یہ پوسٹ LSEG کے لو لیٹنسی گروپ سے پرمود نائک، لکشمی کانتھ مانم اور وویک اگروال کے ساتھ مل کر لکھی گئی ہے۔
ٹرانزیکشن لاگت کا تجزیہ (TCA) بڑے پیمانے پر تاجروں، پورٹ فولیو مینیجرز، اور بروکرز کے ذریعے تجارت سے پہلے اور بعد از تجارت کے تجزیے کے لیے استعمال کیا جاتا ہے، اور لین دین کے اخراجات اور ان کی تجارتی حکمت عملیوں کی تاثیر کو ماپنے اور بہتر بنانے میں ان کی مدد کرتا ہے۔ اس پوسٹ میں، ہم آپشنز بِڈ اسک اسپریڈز کا تجزیہ کرتے ہیں۔ LSEG ٹک ہسٹری - PCAP ڈیٹا سیٹ کا استعمال کرتے ہوئے اپاچی اسپارک کے لیے ایمیزون ایتھینا. ہم آپ کو دکھاتے ہیں کہ کس طرح ڈیٹا تک رسائی حاصل کرنا ہے، ڈیٹا پر لاگو کرنے کے لیے کسٹم فنکشنز کی وضاحت کرنا، ڈیٹا سیٹ کو استفسار کرنا اور فلٹر کرنا، اور تجزیہ کے نتائج کا تصور کرنا، یہ سب کچھ بنیادی ڈھانچے کو ترتیب دینے یا اسپارک کو ترتیب دینے کی فکر کیے بغیر، یہاں تک کہ بڑے ڈیٹا سیٹس کے لیے بھی۔
پس منظر
آپشنز پرائس رپورٹنگ اتھارٹی (OPRA) ایک اہم سیکیورٹیز انفارمیشن پروسیسر کے طور پر کام کرتی ہے، آخری سیل رپورٹس، اقتباسات، اور یو ایس آپشنز کے لیے متعلقہ معلومات کو اکٹھا کرنا، مضبوط کرنا اور پھیلانا۔ 18 فعال یو ایس آپشنز ایکسچینجز اور 1.5 ملین سے زیادہ اہل معاہدوں کے ساتھ، OPRA جامع مارکیٹ ڈیٹا فراہم کرنے میں ایک اہم کردار ادا کرتا ہے۔
5 فروری 2024 کو، سیکیورٹیز انڈسٹری آٹومیشن کارپوریشن (SIAC) OPRA فیڈ کو 48 سے 96 ملٹی کاسٹ چینلز تک اپ گریڈ کرنے کے لیے تیار ہے۔ اس اضافہ کا مقصد امریکی آپشنز مارکیٹ میں بڑھتی ہوئی تجارتی سرگرمیوں اور اتار چڑھاؤ کے جواب میں علامت کی تقسیم اور لائن صلاحیت کے استعمال کو بہتر بنانا ہے۔ SIAC نے سفارش کی ہے کہ فرمیں 37.3 GBits فی سیکنڈ تک کی چوٹی ڈیٹا کی شرح کے لیے تیاری کریں۔
اپ گریڈ کے باوجود شائع شدہ ڈیٹا کے کل حجم میں فوری طور پر کوئی ردوبدل نہ ہونے کے باوجود، یہ OPRA کو قابل بناتا ہے کہ ڈیٹا کو نمایاں طور پر تیز رفتاری سے پھیلا سکے۔ یہ منتقلی متحرک آپشنز مارکیٹ کے مطالبات کو پورا کرنے کے لیے بہت اہم ہے۔
OPRA 150.4 کی سہ ماہی میں ایک ہی دن میں 3 بلین پیغامات کی چوٹی کے ساتھ اور ایک ہی دن میں 2023 بلین پیغامات کی گنجائش کے ہیڈ روم کی ضرورت کے ساتھ سب سے زیادہ بڑے فیڈز کے طور پر نمایاں ہے۔ لین دین کی لاگت کے تجزیات، مارکیٹ لیکویڈیٹی کی نگرانی، تجارتی حکمت عملی کی تشخیص، اور مارکیٹ ریسرچ کے لیے ہر ایک پیغام کو کیپچر کرنا بہت ضروری ہے۔
ڈیٹا کے بارے میں
