مصنف کی طرف سے تصویر
اس پوسٹ میں، ہم Mixtral 8x7b نامی نئے جدید ترین اوپن سورس ماڈل کو دریافت کریں گے۔ ہم یہ بھی سیکھیں گے کہ LLaMA C++ لائبریری کا استعمال کرتے ہوئے اس تک کیسے رسائی حاصل کی جائے اور کم کمپیوٹنگ اور میموری پر بڑے لینگویج ماڈل کیسے چلائے جائیں۔
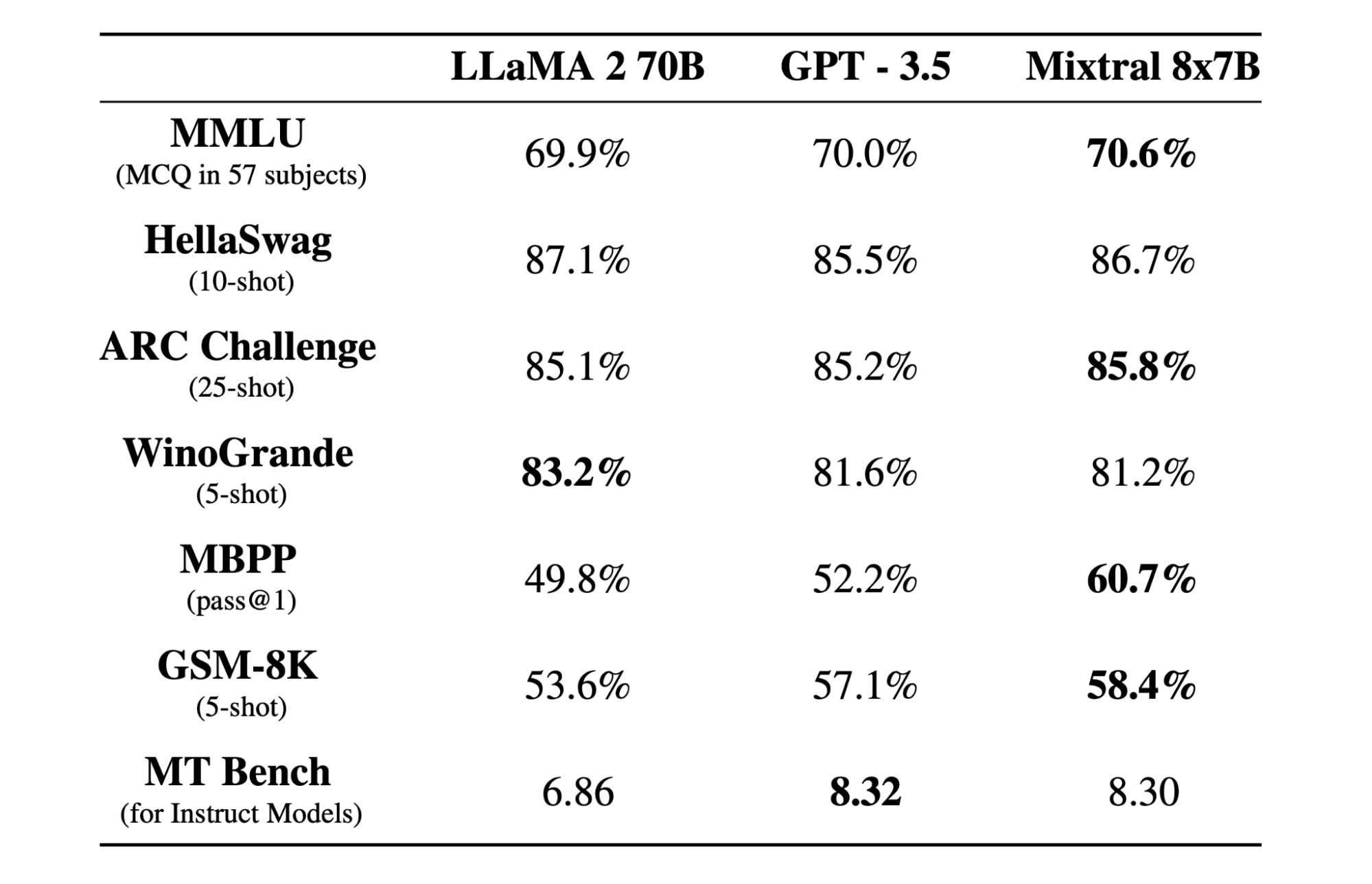
Mixtral 8x7b Mistral AI کی طرف سے تخلیق کردہ کھلے وزن کے ساتھ ماہرین (SMoE) ماڈل کا ایک اعلیٰ معیار کا ویرل مرکب ہے۔ یہ Apache 2.0 کے تحت لائسنس یافتہ ہے اور Llama 2 70B کو زیادہ تر بینچ مارکس پر بہتر کارکردگی کا مظاہرہ کرتا ہے جبکہ 6x تیز تر اندازہ لگاتا ہے۔ Mixtral میچ کرتا ہے یا زیادہ تر معیاری بینچ مارکس پر GPT3.5 کو شکست دیتا ہے اور لاگت/کارکردگی کے حوالے سے بہترین اوپن ویٹ ماڈل ہے۔
سے تصویر ماہرین کا مرکب
Mixtral 8x7B ماہرین کے نیٹ ورک کا استعمال کرتا ہے۔ اس میں پیرامیٹرز کے 8 گروپوں میں سے فیڈ فارورڈ بلاک کا انتخاب شامل ہے، جس میں روٹر نیٹ ورک ہر ٹوکن کے لیے ان میں سے دو گروپوں کا انتخاب کرتا ہے، اور ان کے آؤٹ پٹس کو اضافی طور پر جوڑتا ہے۔ یہ طریقہ لاگت اور تاخیر کا انتظام کرتے ہوئے ماڈل کے پیرامیٹر کی تعداد کو بڑھاتا ہے، 12.9B کل پیرامیٹرز ہونے کے باوجود اسے 46.7B ماڈل کی طرح موثر بناتا ہے۔
Mixtral 8x7B ماڈل 32k ٹوکنز کے وسیع سیاق و سباق کو سنبھالنے میں بہترین ہے اور انگریزی، فرانسیسی، اطالوی، جرمن اور ہسپانوی سمیت متعدد زبانوں کو سپورٹ کرتا ہے۔ یہ کوڈ جنریشن میں مضبوط کارکردگی کا مظاہرہ کرتا ہے اور MT-Bench جیسے بینچ مارکس پر اعلیٰ سکور حاصل کرتے ہوئے، ہدایات کے بعد ماڈل میں ٹھیک بنایا جا سکتا ہے۔
