ایمیزون ریڈ شفٹ, ایک وسیع پیمانے پر استعمال ہونے والا کلاؤڈ ڈیٹا گودام، سب سے زیادہ کام کے بوجھ کی کارکردگی کی ضروریات کو پورا کرنے کے لیے نمایاں طور پر تیار ہوا ہے۔ یہ پوسٹ ایسی ہی ایک نئی خصوصیت کا احاطہ کرتی ہے — کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید۔
Amazon Redshift اب آپ کے استفسار کی کارکردگی کو کثیر جہتی ڈیٹا لے آؤٹ سورٹ کیز کو سپورٹ کر کے بہتر بناتا ہے، جو کہ ایک نئی قسم کی ترتیب کی کلید ہے جو ٹیبل کے فزیکل کالم کے بجائے فلٹر پریڈیکیٹ کے ذریعے ٹیبل کے ڈیٹا کو ترتیب دیتی ہے۔ کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب والی کلیدیں ٹیبل اسکینز کی کارکردگی کو نمایاں طور پر بہتر بنائیں گی، خاص طور پر جب آپ کے استفسار کے کام کا بوجھ بار بار اسکین فلٹرز پر مشتمل ہو۔
ایمیزون ریڈ شفٹ پہلے ہی کی صلاحیت فراہم کرتا ہے۔ خودکار میز کی اصلاح (ATO)، جو منتظم کی مداخلت کی ضرورت کے بغیر ترتیب اور تقسیم کی چابیاں لگا کر میزوں کے ڈیزائن کو خود بخود بہتر بناتا ہے۔ اس پوسٹ میں، ہم ATO کی طرف سے پیش کردہ ایک اضافی صلاحیت کے طور پر کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلیدوں کو متعارف کراتے ہیں اور Amazon Redshift کے ترتیب کلیدی مشیر الگورتھم کے ذریعے مضبوط کیا جاتا ہے۔
کثیر جہتی ڈیٹا لے آؤٹ ترتیب کی چابیاں
جب آپ AUTO ترتیب کی کلید کے ساتھ ٹیبل کی وضاحت کرتے ہیں، تو Amazon Redshift ATO آپ کے استفسار کی سرگزشت کا تجزیہ کرے گا اور خود بخود آپ کے ٹیبل کے لیے سنگل کالم کی ترتیب کی کلید یا کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید کو منتخب کرے گا، اس بنیاد پر کہ آپ کے کام کے بوجھ کے لیے کون سا اختیار بہتر ہے۔ جب کثیر جہتی ڈیٹا لے آؤٹ کو منتخب کیا جاتا ہے، تو Amazon Redshift ایک کثیر جہتی ترتیب کا فنکشن بنائے گا جو قطاروں کو مشترکہ طور پر تلاش کرتا ہے جن تک عام طور پر ایک ہی سوالات کے ذریعے رسائی حاصل کی جاتی ہے، اور ترتیب کے فنکشن کو بعد میں ڈیٹا بلاکس کو چھوڑنے اور انفرادی پیش گوئی کو اسکین کرنے کو چھوڑنے کے لیے استفسار کے دوران استعمال کیا جاتا ہے۔ کالم
مندرجہ ذیل صارف کے استفسار پر غور کریں، جو صارف کے کام کے بوجھ میں ایک غالب سوال کا نمونہ ہے:
Amazon Redshift ہر کالم کے لیے ڈیٹا کو 1 MB ڈسک بلاکس میں اسٹور کرتا ہے اور میز کے میٹا ڈیٹا کے حصے کے طور پر ہر بلاک میں کم از کم اور زیادہ سے زیادہ قدروں کو اسٹور کرتا ہے۔ اگر کوئی استفسار a استعمال کرتا ہے۔ حد تک محدود پیش گوئی، Amazon Redshift ٹیبل اسکین کے دوران بڑی تعداد میں بلاکس کو تیزی سے چھوڑنے کے لیے کم از کم اور زیادہ سے زیادہ اقدار کا استعمال کر سکتا ہے۔ تاہم، ذیلی خطہ کے کالم پر اس استفسار کا فلٹر اس بات کا تعین کرنے کے لیے استعمال نہیں کیا جا سکتا کہ کون سے بلاکس کو کم سے کم اور زیادہ سے زیادہ قدروں کی بنیاد پر چھوڑنا ہے، اور اس کے نتیجے میں، Amazon Redshift عنوانات کی میز سے تمام قطاروں کو اسکین کرتا ہے:
جب صارف کی استفسار کے ساتھ چلایا گیا تھا۔ titles سنگل کالم کی ترتیب والی کلید کا استعمال کرتے ہوئے subregion، سابقہ استفسار کا نتیجہ حسب ذیل ہے:
اس سے پتہ چلتا ہے کہ ٹیبل اسکین نے 2,164,081,640 قطاریں پڑھی ہیں۔
پر اسکینوں کو بہتر بنانے کے لیے titles ٹیبل، ایمیزون ریڈ شفٹ خود بخود کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید استعمال کرنے کا فیصلہ کر سکتا ہے۔ تمام قطاریں جو مطمئن کرتی ہیں۔ lower(subregion) like '%United States%' predicate ٹیبل کے ایک وقف شدہ علاقے میں شریک ہوگا، اور اس وجہ سے Amazon Redshift صرف ڈیٹا بلاکس کو اسکین کرے گا جو پیش گوئی کو پورا کرتے ہیں۔
جب صارف کی استفسار کے ساتھ چلایا جاتا ہے۔ titles کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید کا استعمال کرتے ہوئے جس میں شامل ہے۔ lower(subregion) like '%United States%' ایک پیش گوئی کے طور پر، کا نتیجہ sys_query_detail استفسار درج ذیل ہے:
اس سے پتہ چلتا ہے کہ ٹیبل اسکین نے 152,324,046 قطاریں پڑھی ہیں، جو کہ اصل کا صرف 7% ہے، اور اس میں کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید استعمال کی گئی ہے۔
نوٹ کریں کہ یہ مثال کثیر جہتی ڈیٹا لے آؤٹ خصوصیت کو ظاہر کرنے کے لیے ایک سوال کا استعمال کرتی ہے، لیکن Amazon Redshift ٹیبل کے خلاف چلنے والے تمام سوالات پر غور کرے گا اور عام طور پر چلنے والی پیشین گوئیوں کو پورا کرنے کے لیے متعدد خطوں کو تشکیل دے سکتا ہے۔
آئیے ایک اور مثال لیتے ہیں، اس بار زیادہ پیچیدہ پیشین گوئیوں اور متعدد سوالات کے ساتھ۔
ایک میز رکھنے کا تصور کریں۔ items (cost int, available int, demand int) چار قطاروں کے ساتھ جیسا کہ مندرجہ ذیل مثال میں دکھایا گیا ہے۔
| # ایڈ | لاگت آئے | دستیاب | مطالبہ |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
آپ کا غالب کام کا بوجھ دو سوالات پر مشتمل ہے:
- 70% سوالات کا نمونہ:
- 20% سوالات کا نمونہ:
چھانٹنے کی روایتی تکنیکوں کے ساتھ، آپ قیمت کے کالم پر جدول کو ترتیب دینے کا انتخاب کر سکتے ہیں، اس طرح کہ cost > 3 ترتیب سے فائدہ ہو گا۔ لہذا، ایک واحد کا استعمال کرتے ہوئے چھانٹنے کے بعد اشیاء کی میز cost کالم مندرجہ ذیل کی طرح نظر آئے گا۔
| # ایڈ | لاگت آئے | دستیاب | مطالبہ |
| علاقہ #1، قیمت <= 3 کے ساتھ | |||
| علاقہ #2، قیمت > 3 کے ساتھ | |||
| # ایڈ | لاگت آئے | دستیاب | مطالبہ |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
اس روایتی ترتیب کو استعمال کرتے ہوئے، ہم ID 4 اور ID 2 کے ساتھ اوپر کی دو (نیلی) قطاروں کو فوری طور پر خارج کر سکتے ہیں، کیونکہ وہ مطمئن نہیں ہیں۔ cost > 3.