LSEG ٹک ہسٹری - PCAP ایک کلاؤڈ بیسڈ ریپوزٹری ہے، جو 30 PB سے زیادہ ہے، جس میں انتہائی اعلیٰ معیار کا عالمی مارکیٹ ڈیٹا موجود ہے۔ یہ ڈیٹا احتیاط سے براہ راست ایکسچینج ڈیٹا سینٹرز کے اندر حاصل کیا جاتا ہے، دنیا بھر کے بڑے پرائمری اور بیک اپ ایکسچینج ڈیٹا سینٹرز میں اسٹریٹجک طور پر موجود بے کار کیپچر کے عمل کو استعمال کرتے ہوئے۔ LSEG کی کیپچر ٹیکنالوجی بے نقصان ڈیٹا کیپچر کو یقینی بناتی ہے اور نینو سیکنڈ ٹائم اسٹیمپ کی درستگی کے لیے GPS ٹائم سورس استعمال کرتی ہے۔ مزید برآں، ڈیٹا کے کسی بھی خلاء کو بغیر کسی رکاوٹ کے پُر کرنے کے لیے جدید ترین ڈیٹا ثالثی تکنیکوں کا استعمال کیا جاتا ہے۔ کیپچر کرنے کے بعد، ڈیٹا کو پیچیدہ پروسیسنگ اور ثالثی سے گزرنا پڑتا ہے، اور پھر اسے استعمال کرتے ہوئے پارکیٹ فارمیٹ میں نارمل کیا جاتا ہے۔ ایل ایس ای جی کا ریئل ٹائم الٹرا ڈائریکٹ (RTUD) فیڈ ہینڈلرز۔
نارملائزیشن کا عمل، جو کہ تجزیہ کے لیے ڈیٹا کی تیاری کے لیے لازمی ہے، روزانہ 6 TB تک کمپریسڈ Parquet فائلیں تیار کرتا ہے۔ اعداد و شمار کے بڑے حجم کو OPRA کی محیط نوعیت سے منسوب کیا گیا ہے، جس میں متعدد تبادلے پھیلے ہوئے ہیں، اور متعدد اختیارات کے معاہدوں کی خصوصیات ہیں جن کی خصوصیات متنوع خصوصیات ہیں۔ مارکیٹ کے اتار چڑھاؤ میں اضافہ اور آپشن ایکسچینجز پر مارکیٹ بنانے کی سرگرمی OPRA پر شائع شدہ ڈیٹا کے حجم میں مزید اضافہ کرتی ہے۔
ٹک ہسٹری کے اوصاف - PCAP فرموں کو مختلف تجزیہ کرنے کے قابل بناتا ہے، بشمول درج ذیل:
- تجارت سے پہلے کا تجزیہ - ممکنہ تجارتی اثرات کا جائزہ لیں اور تاریخی ڈیٹا کی بنیاد پر عمل درآمد کی مختلف حکمت عملیوں کو دریافت کریں۔
- تجارت کے بعد کی تشخیص - عمل درآمد کی حکمت عملیوں کی کارکردگی کا جائزہ لینے کے لیے بینچ مارکس کے خلاف عمل درآمد کے اصل اخراجات کی پیمائش کریں۔
- آپٹمائزڈ پھانسی - مارکیٹ کے اثرات کو کم سے کم کرنے اور مجموعی تجارتی لاگت کو کم کرنے کے لیے تاریخی مارکیٹ پیٹرن کی بنیاد پر عمل درآمد کی حکمت عملی
- رسک مینیجمنٹ - پھسلنے کے نمونوں کی شناخت کریں، باہر نکلنے والوں کی شناخت کریں، اور تجارتی سرگرمیوں سے وابستہ خطرات کو فعال طور پر منظم کریں
- کارکردگی کا انتساب - پورٹ فولیو کی کارکردگی کا تجزیہ کرتے وقت تجارتی فیصلوں کے اثرات کو سرمایہ کاری کے فیصلوں سے الگ کریں۔
LSEG ٹک ہسٹری – PCAP ڈیٹاسیٹ دستیاب ہے۔ AWS ڈیٹا ایکسچینج اور پر رسائی حاصل کی جا سکتی ہے۔ AWS مارکیٹ پلیٹ فارم. کے ساتھ AWS ڈیٹا ایکسچینج برائے Amazon S3، آپ LSEG's سے براہ راست PCAP ڈیٹا تک رسائی حاصل کر سکتے ہیں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹیاں، فرموں کو ڈیٹا کی اپنی کاپی کو ذخیرہ کرنے کی ضرورت کو ختم کرتی ہے۔ یہ نقطہ نظر ڈیٹا مینجمنٹ اور سٹوریج کو ہموار کرتا ہے، جو کلائنٹس کو اعلیٰ معیار کے PCAP یا نارملائزڈ ڈیٹا تک آسانی سے استعمال، انضمام اور آسانی کے ساتھ رسائی فراہم کرتا ہے۔ کافی ڈیٹا اسٹوریج کی بچت.
