اس مضمون میں ہم سیکھیں گے۔ اپنے صرف CPU کمپیوٹر پر GPT4All ماڈل کو کیسے تعینات اور استعمال کریں۔ (میں استعمال کر رہا ہوں a میک بک پرو GPU کے بغیر!)

اپنے کمپیوٹر پر GPT4All استعمال کریں — مصنف کی تصویر
اس مضمون میں ہم اپنے مقامی کمپیوٹر GPT4All (ایک طاقتور LLM) پر انسٹال کرنے جا رہے ہیں اور ہم دریافت کریں گے کہ python کے ساتھ اپنی دستاویزات کے ساتھ کیسے تعامل کیا جائے۔ PDFs یا آن لائن مضامین کا مجموعہ ہمارے سوال/جوابات کے لیے علمی بنیاد ہوگا۔
سے سرکاری ویب سائٹ GPT4All اس کے طور پر بیان کیا جاتا ہے استعمال میں مفت، مقامی طور پر چلنے والا، رازداری سے آگاہ چیٹ بوٹ۔ GPU یا انٹرنیٹ کی ضرورت نہیں ہے۔
GTP4All تربیت اور تعیناتی کے لیے ایک ماحولیاتی نظام ہے۔ طاقتور اور اپنی مرضی کے مطابق بڑے زبان کے ماڈل جو چلتے ہیں۔ مقامی طور پر صارفین کے گریڈ CPUs پر۔
ہمارا GPT4All ماڈل ایک 4GB فائل ہے جسے آپ GPT4All اوپن سورس ایکو سسٹم سافٹ ویئر میں ڈاؤن لوڈ اور پلگ ان کر سکتے ہیں۔ Nomic AI اعلیٰ معیار اور محفوظ سافٹ ویئر ایکو سسٹم کی سہولت فراہم کرتا ہے، جو افراد اور تنظیموں کو مقامی طور پر اپنی بڑی زبان کے ماڈلز کو آسانی سے تربیت دینے اور لاگو کرنے کے قابل بنانے کی کوشش کو آگے بڑھاتا ہے۔
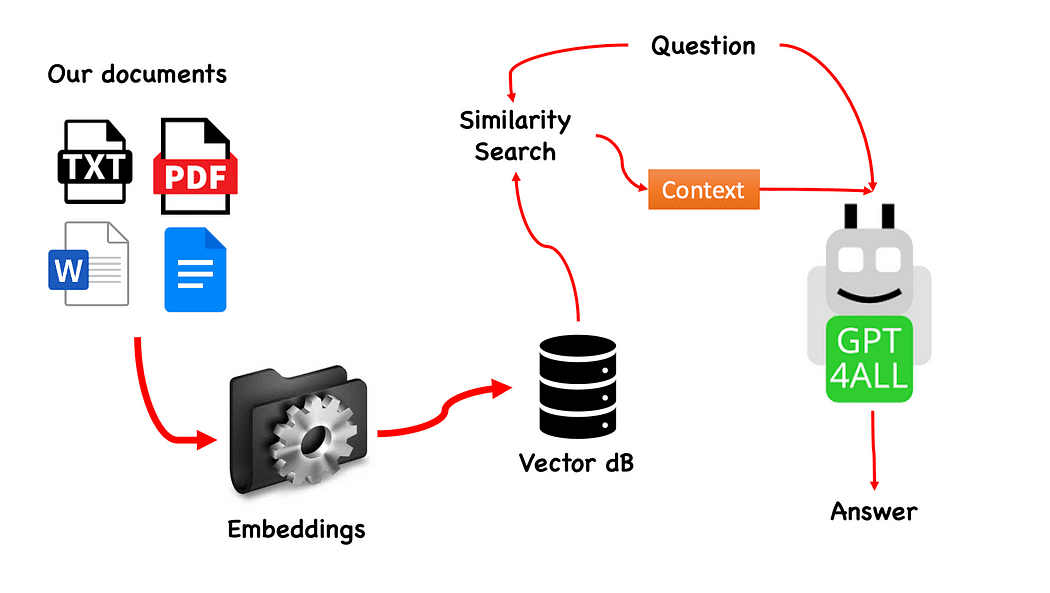
GPT4All کے ساتھ QnA کا ورک فلو — مصنف کا تخلیق کردہ
یہ عمل واقعی آسان ہے (جب آپ اسے جانتے ہیں) اور دوسرے ماڈلز کے ساتھ بھی دہرایا جا سکتا ہے۔ اقدامات درج ذیل ہیں:
- GPT4All ماڈل لوڈ کریں۔
- استعمال کی شرائط لینگچین ہمارے دستاویزات کو بازیافت کرنے اور انہیں لوڈ کرنے کے لیے
- Embeddings کے ذریعے ہضم ہونے والے چھوٹے ٹکڑوں میں دستاویزات کو تقسیم کریں۔
- ایمبیڈنگز کے ساتھ ہمارا ویکٹر ڈیٹا بیس بنانے کے لیے FAISS کا استعمال کریں۔
- ہمارے ویکٹر ڈیٹا بیس پر اس سوال کی بنیاد پر مماثلت کی تلاش (Semantic search) انجام دیں جسے ہم GPT4All کو دینا چاہتے ہیں: اسے بطور استعمال کیا جائے گا۔ سیاق و سباق ہمارے سوال کے لیے
- سوال اور سیاق و سباق کو GPT4All کے ساتھ فیڈ کریں۔ لینگچین اور جواب کا انتظار کریں.
