آج، ہم Llama 2 انفرنس اور فائن ٹیوننگ سپورٹ کی دستیابی کا اعلان کرتے ہوئے پرجوش ہیں۔ AWS ٹرینیم اور AWS Inferentia میں مثال کے طور پر ایمیزون سیج میکر جمپ اسٹارٹ. AWS Trainium اور Inferentia پر مبنی مثالوں کا استعمال، SageMaker کے ذریعے، صارفین کو فائن ٹیوننگ کی لاگت کو 50% تک، اور تعیناتی لاگت کو 4.7x تک کم کرنے میں مدد کر سکتا ہے، جبکہ فی ٹوکن لیٹنسی کو کم کر سکتا ہے۔ Llama 2 ایک آٹو ریگریسیو جنریٹیو ٹیکسٹ لینگویج ماڈل ہے جو ایک بہتر ٹرانسفارمر فن تعمیر کا استعمال کرتا ہے۔ عوامی طور پر دستیاب ماڈل کے طور پر، Llama 2 بہت سے NLP کاموں کے لیے ڈیزائن کیا گیا ہے جیسے کہ متن کی درجہ بندی، جذبات کا تجزیہ، زبان کا ترجمہ، زبان کی ماڈلنگ، ٹیکسٹ جنریشن، اور ڈائیلاگ سسٹم۔ Llama 2 کی طرح LLMs کو فائن ٹیوننگ اور تعینات کرنا مہنگا ہو سکتا ہے یا کسٹمر کا اچھا تجربہ فراہم کرنے کے لیے حقیقی وقت کی کارکردگی کو پورا کرنا مشکل ہو سکتا ہے۔ ٹرینیم اور AWS Inferentia، کی طرف سے فعال AWS نیوران سافٹ ویئر ڈویلپمنٹ کٹ (SDK)، Llama 2 ماڈلز کی تربیت اور اندازہ لگانے کے لیے ایک اعلیٰ کارکردگی، اور لاگت سے موثر آپشن پیش کرتا ہے۔
اس پوسٹ میں، ہم دکھاتے ہیں کہ سیج میکر جمپ اسٹارٹ میں ٹرینیئم اور AWS Inferentia مثالوں پر Llama 2 کو کیسے تعینات اور ٹھیک کیا جائے۔
حل جائزہ
اس بلاگ میں، ہم درج ذیل منظرناموں پر جائیں گے:
- دونوں میں AWS Inferentia مثالوں پر Llama 2 تعینات کریں۔ ایمیزون سیج میکر اسٹوڈیو UI، ایک کلک کی تعیناتی کے تجربے کے ساتھ، اور SageMaker Python SDK۔
- سیج میکر اسٹوڈیو UI اور SageMaker Python SDK دونوں میں ٹرینیم مثالوں پر لاما 2 کو ٹھیک بنائیں۔
- فائن ٹیوننگ لاما 2 ماڈل کی کارکردگی کا پہلے سے تربیت یافتہ ماڈل کے ساتھ موازنہ کریں تاکہ فائن ٹیوننگ کی تاثیر کو ظاہر کیا جا سکے۔
پر ہاتھ حاصل کرنے کے لئے، دیکھیں GitHub مثال کے طور پر نوٹ بک.
SageMaker Studio UI اور Python SDK کا استعمال کرتے ہوئے AWS Inferentia مثالوں پر Llama 2 کو تعینات کریں۔
اس سیکشن میں، ہم یہ ظاہر کرتے ہیں کہ Llama 2 کو AWS Inferentia مثالوں پر ایک کلک کی تعیناتی اور Python SDK کے لیے SageMaker Studio UI کا استعمال کرتے ہوئے کیسے تعینات کیا جائے۔
SageMaker Studio UI پر Llama 2 ماڈل دریافت کریں۔
SageMaker JumpStart عوامی طور پر دستیاب اور ملکیتی دونوں تک رسائی فراہم کرتا ہے۔ بنیاد ماڈل. فاؤنڈیشن ماڈلز تیسرے فریق اور ملکیتی فراہم کنندگان سے آن بورڈ اور برقرار رکھے جاتے ہیں۔ اس طرح، وہ مختلف لائسنسوں کے تحت جاری کیے جاتے ہیں جیسا کہ ماڈل ماخذ کے ذریعہ نامزد کیا گیا ہے۔ کسی بھی فاؤنڈیشن ماڈل کے لائسنس کا جائزہ لینا یقینی بنائیں جسے آپ استعمال کرتے ہیں۔ آپ کسی بھی قابل اطلاق لائسنس کی شرائط کا جائزہ لینے اور ان کی تعمیل کرنے اور اس بات کو یقینی بنانے کے ذمہ دار ہیں کہ وہ مواد کو ڈاؤن لوڈ کرنے یا استعمال کرنے سے پہلے آپ کے استعمال کے معاملے کے لیے قابل قبول ہیں۔
آپ SageMaker Studio UI اور SageMaker Python SDK میں SageMaker JumpStart کے ذریعے Llama 2 فاؤنڈیشن ماڈلز تک رسائی حاصل کر سکتے ہیں۔ اس سیکشن میں، ہم سیج میکر اسٹوڈیو میں ماڈلز کو دریافت کرنے کا طریقہ دیکھتے ہیں۔
سیج میکر اسٹوڈیو ایک مربوط ترقیاتی ماحول (IDE) ہے جو ایک واحد ویب پر مبنی بصری انٹرفیس فراہم کرتا ہے جہاں آپ تمام مشین لرننگ (ML) کے ترقیاتی مراحل کو انجام دینے کے لیے مقصد کے لیے بنائے گئے ٹولز تک رسائی حاصل کر سکتے ہیں، ڈیٹا کی تیاری سے لے کر اپنے ML کی تعمیر، تربیت اور تعیناتی تک۔ ماڈلز شروع کرنے اور SageMaker اسٹوڈیو کو ترتیب دینے کے طریقے کے بارے میں مزید تفصیلات کے لیے، رجوع کریں۔ ایمیزون سیج میکر اسٹوڈیو۔
SageMaker سٹوڈیو میں آنے کے بعد، آپ SageMaker JumpStart تک رسائی حاصل کر سکتے ہیں، جس میں پہلے سے تربیت یافتہ ماڈلز، نوٹ بکس اور پہلے سے تیار کردہ حل شامل ہیں۔ پہلے سے تعمیر شدہ اور خودکار حل. ملکیتی ماڈلز تک رسائی کے بارے میں مزید تفصیلی معلومات کے لیے، رجوع کریں۔ ایمیزون سیج میکر اسٹوڈیو میں ایمیزون سیج میکر جمپ اسٹارٹ کے ملکیتی فاؤنڈیشن ماڈل استعمال کریں۔.
سیج میکر جمپ اسٹارٹ لینڈنگ پیج سے، آپ حل، ماڈل، نوٹ بک اور دیگر وسائل کو براؤز کر سکتے ہیں۔
اگر آپ کو Llama 2 ماڈل نظر نہیں آتے ہیں، تو بند کرکے اور دوبارہ شروع کرکے اپنے SageMaker اسٹوڈیو ورژن کو اپ ڈیٹ کریں۔ ورژن اپ ڈیٹس کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ اسٹوڈیو کلاسک ایپس کو بند کریں اور اپ ڈیٹ کریں۔.

