تعارف
کا امتزاج مصنوعی ذہانت (AI) اور فنکارانہ تخلیقی ڈیجیٹل آرٹ میں نمایاں طور پر پھیلاؤ کے ماڈلز کے ذریعے نئی راہیں کھولتے ہیں۔ یہ ماڈل تخلیقی AI آرٹ جنریشن میں نمایاں ہیں، جو روایتی نیورل نیٹ ورکس سے ایک الگ نقطہ نظر پیش کرتے ہیں۔ یہ مضمون آپ کو ڈفیوژن ماڈلز کی گہرائیوں میں ایک تحقیقی سفر پر لے جاتا ہے، جو بصری طور پر شاندار اور تخلیقی طور پر بھرپور فن پاروں کو تیار کرنے میں ان کے منفرد طریقہ کار کو واضح کرتا ہے۔ ڈفیوژن ماڈلز کی باریکیوں کو سمجھیں اور جدید AI ٹیکنالوجیز کے لینز کے ذریعے فنکارانہ اظہار کی نئی تعریف کرنے میں ان کے کردار کے بارے میں بصیرت حاصل کریں۔

سیکھنے کے مقاصد
- AI میں پھیلاؤ کے ماڈلز کے بنیادی تصورات کو سمجھیں۔
- آرٹ جنریشن میں ڈفیوژن ماڈلز اور روایتی نیورل نیٹ ورکس کے درمیان فرق کو دریافت کریں۔
- ڈفیوژن ماڈلز کا استعمال کرتے ہوئے آرٹ بنانے کے عمل کا تجزیہ کریں۔
- ڈیجیٹل آرٹ میں AI کے تخلیقی اور جمالیاتی مضمرات کا جائزہ لیں۔
- AI سے تیار کردہ آرٹ ورک میں اخلاقی تحفظات پر بحث کریں۔
اس مضمون کے ایک حصے کے طور پر شائع کیا گیا تھا۔ ڈیٹا سائنس بلاگتھون۔
فہرست
ڈفیوژن ماڈلز کو سمجھنا

ڈفیوژن ماڈل جنریٹو AI میں انقلاب لاتے ہیں، جو کہ روایتی تکنیکوں جیسے جنریٹو ایڈورسریئل نیٹ ورکس (GANs) سے الگ تصویر بنانے کا ایک منفرد طریقہ پیش کرتے ہیں۔ بے ترتیب شور کے ساتھ شروع کرتے ہوئے، یہ ماڈل آہستہ آہستہ اسے بہتر بناتے ہیں، ایک مصور کی طرح پینٹنگ کو ٹھیک کرتے ہیں، جس کے نتیجے میں پیچیدہ اور مربوط تصاویر بنتی ہیں۔
یہ بڑھتی ہوئی تطہیر کا عمل بازی کی طریقہ کار کی عکاسی کرتا ہے۔ یہاں ہر تکرار شور کو ٹھیک طریقے سے تبدیل کرتی ہے، اسے حتمی فنکارانہ وژن کے قریب کرتی ہے۔ آؤٹ پٹ محض بے ترتیب پن کی پیداوار نہیں ہے بلکہ فن کا ایک ارتقائی نمونہ ہے، جو اپنی ترقی اور تکمیل میں الگ ہے۔
ڈفیوژن ماڈلز کے لیے کوڈنگ نیورل نیٹ ورکس اور مشین لرننگ فریم ورک جیسے کہ TensorFlow یا PyTorch کی گہرائی سے گرفت کا مطالبہ کرتی ہے۔ نتیجے میں آنے والا کوڈ پیچیدہ ہے، جس میں AI سے تیار کردہ آرٹ میں مشاہدہ کیے گئے باریک اثرات کو حاصل کرنے کے لیے وسیع ڈیٹا سیٹس پر وسیع تربیت کی ضرورت ہوتی ہے۔
آرٹ میں مستحکم بازی کا اطلاق
AI آرٹ جنریٹرز جیسے مستحکم ڈفیوژن ماڈلز کی آمد کے لیے پلیٹ فارمز جیسے TensorFlow یا PyTorch کے اندر نفیس کوڈنگ کی ضرورت ہوتی ہے۔ یہ ماڈل بے ترتیب پن کو ساخت میں تبدیل کرنے کی اپنی صلاحیت کے لیے نمایاں ہیں، بالکل ایسے فنکار کی طرح جو ابتدائی خاکے کو ایک وشد شاہکار میں بدل دیتا ہے۔
مستحکم ڈفیوژن ماڈل GANs کی مسابقتی حرکیات کی خصوصیت کو چھوڑ کر، بے ترتیبی سے منظم تصاویر کو مجسمہ بنا کر AI آرٹ منظر کو نئی شکل دیتے ہیں۔ وہ تصوراتی اشارے کو بصری فن میں تشریح کرنے میں مہارت رکھتے ہیں، AI صلاحیتوں اور انسانی آسانی کے درمیان ہم آہنگی کے رقص کو فروغ دیتے ہیں۔ PyTorch کا استعمال کرتے ہوئے، ہم مشاہدہ کرتے ہیں کہ یہ ماڈل کس طرح بار بار افراتفری کو واضح طور پر بہتر بناتے ہیں، فنکار کے نئے خیال سے چمکدار تخلیق تک کے سفر کی عکاسی کرتے ہیں۔
