机器人律师。 学分:中途
如果你读过我的作品,你可能知道我首先在我的 AI 时事通讯中发表我的文章, 算法桥. 你可能不知道的是,每个星期天我都会发布一个特别的专栏,我称之为“你可能错过了什么”,我会回顾一周内发生的一切,并进行分析,帮助你理解新闻。
微软与 OpenAI 达成 10 亿美元的交易
Semafor 报告 两周前,如果一切按计划进行,微软将在 10 月底前与 OpenAI 达成 XNUMXB 美元的投资协议(微软首席执行官 Satya Nadella 宣布 扩大伙伴关系 周一正式)。
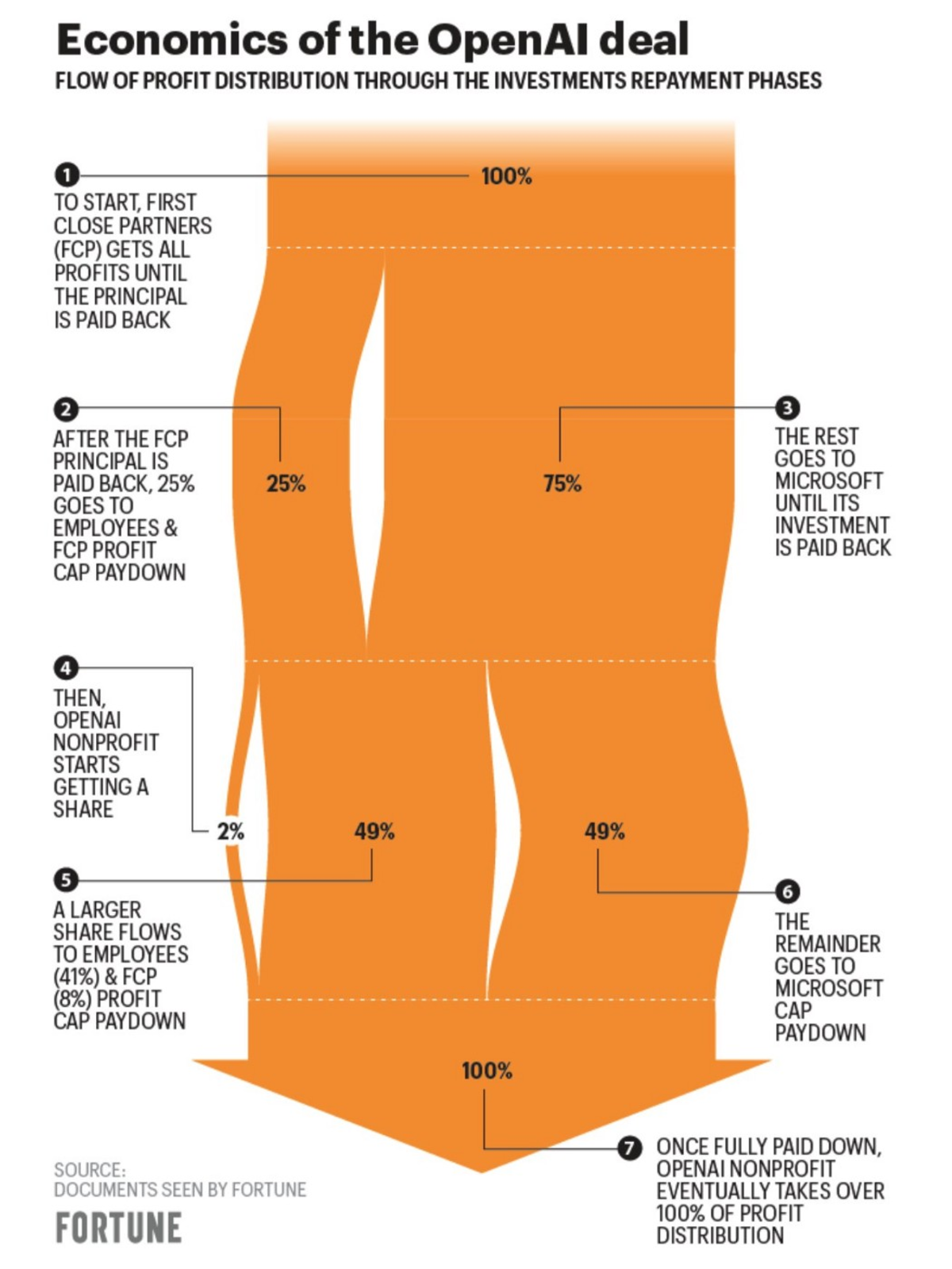
有一些关于这笔交易的错误信息暗示 OpenAI 的高管们不确定公司的长期生存能力。 然而, 后来澄清了 交易看起来像这样:
信用: 运气
Leo L'Orange,《神经元》的作者, 解释 “一旦 92 亿美元的利润加上 13 亿美元的初始投资被偿还给微软,一旦其他风险投资者赚到 150 亿美元,所有股权就会归还给 OpenAI。”
人们是分裂的。 有人说这笔交易“很酷”或“有趣”,而其他人则说它“奇怪”和“疯狂”。 我以非专家的眼光所感知的是 OpenAI 和 Sam Altman do 信任(有人会说 过度信任) 公司实现目标的长期能力。
但是, 威尔奈特写道 对于 WIRED,“目前还不清楚哪些产品可以基于该技术构建。” OpenAI 必须尽快找到可行的商业模式。
ChatGPT 的变化:新功能和货币化
OpenAI 更新了 ChatGPT 9 月 15 日(上次更新于 XNUMX 月 XNUMX 日)。 现在聊天机器人“改进了真实性”,你可以在生成中期停止它。
他们还在开发“ChatGPT 的专业版”(据传将在 $ 42 /月) 作为 OpenAI 的总裁 格雷格布罗克曼宣布 11 月 XNUMX 日。以下是三个主要特征:
“始终可用(没有停电窗口)。
来自 ChatGPT 的快速响应(即无节流)。
您需要多少消息(至少是常规每日限额的 2 倍)。”
要注册候补名单,您必须 填写表格 他们在哪里问你,除其他外,你愿意支付多少钱(以及多少会太多)。
如果你打算认真对待它,你应该考虑深入了解 OpenAI 的产品堆栈 OpenAI 食谱回购. Bojan Tunguz 说这是“本月 GitHub 上最热门的回购” 总是一个好兆头。
ChatGPT,假科学家
ChatGPT 已进入科学领域。 卡里姆卡尔 周四发布了一篇论文的截图,ChatGPT 是该论文的合著者。
但为什么,既然 ChatGPT 是一种工具呢? “人们开始将 ChatGPT 视为真正的、具有良好资质的科学 合作者”,加里·马库斯解释道 在 Substack 帖子中. “科学家们,请不要让你们的聊天机器人成长为合著者,”他恳求道。