دوسری طرف، کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید کے ساتھ، میز کو صارف کے کام کے بوجھ میں عام طور پر پائے جانے والے دو پیشین گوئیوں کے امتزاج کی بنیاد پر ترتیب دیا جائے گا، جو کہ cost > 3 اور available < demand. نتیجے کے طور پر، میز کی قطاروں کو چار خطوں میں ترتیب دیا گیا ہے۔
| # ایڈ | لاگت آئے | دستیاب | مطالبہ |
| علاقہ #1، قیمت <= 3 اور دستیاب < طلب کے ساتھ | |||
| علاقہ #2، قیمت <= 3 اور دستیاب >= طلب کے ساتھ | |||
| علاقہ #3، قیمت > 3 اور دستیاب < ڈیمانڈ کے ساتھ | |||
| خطہ #4، قیمت > 3 اور دستیاب >= طلب کے ساتھ | |||
| # ایڈ | لاگت آئے | دستیاب | مطالبہ |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
یہ تصور اس وقت اور بھی زیادہ طاقتور ہوتا ہے جب ایک قطار کی بجائے پورے بلاکس پر لاگو کیا جاتا ہے، جب ان پیچیدہ پیشین گوئیوں پر لاگو ہوتا ہے جو آپریٹرز کو چھانٹنے کی روایتی تکنیکوں کے لیے موزوں نہیں ہوتے ہیں (جیسے like)، اور جب دو سے زیادہ پیشین گوئیوں پر لاگو ہوتا ہے۔
سسٹم ٹیبلز
مندرجہ ذیل Amazon Redshift سسٹم ٹیبلز صارفین کو دکھائیں گے کہ آیا ان کے ٹیبلز اور سوالات پر کثیر جہتی ڈیٹا لے آؤٹ استعمال کیے گئے ہیں:
- اس بات کا تعین کرنے کے لیے کہ آیا کوئی خاص ٹیبل کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید استعمال کر رہا ہے، آپ چیک کر سکتے ہیں کہ آیا
sortkey1in svv_table_info مساوی ہےAUTO(SORTKEY(padb_internal_mddl_key_col)). - اس بات کا تعین کرنے کے لیے کہ آیا کوئی خاص سوال ٹیبل اسکینز کو تیز کرنے کے لیے کثیر جہتی ڈیٹا لے آؤٹ کا استعمال کرتا ہے، آپ چیک کر سکتے ہیں
step_attributeمیں sys_query_detail دیکھیں قیمت کے برابر ہوگی۔multi-dimensionalاگر اسکین کے دوران ٹیبل کی کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلید استعمال کی گئی تھی۔
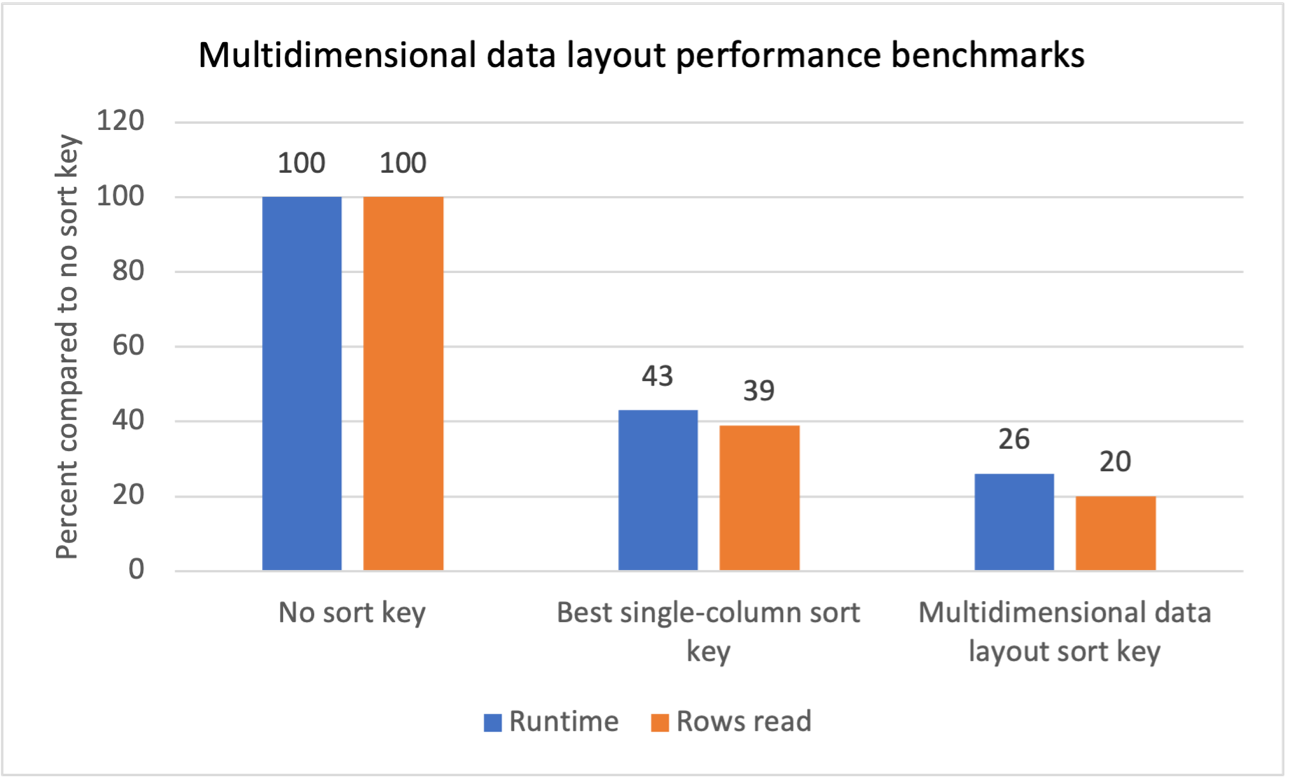
کارکردگی کے معیارات
ہم نے دہرائے جانے والے اسکین فلٹرز کے ساتھ متعدد کام کے بوجھ کے لیے اندرونی بینچ مارک ٹیسٹنگ کی اور دیکھتے ہیں کہ کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی چابیاں متعارف کرانے سے درج ذیل نتائج برآمد ہوئے:
- کوئی ترتیب کلید نہ ہونے کے مقابلے میں کل رن ٹائم میں 74% کمی۔
- ہر ٹیبل پر بہترین سنگل کالم ترتیب والی کلید رکھنے کے مقابلے میں 40% کل رن ٹائم کمی۔
