Welcome to the era of data. The sheer volume of data captured daily continues to grow, calling for platforms and solutions to evolve. Services such as ایمیزون سادہ اسٹوریج سروس (Amazon S3) offer a scalable solution that adapts yet remains cost-effective for growing datasets. The ایمیزون پائیداری ڈیٹا انیشی ایٹو (ASDI) uses the capabilities of Amazon S3 to provide a no-cost solution for you to store and share climate science workloads across the globe. Amazon’s Open Data Sponsorship Program allows organizations to host free of charge on AWS.
Over the last decade, we’ve seen a surge in data science frameworks coming to fruition, along with mass adoption by the data science community. One such framework is ڈسک, which is powerful for its ability to provision an orchestration of worker compute nodes, thereby accelerating complex analysis on large datasets.
In this post, we show you how to deploy a custom AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK) solution that extends Dask’s functionality to work inter-Regionally across Amazon’s global network. The AWS CDK solution deploys a network of Dask workers across two AWS Regions, connecting into a client Region. For more information, refer to Guidance for Distributed Computing with Cross Regional Dask on AWS اور GitHub repo for open-source code.
After deployment, the user will have access to a Jupyter notebook, where they can interact with two datasets from ASDI on AWS: Coupled Model Intercomparison Project 6 (CMIP6) اور ECMWF ERA5 Reanalysis. CMIP6 focuses on the sixth phase of global coupled ocean-atmosphere general circulation model ensemble; ERA5 is the fifth generation of ECMWF atmospheric reanalyses of the global climate, and the first reanalysis produced as an operational service.
This solution was inspired by work with a key AWS customer, the برطانیہ کے میٹ آفس. The Met Office was founded in 1854 and is the national meteorological service for the UK. They provide weather and climate predictions to help you make better decisions to stay safe and thrive. A collaboration between the Met Office and EUMETSAT, detailed in Data Proximate Computation on a Dask Cluster Distributed Between Data Centres, highlights the growing need to develop a sustainable, efficient, and scalable data science solution. This solution achieves this by bringing compute closer to the data, rather than forcing the data to come closer to compute resources, which adds cost, latency, and energy.
حل جائزہ
Each day, the UK Met Office produces up to 300 TB of weather and climate data, a portion of which is published to ASDI. These datasets are distributed across the world and hosted for public use. The Met Office would like to enable consumers to make the more of their data to help inform critical decisions on addressing issues such as better preparation for climate change-induced wildfires and floods, and reducing food insecurity through better crop yield analysis.
Traditional solutions in use today, particularly with climate data, are time consuming and unsustainable, replicating datasets cross Regions. Unnecessary data transfer on the petabyte scale is costly, slow, and consumes energy.
We estimated that if this practice were adopted by the Met Office users, the equivalent of 40 homes’ daily power consumption could be saved every day, and they could also reduce the transfer of data between regions.
مندرجہ ذیل خاکہ حل کے فن تعمیر کی وضاحت کرتا ہے۔
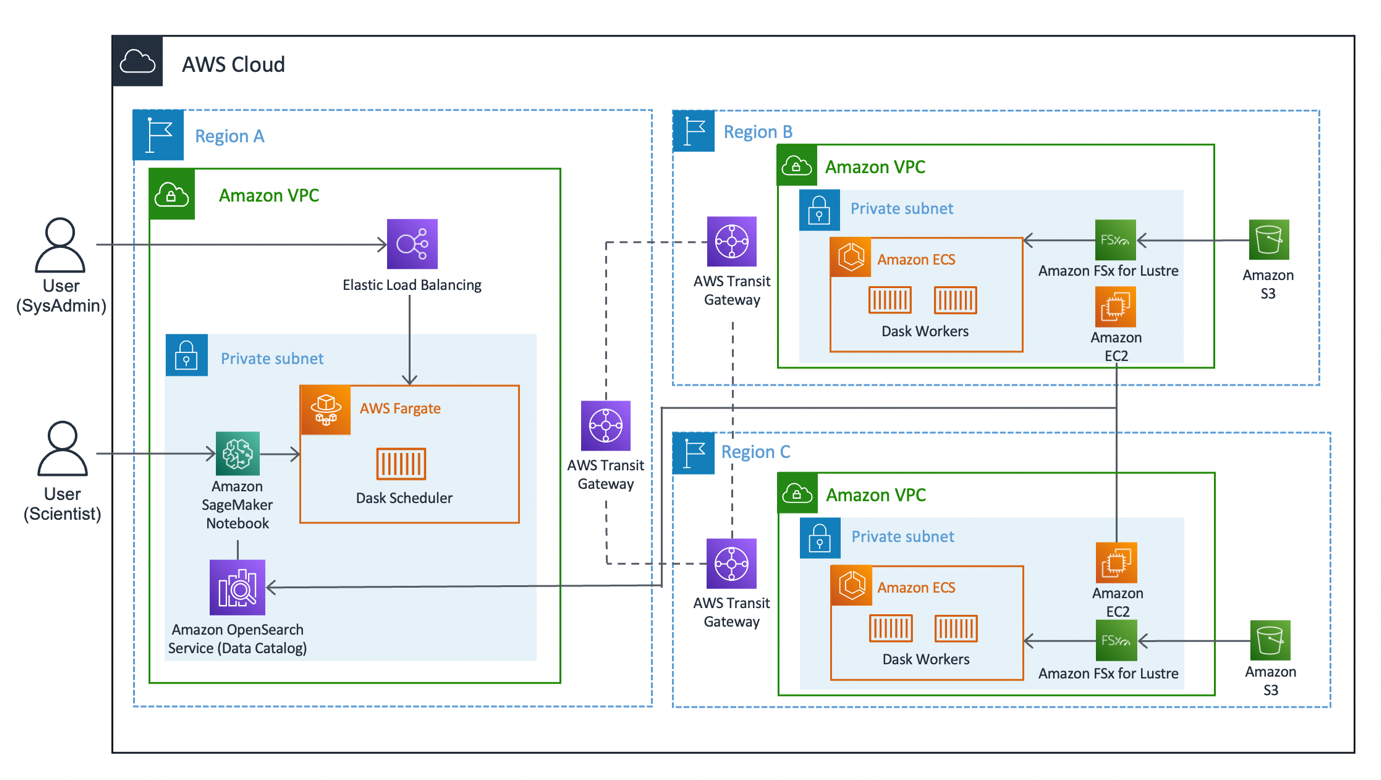
The solution can be broken into three major segments: client, workers, and network. Let’s dive into each and see how they come together.