更令人担忧的是那些没有披露人工智能使用情况的案例。 科学家们 已经发现 他们无法可靠地识别由 ChatGPT 编写的摘要——它雄辩的废话甚至愚弄了他们领域的专家。 正如在牛津“研究技术和监管”的 Sandra Wachter 告诉 Holly Else 一篇关于自然的文章:
“如果我们现在处于专家无法确定什么是真的或什么是假的情况下,我们就会失去我们迫切需要的中间人来指导我们解决复杂的话题。”
ChatGPT 对教育的挑战
ChatGPT 已在全球各地的教育中心被禁止(例如 纽约公立学校, 澳大利亚大学及 英国讲师 正在考虑)。 正如我在 之前的一篇文章,我认为这不是最明智的决定,而只是由于对生成式人工智能的快速发展毫无准备而做出的反应。
纽约时报的凯文罗斯认为 “[ChatGPT] 作为教育工具的潜力大于其风险。” 伟大的数学家陶哲轩, 同意:“从长远来看,与之抗争似乎是徒劳的; 也许我们作为讲师需要做的是转向“开放书籍,开放人工智能”的考试模式。”
贾达·皮斯蒂利Hugging Face 的首席伦理学家,解释了学校在 ChatGPT 方面面临的挑战:
“不幸的是,教育系统似乎被迫适应这些新技术。 作为一种反应,我认为这是可以理解的,因为在预测、减轻或制定替代解决方案以勾勒出可能产生的问题方面并没有做太多工作。 颠覆性技术通常需要对用户进行教育,因为它们不能不受控制地简单地扔给人们。”
最后一句话完美地抓住了问题出现的地方和潜在的解决方案所在。 我们必须付出额外的努力来教育用户这项技术是如何工作的,以及什么是可能的,而不是用他们做的。 这就是加泰罗尼亚采取的方法。 作为 Francesc Bracero 和 Carina Farreras 报告 对于 La Vanguardia:
“在加泰罗尼亚,教育部不会‘在整个系统和每个人中’禁止它,因为这将是一种无效的措施。” 据该部消息人士称,最好让这些中心进行人工智能使用方面的教育,“这可以提供很多知识和优势。”
学生最好的朋友:ChatGPT 错误数据库
加里·马库斯 (Gary Marcus) 和欧内斯特·戴维斯 (Ernest Davis) 建立了一个“错误跟踪器” 来捕获和分类像 ChatGPT 这样的语言模型的错误 (这里有更多信息 关于他们为什么要编写这份文件以及他们打算用它做什么)。
该数据库是公开的,任何人都可以参与。 这是一个很好的资源,可以用来严格研究这些模型如何行为不端以及人们如何避免误用。 这是为什么这很重要的一个搞笑的例子:
OpenAI 意识到了这一点,并希望与错误和虚假信息作斗争:“预测用于虚假宣传活动的语言模型的潜在滥用——以及如何降低风险设立的区域办事处外,我们在美国也开设了办事处,以便我们为当地客户提供更多的支持。“
新的信息
山姆奥特曼暗示 在与 GPT-4 的对话中延迟发布 康妮Loizos,TechCrunch 的硅谷编辑。 Altman 说:“总的来说,我们发布技术的速度比人们希望的要慢得多。 我们将在上面坐更长的时间……”这是我的看法:
(奥特曼还说有一个视频模型正在制作中!)
关于 GPT-4 的错误信息
社交媒体上到处都有“GPT-4 = 100T”的说法(我主要是在 Twitter 和 LinkedIn 上看到的)。 如果您还没有看到它,它看起来像这样:
或这个:
所有这些都是同一事物的略有不同的版本:吸引注意力的吸引人的可视化图表,以及与 GPT-4/GPT-3 比较的强大关联(他们使用 GPT-3 作为 ChatGPT 的代理)。
我认为分享谣言和猜测并以此来构建它们是可以的(我觉得对此负有部分责任),但以权威的语气发布无法验证的信息且没有参考文献是应该受到谴责的。
这样做的人在信息来源方面与 ChatGPT 一样无用和危险——并且有更强烈的动机继续这样做。 当心这一点,因为它会污染有关 AI 的所有信息渠道。
机器人律师
DoNotPay 首席执行官 Joshua Browder, 于 9 月 XNUMX 日发布:
否则,这一大胆的主张产生了 很多争论 以至于 Twitter 现在用链接标记推文 最高法院违禁物品页面.
即使他们最终由于法律原因不能这样做,也值得从道德和社会的角度考虑这个问题。 如果人工智能系统犯了严重的错误会怎样? 可以 无法访问的人 律师从这项技术的成熟版本中获益?
针对稳定扩散的诉讼已经开始
马修·巴特里克 发表于 13 月 XNUMX 日:
“代表三个精彩 艺术家原告 - 莎拉·安徒生, 凯利麦克南及 卡拉·奥尔蒂斯 - 我们已经针对 稳定性人工智能, deviantART的及 中途 供他们使用 稳定扩散,一种 21 世纪的拼贴工具,可以重新混合数百万艺术家的受版权保护的作品,这些艺术家的作品被用作训练数据。”
它开始了——这有望成为一场长期斗争的第一步,以缓和生成人工智能的培训和使用。 我同意这样的动机:“AI 需要对每个人都公平和合乎道德。”
但 像许多其他人一样,我在博文中发现了不准确之处。 它深入研究了稳定扩散的技术细节,但未能正确解释某些部分。 这是否是有意为那些不知道——也没有时间学习——这项技术如何工作的人弥合技术差距的一种手段(或者作为一种以有利于他们的方式描述技术特征的手段) 或一个错误是开放的猜测。
我争吵了 在上一篇文章中 现在人工智能艺术和传统艺术家之间的冲突是非常情绪化的。 对这起诉讼的回应不会有任何不同。 我们将不得不等待评委决定结果。
CNET 发布 AI 生成的文章
未来主义报道 这是几周前的:
“CNET, 一家广受欢迎的科技新闻媒体,一直在悄悄地利用“自动化技术”——人工智能的一种文体委婉说法——来推出新一波的金融解释文章。
最早发现这一点的盖尔·布雷顿 (Gael Breton) 星期五写了更深入的分析. 他解释说,谷歌似乎并没有阻碍这些帖子的流量。 “AI内容现在可以了吗?” 他问.