- کوئی ترتیب کلید نہ ہونے کے مقابلے میں میزوں سے پڑھی جانے والی کل قطاروں میں 80% کمی۔
- ہر ٹیبل پر بہترین سنگل کالم ترتیب والی کلید رکھنے کے مقابلے میں میزوں سے پڑھی جانے والی کل قطاروں میں 47% کمی۔
خصوصیت کا موازنہ
کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلیدوں کے متعارف ہونے کے ساتھ، آپ کے ٹیبلز کو اب آپ کے کام کے بوجھ میں عام طور پر پائے جانے والے فلٹر کی پیشین گوئیوں کی بنیاد پر تاثرات کے مطابق ترتیب دیا جا سکتا ہے۔ مندرجہ ذیل جدول Amazon Redshift کے لیے دو حریفوں کے مقابلے میں ایک خصوصیت کا موازنہ فراہم کرتا ہے۔
| نمایاں کریں | ایمیزون ریڈ شفٹ | مدمقابل اے | مدمقابل B |
| کالموں پر چھانٹنے کے لیے معاونت | جی ہاں | جی ہاں | جی ہاں |
| اظہار کے لحاظ سے ترتیب دینے کے لیے معاونت | جی ہاں | جی ہاں | نہیں |
| چھانٹنے کے لیے کالم کا خودکار انتخاب | جی ہاں | نہیں | جی ہاں |
| چھانٹنے کے لیے خودکار اظہار کا انتخاب | جی ہاں | نہیں | نہیں |
| کالم کی چھانٹی یا اظہار کی چھانٹی کے درمیان خودکار انتخاب | جی ہاں | نہیں | نہیں |
| اسکین کے دوران اظہار کے لیے چھانٹنے والی خصوصیات کا خودکار استعمال | جی ہاں | نہیں | نہیں |
خیال
کثیر جہتی ڈیٹا لے آؤٹ کا استعمال کرتے وقت درج ذیل کو ذہن میں رکھیں:
- جب آپ اپنے ٹیبل کو SORTKEY AUTO کے طور پر سیٹ کرتے ہیں تو کثیر جہتی ڈیٹا لے آؤٹ فعال ہوجاتا ہے۔
- Amazon Redshift Advisor خودکار طور پر آپ کے تاریخی کام کے بوجھ کا تجزیہ کرکے ٹیبل کے لیے سنگل کالم کی ترتیب کی کلید یا کثیر جہتی ڈیٹا لے آؤٹ کا انتخاب کرے گا۔
- Amazon Redshift ATO کثیر جہتی ڈیٹا ترتیب ترتیب دینے کے نتائج کو اس طریقے کی بنیاد پر ایڈجسٹ کرتا ہے جس میں جاری سوالات کام کے بوجھ کے ساتھ تعامل کرتے ہیں۔
- Amazon Redshift ATO کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی کلیدوں کو اسی طرح برقرار رکھتا ہے جیسا کہ یہ موجودہ ترتیب والی کلیدوں کے لیے کرتا ہے۔ کا حوالہ دیتے ہیں خودکار جدول کی اصلاح کے ساتھ کام کرنا ATO پر مزید تفصیلات کے لیے۔
- کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب والی کلیدیں فراہم کردہ کلسٹرز اور سرور لیس ورک گروپس دونوں کے ساتھ کام کریں گی۔
- کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب والی کلیدیں آپ کے موجودہ ڈیٹا کے ساتھ اس وقت تک کام کریں گی جب تک کہ آپ کے ٹیبل پر AUTO SORTKEY فعال ہے اور بار بار اسکین فلٹرز کے ساتھ کام کے بوجھ کا پتہ چلا ہے۔ میز کو کثیر جہتی ترتیب کے فنکشن کے نتائج کی بنیاد پر دوبارہ ترتیب دیا جائے گا۔
- کسی ٹیبل کے لیے کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کو غیر فعال کرنے کے لیے، الٹر ٹیبل استعمال کریں:
ALTER TABLE table_name ALTER SORTKEY NONE. یہ میز پر آٹو ترتیب کی کلیدی خصوصیت کو غیر فعال کر دیتا ہے۔ - کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب کی چابیاں اس وقت محفوظ رہتی ہیں جب آپ کے فراہم کردہ کلسٹر کو سرور کے بغیر کلسٹر میں بحال یا منتقل کیا جاتا ہے یا اس کے برعکس۔
نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ کثیر جہتی ڈیٹا لے آؤٹ کی ترتیب والی کلیدیں کام کے بوجھ کے لیے استفسار کے رن ٹائم کارکردگی کو نمایاں طور پر بہتر بنا سکتی ہیں جہاں غالب سوالات میں بار بار اسکین فلٹرز ہوتے ہیں۔
Amazon Redshift کنسول سے ایک پیش نظارہ کلسٹر بنانے کے لیے، پر جائیں۔ کلسٹر صفحہ اور منتخب کریں۔ پیش نظارہ کلسٹر بنائیں. آپ یو ایس ایسٹ (اوہائیو)، یو ایس ایسٹ (این. ورجینیا)، یو ایس ویسٹ (اوریگون)، ایشیا پیسیفک (ٹوکیو)، یورپ (آئرلینڈ) اور یورپ (اسٹاک ہوم) ریجنز میں ایک کلسٹر بنا سکتے ہیں اور اپنے کام کے بوجھ کو جانچ سکتے ہیں۔
ہم اس نئی خصوصیت پر آپ کے تاثرات سننا پسند کریں گے اور اس پوسٹ پر آپ کے تبصروں کا انتظار کریں گے۔
مصنفین کے بارے میں
 ملند اوکے نیو یارک میں مقیم ڈیٹا ویئر ہاؤس اسپیشلسٹ سولیوشن آرکیٹیکٹ ہے۔ وہ 15 سالوں سے ڈیٹا گودام حل بنا رہا ہے اور Amazon Redshift میں مہارت رکھتا ہے۔
ملند اوکے نیو یارک میں مقیم ڈیٹا ویئر ہاؤس اسپیشلسٹ سولیوشن آرکیٹیکٹ ہے۔ وہ 15 سالوں سے ڈیٹا گودام حل بنا رہا ہے اور Amazon Redshift میں مہارت رکھتا ہے۔
 جیالن ڈنگ لرنڈ سسٹمز گروپ میں ایک اپلائیڈ سائنٹسٹ ہے، جو ایمیزون ریڈ شفٹ جیسے ڈیٹا سسٹمز کی کارکردگی کو بہتر بنانے کے لیے مشین لرننگ اور آپٹیمائزیشن تکنیکوں کو لاگو کرنے میں مہارت رکھتا ہے۔
جیالن ڈنگ لرنڈ سسٹمز گروپ میں ایک اپلائیڈ سائنٹسٹ ہے، جو ایمیزون ریڈ شفٹ جیسے ڈیٹا سسٹمز کی کارکردگی کو بہتر بنانے کے لیے مشین لرننگ اور آپٹیمائزیشن تکنیکوں کو لاگو کرنے میں مہارت رکھتا ہے۔