اپاچی اسپارک کے لیے ایتھینا
تجزیاتی کوششوں کے لیے، اپاچی اسپارک کے لیے ایتھینا ایتھینا کنسول یا ایتھینا APIs کے ذریعے قابل رسائی نوٹ بک کا ایک آسان تجربہ پیش کرتا ہے، جو آپ کو انٹرایکٹو اپاچی اسپارک ایپلی کیشنز بنانے کی اجازت دیتا ہے۔ ایک بہترین اسپارک رن ٹائم کے ساتھ، ایتھینا اسپارک انجنوں کی تعداد کو ایک سیکنڈ سے بھی کم کر کے متحرک طور پر ڈیٹا کے پیٹا بائٹس کے تجزیہ میں مدد کرتی ہے۔ مزید برآں، عام Python لائبریریاں جیسے pandas اور NumPy کو بغیر کسی رکاوٹ کے مربوط کیا جاتا ہے، جس سے ایپلی کیشن کی پیچیدہ منطق کی تخلیق ہوتی ہے۔ یہ لچک نوٹ بک میں استعمال کے لیے اپنی مرضی کی لائبریریوں کی درآمد تک پھیلی ہوئی ہے۔ ایتھینا فار اسپارک زیادہ تر اوپن ڈیٹا فارمیٹس کو ایڈجسٹ کرتا ہے اور بغیر کسی رکاوٹ کے ساتھ مربوط ہے۔ AWS گلو ڈیٹا کیٹلاگ۔
ڈیٹا بیس
اس تجزیہ کے لیے، ہم نے 17 مئی 2023 سے LSEG ٹک ہسٹری – PCAP OPRA ڈیٹاسیٹ استعمال کیا۔ یہ ڈیٹا سیٹ درج ذیل اجزاء پر مشتمل ہے:
- بہترین بولی اور پیشکش (BBO) - دیے گئے ایکسچینج میں سب سے زیادہ بولی اور سب سے کم سیکیورٹی کی اطلاع دیتا ہے۔
- قومی بہترین بولی اور پیشکش (NBBO) - تمام ایکسچینجز میں سب سے زیادہ بولی اور سب سے کم سیکیورٹی کی اطلاع دیتا ہے۔
- ٹریڈز - تمام ایکسچینجز میں مکمل ہونے والی تجارت کا ریکارڈ
ڈیٹاسیٹ میں درج ذیل ڈیٹا والیوم شامل ہیں:
- ٹریڈز - 160 MB تقریباً 60 کمپریسڈ پارکیٹ فائلوں میں تقسیم
- بی بی او - 2.4 ٹی بی تقریباً 300 کمپریسڈ پارکیٹ فائلوں میں تقسیم
- این بی بی او - 2.8 ٹی بی تقریباً 200 کمپریسڈ پارکیٹ فائلوں میں تقسیم
تجزیہ کا جائزہ
ٹرانزیکشن لاگت کے تجزیہ (TCA) کے لیے OPRA ٹک ہسٹری کے ڈیٹا کا تجزیہ کرنے میں ایک مخصوص تجارتی ایونٹ کے ارد گرد مارکیٹ کی قیمتوں اور تجارت کی جانچ پڑتال شامل ہے۔ ہم اس مطالعہ کے حصے کے طور پر درج ذیل میٹرکس کا استعمال کرتے ہیں:
- حوالہ شدہ اسپریڈ (QS) - BBO پوچھنے اور BBO بولی کے درمیان فرق کے طور پر شمار کیا جاتا ہے۔
- مؤثر پھیلاؤ (ES) - تجارتی قیمت اور BBO کے وسط پوائنٹ کے درمیان فرق کے طور پر شمار کیا جاتا ہے (BBO بولی + (BBO پوچھنا - BBO بولی)/2)
- مؤثر/کوٹڈ اسپریڈ (EQF) - (ES/QS) * 100 کے حساب سے شمار کیا جاتا ہے۔
ہم تجارت سے پہلے ان اسپریڈز کا حساب لگاتے ہیں اور اس کے علاوہ تجارت کے بعد چار وقفوں پر (صرف اس کے بعد، 1 سیکنڈ، 10 سیکنڈ، اور 60 سیکنڈ تجارت کے بعد)۔
Apache Spark کے لیے Athena کو ترتیب دیں۔
Apache Spark کے لیے Athena کو ترتیب دینے کے لیے، درج ذیل مراحل کو مکمل کریں:
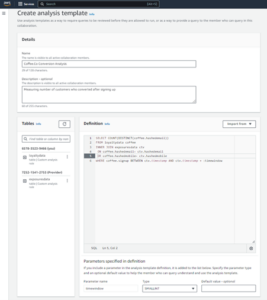
- ایتھینا کنسول پر، نیچے شروع کریںمنتخب PySpark اور Spark SQL کا استعمال کرتے ہوئے اپنے ڈیٹا کا تجزیہ کریں۔.
- اگر آپ پہلی بار ایتھینا اسپارک کا استعمال کر رہے ہیں، تو منتخب کریں۔ ورک گروپ بنائیں.

- کے لئے ورک گروپ کا نامورک گروپ کے لیے ایک نام درج کریں، جیسے
tca-analysis. - میں تجزیاتی انجن سیکشن، منتخب کریں اپاچی چمک.
