تصویر کی طرف سے jcomp on Freepik
ٹائم سیریز ڈیٹا سائنس فیلڈ میں ایک منفرد ڈیٹا سیٹ ہے۔ ڈیٹا کو وقت کی تعدد (مثال کے طور پر، روزانہ، ہفتہ وار، ماہانہ، وغیرہ) پر ریکارڈ کیا جاتا ہے، اور ہر مشاہدے کا تعلق دوسرے سے ہوتا ہے۔ ٹائم سیریز کا ڈیٹا اس وقت قیمتی ہوتا ہے جب آپ تجزیہ کرنا چاہتے ہیں کہ وقت کے ساتھ ساتھ آپ کے ڈیٹا کا کیا ہوتا ہے اور مستقبل کی پیشین گوئیاں بنانا چاہتے ہیں۔
ٹائم سیریز کی پیشن گوئی تاریخی ٹائم سیریز ڈیٹا کی بنیاد پر مستقبل کی پیشین گوئیاں بنانے کا ایک طریقہ ہے۔ ٹائم سیریز کی پیشن گوئی کے بہت سے شماریاتی طریقے ہیں، جیسے اریما۔ or کفایتی ہموار کرنا.
ٹائم سیریز کی پیشن گوئی کا اکثر کاروبار میں سامنا ہوتا ہے، لہذا ڈیٹا سائنسدان کے لیے یہ جاننا فائدہ مند ہے کہ ٹائم سیریز کا ماڈل کیسے تیار کیا جائے۔ اس آرٹیکل میں، ہم سیکھیں گے کہ دو مشہور پیشن گوئی Python پیکجز کا استعمال کرتے ہوئے ٹائم سیریز کی پیشن گوئی کیسے کی جاتی ہے۔ statsmodels اور نبی. آئیے اس میں داخل ہوں۔
۔ اعدادوشمار کے ماڈلز Python پیکیج ایک اوپن سورس پیکیج ہے جو مختلف شماریاتی ماڈل پیش کرتا ہے، بشمول ٹائم سیریز کی پیشن گوئی کا ماڈل۔ آئیے ڈیٹا سیٹ کی مثال کے ساتھ پیکیج کو آزماتے ہیں۔ یہ مضمون استعمال کرے گا ڈیجیٹل کرنسی ٹائم سیریز Kaggle سے ڈیٹا (CC0: پبلک ڈومین)۔
آئیے ڈیٹا کو صاف کریں اور ہمارے پاس موجود ڈیٹا سیٹ پر ایک نظر ڈالیں۔
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
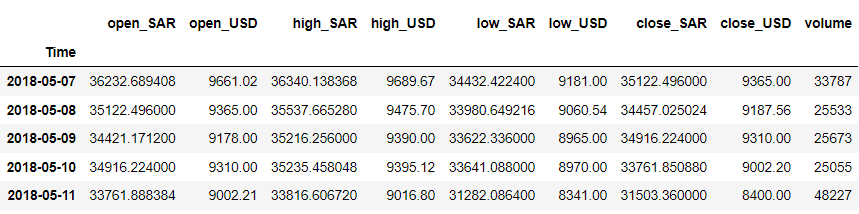
ہماری مثال کے لیے، ہم کہتے ہیں کہ ہم 'close_USD' متغیر کی پیش گوئی کرنا چاہتے ہیں۔ آئیے دیکھتے ہیں کہ وقت کے ساتھ ڈیٹا کا پیٹرن کیسے ہوتا ہے۔
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
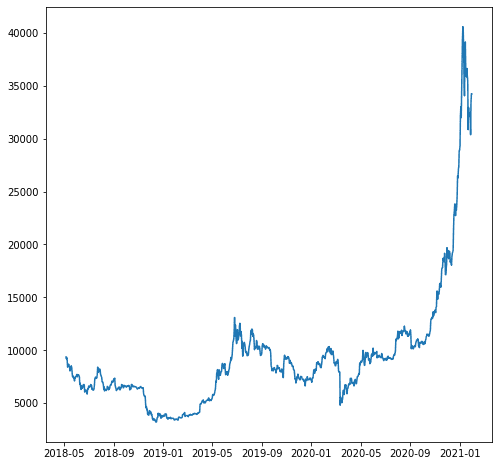
آئیے اپنے اوپر والے ڈیٹا کی بنیاد پر پیشن گوئی کا ماڈل بنائیں۔ ماڈلنگ سے پہلے، آئیے ڈیٹا کو ٹرین اور ٹیسٹ ڈیٹا میں تقسیم کرتے ہیں۔
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