تو ہمیں ایمبیڈنگز کی ضرورت ہے۔ ایمبیڈنگ معلومات کے ایک ٹکڑے کی عددی نمائندگی ہے، مثال کے طور پر، متن، دستاویزات، تصاویر، آڈیو، وغیرہ۔ نمائندگی اس کے معنی کے معنی کو پکڑتی ہے جو سرایت کی جا رہی ہے، اور یہ بالکل وہی ہے جس کی ہمیں ضرورت ہے۔ اس پروجیکٹ کے لیے ہم بھاری GPU ماڈلز پر بھروسہ نہیں کر سکتے: اس لیے ہم Alpaca کا مقامی ماڈل ڈاؤن لوڈ کریں گے اور اس سے استعمال کریں گے۔ لینگچین la LlamaCppEmbeddings. فکر نہ کرو! قدم بہ قدم ہر چیز کی وضاحت کی گئی ہے۔
ایک ورچوئل ماحول بنائیں
اپنے نئے Python پروجیکٹ کے لیے ایک نیا فولڈر بنائیں، مثال کے طور پر GPT4ALL_Fabio (اپنا نام رکھیں…):
mkdir GPT4ALL_Fabio
cd GPT4ALL_Fabioاگلا، ایک نیا ازگر ورچوئل ماحول بنائیں۔ اگر آپ کے پاس ایک سے زیادہ ازگر کے ورژن انسٹال ہیں، تو اپنا مطلوبہ ورژن بتائیں: اس صورت میں میں اپنی مین انسٹالیشن کا استعمال کروں گا، جو python 3.10 سے وابستہ ہے۔
python3 -m venv .venvکمانڈر python3 -m venv .venv نام کا ایک نیا ورچوئل ماحول بناتا ہے۔ .venv (ڈاٹ venv نامی ایک پوشیدہ ڈائریکٹری بنائے گا)۔
ایک ورچوئل ماحول ایک الگ تھلگ ازگر کی تنصیب فراہم کرتا ہے، جو آپ کو سسٹم بھر میں پائیتھون کی تنصیب یا دیگر منصوبوں کو متاثر کیے بغیر صرف ایک مخصوص پروجیکٹ کے لیے پیکجز اور انحصار کو انسٹال کرنے کی اجازت دیتا ہے۔ یہ تنہائی مستقل مزاجی کو برقرار رکھنے اور مختلف پروجیکٹ کی ضروریات کے درمیان ممکنہ تنازعات کو روکنے میں مدد کرتی ہے۔
ایک بار ورچوئل ماحول بن جانے کے بعد، آپ اسے درج ذیل کمانڈ کا استعمال کرکے چالو کرسکتے ہیں۔
source .venv/bin/activate 
چالو مجازی ماحول
انسٹال کرنے کے لیے لائبریریاں
ہم جو پروجیکٹ بنا رہے ہیں اس کے لیے ہمیں زیادہ پیکجز کی ضرورت نہیں ہے۔ ہمیں صرف ضرورت ہے:
- python bindings for GPT4All
- ہمارے دستاویزات کے ساتھ تعامل کرنے کے لیے Langchain
LangChain زبان کے ماڈلز سے چلنے والی ایپلیکیشنز تیار کرنے کا ایک فریم ورک ہے۔ یہ آپ کو نہ صرف ایک API کے ذریعے زبان کے ماڈل کو کال کرنے کی اجازت دیتا ہے، بلکہ زبان کے ماڈل کو ڈیٹا کے دوسرے ذرائع سے جوڑنے اور زبان کے ماڈل کو اس کے ماحول کے ساتھ تعامل کرنے کی اجازت دیتا ہے۔
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4LangChain کے لیے آپ دیکھتے ہیں کہ ہم نے ورژن کی بھی وضاحت کی ہے۔ اس لائبریری کو حال ہی میں بہت ساری اپ ڈیٹس موصول ہو رہی ہیں، اس لیے اس بات کا یقین کرنے کے لیے کہ ہمارا سیٹ اپ کل بھی کام کر رہا ہے، بہتر ہے کہ ہم کسی ایسے ورژن کی وضاحت کریں جو ہم جانتے ہیں کہ ٹھیک کام کر رہا ہے۔ پی ڈی ایف لوڈر اور کے لیے غیر ساختہ ایک مطلوبہ انحصار ہے۔ pytesseract اور پی ڈی ایف 2 امیج ساتھ ہی.
نوٹس: GitHub ریپوزٹری پر ایک requirements.txt فائل موجود ہے (جس کی طرف سے تجویز کردہ jl adcr) اس پروجیکٹ سے وابستہ تمام ورژن کے ساتھ۔ آپ مندرجہ ذیل کمانڈ کے ساتھ مین پروجیکٹ فائل ڈائرکٹری میں ڈاؤن لوڈ کرنے کے بعد ایک شاٹ میں انسٹالیشن کر سکتے ہیں۔
pip install -r requirements.txtمضمون کے آخر میں میں نے ایک تخلیق کیا۔ خرابیوں کا سراغ لگانے کے لیے سیکشن. GitHub ریپو میں ان تمام معلومات کے ساتھ ایک اپ ڈیٹ شدہ READ.ME بھی ہے۔
ذہن میں رکھو کہ کچھ لائبریریوں کے پاس python ورژن کے لحاظ سے ورژن دستیاب ہیں۔ آپ اپنے ورچوئل ماحول پر چل رہے ہیں۔
اپنے پی سی پر ماڈلز ڈاؤن لوڈ کریں۔
یہ واقعی ایک اہم قدم ہے۔
پروجیکٹ کے لیے ہمیں یقینی طور پر GPT4All کی ضرورت ہے۔ Nomic AI پر بیان کردہ عمل واقعی پیچیدہ ہے اور اس کے لیے ہارڈ ویئر کی ضرورت ہوتی ہے جو ہم سب کے پاس نہیں ہوتا (میری طرح)۔ تو یہاں ماڈل کا لنک ہے پہلے ہی تبدیل اور استعمال کے لیے تیار ہے۔ بس ڈاؤن لوڈ پر کلک کریں۔
GPT4All ماڈل ڈاؤن لوڈ کریں۔
جیسا کہ تعارف میں مختصراً بیان کیا گیا ہے کہ ہمیں ایمبیڈنگز کے لیے ماڈل کی بھی ضرورت ہے، ایسا ماڈل جسے ہم اپنے CPU پر بغیر کچلائے چلا سکتے ہیں۔ پر کلک کریں۔ alpaca-native-7B-ggml ڈاؤن لوڈ کرنے کے لیے یہاں لنک کریں۔ پہلے ہی 4 بٹ میں تبدیل ہو چکا ہے اور ایمبیڈنگ کے لیے ہمارے ماڈل کے طور پر کام کرنے کے لیے استعمال کے لیے تیار ہے۔

آگے ڈاؤن لوڈ کے تیر پر کلک کریں۔ ggml-model-q4_0.bin
ہمیں ایمبیڈنگز کی ضرورت کیوں ہے؟ اگر آپ کو فلو ڈایاگرام سے یاد ہے کہ ہمارے علم کی بنیاد کے لیے دستاویزات جمع کرنے کے بعد پہلا قدم درکار ہے، یمبیڈ انہیں اس الپاکا ماڈل کی LLamaCPP ایمبیڈنگز کام میں بالکل فٹ بیٹھتی ہیں اور یہ ماڈل بھی کافی چھوٹا ہے (4 جی بی)۔ ویسے آپ اپنے QnA کے لیے الپاکا ماڈل بھی استعمال کر سکتے ہیں!
اپ ڈیٹ 2023.05.25: مانی ونڈوز کے صارفین کو لاما سی پی پی ایمبیڈنگز استعمال کرنے میں مشکلات کا سامنا ہے۔ یہ بنیادی طور پر اس لیے ہوتا ہے کیونکہ python پیکیج llama-cpp-python کی تنصیب کے دوران:
pip install llama-cpp-pythonپائپ پیکیج سورس لائبریری سے مرتب کرنے جا رہا ہے۔ ونڈوز میں عام طور پر مشین پر ڈیفالٹ کے طور پر CMake یا C کمپائلر انسٹال نہیں ہوتا ہے۔ لیکن پریشان نہ ہوں اس کا ایک حل ہے۔
llama-cpp-python کی انسٹالیشن کو چلانا، جو LangChain کو llamaEmbeddings کے ساتھ درکار ہے، ونڈوز پر CMake C کمپلیئر ڈیفالٹ انسٹال نہیں ہے، اس لیے آپ سورس سے نہیں بنا سکتے۔
Xtools والے میک صارفین اور لینکس پر، عام طور پر OS پر C complier پہلے سے ہی دستیاب ہوتا ہے۔
مسئلے سے بچنے کے لیے آپ کو پہلے سے تعمیل شدہ وہیل استعمال کرنا چاہیے۔.