اے آئی جنریٹڈ آرٹ کے ساتھ تجربہ کرنا
یہ مظاہرہ AI سے تیار کردہ آرٹ کی دلچسپ دنیا میں شامل ہے جس کا استعمال کرتے ہوئے ایک convolutional عصبی نیٹ ورک کہا جاتا ہے۔ ConvDiffusionModel. اس ماڈل کو متنوع آرٹ امیجز پر تربیت دی جاتی ہے، جس میں ڈرائنگز، پینٹنگز، مجسمے اور نقاشی شامل ہیں، جیسا کہ اس سے ماخذ کیا گیا ہے۔ یہ Kaggle ڈیٹاسیٹ. ہمارا مقصد ان آرٹ ورکس کے پیچیدہ جمالیات کو حاصل کرنے اور دوبارہ پیش کرنے کے ماڈل کی صلاحیت کو تلاش کرنا ہے۔
ماڈل آرکیٹیکچر اور ٹریننگ
تعمیراتی خاکہ
ConvDiffusionModel، اپنے بنیادی طور پر، عصبی انجینئرنگ کا ایک کمال ہے، جس میں آرٹ کی نسل کے تقاضوں کے مطابق ایک نفیس انکوڈر-ڈیکوڈر فن تعمیر کو نمایاں کیا گیا ہے۔ ماڈل کا ڈھانچہ ایک پیچیدہ عصبی نیٹ ورک ہے، جو کہ آرٹ کی نسل کے لیے خاص طور پر پیش کیے گئے بہتر انکوڈر-ڈیکوڈر میکانزم کو مربوط کرتا ہے۔ اضافی ارتعاشی تہوں اور کنکشن کو چھوڑنے کے ساتھ جو فنکارانہ وجدان کی تقلید کرتے ہیں، ماڈل کمپوزیشن اور اسلوب کی ہوشیار سمجھ کے ساتھ آرٹ کو الگ اور دوبارہ جوڑ سکتا ہے۔
- انکوڈر: انکوڈر ماڈل کی تجزیاتی آنکھ ہے، ہر ان پٹ امیج کی منٹ کی تفصیلات کی چھان بین کرتا ہے۔ جیسا کہ تصاویر انکوڈر کی ارتعاشی تہوں سے گزرتی ہیں، وہ آہستہ آہستہ ایک اویکت جگہ میں سکیڑ جاتی ہیں - اصل آرٹ ورک کی ایک کمپیکٹ، انکوڈ شدہ نمائندگی۔ ہمارا انکوڈر نہ صرف ان پٹ امیجز کی جانچ پڑتال کرتا ہے بلکہ اب اضافی تہوں اور بیچ نارملائزیشن کی تکنیکوں کے بشکریہ تصور کی بڑھی ہوئی گہرائی کے ساتھ ایسا کرتا ہے۔ یہ توسیع شدہ امتحان اویکت جگہ کے اندر ایک بھرپور، گاڑھا نمائندگی کرنے کی اجازت دیتا ہے، جو کسی فنکار کے کسی مضمون کے گہرے غور و فکر کا آئینہ دار ہوتا ہے۔
- ڈوڈور: اس کے برعکس، ڈیکوڈر ماڈل کے تخلیقی ہاتھ کے طور پر کام کرتا ہے، انکوڈر سے تجریدی خاکے لے کر ان میں زندگی کا سانس لیتا ہے۔ یہ پوشیدہ جگہ سے آرٹ ورک کو دوبارہ تشکیل دیتا ہے، تہہ در تہہ، تفصیل سے تفصیل، یہاں تک کہ ایک مکمل تصویر ابھرے۔ ہمارا ڈیکوڈر کنکشن چھوڑنے سے فائدہ اٹھاتا ہے اور زیادہ درستگی کے ساتھ آرٹ ورک کو دوبارہ بنا سکتا ہے۔ یہ ان پٹ کے تجریدی جوہر پر نظرثانی کرتا ہے اور اسے بتدریج مزین کرتا ہے، اور ایک ایسی پیش کش کو حاصل کرتا ہے جو ماخذ مواد کے لیے زیادہ وفادار ہو۔ بہتر شدہ پرتیں کنسرٹ میں اس بات کو یقینی بنانے کے لیے کام کرتی ہیں کہ حتمی تصویر ایک وشد، پیچیدہ ٹکڑا ہے جو ان پٹ کی فنکاری کا عکاس ہے۔
تربیتی عمل
ConvDiffusionModel کی تربیت 150 عہدوں پر محیط فنکارانہ منظر نامے کے ذریعے ایک سفر ہے۔ ہر دور پورے ڈیٹاسیٹ کے ذریعے مکمل گزرنے کی نمائندگی کرتا ہے، جس میں ماڈل اپنی سمجھ کو بہتر بنانے اور اپنی تخلیق کردہ تصاویر کی وفاداری کو بہتر بنانے کی کوشش کرتا ہے۔