ہم ڈیٹا کو تصادفی طور پر تقسیم نہیں کرتے ہیں کیونکہ یہ ٹائم سیریز کا ڈیٹا ہے، اور ہمیں آرڈر کو محفوظ رکھنے کی ضرورت ہے۔ اس کے بجائے، ہم پہلے سے ٹرین کا ڈیٹا اور تازہ ترین ڈیٹا سے ٹیسٹ ڈیٹا رکھنے کی کوشش کرتے ہیں۔
آئیے ایک پیشن گوئی ماڈل بنانے کے لیے statsmodels کا استعمال کریں۔ دی statsmodel کئی ٹائم سیریز ماڈل APIs فراہم کرتا ہے، لیکن ہم ARIMA ماڈل کو اپنی مثال کے طور پر استعمال کریں گے۔
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
ہماری اوپر کی مثال میں، ہم statsmodels سے ARIMA ماڈل کو پیشن گوئی کے ماڈل کے طور پر استعمال کرتے ہیں اور اگلے 200 دنوں کی پیشین گوئی کرنے کی کوشش کرتے ہیں۔
کیا ماڈل کا نتیجہ اچھا ہے؟ آئیے ان کا جائزہ لینے کی کوشش کرتے ہیں۔ ٹائم سیریز ماڈل کی تشخیص عام طور پر ریگریشن میٹرکس کے ساتھ اصل اور پیشین گوئی کا موازنہ کرنے کے لیے ایک تصوراتی گراف کا استعمال کرتی ہے جیسے کہ Mean Absolute Error (MAE)، Root Mean Square Error (RMSE)، اور MAPE (Mean Absolute Percentage Error)۔
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
اوپر کا سکور ٹھیک لگتا ہے، لیکن آئیے دیکھتے ہیں کہ جب ہم ان کا تصور کرتے ہیں تو یہ کیسا ہوتا ہے۔
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
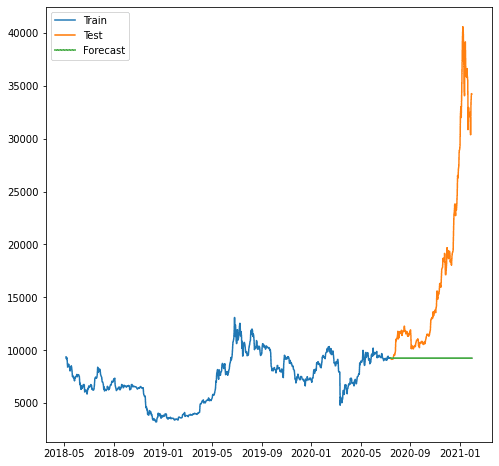
جیسا کہ ہم دیکھ سکتے ہیں، پیشن گوئی بدتر تھی کیونکہ ہمارا ماڈل بڑھتے ہوئے رجحان کی پیش گوئی نہیں کر سکتا۔ ARIMA جو ماڈل ہم استعمال کرتے ہیں وہ پیشین گوئی کے لیے بہت آسان لگتا ہے۔
ہوسکتا ہے کہ یہ بہتر ہو اگر ہم statsmodels کے باہر کوئی دوسرا ماڈل استعمال کرنے کی کوشش کریں۔ آئیے فیس بک سے مشہور نبی پیکج آزماتے ہیں۔
نبی ایک ٹائم سیریز کی پیشن گوئی کرنے والا ماڈل پیکیج ہے جو موسمی اثرات کے ساتھ ڈیٹا پر بہترین کام کرتا ہے۔ پیغمبر کو ایک مضبوط پیشن گوئی ماڈل بھی سمجھا جاتا تھا کیونکہ یہ گمشدہ ڈیٹا اور آؤٹ لیرز کو سنبھال سکتا تھا۔
آئیے نبی پیکج کو آزماتے ہیں۔ سب سے پہلے، ہمیں پیکج کو انسٹال کرنے کی ضرورت ہے.