یہاں جاو https://github.com/abetlen/llama-cpp-python/releases
اور اپنے فن تعمیر اور ازگر کے ورژن کے لیے تعمیل شدہ وہیل تلاش کریں — آپ کو ویلز ورژن 0.1.49 لینا چاہیے۔ کیونکہ اعلی ورژن مطابقت نہیں رکھتے ہیں۔
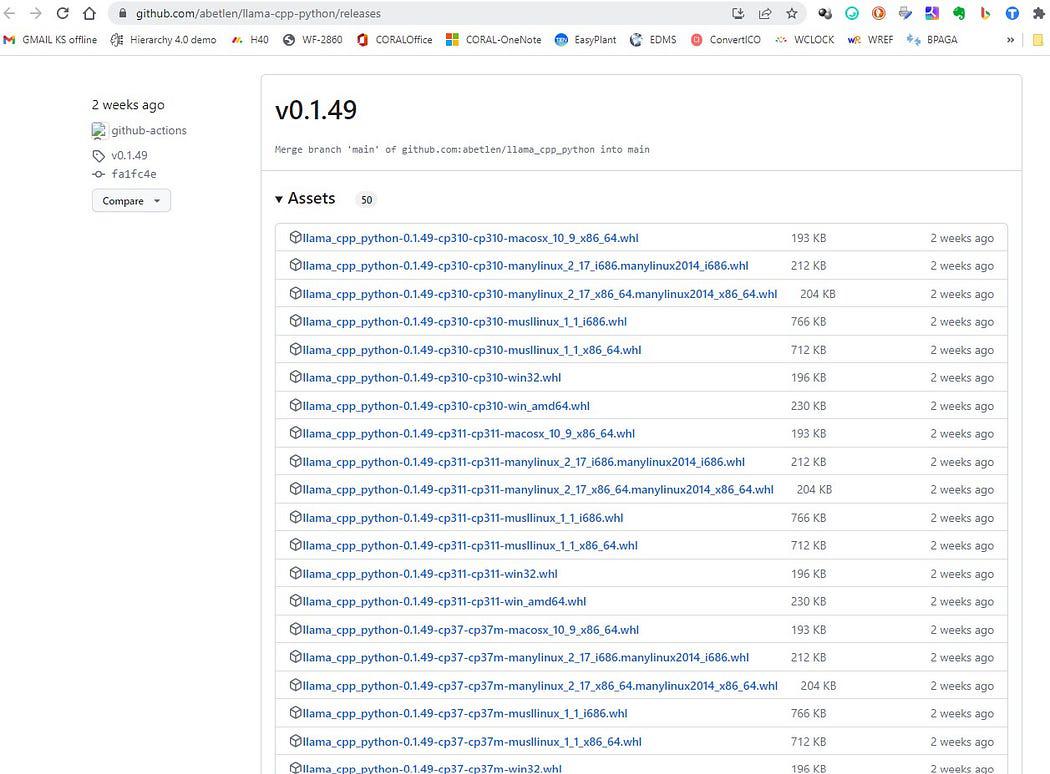
اسکرین شاٹ سے https://github.com/abetlen/llama-cpp-python/releases
میرے معاملے میں میرے پاس ونڈوز 10، 64 بٹ، ازگر 3.10 ہے۔
تو میری فائل ہے llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
یہ مسئلہ GitHub ذخیرہ پر ٹریک کیا جاتا ہے
ڈاؤن لوڈ کرنے کے بعد آپ کو دونوں ماڈلز کو ماڈلز ڈائرکٹری میں ڈالنے کی ضرورت ہے، جیسا کہ نیچے دکھایا گیا ہے۔

ڈائرکٹری کا ڈھانچہ اور ماڈل فائلوں کو کہاں رکھنا ہے۔
چونکہ ہم اپنے تعامل کو GPT ماڈل پر کنٹرول کرنا چاہتے ہیں، ہمیں ایک python فائل بنانا ہوگی (آئیے اسے کال کریں pygpt4all_test.py)، انحصار درآمد کریں اور ماڈل کو ہدایات دیں۔ آپ دیکھیں گے کہ یہ کافی آسان ہے۔
from pygpt4all.models.gpt4all import GPT4Allیہ ہمارے ماڈل کے لیے ازگر کا پابند ہے۔ اب ہم اسے کال کر کے پوچھنا شروع کر سکتے ہیں۔ آئیے ایک تخلیقی کوشش کریں۔
ہم ایک فنکشن بناتے ہیں جو ماڈل سے کال بیک پڑھتا ہے، اور ہم GPT4All سے اپنا جملہ مکمل کرنے کو کہتے ہیں۔
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)پہلا بیان ہمارے پروگرام کو بتا رہا ہے کہ ماڈل کہاں تلاش کرنا ہے (یاد رکھیں کہ ہم نے اوپر والے حصے میں کیا کیا)
دوسرا بیان ماڈل سے جواب پیدا کرنے اور ہمارے پرامپٹ کو مکمل کرنے کے لیے کہہ رہا ہے "ایک بار،"۔
اسے چلانے کے لیے، یقینی بنائیں کہ ورچوئل ماحول ابھی بھی فعال ہے اور بس چلائیں:
python3 pygpt4all_test.pyآپ کو ماڈل کا لوڈنگ ٹیکسٹ اور جملے کی تکمیل دیکھنا چاہیے۔ آپ کے ہارڈویئر وسائل پر منحصر ہے اس میں تھوڑا وقت لگ سکتا ہے۔
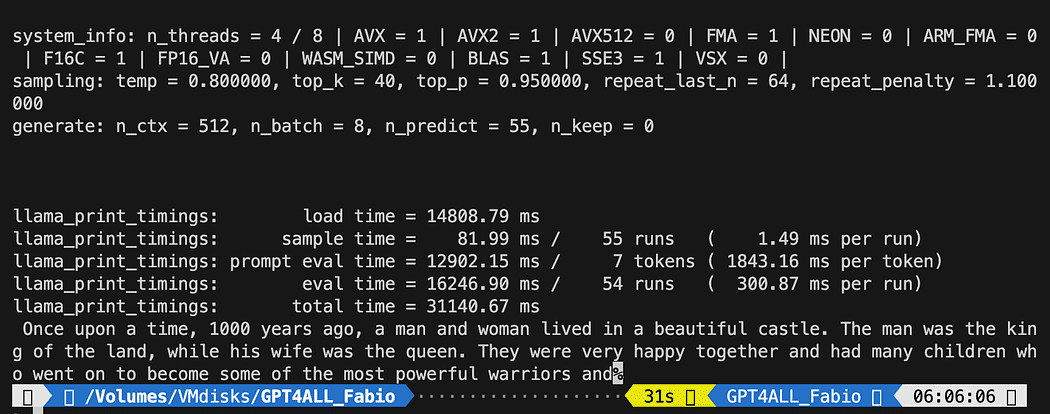
نتیجہ آپ سے مختلف ہو سکتا ہے… لیکن ہمارے لیے اہم یہ ہے کہ یہ کام کر رہا ہے اور ہم کچھ جدید چیزیں بنانے کے لیے LangChain کے ساتھ آگے بڑھ سکتے ہیں۔
نوٹ (2023.05.23 کو اپ ڈیٹ کیا گیا): اگر آپ کو pygpt4all سے متعلق کسی خرابی کا سامنا ہے تو، اس موضوع پر ٹربل شوٹنگ سیکشن کی طرف سے دیئے گئے حل کے ساتھ چیک کریں۔ رجنیش اگروال or آسکر جیونگ کے ذریعہ۔
LangChain فریم ورک واقعی ایک حیرت انگیز لائبریری ہے۔ یہ دیتا یے اجزاء زبان کے ماڈلز کے ساتھ استعمال میں آسان طریقے سے کام کرنا، اور یہ بھی فراہم کرتا ہے۔ زنجیروں. زنجیروں کے بارے میں سوچا جا سکتا ہے کہ ان اجزاء کو خاص طریقوں سے جمع کیا جائے تاکہ کسی خاص استعمال کے معاملے کو بہترین طریقے سے پورا کیا جا سکے۔ ان کا مقصد ایک اعلیٰ سطح کا انٹرفیس ہے جس کے ذریعے لوگ آسانی سے استعمال کے مخصوص کیس کے ساتھ شروعات کر سکتے ہیں۔ یہ زنجیروں کو حسب ضرورت بنانے کے لیے بھی ڈیزائن کیا گیا ہے۔
ہمارے اگلے ازگر ٹیسٹ میں ہم استعمال کریں گے a پرامپٹ ٹیمپلیٹ. زبان کے ماڈل متن کو بطور ان پٹ لیتے ہیں - اس متن کو عام طور پر ایک پرامپٹ کہا جاتا ہے۔ عام طور پر یہ صرف ایک ہارڈ کوڈڈ سٹرنگ نہیں ہے بلکہ ایک ٹیمپلیٹ، کچھ مثالوں اور صارف کے ان پٹ کا مجموعہ ہے۔ LangChain پرامپٹس کے ساتھ تعمیر اور کام کو آسان بنانے کے لیے کئی کلاسز اور فنکشنز فراہم کرتا ہے۔ آئیے دیکھتے ہیں کہ ہم بھی یہ کیسے کر سکتے ہیں۔