کلائنٹ
The client represents the source Region where data scientists connect. This Region (Region A in the diagram) contains an ایمیزون سیج میکر نوٹ بکایک ایمیزون اوپن سرچ سروس domain, and a Dask scheduler as key components. System administrators have access to the built-in Dask dashboard exposed via an لچکدار لوڈ بیلنسر.
Data scientists have access to the Jupyter notebook hosted on SageMaker. The notebook is able to connect and run workloads on the Dask scheduler. The OpenSearch Service domain stores metadata on the datasets connected at the Regions. Notebook users can query this service to retrieve details such as the correct Region of Dask workers without needing to know the data’s Regional location beforehand.
کارکن
Each of the worker Regions (Regions B and C in the diagram) is comprised of an ایمیزون لچکدار کنٹینر سروس (Amazon ECS) cluster of Dask workersایک ایمیزون ایف ایس ایکس لسٹر file system, and a standalone ایمیزون لچکدار کمپیوٹ کلاؤڈ (Amazon EC2) instance. FSx for Lustre allows Dask workers to access and process Amazon S3 data from a high-performance file system by linking your file systems to S3 buckets. It provides sub-millisecond latencies, up to hundreds of GBs/s of throughput, and millions of IOPS. A key feature of Lustre is that only the file system’s metadata is synced. Lustre manages the balance of files to be loaded in and kept warm, based on demand.
Worker clusters scale based on CPU usage, provision additional workers in extended periods of demand, and scale down as resources become idle.
Each night at 0:00 UTC, a data sync job prompts the Lustre file system to resync with the attached S3 bucket, and pulls an up-to-date metadata catalog of the bucket. Subsequently, the standalone EC2 instance pushes these updates into OpenSearch Service respective to that Region’s index. OpenSearch Service provides the necessary information to the client as to which pool of workers should be called upon for a particular dataset.
نیٹ ورک
Networking forms the crux of this solution, utilizing Amazon’s internal backbone network. By using AWS ٹرانزٹ گیٹ وے, we’re able to connect each of the Regions to each other without needing to traverse the public internet. Each of the workers are able to connect dynamically into the Dask scheduler, allowing data scientists to run inter-regional queries through Dask.
شرائط
The AWS CDK package uses the TypeScript programming language. Follow the steps in Getting Started for AWS CDK to set up your local environment and bootstrap your development account (you’ll need to bootstrap all Regions specified in the GitHub repo).
For a successful deployment, you’ll need ڈوکر انسٹال ہوا۔ and running on your local machine.
Deploy the AWS CDK package
Deploying an AWS CDK package is straightforward. After you install the prerequisites and bootstrap your account, you can proceed with downloading the code base.
- ڈاؤن لوڈ، اتارنا GitHub ذخیرہ:
- Install node modules:
- Deploy the AWS CDK:
The stack can take over an hour and a half to deploy.
کوڈ واک تھرو
In this section, we inspect some of the key features of the code base. If you’d like to inspect the full code base, refer to the GitHub ذخیرہ.
Configure and customize your stack
فائل میں bin/variables.ts, you’ll find two variable declarations: one for the client and one for workers. The client declaration is a dictionary with a reference to a Region and CIDR range. Customizing these variables will change both the Region and CIDR range of where client resources will deploy.