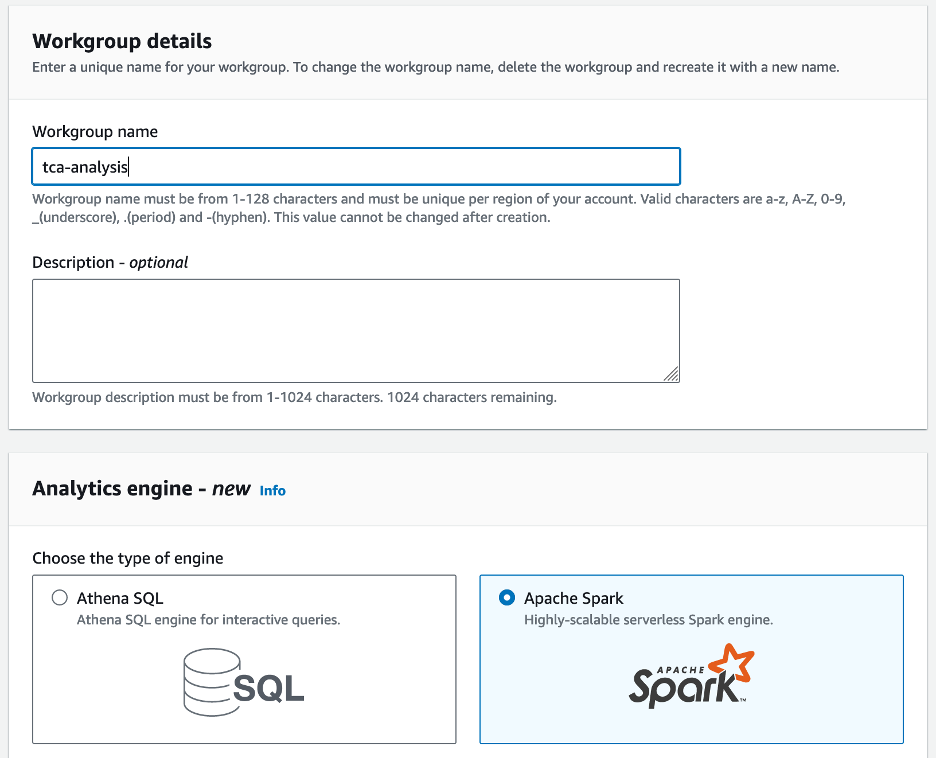
- میں اضافی کنفیگریشنز سیکشن، آپ منتخب کر سکتے ہیں ڈیفالٹس استعمال کریں۔ یا اپنی مرضی کے مطابق فراہم کریں AWS شناخت اور رسائی کا انتظام (IAM) کا کردار اور حساب کے نتائج کے لیے Amazon S3 مقام۔
- میں سے انتخاب کریں ورک گروپ بنائیں.
- ورک گروپ بنانے کے بعد، پر تشریف لے جائیں۔ نوٹ بک ٹیب اور منتخب کریں نوٹ بک بنائیں.
- اپنی نوٹ بک کے لیے ایک نام درج کریں، جیسے
tca-analysis-with-tick-history. - میں سے انتخاب کریں تخلیق کریں اپنی نوٹ بک بنانے کے لیے۔
اپنی نوٹ بک لانچ کریں۔
اگر آپ نے پہلے ہی اسپارک ورک گروپ بنا لیا ہے تو منتخب کریں۔ نوٹ بک ایڈیٹر لانچ کریں۔ کے تحت شروع کریں.
![]()
آپ کی نوٹ بک بننے کے بعد، آپ کو انٹرایکٹو نوٹ بک ایڈیٹر پر بھیج دیا جائے گا۔
![]()
اب ہم اپنی نوٹ بک میں درج ذیل کوڈ کو شامل اور چلا سکتے ہیں۔
ایک تجزیہ بنائیں
تجزیہ بنانے کے لیے درج ذیل مراحل کو مکمل کریں:
- عام لائبریریاں درآمد کریں:
- BBO، NBBO، اور تجارت کے لیے ہمارے ڈیٹا فریم بنائیں:
- اب ہم ٹرانزیکشن لاگت کے تجزیہ کے لیے استعمال کرنے کے لیے تجارت کی شناخت کر سکتے ہیں:
ہمیں درج ذیل آؤٹ پٹ ملتا ہے:
ہم تجارتی مصنوعات (tp)، تجارتی قیمت (tpr)، اور تجارتی وقت (tt) کے لیے آگے بڑھنے والی تجارتی معلومات کا استعمال کرتے ہیں۔
- یہاں ہم اپنے تجزیے کے لیے کئی مددگار افعال تخلیق کرتے ہیں۔
- مندرجہ ذیل فنکشن میں، ہم ڈیٹا سیٹ بناتے ہیں جس میں تجارت سے پہلے اور بعد کے تمام اقتباسات ہوتے ہیں۔ Athena Spark خود بخود تعین کرتا ہے کہ ہمارے ڈیٹاسیٹ پر کارروائی کرنے کے لیے کتنے DPUs کو لانچ کرنا ہے۔
- اب آئیے اپنی منتخب کردہ تجارت سے معلومات کے ساتھ TCA تجزیہ فنکشن کو کال کریں:
تجزیہ کے نتائج کا تصور کریں۔
اب آئیے ڈیٹا فریم بناتے ہیں جو ہم اپنے تصور کے لیے استعمال کرتے ہیں۔ ہر ڈیٹا فریم میں ہر ڈیٹا فیڈ (BBO، NBBO) کے لیے پانچ وقت کے وقفوں میں سے ایک کے حوالے شامل ہوتے ہیں:
مندرجہ ذیل حصوں میں، ہم مختلف تصورات بنانے کے لیے مثالی کوڈ فراہم کرتے ہیں۔
تجارت سے پہلے QS اور NBBO پلاٹ کریں۔
تجارت سے پہلے حوالہ شدہ اسپریڈ اور NBBO کو پلاٹ کرنے کے لیے درج ذیل کوڈ کا استعمال کریں:
![]()
تجارت کے بعد ہر مارکیٹ اور NBBO کے لیے QS پلاٹ کریں۔
تجارت کے فوراً بعد ہر مارکیٹ اور NBBO کے لیے درج ذیل کوڈ کا استعمال کریں:
![]()
BBO کے لیے ہر وقت کے وقفے اور ہر مارکیٹ کے لیے QS پلاٹ کریں۔
بی بی او کے لیے ہر وقت کے وقفے اور ہر مارکیٹ کے لیے درج ذیل کوڈ کا استعمال کریں:
![]()
پلاٹ ES ہر وقت کے وقفے کے لیے اور BBO کے لیے مارکیٹ
BBO کے لیے ہر وقت کے وقفے اور مارکیٹ کے لیے مؤثر اسپریڈ کی منصوبہ بندی کرنے کے لیے درج ذیل کوڈ کا استعمال کریں:
BBO کے لیے ہر بار وقفہ اور مارکیٹ کے لیے EQF پلاٹ کریں۔
BBO کے لیے ہر وقت کے وقفے اور مارکیٹ کے لیے موثر/کوٹڈ اسپریڈ کی منصوبہ بندی کرنے کے لیے درج ذیل کوڈ کا استعمال کریں:
ایتھینا اسپارک حساب کی کارکردگی