LLaMA.cpp ایک C/C++ لائبریری ہے جو Facebook کے LLM فن تعمیر پر مبنی بڑے لینگویج ماڈلز (LLMs) کے لیے ایک اعلیٰ کارکردگی کا انٹرفیس فراہم کرتی ہے۔ یہ ایک ہلکی پھلکی اور موثر لائبریری ہے جسے متن کی تخلیق، ترجمہ اور سوالوں کے جوابات سمیت متعدد کاموں کے لیے استعمال کیا جا سکتا ہے۔ LLaMA.cpp LLMs کی وسیع رینج کو سپورٹ کرتا ہے، بشمول LLaMA، LLaMA 2، Falcon، Alpaca، Mistral 7B، Mixtral 8x7B، اور GPT4ALL۔ یہ تمام آپریٹنگ سسٹمز کے ساتھ مطابقت رکھتا ہے اور CPUs اور GPUs دونوں پر کام کر سکتا ہے۔
اس سیکشن میں، ہم Colab پر llama.cpp ویب ایپلیکیشن چلائیں گے۔ کوڈ کی چند سطریں لکھ کر، آپ اپنے PC یا Google Colab پر نئے جدید ترین ماڈل کی کارکردگی کا تجربہ کر سکیں گے۔
شروع
سب سے پہلے، ہم نیچے کمانڈ لائن کا استعمال کرتے ہوئے llama.cpp GitHub ذخیرہ ڈاؤن لوڈ کریں گے:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitاس کے بعد، ہم ڈائریکٹری کو ریپوزٹری میں تبدیل کریں گے اور 'make' کمانڈ کا استعمال کرتے ہوئے llama.cpp انسٹال کریں گے۔ ہم NVidia GPU کے لیے llama.cpp انسٹال کر رہے ہیں جس میں CUDA انسٹال ہے۔
%cd llama.cpp
!make LLAMA_CUBLAS=1ماڈل ڈاؤن لوڈ کریں۔
ہم `.gguf` ماڈل فائل کے مناسب ورژن کو منتخب کر کے Hugging Face Hub سے ماڈل ڈاؤن لوڈ کر سکتے ہیں۔ مختلف ورژن کے بارے میں مزید معلومات اس میں مل سکتی ہیں۔ TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
سے تصویر TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
آپ موجودہ ڈائرکٹری میں ماڈل کو ڈاؤن لوڈ کرنے کے لیے 'wget' کمانڈ استعمال کر سکتے ہیں۔
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufایل ایل اے ایم اے سرور کے لیے بیرونی پتہ
