改善用户发现新内容的方式对于提高用户在媒体平台上的参与度和满意度至关重要。仅关键字搜索就很难捕获语义和用户意图,从而导致结果缺乏相关上下文;例如,寻找约会之夜或圣诞节主题的电影。如果用户无法可靠地找到他们想要的内容,这可能会降低保留率。然而,随着 大型语言模型 (法学硕士),有机会解决这些语义和用户意图挑战。通过结合 嵌入 使用一种称为的技术捕获语义 检索增强生成 (RAG),您可以根据从您自己的数据源检索到的上下文生成更相关的答案。
在这篇文章中,我们将向您展示如何通过使用您自己的数据实现 RAG 来安全地创建电影聊天机器人 知识库 亚马逊基岩。我们使用 IMDb 和 Box Office Mojo 数据集来模拟媒体和娱乐客户的目录,并展示如何只需几个步骤即可构建自己的 RAG 解决方案。
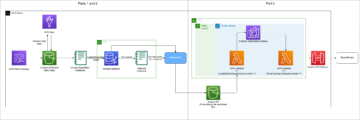
解决方案概述
IMDb 和 Box Office Mojo 电影/电视/OTT 可授权数据包提供范围广泛的娱乐元数据,包括超过 1.6 亿的用户评级; 超过 13 万演职人员的演职员表; 10 万部电影、电视和娱乐节目; 以及来自 60 多个国家/地区的全球票房报告数据。 许多 AWS 媒体和娱乐客户通过 AWS数据交换 以改进内容发现并提高客户参与度和保留率。
Amazon Bedrock 知识库简介
为了给法学硕士配备最新的专有信息,组织使用 RAG,这是一种从公司数据源获取数据并使用该数据丰富提示的技术,以提供更相关和更准确的响应。 Amazon Bedrock 知识库支持完全托管的 RAG 功能,允许您使用上下文和相关公司数据自定义 LLM 响应。知识库自动执行端到端 RAG 工作流程,包括摄取、检索、提示增强和引用,从而无需编写自定义代码来集成数据源和管理查询。 Amazon Bedrock 的知识库还支持多轮对话,以便法学硕士可以用正确的答案回答复杂的用户查询。
我们使用以下服务作为此解决方案的一部分:
我们将完成以下高级步骤:
- 预处理 IMDb 数据以从每个电影记录创建文档并将数据上传到 亚马逊简单存储服务 (Amazon S3)存储桶。
- 创建知识库。
- 将您的知识库与数据源同步。
- 使用知识库回答有关电影目录的语义查询。
先决条件
本文中使用的 IMDb 数据需要商业内容许可证并付费订阅 AWS Data Exchange 上的 IMDb 和 Box Office Mojo 电影/电视/OTT 许可包。要查询许可证并访问示例数据,请访问 开发者.imdb.com。要访问数据集,请参阅 使用 IMDb 知识图进行强力推荐和搜索——第 1 部分 并按照 访问 IMDb 数据 部分。
预处理 IMDb 数据
在创建知识库之前,我们需要将 IMDb 数据集预处理为文本文件并将其上传到 S3 存储桶。在这篇文章中,我们使用 IMDb 数据集模拟客户目录。我们从 IMDb 数据集中选取 10,000 部热门电影作为目录并构建数据集。
使用以下内容 笔记本 使用演员、导演和制片人姓名等附加信息创建数据集。我们使用以下代码为电影创建一个文件,其中所有信息都以法学硕士可以理解的非结构化文本形式存储在文件中:
获得 .txt 格式的数据后,您可以使用以下命令将数据上传到 Amazon S3:
创建 IMDb 知识库
完成以下步骤来创建您的知识库:
- 在 Amazon Bedrock 控制台上,选择 知识库 在导航窗格中。
- 创建知识库.
- 针对 知识库名称,输入
imdb. - 针对 知识库描述,输入可选描述,例如用于提取和存储 imdb 数据的知识库。
- 针对 IAM 权限, 选择 创建并使用新的服务角色,然后输入新服务角色的名称。
- 下一页.