The worker variable copies this same functionality; however, it’s a list of dictionaries to accommodate adding or subtracting datasets the user wishes to include. Additionally, each dictionary contains the added fields of dataset اور lustreFileSystemPath. Dataset is used to specify the connecting S3 URI for Lustre to connect to. The lustreFileSystemPath variable is used as a mapping for how the user wants that dataset to map locally on the worker file system. See the following code:
Dynamically publish the scheduler IP
A challenge inherent to the cross-Regional nature of this project was maintaining a dynamic connection between the Dask workers and the scheduler. How could we publish an IP address, which is capable of changing, across AWS Regions? We were able to accomplish this through the use of AWS Cloud Map اور associate-vpc-with-hosted-zone. The service abstracts allowing AWS to manage this DNS namespace privately. See the following code:
Jupyter notebook UI
The Jupyter notebook hosted on SageMaker provides scientists with a ready-made environment for deployment to easily connect and experiment on the loaded datasets. We used a لائف سائیکل کنفیگریشن اسکرپٹ to provision the notebook with a preconfigured developer environment and example code base. See the following code:
Dask worker nodes
When it comes to the Dask workers, greater customizability is provided, more specifically on instance type, threads per container, and scaling alarms. By default, the workers provision on instance type m5d.4xlarge, mount to the Lustre file system on launch, and subdivide its workers and threads dynamically to ports. All this is optionally customizable. See the following code:
کارکردگی
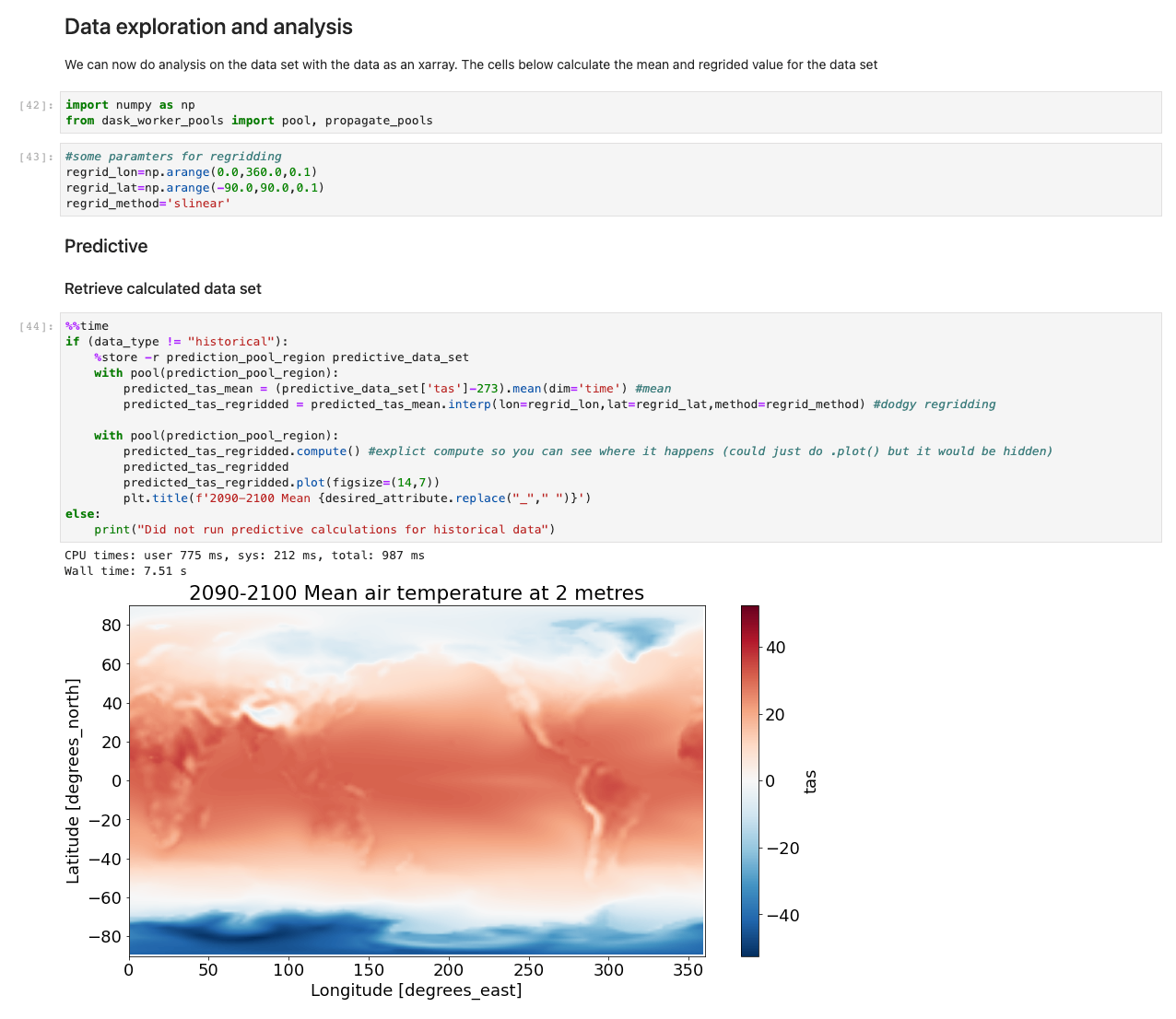
To assess performance, we use a sample computation and plotting of air temperature at 2 meters based on the difference between CMIP6 prediction for a month and ERA5 mean air temperature for 10 years. We set a benchmark of two workers in each Region and assess the difference in time reduction as additional workers were added. In theory, as the solution scales, there should be a productive material difference in reducing overall time.
The following table summarizes our dataset details.
| ڈیٹا بیس | متغیرات | ڈسک کا سائز | Xarray Dataset Size | ریجن |
| ایرا 5 | 2011–2020 (120 netcdf files) | 53.5GB | 364.1 GB | us-east-1 |
| CMIP6 | 1.13GB | 0.11 GB | us-west-2 |
The following table shows the results collected, showcasing the time (in seconds) for each computation and prediction in three stages in computing CMIP6 prediction, ERA5, and difference.
| . | . | کارکنوں کی تعداد | |||
| کمپیوٹنگ | ریجن | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
us-west-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-east-1 | 1512 | 711 | 427 | 202 |
فرق (propogated pool) |
us-west-2 and us-east-1 | 1527 | 906 | 469 | 251 |
The following graph visualizes the performance and scale.