جب ہم LLaMA سرور چلاتے ہیں تو یہ ہمیں لوکل ہوسٹ IP دے گا جو Colab پر ہمارے لیے بیکار ہے۔ ہمیں Colab کرنل پراکسی پورٹ استعمال کر کے لوکل ہوسٹ پراکسی سے کنکشن کی ضرورت ہے۔
نیچے دیئے گئے کوڈ کو چلانے کے بعد، آپ کو عالمی ہائپر لنک مل جائے گا۔ ہم بعد میں اپنی ویب ایپ تک رسائی کے لیے اس لنک کا استعمال کریں گے۔
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/سرور چل رہا ہے۔
LLaMA C++ سرور چلانے کے لیے، آپ کو سرور کمانڈ کو ماڈل فائل کی لوکیشن اور صحیح پورٹ نمبر فراہم کرنے کی ضرورت ہے۔ یہ یقینی بنانا ضروری ہے کہ پورٹ نمبر اس سے میل کھاتا ہے جو ہم نے پراکسی پورٹ کے لیے پچھلے مرحلے میں شروع کیا تھا۔
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
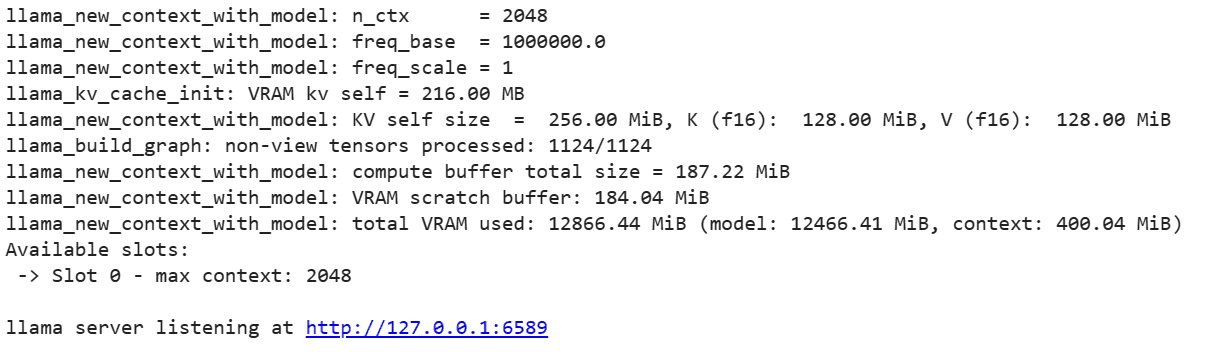
پچھلے مرحلے میں پراکسی پورٹ ہائپر لنک پر کلک کرکے چیٹ ویب ایپ تک رسائی حاصل کی جاسکتی ہے کیونکہ سرور مقامی طور پر نہیں چل رہا ہے۔
LLaMA C++ Webapp
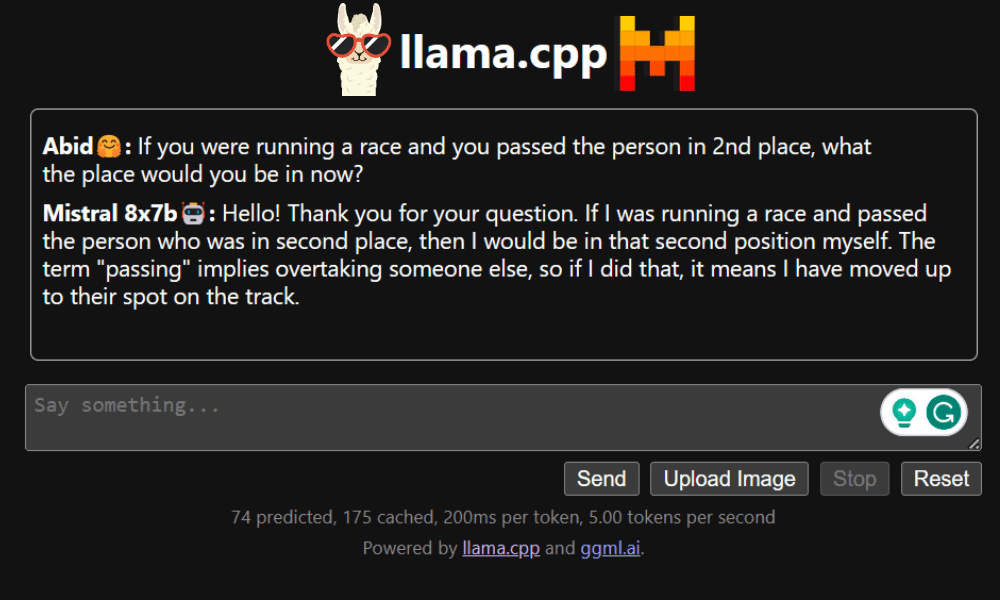
اس سے پہلے کہ ہم چیٹ بوٹ کا استعمال شروع کریں، ہمیں اسے اپنی مرضی کے مطابق کرنے کی ضرورت ہے۔ پرامپٹ سیکشن میں "LLaMA" کو اپنے ماڈل کے نام سے تبدیل کریں۔ مزید برآں، پیدا کردہ جوابات کے درمیان فرق کرنے کے لیے صارف کے نام اور بوٹ کے نام میں ترمیم کریں۔
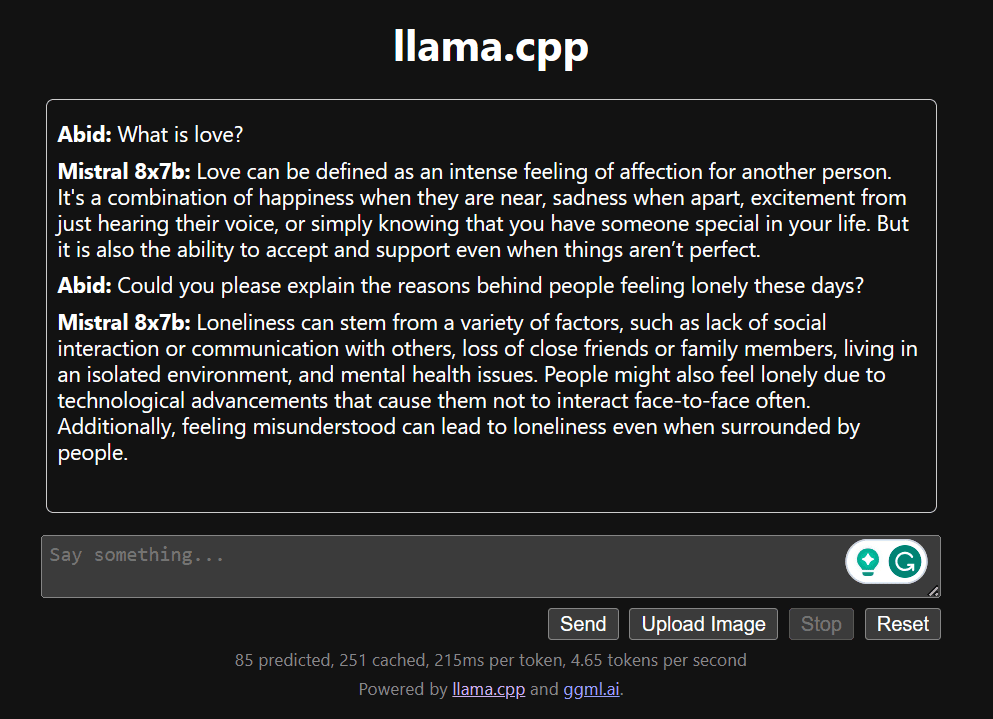
چیٹ سیکشن میں نیچے سکرول کرکے اور ٹائپ کرکے چیٹنگ شروع کریں۔ بلا جھجھک تکنیکی سوالات پوچھیں جن کا دیگر اوپن سورس ماڈل مناسب طریقے سے جواب دینے میں ناکام رہے ہیں۔
اگر آپ کو ایپ میں مسائل کا سامنا کرنا پڑتا ہے، تو آپ میرا Google Colab استعمال کرکے اسے خود چلانے کی کوشش کر سکتے ہیں: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