pip install prophet
اس کے بعد، ہمیں پیشن گوئی کے ماڈل کی تربیت کے لیے اپنا ڈیٹا سیٹ تیار کرنا چاہیے۔ پیغمبر کی ایک خاص ضرورت ہے: وقت کے کالم کو 'ds' اور قدر کو 'y' کے طور پر نامزد کرنے کی ضرورت ہے۔
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
ہمارے ڈیٹا کے تیار ہونے کے ساتھ، آئیے ڈیٹا کی بنیاد پر پیشین گوئی بنانے کی کوشش کرتے ہیں۔
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
نبی صلی اللہ علیہ وسلم کے بارے میں سب سے اچھی بات یہ تھی کہ ہر پیشین گوئی ڈیٹا پوائنٹ ہمارے صارفین کے سمجھنے کے لیے مفصل تھا۔ تاہم، صرف اعداد و شمار سے نتیجہ سمجھنا مشکل ہے۔ لہذا، ہم پیغمبر کا استعمال کرتے ہوئے ان کا تصور کرنے کی کوشش کر سکتے ہیں۔
model.plot(predictions)
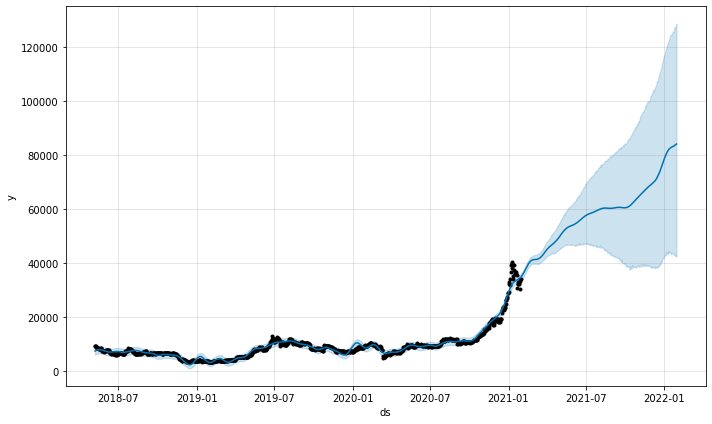
ماڈل سے پیشین گوئیوں کا پلاٹ فنکشن ہمیں فراہم کرے گا کہ پیشین گوئیاں کتنے پر اعتماد تھیں۔ مندرجہ بالا پلاٹ سے، ہم دیکھ سکتے ہیں کہ پیشین گوئی میں اوپر کا رجحان ہے لیکن بڑھتی ہوئی غیر یقینی صورتحال کے ساتھ پیشین گوئیاں اتنی ہی لمبی ہوتی ہیں۔
مندرجہ ذیل فنکشن کے ساتھ پیشن گوئی کے اجزاء کی جانچ کرنا بھی ممکن ہے۔
model.plot_components(predictions)
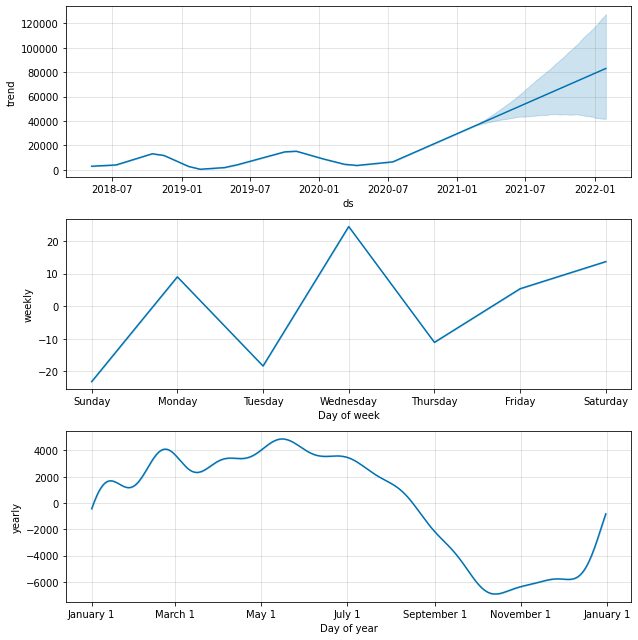
پہلے سے طے شدہ طور پر، ہم سالانہ اور ہفتہ وار موسم کے ساتھ ڈیٹا کا رجحان حاصل کریں گے۔ ہمارے ڈیٹا کے ساتھ کیا ہوتا ہے اس کی وضاحت کرنے کا یہ ایک اچھا طریقہ ہے۔
کیا نبی صلی اللہ علیہ وسلم کے نمونے کو بھی جانچنا ممکن ہے؟ بالکل۔ نبی میں ایک تشخیصی پیمائش شامل ہے جسے ہم استعمال کر سکتے ہیں: ٹائم سیریز کراس توثیق. یہ طریقہ تاریخی ڈیٹا کا حصہ استعمال کرتا ہے اور کٹ آف پوائنٹ تک ڈیٹا کا استعمال کرتے ہوئے ہر بار ماڈل کو فٹ کرتا ہے۔ اس کے بعد نبی صلی اللہ علیہ وسلم پیشین گوئیوں کا اصل سے موازنہ کریں گے۔ آئیے کوڈ استعمال کرنے کی کوشش کریں۔
