我们生活在由低延迟数据流应用程序驱动的实时数据和洞察时代。如今,每个人都希望在任何应用程序中获得个性化体验,组织也在不断创新以提高业务运营和决策的速度。随着新业务和客户用例引入不同格式的数据,产生的时间敏感数据量正在迅速增加。因此,组织采用低延迟、可扩展且可靠的数据流基础设施来提供实时业务应用程序和更好的客户体验至关重要。
这是博客系列的第一篇文章,该系列提供了使用 Kinesis Data Streams 为各种用例构建实时数据流基础设施的常见架构模式。它旨在提供一个框架,使用以下方式在 AWS 云上创建低延迟流应用程序: Amazon Kinesis数据流 和 AWS 专门构建的数据分析服务.
在这篇文章中,我们将回顾两个用例的常见架构模式:时间序列数据分析和事件驱动的微服务。在我们系列的后续文章中,我们将探讨为实时 BI 仪表板、联络中心代理、账本数据、个性化实时推荐、日志分析、物联网数据、变更数据捕获和实时数据构建流式管道的架构模式。 - 时间营销数据。所有这些架构模式都与 Amazon Kinesis Data Streams 集成。
使用 Kinesis Data Streams 进行实时流式传输
Amazon Kinesis Data Streams 是一种云原生、无服务器流数据服务,可以轻松捕获、处理和存储任何规模的实时数据。借助 Kinesis Data Streams,您可以每秒从数十万个源收集和处理数百 GB 的数据,从而使您可以轻松编写实时处理信息的应用程序。收集到的数据可在几毫秒内获得,以支持实时分析用例,例如实时仪表板、实时异常检测和动态定价。默认情况下,Kinesis Data Stream 中的数据会存储 24 小时,并且可以选择将数据保留期延长至 365 天。如果客户希望通过多个应用程序实时处理相同的数据,那么他们可以使用增强型扇出 (EFO) 功能。在此功能之前,每个使用流数据的应用程序共享 2MB/秒/分片输出。通过将流消费者配置为使用增强型扇出,每个数据消费者可以接收每个分片的专用 2MB/秒读取吞吐量管道,以进一步减少数据检索的延迟。
为了实现高可用性和持久性,Kinesis Data Streams 通过在 AWS 区域中的三个可用区同步复制流数据来实现高持久性,并让您可以选择将数据保留长达 365 天。为了安全起见,Kinesis Data Streams 提供服务器端加密,因此您可以通过加密静态数据和 Amazon Virtual Private Cloud (VPC) 接口终端节点来满足严格的数据管理要求,从而保持 Amazon VPC 和 Kinesis Data Streams 之间的流量私有。
Kinesis Data Streams 与其他 AWS 服务具有本机集成,例如 AWS胶水 和 亚马逊EventBridge 在 AWS 上构建实时流应用程序。有关更多详细信息,请参阅 Amazon Kinesis Data Streams 集成。
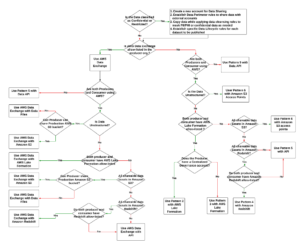
具有 Kinesis Data Streams 的现代数据流架构