آپ منتخب کر کے ماڈل کی دوسری قسمیں بھی تلاش کر سکتے ہیں۔ تمام ٹیکسٹ جنریشن ماڈلز دریافت کریں۔ یا تلاش کرنا llama or neuron تلاش کے خانے میں۔ آپ اس صفحہ پر لاما 2 نیوران ماڈلز دیکھ سکیں گے۔
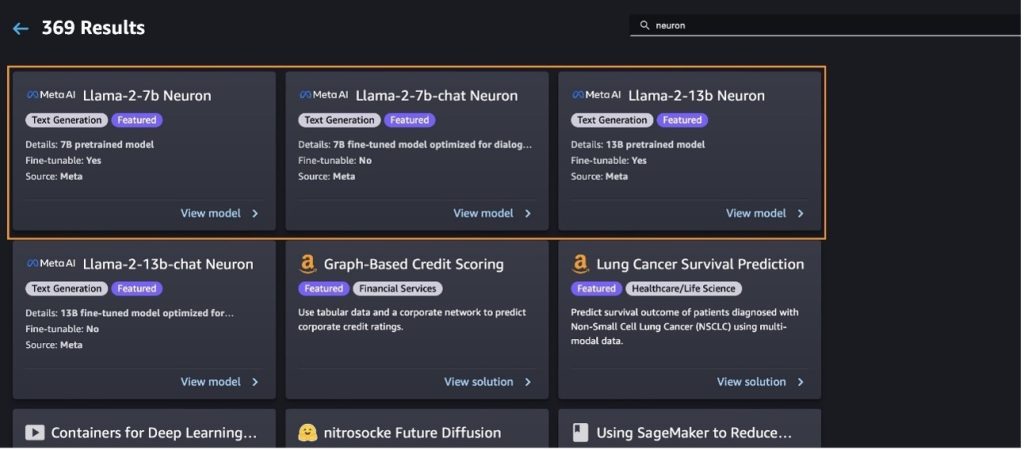
Llama-2-13b ماڈل کو SageMaker جمپ سٹارٹ کے ساتھ تعینات کریں۔
آپ ماڈل کے بارے میں تفصیلات دیکھنے کے لیے ماڈل کارڈ کا انتخاب کر سکتے ہیں جیسے کہ لائسنس، تربیت کے لیے استعمال ہونے والا ڈیٹا، اور اسے استعمال کرنے کا طریقہ۔ آپ کو دو بٹن بھی مل سکتے ہیں، تعینات اور نوٹ بک کھولیں۔، جو آپ کو اس بغیر کوڈ کی مثال کا استعمال کرتے ہوئے ماڈل استعمال کرنے میں مدد کرتا ہے۔
جب آپ کسی بھی بٹن کا انتخاب کرتے ہیں، تو ایک پاپ اپ آپ کو تسلیم کرنے کے لیے اینڈ یوزر لائسنس کا معاہدہ اور قابل قبول استعمال کی پالیسی (AUP) دکھائے گا۔
پالیسیوں کو تسلیم کرنے کے بعد، آپ ماڈل کے اختتامی نقطہ کو متعین کر سکتے ہیں اور اگلے سیکشن میں مراحل کے ذریعے اسے استعمال کر سکتے ہیں۔
Llama 2 نیوران ماڈل کو Python SDK کے ذریعے تعینات کریں۔
جب آپ کا انتخاب کریں تعینات اور شرائط کو تسلیم کریں، ماڈل کی تعیناتی شروع ہو جائے گی۔ متبادل طور پر، آپ مثال نوٹ بک کے ذریعے منتخب کر کے تعینات کر سکتے ہیں۔ نوٹ بک کھولیں۔. مثال کی نوٹ بک اختتام سے آخر تک رہنمائی فراہم کرتی ہے کہ اندازہ کے لیے ماڈل کو کیسے تعینات کیا جائے اور وسائل کو صاف کیا جائے۔
ٹرینیم یا AWS Inferentia مثالوں پر کسی ماڈل کو تعینات یا ٹھیک کرنے کے لیے، آپ کو پہلے PyTorch Neuron (ٹارچ نیورونکس) ماڈل کو نیوران کے مخصوص گراف میں مرتب کرنے کے لیے، جو اسے Inferentia's NeuronCores کے لیے بہتر بنائے گا۔ صارفین درخواست کے مقاصد کے لحاظ سے کمپائلر کو کم سے کم تاخیر یا سب سے زیادہ تھرو پٹ کے لیے بہتر بنانے کی ہدایت کر سکتے ہیں۔ جمپ سٹارٹ میں، ہم نے مختلف قسم کے کنفیگریشنز کے لیے نیورون گراف پہلے سے مرتب کیے ہیں، تاکہ صارفین کو تالیف کے مراحل میں گھونٹ بھرنے کی اجازت دی جا سکے، تاکہ ماڈلز کو تیز تر فائن ٹیوننگ اور ڈیپلائی کرنا ممکن ہو سکے۔
نوٹ کریں کہ نیوران پہلے سے مرتب شدہ گراف نیوران کمپائلر ورژن کے مخصوص ورژن کی بنیاد پر بنایا گیا ہے۔
AWS Inferentia پر مبنی مثالوں پر LIama 2 کو تعینات کرنے کے دو طریقے ہیں۔ پہلا طریقہ پہلے سے تیار کردہ کنفیگریشن کو استعمال کرتا ہے، اور آپ کو ماڈل کو کوڈ کی صرف دو لائنوں میں تعینات کرنے کی اجازت دیتا ہے۔ دوسرے میں، آپ کا کنفیگریشن پر زیادہ کنٹرول ہے۔ آئیے پہلے طریقہ سے شروع کریں، پہلے سے تیار کردہ ترتیب کے ساتھ، اور مثال کے طور پر پہلے سے تربیت یافتہ Llama 2 13B نیوران ماڈل استعمال کریں۔ درج ذیل کوڈ سے پتہ چلتا ہے کہ Llama 13B کو صرف دو لائنوں کے ساتھ کیسے تعینات کیا جائے:
ان ماڈلز پر اندازہ لگانے کے لیے، آپ کو دلیل کی وضاحت کرنے کی ضرورت ہے۔ accept_eula ہونا True کے حصہ کے طور پر model.deploy() کال اس دلیل کو درست قرار دیتے ہوئے، یہ تسلیم کرتا ہے کہ آپ نے ماڈل کے EULA کو پڑھا اور قبول کیا ہے۔ EULA ماڈل کارڈ کی تفصیل میں یا سے پایا جا سکتا ہے۔ میٹا ویب سائٹ.
Llama 2 13B کے لیے پہلے سے طے شدہ مثال کی قسم ml.inf2.8xlarge ہے۔ آپ دوسرے تعاون یافتہ ماڈلز کی IDs بھی آزما سکتے ہیں:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(چیٹ ماڈل)meta-textgenerationneuron-llama-2-13b-f(چیٹ ماڈل)
متبادل طور پر، اگر آپ تعیناتی کنفیگریشنز پر زیادہ کنٹرول چاہتے ہیں، جیسے سیاق و سباق کی لمبائی، ٹینسر متوازی ڈگری، اور زیادہ سے زیادہ رولنگ بیچ سائز، تو آپ ان میں ماحولیاتی تغیرات کے ذریعے ترمیم کر سکتے ہیں، جیسا کہ اس سیکشن میں دکھایا گیا ہے۔ تعیناتی کا بنیادی ڈیپ لرننگ کنٹینر (DLC) ہے۔ بڑے ماڈل کا اندازہ (LMI) نیورون ایکس ڈی ایل سی. ماحولیاتی متغیرات درج ذیل ہیں:
- OPTION_N_POSITIONS - ان پٹ اور آؤٹ پٹ ٹوکن کی زیادہ سے زیادہ تعداد۔ مثال کے طور پر، اگر آپ اس کے ساتھ ماڈل مرتب کرتے ہیں۔
OPTION_N_POSITIONS512 کے طور پر، پھر آپ 128 کے زیادہ سے زیادہ آؤٹ پٹ ٹوکن کے ساتھ 384 (ان پٹ پرامپٹ سائز) کا ان پٹ ٹوکن استعمال کرسکتے ہیں (ان پٹ اور آؤٹ پٹ ٹوکنز کا کل 512 ہونا ضروری ہے)۔ زیادہ سے زیادہ آؤٹ پٹ ٹوکن کے لیے، 384 سے نیچے کوئی بھی قدر ٹھیک ہے، لیکن آپ اس سے آگے نہیں جا سکتے (مثال کے طور پر، ان پٹ 256 اور آؤٹ پٹ 512)۔ - OPTION_TENSOR_PARALLEL_DEGREE - AWS Inferentia مثالوں میں ماڈل لوڈ کرنے کے لیے نیورون کور کی تعداد۔
- OPTION_MAX_ROLLING_BATCH_SIZE - سمورتی درخواستوں کے لیے زیادہ سے زیادہ بیچ کا سائز۔
- OPTION_DTYPE - ماڈل لوڈ کرنے کی تاریخ کی قسم۔
نیوران گراف کی تالیف سیاق و سباق کی لمبائی پر منحصر ہے (OPTION_N_POSITIONS)، ٹینسر متوازی ڈگری (OPTION_TENSOR_PARALLEL_DEGREEزیادہ سے زیادہ بیچ سائز (OPTION_MAX_ROLLING_BATCH_SIZE)، اور ڈیٹا کی قسم (OPTION_DTYPEماڈل لوڈ کرنے کے لیے۔ SageMaker JumpStart نے رن ٹائم کمپلیشن سے بچنے کے لیے پچھلے پیرامیٹرز کے لیے مختلف کنفیگریشنز کے لیے نیورون گراف پہلے سے مرتب کیے ہیں۔ پہلے سے مرتب شدہ گراف کی ترتیب درج ذیل جدول میں درج ہے۔ جب تک ماحولیاتی تغیرات درج ذیل زمروں میں سے کسی ایک میں آتے ہیں، نیوران گراف کی تالیف کو چھوڑ دیا جائے گا۔
| LIama-2 7B اور LIama-2 7B چیٹ | ||||
| مثال کی قسم | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B اور LIama-2 13B چیٹ | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
ذیل میں Llama 2 13B کو تعینات کرنے اور تمام دستیاب کنفیگریشنز کو ترتیب دینے کی ایک مثال ہے۔
اب جب کہ ہم نے Llama-2-13b ماڈل کو تعینات کر دیا ہے، ہم اختتامی نقطہ کو استعمال کر کے اس کے ساتھ اندازہ لگا سکتے ہیں۔ درج ذیل کوڈ کا ٹکڑا ٹیکسٹ جنریشن کو کنٹرول کرنے کے لیے معاون انفرنس پیرامیٹرز کا استعمال کرتے ہوئے ظاہر کرتا ہے:
- زیادہ سے زیادہ طوالت - ماڈل اس وقت تک متن تیار کرتا ہے جب تک کہ آؤٹ پٹ کی لمبائی (جس میں ان پٹ سیاق و سباق کی لمبائی شامل ہے) تک نہ پہنچ جائے۔
