS胶水 是一种无服务器数据集成服务,可以直接从多个来源发现、准备、移动和集成数据,用于分析、机器学习 (ML) 和应用程序开发。 MongoDB地图集 是一个集成的云数据库和数据服务套件,将事务处理、基于相关性的搜索、实时分析和移动到云数据同步结合在一个优雅的集成架构中。
通过将 AWS Glue 与 MongoDB Atlas 结合使用,组织可以简化其 ETL 流程。 凭借其完全托管、可扩展且安全的数据库解决方案,MongoDB Atlas 为存储和管理运营数据提供了一个灵活可靠的环境。 AWS Glue ETL 和 MongoDB Atlas 共同构成了一个强大的解决方案,适用于希望优化其构建数据湖和数据仓库的方式并对其应用程序进行现代化改造以提高业务绩效、降低成本并推动增长和成功的组织。
在这篇文章中,我们演示了如何从 亚马逊简单存储服务 (Amazon S3) 使用 AWS Glue ETL 将数据存储到 MongoDB Atlas,以及如何将数据从 MongoDB Atlas 提取到基于 Amazon S3 的数据湖中。
解决方案概述
在这篇文章中,我们探讨了以下用例:
- 从 MongoDB 中提取数据 – MongoDB 是一种流行的数据库,成千上万的客户使用它来大规模存储应用程序数据。 企业客户可以通过构建数据湖和数据仓库来集中和集成来自多个数据存储的数据。 此过程涉及从操作数据存储中提取数据。 当数据位于一处时,客户可以快速将其用于商业智能需求或 ML。