我发现这是 CNET 的决定 充分披露人工智能的使用 在他们的文章中有一个很好的先例。 现在有多少人在不公开的情况下使用 AI 发布内容? 然而,结果是,如果这样做的话,人们可能会失去工作(就像我和其他许多人一样, 都曾预测). 它已经在发生:
我完全同意圣地亚哥的这条推文:
用于图像生成的 RLHF
如果通过人类反馈的强化学习适用于语言模型,为什么不适用于文本到图像? 这就是 PickaPic 正在努力实现的目标。
演示 用于研究目的,但可能是对 Stable Diffusion 或 DALL-E 的有趣补充(Midjourney 做了类似的事情——它们在内部引导模型输出美丽的艺术图像)。
“让 Siri/Alexa 性能提升 10 倍”的秘诀
混合不同的生成 AI 模型以创建比部分总和更好的方法:
阿尔贝托·罗梅罗 是一名专注于技术和人工智能的自由撰稿人。 他写 算法桥,帮助非技术人员理解 AI 新闻和事件的时事通讯。 他还是 CambrianAI 的技术分析师,专门研究大型语言模型。
原版。 经许可重新发布。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://www.kdnuggets.com/2023/02/chatgpt-gpt4-generative-ai-news.html?utm_source=rss&utm_medium=rss&utm_campaign=chatgpt-gpt-4-and-more-generative-ai-news
- 11
- 7
- 9
- a
- 对,能力--
- Able
- 关于
- 关于它
- 摘要
- 根据
- 横过
- 适应
- 增加
- 优点
- 驳
- AI
- 人工智能艺术
- 算法
- 所有类型
- 允许
- 已经
- 替代
- 时刻
- 其中
- 分析
- 分析人士
- 和
- 公布
- 预料
- 任何人
- 吸引人的
- 的途径
- 艺术
- 刊文
- 艺术的
- 艺术家
- 关注我们
- 可使用
- 背部
- 禁止
- 美丽
- 因为
- before
- 作为
- 得益
- 好处
- 最佳
- 更好
- 之间
- 提防
- 亿
- 博客
- 无所畏惧
- 书籍
- 桥
- 建
- 商业
- 商业模式
- 呼叫
- 活动
- 不能
- 捕获
- 捕获
- 案件
- 例
- 中心
- CEO
- 挑战
- 渠道
- 特点
- 聊天机器人
- 聊天机器人
- ChatGPT
- 要求
- 冲
- 分类
- 关闭
- CNET
- 合著者
- 柱
- COM的
- 公司的
- 对照
- 复杂
- 考虑
- 考虑
- 内容
- 谈话
- 可以
- 情侣
- 法庭
- 创建信息图
- 信用
- 每天
- 达尔-e
- 危险的
- data
- 数据库
- 戴维斯
- 处理
- 决定
- 深
- 更深
- 延迟
- 需求
- 问题类型
- 确定
- 研发支持
- 不同
- 扩散
- 透露
- 揭露
- 泄露
- 造谣
- 破坏性
- 分
- 文件
- 不会
- 做
- 域
- 别
- ,我们将参加
- 赚
- 编辑
- 教育
- 教育
- 教育的
- 努力
- 阐述
- 进入
- 整个
- 公平
- 故障
- 醚(ETH)
- 伦理
- 甚至
- 事件
- 所有的
- 每个人
- 一切
- 例子
- 高管
- 专家
- 说明
- 介绍
- 额外
- 眼部彩妆
- 面部彩妆
- 失败
- 公平
- 假
- 高效率
- 特征
- 反馈
- 部分
- 战斗
- 数字
- 终于
- 金融
- 找到最适合您的地方
- (名字)
- 第一步
- 标志
- 重点
- 最重要的
- 向前
- 发现