具有 Kinesis Data Streams 的现代流数据架构可以设计为五个逻辑层的堆栈;每一层都由多个满足特定要求的专用组件组成,如下图所示:
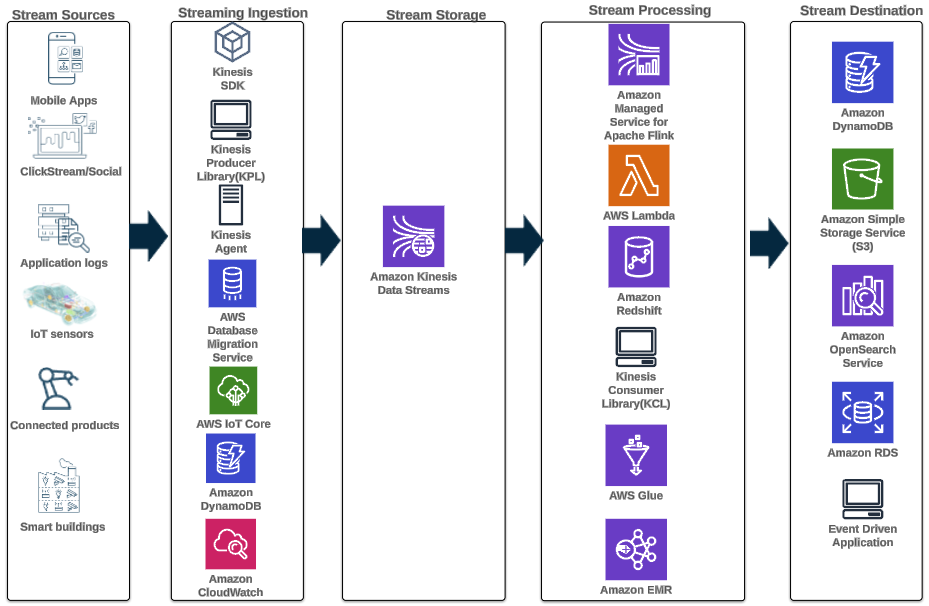
该架构由以下关键组件组成:
- 流媒体来源 – 您的流数据源包括点击流数据、传感器、社交媒体、物联网 (IoT) 设备、使用 Web 和移动应用程序生成的日志文件以及以连续流形式生成半结构化和非结构化数据的移动设备等数据源以高速。
- 流摄取 – 流摄取层负责将数据摄取到流存储层中。它提供了从数以万计的数据源收集数据并实时摄取的能力。您可以使用 运动SDK 为了通过 API 摄取流数据, Kinesis 生产者库 用于构建高性能且长期运行的流媒体生产者,或者 运动剂 用于收集一组文件并将其提取到 Kinesis Data Streams 中。此外,您可以使用许多预构建集成,例如 AWS 数据库迁移服务 (AWS DMS), Amazon DynamoDB及 AWS IoT核心 以无代码方式摄取数据。您还可以从第三方平台(例如 Apache Spark 和 Apache Kafka Connect)提取数据
- 流存储 – Kinesis Data Streams 提供两种模式来支持数据吞吐量:按需模式和预配置模式。按需模式现在是默认选择,可以弹性扩展以吸收可变吞吐量,因此客户无需担心容量管理并按数据吞吐量付费。按需模式会自动将流容量扩展到其历史最大数据摄取量的 2 倍,以便为意外的数据摄取高峰提供足够的容量。或者,想要对流资源进行精细控制的客户可以使用预配置模式并主动扩大和缩小分片数量以满足其吞吐量要求。此外,Kinesis Data Streams 默认情况下可以存储长达 24 小时的流数据,但根据使用案例可以延长至 7 天或 365 天。多个应用程序可以使用同一个流。
- 流处理 – 流处理层负责通过数据验证、清理、规范化、转换和丰富将数据转换为可使用状态。流记录按照生成的顺序读取,从而可以进行实时分析、构建事件驱动的应用程序或流 ETL(提取、转换和加载)。您可以使用 适用于 Apache Flink 的 Amazon 托管服务 对于复杂的流数据处理, AWS Lambda 用于无状态流数据处理,以及 AWS胶水 & 亚马逊电子病历 用于近实时计算。您还可以使用以下方式构建定制的消费者应用程序 Kinesis 消费者库, 它将处理与分布式计算相关的许多复杂任务。
- 目的地 - 目标层就像一个专门构建的目标,具体取决于您的用例。您可以将数据直接传输到 亚马逊Redshift 用于数据仓库和 Amazon EventBridge 用于构建事件驱动的应用程序。您还可以使用 亚马逊 Kinesis 数据流水线 对于流集成,您可以使用 AWS Lambda 进行流处理,然后将处理后的流传输到目的地,例如 Amazon S3 数据湖、用于运营分析的 OpenSearch Service、Redshift 数据仓库、No-SQL 数据库(例如 Amazon DynamoDB)以及关系数据库(例如 亚马逊RDS 将实时流消费到业务应用程序中。目的地可以是事件驱动的应用程序,用于实时仪表板、基于处理的流数据的自动决策、实时更改等。