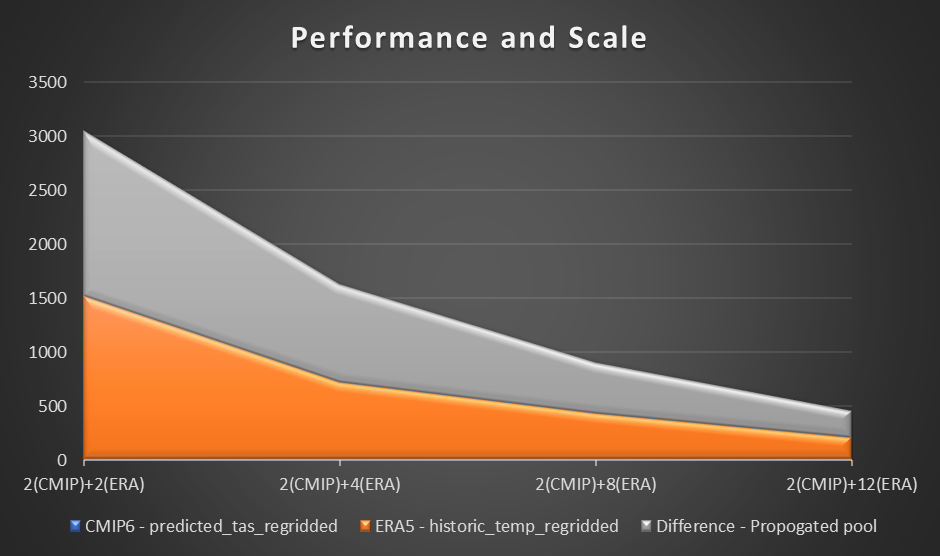
From our experiment, we observed a linear improvement on computation for the ERA5 dataset as the number of workers increased. As the numbers of workers increased, computation times were at times halved.
Jupyter نوٹ بک
As part of the solution launch, we deploy a preconfigured Jupyter notebook to help test the cross-Regional Dask solution. The notebook demonstrates the removed worry of needing to know the Regional location of datasets, instead querying a catalog through a series of Jupyter notebooks running in the background.
To get started, follow the instructions in this section.
The code for the notebooks can be found in lib/SagemakerCode with the primary notebook being ux_notebook.ipynb. This notebook calls upon other notebooks, triggering helper scripts. ux_notebook is designed to be the entry point for scientists, without the need for going elsewhere.
To get started, open this notebook in SageMaker after you have deployed the AWS CDK. The AWS CDK creates a notebook instance with all of the files in the repository loaded and backed up to an AWS CodeCommit ذخیرہ.
To run the application, open and run the first cell of ux_notebook. This cell runs the get_variables notebook in the background, which prompts you for an input for the data you would like to select. We include an example; however, note that questions will only appear after the previous option has been selected. This is intentional in limiting the drop-down choices and is optionally configurable by editing the get_variables کاپی.
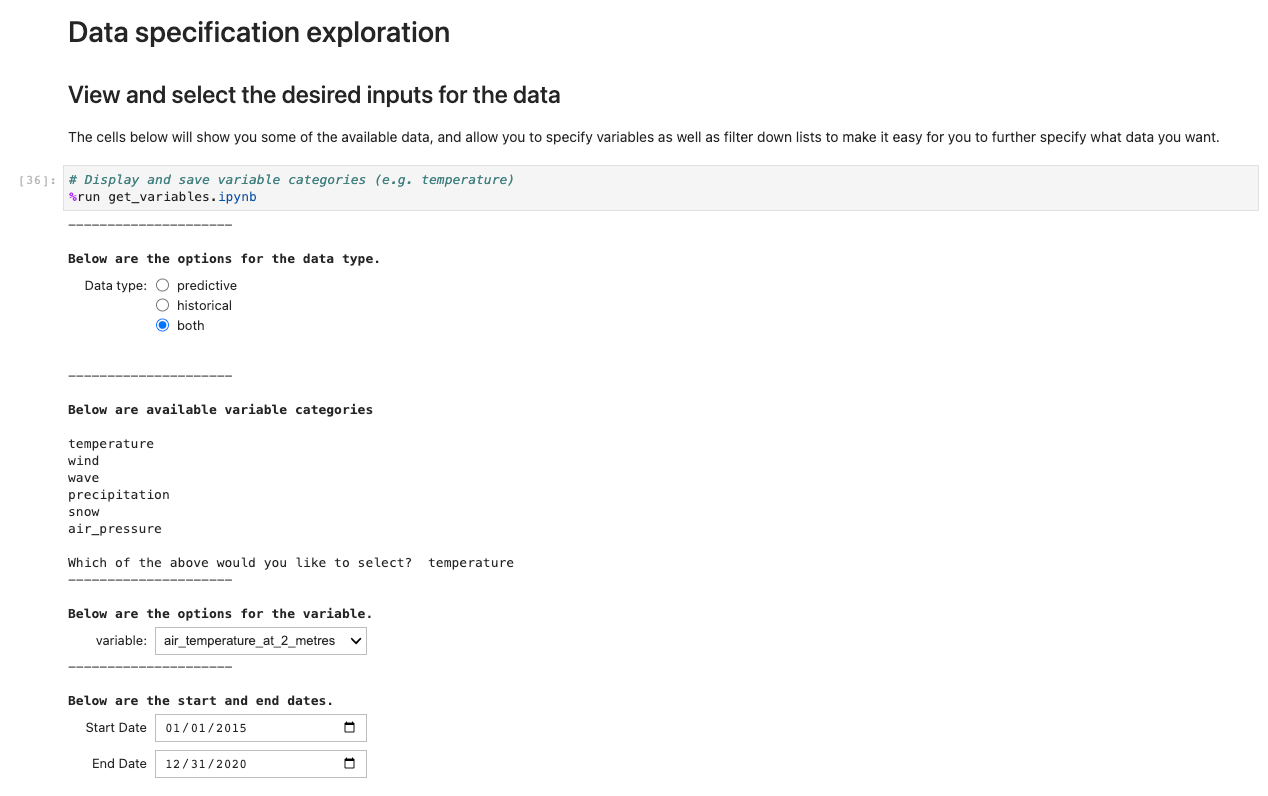
The preceding code stores variables globally so that other notebooks can retrieve and load your selection of choices. For demonstration, the next cell should output the save variables from before.