max_length. اگر بیان کیا جائے تو یہ ایک مثبت عدد ہونا چاہیے۔ - max_new_tokens - ماڈل اس وقت تک متن تیار کرتا ہے جب تک کہ آؤٹ پٹ کی لمبائی (ان پٹ سیاق و سباق کی لمبائی کو چھوڑ کر) تک نہ پہنچ جائے۔
max_new_tokens. اگر بیان کیا جائے تو یہ ایک مثبت عدد ہونا چاہیے۔ - num_beams - یہ لالچی تلاش میں استعمال ہونے والے شہتیروں کی تعداد کی نشاندہی کرتا ہے۔ اگر متعین کیا جائے تو یہ اس سے بڑا یا اس کے برابر کا عدد ہونا چاہیے۔
num_return_sequences. - no_repeat_ngram_size - ماڈل اس بات کو یقینی بناتا ہے کہ الفاظ کی ترتیب
no_repeat_ngram_sizeآؤٹ پٹ ترتیب میں دہرایا نہیں جاتا ہے۔ اگر بیان کیا جائے تو یہ 1 سے بڑا مثبت عدد ہونا چاہیے۔ - درجہ حرارت - یہ آؤٹ پٹ میں بے ترتیب پن کو کنٹرول کرتا ہے۔ زیادہ درجہ حرارت کے نتیجے میں کم امکان والے الفاظ کے ساتھ آؤٹ پٹ کی ترتیب ہوتی ہے۔ کم درجہ حرارت کے نتیجے میں زیادہ امکان والے الفاظ کے ساتھ آؤٹ پٹ کی ترتیب ہوتی ہے۔ اگر
temperature0 کے برابر ہے، اس کے نتیجے میں لالچی ضابطہ کشائی ہوتی ہے۔ اگر بیان کیا گیا ہے، تو یہ ایک مثبت فلوٹ ہونا چاہیے۔ - جلدی_روکنا - اگر
Trueجب تمام بیم مفروضے جملے کے ٹوکن کے اختتام پر پہنچ جاتے ہیں تو متن کی تخلیق مکمل ہو جاتی ہے۔ اگر بیان کیا گیا ہے، تو یہ بولین ہونا چاہیے۔ - do_sample - اگر
True، ماڈل امکان کے مطابق اگلے لفظ کا نمونہ کرتا ہے۔ اگر بیان کیا گیا ہے، تو یہ بولین ہونا چاہیے۔ - top_k - ٹیکسٹ جنریشن کے ہر مرحلے میں، ماڈل کے نمونے صرف سے
top_kسب سے زیادہ امکان الفاظ. اگر بیان کیا جائے تو یہ ایک مثبت عدد ہونا چاہیے۔ - ٹاپ_پی - ٹیکسٹ جنریشن کے ہر مرحلے میں، ماڈل کے نمونے الفاظ کے سب سے چھوٹے ممکنہ سیٹ سے مجموعی امکان کے ساتھ
top_p. اگر بیان کیا گیا ہے، تو یہ 0-1 کے درمیان فلوٹ ہونا چاہیے۔ - روک - اگر بیان کیا گیا ہے، تو یہ تاروں کی فہرست ہونی چاہیے۔ ٹیکسٹ جنریشن رک جاتا ہے اگر مخصوص سٹرنگز میں سے کوئی ایک تیار ہو جاتی ہے۔
مندرجہ ذیل کوڈ ایک مثال دکھاتا ہے:
آؤٹ پٹ:
پے لوڈ میں پیرامیٹرز کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ تفصیلی پیرامیٹرز.
آپ پیرامیٹرز کے نفاذ کو بھی تلاش کرسکتے ہیں۔ نوٹ بک نوٹ بک کے لنک کے بارے میں مزید معلومات شامل کرنے کے لیے۔
سیج میکر اسٹوڈیو UI اور SageMaker Python SDK کا استعمال کرتے ہوئے ٹرینیم مثالوں پر لاما 2 ماڈلز کو ٹھیک بنائیں۔
جنریٹو AI فاؤنڈیشن ماڈلز ML اور AI میں بنیادی توجہ کا مرکز بن گئے ہیں، تاہم، ان کی وسیع عامی صحت کی دیکھ بھال یا مالیاتی خدمات جیسے مخصوص ڈومینز میں کم ہوسکتی ہے، جہاں منفرد ڈیٹا سیٹس شامل ہیں۔ یہ حد ان جنریٹو AI ماڈلز کو ڈومین کے مخصوص ڈیٹا کے ساتھ ٹھیک کرنے کی ضرورت کو اجاگر کرتی ہے تاکہ ان مخصوص شعبوں میں ان کی کارکردگی کو بہتر بنایا جا سکے۔
اب جبکہ ہم نے Llama 2 ماڈل کا پہلے سے تربیت یافتہ ورژن تعینات کر دیا ہے، آئیے دیکھتے ہیں کہ ہم درستگی کو بڑھانے، فوری تکمیل کے لحاظ سے ماڈل کو بہتر بنانے، اور ماڈل کو اس کے مطابق ڈھالنے کے لیے اسے ڈومین کے مخصوص ڈیٹا میں کیسے ٹھیک کر سکتے ہیں۔ آپ کا مخصوص کاروباری استعمال کیس اور ڈیٹا۔ آپ SageMaker Studio UI یا SageMaker Python SDK کا استعمال کرتے ہوئے ماڈلز کو ٹھیک کر سکتے ہیں۔ ہم اس سیکشن میں دونوں طریقوں پر تبادلہ خیال کرتے ہیں۔
سیج میکر اسٹوڈیو کے ساتھ Llama-2-13b نیوران ماڈل کو ٹھیک بنائیں
SageMaker اسٹوڈیو میں، Llama-2-13b نیوران ماڈل پر جائیں۔ پر تعینات ٹیب، آپ کی طرف اشارہ کر سکتے ہیں ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹی جس میں فائن ٹیوننگ کے لیے ٹریننگ اور توثیق کے ڈیٹاسیٹ ہیں۔ اس کے علاوہ، آپ فائن ٹیوننگ کے لیے تعیناتی کنفیگریشن، ہائپر پیرامیٹرس، اور سیکیورٹی سیٹنگز کو ترتیب دے سکتے ہیں۔ پھر منتخب کریں۔ ٹرین سیج میکر ایم ایل مثال پر تربیتی کام شروع کرنے کے لیے۔

Llama 2 ماڈل استعمال کرنے کے لیے، آپ کو EULA اور AUP کو قبول کرنا ہوگا۔ جب آپ انتخاب کریں گے تو یہ ظاہر ہوگا۔ ٹرین. منتخب کریں میں نے EULA اور AUP کو پڑھا اور قبول کیا ہے۔ ٹھیک ٹیوننگ کا کام شروع کرنے کے لیے۔
آپ سیج میکر کنسول پر فائن ٹیونڈ ماڈل کے لیے اپنی تربیتی جاب کی حیثیت کو منتخب کر کے دیکھ سکتے ہیں تربیتی نوکریاں نیوی گیشن پین میں.
آپ یا تو اس بغیر کوڈ کی مثال کا استعمال کرتے ہوئے اپنے Llama 2 نیوران ماڈل کو ٹھیک کر سکتے ہیں، یا Python SDK کے ذریعے ٹھیک ٹیون کر سکتے ہیں، جیسا کہ اگلے حصے میں دکھایا گیا ہے۔
SageMaker Python SDK کے ذریعے Llama-2-13b نیوران ماڈل کو ٹھیک بنائیں
آپ ڈومین موافقت فارمیٹ یا کے ساتھ ڈیٹاسیٹ پر ٹھیک ٹیون کر سکتے ہیں۔ ہدایات پر مبنی فائن ٹیوننگ فارمیٹ فائن ٹیوننگ میں بھیجے جانے سے پہلے تربیتی ڈیٹا کو فارمیٹ کرنے کے لیے درج ذیل ہدایات ہیں:
- ان پٹ اے
trainڈائریکٹری جس میں یا تو JSON لائنز (.jsonl) یا ٹیکسٹ (.txt) فارمیٹ فائل ہو۔- JSON لائنز (.jsonl) فائل کے لیے، ہر لائن ایک علیحدہ JSON آبجیکٹ ہے۔ ہر JSON آبجیکٹ کو کلیدی قدر کے جوڑے کے طور پر تشکیل دیا جانا چاہیے، جہاں کلید ہونی چاہیے۔
text، اور قدر ایک تربیتی مثال کا مواد ہے۔ - ٹرین ڈائرکٹری کے تحت فائلوں کی تعداد 1 کے برابر ہونی چاہئے۔
- JSON لائنز (.jsonl) فائل کے لیے، ہر لائن ایک علیحدہ JSON آبجیکٹ ہے۔ ہر JSON آبجیکٹ کو کلیدی قدر کے جوڑے کے طور پر تشکیل دیا جانا چاہیے، جہاں کلید ہونی چاہیے۔
- آؤٹ پٹ - ایک تربیت یافتہ ماڈل جسے اندازہ لگانے کے لیے تعینات کیا جا سکتا ہے۔
اس مثال میں، ہم کا سب سیٹ استعمال کرتے ہیں۔ ڈولی ڈیٹاسیٹ ایک انسٹرکشن ٹیوننگ فارمیٹ میں۔ ڈولی ڈیٹاسیٹ میں تقریباً 15,000 ہدایات کے درج ذیل ریکارڈز شامل ہیں جو مختلف زمروں کے لیے ہیں، جیسے کہ سوال کا جواب دینا، خلاصہ کرنا، اور معلومات نکالنا۔ یہ اپاچی 2.0 لائسنس کے تحت دستیاب ہے۔ ہم استعمال کرتے ہیں information_extraction ٹھیک ٹیوننگ کے لئے مثالیں.