- 将数据提取到 MongoDB – MongoDB 还用作非 SQL 数据库来存储应用程序数据和构建操作数据存储。 应用程序现代化通常涉及将操作存储迁移到 MongoDB。 客户需要从关系数据库或平面文件中提取现有数据。 移动和 Web 应用程序通常需要数据工程师构建数据管道,以在 Atlas 中创建单一数据视图,同时从多个孤立源获取数据。 在此迁移期间,他们需要加入不同的数据库来创建文档。 这种复杂的连接操作需要大量的一次性计算能力。 开发人员还需要快速构建它以迁移数据。
在这些情况下,AWS Glue 可以派上用场,它采用即用即付模式,并且能够跨庞大的数据集运行复杂的转换。 开发人员可以使用 AWS Glue Studio 高效地创建此类数据管道。
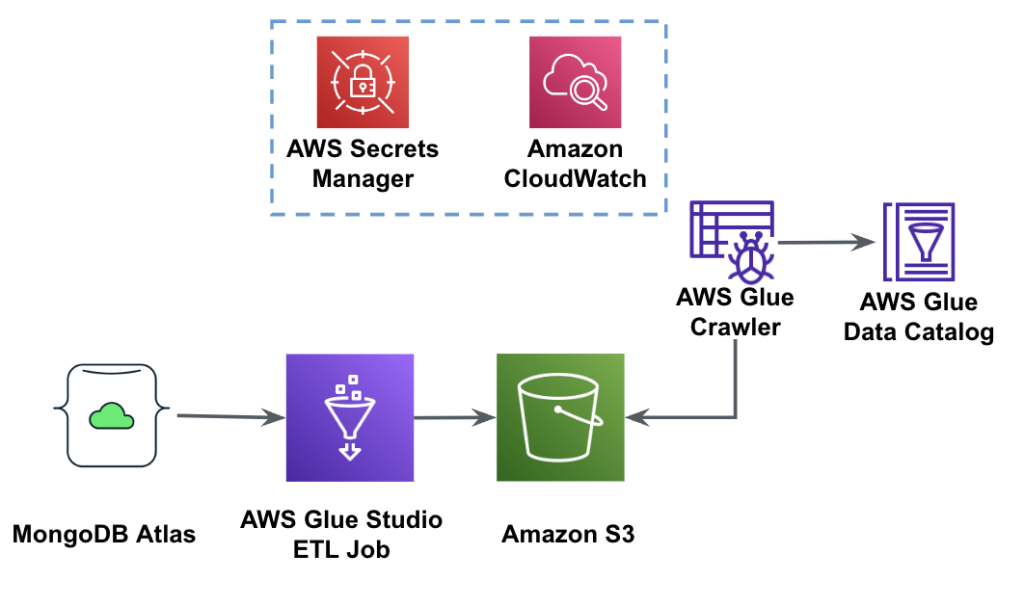
下图显示了使用 AWS Glue Studio 从 MongoDB Atlas 到 S3 存储桶的数据提取工作流程。
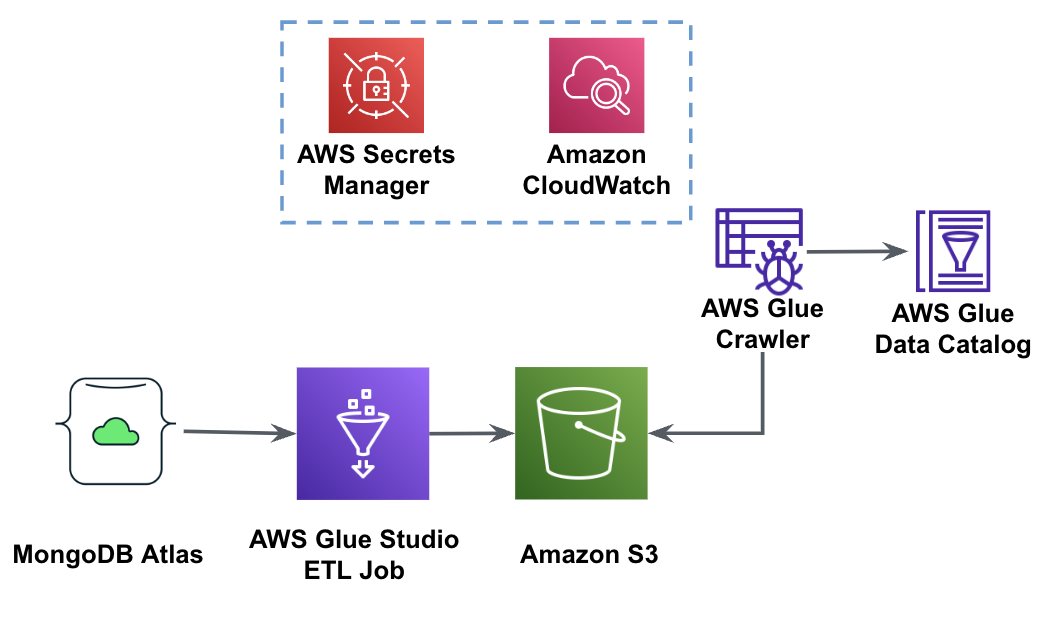
为了实施此架构,您将需要一个 MongoDB Atlas 集群、一个 S3 存储桶和一个 AWS身份和访问管理 AWS Glue 的 (IAM) 角色。 要配置这些资源,请参考以下先决条件步骤 GitHub回购.
下图显示了使用 AWS Glue 从 S3 存储桶到 MongoDB Atlas 的数据加载工作流程。