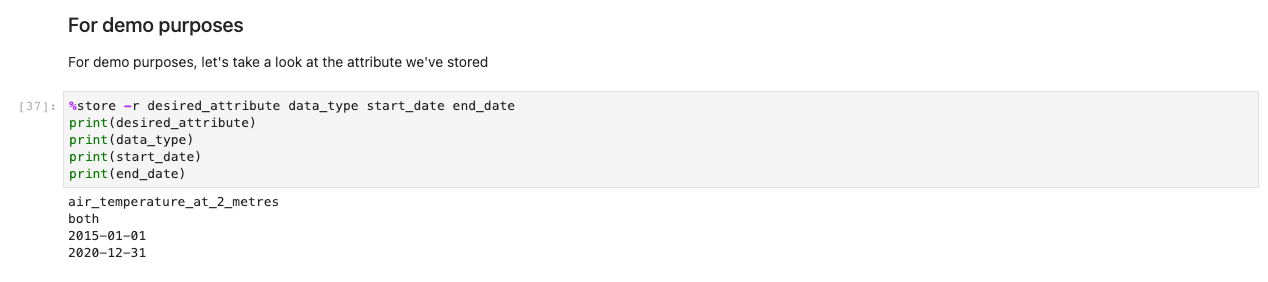
Next, a prompt for further data specifications appears. This cell refines the data you’re after by presenting the IDs of tables in human-readable format. Users select as if it were a form, but the titles map to tables in the background that help the system retrieve the appropriate datasets.
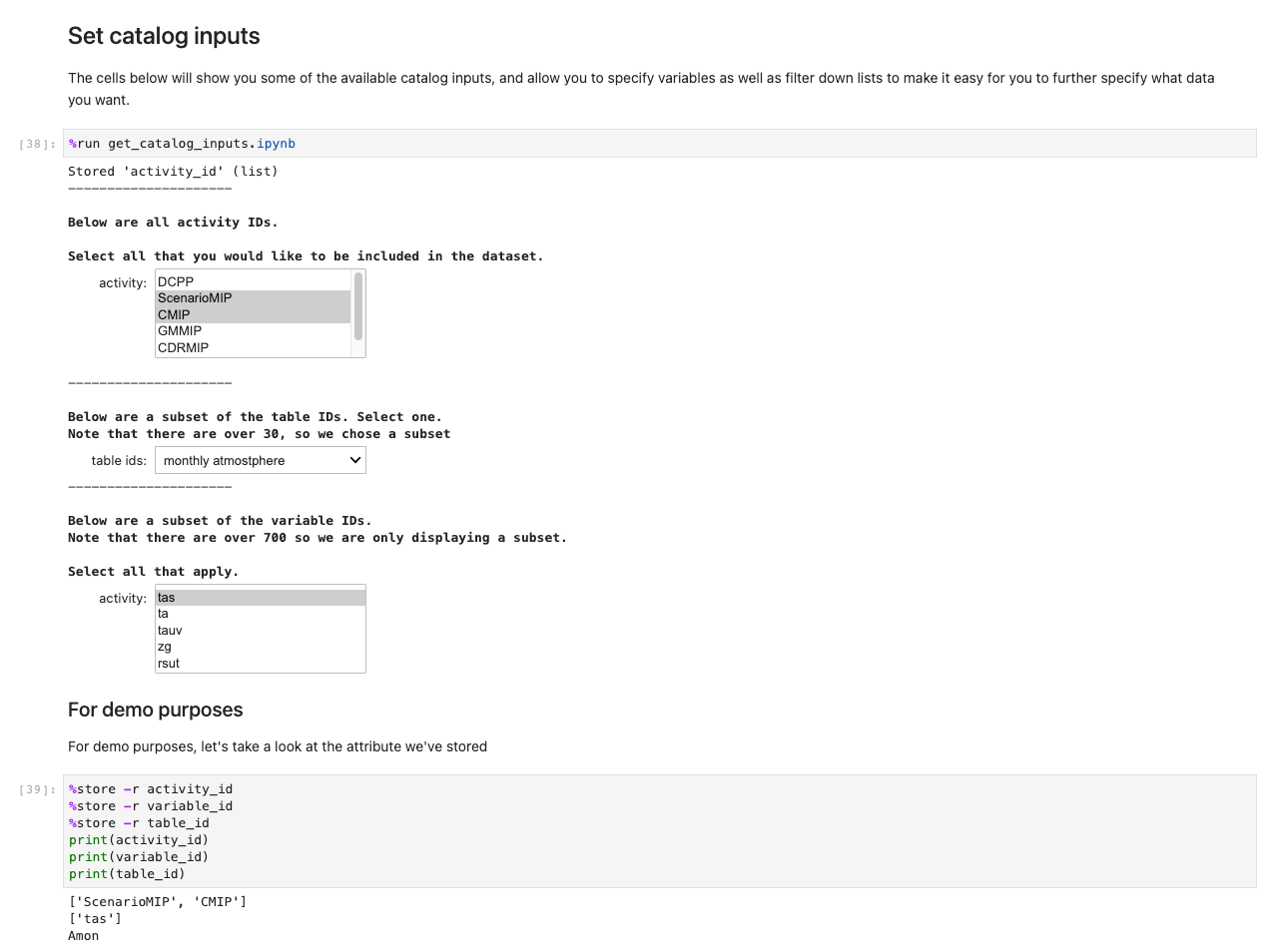
After you have stored all your choices and selection cells, load the data into the Regions by running the cell in the ڈیٹا حاصل کرنا مقرر section. The %%capture command will suppress unnecessary outputs from the get_data notebook. Note you may remove this to inspect outputs from the other notebooks. Data is then retrieved in the backend.