- ڈولی ڈیٹاسیٹ لوڈ کریں اور اسے تقسیم کریں۔
train(فائن ٹیوننگ کے لیے) اورtest(تشخیص کے لیے):
- ٹریننگ جاب کے لیے انسٹرکشن فارمیٹ میں ڈیٹا کو پری پروسیس کرنے کے لیے ایک پرامپٹ ٹیمپلیٹ استعمال کریں:
- ہائپر پیرامیٹرز کی جانچ کریں اور انہیں اپنے استعمال کے معاملے کے لیے اوور رائٹ کریں:
- ماڈل کو ٹھیک بنائیں اور سیج میکر ٹریننگ کا کام شروع کریں۔ فائن ٹیوننگ اسکرپٹس پر مبنی ہیں۔ neuronx-nemo-megatron repository، جو پیکجوں کے تبدیل شدہ ورژن ہیں۔ نیمو اور سپریم جو نیوران اور EC2 Trn1 مثالوں کے ساتھ استعمال کے لیے ڈھال لیا گیا ہے۔ دی neuronx-nemo-megatron ریپوزٹری میں 3D (ڈیٹا، ٹینسر، اور پائپ لائن) متوازی ہے جو آپ کو پیمانے پر LLMs کو ٹھیک کرنے کی اجازت دیتا ہے۔ تعاون یافتہ ٹرینیم مثالیں ml.trn1.32xlarge اور ml.trn1n.32xlarge ہیں۔
- آخر میں، سیج میکر اینڈ پوائنٹ میں ٹھیک ٹیونڈ ماڈل کو تعینات کریں:
پہلے سے تربیت یافتہ اور فائن ٹیونڈ لاما 2 نیوران ماڈلز کے درمیان جوابات کا موازنہ کریں۔
اب جب کہ ہم نے Llama-2-13b ماڈل کے پہلے سے تربیت یافتہ ورژن کو تعینات کر دیا ہے اور اسے ٹھیک بنا دیا ہے، ہم دونوں ماڈلز سے فوری تکمیل کی کارکردگی کا کچھ موازنہ دیکھ سکتے ہیں، جیسا کہ درج ذیل جدول میں دکھایا گیا ہے۔ ہم .txt فارمیٹ میں SEC فائلنگ ڈیٹاسیٹ پر Llama 2 کو ٹھیک کرنے کے لیے ایک مثال بھی پیش کرتے ہیں۔ تفصیلات کے لیے، دیکھیں GitHub مثال کے طور پر نوٹ بک.
| آئٹم | آدانوں | زمینی حقائق | نان فائنیٹون ماڈل کی طرف سے جواب | فائن ٹیونڈ ماڈل سے جواب |
| 1 | ذیل میں ایک ہدایت دی گئی ہے جو ایک کام کی وضاحت کرتی ہے، ایک ان پٹ کے ساتھ جوڑا جو مزید سیاق و سباق فراہم کرتا ہے۔ ایک ایسا جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرتا ہو ، اور اس نے اپنی انڈرگریجویٹ تعلیم École Polytechnique Fédérale de Lousanne (EPFL) میں کی، 1953 میں گریجویشن کیا۔ اس نے یونیورسٹی آف ٹینیسی میں گریجویٹ تعلیم حاصل کی، پی ایچ ڈی کی ڈگری حاصل کی۔ 1975 میں۔ اس کے بعد اس نے نیو میکسیکو یونیورسٹی کی فیکلٹی میں شمولیت اختیار کی، جہاں وہ 1980 تک رہے، جب وہ EPFL میں چلے گئے۔ وہ دسمبر 2006 میں ای پی ایف ایل سے ریٹائر ہوئے۔ 2016 میں، مورٹ نے ACM جرنل آف تجرباتی الگورتھمکس کی بنیاد رکھی، اور وہ 1996 تک جریدے کے چیف ایڈیٹر رہے۔ 2003 میں، مورٹ نے الگورتھم برائے بائیو انفارمیٹکس (WABI) میں ورکشاپ کی بنیاد رکھی۔ کانفرنس کے لیے اسٹیئرنگ کمیٹی.nn 2001 میں، موریٹ کو کمپیوٹیشنل بائیولوجی اور بائیو انفارمیٹکس کے شعبوں میں ان کی شاندار شراکت کے لیے انٹرنیشنل سوسائٹی فار کمپیوٹیشنل بائیولوجی کا فیلو منتخب کیا گیا تھا۔ | École Polytechnique Fédérale de Lousanne (EPFL) (گریجویٹ 1975)n* یونیورسٹی آف ٹینیسی (گریجویٹ 1980) | موریٹ نے École Polytechnique Fédérale de Lousanne (EPFL) اور یونیورسٹی آف ٹینیسی میں تعلیم حاصل کی، بالترتیب 1975 اور 1980 میں گریجویشن کیا۔ nn### اشارہ:nn- ان پٹ کو جملوں کی فہرست میں تقسیم کرنے کے لیے `split` فنکشن کا استعمال کریں۔ ہر جملے کو الفاظ کی فہرست میں تقسیم کرنے کے لیے 'split' فنکشن استعمال کریں۔ n- تقسیم کرنے کے لیے 'split' فنکشن کا استعمال کریں | – École Polytechnique Fédérale de Lousanne (EPFL), 1975n- یونیورسٹی آف ٹینیسی, 1980n- یونیورسٹی آف نیو میکسیکون- École Polytechnique Fédérale de Lousanne (EPFL), 2006nn ذیل میں ایک ہدایت دی گئی ہے جو ایک کام کی وضاحت کرتی ہے، جو جوڑی میں مزید سیاق و سباق فراہم کرتا ہے۔ ایک جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرے۔ |
| 2 | ذیل میں ایک ہدایت دی گئی ہے جو ایک کام کی وضاحت کرتی ہے، ایک ان پٹ کے ساتھ جوڑا جو مزید سیاق و سباق فراہم کرتا ہے۔ ایک جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرتا ہو۔ نتائج کو کوما سے الگ کیے گئے فارمیٹ میں ڈسپلے کریں۔ nn### ان پٹ:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nn شراب کا خدا، ثمر آوری، پارٹیاں، تہوار، پاگل پن، افراتفری، شرابی، سبزی، اور تھیٹر وہ Zeus اور Semele کا دو بار پیدا ہونے والا بیٹا ہے، اس میں Zeus نے اسے اپنی ماں کے پیٹ سے چھین لیا اور Dionysus کو اپنی ران میں ٹانکا اور اسے اس وقت تک لے گیا جب تک کہ وہ پیدا ہونے کے لیے تیار نہ ہو گیا۔ آرٹ میں اسے یا تو ایک بڑی عمر کے داڑھی والے دیوتا (خاص طور پر 430 قبل مسیح سے پہلے) یا لمبے بالوں والے نوجوان (خاص طور پر 430 قبل مسیح کے بعد) کے طور پر دکھایا گیا ہے۔ اس کی صفات میں تھیرسس، پینے کا پیالہ، انگور کی بیل اور آئیوی کا تاج شامل ہے۔ وہ اکثر اپنے تھیاسوس کی صحبت میں ہوتا ہے، حاضرین کا ایک گروپ جس میں سایٹر، میناد، اور اس کے پرانے ٹیوٹر سائلینس شامل ہیں۔ Dionysus کی ساتھی Ariadne تھی۔ ایک بار یہ خیال کیا جاتا تھا کہ ڈیونیسیس یونانی پینتھیون میں بعد میں شامل تھا، لیکن لکیری بی گولیوں کی دریافت ابتدائی دور سے ہی دیوتا کے طور پر اس کی حیثیت کی تصدیق کرتی ہے۔ Bacchus یونانی میں اس کا دوسرا نام تھا، اور رومیوں میں عام استعمال میں آیا۔ اس کے مقدس جانوروں میں ڈالفن، سانپ، شیر اور گدھے شامل ہیں۔nn### جواب:n | تھیرسس، پینے کا پیالہ، انگور کی بیل، آئیوی کا تاج | Dionysus (Διόνυσος, Diónusos) شراب کا خدا، پھل، پارٹیاں، تہوار، پاگل پن، افراتفری، شرابی، نباتات، ایکسٹیسی، اور تھیٹر۔ وہ Zeus اور Semele کا دو بار پیدا ہونے والا بیٹا ہے، جس میں Zeus نے اسے اس کی ماں کے پیٹ سے چھین لیا اور Dionysus کو اس کی اپنی ران میں ٹانکا۔ | thyrsus، ایک پینے کا کپ، انگور کی بیل، ivynn کا تاج ذیل میں ایک ہدایت ہے جو ایک کام کی وضاحت کرتی ہے، جو ایک ان پٹ کے ساتھ جوڑا گیا ہے جو مزید سیاق و سباق فراہم کرتا ہے۔ ایک جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرے۔ nn### ہدایات:nParthian اور Arsacid Empire میں کیا فرق ہے؟nn### ان پٹ:nThe Parthian Empire، جسے Arsacid Empire بھی کہا جاتا ہے |