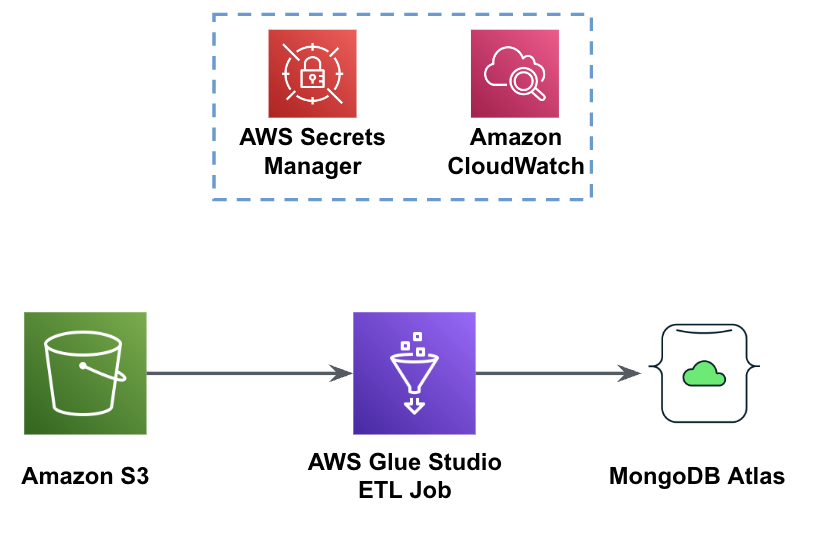
这里需要相同的先决条件:S3 存储桶、IAM 角色和 MongoDB Atlas 集群。
使用 AWS Glue 将数据从 Amazon S3 加载到 MongoDB Atlas
以下步骤描述了如何使用 AWS Glue 作业将数据从 S3 存储桶加载到 MongoDB Atlas 中。 从 MongoDB Atlas 到 Amazon S3 的提取过程非常相似,只是使用的脚本不同。 我们指出这两个过程之间的差异。
- 创建一个免费集群 在 MongoDB Atlas 中。
- 上载 示例 JSON 文件 到您的 S3 存储桶。
- 使用以下命令创建一个新的 AWS Glue Studio 作业 Spark 脚本编辑器 选项。

以下屏幕截图显示了将数据加载到 MongoDB Atlas 集群的代码片段。

代码使用 AWS机密管理器 检索 MongoDB Atlas 集群名称、用户名和密码。 然后,它创建一个 DynamicFrame 对于作为参数传递给脚本的 S3 存储桶和文件名。 该代码从作业参数配置中检索数据库和集合名称。 最后,代码写了 DynamicFrame 使用检索到的参数到 MongoDB Atlas 集群。
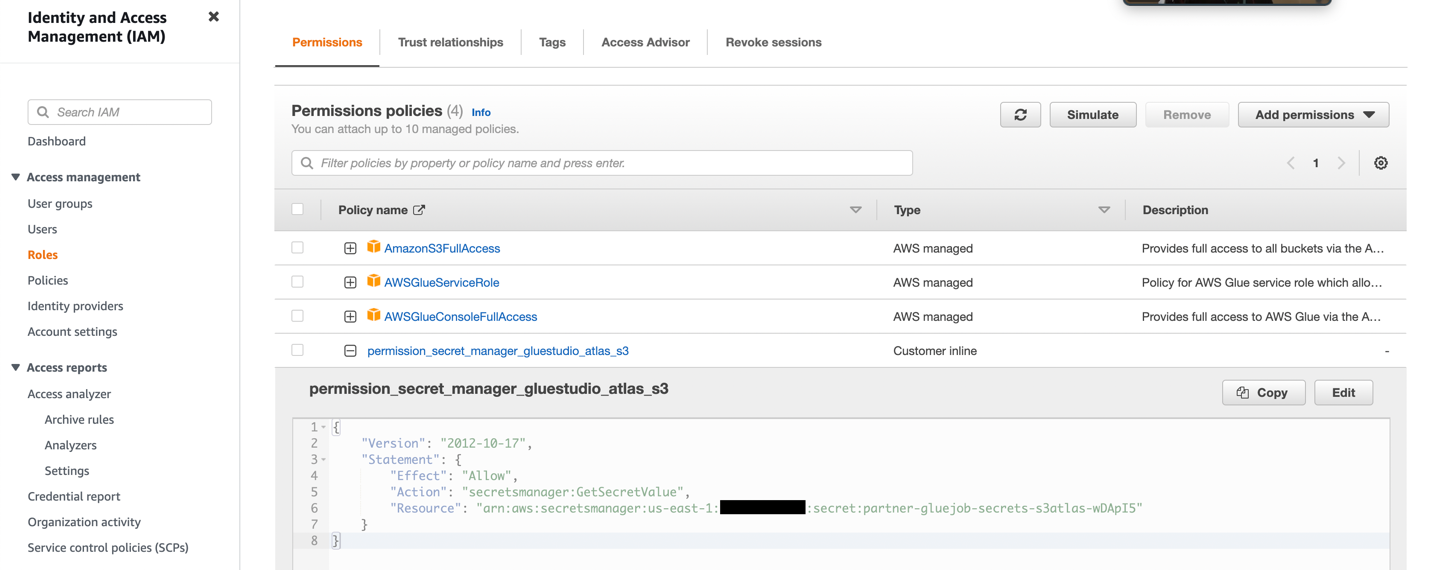
- 创建具有以下屏幕截图所示权限的 IAM 角色。
有关更多详细信息,请参阅 为您的 ETL 作业配置 IAM 角色.