یہ ٹیوٹوریل LLaMA C++ لائبریری کا استعمال کرتے ہوئے Google Colab پر ایڈوانسڈ اوپن سورس ماڈل، Mixtral 8x7b کو چلانے کے بارے میں ایک جامع گائیڈ فراہم کرتا ہے۔ دوسرے ماڈلز کے مقابلے میں، Mixtral 8x7b اعلی کارکردگی اور کارکردگی فراہم کرتا ہے، جو اسے ان لوگوں کے لیے ایک بہترین حل بناتا ہے جو بڑے زبان کے ماڈلز کے ساتھ تجربہ کرنا چاہتے ہیں لیکن ان کے پاس وسیع کمپیوٹیشنل وسائل نہیں ہیں۔ آپ اسے آسانی سے اپنے لیپ ٹاپ پر یا مفت کلاؤڈ کمپیوٹ پر چلا سکتے ہیں۔ یہ صارف دوست ہے، اور آپ اپنی چیٹ ایپ کو دوسروں کے استعمال اور تجربہ کرنے کے لیے بھی تعینات کر سکتے ہیں۔
مجھے امید ہے کہ آپ کو بڑے ماڈل کو چلانے کے لیے یہ آسان حل مددگار ثابت ہوا ہے۔ میں ہمیشہ آسان اور بہتر آپشنز کی تلاش میں رہتا ہوں۔ اگر آپ کے پاس اس سے بھی بہتر حل ہے تو براہ کرم مجھے بتائیں، اور میں اگلی بار اس کا احاطہ کروں گا۔
عابد علی اعوان (@1abidaliawan) ایک سرٹیفائیڈ ڈیٹا سائنٹسٹ پروفیشنل ہے جو مشین لرننگ ماڈل بنانا پسند کرتا ہے۔ فی الحال، وہ مشین لرننگ اور ڈیٹا سائنس ٹیکنالوجیز پر مواد کی تخلیق اور تکنیکی بلاگ لکھنے پر توجہ دے رہا ہے۔ عابد کے پاس ٹیکنالوجی مینجمنٹ میں ماسٹر ڈگری اور ٹیلی کمیونیکیشن انجینئرنگ میں بیچلر ڈگری ہے۔ اس کا وژن دماغی بیماری کے ساتھ جدوجہد کرنے والے طلباء کے لیے گراف نیورل نیٹ ورک کا استعمال کرتے ہوئے ایک AI پروڈکٹ بنانا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- : ہے
- : نہیں
- 1
- 12
- 27
- 46
- 7
- 8
- a
- قابلیت
- تک رسائی حاصل
- رسائی
- حصول
- اس کے علاوہ
- پتہ
- اعلی درجے کی
- AI