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
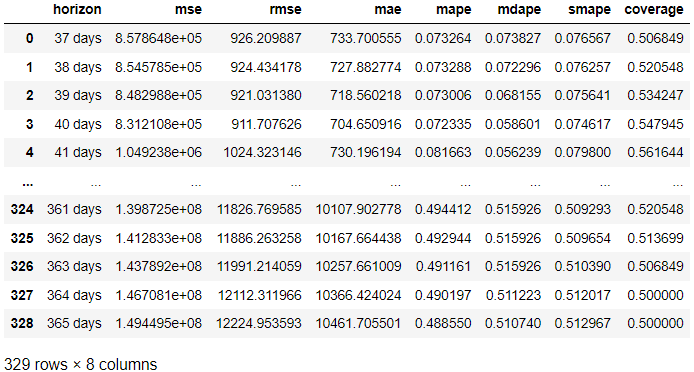
اوپر کے نتیجے میں، ہم نے ہر پیشین گوئی کے دن کی پیشن گوئی کے مقابلے میں اصل نتیجہ سے تشخیص کا نتیجہ حاصل کیا۔ مندرجہ ذیل کوڈ کے ساتھ نتیجہ کا تصور کرنا بھی ممکن ہے۔
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
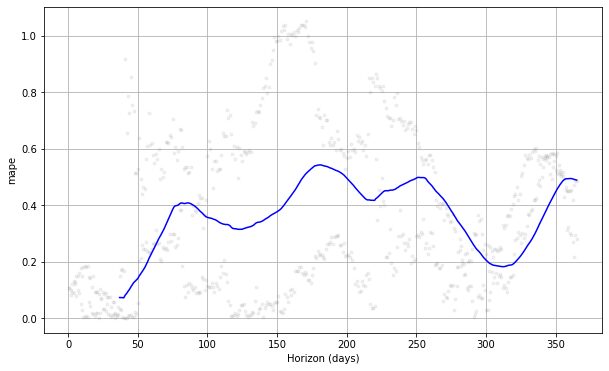
اگر ہم اوپر والے پلاٹ کو دیکھتے ہیں، تو ہم دیکھ سکتے ہیں کہ پیشین گوئی کی غلطی آنے والے دنوں میں مختلف تھی، اور یہ کچھ پوائنٹس پر 50% غلطی حاصل کر سکتی ہے۔ اس طرح، ہم غلطی کو ٹھیک کرنے کے لیے ماڈل کو مزید موافقت کرنا چاہتے ہیں۔ آپ چیک کر سکتے ہیں۔ دستاویزات مزید تحقیق کے لیے۔
پیشن گوئی کاروبار میں پائے جانے والے عام معاملات میں سے ایک ہے۔ پیشن گوئی کا ماڈل تیار کرنے کا ایک آسان طریقہ statsforecast اور Prophet Python پیکجز کا استعمال ہے۔ اس مضمون میں، ہم سیکھتے ہیں کہ پیشن گوئی کا ماڈل کیسے بنایا جائے اور اعدادوشمار کی پیشن گوئی اور نبی کے ساتھ ان کا اندازہ لگایا جائے۔
کارنیلیس یودھا وجایا ڈیٹا سائنس اسسٹنٹ مینیجر اور ڈیٹا رائٹر ہے۔ Allianz Indonesia میں کل وقتی کام کرتے ہوئے، وہ سوشل میڈیا اور تحریری میڈیا کے ذریعے Python اور Data ٹپس کا اشتراک کرنا پسند کرتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- : ہے
- $UP
- 1
- 11
- 7
- 8
- 9
- a
- ہمارے بارے میں
- اوپر
- مطلق
- بالکل
- حاصل
- حاصل
- آلانز
- تجزیے
- اور
- ایک اور
- APIs
- کیا
- مضمون
- AS
- اسسٹنٹ
- At
- کی بنیاد پر
- BE
- کیونکہ
- اس سے پہلے
- فائدہ مند
- BEST
- بہتر
- کے درمیان
- تعمیر
- کاروبار
- by
- حساب
- کر سکتے ہیں
- مقدمات
- CC0
- چیک کریں
- کوڈ
- کالم
- کالم
- کامن
- موازنہ
- مقابلے میں
- اجزاء
- اعتماد
- سمجھا
- سکتا ہے
- کوریج
- تخلیق
- کرنسی
- روزانہ
- اعداد و شمار
- ڈیٹا سائنس
- ڈیٹا سائنسدان
- تاریخ
- دن
- دن
- dc