ایک نئی python فائل بنائیں اور اسے کال کریں۔ my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])ہم نے اپنے GPT ماڈل کے ساتھ براہ راست تعامل کرنے کے قابل ہونے کے لیے LangChain the Prompt Template and Chain اور GPT4All llm کلاس سے درآمد کیا۔
پھر، اپنا LLM راستہ طے کرنے کے بعد (جیسا کہ ہم نے پہلے کیا تھا) ہم کال بیک مینیجرز کو انسٹیٹیوٹ کرتے ہیں تاکہ ہم اپنے استفسار کے جوابات حاصل کر سکیں۔
ٹیمپلیٹ بنانا واقعی آسان ہے: مندرجہ ذیل دستاویزات ٹیوٹوریل ہم اس طرح کچھ استعمال کر سکتے ہیں…
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])۔ سانچے متغیر ایک ملٹی لائن سٹرنگ ہے جو ماڈل کے ساتھ ہماری تعامل کی ساخت پر مشتمل ہے: گھوبگھرالی منحنی خطوط وحدانی میں ہم ٹیمپلیٹ میں بیرونی متغیرات داخل کرتے ہیں، ہمارے منظر نامے میں ہمارا سوال.
چونکہ یہ ایک متغیر ہے آپ فیصلہ کر سکتے ہیں کہ آیا یہ ہارڈ کوڈ والا سوال ہے یا صارف کا ان پٹ سوال: یہاں دو مثالیں ہیں۔
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")اپنے ٹیسٹ رن کے لیے ہم صارف کے ان پٹ ون پر تبصرہ کریں گے۔ اب ہمیں صرف اپنے سانچے، سوال اور زبان کے ماڈل کو ایک ساتھ جوڑنے کی ضرورت ہے۔
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)اس بات کی تصدیق کرنا یاد رکھیں کہ آپ کا ورچوئل ماحول ابھی بھی فعال ہے اور کمانڈ چلائیں:
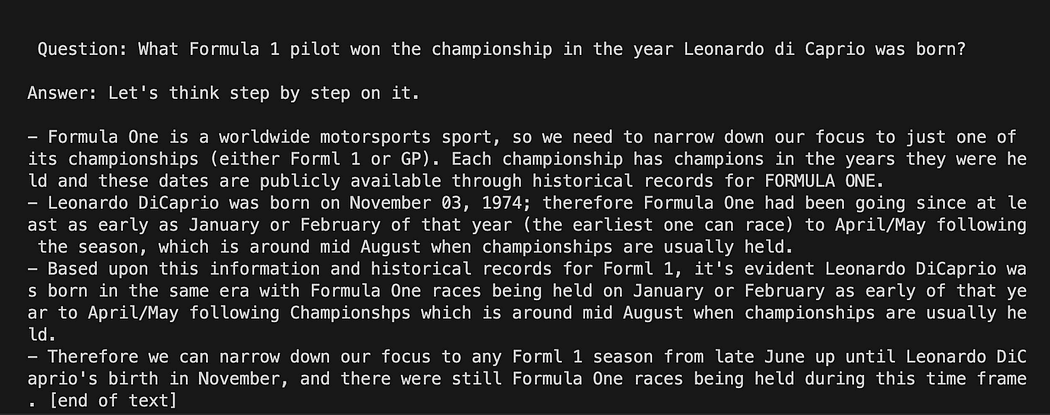
python3 my_langchain.pyآپ کو میری طرف سے مختلف نتائج مل سکتے ہیں۔ حیرت انگیز بات یہ ہے کہ آپ پوری استدلال دیکھ سکتے ہیں جس کے بعد GPT4All آپ کے لیے جواب حاصل کرنے کی کوشش کر رہا ہے۔ سوال کو ایڈجسٹ کرنے سے آپ کو بہتر نتائج بھی مل سکتے ہیں۔
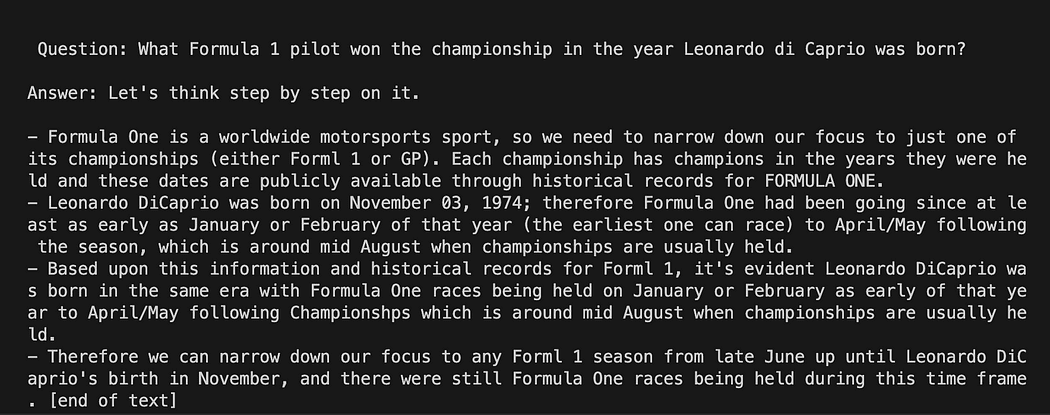
GPT4All پر پرامپٹ ٹیمپلیٹ کے ساتھ لینگچین
یہاں ہم حیرت انگیز حصہ شروع کرتے ہیں، کیونکہ ہم GPT4All کو ایک چیٹ بوٹ کے طور پر استعمال کرتے ہوئے اپنے دستاویزات سے بات کرنے جا رہے ہیں جو ہمارے سوالات کا جواب دیتا ہے۔
اقدامات کی ترتیب، حوالہ دیتے ہوئے GPT4All کے ساتھ QnA کا ورک فلو، ہماری پی ڈی ایف فائلوں کو لوڈ کرنا ہے، انہیں ٹکڑوں میں بنانا ہے۔ اس کے بعد ہمیں اپنے ایمبیڈنگ کے لیے ویکٹر اسٹور کی ضرورت ہوگی۔ معلومات کی بازیافت کے لیے ہمیں اپنے ٹکڑے شدہ دستاویزات کو ویکٹر اسٹور میں فیڈ کرنے کی ضرورت ہے اور پھر ہم انہیں اپنے LLM استفسار کے تناظر کے طور پر اس ڈیٹا بیس پر مماثلت کی تلاش کے ساتھ شامل کریں گے۔
اس مقصد کے لیے ہم براہ راست سے FAISS استعمال کرنے جا رہے ہیں۔ لینگچین کتب خانہ. FAISS فیس بک AI ریسرچ کی ایک اوپن سورس لائبریری ہے، جسے اعلیٰ جہتی ڈیٹا کے بڑے ذخیرے میں ملتے جلتے آئٹمز کو تیزی سے تلاش کرنے کے لیے ڈیزائن کیا گیا ہے۔ یہ ڈیٹاسیٹ میں سب سے ملتی جلتی اشیاء کو تلاش کرنا آسان اور تیز تر بنانے کے لیے اشاریہ سازی اور تلاش کے طریقے پیش کرتا ہے۔ یہ ہمارے لیے خاص طور پر آسان ہے کیونکہ یہ آسان بناتا ہے۔ معلومات کی بازیافت اور ہمیں مقامی طور پر بنائے گئے ڈیٹا بیس کو محفوظ کرنے کی اجازت دیتا ہے: اس کا مطلب ہے کہ پہلی تخلیق کے بعد اسے مزید استعمال کے لیے بہت تیزی سے لوڈ کیا جائے گا۔
ویکٹر انڈیکس ڈی بی کی تخلیق