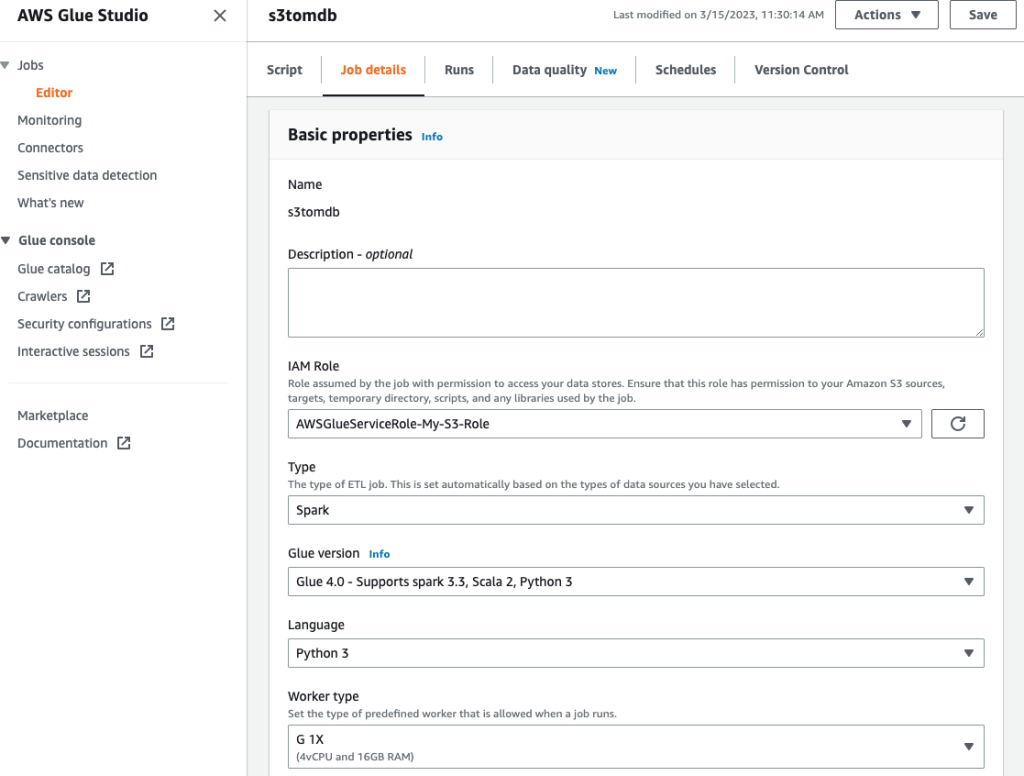
- 为作业命名并提供在上一步中创建的 IAM 角色 工作细节 标签。
- 您可以将其余参数保留为默认值,如以下屏幕截图所示。
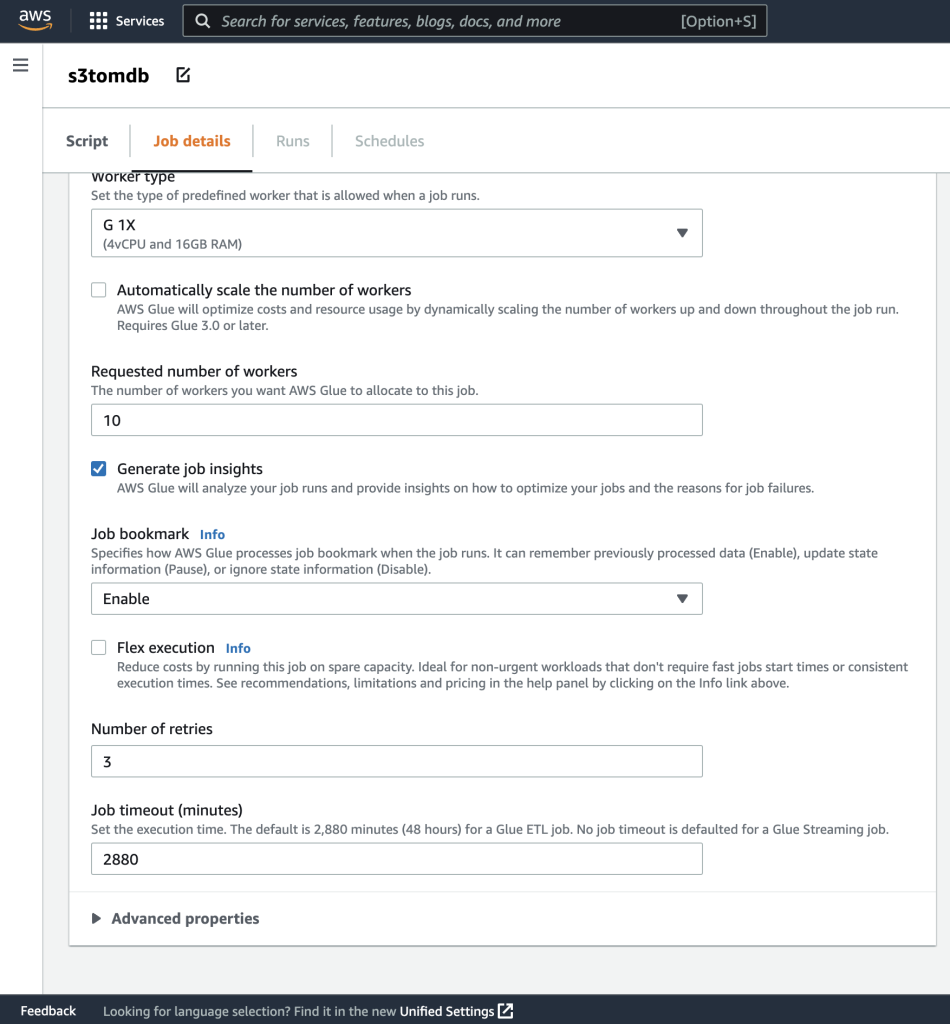
- 接下来,定义脚本使用的作业参数并提供默认值。
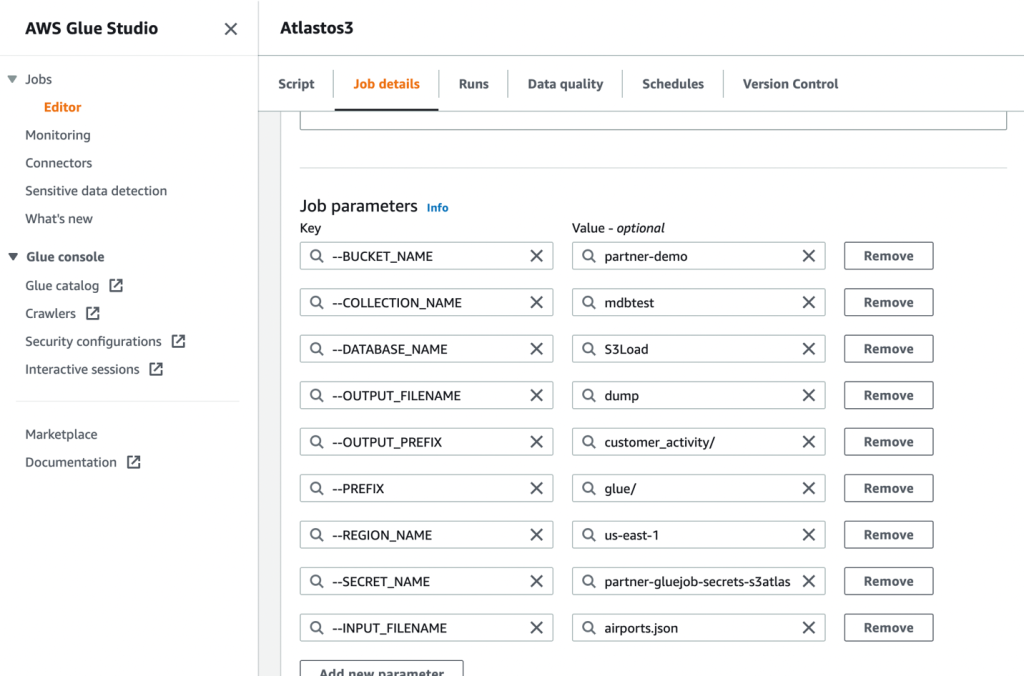
- 保存作业并运行它。
- 要确认运行成功,请在加载数据时观察 MongoDB Atlas 数据库集合的内容,或者在执行提取时观察 S3 存储桶的内容。



以下屏幕截图显示了从 Amazon S3 存储桶成功将数据加载到 MongoDB Atlas 集群的结果。 数据现在可用于 MongoDB Atlas UI 中的查询。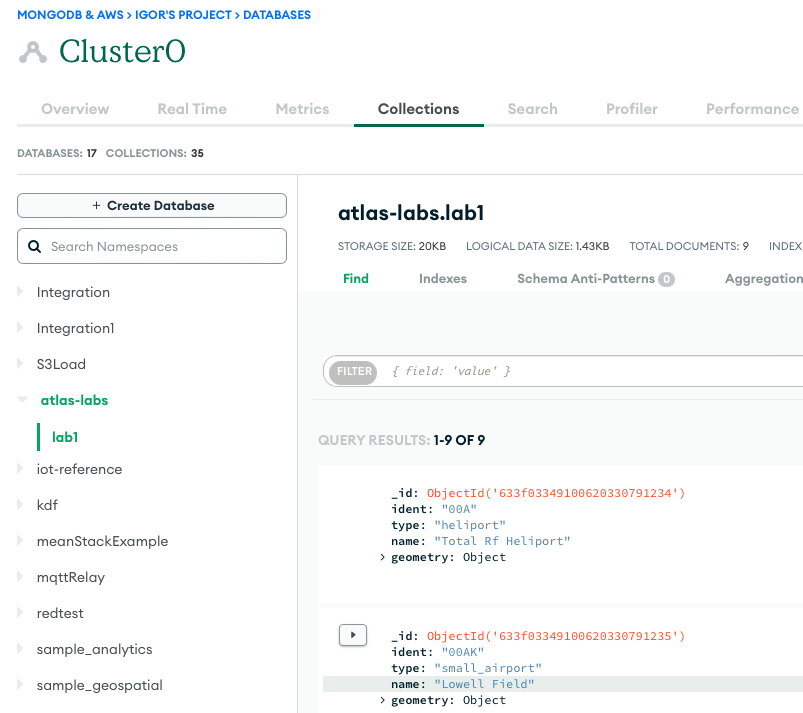
- 要排除运行故障,请查看 亚马逊CloudWatch 使用作业上的链接记录 运行 标签。
以下屏幕截图显示作业已成功运行,并提供了其他详细信息,例如指向 CloudWatch 日志的链接。

结论
在本文中,我们描述了如何使用 AWS Glue 将数据提取和提取到 MongoDB Atlas。
借助 AWS Glue ETL 作业,我们现在可以将数据从 MongoDB Atlas 传输到与 AWS Glue 兼容的源,反之亦然。 您还可以扩展解决方案以使用 AWS AI 和 ML 服务构建分析。
要了解更多信息,请参阅 GitHub存储库 有关分步说明和示例代码。 你可以采购 MongoDB地图集 在 AWS 市场上。
作者简介

伊戈尔·阿列克谢耶夫 是 AWS 数据和分析领域的高级合作伙伴解决方案架构师。 Igor 正在与战略合作伙伴合作,帮助他们构建复杂的 AWS 优化架构。 在加入 AWS 之前,作为一名数据/解决方案架构师,他在大数据领域实施了许多项目,包括 Hadoop 生态系统中的多个数据湖。 作为一名数据工程师,他参与了将 AI/ML 应用于欺诈检测和办公自动化的工作。