جب آپ کوڈ بلاک چلاتے ہیں، تو Athena Spark خود بخود تعین کرتا ہے کہ اسے حساب مکمل کرنے کے لیے کتنے DPUs کی ضرورت ہے۔ آخری کوڈ بلاک میں، جہاں ہم کال کرتے ہیں۔ tca_analysis فنکشن، ہم اصل میں اسپارک کو ڈیٹا پر کارروائی کرنے کی ہدایت کر رہے ہیں، اور پھر ہم نتیجے میں آنے والے اسپارک ڈیٹا فریمز کو پانڈاس ڈیٹا فریمز میں تبدیل کر دیتے ہیں۔ یہ تجزیہ کا سب سے گہرا پروسیسنگ حصہ بناتا ہے، اور جب ایتھینا اسپارک اس بلاک کو چلاتا ہے، تو یہ پروگریس بار، گزرا ہوا وقت، اور کتنے DPUs اس وقت ڈیٹا پر کارروائی کر رہے ہیں۔ مثال کے طور پر، درج ذیل حساب میں، Athena Spark 18 DPUs استعمال کر رہی ہے۔
![]()
جب آپ اپنی Athena Spark نوٹ بک کو ترتیب دیتے ہیں، تو آپ کے پاس DPUs کی زیادہ سے زیادہ تعداد سیٹ کرنے کا اختیار ہوتا ہے جسے وہ استعمال کر سکتا ہے۔ پہلے سے طے شدہ 20 DPUs ہیں، لیکن ہم نے اس حساب کو 10، 20، اور 40 DPUs کے ساتھ آزمایا تاکہ یہ ظاہر کیا جا سکے کہ کیسے Athena Spark ہمارے تجزیہ کو چلانے کے لیے خود بخود اسکیل کرتا ہے۔ ہم نے مشاہدہ کیا کہ Athena Spark لکیری طور پر اسکیل کرتا ہے، جب نوٹ بک کو زیادہ سے زیادہ 15 DPUs کے ساتھ ترتیب دیا گیا تھا تو 21 منٹ اور 10 سیکنڈ کا وقت لگتا ہے، اور جب نوٹ بک کو 8 DPUs کے ساتھ ترتیب دیا گیا تھا تو 23 منٹ اور 20 سیکنڈ کا وقت لگتا ہے۔ 4 DPUs کے ساتھ تشکیل شدہ۔ چونکہ Athena Spark چارجز DPU کے استعمال کی بنیاد پر، فی سیکنڈ گرانولریٹی پر، ان حسابات کی لاگت یکساں ہے، لیکن اگر آپ زیادہ سے زیادہ DPU قدر سیٹ کرتے ہیں، تو Athena Spark تجزیہ کا نتیجہ بہت تیزی سے واپس کر سکتی ہے۔ Athena Spark کی قیمتوں کے بارے میں مزید تفصیلات کے لیے براہ کرم کلک کریں۔ یہاں.
نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ آپ کس طرح LSEG کی Tick History-PCAP سے اعلیٰ مخلص OPRA ڈیٹا کو Athena Spark کا استعمال کرتے ہوئے ٹرانزیکشن لاگت کے تجزیات کو انجام دینے کے لیے استعمال کر سکتے ہیں۔ OPRA ڈیٹا کی بروقت دستیابی، Amazon S3 کے لیے AWS ڈیٹا ایکسچینج کی ایکسیسبیلٹی ایجادات کے ساتھ مکمل، حکمت عملی سے ان فرموں کے لیے تجزیات کے لیے وقت کو کم کرتی ہے جو تجارتی فیصلوں کے لیے قابل عمل بصیرت پیدا کرنا چاہتے ہیں۔ OPRA ہر روز تقریباً 7 TB نارملائزڈ Parquet ڈیٹا تیار کرتا ہے، اور OPRA ڈیٹا کی بنیاد پر تجزیات فراہم کرنے کے لیے انفراسٹرکچر کا انتظام کرنا مشکل ہے۔
ٹک ہسٹری کے لیے بڑے پیمانے پر ڈیٹا پروسیسنگ کو سنبھالنے میں ایتھینا کی قابلیت - OPRA ڈیٹا کے لیے PCAP اسے AWS میں تیز اور قابل توسیع تجزیاتی حل تلاش کرنے والی تنظیموں کے لیے ایک زبردست انتخاب بناتا ہے۔ یہ پوسٹ AWS ایکو سسٹم اور ٹک ہسٹری-PCAP ڈیٹا کے درمیان ہموار تعامل کو ظاہر کرتی ہے اور کس طرح مالیاتی ادارے اس ہم آہنگی سے فائدہ اٹھاتے ہوئے ڈیٹا پر مبنی فیصلہ سازی کو اہم ٹریڈنگ اور سرمایہ کاری کی حکمت عملیوں کے لیے آگے بڑھا سکتے ہیں۔
مصنفین کے بارے میں