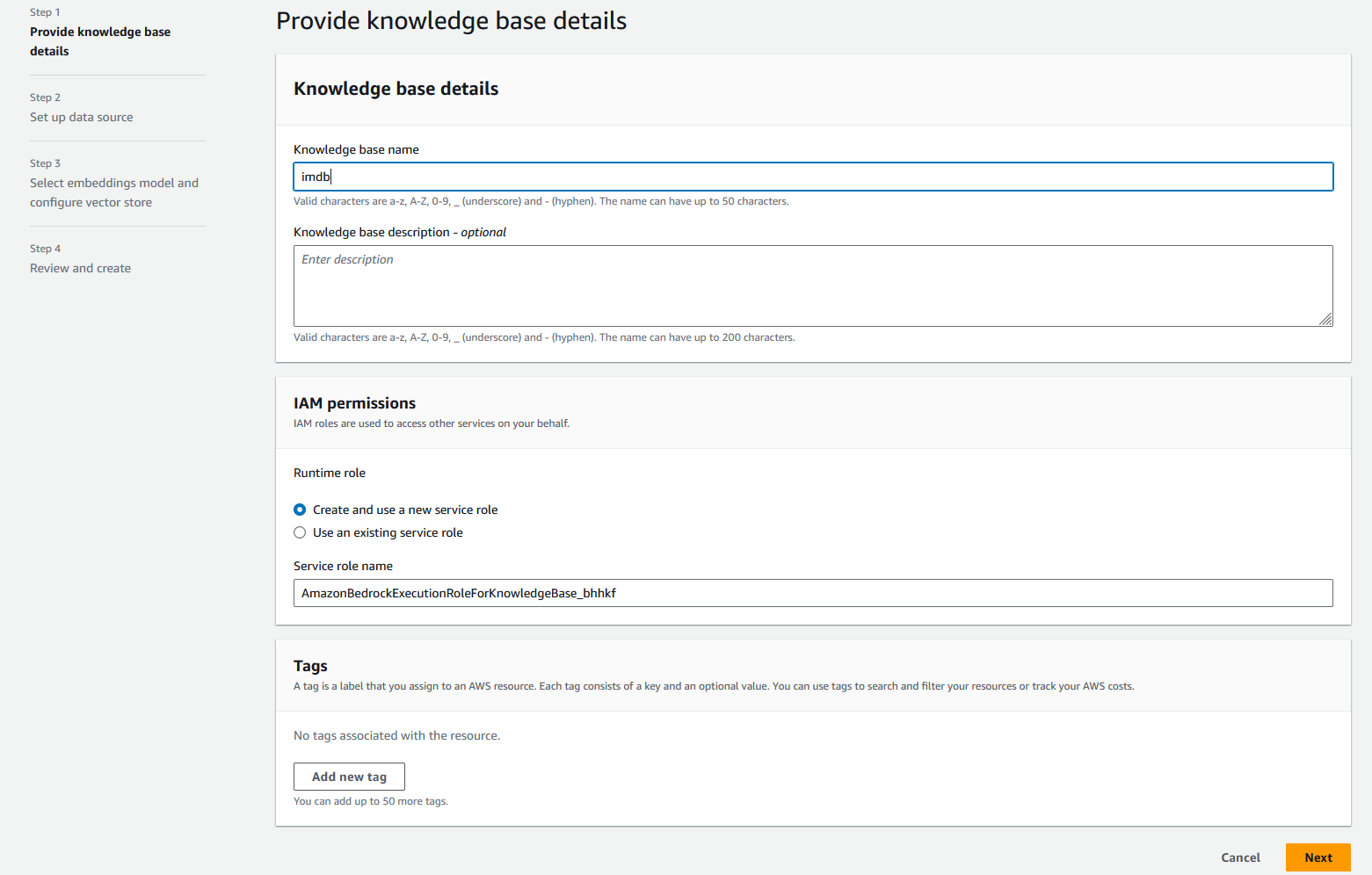
- 针对 资料来源名称,输入
imdb-s3. - 针对 S3 URI,输入您将数据上传到的 S3 URI。