ایک نئی فائل بنائیں اور اسے کال کریں۔ my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeپہلی لائبریریاں وہی ہیں جو ہم پہلے استعمال کرتے تھے: اس کے علاوہ ہم استعمال کر رہے ہیں۔ لینگچین ویکٹر اسٹور انڈیکس بنانے کے لیے، LlamaCppEmbeddings ہمارے الپاکا ماڈل کے ساتھ تعامل کرنے کے لیے (4 بٹ کوانٹائزڈ اور سی پی پی لائبریری کے ساتھ مرتب کیا گیا) اور پی ڈی ایف لوڈر۔
آئیے اپنے LLMs کو بھی ان کے اپنے راستوں کے ساتھ لوڈ کریں: ایک ایمبیڈنگز کے لیے اور دوسرا ٹیکسٹ جنریشن کے لیے۔
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)ٹیسٹ کے لیے آئیے دیکھتے ہیں کہ کیا ہم تمام pfd فائلوں کو پڑھنے میں کامیاب ہو گئے ہیں: پہلا قدم یہ ہے کہ ہر ایک دستاویز پر استعمال کیے جانے والے 3 فنکشنز کا اعلان کریں۔ پہلا ہے نکالے گئے متن کو ٹکڑوں میں تقسیم کرنا، دوسرا میٹا ڈیٹا (جیسے صفحہ نمبر وغیرہ…) کے ساتھ ویکٹر انڈیکس بنانا ہے اور آخری مماثلت کی تلاش کی جانچ کے لیے ہے (میں بعد میں بہتر وضاحت کروں گا)۔
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesاب ہم دستاویزات کے لیے انڈیکس جنریشن کی جانچ کر سکتے ہیں۔ دستاویزات ڈائریکٹری: ہمیں وہاں اپنے تمام پی ڈی ایف ڈالنے کی ضرورت ہے۔ لینگچین فائل کی قسم سے قطع نظر پورے فولڈر کو لوڈ کرنے کا ایک طریقہ بھی ہے: چونکہ یہ پوسٹ کا عمل پیچیدہ ہے، اس لیے میں LaMini ماڈلز کے بارے میں اگلے مضمون میں اس کا احاطہ کروں گا۔

میری دستاویزات کی ڈائرکٹری میں 4 پی ڈی ایف فائلیں ہیں۔
ہم فہرست میں پہلی دستاویز پر اپنے افعال کا اطلاق کریں گے۔
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)پہلی لائنوں میں ہم حاصل کرنے کے لیے OS لائبریری کا استعمال کرتے ہیں۔ پی ڈی ایف فائلوں کی فہرست دستاویزات کی ڈائرکٹری کے اندر۔ پھر ہم پہلی دستاویز لوڈ کرتے ہیں (doc_list[0]) کے ساتھ دستاویزات کے فولڈر سے لینگچین، ٹکڑوں میں تقسیم کریں اور پھر ہم اس کے ساتھ ویکٹر ڈیٹا بیس بناتے ہیں۔ کال کریں۔ سرایت
جیسا کہ آپ نے دیکھا کہ ہم استعمال کر رہے ہیں۔ pyPDF طریقہ. یہ استعمال کرنے میں تھوڑا سا لمبا ہے، کیونکہ آپ کو ایک ایک کرکے فائلیں لوڈ کرنی پڑتی ہیں، لیکن پی ڈی ایف لوڈ کرنا pypdf دستاویزات کی صف میں آپ کو ایک صف رکھنے کی اجازت دیتا ہے جہاں ہر دستاویز میں صفحہ کا مواد اور میٹا ڈیٹا ہوتا ہے page نمبر یہ واقعی آسان ہے جب آپ سیاق و سباق کے ذرائع جاننا چاہتے ہیں جو ہم اپنے استفسار کے ساتھ GPT4All کو دیں گے۔ یہاں readthedocs کی مثال ہے:
اسکرین شاٹ سے لینگچین دستاویزات
ہم ٹرمینل سے کمانڈ کے ساتھ python فائل چلا سکتے ہیں:
python3 my_knowledge_qna.pyایمبیڈنگز کے لیے ماڈل کی لوڈنگ کے بعد آپ کو انڈیکسنگ کے لیے کام پر ٹوکن نظر آئیں گے: گھبرائیں نہیں کیونکہ اس میں وقت لگے گا، خاص طور پر اگر آپ صرف CPU پر چلتے ہیں، میری طرح (اس میں 8 منٹ لگے)۔
پہلے ویکٹر ڈی بی کی تکمیل
جیسا کہ میں وضاحت کر رہا تھا کہ pyPDF طریقہ سست ہے لیکن ہمیں مماثلت کی تلاش کے لیے اضافی ڈیٹا فراہم کرتا ہے۔ اپنی تمام فائلوں میں اعادہ کرنے کے لیے ہم FAISS سے ایک آسان طریقہ استعمال کریں گے جو ہمیں مختلف ڈیٹا بیس کو ایک ساتھ ضم کرنے کی اجازت دیتا ہے۔ اب ہم کیا کرتے ہیں کہ ہم اوپر والے کوڈ کو پہلا ڈی بی بنانے کے لیے استعمال کرتے ہیں (ہم اسے کال کریں گے۔ db0) اور a for لوپ کے ساتھ ہم فہرست میں اگلی فائل کا انڈیکس بناتے ہیں اور اسے فوری طور پر ضم کر دیتے ہیں۔ db0.