- ہائبرڈ نقصان کا فنکشن: تربیت کے مرکز میں اوسط اسکوائرڈ ایرر (MSE) نقصان کا فنکشن ہے۔ یہ فنکشن اصل شاہکار اور ماڈل کی تفریح کے درمیان فرق کو کم سے کم کرنے کے لیے واضح میٹرک فراہم کرتا ہے۔ ہم پہلے سے تربیت یافتہ VGG نیٹ ورک سے اخذ کردہ ایک ادراک نقصان کا جزو متعارف کرائیں گے جو اوسط اسکوائرڈ ایرر (MSE) میٹرک کی تکمیل کرتا ہے۔ یہ دوہرے نقصان کی حکمت عملی ماڈل کو اصل کی فنکارانہ سالمیت کا احترام کرنے پر مجبور کرتی ہے جبکہ ان کی تفصیلات کے تکنیکی پنروتپادن کو مکمل کرتی ہے۔
- اصلاح کنندہ: اس کی سیکھنے کی شرح کو ایک شیڈیولر کے ذریعے متحرک طور پر ایڈجسٹ کرنے کے ساتھ، ایڈم آپٹیمائزر ماڈل کے سیکھنے کی بڑھتی ہوئی سمجھداری کے ساتھ رہنمائی کرتا ہے۔ یہ انکولی نقطہ نظر اس بات کو یقینی بناتا ہے کہ آرٹ کی نقل تیار کرنے اور اختراع کرنے کے بارے میں سیکھنے میں ماڈل کی پیشرفت مستحکم اور مضبوط ہے۔
- تکرار اور تطہیر: تربیتی تکرار فنکارانہ جوہر کو محفوظ رکھنے اور تکنیکی نقل تیار کرنے کے درمیان ایک رقص ہے۔ ہر چکر کے ساتھ، ماڈل وفاداری اور تخلیقی صلاحیتوں کی ترکیب کے قریب پہنچ جاتا ہے۔
- پیشرفت کا تصور: ماڈل کی پیشرفت کو دیکھنے کے لیے تربیت کے دوران باقاعدہ وقفوں پر تصاویر محفوظ کی جاتی ہیں۔. یہ سنیپ شاٹس ماڈل کے سیکھنے کے منحنی خطوط میں ایک ونڈو پیش کرتے ہیں، یہ ظاہر کرتے ہیں کہ اس کا تخلیق کردہ آرٹ کس طرح تیار ہوتا ہے، واضح، زیادہ مفصل، اور ہر دور کے ساتھ زیادہ فنکارانہ طور پر ہم آہنگ ہوتا ہے۔



مندرجہ بالا کوڈ کے درج ذیل ٹکڑے کے ذریعے ظاہر کیا گیا ہے:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')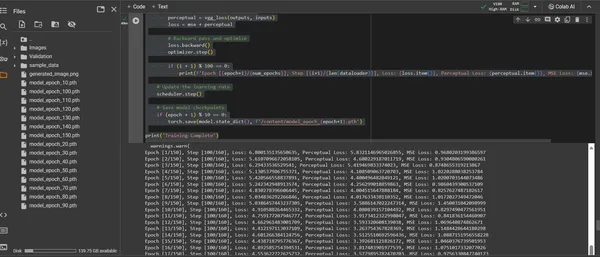
تخلیق شدہ آرٹ ورک کا تصور کرنا
AI-کرافٹڈ آرٹسٹری کو ظاہر کرنا
اب مکمل طور پر تربیت یافتہ ConvDiffusionModel کے ساتھ، توجہ تجریدی سے کنکریٹ کی طرف منتقل ہو جاتی ہے — AI سے تیار کردہ آرٹ کو حقیقت میں لانے کی صلاحیت سے۔ بعد کے کوڈ کا ٹکڑا ماڈل کی سیکھی ہوئی فنکارانہ صلاحیتوں کو عملی شکل دیتا ہے، ان پٹ ڈیٹا کو اظہار کے ڈیجیٹل کینوس میں تبدیل کرتا ہے۔
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()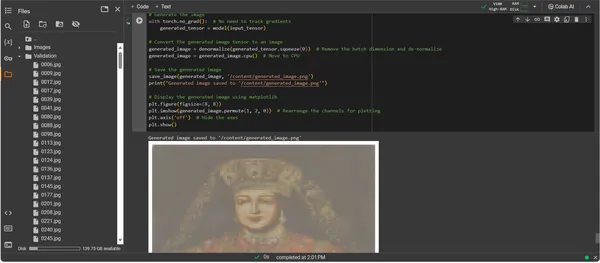

آرٹ ورک جنریشن کوڈ واک تھرو
- ماڈل قیامت: آرٹ ورک کی نسل کا پہلا قدم ہمارے تربیت یافتہ ConvDiffusionModel کو زندہ کرنا ہے۔ ماڈل کے سیکھے ہوئے وزن کو لوڈ کیا جاتا ہے اور تشخیص کے موڈ میں لایا جاتا ہے، اس کے پیرامیٹرز کو مزید تبدیل کیے بغیر تخلیق کا مرحلہ طے کرتا ہے۔
- تصویری تبدیلی: تربیتی نظام کے ساتھ مستقل مزاجی کو یقینی بنانے کے لیے، ان پٹ امیجز پر تبدیلیوں کے اسی سلسلے کے ذریعے کارروائی کی جاتی ہے۔ اس میں ماڈل کے ان پٹ ڈائمینشنز سے ملنے کے لیے سائز تبدیل کرنا، PyTorch مطابقت کے لیے ٹینسر کی تبدیلی، اور ٹریننگ ڈیٹا کے شماریاتی پروفائل کی بنیاد پر نارملائزیشن شامل ہے۔
- غیر معمولی بنانے کی افادیت: ایک حسب ضرورت فنکشن پری پروسیسنگ اثرات کو ریورس کرتا ہے، ٹینسر کو اصل تصویر کے رنگ کی حد میں دوبارہ اسکیل کرتا ہے۔ یہ مرحلہ پیدا شدہ آؤٹ پٹ کو بصری طور پر درست نمائندگی میں پیش کرنے کے لیے ضروری ہے۔