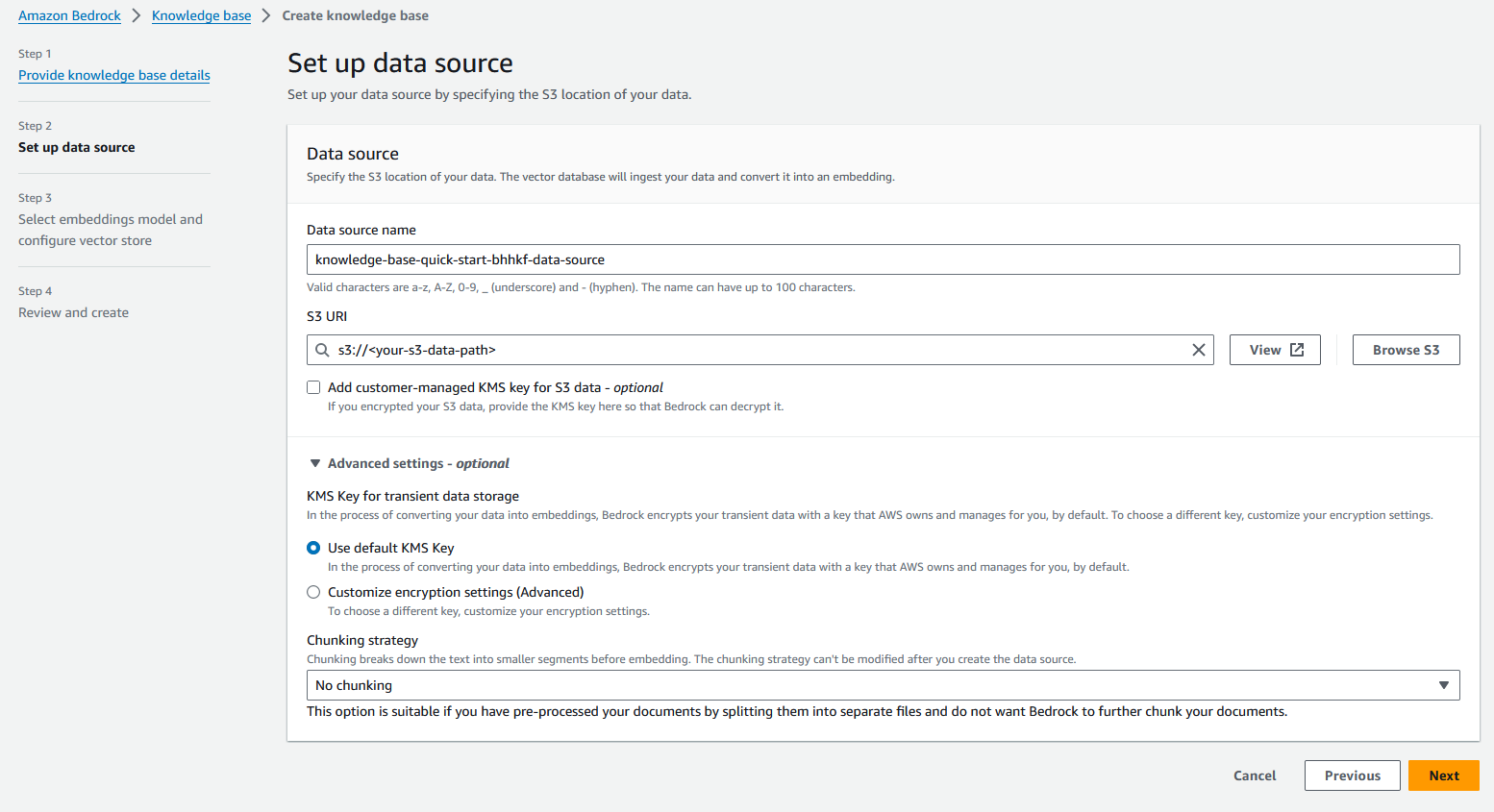
- 在 高级设置 – 可选 部分,用于 分块策略,选择 无分块.