 یانزھو جی Amazon Redshift ٹیم میں پروڈکٹ مینیجر ہے۔ اسے صنعت کے معروف ڈیٹا پروڈکٹس اور پلیٹ فارمز میں پروڈکٹ وژن اور حکمت عملی کا تجربہ ہے۔ وہ ویب ڈویلپمنٹ، سسٹم ڈیزائن، ڈیٹا بیس، اور تقسیم شدہ پروگرامنگ تکنیک کا استعمال کرتے ہوئے کافی سافٹ ویئر پروڈکٹس بنانے میں شاندار مہارت رکھتی ہے۔ اپنی ذاتی زندگی میں، یانزو کو پینٹنگ، فوٹو گرافی اور ٹینس کھیلنا پسند ہے۔
یانزھو جی Amazon Redshift ٹیم میں پروڈکٹ مینیجر ہے۔ اسے صنعت کے معروف ڈیٹا پروڈکٹس اور پلیٹ فارمز میں پروڈکٹ وژن اور حکمت عملی کا تجربہ ہے۔ وہ ویب ڈویلپمنٹ، سسٹم ڈیزائن، ڈیٹا بیس، اور تقسیم شدہ پروگرامنگ تکنیک کا استعمال کرتے ہوئے کافی سافٹ ویئر پروڈکٹس بنانے میں شاندار مہارت رکھتی ہے۔ اپنی ذاتی زندگی میں، یانزو کو پینٹنگ، فوٹو گرافی اور ٹینس کھیلنا پسند ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- : ہے
- : ہے
- : نہیں
- :کہاں
- 1
- 100
- 15 سال
- 15٪
- 152
- 7
- 8
- 9
- a
- رفتار کو تیز تر
- رسائی
- ایڈیشنل
- مشیر
- کے بعد
- کے خلاف
- یلگورتم
- تمام
- پہلے ہی
- ایمیزون
- ایمیزون ویب سروسز
- an
- تجزیے
- تجزیہ
- اور
- ایک اور
- اطلاقی
- درخواست دینا
- کیا
- AS
- ایشیا
- ایشیا پیسیفک
- آٹو
- خودکار
- خود کار طریقے سے
- دستیاب
- AWS
- کی بنیاد پر
- BE
- کیونکہ
- رہا
- معیار
- فائدہ
- BEST
- بہتر
- کے درمیان
- بلاک
- بلاکس
- بلیو
- دونوں
- عمارت
- لیکن
- by
- کر سکتے ہیں
- صلاحیت
- چیک کریں
- میں سے انتخاب کریں
- بادل
- کلسٹر
- کالم
- کالم
- مجموعہ
- تبصروں
- عام طور پر
- مقابلے میں
- موازنہ
- حریف
- پیچیدہ
- تصور
- غور کریں
- مشتمل
- کنسول
- تعمیر
- پر مشتمل ہے
- قیمت
- پر محیط ہے
- تخلیق
- اس وقت
- اعداد و شمار
- ڈیٹا گودام
- ڈیٹا بیس
- فیصلہ کرنا
- وقف
- وضاحت
- ڈیمانڈ
- مطالبہ
- ڈیزائن
- تفصیلات
- پتہ چلا
- اس بات کا تعین
- ترقی
- تقسیم کئے
- تقسیم
- کرتا
- غالب
- نہیں
- کے دوران
- ہر ایک
- وسطی
- یا تو
- چالو حالت میں
- پوری
- برابر
- خاص طور پر
- Ether (ETH)
- یورپ
- تشخیص
- بھی
- وضع
- مثال کے طور پر
- موجودہ
- تجربہ
- اظہار
- نمایاں کریں
- آراء
- فلٹر
- فلٹر
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- آگے
- چار
- سے
- تقریب
- گروپ
- ہاتھ
- ہے
- ہونے
- he
- سن
- اس کی