- ان پٹ کی تیاری: ایک تصویر بھری ہوئی ہے اور مذکورہ بالا تبدیلیوں کے تابع ہے۔ یہ نوٹ کرنا بہت ضروری ہے کہ یہ تصویر اس میوز کے طور پر کام کرتی ہے جس سے AI متاثر کرے گا — خاموش سرگوشی ماڈل کے مصنوعی تخیل کو بھڑکاتی ہے۔
- آرٹ ورک کی ترکیب: آگے بڑھنے کے ایک نازک رقص میں، ماڈل ان پٹ ٹینسر کی تشریح کرتا ہے، جس سے اس کی تہوں کو ایک نیا فنکارانہ وژن پیدا کرنے میں تعاون کرنے کی اجازت ملتی ہے۔ گریڈیئنٹس کو ٹریک کیے بغیر اس عمل کو انجام دیں، کیونکہ اب ہم درخواست کے دائرے میں ہیں، تربیت کے نہیں۔
- تصویری تبدیلی: ماڈل کا ٹینسر آؤٹ پٹ، جو اب ڈیجیٹل طور پر پیدا ہونے والے آرٹ ورک کو رکھتا ہے، کو غیر معمولی بنا دیا گیا ہے، جو ماڈل کی تخلیق کو رنگ اور روشنی کی مانوس جگہ میں ترجمہ کر رہا ہے جس کی ہماری آنکھیں تعریف کر سکتی ہیں۔
- آرٹ ورک کا انکشاف: تبدیل شدہ ٹینسر کو ڈیجیٹل کینوس پر بچھایا جاتا ہے، جس کا اختتام ایک محفوظ کردہ تصویری فائل میں ہوتا ہے۔ یہ فائل AI کی تخلیقی روح میں ایک ونڈو ہے، متحرک عمل کی ایک مستحکم بازگشت جس نے اسے زندگی بخشی۔
- آرٹ ورک کی بازیافت: اسکرپٹ تیار کردہ تصویر کو ایک مقررہ راستے پر محفوظ کرکے اور اس کی تکمیل کا اعلان کرکے اختتام پذیر ہوتا ہے۔ محفوظ شدہ تصویر، سیکھے ہوئے فنکارانہ اصولوں اور ابھرتی ہوئی تخلیقی صلاحیتوں کی ترکیب، نمائش اور غور و فکر کے لیے تیار ہے۔
آؤٹ پٹ کا تجزیہ کرنا
ConvDiffusionModel کا آؤٹ پٹ تاریخی آرٹ کی واضح منظوری کے ساتھ ایک شخصیت پیش کرتا ہے۔ وسیع و عریض لباس میں ملبوس، AI کی طرف سے پیش کی گئی تصویر کلاسیکی پورٹریٹ کی عظمت کی بازگشت ابھی تک ایک الگ، جدید ٹچ کے ساتھ ہے۔ موضوع کا لباس ساخت سے بھرپور ہے، جو ماڈل کے سیکھے ہوئے نمونوں کو ایک نئی تشریح کے ساتھ ملاتا ہے۔ چہرے کے نازک خدوخال اور روشنی اور سائے کا ایک لطیف تعامل روایتی فنی تکنیکوں کے بارے میں AI کی باریک بینی کو ظاہر کرتا ہے۔ یہ آرٹ ورک ماڈل کی نفیس تربیت کا ثبوت ہے، جو جدید مشین لرننگ کے پرزم کے ذریعے تاریخی فن کاری کی ایک خوبصورت ترکیب کی عکاسی کرتا ہے۔ جوہر میں، یہ ماضی کے لیے ایک ڈیجیٹل خراج ہے، جو حال کے الگورتھم کے ساتھ تیار کیا گیا ہے۔
چیلنجز اور اخلاقی تحفظات
آرٹ جنریشن کے لیے ڈفیوژن ماڈلز کا نفاذ اپنے ساتھ کئی چیلنجز اور اخلاقی تحفظات لاتا ہے جن پر آپ کو غور کرنا چاہیے:
- ڈیٹا پرووینس: تربیتی ڈیٹاسیٹس کو ذمہ داری سے تیار کیا جانا چاہیے۔ اس بات کی تصدیق کرنا کہ ڈفیوژن ماڈلز کو تربیت دینے کے لیے استعمال ہونے والے ڈیٹا میں مناسب اجازت کے بغیر کاپی رائٹ شدہ یا محفوظ کام شامل نہیں ہیں۔
- تعصب اور نمائندگی: AI ماڈلز اپنے تربیتی ڈیٹا میں تعصب کو برقرار رکھ سکتے ہیں۔ متنوع اور جامع ڈیٹاسیٹس کو یقینی بنانا AI سے تیار کردہ آرٹ میں دقیانوسی تصورات کو تقویت دینے سے بچنے کے لیے اہم ہے۔