![]() پرمود نائک LSEG میں کم لیٹنسی گروپ کے پروڈکٹ مینجمنٹ کے ڈائریکٹر ہیں۔ پرمود کے پاس مالیاتی ٹیکنالوجی کی صنعت میں 10 سال سے زیادہ کا تجربہ ہے، جو سافٹ ویئر کی ترقی، تجزیات، اور ڈیٹا مینجمنٹ پر توجہ مرکوز کرتا ہے۔ پرمود ایک سابق سافٹ ویئر انجینئر ہیں اور مارکیٹ ڈیٹا اور مقداری تجارت کے بارے میں پرجوش ہیں۔
پرمود نائک LSEG میں کم لیٹنسی گروپ کے پروڈکٹ مینجمنٹ کے ڈائریکٹر ہیں۔ پرمود کے پاس مالیاتی ٹیکنالوجی کی صنعت میں 10 سال سے زیادہ کا تجربہ ہے، جو سافٹ ویئر کی ترقی، تجزیات، اور ڈیٹا مینجمنٹ پر توجہ مرکوز کرتا ہے۔ پرمود ایک سابق سافٹ ویئر انجینئر ہیں اور مارکیٹ ڈیٹا اور مقداری تجارت کے بارے میں پرجوش ہیں۔
![]() لکشمی کانتھ مانم LSEG کے کم لیٹنسی گروپ میں پروڈکٹ مینیجر ہے۔ وہ کم تاخیر والی مارکیٹ ڈیٹا انڈسٹری کے لیے ڈیٹا اور پلیٹ فارم پروڈکٹس پر توجہ مرکوز کرتا ہے۔ لکشمی کانتھ صارفین کو ان کی مارکیٹ ڈیٹا کی ضروریات کے لیے بہترین حل تیار کرنے میں مدد کرتا ہے۔
لکشمی کانتھ مانم LSEG کے کم لیٹنسی گروپ میں پروڈکٹ مینیجر ہے۔ وہ کم تاخیر والی مارکیٹ ڈیٹا انڈسٹری کے لیے ڈیٹا اور پلیٹ فارم پروڈکٹس پر توجہ مرکوز کرتا ہے۔ لکشمی کانتھ صارفین کو ان کی مارکیٹ ڈیٹا کی ضروریات کے لیے بہترین حل تیار کرنے میں مدد کرتا ہے۔
![]() وویک اگروال LSEG کے کم لیٹنسی گروپ میں ایک سینئر ڈیٹا انجینئر ہے۔ ویویک کیپچر شدہ مارکیٹ ڈیٹا فیڈز اور حوالہ ڈیٹا فیڈز کی پروسیسنگ اور ڈیلیوری کے لیے ڈیٹا پائپ لائنوں کو تیار کرنے اور برقرار رکھنے پر کام کرتا ہے۔
وویک اگروال LSEG کے کم لیٹنسی گروپ میں ایک سینئر ڈیٹا انجینئر ہے۔ ویویک کیپچر شدہ مارکیٹ ڈیٹا فیڈز اور حوالہ ڈیٹا فیڈز کی پروسیسنگ اور ڈیلیوری کے لیے ڈیٹا پائپ لائنوں کو تیار کرنے اور برقرار رکھنے پر کام کرتا ہے۔
![]() الکیٹ میموشاج AWS میں فنانشل سروسز مارکیٹ ڈیولپمنٹ ٹیم میں پرنسپل آرکیٹیکٹ ہیں۔ Alket تکنیکی حکمت عملی کے لیے ذمہ دار ہے، شراکت داروں اور صارفین کے ساتھ مل کر کام کرنے کے لیے یہاں تک کہ سب سے زیادہ مانگی جانے والی کیپیٹل مارکیٹس کے کام کے بوجھ کو AWS کلاؤڈ پر تعینات کرتا ہے۔
الکیٹ میموشاج AWS میں فنانشل سروسز مارکیٹ ڈیولپمنٹ ٹیم میں پرنسپل آرکیٹیکٹ ہیں۔ Alket تکنیکی حکمت عملی کے لیے ذمہ دار ہے، شراکت داروں اور صارفین کے ساتھ مل کر کام کرنے کے لیے یہاں تک کہ سب سے زیادہ مانگی جانے والی کیپیٹل مارکیٹس کے کام کے بوجھ کو AWS کلاؤڈ پر تعینات کرتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 1
- 10
- 100
- 12
- 15٪
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- ہمارے بارے میں
- تک رسائی حاصل
- رسائی
- رسائی پذیری
- قابل رسائی
- کے پار
- فعال
- سرگرمی
- اصل
- اصل میں
- شامل کریں
- اس کے علاوہ
- خطاب کرتے ہوئے
- فائدہ
- کے بعد
- کے خلاف
- اگروال
- مقصد ہے
- تمام
- اجازت دے رہا ہے
- پہلے ہی
- ایمیزون
- ایمیزون ایتینا
- ایمیزون ویب سروسز
- an
- تجزیہ کرتا ہے
- تجزیہ
- تجزیاتی
- تجزیاتی
- تجزیے
- تجزیہ
- اور
- کوئی بھی
- اپاچی
- اپاچی چمک
- APIs
- درخواست
- ایپلی کیشنز
- کا اطلاق کریں
- نقطہ نظر
- تقریبا
- انترپنن
- ثالثی
- کیا
- ارد گرد
- AS
- پوچھنا
- تشخیص کریں