While other notebooks are being run in the background, the only touchpoint for the user is the ux_notebook. This is to abstract the tedious process of importing data into a format any user is able to follow with ease.
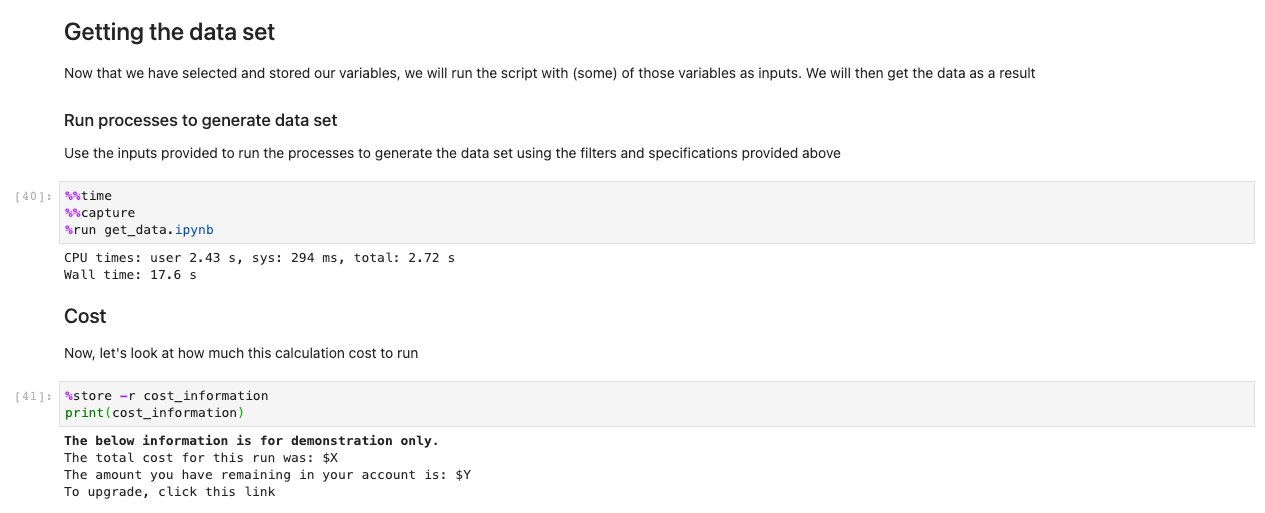
With the data now loaded, we can start interacting with it. The following cells are examples of calculations you may run on weather data. Using xarrays, we import, calculate, and then plot those datasets.
Our sample illustrates a plot of predictive data retrieving data, running the computation, and plotting the results in under 7.5 seconds—orders of magnitude faster than a typical approach.
ٹوپی کے نیچے
The notebooks get_catalog_input اور get_variables use the library ipywidgets to display widgets such as drop-downs and multi-box selections. These options are saved globally using the %%store command so that they can be accessed from the ux_notebook. One of the options prompts you on whether you want historical data, predictive data, or both. This variable is passed to the get_data notebook to determine which subsequent notebooks to run.
۔ get_data notebook first retrieves the shared OpenSearch Service domain saved to AWS سسٹمز مینیجر پیرامیٹر اسٹور. This domain allows our notebook to run a query on collecting information that will indicate where the selected datasets are stored Regionally. With those datasets located Regionally, the notebook will make a connection attempt to the Dask scheduler, passing the information collected from OpenSearch Service. The Dask scheduler in turn will be able to call on workers in the correct Regions.
How to customize and continue development
These notebooks are meant to be an example of how you can create a way for users to interface and interact with the data. The notebook in this post serves as an illustration for what’s possible, and we invite you to continue building upon the solution to further improve user engagement. The core part of this solution is the backend technology, but without some mechanism to interact with that backend, users won’t realize the full potential of the solution.
To avoid incurring future charges, delete the resources. Let’s destroy our deployed solution with the following command:
نتیجہ
This post showcases the extension of Dask inter-Regionally on AWS, and a possible integration with public datasets on AWS. The solution was built as a generic pattern, and further datasets can be loaded in to accelerate high I/O analyses on complex data.
Data is transforming every field and every business. However, with data growing faster than most companies can keep track of, collecting data and getting value out of that data is challenging. A modern data strategy can help you create better business outcomes with data. AWS provides the most complete set of services for the end-to-end data journey to help you unlock value from your data and turn it into insight.
To learn more about the various ways to use your data on the cloud, visit the AWS بگ ڈیٹا بلاگ. We further invite you to comment with your thoughts on this post, and whether this is a solution you plan on trying out.
مصنفین کے بارے میں
 پیٹرک او کونر is a WWSO Prototyping Engineer based in London. He is a creative problem-solver, adaptable across a wide range of technologies, such as IoT, serverless tech, 3D spatial tech, and ML/AI, along with a relentless curiosity on how technology can continue to evolve everyday approaches.
پیٹرک او کونر is a WWSO Prototyping Engineer based in London. He is a creative problem-solver, adaptable across a wide range of technologies, such as IoT, serverless tech, 3D spatial tech, and ML/AI, along with a relentless curiosity on how technology can continue to evolve everyday approaches.