- آؤٹ پٹ پر کنٹرول: چونکہ ڈفیوژن ماڈل وسیع پیمانے پر آؤٹ پٹ پیدا کر سکتے ہیں، اس لیے نامناسب یا جارحانہ مواد کی تخلیق کو روکنے کے لیے حدود کا تعین ضروری ہے۔
- قانونی ڈھانچہ: تخلیقی عمل میں AI کی باریکیوں سے نمٹنے کے لیے ایک مضبوط قانونی فریم ورک کی کمی ایک چیلنج پیش کرتی ہے۔ اس میں شامل تمام فریقین کے حقوق کے تحفظ کے لیے قانون سازی کی ضرورت ہے۔
نتیجہ
AI اور آرٹ میں پھیلاؤ کے ماڈلز کا عروج ایک تبدیلی کے دور کی نشاندہی کرتا ہے، جس میں کمپیوٹیشنل درستگی کو جمالیاتی ریسرچ کے ساتھ ملایا جاتا ہے۔ فن کی دنیا میں ان کا سفر اہم اختراعی صلاحیت کو اجاگر کرتا ہے لیکن پیچیدگیوں کے ساتھ آتا ہے۔ اصلیت، اثر و رسوخ، اخلاقی تخلیق، اور موجودہ کاموں کا احترام کرنا فنکارانہ عمل کا لازمی جزو ہے۔
کلیدی لے لو
- ڈفیوژن ماڈل آرٹ کی تخلیق میں تبدیلی کی تبدیلی میں سب سے آگے ہیں۔ وہ نئے ڈیجیٹل ٹولز پیش کرتے ہیں جو روایتی حدود سے باہر فنکارانہ اظہار کے کینوس کو وسعت دیتے ہیں۔
- AI سے بہتر آرٹ میں، تربیتی ڈیٹا کے اخلاقی اجتماع کو ترجیح دینا اور تخلیق کاروں کی دانشورانہ املاک کا احترام کرنا ڈیجیٹل آرٹسٹری میں سالمیت کو برقرار رکھنے کے لیے ناگزیر ہے۔
- فنکارانہ وژن اور تکنیکی جدت طرازی سے فنکاروں اور AI ڈویلپرز کے درمیان ایک علامتی تعلق کے دروازے کھلتے ہیں۔ ایک باہمی تعاون کے ماحول کو فروغ دیں جو زمینی فن کو جنم دے سکے۔
- اس بات کو یقینی بنانا کہ AI سے تیار کردہ آرٹ وسیع تناظر کی نمائندگی کرتا ہے۔ ڈیٹا کی متنوع رینج کو شامل کریں جو مختلف ثقافتوں اور نقطہ نظر کی بھرپوریت کو ظاہر کرتا ہے، اس طرح شمولیت کو فروغ دیتا ہے۔
- AI سے تیار کردہ آرٹ میں بڑھتی ہوئی دلچسپی مضبوط قانونی فریم ورک کے قیام کی ضرورت ہے۔ ان فریم ورک کو کاپی رائٹ کے مسائل کو واضح کرنا چاہیے، شراکت کو تسلیم کرنا چاہیے، اور AI سے تیار کردہ آرٹ ورک کے تجارتی استعمال کو کنٹرول کرنا چاہیے۔
اس فنی ارتقاء کا آغاز تخلیقی صلاحیتوں سے بھرا ہوا راستہ پیش کرتا ہے لیکن اس کے لیے ذہن سازی کی ضرورت ہے۔ یہ ہم پر فرض ہے کہ ہم ایک ایسی زمین کی تزئین و آرائش کریں جہاں ذمہ دارانہ اور ثقافتی طور پر حساس طریقوں سے رہنمائی کرتے ہوئے AI اور آرٹ کا امتزاج پروان چڑھے۔
اکثر پوچھے گئے سوالات
A. ڈفیوژن ماڈل جنریٹیو ایم ایل الگورتھم ہیں جو بے ترتیب شور کے پیٹرن سے شروع کرکے اور آہستہ آہستہ اسے ایک مربوط تصویر میں شکل دے کر تصاویر بناتے ہیں۔ یہ عمل ایک فنکار کی طرح ہے جو خالی کینوس سے شروع ہوتا ہے اور آہستہ آہستہ تفصیل کی تہوں کو شامل کرتا ہے۔
A. GANs، ڈفیوژن ماڈلز کو آؤٹ پٹ کا فیصلہ کرنے کے لیے علیحدہ نیٹ ورک کی ضرورت نہیں ہوتی ہے۔ وہ بار بار شور کو شامل کرکے اور ہٹا کر کام کرتے ہیں، جس کے نتیجے میں اکثر زیادہ تفصیلی اور باریک تصاویر بنتی ہیں۔
A. ہاں، ڈفیوژن ماڈل تصاویر کے ڈیٹاسیٹ سے سیکھ کر آرٹ کے اصل ٹکڑوں کو تیار کر سکتے ہیں۔ تاہم، اصلیت تربیتی ڈیٹا کے تنوع اور دائرہ کار سے متاثر ہوتی ہے۔ ان ماڈلز کو تربیت دینے کے لیے موجودہ آرٹ ورکس کو استعمال کرنے کی اخلاقیات کے بارے میں ایک بحث جاری ہے۔