时间序列实时分析架构
时间序列数据是在一定时间间隔内记录的一系列数据点,用于测量随时间变化的事件。例如,随时间变化的股票价格、网页点击流和随时间变化的设备日志。客户可以使用时间序列数据来监控随时间的变化,以便检测异常、识别模式并分析某些变量随时间的影响方式。时间序列数据通常是从多个来源大量生成的,并且需要以近乎实时的方式经济高效地收集。
通常,客户在处理时间序列数据时希望实现三个主要目标:
- 实时洞察系统性能并检测异常
- 了解最终用户行为以跟踪趋势并根据这些见解查询/构建可视化
- 拥有持久的存储解决方案来摄取和存储存档数据和经常访问的数据。
借助 Kinesis Data Streams,客户可以从数千个来源持续捕获 TB 级的时间序列数据,以进行清理、丰富、存储、分析和可视化。
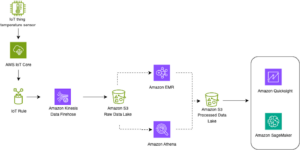
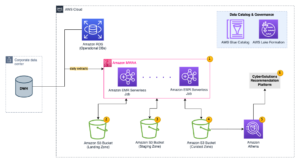
以下架构模式说明了如何使用 Kinesis Data Streams 对时间序列数据实现实时分析:
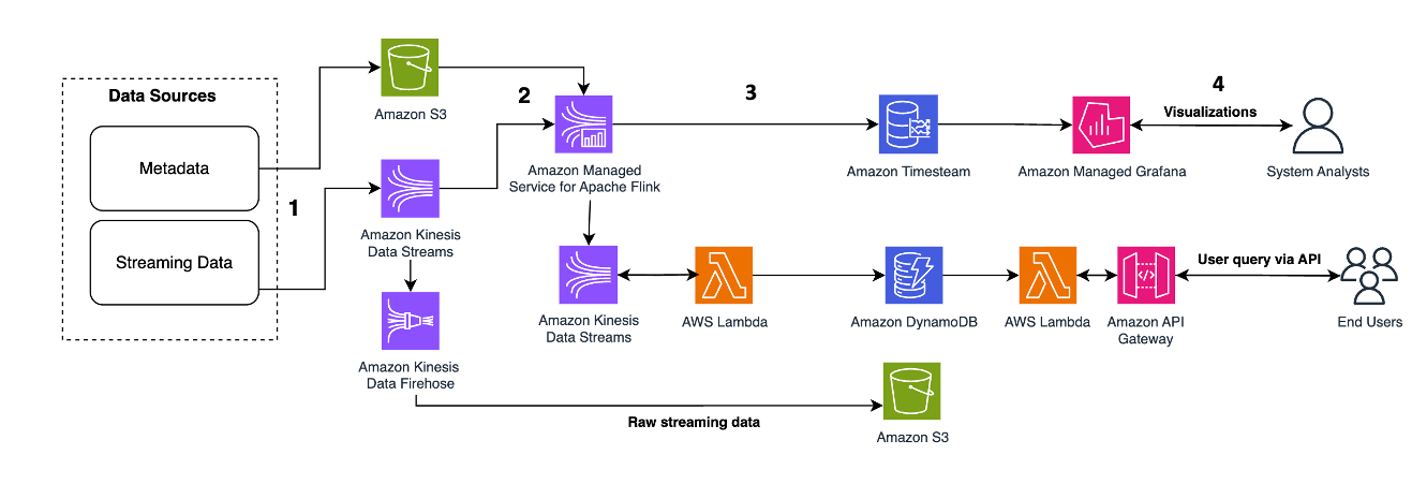
工作流程步骤如下:
- 数据摄取和存储 – Kinesis Data Streams 可以持续捕获和存储来自数千个来源的 TB 级数据。
- 流处理 – 使用创建的应用程序 适用于 Apache Flink 的 Amazon 托管服务 可以从数据流中读取记录,以检测和清除时间序列数据中的任何错误,并使用特定的元数据丰富数据以优化运营分析。在中间使用数据流提供了同时在其他流程和解决方案中使用时间序列数据的优势。然后使用这些事件调用 Lambda 函数,并可以在内存中执行时间序列计算。
- 目的地 – 经过清洗和浓缩后,处理后的时间序列数据可以流式传输到 亚马逊时间流 用于实时仪表板和分析的数据库,或存储在 DynamoDB 等数据库中用于最终用户查询。原始数据可以流式传输到 Amazon S3 进行存档。
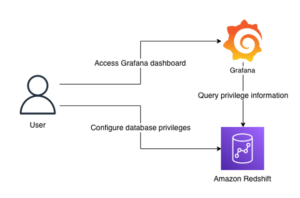
- 可视化并获得见解 – 客户可以使用以下方式查询、可视化和创建警报 Grafana 的 Amazon 托管服务。 Grafana 支持作为时间序列数据存储后端的数据源。要从 Timestream 访问数据,您需要安装 Grafana 的 Timestream 插件。最终用户可以使用以下命令从 DynamoDB 表中查询数据 Amazon API网关 充当代理。
请参阅 使用 Amazon Kinesis、Amazon Timestream 和 Grafana 进行近实时处理 展示无服务器流管道,用于处理设备遥测 IoT 数据并将其存储到时间序列优化的数据存储(例如 Amazon Timestream)中。
实时丰富和重放事件溯源微服务的数据