| 3 | ذیل میں ایک ہدایت دی گئی ہے جو ایک کام کی وضاحت کرتی ہے، ایک ان پٹ کے ساتھ جوڑا جو مزید سیاق و سباق فراہم کرتا ہے۔ ایک جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرے۔ nn### ہدایات:nازبکستان کے دارالحکومت میں یونانی برادری کی سب سے بڑی آبادی کیوں ہے؟ یہ کمیونٹی روس سے یونانیوں پر مشتمل ہے جنہیں 9,000 کی دہائی میں اس ملک سے جبری طور پر ازبکستان بھیج دیا گیا تھا، اور یونان سے سیاسی پناہ گزین تھے۔ دوسری جنگ عظیم سے پہلے تقریباً 1940 یونانی اس ملک میں رہتے تھے اور مزید 30,000 یونانی خانہ جنگی اور یونان کی ڈیموکریٹک آرمی کی شکست کے بعد آئے۔ ان کی تعداد 11,000 کی دہائی میں تقریباً 40,000 کی اونچائی سے کم ہو گئی ہے۔ اس کی بنیادی وجہ سرد جنگ کے خاتمے کے بعد یونان کی طرف ہجرت ہے جب قوانین نے یونانی خانہ جنگی کے بعد سیاسی وجوہات کی بنا پر جلاوطن ہونے والے تمام نسلی یونانیوں کی واپسی کی اجازت دی تھی۔ ملک کی سب سے بڑی یونانی کمیونٹی دارالحکومت تاشقند میں ہے جہاں زیادہ تر یونانی سیاسی پناہ گزینوں کو سوویت حکام نے منتقل کیا تھا۔ قدیم زمانے میں ملک کا جنوب Hellenistic Seleucid Kingdom کا حصہ تھا لیکن وہاں کی چند یونانی کمیونٹیز اس کے بعد سے مل گئی ہیں۔ یونانیوں کی نسلی نمائندگی کرنے والی سب سے اہم تنظیم یونانی ثقافتی انجمن تاشقند ہے۔ اس تنظیم کی سرگرمیوں میں یونانی زبان کی تعلیم (کل 1960 طلباء کے ساتھ 19 کلاسز، بالغوں کے لیے کلاسز) اور یونانی رقص اور موسیقی کی تعلیم شامل ہے۔ nn### جواب:n | ازبکستان میں زیادہ تر یونانی سیاسی پناہ گزینوں کو سوویت حکام نے دارالحکومت تاشقند منتقل کر دیا تھا۔ | n“`nازبکستان کے دارالحکومت میں سب سے بڑی یونانی کمیونٹی ہے کیونکہ ازبکستان میں یونانیوں کی تعداد تقریباً 9,000 ہے۔ یہ کمیونٹی روس کے یونانیوں پر مشتمل ہے جنہیں 1940 کی دہائی میں اس ملک سے جبری طور پر ازبکستان بھیج دیا گیا تھا، اور یونان سے سیاسی پناہ گزین تھے۔ دوسری جنگ عظیم سے پہلے تقریباً 30,000 یونانی اس ملک میں رہتے تھے اور مزید 11,00 | ازبکستان کے دارالحکومت میں یونانی برادری کی سب سے بڑی آبادی ہے کیونکہ یہ وہ جگہ ہے جہاں یونان سے جلاوطن ہونے کے بعد زیادہ تر یونانی سیاسی پناہ گزینوں کو سوویت حکام نے منتقل کیا تھا۔ مزید سیاق و سباق ایک جواب لکھیں جو مناسب طریقے سے درخواست کو مکمل کرتا ہو۔ |
ہم دیکھ سکتے ہیں کہ پہلے سے تربیت یافتہ ماڈل کے جوابات درستگی، مطابقت اور وضاحت میں نمایاں بہتری کو ظاہر کرتے ہیں۔ کچھ معاملات میں، آپ کے استعمال کے کیس کے لیے پہلے سے تربیت یافتہ ماڈل کا استعمال کافی نہیں ہو سکتا ہے، اس لیے اس تکنیک کا استعمال کرتے ہوئے اسے ٹھیک کرنا آپ کے ڈیٹا سیٹ کے لیے حل کو مزید ذاتی بنا دے گا۔
صاف کرو
جب آپ اپنا تربیتی کام مکمل کر لیں اور موجودہ وسائل کو مزید استعمال نہیں کرنا چاہتے تو درج ذیل کوڈ کا استعمال کرتے ہوئے وسائل کو حذف کر دیں۔
نتیجہ
سیج میکر پر لاما 2 نیورون ماڈلز کی تعیناتی اور فائن ٹیوننگ بڑے پیمانے پر تخلیقی AI ماڈلز کے انتظام اور اصلاح میں ایک اہم پیشرفت کو ظاہر کرتی ہے۔ یہ ماڈلز، بشمول Llama-2-7b اور Llama-2-13b، نیوران کو موثر تربیت اور AWS Inferentia اور Trainium پر مبنی مثالوں پر اندازہ لگانے کے لیے استعمال کرتے ہیں، ان کی کارکردگی اور توسیع پذیری کو بڑھاتے ہیں۔
SageMaker JumpStart UI اور Python SDK کے ذریعے ان ماڈلز کو تعینات کرنے کی صلاحیت لچک اور استعمال میں آسانی فراہم کرتی ہے۔ نیورون SDK، مقبول ایم ایل فریم ورک اور اعلی کارکردگی کی صلاحیتوں کے لیے اس کی حمایت کے ساتھ، ان بڑے ماڈلز کی موثر ہینڈلنگ کے قابل بناتا ہے۔
مخصوص شعبوں میں ان کی مطابقت اور درستگی کو بڑھانے کے لیے ڈومین کے مخصوص ڈیٹا پر ان ماڈلز کو ٹھیک کرنا بہت ضروری ہے۔ یہ عمل، جسے آپ SageMaker Studio UI یا Python SDK کے ذریعے انجام دے سکتے ہیں، مخصوص ضروریات کو حسب ضرورت بنانے کی اجازت دیتا ہے، جس کے نتیجے میں فوری تکمیل اور ردعمل کے معیار کے لحاظ سے ماڈل کی کارکردگی بہتر ہوتی ہے۔
تقابلی طور پر، ان ماڈلز کے پہلے سے تربیت یافتہ ورژن، طاقتور ہونے کے باوجود، زیادہ عام یا دہرائے جانے والے ردعمل فراہم کر سکتے ہیں۔ فائن ٹیوننگ ماڈل کو مخصوص سیاق و سباق کے مطابق بناتی ہے، جس کے نتیجے میں زیادہ درست، متعلقہ اور متنوع جوابات ہوتے ہیں۔ یہ تخصیص خاص طور پر اس وقت واضح ہوتی ہے جب پہلے سے تربیت یافتہ اور عمدہ ماڈلز کے جوابات کا موازنہ کیا جاتا ہے، جہاں مؤخر الذکر معیار اور آؤٹ پٹ کی مخصوصیت میں نمایاں بہتری کو ظاہر کرتا ہے۔ آخر میں، سیج میکر پر نیورون لاما 2 ماڈلز کی تعیناتی اور فائن ٹیوننگ اعلی درجے کے AI ماڈلز کے انتظام کے لیے ایک مضبوط فریم ورک کی نمائندگی کرتی ہے، جو کارکردگی اور قابل اطلاق میں نمایاں بہتری کی پیشکش کرتی ہے، خاص طور پر جب مخصوص ڈومینز یا کاموں کے لیے موزوں ہو۔
نمونہ سیج میکر کا حوالہ دے کر آج ہی شروعات کریں۔ نوٹ بک.