A. اخلاقی خدشات AI سے تیار کردہ آرٹ کاپی رائٹ کی خلاف ورزی سے گریز پر محیط ہیں۔ انسانی فنکاروں کی اصلیت کا احترام کرنا، تعصب کو برقرار رکھنے سے روکنا، اور AI کے تخلیقی عمل میں شفافیت کو یقینی بنانا۔
A. AI سے تیار کردہ آرٹ کا مستقبل امید افزا لگتا ہے، جس میں پھیلاؤ والے ماڈل فنکاروں اور تخلیق کاروں کے لیے نئے ٹولز پیش کرتے ہیں۔ ہم ٹیکنالوجی کی ترقی کے ساتھ مزید نفیس اور پیچیدہ فن پارے دیکھنے کی توقع کر سکتے ہیں۔ تاہم، تخلیقی کمیونٹی کو اخلاقی تحفظات کو نیویگیٹ کرنا چاہیے اور واضح رہنما خطوط اور بہترین طریقوں کی طرف کام کرنا چاہیے۔
اس مضمون میں دکھایا گیا میڈیا Analytics ودھیا کی ملکیت نہیں ہے اور مصنف کی صوابدید پر استعمال ہوتا ہے۔
متعلقہ
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- : ہے
- : نہیں
- :کہاں
- 001
- 1
- 10
- 100
- 11
- 12
- 15٪
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- کی صلاحیت
- ہمارے بارے میں
- اوپر
- خلاصہ
- درست
- حاصل
- حصول
- آدم
- انکولی
- انہوں نے مزید کہا
- ایڈیشنل
- پتہ
- ایڈجسٹ
- اعلی درجے کی
- ترقی
- آمد
- شکست
- AI
- ai آرٹ
- ماخوذ
- یلگوردمز
- تمام
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- an
- تجزیاتی
- تجزیاتی
- تجزیات ودھیا
- اور
- اعلان
- درخواست
- کی تعریف
- نقطہ نظر
- فن تعمیر
- کیا
- فن
- مضمون
- مصور
- فنکارانہ
- فنکارانہ طور پر
- فنکارانہ
- آرٹسٹ
- آرٹ ورک
- آرٹ ورکس
- AS
- At
- اضافہ
- اجازت
- دستیاب
- راستے
- سے اجتناب
- گریز
- ایکسس
- واپس
- برا
- توازن
- کی بنیاد پر
- BE
- بننے
- فوائد
- BEST
- بہترین طریقوں
- کے درمیان
- سے پرے
- تعصب
- باضابطہ
- خالی
- ملاوٹ
- بلاگتھون
- پیدا
- دونوں
- حدود
- سانس لینے
- گنگنا
- لاتا ہے
- وسیع
- لایا
- بڑھتی ہوئی
- لیکن
- by
- حساب
- کہا جاتا ہے
- کر سکتے ہیں
- کینوس
- صلاحیتوں
- صلاحیت
- قبضہ
- چیلنج
- چیلنجوں
- چینل
- افراتفری
- خصوصیت
- چیک کریں
- جانچ پڑتال
- کلپ
- وضاحت
- طبقے
- واضح
- واضح
- قریب
- کوڈ
- کوڈنگ
- مربوط
- تعاون
- باہمی تعاون کے ساتھ
- رنگ
- آتا ہے
- تجارتی
- کمیونٹی
- کمپیکٹ
- مطابقت
- مقابلہ
- مکمل
- تکمیل
- پیچیدہ
- پیچیدگیاں
- جزو
- ساخت
- کمپیوٹیشنل
- کمپیوٹنگ
- تصورات
- تصوراتی
- اندراج
- کنسرٹ
- اختتام
- کنکشن
- غور کریں
- خیالات
- پر مشتمل ہے
- مواد
- اس کے برعکس
- شراکت دار
- روایتی
- کنورجنس
- تبادلوں سے
- تبدیل کرنا
- مجاز اعصابی نیٹ ورک
- کاپی رائٹ
- کاپی رائٹ کی خلاف ورزی
- کور
- بدعنوان
- CPU
- تیار کیا
- تخلیق
- تخلیق
- مخلوق
- تخلیقی
- تخلیقی طور پر
- تخلیقی
- تخلیق کاروں
- اہم
- اختتامی
- کھیتی
- ثقافتی طور پر
- cured
- وکر
- اپنی مرضی کے
- سائیکل
- رقص
- اعداد و شمار
- ڈیٹاسیٹس
- بحث
- گہری
- وضاحت
- مطالبات
- demonstrated,en
- گہرائی
- گہرائی
- اخذ کردہ
- نامزد
- تفصیل