微服务是一种软件开发的架构和组织方法,其中软件由通过明确定义的 API 进行通信的小型独立服务组成。在构建事件驱动的微服务时,客户希望实现 1. 高可扩展性以处理大量传入事件;2. 事件处理的可靠性并在出现故障时维持系统功能。
客户利用微服务架构模式来加速新功能的创新和上市时间,因为它使应用程序更容易扩展并更快地开发。然而,在对另一个微服务的网络调用中丰富和重放数据具有挑战性,因为它会影响应用程序的可靠性,并使调试和跟踪错误变得困难。为了解决这个问题,事件溯源是一种有效的设计模式,它集中所有状态更改的历史记录以进行丰富和重放,并将读取与写入工作负载分离。客户可以使用 Kinesis Data Streams 作为事件溯源微服务的集中式事件存储,因为 KDS 每个流每秒可以处理千兆字节的数据吞吐量,并以毫秒为单位传输数据,以满足高可扩展性和近实时的要求延迟,1/ 与 Flink 和 S2 集成,实现数据丰富和实现,同时与微服务完全解耦,3/ 允许稍后重试和异步读取,因为 KDS 默认保留数据记录 3 小时,并且可选长达 24 天。
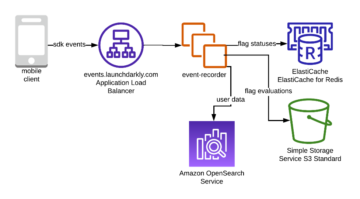
以下架构模式是 Kinesis Data Streams 如何用于事件溯源微服务的一般说明:
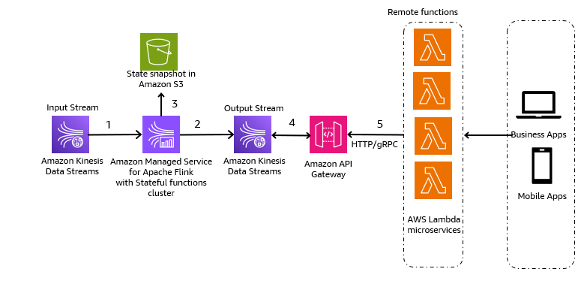
工作流程的步骤如下:
- 数据摄取和存储 – 您可以将微服务的输入聚合到 Kinesis Data Streams 进行存储。
- 流处理 – Apache Flink 有状态函数 简化了分布式有状态事件驱动应用程序的构建。它可以从输入 Kinesis 数据流接收事件,并将结果流路由到输出数据流。您可以根据应用程序业务逻辑使用 Apache Flink 创建有状态功能集群。
- Amazon S3 中的状态快照 – 您可以将状态快照存储在 Amazon S3 中以进行跟踪。
- 输出流 – 可以通过 API Gateway 通过 HTTP/gRPC 协议通过 Lambda 远程函数使用输出流。
- Lambda 远程函数 – Lambda 函数可以充当各种应用程序和业务逻辑的微服务,为业务应用程序和移动应用程序提供服务。
要了解其他客户如何使用 Kinesis Data Streams 构建基于事件的微服务,请参阅以下内容:
关键考虑因素和最佳实践
以下是需要牢记的注意事项和最佳实践:
- 数据发现应该是构建现代数据流应用程序的第一步。您必须定义业务价值,然后确定流数据源和用户角色,以实现所需的业务成果。
- 根据您的流数据源选择流数据摄取工具。例如,您可以使用 运动SDK 为了通过 API 摄取流数据, Kinesis 生产者库 为了构建高性能和长期运行的流媒体生产者, 运动剂 用于收集一组文件并将其提取到 Kinesis Data Streams 中, AWS数据管理系统 对于 CDC 流媒体用例,以及 AWS IoT核心 用于将 IoT 设备数据提取到 Kinesis Data Streams 中。您可以将流数据直接提取到 Amazon Redshift 中以构建低延迟流应用程序。您还可以使用 Apache Spark 和 Apache Kafka 等第三方库将流数据提取到 Kinesis Data Streams 中。