- 下一页.
知识库使您能够将文档分成更小的部分,以便您可以轻松地处理大型文档。在我们的例子中,我们已经将数据分块为较小的文档(每部电影一个)。
- 在 矢量数据库 部分,选择 快速创建新的矢量存储.
Amazon Bedrock 将自动创建完全托管的 OpenSearch Serverless 矢量搜索集合,并使用所选的 Titan Embedding G1 – 文本嵌入模型配置用于嵌入数据源的设置。
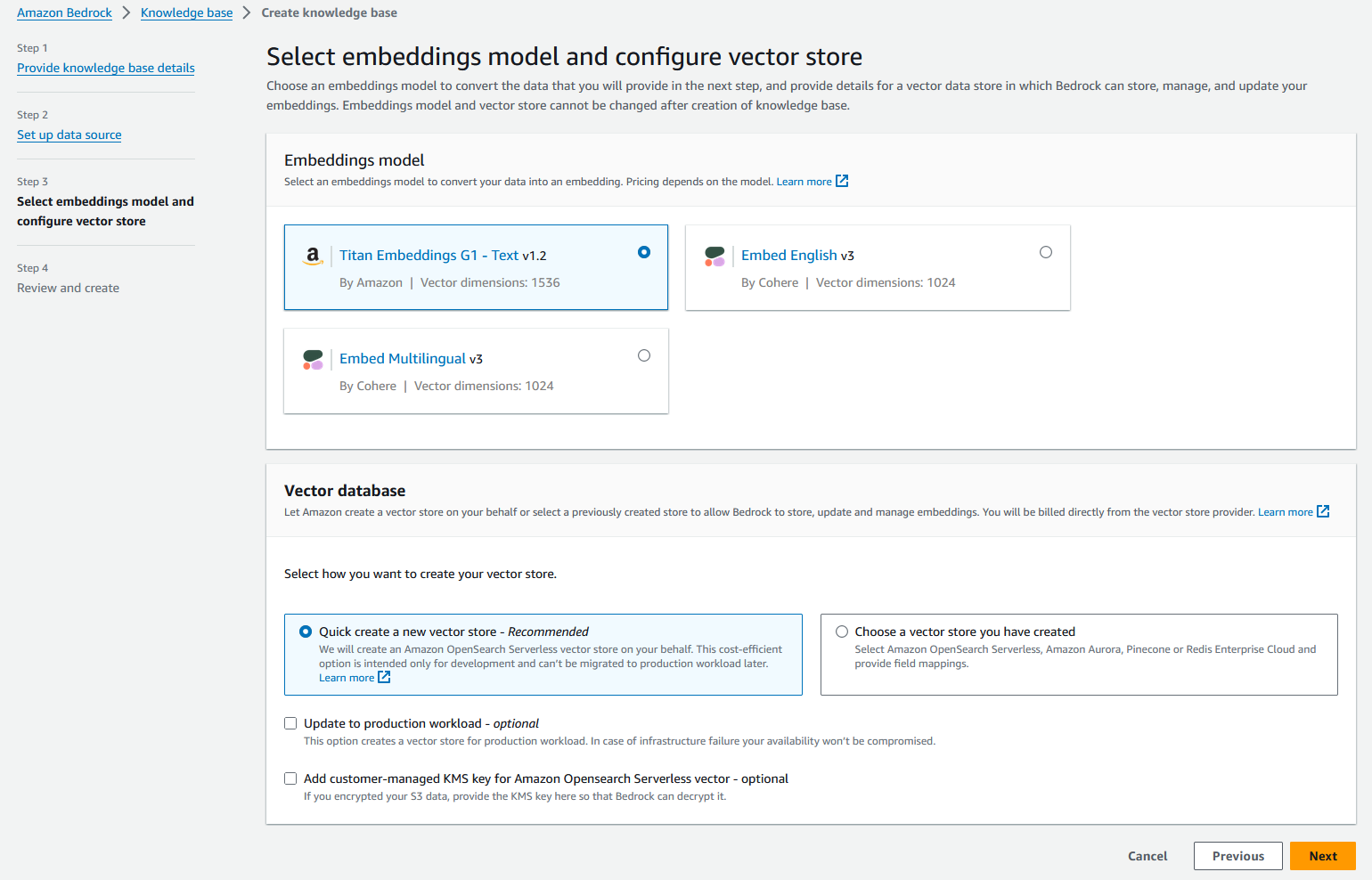
- 下一页.