- پہلے سے طے شدہ
- تفصیلی
- ترقی
- ڈومین
- نہیں
- e
- ہر ایک
- اس سے قبل
- اثرات
- خرابی
- وغیرہ
- اندازہ
- تشخیص
- ہر کوئی
- مثال کے طور پر
- وضاحت
- کی تلاش
- فیس بک
- مشہور
- میدان
- آخر
- پہلا
- فٹ
- درست کریں
- کے بعد
- کے لئے
- پیشن گوئی
- سے
- تقریب
- مزید
- مستقبل
- حاصل
- GitHub کے
- اچھا
- گراف
- عظیم
- ہینڈل
- ہوتا ہے
- ہارڈ
- ہے
- تاریخی
- افق
- کس طرح
- کیسے
- تاہم
- HTML
- HTTPS
- درآمد
- in
- شامل ہیں
- سمیت
- اضافہ
- اضافہ
- انڈکس
- انڈونیشیا
- ابتدائی
- انسٹال
- کے بجائے
- IT
- فوٹو
- KDnuggets
- جان
- تازہ ترین
- جانیں
- لنکڈ
- اب
- دیکھو
- دیکھنا
- بنا
- مینیجر
- بہت سے
- matplotlib
- میڈیا
- طریقہ
- طریقوں
- پیمائش کا معیار
- شاید
- لاپتہ
- ماڈل
- ماڈلنگ
- ماڈل
- ماہانہ
- نامزد
- ضرورت ہے
- ضروریات
- اگلے
- عجیب
- حاصل
- of
- کی پیشکش
- on
- ایک
- اوپن سورس
- حکم
- دیگر
- باہر
- پیکج
- پیکجوں کے
- pandas
- پیرامیٹرز
- حصہ
- پاٹرن
- فیصد
- انجام دینے کے
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پوائنٹ
- پوائنٹس
- مقبول
- ممکن
- پیشن گوئی
- کی پیشن گوئی
- پیشن گوئی
- تیار
- فراہم
- فراہم کرتا ہے
- عوامی
- ازگر
- تیار
- درج
- رجعت
- متعلقہ
- ضرورت
- نتیجہ
- نتائج کی نمائش
- مضبوط
- جڑ
- سائنس
- سائنسدان
- لگتا ہے
- سیریز
- مقرر
- سیکنڈ اور
- سادہ
- So
- سماجی
- سوشل میڈیا
- کچھ
- مخصوص
- تقسیم
- چوک میں
- شماریات
- اس طرح
- لے لو
- ٹیسٹ
- کہ
- ۔
- ان
- وقت
- وقت کا سلسلہ
- تجاویز
- کرنے کے لئے
- بھی
- ٹرین
- ٹریننگ
- رجحان
- غیر یقینی صورتحال
- سمجھ
- منفرد
- UNNAMED
- اضافہ
- us
- استعمال کی شرائط
- صارفین
- عام طور پر
- قیمتی
- قیمت
- مختلف
- کی طرف سے
- تصور
- راستہ..
- ہفتہ وار
- اچھا ہے
- کیا
- جبکہ
- وکیپیڈیا
- گے
- ساتھ
- کے اندر
- کام کر
- کام کرتا ہے
- گا
- مصنف
- تحریری طور پر
- اور
- زیفیرنیٹ