- منسلک
- At
- اوصاف
- اتھارٹی
- خود کار طریقے سے
- میشن
- دستیابی
- دستیاب
- AWS
- بیک اپ
- بار
- کی بنیاد پر
- BE
- کیونکہ
- اس سے پہلے
- معیارات
- BEST
- کے درمیان
- بولی
- ارب
- بلاک
- بروکرز
- تعمیر
- لیکن
- by
- حساب
- حساب
- حساب سے
- فون
- کر سکتے ہیں
- اہلیت
- دارالحکومت
- کیپٹل مارکیٹس
- قبضہ
- پر قبضہ کر لیا
- گرفتاری
- کیٹلوگ
- مراکز
- چیلنج
- چینل
- خصوصیات
- بوجھ
- انتخاب
- میں سے انتخاب کریں
- کلائنٹس
- بادل
- کوڈ
- جمع
- کامن
- زبردست
- مکمل
- مکمل
- اجزاء
- وسیع
- پر مشتمل ہے
- سلوک
- تشکیل شدہ
- ترتیب دیں
- کنسول
- مضبوط
- پر مشتمل ہے
- معاہدے
- شراکت
- تبدیل
- کارپوریشن
- قیمت
- اخراجات
- لکھا ہوا
- تخلیق
- بنائی
- مخلوق
- اہم
- اہم
- اس وقت
- اپنی مرضی کے
- گاہکوں
- ڈیش
- اعداد و شمار
- ڈیٹا مراکز
- ڈیٹا انجینئر
- ڈیٹا ایکسچینج
- ڈیٹا مینجمنٹ
- ڈیٹا پروسیسنگ
- ڈیٹا اسٹوریج
- اعداد و شمار پر مبنی ہے
- ڈیٹاسیٹس
- دن
- فیصلہ کرنا
- فیصلے
- پہلے سے طے شدہ
- وضاحت
- ترسیل
- مطالبہ
- مطالبات
- مظاہرہ
- demonstrated,en
- تعیناتی
- تفصیلات
- یہ تعین
- ترقی
- ترقی
- ترقیاتی ٹیم
- فرق
- مختلف
- براہ راست
- ڈائریکٹر
- تقسیم کئے
- تقسیم
- متنوع
- دوگنا
- ڈرائیو
- متحرک
- متحرک طور پر
- حرکیات
- ہر ایک
- کو کم
- استعمال میں آسانی
- ماحول
- ایڈیٹر
- موثر
- تاثیر
- اہل
- ختم کرنا
- ملازم
- ملازم
- کو چالو کرنے کے
- کے قابل بناتا ہے
- احاطہ کرتا ہے
- کوششیں
- انجن
- انجینئر
- انجن
- اضافہ
- یقینی بناتا ہے
- درج
- بڑھتی ہوئی
- Ether (ETH)
- اندازہ
- تشخیص
- بھی
- واقعہ
- ہر کوئی
- مثال کے طور پر
- ایکسچینج
- تبادلے
- پھانسی
- تجربہ
- تلاش
- ایکسپریس
- توسیع
- تیز تر
- خاصیت
- فروری
- انجیر
- فائلوں
- بھرنے
- فلٹر
- مالی
- مالیاتی ادارے
- مالیاتی خدمات
- مالیاتی ٹیکنالوجی
- فرم
- پہلا
- پہلی بار
- پانچ
- لچک
- توجہ مرکوز
- توجہ مرکوز
- کے بعد
- کے لئے
- فارمیٹ
- سابق
- آگے
- چار
- فریم
- سے
- تقریب
- افعال
- مزید
- فرق
- پیدا ہوتا ہے
- حاصل
- دی
- گلوبل
- عالمی بازار
- Go
- جا
- GPS
- گروپ
- ہینڈلنگ
- ہے
- ہونے
- he
- ہیڈ روم
- مدد کرتا ہے
- اعلی معیار کی
- اعلی
- سب سے زیادہ
- روشنی ڈالی گئی
- تاریخی
- تاریخ
- ہاؤسنگ
- کس طرح
- کیسے
- HTTP
- HTTPS
- IAM
- شناخت
- شناختی
- if
- فوری طور پر
- فوری طور پر
- اثر
- درآمد
- in
- سمیت
- اضافہ
- صنعت
- معلومات
- انفراسٹرکچر
- بدعت
- بصیرت
- اداروں
- اٹوٹ
- ضم
- انضمام
- بات چیت
- انٹرایکٹو
- میں
- پیچیدہ
- سرمایہ کاری
- شامل ہے
- IT
- فوٹو
- صرف
- بڑے
- بڑے پیمانے پر
- آخری
- تاخیر
- شروع
- کم
- لائبریریوں
- لائن
- لیکویڈیٹی
- محل وقوع
- منطق
- تلاش
- لو
- سب سے کم
- برقرار رکھنے
- اہم
- بناتا ہے
- بنانا
- انتظام
- انتظام
- مینیجر
- مینیجر
- مینیجنگ
- انداز
- بہت سے
- مارکیٹ
- مارکیٹ ڈیٹا
- مارکیٹ کا اثر
- مارکیٹ کی تحقیق
- مارکیٹ کے عدم استحکام
- مارکیٹ سازی
- Markets
- بڑے پیمانے پر
- ماسٹرنگ
- زیادہ سے زیادہ
- مئی..