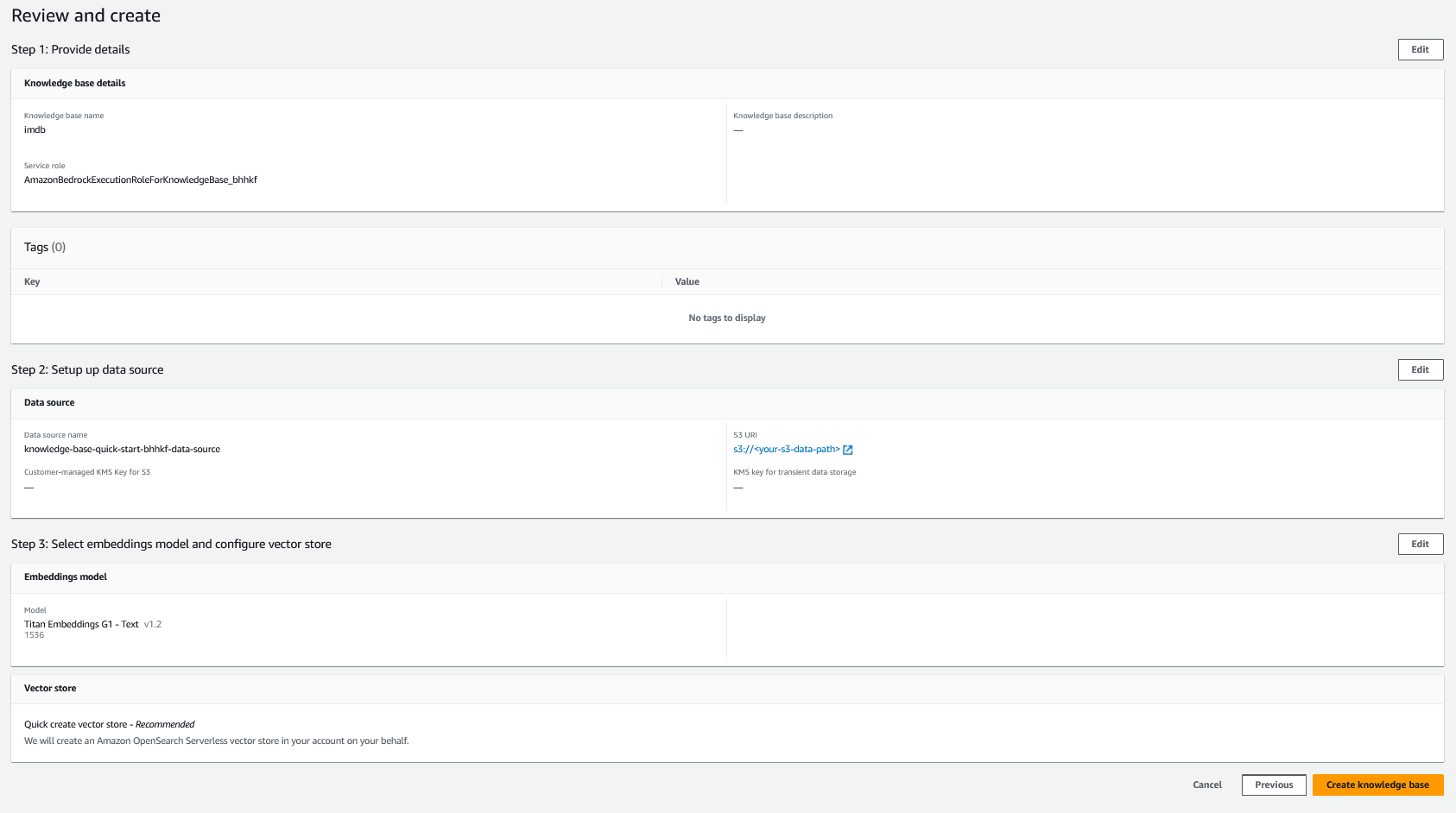
- 查看您的设置并选择 创建知识库.