- تمام
- بھی
- ہمیشہ
- am
- an
- اور
- جواب
- اپاچی
- اپلی کیشن
- درخواست
- مناسب
- فن تعمیر
- کیا
- AS
- پوچھنا
- کی بنیاد پر
- BE
- شروع کریں
- نیچے
- معیارات
- BEST
- بہتر
- کے درمیان
- بلاک
- بلاگز
- بوٹ
- دونوں
- تعمیر
- عمارت
- لیکن
- by
- C ++
- کہا جاتا ہے
- کر سکتے ہیں
- مصدقہ
- تبدیل
- چیٹ
- چیٹ بٹ
- چیٹنگ
- منتخب کریں
- بادل
- کوڈ
- امتزاج
- مقابلے میں
- ہم آہنگ
- وسیع
- کمپیوٹیشنل
- کمپیوٹنگ
- کمپیوٹنگ
- کنکشن
- مواد
- مواد کی تخلیق
- سیاق و سباق
- درست
- قیمت
- احاطہ
- بنائی
- مخلوق
- موجودہ
- اس وقت
- اپنی مرضی کے مطابق
- اعداد و شمار
- ڈیٹا سائنس
- ڈیٹا سائنسدان
- ڈگری
- فراہم کرتا ہے
- ثبوت
- تعیناتی
- کے باوجود
- ممتاز
- do
- نیچے
- ڈاؤن لوڈ، اتارنا
- ہر ایک
- آسانی سے
- کارکردگی
- ہنر
- تصادم
- انجنیئرنگ
- انگریزی
- بڑھاتا ہے
- بھی
- بہترین
- تجربہ
- تجربہ
- ماہرین
- تلاش
- وسیع
- چہرہ
- فیس بک
- ناکام
- باہمی
- تیز تر
- محسوس
- چند
- فائل
- توجہ مرکوز
- کے لئے
- ملا
- مفت
- فرانسیسی
- سے
- تقریب
- پیدا
- نسل
- جرمن
- حاصل
- GitHub کے
- دے دو
- گلوبل
- گوگل
- GPU
- GPUs
- گراف
- گراف نیورل نیٹ ورک
- گروپ کا
- رہنمائی
- ہینڈلنگ
- ہے
- ہونے
- he
- مدد گار
- ہائی
- اعلی کارکردگی
- اعلی معیار کی
- ان
- کی ڈگری حاصل کی
- امید ہے کہ
- کس طرح
- کیسے
- HTTPS
- حب
- i
- if
- بیماری
- درآمد
- اہم
- in
- سمیت
- معلومات
- شروع ہوا
- انسٹال
- انسٹال کرنا
- انٹرفیس
- میں
- شامل ہے
- IP
- مسائل
- IT
- اطالوی
- KDnuggets
- جان
- زبان
- زبانیں
- لیپ ٹاپ
- بڑے
- تاخیر
- بعد
- جانیں
- سیکھنے
- دو
- لائبریری
- لائسنس یافتہ
- ہلکا پھلکا