- 您需要根据您的具体用例和业务需求选择流数据处理服务。例如,您可以将 Amazon Kinesis Managed Service for Apache Flink 用于具有多个流目标和复杂的有状态流处理的高级流用例,或者如果您想要实时(例如每小时)监控业务指标。 Lambda 非常适合基于事件和无状态的处理。您可以使用 亚马逊电子病历 对于流数据处理,请使用您最喜欢的开源大数据框架。 AWS Glue 非常适合流式 ETL 等用例的近实时流式数据处理。
- Kinesis Data Streams 按需模式按使用情况收费,并自动扩展资源容量,因此非常适合尖峰流工作负载和免提维护。预配置模式按容量收费,并且需要主动的容量管理,因此它非常适合可预测的流工作负载。
- 您可以使用 Kinesis 共享计算器 计算配置模式所需的分片数量。您无需担心按需模式下的分片。
- 授予权限时,您可以决定谁获得对哪些 Kinesis Data Streams 资源的哪些权限。您可以启用您希望对这些资源允许的特定操作。因此,您应该仅授予执行任务所需的权限。您还可以使用 KMS 客户管理密钥 (CMK) 加密静态数据。
- 您还可以 更新保留期限 通过 Kinesis Data Streams 控制台或使用 增加流保留期 和 减少流保留期 根据您的具体用例进行操作。
- Kinesis Data Streams 支持 重新分片。此功能推荐的 API 是 更新分片数,它允许您修改流中的分片数量,以适应流中数据流速率的变化。重新分片 API(拆分和合并)通常用于处理热分片。
结论
本文演示了使用 Kinesis Data Streams 构建低延迟流应用程序的各种架构模式。您可以使用本文中的信息通过 Kinesis Data Streams 构建自己的低延迟流应用程序。
有关详细的架构模式,请参考以下资源:
如果您想构建数据愿景和策略,请查看 AWS 数据驱动一切 (D2E)计划。
作者简介
 拉加瓦劳·索达巴蒂娜 是 AWS 的首席解决方案架构师,专注于数据分析、AI/ML 和云安全。他与客户合作创建创新解决方案,解决客户业务问题并加速 AWS 服务的采用。在业余时间,拉加瓦劳喜欢与家人共度时光、读书和看电影。
拉加瓦劳·索达巴蒂娜 是 AWS 的首席解决方案架构师,专注于数据分析、AI/ML 和云安全。他与客户合作创建创新解决方案,解决客户业务问题并加速 AWS 服务的采用。在业余时间,拉加瓦劳喜欢与家人共度时光、读书和看电影。
 航佐 是 Amazon Web Services 的 Amazon Kinesis Data Streams 团队的高级产品经理。 他热衷于开发直观的产品体验,以解决复杂的客户问题并帮助客户实现其业务目标。
航佐 是 Amazon Web Services 的 Amazon Kinesis Data Streams 团队的高级产品经理。 他热衷于开发直观的产品体验,以解决复杂的客户问题并帮助客户实现其业务目标。