 巴布·斯里尼瓦桑(Babu Srinivasan) 是 MongoDB 的高级合作伙伴解决方案架构师。 在目前的职位上,他正在与 AWS 合作,为 AWS 和 MongoDB 解决方案构建技术集成和参考架构。 他在数据库和云技术方面拥有超过二十年的经验。 他热衷于为与跨多个地区的多个全球系统集成商 (GSI) 合作的客户提供技术解决方案。
巴布·斯里尼瓦桑(Babu Srinivasan) 是 MongoDB 的高级合作伙伴解决方案架构师。 在目前的职位上,他正在与 AWS 合作,为 AWS 和 MongoDB 解决方案构建技术集成和参考架构。 他在数据库和云技术方面拥有超过二十年的经验。 他热衷于为与跨多个地区的多个全球系统集成商 (GSI) 合作的客户提供技术解决方案。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- 与 Adryenn Ashley 一起铸造未来。 访问这里。
- 使用 PREIPO® 买卖 PRE-IPO 公司的股票。 访问这里。
- Sumber: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :具有
- :是
- 100
- 11
- a
- 对,能力--
- 关于
- ACCESS
- 横过
- 额外
- AI
- AI / ML
- 还
- Amazon
- 量
- an
- 分析
- 和
- 应用领域
- 应用程序开发
- 应用领域
- 应用
- 应用
- 架构
- 保健
- AS
- At
- 舆图
- 自动化
- 可使用
- AWS
- AWS胶水
- AWS Marketplace
- 已备份
- 基于
- 作为
- 之间
- 大
- 大数据运用
- 建立
- 建筑物
- 商业
- 商业智能
- 经营业绩
- 企业
- by
- 呼叫
- CAN
- 例
- 挑战
- 改变