- تاریخی
- تاریخ
- تاہم
- HTML
- HTTPS
- ID
- if
- فوری طور پر
- کو بہتر بنانے کے
- بہتر ہے
- in
- شامل ہیں
- انفرادی
- صنعت کے معروف
- کے بجائے
- بات چیت
- اندرونی
- مداخلت
- میں
- متعارف کرانے
- متعارف کرانے
- تعارف
- آئر لینڈ
- IT
- اشیاء
- کلیدی
- چابیاں
- بڑے
- لے آؤٹ
- سیکھا ہے
- سیکھنے
- زندگی
- کی طرح
- پسند
- لانگ
- دیکھو
- کی طرح دیکھو
- محبت
- مشین
- مشین لرننگ
- برقرار رکھتا ہے
- مینیجر
- انداز
- زیادہ سے زیادہ
- سے ملو
- میٹا ڈیٹا
- شاید
- ہجرت کرنا
- برا
- کم سے کم
- زیادہ
- سب سے زیادہ
- ایک سے زیادہ
- تشریف لے جائیں
- ضرورت ہے
- نئی
- نئی سہولت
- NY
- نہیں
- اب
- تعداد
- واقع ہو رہا ہے
- of
- بند
- کی پیشکش کی
- اوہائیو
- on
- ایک
- جاری
- صرف
- آپریٹرز
- اصلاح کے
- اصلاح کرتا ہے
- اختیار
- or
- حکم
- وریگن
- اصل
- دیگر
- باہر
- بقایا
- پر
- پیسیفک
- پینٹنگ
- حصہ
- خاص طور پر
- پاٹرن
- کارکردگی
- کارکردگی
- ذاتی
- فوٹو گرافی
- جسمانی
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیل
- پوسٹ
- طاقتور
- محفوظ
- پیش نظارہ
- تیار
- مصنوعات
- پروڈکٹ مینیجر
- حاصل
- پروگرامنگ
- خصوصیات
- فراہم کرتا ہے
- سوالات
- میں تیزی سے
- پڑھیں
- کمی
- کا حوالہ دیتے ہیں
- خطے
- خطوں
- بار بار
- ضروریات
- بحال
- نتیجہ
- نتائج کی نمائش
- رن
- چل رہا ہے
- چلتا ہے
- اسی
- اسکین
- سکیننگ
- اسکین کرتا ہے
- سائنسدان
- موسم
- دیکھنا
- منتخب
- منتخب
- انتخاب
- بے سرور
- سروسز
- مقرر
- وہ
- دکھائیں
- نمائش
- سے ظاہر ہوا
- دکھایا گیا
- شوز
- نمایاں طور پر
- ایک
- مہارت
- So
- سافٹ ویئر کی
- حل
- ماہر
- مہارت دیتا ہے
- مہارت
- پردہ
- حکمت عملی
- بعد میں
- کافی
- اس طرح
- موزوں
- امدادی
- کے نظام
- سسٹمز
- ٹیبل
- لے لو
- ٹیم
- تکنیک
- ٹینس
- ٹیسٹ
- ٹیسٹنگ
- سے
- کہ
- ۔
- ان
- لہذا
- وہ
- اس
- وقت
- عنوانات
- کرنے کے لئے
- ٹوکیو
- سب سے اوپر
- کل
- روایتی
- دو
- قسم
- عام طور پر
- us
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- استعمال
- کا استعمال کرتے ہوئے
- قیمت
- اقدار
- وائس
- لنک
- ورجینیا
- نقطہ نظر
- گودام
- تھا
- راستہ..
- we
- ویب
- ویب سازی
- ویب خدمات
- مغربی
- جب
- چاہے
- جس
- بڑے پیمانے پر
- گے
- ساتھ
- بغیر
- کام
- گا
- سال
- یارک
- آپ
- اور
- زیفیرنیٹ