 瑞塔·拉达克里希南 是 AWS 的解决方案架构师,专注于数据分析。她一直在构建推动云采用并帮助公共部门组织做出数据驱动决策的解决方案。工作之余,她喜欢跳舞、与朋友和家人共度时光以及旅行。
瑞塔·拉达克里希南 是 AWS 的解决方案架构师,专注于数据分析。她一直在构建推动云采用并帮助公共部门组织做出数据驱动决策的解决方案。工作之余,她喜欢跳舞、与朋友和家人共度时光以及旅行。
 布列塔尼·李 是 AWS 的解决方案架构师。她专注于帮助企业客户完成云采用和现代化之旅,并对安全和分析领域感兴趣。工作之余,她喜欢与她的狗共度时光并玩泡菜球。
布列塔尼·李 是 AWS 的解决方案架构师。她专注于帮助企业客户完成云采用和现代化之旅,并对安全和分析领域感兴趣。工作之余,她喜欢与她的狗共度时光并玩泡菜球。
- :具有
- :是
- :不是
- :在哪里
- $UP
- 1
- 100
- 24
- 7
- a
- 对,能力--
- 关于
- 加快
- ACCESS
- 访问
- 实现
- 实现
- 实现
- 横过
- 法案
- 演戏
- 行动
- 适应
- 增加
- 额外
- 另外
- 地址
- 采用
- 高级
- 优点
- 后
- 年龄
- 经纪人
- 骨料
- AI / ML
- 目标
- 警报
- 所有类型
- 让
- 允许
- 允许
- 还
- Amazon
- 亚马逊Kinesis
- 亚马逊时间流
- 亚马逊网络服务
- an
- 分析
- 分析
- 分析
- 和
- 异常检测
- 另一个
- 任何
- 阿帕奇
- 阿帕奇卡夫卡
- Apache Spark
- API
- APIs
- 应用领域
- 应用领域
- 的途径
- 应用
- 建筑的
- 架构
- 保健
- AS
- 相关
- At
- 自动表
- 自动
- 可用性
- 可使用
- AWS
- AWS胶水
- AWS Lambda
- 基于
- BE
- 因为
- 很
- 行为
- 作为
- 最佳
- 最佳实践
- 更好
- 之间
- 大
- 大数据运用
- 博客
- 书籍
- 都
- 建立
- 建筑物
- 建
- 商业
- 商业应用
- 企业
- 但是
- by
- 计算
- 呼叫
- CAN
- 容量
- 捕获
- 关心
- 案件
- 例
- 疾病预防控制中心
- Center
- 集中
- 一定
- 挑战
- 更改
- 更改
- 收费
- 查
- 选择
- 清洁
- 清洁
- 云端技术
- 云采用
- 云安全
- 簇
- 收集
- 收藏
- 相当常见
- 通信
- 完全
- 复杂
- 组件
- 由
- 计算
- 计算
- 关心
- 配置
- 注意事项
- 由
- 安慰
- 经常
- 消耗
- 消费
- 消费者
- 消费者
- CONTACT
- 联络中心
- 连续
- 一直
- 控制
- 创建信息图
- 创建
- 危急
- 顾客
- 合作伙伴
- 定制
- 跳舞
- 仪表板
- data
- 数据分析
- 数据分析
- 数据充实
- 数据湖
- 数据管理