将您的数据与知识库同步
现在您已经创建了知识库,您可以将知识库与您的数据同步。
- 在 Amazon Bedrock 控制台上,导航到您的知识库。
- 在 数据源 部分中,选择 Sync.

数据源同步后,您就可以查询数据了。
使用语义结果改进搜索
请完成以下步骤来测试解决方案并使用语义结果改进搜索:
- 在 Amazon Bedrock 控制台上,导航到您的知识库。
- 选择您的知识库并选择 测试知识库.
- 选择型号,并选择 人类克劳德 v2.1.
- 使用.
现在您可以查询数据了。
我们可以问一些语义问题,例如“推荐一些圣诞节主题的电影”。
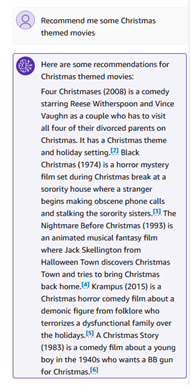
知识库响应包含引文,您可以探索响应的正确性和真实性。
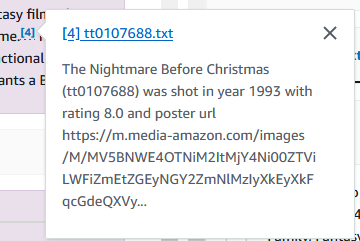
您还可以从这些电影中深入了解所需的任何信息。在下面的例子中,我们问“谁在圣诞节前导演了噩梦?”

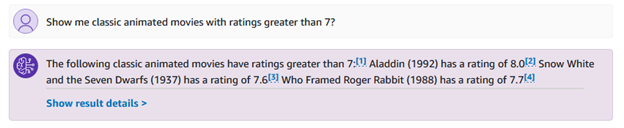
您还可以提出与类型和收视率相关的更具体的问题,例如“向我展示收视率大于 7 的经典动画电影?”
通过代理扩充您的知识库
亚马逊基岩代理 帮助您自动执行复杂的任务。代理可以将用户查询分解为更小的任务,并调用自定义 API 或知识库来补充运行操作的信息。借助 Agents for Amazon Bedrock,开发人员可以将智能代理集成到他们的应用程序中,从而加速 AI 支持的应用程序的交付并节省数周的开发时间。通过代理,您可以通过添加更多功能(例如来自的推荐)来扩充您的知识库 亚马逊个性化 用于特定于用户的推荐或执行操作,例如根据用户需求过滤电影。
结论
在这篇文章中,我们展示了如何使用 Amazon Bedrock 通过几个步骤构建对话式电影聊天机器人,以根据您自己的数据以及 IMDb 和 Box Office Mojo 电影/电视/OTT 许可数据集回答语义搜索和对话体验。在下一篇文章中,我们将介绍使用 Agents for Amazon Bedrock 向您的解决方案添加更多功能的过程。要开始使用 Amazon Bedrock 上的知识库,请参阅 Amazon Bedrock 知识库.