- تفصیلی
- تفصیلات
- ڈویلپرز
- آلہ
- مختلف
- فرق
- مختلف
- براڈ کاسٹننگ
- ڈیجیٹل
- ڈیجیٹل آرٹ
- ڈیجیٹل
- طول و عرض
- طول و عرض
- صوابدید
- دکھائیں
- دکھانا
- مختلف
- امتیاز
- متنوع
- تنوع
- do
- کرتا
- دروازے
- اپنی طرف متوجہ
- ڈرائنگ
- کے دوران
- متحرک
- متحرک طور پر
- حرکیات
- e
- ہر ایک
- یاد آتی ہے
- اقرار
- اثرات
- تفصیل
- اور
- ابھرتا ہے
- انکوڈنگ
- احاطہ
- احاطہ کرتا ہے
- انجنیئرنگ
- بہتر
- کو یقینی بنانے کے
- یقینی بناتا ہے
- کو یقینی بنانے ہے
- پوری
- ماحولیات
- عہد
- زمانے
- دور
- خرابی
- جوہر
- ضروری
- قیام
- Ether (ETH)
- اخلاقی
- اخلاقیات
- تشخیص
- ہر کوئی
- ارتقاء
- تیار
- وضع
- تیار ہے
- امتحان
- ایکسل
- اس کے علاوہ
- موجودہ
- توسیع
- وسیع
- توقع ہے
- کی تلاش
- تلاش
- اظہار
- توسیع
- وسیع
- آنکھ
- آنکھیں
- چہرے
- دیانتدار
- جھوٹی
- واقف
- دلچسپ
- خصوصیات
- خاصیت
- مخلص
- اعداد و شمار
- فائل
- فائلوں
- فائنل
- ختم
- پہلا
- توجہ مرکوز
- کے بعد
- کے لئے
- سب سے اوپر
- آگے
- رضاعی
- فروغ
- فریم ورک
- فریم ورک
- سے
- مکمل طور پر
- تقریب
- فنکشنل
- بنیادی
- مزید
- فیوژن
- مستقبل
- حاصل کرنا
- GANs
- جمع
- دی
- پیدا
- پیدا
- پیدا کرنے والے
- نسل
- پیداواری
- پیداواری اشتھاراتی نیٹ ورک
- پیداواری AI۔
- جنریٹر
- دے دو
- مقصد
- GPU
- میلان
- آہستہ آہستہ
- بویتا
- سمجھو
- زیادہ سے زیادہ
- جھنڈا
- ہدایت دی
- ہدایات
- ہدایات
- ہاتھ
- استعمال کرنا
- ہارٹ
- یہاں
- ذاتی ترامیم چھپائیں
- پر روشنی ڈالی گئی
- تاریخی
- انعقاد
- خراج
- عزت
- کس طرح
- تاہم
- HTTPS
- انسانی
- i
- خیال
- if
- بھڑکاتا ہے
- تصویر
- تصاویر
- تخیل
- ضروری ہے
- پر عمل درآمد
- اثرات
- درآمد
- اہم
- کو بہتر بنانے کے
- in
- شامل ہیں
- شامل
- شمولیت
- شامل
- اضافہ
- اضافہ
- مابعد
- اثر و رسوخ
- متاثر ہوا
- خلاف ورزی
- آسانی سے
- اختراعات
- جدت طرازی
- ان پٹ
- آدانوں
- بصیرت
- اٹوٹ
- انضمام کرنا
- سالمیت
- دانشورانہ
- املاک دانش
- دلچسپی
- تشریح
- میں
- پیچیدہ
- متعارف کرانے
- انترجشتھان
- ملوث
- مسائل
- IT
- تکرار
- تکرار
- میں
- سفر
- فوٹو
- جج
- نہیں
- زمین کی تزئین کی
- پرت
- تہوں
- سیکھا ہے
- سیکھنے
- قانونی
- قانونی ڈھانچہ
- قانون سازی
- لینس
- جھوٹ ہے
- زندگی
- روشنی
- کی طرح
- لوڈ کر رہا ہے
- دیکھنا
- بند
- نقصانات
- مشین
- مشین لرننگ
- برقرار رکھنے کے
- چمتکار
- شاہکار
- میچ
- مواد
- matplotlib
- مطلب
- میکانزم
- نظام
- میڈیا
- محض
- ضم
- طریقہ
- طریقہ کار
- میٹرک۔
- کم سے کم
- منٹ
- آئینہ کرنا
- ML
- ایم ایل الگورتھم
- موڈ
- ماڈل
- ماڈل
- جدید
- ماڈیول
- زیادہ
- منتقل
- بہت
- فن کی دیوی
- ضروری
- نام
- نوزائیدہ
- فطرت، قدرت
- تشریف لے جائیں
- ضروری
- ضروریات
- نیٹ ورک
- نیٹ ورک
- عصبی
- نیورل انجینئرنگ
- عصبی نیٹ ورک
- نیند نیٹ ورک
- نئی
- شور
- براہ مہربانی نوٹ کریں
- ناول
- اب
- شیڈنگ
- مشاہدہ
- مشاہدہ
- of
- بند
- جارحانہ