یہ کوڈ ہے: نوٹ کریں کہ میں نے آپ کو استعمال کی پیشرفت کی حیثیت دینے کے لیے کچھ لاگز شامل کیے ہیں۔ datetime.datetime.now() اور اختتامی وقت اور آغاز کے وقت کے ڈیلٹا کو پرنٹ کرنا یہ حساب کرنے کے لیے کہ آپریشن میں کتنا وقت لگا (اگر آپ کو یہ پسند نہیں ہے تو آپ اسے ہٹا سکتے ہیں)۔
انضمام کی ہدایات اس طرح ہیں۔
# merge dbi with the existing db0
db0.merge_from(dbi)آخری ہدایات میں سے ایک ہمارے ڈیٹا بیس کو مقامی طور پر محفوظ کرنے کے لیے ہے: پوری نسل کو گھنٹے بھی لگ سکتے ہیں (اس بات پر منحصر ہے کہ آپ کے پاس کتنے دستاویزات ہیں) لہذا یہ واقعی اچھا ہے کہ ہمیں اسے صرف ایک بار کرنا پڑے گا!
# Save the databasae locally
db0.save_local("my_faiss_index")یہاں پورا کوڈ ہے۔ جب ہم اپنے فولڈر سے براہ راست انڈیکس لوڈ کرنے والے GPT4All کے ساتھ تعامل کریں گے تو ہم اس کے بہت سے حصے پر تبصرہ کریں گے۔
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  python فائل کو چلانے میں 22 منٹ لگے
python فائل کو چلانے میں 22 منٹ لگے
اپنے دستاویزات پر GPT4All سے سوالات پوچھیں۔
اب ہم یہاں ہیں۔ ہمارے پاس ہمارا انڈیکس ہے، ہم اسے لوڈ کر سکتے ہیں اور ایک پرامپٹ ٹیمپلیٹ کے ساتھ ہم اپنے سوالات کے جوابات کے لیے GPT4All سے پوچھ سکتے ہیں۔ ہم ایک مشکل کوڈ والے سوال کے ساتھ شروع کرتے ہیں اور پھر ہم اپنے ان پٹ سوالات کو لوپ کریں گے۔
درج ذیل کوڈ کو ازگر کی فائل کے اندر رکھیں db_loading.py اور اسے ٹرمینل سے کمانڈ کے ساتھ چلائیں۔ python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])طباعت شدہ متن 3 ذرائع کی فہرست ہے جو استفسار کے ساتھ بہترین میل کھاتا ہے، ہمیں دستاویز کا نام اور صفحہ نمبر بھی دیتا ہے۔
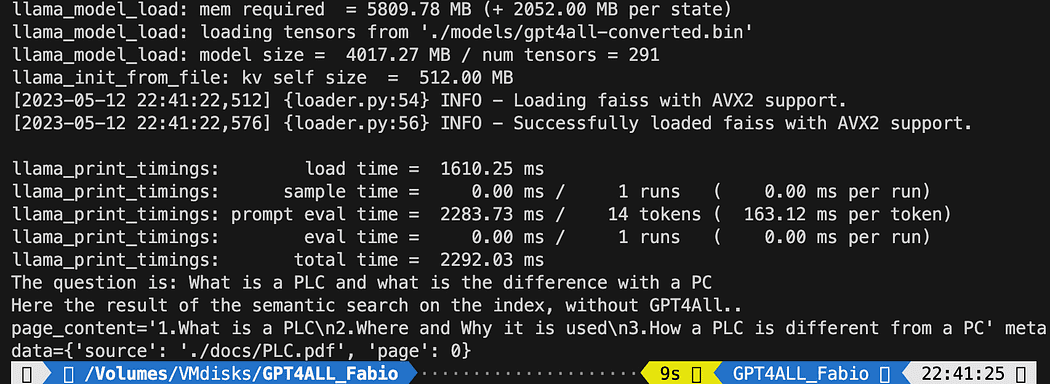
فائل کو چلانے والی سیمنٹک تلاش کے نتائج db_loading.py
اب ہم پرامپٹ ٹیمپلیٹ کا استعمال کرتے ہوئے مماثلت کی تلاش کو اپنی استفسار کے سیاق و سباق کے طور پر استعمال کر سکتے ہیں۔ 3 فنکشنز کے بعد تمام کوڈ کو درج ذیل سے بدل دیں:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))دوڑنے کے بعد آپ کو اس طرح کا نتیجہ ملے گا (لیکن مختلف ہوسکتا ہے)۔ حیرت انگیز نہیں!؟!؟
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.اگر آپ چاہتے ہیں کہ صارف کا ان پٹ سوال لائن کو تبدیل کرے۔
question = "What is a PLC and what is the difference with a PC"کچھ اس طرح کے ساتھ:
question = input("Your question: ")یہ آپ کے لئے تجربہ کرنے کا وقت ہے. اپنے دستاویزات سے متعلق تمام موضوعات پر مختلف سوالات پوچھیں، اور نتائج دیکھیں۔ بہتری کی ایک بڑی گنجائش ہے، یقینی طور پر فوری اور ٹیمپلیٹ پر: آپ دیکھ سکتے ہیں۔ یہاں کچھ پریرتا کے لئے. لیکن لینگچین دستاویزات واقعی حیرت انگیز ہے (میں اس کی پیروی کرسکتا ہوں !!)۔
آپ مضمون سے کوڈ کی پیروی کر سکتے ہیں یا اسے چیک کر سکتے ہیں۔ میرا گیتوب ریپو.