作者简介
 高拉夫·雷尔(Gaurav Rele) 是生成式 AI 创新中心的高级数据科学家,他与不同垂直领域的 AWS 客户合作,加速他们使用生成式 AI 和 AWS 云服务来解决业务挑战。
高拉夫·雷尔(Gaurav Rele) 是生成式 AI 创新中心的高级数据科学家,他与不同垂直领域的 AWS 客户合作,加速他们使用生成式 AI 和 AWS 云服务来解决业务挑战。
 迪维亚·巴尔加维(Divya Bhargavi) 是生成式 AI 创新中心的高级应用科学家主管,她使用生成式 AI 方法为 AWS 客户解决高价值的业务问题。她致力于图像/视频理解和检索、知识图增强大型语言模型和个性化广告用例。
迪维亚·巴尔加维(Divya Bhargavi) 是生成式 AI 创新中心的高级应用科学家主管,她使用生成式 AI 方法为 AWS 客户解决高价值的业务问题。她致力于图像/视频理解和检索、知识图增强大型语言模型和个性化广告用例。
 苏伦·贡图鲁 是在生成式 AI 创新中心工作的数据科学家,他与各种 AWS 客户合作解决高价值的业务问题。他专门使用大型语言模型(主要通过 Amazon Bedrock 和其他 AWS 云服务)构建 ML 管道。
苏伦·贡图鲁 是在生成式 AI 创新中心工作的数据科学家,他与各种 AWS 客户合作解决高价值的业务问题。他专门使用大型语言模型(主要通过 Amazon Bedrock 和其他 AWS 云服务)构建 ML 管道。
 维迪亚·萨加尔·拉维帕蒂(Vidya Sagar Ravipati) 是生成式 AI 创新中心的科学经理,他利用自己在大规模分布式系统方面的丰富经验以及对机器学习的热情,帮助不同行业垂直领域的 AWS 客户加速 AI 和云的采用。
维迪亚·萨加尔·拉维帕蒂(Vidya Sagar Ravipati) 是生成式 AI 创新中心的科学经理,他利用自己在大规模分布式系统方面的丰富经验以及对机器学习的热情,帮助不同行业垂直领域的 AWS 客户加速 AI 和云的采用。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 赋予自己力量。 访问这里。
- 柏拉图爱流。 Web3 智能。 知识放大。 访问这里。
- 柏拉图ESG。 碳, 清洁科技, 能源, 环境, 太阳能, 废物管理。 访问这里。
- 柏拉图健康。 生物技术和临床试验情报。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- :具有
- :是
- :在哪里
- 10 百万美元
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- 关于
- 加快
- 加速
- ACCESS
- 精准的
- 横过
- 行动
- 演员
- 添加
- 额外
- 采用
- 广告
- 中介代理
- AI
- AI供电
- 所有类型
- 允许
- 单
- 已经
- 还
- Amazon
- 亚马逊网络服务
- an
- 和
- 回答
- 答案
- 任何
- APIs
- 应用领域
- 应用的
- 应用
- 保健
- AS
- 问
- At
- 增加
- 增强
- 自动化
- 自动
- AWS
- 基地
- 基于
- BE
- before
- 亿
- 盒子
- 票房
- 午休
- 建立
- 建筑物
- 商业
- by
- 呼叫
- 被称为
- CAN
- 能力
- 捕获
- 捕获
- 案件
- 例
- 检索目录
- Center
- 挑战
- 聊天机器人
- 选择
- 圣诞
- 经典
- 云端技术
- 云采用
- 云服务
- 码
- 采集
- 结合
- 商业的
- 公司
- 复杂
- 安慰
- 包含
- 内容
- 上下文
- 上下文
- 听起来像对话
- 对话
- 正确
- 国家
- 情侣
- 创建信息图
- 创建
- 积分
- 船员
- 危急
- 习俗
- 顾客