- 数据点
- 数据处理
- 数据仓库
- 数据驱动
- 数据库
- 数据库
- 一年中的
- 决定
- 决定
- 决策
- 决定
- 解耦
- 专用
- 默认
- 定义
- 交付
- 证明
- 根据
- 设计
- 设计
- 期望
- 目的地
- 旅游目的地
- 详细
- 详情
- 检测
- 检测
- 开发
- 发展
- 研发支持
- 设备
- 设备
- 不同
- 难
- 直接
- 发现
- 分布
- 分布式计算
- do
- 狗
- 别
- 向下
- 驾驶
- 驱动
- 耐久力
- 动态
- 每
- 更容易
- 容易
- 易
- 有效
- 拥抱
- enable
- 加密
- 端点
- 订婚
- 增强
- 丰富
- 企业
- 企业客户
- 故障
- 醚(ETH)
- 活动
- 事件
- 所有的
- 每个人
- 例子
- 例子
- 预计
- 体验
- 体验
- 探索
- 延长
- 提取
- 面部彩妆
- 失败
- 家庭
- 时尚
- 快
- 喜爱
- 专栏
- 特征
- 部分
- 档
- 姓氏:
- 五
- 流
- 专注焦点
- 重点
- 聚焦
- 以下
- 如下
- 针对
- 骨架
- 框架
- 频繁
- 朋友
- 止
- 功能
- 功能
- 功能
- 进一步
- Gain增益
- 网关
- 生成
- 产生
- 越来越
- GitHub上
- 给
- 理想中
- 非常好
- 授予
- 发放
- 处理
- 挂
- he
- 帮助
- 帮助
- 这里
- 高
- 高性能
- 他的
- 历史性
- 热卖
- 小时
- HOURS
- 创新中心
- 但是
- HTML
- HTTP
- HTTPS
- 数百
- 鉴定
- if
- 说明
- 影响力故事
- in
- 其他
- 包括
- 来电
- 增加
- 增加
- 独立
- 影响
- 信息
- 基础设施
- 基础设施
- 创新
- 創新
- 创新
- 输入
- 可行的洞见
- 安装
- 整合
- 集成
- 积分
- 集成
- 兴趣
- 接口
- 网络
- 物联网
- 成
- 介绍
- 直观的
- 调用
- 物联网
- 物联网设备
- IT
- 它的
- 旅程
- JPG
- 卡夫卡
- 保持
- 键
- Kinesis 数据流
- 湖泊
- 潜伏
- 后来
- 层
- 层
- 学习用品
- 莱杰
- 库
- 自学资料库
- 光
- 喜欢
- 活的
- 加载
- 日志
- 逻辑
- 合乎逻辑的
- 爱
- 保持
- 保养
- 使
- 制作
- 制作
- 管理
- 颠覆性技术
- 经理
- 许多
- 营销
- 最多
- 测量
- 媒体
- 满足
- 内存
- 合并
- 元数据
- 指标
- 微服务
- 中间
- 移民
- 毫秒
- 介意
- 联络号码
- 移动应用程序
- 移动设备
- 移动应用
- 时尚
- 现代
- 现代化
- 模式
- 修改
- 显示器
- 更多
- 电影
- 多
- 必须
- 本地人
- 近
- 需求
- 打印车票
- 需要
- 网络
- 全新
- 新功能
- 现在
- 数
- of
- 提供
- 优惠精选
- on
- 点播
- 仅由
- 打开