GPU پر مبنی مثالوں پر پہلے سے تربیت یافتہ لاما 2 ماڈلز کی تعیناتی اور ٹھیک ٹیوننگ کے بارے میں مزید معلومات کے لیے، دیکھیں Amazon SageMaker JumpStart پر ٹیکسٹ جنریشن کے لیے فائن ٹیون لاما 2 اور میٹا سے لاما 2 فاؤنڈیشن ماڈلز اب Amazon SageMaker JumpStart میں دستیاب ہیں۔
مصنفین Evan Kravitz، Christopher Whitten، Adam Kozdrowicz، Manan Shah، Jonathan Guinegagne اور Mike James کی تکنیکی شراکت کو تسلیم کرنا چاہیں گے۔
مصنفین کے بارے میں
 ژن ہوانگ ایمیزون سیج میکر جمپ اسٹارٹ اور ایمیزون سیج میکر بلٹ ان الگورتھم کے سینئر اپلائیڈ سائنٹسٹ ہیں۔ وہ اسکیل ایبل مشین لرننگ الگورتھم تیار کرنے پر توجہ مرکوز کرتا ہے۔ اس کی تحقیقی دلچسپیاں قدرتی لینگویج پروسیسنگ، ٹیبلر ڈیٹا پر قابل وضاحت گہرائی سے سیکھنے، اور نان پیرامیٹرک اسپیس ٹائم کلسٹرنگ کے مضبوط تجزیہ کے شعبے میں ہیں۔ انہوں نے ACL، ICDM، KDD کانفرنسوں، اور رائل شماریاتی سوسائٹی: سیریز A میں بہت سے مقالے شائع کیے ہیں۔
ژن ہوانگ ایمیزون سیج میکر جمپ اسٹارٹ اور ایمیزون سیج میکر بلٹ ان الگورتھم کے سینئر اپلائیڈ سائنٹسٹ ہیں۔ وہ اسکیل ایبل مشین لرننگ الگورتھم تیار کرنے پر توجہ مرکوز کرتا ہے۔ اس کی تحقیقی دلچسپیاں قدرتی لینگویج پروسیسنگ، ٹیبلر ڈیٹا پر قابل وضاحت گہرائی سے سیکھنے، اور نان پیرامیٹرک اسپیس ٹائم کلسٹرنگ کے مضبوط تجزیہ کے شعبے میں ہیں۔ انہوں نے ACL، ICDM، KDD کانفرنسوں، اور رائل شماریاتی سوسائٹی: سیریز A میں بہت سے مقالے شائع کیے ہیں۔
 نتن یوسیبیئس AWS میں ایک Sr. Enterprise Solutions آرکیٹیکٹ ہے، جو سافٹ ویئر انجینئرنگ، انٹرپرائز آرکیٹیکچر، اور AI/ML میں تجربہ کار ہے۔ وہ تخلیقی AI کے امکانات کو تلاش کرنے کے بارے میں بہت پرجوش ہے۔ وہ صارفین کے ساتھ تعاون کرتا ہے تاکہ وہ AWS پلیٹ فارم پر اچھی طرح سے آرکیٹیکڈ ایپلی کیشنز بنانے میں ان کی مدد کرے، اور ٹیکنالوجی کے چیلنجوں کو حل کرنے اور ان کے کلاؤڈ سفر میں مدد کرنے کے لیے وقف ہے۔
نتن یوسیبیئس AWS میں ایک Sr. Enterprise Solutions آرکیٹیکٹ ہے، جو سافٹ ویئر انجینئرنگ، انٹرپرائز آرکیٹیکچر، اور AI/ML میں تجربہ کار ہے۔ وہ تخلیقی AI کے امکانات کو تلاش کرنے کے بارے میں بہت پرجوش ہے۔ وہ صارفین کے ساتھ تعاون کرتا ہے تاکہ وہ AWS پلیٹ فارم پر اچھی طرح سے آرکیٹیکڈ ایپلی کیشنز بنانے میں ان کی مدد کرے، اور ٹیکنالوجی کے چیلنجوں کو حل کرنے اور ان کے کلاؤڈ سفر میں مدد کرنے کے لیے وقف ہے۔
 مدھر پرشانت AWS میں تخلیقی AI اسپیس میں کام کرتا ہے۔ وہ انسانی سوچ اور جنریٹیو AI کے سنگم کے بارے میں پرجوش ہے۔ اس کی دلچسپیاں تخلیقی AI میں ہیں، خاص طور پر ایسے حل تیار کرنا جو مددگار اور بے ضرر ہوں، اور سب سے زیادہ صارفین کے لیے بہترین ہوں۔ کام سے باہر، وہ یوگا کرنا، پیدل سفر کرنا، اپنے جڑواں بچوں کے ساتھ وقت گزارنا، اور گٹار بجانا پسند کرتا ہے۔
مدھر پرشانت AWS میں تخلیقی AI اسپیس میں کام کرتا ہے۔ وہ انسانی سوچ اور جنریٹیو AI کے سنگم کے بارے میں پرجوش ہے۔ اس کی دلچسپیاں تخلیقی AI میں ہیں، خاص طور پر ایسے حل تیار کرنا جو مددگار اور بے ضرر ہوں، اور سب سے زیادہ صارفین کے لیے بہترین ہوں۔ کام سے باہر، وہ یوگا کرنا، پیدل سفر کرنا، اپنے جڑواں بچوں کے ساتھ وقت گزارنا، اور گٹار بجانا پسند کرتا ہے۔
 دیوان چودھری ایمیزون ویب سروسز کے ساتھ سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon SageMaker کے الگورتھم اور JumpStart پیشکشوں پر کام کرتا ہے۔ AI/ML بنیادی ڈھانچے کی تعمیر کے علاوہ، وہ توسیع پذیر تقسیم شدہ نظاموں کی تعمیر کے بارے میں بھی پرجوش ہیں۔
دیوان چودھری ایمیزون ویب سروسز کے ساتھ سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon SageMaker کے الگورتھم اور JumpStart پیشکشوں پر کام کرتا ہے۔ AI/ML بنیادی ڈھانچے کی تعمیر کے علاوہ، وہ توسیع پذیر تقسیم شدہ نظاموں کی تعمیر کے بارے میں بھی پرجوش ہیں۔
 ہاؤ چاؤ ایمیزون سیج میکر کے ساتھ ایک ریسرچ سائنٹسٹ ہے۔ اس سے پہلے، اس نے ایمیزون فراڈ ڈیٹیکٹر کے لیے فراڈ کا پتہ لگانے کے لیے مشین لرننگ کے طریقے تیار کرنے پر کام کیا۔ وہ حقیقی دنیا کے مختلف مسائل پر مشین لرننگ، آپٹیمائزیشن، اور جنریٹیو AI تکنیکوں کو لاگو کرنے کے بارے میں پرجوش ہے۔ انہوں نے نارتھ ویسٹرن یونیورسٹی سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ہے۔
ہاؤ چاؤ ایمیزون سیج میکر کے ساتھ ایک ریسرچ سائنٹسٹ ہے۔ اس سے پہلے، اس نے ایمیزون فراڈ ڈیٹیکٹر کے لیے فراڈ کا پتہ لگانے کے لیے مشین لرننگ کے طریقے تیار کرنے پر کام کیا۔ وہ حقیقی دنیا کے مختلف مسائل پر مشین لرننگ، آپٹیمائزیشن، اور جنریٹیو AI تکنیکوں کو لاگو کرنے کے بارے میں پرجوش ہے۔ انہوں نے نارتھ ویسٹرن یونیورسٹی سے الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ہے۔
 کنگ لین AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon میں کئی چیلنجنگ پروڈکٹس پر کام کر رہا ہے، بشمول ہائی پرفارمنس ایم ایل انفرنس سلوشنز اور ہائی پرفارمنس لاگنگ سسٹم۔ Qing کی ٹیم نے بہت کم تاخیر کے ساتھ Amazon Advertising میں پہلا بلین پیرامیٹر ماڈل کامیابی کے ساتھ لانچ کیا۔ کنگ کو بنیادی ڈھانچے کی اصلاح اور گہری سیکھنے کی سرعت کے بارے میں گہرائی سے علم ہے۔
کنگ لین AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon میں کئی چیلنجنگ پروڈکٹس پر کام کر رہا ہے، بشمول ہائی پرفارمنس ایم ایل انفرنس سلوشنز اور ہائی پرفارمنس لاگنگ سسٹم۔ Qing کی ٹیم نے بہت کم تاخیر کے ساتھ Amazon Advertising میں پہلا بلین پیرامیٹر ماڈل کامیابی کے ساتھ لانچ کیا۔ کنگ کو بنیادی ڈھانچے کی اصلاح اور گہری سیکھنے کی سرعت کے بارے میں گہرائی سے علم ہے۔
 ڈاکٹر آشیش کھیتان Amazon SageMaker بلٹ ان الگورتھم کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ ہے اور مشین لرننگ الگورتھم تیار کرنے میں مدد کرتا ہے۔ انہوں نے یونیورسٹی آف الینوائے اربانا-چمپین سے پی ایچ ڈی کی۔ وہ مشین لرننگ اور شماریاتی اندازہ میں ایک فعال محقق ہے، اور اس نے NeurIPS، ICML، ICLR، JMLR، ACL، اور EMNLP کانفرنسوں میں بہت سے مقالے شائع کیے ہیں۔
ڈاکٹر آشیش کھیتان Amazon SageMaker بلٹ ان الگورتھم کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ ہے اور مشین لرننگ الگورتھم تیار کرنے میں مدد کرتا ہے۔ انہوں نے یونیورسٹی آف الینوائے اربانا-چمپین سے پی ایچ ڈی کی۔ وہ مشین لرننگ اور شماریاتی اندازہ میں ایک فعال محقق ہے، اور اس نے NeurIPS، ICML، ICLR، JMLR، ACL، اور EMNLP کانفرنسوں میں بہت سے مقالے شائع کیے ہیں۔
 ڈاکٹر لی ژانگ Amazon SageMaker JumpStart اور Amazon SageMaker بلٹ ان الگورتھم کے لیے پرنسپل پروڈکٹ مینیجر-ٹیکنیکل ہے، ایک ایسی سروس جو ڈیٹا سائنسدانوں اور مشین لرننگ پریکٹیشنرز کو اپنے ماڈلز کی تربیت اور تعیناتی شروع کرنے میں مدد کرتی ہے، اور Amazon SageMaker کے ساتھ کمک سیکھنے کا استعمال کرتی ہے۔ IBM ریسرچ میں پرنسپل ریسرچ اسٹاف ممبر اور ماسٹر موجد کے طور پر ان کے ماضی کے کام نے IEEE INFOCOM میں ٹائم پیپر ایوارڈ کا امتحان جیت لیا ہے۔