- 云端技术
- 簇
- 码
- 采集
- 结合
- 购买的订单均
- 未来
- 复杂
- 计算
- 配置
- 确认
- 合并
- 建设
- Contents
- 持续
- 成本
- 创建信息图
- 创建
- 创建
- 创建
- 电流
- 合作伙伴
- data
- 数据工程师
- 数据集成
- 数据湖
- 数据科学
- 数据仓库
- 数据驱动
- 数据库
- 数据库
- 数据集
- 几十年
- 默认
- 演示
- 描述
- 描述
- 详情
- 检测
- 开发
- 研发支持
- 差异
- 不同
- 通过各种方式找到
- 不同
- 文件
- 域
- 驾驶
- 驱动
- ,我们将参加
- 生态系统
- 编辑
- 有效
- 发动机
- 工程师
- 工程师
- 输入
- 企业
- 企业客户
- 环境
- 醚(ETH)
- 例外
- 现有
- 体验
- 探索
- 延长
- 提取
- 萃取
- 面部彩妆
- 数字
- 文件
- 档
- 终于
- 平面
- 柔软
- 以下
- 针对
- 骗局
- 欺诈检测
- Free
- 止
- 充分
- 功能
- 地域
- 全球
- 事业发展
- Hadoop的
- 便利
- 有
- he
- 帮助
- 此处
- 他的
- 创新中心
- How To
- HTML
- HTTP
- HTTPS
- 巨大
- IAM
- 身分
- if
- 实施
- 实施
- 改善
- in
- 包含
- 增加
- 输入
- 说明
- 整合
- 集成
- 积分
- 集成
- 房源搜索
- 成
- 涉及
- 参与
- IT
- 它的
- 工作
- 工作机会
- 加入
- 加盟
- JSON
- 键
- 湖泊
- 大
- 学习用品
- 学习
- 离开
- 遗产
- 喜欢
- 友情链接
- 链接
- 加载
- 装载
- 寻找
- 机
- 机器学习
- 保养
- 制作
- 管理
- 管理的
- 许多
- 市场
- 可能..
- 迁移
- 移民
- ML
- 联络号码
- 模型
- 现代
- 现代化
- 现代化