- پیمائش
- پیغام
- پیغامات
- پیچیدہ
- احتیاط سے
- پیمائش کا معیار
- دس لاکھ
- کم سے کم
- منٹ
- نگرانی
- زیادہ
- اس کے علاوہ
- سب سے زیادہ
- بہت
- ایک سے زیادہ
- نام
- فطرت، قدرت
- تشریف لے جائیں
- ضرورت ہے
- ضروریات
- کوئی بھی نہیں
- نوٹ بک
- نوٹ بک
- تعداد
- متعدد
- عجیب
- مشاہدہ
- of
- پیش کرتے ہیں
- تجویز
- on
- ایک
- زیادہ سے زیادہ
- کی اصلاح کریں
- اصلاح
- اختیار
- آپشنز کے بھی
- or
- تنظیمیں
- ہمارے
- باہر
- پیداوار
- پر
- مجموعی طور پر
- خود
- pandas
- حصہ
- شراکت داروں کے
- جذباتی
- پیٹرن
- چوٹی
- فی
- انجام دینے کے
- کارکردگی
- اہم
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- ادا کرتا ہے
- مہربانی کرکے
- پلاٹ
- پورٹ فولیو
- پورٹ فولیو مینیجرز
- پوزیشن میں
- پوسٹ
- تجارت کے بعد
- ممکنہ
- صحت سے متعلق
- تیار
- کی تیاری
- قیمت
- قیمتوں کا تعین
- پرائمری
- پرنسپل
- عمل
- عمل
- پروسیسنگ
- پروسیسر
- مصنوعات
- پروڈکٹ مینجمنٹ
- پروڈکٹ مینیجر
- حاصل
- پیش رفت
- فراہم
- فراہم کرنے
- شائع
- ازگر
- Q3
- مقدار کی
- مقدار
- استفسار میں
- واوین
- شرح
- قیمتیں
- پڑھیں
- اصلی
- اصل وقت
- سفارش کی
- ریکارڈ
- ریڈ
- کو کم
- کم
- حوالہ
- ریفائنٹیو
- رپورٹ
- رپورٹیں
- ذخیرہ
- ضرورت
- کی ضرورت ہے
- تحقیق
- جواب
- ذمہ دار
- نتیجہ
- نتیجے
- نتائج کی نمائش
- واپسی
- خطرات
- کردار
- رن
- چلتا ہے
- فروخت
- اسکیل ایبلٹی
- توسیع پذیر
- ترازو
- سکیلنگ
- ہموار
- بغیر کسی رکاوٹ کے
- دوسری
- سیکنڈ
- سیکشن
- سیکشنز
- سیکورٹیز
- سیکورٹی
- کی تلاش
- منتخب
- منتخب
- سینئر
- علیحدہ
- کام کرتا ہے
- سروسز
- مقرر
- قائم کرنے
- دکھائیں
- شوز
- نمایاں طور پر
- اسی طرح
- سادہ
- آسان
- ایک
- slippage
- سافٹ ویئر کی
- سوفٹ ویئر کی نشوونما
- سافٹ ویئر انجنیئر
- حل
- بہتر
- تناؤ
- چنگاری
- مخصوص
- پھیلانے
- اسپریڈز
- کھڑا ہے
- مراحل
- ذخیرہ
- ذخیرہ
- حکمت عملی سے
- حکمت عملیوں
- حکمت عملی
- سلسلہ بندیاں۔
- مطالعہ
- بعد میں
- اس طرح
- SWIFT
- علامت
- مطابقت
- لے لو
- لینے
- ٹیم
- ٹیکنیکل
- تکنیک
- ٹیکنالوجی
- تجربہ
- سے
- کہ
- ۔
- کے بارے میں معلومات
- ان
- ان
- تو
- یہ
- اس
- کے ذریعے
- ٹک
- وقت
- بروقت
- ٹائمسٹیمپ
- عنوان
- کرنے کے لئے
- کل
- tp
- TPR
- تجارت
- تاجروں
- تجارت
- ٹریڈنگ
- ٹریڈنگ حکمت عملی
- ٹریڈنگ حکمت عملی ّپ کو کیسی لگی۔
- ٹرانزیکشن
- لین دین کے اخراجات
- تبدیل
- منتقلی
- الٹرا
- کے تحت
- گزرتا ہے
- اپ گریڈ
- us
- استعمال
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- استعمال
- کا استعمال کرتے ہوئے
- استعمال کرنا۔
- قیمت
- مختلف
- تصور
- تصور کرنا
- استرتا
- حجم
- جلد
- تھا
- we
- ویب
- ویب خدمات
- جب
- جس
- بڑے پیمانے پر
- گے
- ساتھ
- کے اندر
- بغیر
- ورک گروپ
- کام کر
- کام کرتا ہے
- دنیا بھر
- فکر
- X
- سال
- آپ
- اور
- زیفیرنیٹ