فیبیو میٹریکارڈی ایک معلم، استاد، انجینئر اور سیکھنے کا شوقین۔ وہ 15 سالوں سے نوجوان طلباء کو پڑھا رہا ہے، اور اب وہ Key Solution Srl میں نئے ملازمین کو تربیت دیتا ہے۔ اس نے 2010 میں انڈسٹریل آٹومیشن انجینئر کے طور پر میرے کیریئر کا آغاز کیا۔ وہ نوعمری سے ہی پروگرامنگ کے بارے میں پرجوش تھے، اس نے کچھ جاندار بنانے کے لیے سافٹ ویئر اور ہیومن مشین انٹرفیس بنانے کی خوبصورتی کو دریافت کیا۔ تدریس اور کوچنگ میرے روزمرہ کے معمولات کا حصہ ہے، نیز یہ سیکھنا اور سیکھنا کہ کس طرح جدید ترین انتظامی مہارتوں کے ساتھ ایک پرجوش لیڈر بننا ہے۔ پورے انجینئرنگ لائف سائیکل میں مشین لرننگ اور مصنوعی ذہانت کا استعمال کرتے ہوئے ایک بہتر ڈیزائن، پیش گوئی کرنے والے نظام کے انضمام کی طرف سفر میں میرے ساتھ شامل ہوں۔
حقیقی. اجازت کے ساتھ دوبارہ پوسٹ کیا۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- ای وی ایم فنانس۔ وکندریقرت مالیات کے لیے متحد انٹرفیس۔ یہاں تک رسائی حاصل کریں۔
- کوانٹم میڈیا گروپ۔ آئی آر/پی آر ایمپلیفائیڈ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 ڈیٹا انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 15 سال
- 15٪
- 16
- 2023
- 22
- 23
- 25
- 420
- 7
- 8
- 9
- a
- کی صلاحیت
- قابلیت
- ہمارے بارے میں
- اوپر
- پورا
- ایکٹ
- چالو
- شامل کیا
- اس کے علاوہ
- ایڈیشنل
- اعلی درجے کی
- کو متاثر
- کے بعد
- AI
- عی تحقیق
- تمام
- کی اجازت
- کی اجازت دیتا ہے
- پہلے ہی
- بھی
- am
- حیرت انگیز
- an
- تجزیہ
- اور
- جواب
- کوئی بھی
- اے پی آئی
- ایپلی کیشنز
- کا اطلاق کریں
- فن تعمیر
- کیا
- لڑی
- مضمون
- مضامین
- مصنوعی
- مصنوعی ذہانت
- AS
- منسلک
- At
- آڈیو
- آٹومیٹڈ
- خود کار طریقے سے
- میشن
- دستیاب
- سے اجتناب
- بیس
- کی بنیاد پر
- BE
- خوبصورتی
- کیونکہ
- رہا
- اس سے پہلے
- کیا جا رہا ہے
- نیچے
- BEST
- بہتر
- کے درمیان
- سے پرے
- بگ
- بن
- بائنڈنگ
- بٹ
- پیدا
- مختصر
- لانے
- تعمیر
- عمارت
- تعمیر میں
- بسیں
- لیکن
- by
- حساب
- فون
- کہا جاتا ہے
- کالز
- کر سکتے ہیں
- نہیں کر سکتے ہیں
- اہلیت
- قبضہ
- کیریئر کے
- لے جانے کے
- کیس
- پکڑو
- CD
- کچھ
- یقینی طور پر
- چین
- زنجیروں
- چیمپئن شپ
- چیٹ بٹ
- چیٹ جی پی ٹی
- چیک کریں
- کیمیائی
- طبقے
- کلاس
- کلک کریں
- کوچنگ
- کوڈ
- کوڈ
- جمع
- مجموعہ
- مجموعے
- مجموعہ
- تبصرہ
- عام طور پر
- ابلاغ
- مواصلات
- ہم آہنگ
- مکمل
- مکمل
- تکمیل
- پیچیدہ
- پیچیدہ
- اجزاء
- کمپیوٹر
- کمپیوٹر
- رابطہ قائم کریں
- منسلک
- تعمیر
- صارفین
- پر مشتمل ہے
- مواد
- سیاق و سباق
- کنٹرول
- کنٹرولر
- کنٹرول
- آسان
- تبدیل
- سکتا ہے
- احاطہ
- CPU
- تخلیق
- بنائی
- پیدا
- تخلیق
- مخلوق
- تخلیقی
- اہم
- مرضی کے مطابق
- روزانہ
- اعداد و شمار
- ڈیٹا بیس
- ڈیٹا بیس
- تاریخ
- تاریخ کے وقت
- فیصلہ کرنا
- پہلے سے طے شدہ
- کی وضاحت
- ڈیلٹا
- انحصار
- منحصر ہے
- انحصار کرتا ہے
- تعیناتی
- بیان کیا
- ڈیزائن
- ڈیزائن
- مطلوبہ
- ترقی
- آلہ
- کے الات
- DID
- فرق
- مختلف
- ہضم
- ڈیجیٹل
- براہ راست
- دریافت
- دریافت
- do
- دستاویز
- دستاویزات
- دستاویزات
- کرتا
- نہیں
- کیا
- نہیں
- ڈاٹ
- ڈاؤن لوڈ، اتارنا
- ڈرائیونگ
- کے دوران
- ہر ایک
- آسان
- آسانی سے
- آسان
- ماحول
- ماحولیاتی نظام۔
- کوشش
- یمبیڈ
- ایمبیڈڈ
- سرایت کرنا
- ملازمین
- کو چالو کرنے کے
- آخر
- انجینئر
- انجنیئرنگ
- درج
- حوصلہ افزائی
- پوری
- ماحولیات
- خرابی
- خاص طور پر
- وغیرہ
- Ether (ETH)
- بھی
- سب کچھ
- بالکل
- مثال کے طور پر
- مثال کے طور پر
- پھانسی
- موجودہ
- تجربہ
- وضاحت
- وضاحت کی
- کی وضاحت
- بیرونی
- چہرہ
- فیس بک
- سہولت
- سامنا کرنا پڑا
- فاسٹ
- تیز تر
- فائل
- فائلوں
- مل
- آخر
- پہلا
- فٹ
- بہاؤ
- پر عمل کریں
- پیچھے پیچھے
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- فارم
- فارمیٹ
- فارمولا
- فارمولہ 1
- فریم ورک
- سے
- تقریب
- افعال
- مزید
- پیدا
- پیدا کرنے والے
- نسل
- حاصل
- GitHub کے
- دے دو
- دی
- فراہم کرتا ہے
- دے
- جا
- اچھا
- GPU
- گریڈ
- ہینڈلنگ
- ہوتا ہے
- ہارڈ
- ہارڈ ویئر
- ہے
- he
- بھاری
- مدد کرتا ہے
- یہاں
- پوشیدہ
- ہائی
- اعلی
- HOURS
- کس طرح
- کیسے
- HTML
- HTTP
- HTTPS
- انسانی
- i
- ICS
- if
- تصاویر
- فوری طور پر
- پر عملدرآمد
- درآمد
- اہم
- بہتری
- in
- شامل
- انڈکس
- انڈیکس
- افراد
- صنعتی
- صنعتی آٹومیشن
- صنعتوں
- معلومات
- ان پٹ
- ان پٹ آؤٹ پٹ
- آدانوں
- انسٹال
- تنصیب
- مثال کے طور پر
- ہدایات
- انضمام
- انٹیلی جنس
- ارادہ
- بات چیت
- بات چیت
- انٹرفیس
- انٹرفیسز
- انٹرنیٹ
- میں
- تعارف
- الگ الگ
- تنہائی
- IT
- اشیاء
- تکرار
- میں
- ایوب
- میں شامل
- سفر
- صرف
- KDnuggets
- کلیدی
- جان
- علم
- زبان
- بڑے
- آخری
- بعد
- رہنما
- سیکھنے
- سطح
- لائبریریوں
- لائبریری
- زندگی
- زندگی کا دورانیہ
- کی طرح
- لائنوں
- LINK
- لنکڈ
- لینکس
- لسٹ
- تھوڑا
- لوڈ
- بارک
- لوڈ کر رہا ہے
- مقامی
- مقامی طور پر
- منطق
- لانگ
- اب
- دیکھو
- بہت
- میک
- مشین
- مشین لرننگ
- مشینری
- مین
- بنیادی طور پر
- برقرار رکھنے کے
- بنا
- میں کامیاب
- انتظام
- مینیجر
- مینیجر
- مینوفیکچرنگ
- بہت سے
- مئی..