- کی طرح
- لائن
- لائنوں
- LINK
- لنکڈ
- لاما
- مقامی طور پر
- محل وقوع
- تلاش
- سے محبت کرتا ہے
- مشین
- مشین لرننگ
- بنا
- بنانا
- انتظام
- مینیجنگ
- ماسٹر
- میچ
- me
- یاد داشت
- ذہنی
- ذہنی بیماری
- طریقہ
- مرکب
- ماڈل
- ماڈل
- نظر ثانی کرنے
- زیادہ
- سب سے زیادہ
- ایک سے زیادہ
- my
- نام
- ضرورت ہے
- نیٹ ورک
- عصبی
- عصبی نیٹ ورک
- نئی
- اگلے
- تعداد
- NVIDIA
- of
- on
- ایک
- کھول
- اوپن سورس
- کام
- آپریٹنگ سسٹم
- آپشنز کے بھی
- or
- دیگر
- دیگر
- ہمارے
- Outperforms
- پیداوار
- نتائج
- خود
- پیرامیٹر
- پیرامیٹرز
- PC
- کارکردگی
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مہربانی کرکے
- پوسٹ
- پچھلا
- مصنوعات
- پیشہ ورانہ
- مناسب طریقے سے
- فراہم
- فراہم کرتا ہے
- پراکسی
- سوال
- سوالات
- رینج
- کم
- کے بارے میں
- کی جگہ
- ذخیرہ
- تحقیق
- وسائل
- جوابات
- روٹر
- رن
- چل رہا ہے
- s
- سائنس
- سائنسدان
- اسکور
- طومار کرنا
- سیکشن
- منتخب
- سرور
- سادہ
- بعد
- حل
- ماخذ
- ہسپانوی
- معیار
- ریاستی آرٹ
- مرحلہ
- مضبوط
- جدوجہد
- طلباء
- اعلی
- کی حمایت کرتا ہے
- اس بات کا یقین
- سسٹمز
- کاموں
- ٹیکنیکل
- ٹیکنالوجی
- ٹیکنالوجی
- ٹیلی مواصلات
- متن
- متن کی نسل
- کہ
- ۔
- ان
- یہ
- اس
- ان
- وقت
- کرنے کے لئے
- ٹوکن
- ٹوکن
- کل
- ترجمہ
- کوشش
- سبق
- دو
- کے تحت
- us
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارف دوست
- استعمال
- کا استعمال کرتے ہوئے
- مختلف اقسام کے
- مختلف
- ورژن
- نقطہ نظر
- چاہتے ہیں
- we
- ویب
- ویب ایپلی کیشن
- جس
- جبکہ
- ڈبلیو
- وسیع
- وسیع رینج
- گے
- ساتھ
- تحریری طور پر
- آپ
- اور
- زیفیرنیٹ