- پیش کرتے ہیں
- کی پیشکش
- تجویز
- اکثر
- on
- جاری
- صرف
- کھولتا ہے
- کی اصلاح کریں
- or
- اصل
- مولکتا
- اصل
- OS
- دیگر
- ہمارے
- باہر
- پیداوار
- نتائج
- پر
- ملکیت
- پینٹنگ
- پینٹنگز
- پیرامیٹر
- پیرامیٹرز
- حصہ
- جماعتوں
- منظور
- گزشتہ
- راستہ
- پاٹرن
- پیٹرن
- خیال
- کامل
- انجام دینے کے
- نقطہ نظر
- تصویر
- ٹکڑا
- ٹکڑے ٹکڑے
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پورٹریٹس
- ممکنہ
- طریقوں
- صحت سے متعلق
- ابتدائی
- حال (-)
- تحفہ
- محفوظ کر رہا ہے
- کی روک تھام
- کی روک تھام
- اصولوں پر
- پرنٹنگ
- ترجیح
- عمل
- عملدرآمد
- پیداوار
- مصنوعات
- پروفائل
- گہرا
- پیش رفت
- بڑھنے
- آہستہ آہستہ
- وعدہ
- کو فروغ دینے
- اشارہ کرتا ہے
- تبلیغ
- مناسب
- جائیداد
- حفاظت
- محفوظ
- provenance کے
- فراہم کرنے
- شائع
- تعاقب
- pytorch
- مقدار بتاتا ہے
- بے ترتیب
- بے ترتیب پن
- رینج
- شرح
- تیار
- دائرے میں
- تسلیم
- دوبارہ وضاحت کرنا
- بہتر
- بہتر
- عکاسی کرنا۔
- کی عکاسی کرتا ہے
- حکومت
- باقاعدہ
- تعلقات
- کو ہٹانے کے
- رینڈرنگ
- نقل
- نمائندگی
- کی نمائندگی کرتا ہے
- پنروتپادن
- کی ضرورت
- کی ضرورت ہے
- مشابہت
- نئی شکل دینا
- احترام
- احترام کرنا
- ذمہ دار
- ذمہ داری سے
- نتیجے
- واپسی
- وحی
- بحال کریں
- انقلاب
- RGB
- امیر
- حقوق
- اضافہ
- مضبوط
- کردار
- اسی
- محفوظ
- بچت
- منظر
- سائنس
- گنجائش
- اسکرپٹ
- دیکھنا
- SELF
- حساس
- علیحدہ
- تسلسل
- کام کرتا ہے
- مقرر
- قائم کرنے
- سیٹ اپ
- کئی
- شیڈو
- تشکیل دینا۔
- منتقل
- شفٹوں
- ہونا چاہئے
- نمائش
- نمائش
- دکھایا گیا
- اہم
- بعد
- آہستہ آہستہ
- ٹکڑا
- So
- بہتر
- روح
- ماخذ
- ھٹا
- خلا
- تناؤ
- خاص طور پر
- سپیکٹرم
- مربع
- مستحکم
- اسٹیج
- کھڑے ہیں
- شروع
- شماریات
- مستحکم
- مرحلہ
- حکمت عملی
- کوشش کر رہے ہیں
- ساخت
- شاندار
- سٹائل
- موضوع
- بعد میں
- اس طرح
- سمبیٹک
- ہم آہنگی
- ترکیب
- مصنوعی
- موزوں
- لیتا ہے
- لینے
- ہدف
- ٹیکنیکل
- تکنیک
- تکنیکی
- ٹیکنالوجی
- ٹیکنالوجی
- ٹیسسرور
- گا
- کہ
- ۔
- مستقبل
- ماخذ
- ان
- ان
- وہاں.
- یہ
- وہ
- اس
- پنپتا ہے
- کے ذریعے
- اس طرح
- کرنے کے لئے
- اوزار
- مشعل
- ٹارچ ویژن
- چھو
- کی طرف
- ٹریکنگ
- روایتی
- ٹرین
- تربیت یافتہ
- ٹریننگ
- تبدیل
- تبدیلی
- تبدیلی
- تبدیلی
- تبدیل
- تبدیل
- تبادلوں
- شفافیت
- سچ
- کوشش
- سمجھ
- افہام و تفہیم
- منفرد
- جب تک
- ظاہر کرتا ہے
- اپ ڈیٹ
- صلی اللہ علیہ وسلم
- us
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- کا استعمال کرتے ہوئے
- کی افادیت
- درست
- تصدیق کرنا
- کی طرف سے
- دیکھنے
- نقطہ نظر
- نقطہ نظر
- بصری
- بصری آرٹ
- تصور
- تصور کرنا
- ضعف
- اہم
- تھا
- we
- ویبپی
- کیا
- کیا ہے
- جس
- جبکہ
- کسبی
- ڈبلیو
- وسیع
- وسیع رینج
- گے
- ونڈو
- ساتھ
- کے اندر
- بغیر
- کام
- کام کرتا ہے
- دنیا
- X
- جی ہاں
- ابھی
- آپ
- زیفیرنیٹ
- صفر