 Chakra Nagarajan is a Principal Machine Learning Prototyping SA with 21 years of experience in machine learning, big data, and high-performance computing. In his current role, he helps customers solve real-world complex business problems by building prototypes with end-to-end AI/ML solutions in cloud and edge devices. His ML specialization includes computer vision, natural language processing, time series forecasting, and personalization.
Chakra Nagarajan is a Principal Machine Learning Prototyping SA with 21 years of experience in machine learning, big data, and high-performance computing. In his current role, he helps customers solve real-world complex business problems by building prototypes with end-to-end AI/ML solutions in cloud and edge devices. His ML specialization includes computer vision, natural language processing, time series forecasting, and personalization.
 Val Cohen is a senior WWSO Prototyping Engineer based in London. A problem solver by nature, Val enjoys writing code to automate processes, build customer obsessed tools, and create infrastructure for various applications for her global customer base. Val has experience across a wide variety of technologies, such as front-end web development, backend work, and AI/ML.
Val Cohen is a senior WWSO Prototyping Engineer based in London. A problem solver by nature, Val enjoys writing code to automate processes, build customer obsessed tools, and create infrastructure for various applications for her global customer base. Val has experience across a wide variety of technologies, such as front-end web development, backend work, and AI/ML.
 Niall Robinson is Head of product futures at the UK Met Office. He and his team explore new ways the Met Office can provide value through product innovation and strategic partnerships. He’s had a varied career, leading a multidisciplinary informatics R&D team, academic research in data science, and field scientist along with climate modeler expertise.
Niall Robinson is Head of product futures at the UK Met Office. He and his team explore new ways the Met Office can provide value through product innovation and strategic partnerships. He’s had a varied career, leading a multidisciplinary informatics R&D team, academic research in data science, and field scientist along with climate modeler expertise.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹوآئ اسٹریم۔ ویب 3 ڈیٹا انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ایڈریین ایشلے کے ساتھ مستقبل کا نقشہ بنانا۔ یہاں تک رسائی حاصل کریں۔
- PREIPO® کے ساتھ PRE-IPO کمپنیوں میں حصص خریدیں اور بیچیں۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- : ہے
- : ہے
- :کہاں
- $UP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- کی صلاحیت
- قابلیت
- ہمارے بارے میں
- اوپر
- خلاصہ
- خلاصہ
- تعلیمی
- تعلیمی تحقیق
- رفتار کو تیز تر
- تیز
- تک رسائی حاصل
- رسائی
- ایڈجسٹ کریں
- پورا
- اکاؤنٹ
- حاصل کرتا ہے
- کے پار
- موافقت کرتا ہے
- شامل کیا
- انہوں نے مزید کہا
- ایڈیشنل
- اس کے علاوہ
- پتہ
- خطاب کرتے ہوئے
- جوڑتا ہے
- منتظمین
- اپنایا
- منہ بولابیٹا بنانے
- کے بعد
- AI / ML
- AIR
- تمام
- اجازت دے رہا ہے
- کی اجازت دیتا ہے
- ساتھ
- بھی
- ایمیزون
- ایمیزون EC2
- an
- تجزیہ
- اور
- کوئی بھی
- ظاہر
- درخواست
- ایپلی کیشنز
- نقطہ نظر
- نقطہ نظر
- مناسب
- فن تعمیر
- کیا
- AS
- At
- ماحول
- وایمنڈلیی
- خود کار طریقے سے
- سے اجتناب
- AWS
- AWS کسٹمر
- ریڑھ کی ہڈی
- حمایت کی
- پسدید
- پس منظر
- متوازن
- بیس
- کی بنیاد پر
- BE
- بن
- رہا
- اس سے پہلے
- کیا جا رہا ہے
- نیچے
- معیار
- بہتر
- کے درمیان
- بگ
- بگ ڈیٹا
- بوٹسٹریپ
- دونوں
- آ رہا ہے
- ٹوٹ
- تعمیر
- عمارت
- تعمیر
- تعمیر میں
- کاروبار
- لیکن
- by
- حساب
- فون