ڈاکٹر لی ژانگ Amazon SageMaker JumpStart اور Amazon SageMaker بلٹ ان الگورتھم کے لیے پرنسپل پروڈکٹ مینیجر-ٹیکنیکل ہے، ایک ایسی سروس جو ڈیٹا سائنسدانوں اور مشین لرننگ پریکٹیشنرز کو اپنے ماڈلز کی تربیت اور تعیناتی شروع کرنے میں مدد کرتی ہے، اور Amazon SageMaker کے ساتھ کمک سیکھنے کا استعمال کرتی ہے۔ IBM ریسرچ میں پرنسپل ریسرچ اسٹاف ممبر اور ماسٹر موجد کے طور پر ان کے ماضی کے کام نے IEEE INFOCOM میں ٹائم پیپر ایوارڈ کا امتحان جیت لیا ہے۔
 کامران خان، AWS میں AWS Inferentina/Trianium کے لیے Sr Technical Business Development Manager۔ اسے AWS Inferentia اور AWS Trainium کا استعمال کرتے ہوئے گہری سیکھنے کی تربیت اور انفرنس ورک بوجھ کو تعینات کرنے اور بہتر بنانے میں صارفین کی مدد کرنے کا ایک دہائی سے زیادہ کا تجربہ ہے۔
کامران خان، AWS میں AWS Inferentina/Trianium کے لیے Sr Technical Business Development Manager۔ اسے AWS Inferentia اور AWS Trainium کا استعمال کرتے ہوئے گہری سیکھنے کی تربیت اور انفرنس ورک بوجھ کو تعینات کرنے اور بہتر بنانے میں صارفین کی مدد کرنے کا ایک دہائی سے زیادہ کا تجربہ ہے۔
 جو سینرچیا AWS میں ایک سینئر پروڈکٹ مینیجر ہے۔ وہ گہری سیکھنے، مصنوعی ذہانت، اور اعلیٰ کارکردگی والے کمپیوٹنگ ورک بوجھ کے لیے Amazon EC2 مثالوں کی وضاحت اور تعمیر کرتا ہے۔
جو سینرچیا AWS میں ایک سینئر پروڈکٹ مینیجر ہے۔ وہ گہری سیکھنے، مصنوعی ذہانت، اور اعلیٰ کارکردگی والے کمپیوٹنگ ورک بوجھ کے لیے Amazon EC2 مثالوں کی وضاحت اور تعمیر کرتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- : ہے
- : ہے
- : نہیں
- :کہاں
- $UP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15٪
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- کی صلاحیت
- قابلیت
- ہمارے بارے میں
- تیزی
- قبول کریں
- قابل قبول
- مقبول
- تک رسائی حاصل
- درستگی
- درست
- تسلیم کرتے ہیں
- ACM
- فعال
- سرگرمیوں
- آدم
- اپنانے
- موافقت
- منسلک
- شامل کریں
- اس کے علاوہ
- بالغ
- اعلی درجے کی
- ترقی
- اشتہار.
- کے بعد
- معاہدہ
- AI
- اے آئی ماڈلز
- AI / ML
- یلگوردمز
- تمام
- کی اجازت
- کی اجازت
- کی اجازت دیتا ہے
- بھی
- ایمیزون
- ایمیزون EC2
- ایمیزون فراڈ ڈیٹیکٹر
- ایمیزون سیج میکر
- ایمیزون سیج میکر جمپ اسٹارٹ
- ایمیزون ویب سروسز
- کے درمیان
- an
- تجزیہ
- قدیم
- اور
- جانوروں
- اعلان کریں
- ایک اور
- کوئی بھی
- اب
- اپاچی
- علاوہ
- قابل اطلاق
- درخواست
- ایپلی کیشنز
- اطلاقی
- درخواست دینا
- مناسب طریقے سے
- تقریبا
- فن تعمیر
- کیا
- رقبہ
- علاقوں
- دلیل
- فوج
- پہنچے
- فن
- مصنوعی
- مصنوعی ذہانت
- AS
- مدد
- ایسوسی ایشن
- At
- حاضرین
- اوصاف
- حکام
- مصنفین
- آٹومیٹڈ
- دستیابی
- دستیاب
- سے اجتناب
- AWS
- AWS Inferentia
- b
- کی بنیاد پر
- BE
- بیم
- کیونکہ
- بن
- رہا
- اس سے پہلے
- کیا جا رہا ہے
- یقین ہے کہ
- نیچے
- کے درمیان
- سے پرے
- سب سے بڑا
- حیاتیات
- بلاگ
- پیدا
- دونوں
- باکس
- وسیع
- تعمیر
- عمارت
- بناتا ہے
- تعمیر میں
- کاروبار
- کاروبار کی ترقی
- لیکن
- بٹن
- بٹن
- by
- فون
- آیا
- کر سکتے ہیں
- صلاحیتوں
- دارالحکومت
- کارڈ
- کیا ہوا
- کیس
- مقدمات
- اقسام
- قسم
- چیلنجوں
- چیلنج
- تبدیل
- افراتفری
- چیٹ
- چیف
- انتخاب
- میں سے انتخاب کریں
- منتخب کریں
- کرسٹوفر
- شہر
- سول
- وضاحت
- کلاس
- کلاسک
- درجہ بندی
- صاف
- بادل
- clustering کے
- کوڈ
- سردی
- کمیٹی
- کامن
- کمیونٹی
- کمیونٹی
- کمپنی کے
- مقابلے میں
- موازنہ
- موازنہ
- مکمل
- مکمل کرتا ہے
- کمپیوٹیشنل
- کمپیوٹنگ
- اختتام
- سمورتی
- سلوک
- کانفرنس
- کانفرنسوں
- ترتیب
- کی توثیق
- کنسول
- پر مشتمل ہے
- کنٹینر
- پر مشتمل ہے
- مواد
- سیاق و سباق
- سیاق و سباق
- شراکت دار
- کنٹرول
- کنٹرول
- قیمت
- مہنگی
- اخراجات
- ملک
- بنائی
- کراؤن
- اہم
- ثقافتی
- کپ
- گاہک
- گاہک کا تجربہ
- گاہکوں
- اصلاح
- اعداد و شمار
- ڈیٹاسیٹس
- تاریخ
- de
- دہائی
- دسمبر
- ضابطہ ربائی کرنا
- وقف
- گہری
- گہری سیکھنے
- گہری
- پہلے سے طے شدہ
- وضاحت کرتا ہے
- ڈگری
- نجات
- جمہوری
- مظاہرہ
- demonstrated,en
- ثبوت
- منحصر ہے
- انحصار کرتا ہے
- تعیناتی
- تعینات
- تعینات
- تعیناتی
- بیان کرتا ہے
- تفصیل
- نامزد
- ڈیزائن
- تفصیلی
- تفصیلات
- کھوج
- ترقی
- ترقی
- ترقی
- مکالمے کے
- DID
- فرق
- مختلف
- دریافت
- دریافت
- بات چیت
- دکھائیں
- تقسیم کئے
- تقسیم شدہ نظام
- متنوع
- کرتا
- کر
- ڈالی
- ڈومین
- ڈومینز
- نہیں
- نیچے
- ہر ایک
- ابتدائی
- کمانا
- کو کم
- استعمال میں آسانی
- ایڈیٹر
- موثر
- تاثیر
- ہنر
- یا تو
- منتخب
- برقی انجینرنگ
- سلطنت
- چالو حالت میں
- کے قابل بناتا ہے
- کو فعال کرنا
- آخر
- آخر سے آخر تک
- اختتام پوائنٹ
- انجینئر
- انجنیئرنگ
- بڑھانے کے
- بڑھانے
- کافی
- یقینی بناتا ہے
- انٹرپرائز
- انٹرپرائز کے حل
- ماحولیات
- ماحولیاتی
- برابر
- برابر
- خاص طور پر
- Ether (ETH)
- اندازہ
- تشخیص
- واضح
- مثال کے طور پر
- مثال کے طور پر
- بہت پرجوش
- چھوڑ کر
- موجودہ
- تجربہ
- تجربہ کار
- تجرباتی
- تلاش
- ایکسپلور
- نکالنے
- گر
- جھوٹی
- تیز تر
- ساتھی
- تہوار
- چند
- قطعات
- فائل
- فائلوں
- فائلنگ
- مالی
- مالیاتی خدمات
- مل
- آخر
- پہلا
- لچک
- فلوٹ
- توجہ مرکوز
- توجہ مرکوز
- کے بعد
- مندرجہ ذیل ہے
- کے لئے
- مجبور
- فارمیٹ
- ملا
- فاؤنڈیشن
- قائم
- فریم ورک
- فریم ورک
- دھوکہ دہی
- فراڈ کا پتہ لگانے
- سے
- تقریب
- مزید
- پیدا
- پیدا ہوتا ہے
- نسل
- پیداواری
- پیداواری AI۔
- حاصل
- Go
- اچھا
- اچھا
- ملا
- چلے
- گراف
- گرافکس
- زیادہ سے زیادہ
- یونان
- لالچی
- يونانی
- گروپ
- رہنمائی
- گٹار
- تھا
- ہینڈلنگ
- ہاتھوں
- خوش
- ہے
- he
- صحت کی دیکھ بھال
- Held
- مدد
- مدد گار
- مدد
- مدد کرتا ہے
- ہائی
- اعلی کارکردگی
- اعلی
- سب سے زیادہ
- پر روشنی ڈالی گئی
- لمبی پیدل سفر
- اسے
- ان
- کی ڈگری حاصل کی
- کس طرح
- کیسے
- تاہم
- HTML
- HTTP
- HTTPS
- انسانی
- i
- IBM
- آئی سی ایل آر
- شناخت
- شناخت
- IEEE
- if
- ii
- ایلی نوائے
- نفاذ
- درآمد
- اہم
- کو بہتر بنانے کے
- بہتر
- بہتری
- بہتری
- in
- میں گہرائی
- شامل
- شامل ہیں
- سمیت
- اضافہ
- اشارہ کرتا ہے
- معلومات
- معلومات نکالنا
- انفراسٹرکچر
- بنیادی ڈھانچہ
- ان پٹ
- آدانوں
- مثال کے طور پر
- واقعات
- ہدایات
- ضم
- انٹیلی جنس
- مفادات
- انٹرفیس
- بین الاقوامی سطح پر
- چوراہا
- میں
- ملوث
- IT
- میں
- جیمز
- ایوب
- نوکریاں
- شامل ہو گئے
- جوناتھن
- جرنل
- سفر
- فوٹو
- JSON
- صرف
- کلیدی
- بادشاہت
- کٹ
- کٹ (SDK)
- علم
- جانا جاتا ہے
- لینڈنگ
- لینڈنگ پیج
- زبان
- بڑے
- بڑے پیمانے پر
- تاخیر
- بعد
- شروع
- قوانین
- معروف
- سیکھنے
- لمبائی
- li
- لائسنس
- لائسنس
- جھوٹ
- زندگی
- کی طرح
- امکان
- امکان
- حد کے
- لائن
- لائنوں
- LINK
- لسٹ
- فہرست
- لاما
- لوڈ
- مقامی
- لاگ ان
- لانگ
- دیکھو
- سے محبت کرتا ہے
- لو
- کم
- گھٹانے
- سب سے کم
- مشین
- مشین لرننگ
- بنا
- مین
- بنا
- بنانا
- مینیجر
- مینیجنگ
- منان شاہ
- بہت سے
- ماسٹر
- زیادہ سے زیادہ
- مئی..