- 开放源码
- 操作
- 操作
- 运营
- 优化
- 优化
- 附加选项
- or
- 秩序
- 组织
- 组织
- 其他名称
- 我们的
- 输出
- 结果
- 产量
- 学校以外
- 超过
- 己
- 部分
- 多情
- 模式
- 模式
- 为
- 演出
- 性能
- 权限
- 个性化你的
- 管
- 管道
- 平台
- 柏拉图
- 柏拉图数据智能
- 柏拉图数据
- 播放
- 插入
- 点
- 帖子
- 做法
- 可预见
- 价格
- 价格
- 小学
- 校长
- 先
- 私立
- 主动
- 市场问题
- 问题
- 过程
- 处理
- 过程
- 处理
- 生成
- 制片人
- 生产者
- 产品
- 产品经理
- 曲目
- 协议
- 提供
- 提供
- 代理
- 国家
- 范围
- 急速
- 率
- 原
- 原始数据
- 阅读
- 阅读
- 真实
- 实时的
- 实时数据
- 接收
- 接收
- 推荐
- 建议
- 记录
- 记录
- 记录
- 减少
- 参考
- 地区
- 可靠性
- 可靠
- 远程
- 必须
- 需求
- 岗位要求
- 需要
- 资源
- 资源
- 提供品牌战略规划
- REST的
- 导致
- 保留
- 保留
- 保留
- 检讨
- 路线
- 同
- 可扩展性
- 可扩展性
- 鳞片
- 秤
- 其次
- 扇形
- 保安
- 前辈
- 传感器
- 序列
- 系列
- 服务
- 无服务器
- 服务
- 特色服务
- 集
- 共用的,
- 她
- 应该
- 陈列宣传
- 简化
- 小
- 快照
- So
- 社会
- 社会化媒体
- 软件
- 软件开发
- 方案,
- 解决方案
- 解决
- 来源
- 来源
- 火花
- 具体的
- 速度
- 花
- 花费
- 钉鞋
- 分裂
- 堆
- 州/领地
- 步
- 步骤
- 库存
- 存储
- 商店
- 存储
- 策略
- 流
- 流
- 流
- 流
- 严格
- 随后
- 这样
- 足够
- SUPPORT
- 支持
- 系统
- 表
- 采取
- 任务
- 任务
- 团队
- HAST
- 这
- 信息
- 国家
- 其
- 他们
- 然后
- 那里。
- 因此
- 博曼
- 他们
- 事
- 第三方
- Free Introduction
- 那些
- 数千
- 三
- 通过
- 吞吐量
- 次
- 时间序列
- 时间敏感
- 至
- 今晚
- 工具
- 追踪
- 跟踪时
- 跟踪
- 交通
- 改造
- 转型
- 转型
- 旅游
- 趋势
- 二
- 一般
- 意外
- 上
- 用法
- 使用
- 用例
- 用过的
- 用户
- 运用
- 利用
- 验证
- 折扣值
- 变量
- 各个
- 速度
- 通过
- 在线会议
- 愿景
- 可视化
- 想像
- 体积
- 卷
- 想
- 仓库保管
- 仓储服务
- 观看
- we
- 卷筒纸
- Web服务
- 定义明确
- 什么是
- ,尤其是
- 这
- 而
- WHO
- 宽
- 大范围
- 将
- 中
- 工作
- 工作流程
- 担心
- 写
- 您
- 您一站式解决方案
- 和风网
- 区