- مطلب
- کا مطلب ہے کہ
- یاد داشت
- ضم کریں
- ضم
- میٹا ڈیٹا
- طریقہ
- طریقوں
- برا
- منٹ
- ماڈل
- ماڈل
- زیادہ
- سب سے زیادہ
- ایک سے زیادہ
- ضروری
- my
- نام
- مقامی
- ضرورت ہے
- نیٹ ورک
- نئی
- اگلے
- اب
- تعداد
- تعداد
- اعتراض
- of
- تجویز
- on
- ایک بار
- ایک
- آن لائن
- صرف
- اوپن سورس
- آپریشن
- آپریشنز
- or
- حکم
- تنظیمیں
- OS
- دیگر
- ہمارے
- باہر
- پیداوار
- پر
- خود
- پیکج
- پیکجوں کے
- صفحہ
- متوازی
- حصہ
- خاص طور پر
- خاص طور پر
- منظور
- جذباتی
- راستہ
- PC
- لوگ
- انجام دینے کے
- اجازت
- ذاتی
- تصویر
- ٹکڑا
- پائلٹ
- پودوں
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- PLC
- مہربانی کرکے
- پلگ
- بندرگاہوں
- پوزیشن
- پوسٹ
- ممکنہ
- طاقت
- بجلی گھر
- طاقت
- طاقتور
- پری
- کی روک تھام
- پرنٹ
- پرنٹنگ
- مسائل
- عمل
- عملدرآمد
- عمل
- پروگرام
- پروگرام
- پروگرامنگ
- پیش رفت
- منصوبے
- منصوبوں
- پروٹوکول
- فراہم کرتا ہے
- مقاصد
- ڈال
- ازگر
- معیار
- سوال
- سوالات
- جلدی سے
- بلکہ
- پڑھیں
- تیار
- واقعی
- وصول کرنا
- حال ہی میں
- کہا جاتا ہے
- مراد
- بے شک
- رجسٹر
- متعلقہ
- وشوسنییتا
- انحصار کرو
- یاد
- ہٹا
- بار بار
- کی جگہ
- رپورٹ
- ذخیرہ
- نمائندگی
- ضرورت
- ضروریات
- کی ضرورت ہے
- تحقیق
- وسائل
- جواب
- جوابات
- نتیجہ
- نتائج کی نمائش
- واپسی
- کمرہ
- رن
- چل رہا ہے
- s
- سیفٹی
- اسی
- محفوظ کریں
- بچت
- منظر نامے
- تلاش کریں
- تلاش
- دوسری
- سیکشن
- محفوظ بنانے
- دیکھنا
- سینسر
- سزا
- تسلسل
- سیریل
- قائم کرنے
- سیٹ اپ
- کئی
- شاٹ
- ہونا چاہئے
- دکھایا گیا
- اسی طرح
- سادہ
- صرف
- بعد
- ایک
- مہارت
- چھوٹے
- So
- سافٹ ویئر کی
- حل
- کچھ
- کچھ
- ماخذ
- ذرائع
- خصوصی
- خاص طور پر
- مخصوص
- مخصوص
- تقسیم
- کمرشل
- شروع کریں
- شروع
- شروع
- بیان
- درجہ
- مرحلہ
- مراحل
- ابھی تک
- ذخیرہ
- سلک
- ساخت
- طلباء
- مطالعہ
- اس طرح
- کے نظام
- لے لو
- بات
- کاموں
- استاد
- پڑھانا
- نوجوان
- سانچے
- ٹرمنل
- ٹیسٹ
- آزمائشی تجربہ
- ٹیسٹنگ
- متن کی نسل
- سے
- کہ
- ۔
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- لگتا ہے کہ
- اس
- سوچا
- کے ذریعے
- بھر میں
- وقت
- کرنے کے لئے
- مل کر
- ٹوکن
- کل
- بھی
- لیا
- موضوع
- موضوعات
- کی طرف
- ٹرین
- کوشش
- دو
- قسم
- ٹھیٹھ
- عام طور پر
- اپ ڈیٹ
- تازہ ترین معلومات
- صلی اللہ علیہ وسلم
- us
- استعمال
- USB
- استعمال کی شرائط
- استعمال کیس
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- کا استعمال کرتے ہوئے
- عام طور پر
- استعمال کیا
- مختلف
- اس بات کی تصدیق
- ورژن
- بہت
- کی طرف سے
- مجازی
- W3
- انتظار
- چاہتے ہیں
- تھا
- راستہ..
- طریقوں
- we
- ویب سائٹ
- اچھا ہے
- کیا
- کیا ہے
- وہیل
- جب
- جس
- ڈبلیو
- کیوں
- بڑے پیمانے پر
- گے
- کھڑکیاں
- ونڈوز صارفین
- ساتھ
- کے اندر
- بغیر
- وون
- کام
- کام کر
- سال
- سال
- آپ
- نوجوان
- اور
- زیفیرنیٹ