- 自由职业者
- 朋友
- 止
- 充分
- 差距
- 家辉
- 其他咨询
- 生成的
- 生成式人工智能
- GitHub上
- 特定
- 地球
- Go
- 理想中
- GOES
- 去
- 非常好
- 谷歌
- 图形
- 大
- 增长
- 指南
- 发生
- 发生
- 帮助
- 帮助
- 欢闹的
- 创新中心
- How To
- 但是
- HTML
- HTTPS
- 人
- 鉴定
- 图片
- 图片
- 默示
- in
- 激励
- info
- 信息
- 初始
- 故意
- 有趣
- 内部
- 投资
- 投资者
- IT
- 一月三十一日
- 一月
- 工作机会
- 掘金队
- 保持
- 骑士
- 知道
- 知识
- 语言
- 大
- (姓氏)
- 诉讼
- 律师
- 学习用品
- 学习
- 法律咨询
- 极限
- 友情链接
- 长
- 长期
- LOOKS
- 失去
- 占地
- 主要
- 使
- 制作
- 许多
- 很多人
- 马库斯
- 大规模
- 事项
- 成熟
- 手段
- 衡量
- 媒体
- 中等
- 仅仅
- 条未读消息
- 微软
- 中途
- 事工
- 误传
- 错误
- 减轻
- 时尚
- 模型
- 模型
- 周一
- 更多
- 动机
- 移动
- 自然
- 需求
- 需要
- 全新
- 新功能
- 新技术
- 消息
- 新闻与活动
- 订阅电子邮件
- 非技术
- 正式
- 好
- 打开
- OpenAI
- 其他名称
- 其它
- 除此以外
- 成果
- 牛津
- 纸类
- 参加
- 部分
- 员工
- 也许
- 允许
- 片
- 计划
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 恳求
- 请
- 加
- 点
- 热门
- 可能
- 帖子
- 发布
- 帖子
- 潜力
- 先例
- 以前
- 校长
- 大概
- 市场问题
- 问题
- 产品
- 核心产品
- 利润
- 禁止
- 承诺
- 提供
- 代理
- 国家
- 发布
- 出版
- 目的
- 题
- 悄悄
- 反应
- 阅读
- 原因
- 食谱
- 减少
- 引用
- 定期
- 强化学习
- 释放
- 研究
- 资源
- 提供品牌战略规划
- 导致
- 检讨
- 严格
- 风险
- 机器人
- 传闻
- 说
- Sam
- 同
- 萨蒂亚纳德拉
- 学区情况
- 似乎
- Semafor
- 感
- 句子
- 严重
- 集
- 共享
- 应该
- 签署
- 硅
- 硅谷
- 类似
- 只是
- 自
- 情况
- 略有不同
- 慢慢地
- 社会
- 社会化媒体
- 方案,
- 解决方案
- 一些
- 东西
- 不久
- 来源
- 特别
- 专业
- 推测
- 稳定
- 堆
- 开始
- 步骤
- Stop 停止
- 强烈
- 强
- 非常
- 学习
- 这样
- 系统
- 采取
- 科技
- 科技新闻
- TechCrunch
- 文案
- 技术
- 专业技术
- 其
- 事
- 事
- 思维
- 三
- 通过
- 次
- 至
- TONE
- 也有
- 工具
- 最佳
- Topics
- 传统
- 交通
- 产品培训
- 治疗
- 趋势
- true
- 信任
- 鸣叫
- typeform
- 可理解的
- 更新
- 更新
- us
- 使用
- 用户
- 用户
- 谷
- 冒险
- 版本
- 可行性
- 可行
- 视频
- 等待
- 波
- 周
- 周
- 什么是
- 是否
- 这
- WHO
- 将
- 愿意
- 窗户
- 也完全不需要
- 工作
- 加工
- 合作
- 价值
- 将
- 作家
- 书面
- 您一站式解决方案
- 和风网