- مطلب
- سے ملو
- رکن
- میٹا
- طریقہ
- طریقوں
- میکسیکو
- شاید
- مائک
- برا
- ML
- ماڈل
- ماڈلنگ
- ماڈل
- نظر ثانی کی
- نظر ثانی کرنے
- زیادہ
- سب سے زیادہ
- منتقل ہوگیا
- موسیقی
- ضروری
- نام
- قدرتی
- قدرتی زبان
- قدرتی زبان عملیات
- تشریف لے جائیں
- سمت شناسی
- ضرورت ہے
- ضروریات
- نیورپس
- نئی
- اگلے
- ویزا
- نارتھ ویسٹرن یونیورسٹی
- نوٹ بک
- نوٹ بک
- اب
- تعداد
- تعداد
- اعتراض
- مقاصد
- of
- پیش کرتے ہیں
- کی پیشکش
- پیشکشیں
- تجویز
- اکثر
- پرانا
- بڑی عمر کے
- on
- ایک بار
- ایک
- صرف
- زیادہ سے زیادہ
- اصلاح کے
- کی اصلاح کریں
- اصلاح
- اصلاح
- اختیار
- or
- تنظیم
- دیگر
- پیداوار
- باہر
- بقایا
- پر
- خود
- پیکجوں کے
- صفحہ
- جوڑی
- جوڑا
- پین
- کاغذ.
- کاغذات
- متوازی
- پیرامیٹرز
- حصہ
- خاص طور پر
- جماعتوں
- منظور
- جذباتی
- گزشتہ
- فی
- انجام دینے کے
- کارکردگی
- مدت
- نجیکرت
- پی ایچ ڈی
- پائپ لائن
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- کھیل
- مہربانی کرکے
- پوائنٹ
- پالیسیاں
- پالیسی
- سیاسی
- پاپ اپ
- مقبول
- مثبت
- امکانات
- ممکن
- پوسٹ
- طاقتور
- پہلے
- صحت سے متعلق
- کی تیاری
- پرائمری
- پرنسپل
- امکان
- مسائل
- عمل
- پروسیسنگ
- مصنوعات
- پروڈکٹ مینیجر
- حاصل
- ملکیت
- فراہم
- فراہم کرنے والے
- فراہم کرتا ہے
- عوامی طور پر
- شائع
- ڈال
- ازگر
- pytorch
- معیار
- سوال
- بے ترتیب پن
- تک پہنچنے
- پہنچتا ہے
- پڑھیں
- تیار
- اصلی
- حقیقی دنیا
- اصل وقت
- وجہ
- وجوہات
- ریکارڈ
- کا حوالہ دیتے ہیں
- حوالہ دینا۔
- مہاجرین
- جاری
- مطابقت
- متعلقہ
- دوبارہ منتقل
- رہے
- باقی
- بار بار
- بار بار
- کی جگہ
- ذخیرہ
- کی نمائندگی
- نمائندگی
- درخواست
- درخواستوں
- ضرورت
- تحقیق
- محقق
- وسائل
- بالترتیب
- جواب
- جوابات
- ذمہ دار
- نتیجے
- نتائج کی نمائش
- واپسی
- کا جائزہ لینے کے
- جائزہ لیں
- مضبوط
- رولنگ
- شاہی
- رن
- روس
- sagemaker
- اسکیل ایبلٹی
- توسیع پذیر
- پیمانے
- منظرنامے
- سائنسدان
- سائنسدانوں
- سکرپٹ
- sdk
- تلاش کریں
- تلاش
- SEC
- ایس ای سی فائلنگ۔
- دوسری
- سیکشن
- سیکورٹی
- دیکھنا
- سینئر
- بھیجا
- سزا
- جذبات
- علیحدہ
- تسلسل
- سیریز
- سیریز اے
- سروس
- سروسز
- مقرر
- قائم کرنے
- ترتیبات
- کئی
- مختصر
- ہونا چاہئے
- دکھائیں
- دکھایا گیا
- شوز
- اہم
- سادہ
- بعد
- ایک
- سائز
- ٹکڑا
- So
- سوسائٹی
- سافٹ ویئر کی
- سوفٹ ویئر کی نشوونما
- سافٹ ویئر ڈویلپمنٹ کٹ
- سافٹ ویئر انجینئرنگ
- حل
- حل
- حل کرنا۔
- کچھ
- اس
- ماخذ
- جنوبی
- سوویت
- خلا
- خصوصی
- مخصوص
- خاص طور پر
- نردجیکرن
- مخصوص
- خرچ کرنا۔
- تقسیم
- سٹاف
- شروع کریں
- شروع
- حالت
- شماریات
- درجہ
- اسٹیئرنگ
- مرحلہ
- مراحل
- رک جاتا ہے
- ذخیرہ
- منظم
- طلباء
- تعلیم حاصل کی
- مطالعہ
- سٹوڈیو
- کامیابی کے ساتھ
- اس طرح
- حمایت
- تائید
- اس بات کا یقین
- سوئٹزرلینڈ
- کے نظام
- سسٹمز
- ٹیبل
- موزوں
- ٹاسک
- کاموں
- پڑھانا
- ٹیم
- ٹیکنیکل
- تکنیک
- تکنیک
- ٹیکنالوجی
- سانچے
- ٹینیسی
- شرائط
- ٹیسٹ
- متن
- متن کی درجہ بندی
- متن کی نسل
- سے
- کہ
- ۔
- علاقہ
- دارالحکومت
- تھیٹر
- ان
- ان
- تو
- وہاں.
- یہ
- وہ
- سوچنا
- تیسری پارٹی
- اس
- ان
- کے ذریعے
- تھرو پٹ
- باگھوں
- وقت
- اوقات
- کرنے کے لئے
- آج
- ٹوکن
- ٹوکن
- اوزار
- کل
- ٹرین
- تربیت یافتہ
- ٹریننگ
- ٹرانسفارمر
- ترجمہ
- سچ
- کوشش
- یکے بعد دیگرے دو
- دو
- قسم
- ui
- کے تحت
- بنیادی
- منفرد
- یونیورسٹیاں
- یونیورسٹی
- جب تک
- اپ ڈیٹ کریں
- تازہ ترین معلومات
- استعمال
- استعمال کی شرائط
- استعمال کیس
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- استعمال
- کا استعمال کرتے ہوئے
- استعمال کرتا ہے
- ازبکستان
- توثیق
- قیمت
- مختلف اقسام کے
- مختلف
- ورژن
- بہت
- کی طرف سے
- لنک
- بیل
- بصری
- چلنا
- چاہتے ہیں
- جنگ
- تھا
- طریقوں
- we
- ویب
- ویب خدمات
- ویب پر مبنی ہے
- چلا گیا
- تھے
- جب
- جس
- جبکہ
- ڈبلیو
- گے
- شراب
- ساتھ
- وون
- لفظ
- الفاظ
- کام
- کام کیا
- کام کر
- کام کرتا ہے
- ورکشاپ
- دنیا
- گا
- لکھنا
- سال
- یوگا
- آپ
- اور
- نوجوان
- زیفیرنیٹ
- Zeus