- MongoDB的
- 更多
- 移动
- 运动
- 多
- 姓名
- 名称
- 需求
- 打印车票
- 需要
- 全新
- 现在
- 观察
- of
- 办公
- 经常
- on
- 一
- 操作
- 操作
- 优化
- 附加选项
- or
- 秩序
- 组织
- 输出
- 参数
- 合伙人
- 伙伴
- 通过
- 多情
- 密码
- 性能
- 执行
- 权限
- 地方
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 热门
- 帖子
- 功率
- 强大
- Prepare
- 准备
- 先决条件
- 以前
- 先
- 过程
- 过程
- 处理
- 项目
- 提供
- 优
- 目的
- 查询
- 很快
- 实时的
- 减少
- 可靠
- 要求
- 需要
- 资源
- REST的
- 成果
- 检讨
- 角色
- 运行
- 同
- 可扩展性
- 鳞片
- 科学
- 截图
- 搜索
- 安全
- 前辈
- 无服务器
- 服务
- 服务
- 特色服务
- 几个
- 如图
- 作品
- 显著
- 类似
- 简易
- 单
- 方案,
- 解决方案
- 来源
- 步
- 步骤
- 存储
- 商店
- 商店
- 简单的
- 善用
- 战略合作伙伴
- 精简
- 工作室
- 走向成功
- 成功
- 成功
- 顺利
- 这样
- 套房
- 供应
- 同步
- 系统
- 任务
- 文案
- 技术
- 比
- 这
- 其
- 他们
- 然后
- 博曼
- 他们
- Free Introduction
- 数千
- 次
- 至
- 今天的
- 一起
- 交易
- 转让
- 改造
- 转换
- 转型
- 转
- 二
- ui
- 相关
- 使用
- 用过的
- 用户
- 运用
- 价值观
- 非常
- 查看
- 想
- 是
- we
- 卷筒纸
- 为
- ,尤其是
- 是否
- 这
- 而
- 将
- 也完全不需要
- 工作流程
- 加工
- 将
- 您
- 您一站式解决方案
- 和风网