- 客户参与
- 合作伙伴
- 定制
- data
- 数据交换
- 数据科学家
- 日期
- 交付
- 交货
- 描述
- 详情
- 开发
- 研发支持
- 不同
- 针对
- 副总经理
- 团队介绍
- 通过各种方式找到
- 发现
- 分布
- 分布式系统
- 文件
- 文件
- 向下
- 驾驶
- 消除
- 嵌入
- enable
- 端至端
- 订婚
- 充实
- 输入
- 娱乐
- 醚(ETH)
- 所有的
- 例子
- 交换
- 体验
- 体验
- 探索
- 少数
- 文件
- 档
- 过滤
- 找到最适合您的地方
- 寻找
- 遵循
- 以下
- 针对
- 格式
- 止
- 充分
- 功能
- g1
- 生成
- 代
- 生成的
- 生成式人工智能
- 流派
- 得到
- 全球
- Go
- 图形
- 更大的
- 有
- he
- 帮助
- 高水平
- 他的
- 创新中心
- How To
- 但是
- HTML
- HTTP
- HTTPS
- if
- 实施
- 改善
- in
- 包含
- 增加
- 行业中的应用:
- info
- 信息
- 創新
- 查询
- 整合
- 智能化
- 意图
- 成
- 涉及
- IT
- JPG
- 只是
- 知识
- 缺乏
- 语言
- 大
- 大规模
- 铅
- 领导
- 学习
- 杠杆
- 执照
- 行货
- 许可证
- 喜欢
- LLM
- 本地
- 圖書分館的位置
- 降低
- 机
- 机器学习
- 使
- 管理
- 管理
- 经理
- 许多
- me
- 媒体
- 成员
- 元数据
- 方法
- 百万
- ML
- 模型
- 模型
- MOJO
- 更多
- 电影
- 电影
- 姓名
- 名称
- 导航
- 旅游导航
- 需求
- 需要
- 全新
- 下页
- 夜
- of
- 办公
- on
- 一
- ZAP优势
- or
- 组织
- 其他名称
- 我们的
- 超过
- 己
- 包
- 页
- 支付
- 面包
- 部分
- 情
- 径
- 为
- 执行
- 个性化你的
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 情节
- 热门
- 帖子
- 海报
- 主要
- 问题
- 过程
- 制片人
- 生产者
- 所有权
- 提供
- 查询
- 询问
- 有疑问吗?
- 抹布
- 范围
- 价格表
- 等级
- 评分
- 准备
- 建议
- 推荐
- 建议
- 记录
- 参考
- 有关
- 相应
- 报告
- 需要
- 响应
- 回复
- 成果
- 保留
- 恢复
- 回报
- 角色
- 行
- 运行
- 满意
- 保存
- 科学
- 科学家
- 搜索
- 部分
- 安全
- 中模板
- 选择
- 语义
- 语义
- 前辈
- 无服务器
- 服务
- 特色服务
- 设置
- 她
- 射击
- 显示
- 展示
- 显示
- 简易
- 模拟
- 单
- 尺寸
- 小
- So
- 方案,
- 解决
- 解决
- 一些
- 来源
- 来源
- 专业
- 具体的
- 开始
- 步骤
- 存储
- 商店
- 存储
- 简单的
- 订阅
- 这样
- 补充
- 同步。
- 产品
- 采取
- 任务
- 技术
- test
- 文本
- 比
- 这
- 信息
- 其
- 他们
- 主题
- 然后
- 那里。
- 博曼
- 他们
- Free Introduction
- 通过
- 次
- 泰坦
- 标题
- 至
- tv
- 理解
- 了解
- 非结构化
- 跟上时代的
- 上传
- 的URI
- 网址
- 使用
- 用过的
- 用户
- 用户
- 运用
- 各个
- 广阔
- 垂直
- 参观
- W
- 走
- 想
- 是
- we
- 卷筒纸
- Web服务
- 周
- 宽
- 大范围
- 将
- 工作流程
- 加工
- 合作
- 写
- X
- 年
- 您
- 您一站式解决方案
- 和风网