- کہا جاتا ہے
- بلا
- کالز
- کر سکتے ہیں
- صلاحیتوں
- صلاحیت رکھتا
- کیریئر کے
- کیٹلوگ
- CD
- خلیات
- چیلنج
- چیلنج
- تبدیل
- تبدیل کرنے
- چارج
- بوجھ
- انتخاب
- سرکولیشن
- کلائنٹ
- آب و ہوا
- قریب
- بادل
- کلسٹر
- CO
- کوڈ
- کوڈ بیس
- تعاون
- جمع
- کس طرح
- آتا ہے
- آنے والے
- تبصرہ
- کمیونٹی
- کمپنیاں
- مکمل
- پیچیدہ
- اجزاء
- پر مشتمل
- حساب
- کمپیوٹنگ
- کمپیوٹر
- کمپیوٹر ویژن
- کمپیوٹنگ
- ترتیب
- رابطہ قائم کریں
- منسلک
- مربوط
- کنکشن
- صارفین
- کھپت
- کنٹینر
- پر مشتمل ہے
- جاری
- جاری ہے
- کاپیاں
- کور
- درست
- قیمت
- سرمایہ کاری مؤثر
- سکتا ہے
- مل کر
- CPU
- تخلیق
- پیدا
- تخلیقی
- اہم
- فصل
- پار
- تجسس
- موجودہ
- اپنی مرضی کے
- گاہک
- گاہکوں
- مرضی کے مطابق
- اپنی مرضی کے مطابق
- روزانہ
- ڈیش بورڈ
- اعداد و شمار
- ڈیٹا سائنس
- ڈیٹا کی حکمت عملی
- ڈیٹاسیٹس
- دن
- دہائی
- فیصلے
- پہلے سے طے شدہ
- ڈیمانڈ
- ثبوت
- تعیناتی
- تعینات
- تعیناتی
- تعینات کرتا ہے
- ڈیزائن
- تباہ
- تفصیلی
- تفصیلات
- اس بات کا تعین
- ترقی
- ڈیولپر
- ترقی
- کے الات
- فرق
- غیر فعال کر دیا
- دریافت
- دکھائیں
- تقسیم کئے
- تقسیم کمپیوٹنگ
- DNS
- میں Docker
- ڈومین
- نیچے
- متحرک
- متحرک طور پر
- ہر ایک
- کو کم
- آسانی سے
- ایج
- ترمیم
- ہنر
- دوسری جگہوں پر
- کو چالو کرنے کے
- آخر سے آخر تک
- توانائی
- مصروفیت
- انجینئر
- اندراج
- ماحولیات
- مساوی
- دور
- اندازے کے مطابق
- Ether (ETH)
- ہر کوئی
- ہر روز
- كل يوم
- تیار
- مثال کے طور پر
- مثال کے طور پر
- تجربہ
- تجربہ
- مہارت
- تلاش
- برآمد
- ظاہر
- مدت ملازمت میں توسیع
- تیز تر
- نمایاں کریں
- خصوصیات
- میدان
- قطعات
- فائل
- فائلوں
- مل
- پہلا
- توجہ مرکوز
- پر عمل کریں
- کے بعد
- کھانا
- کے لئے
- فارم
- فارمیٹ
- فارم
- ملا
- قائم
- فریم ورک
- فریم ورک
- مفت
- سے
- نتیجہ
- مکمل
- فعالیت
- مزید
- مستقبل
- فیوچرز
- جنرل
- نسل
- حاصل
- حاصل کرنے
- جاؤ
- گلوبل
- عالمی نیٹ ورک
- عالمی سطح پر
- دنیا
- جا
- گراف
- زیادہ سے زیادہ
- گرڈ
- بڑھائیں
- بڑھتے ہوئے
- تھا
- نصف
- حل
- ہے
- he
- سر
- مدد
- مدد کرتا ہے
- اس کی
- ہائی
- اعلی کارکردگی
- پر روشنی ڈالی گئی
- ان
- تاریخی
- میزبان
- میزبانی کی
- گھنٹہ
- کس طرح
- کیسے
- تاہم
- HTML
- HTTPS
- انسانی پڑھنے کے قابل
- سینکڑوں
- ناقابل یقین
- شناخت
- if
- وضاحت کرتا ہے
- درآمد
- درآمد
- کو بہتر بنانے کے
- بہتری
- in
- شامل
- شامل ہیں
- اضافہ
- انڈکس
- اشارہ کرتے ہیں
- مطلع
- معلومات
- انفراسٹرکچر
- ذاتی، پیدائشی
- جدت طرازی
- ان پٹ
- عدم تحفظ
- بصیرت
- متاثر
- انسٹال
- مثال کے طور پر
- کے بجائے
- ہدایات
- انضمام
- جان بوجھ کر
- بات چیت
- بات چیت
- انٹرفیس
- اندرونی
- انٹرنیٹ
- میں
- مدعو
- IOT
- IP
- IP ایڈریس
- مسائل
- IT
- میں
- ایوب
- سفر
- فوٹو
- Jupyter نوٹ بک
- رکھیں
- کلیدی
- جان
- زبان
- بڑے
- آخری
- تاخیر
- شروع
- معروف
- جانیں
- سیکھنے
- لائبریری
- زندگی کا دورانیہ
- کی طرح
- لنکڈ
- منسلک
- لسٹ
- لوڈ
- مقامی
- مقامی طور پر
- واقع ہے
- محل وقوع
- لندن
- مشین
- مشین لرننگ
- اہم
- بنا
- انتظام
- مینیجر
- انتظام کرتا ہے
- نقشہ
- تعریفیں
- ماس
- بڑے پیمانے پر اپنانے
- مواد
- مئی..
- مطلب
- میکانزم
- میٹا ڈیٹا
- لاکھوں
- ML
- ماڈل
- جدید
- ماڈیولز
- مہینہ
- ماہانہ
- ماہانہ ڈیٹا
- زیادہ
- سب سے زیادہ
- چڑھکر
- کثیر مضامین
- نام
- قومی
- قدرتی
- قدرتی زبان
- قدرتی زبان عملیات
- فطرت، قدرت
- ضروری
- ضرورت ہے
- ضرورت ہے
- نیٹ ورک
- نئی
- اگلے
- رات
- نوڈ
- نوڈس
- نوٹ بک
- نوٹ بک
- اب
- تعداد
- تعداد
- of
- پیش کرتے ہیں
- دفتر
- on
- ایک
- صرف
- کھول
- کھولیں ڈیٹا
- اوپن سورس
- اوپن سورس کوڈ
- آپریشنل
- اختیار
- آپشنز کے بھی
- or
- آرکیسٹرا
- تنظیمیں
- دیگر
- ہمارے
- باہر
- نتائج
- پیداوار
- پر
- مجموعی طور پر
- پیکج
- پیرامیٹر
- حصہ
- خاص طور پر
- خاص طور پر
- شراکت داری
- منظور
- پاسنگ
- پاٹرن
- کارکردگی
- ادوار
- شخصی
- پیٹا بائٹ
- مرحلہ
- منصوبہ
- پلیٹ فارم
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- پوائنٹ
- پول
- بندرگاہوں
- ممکن
- پوسٹ
- ممکنہ
- طاقت
- طاقتور
- پریکٹس
- کی پیشن گوئی
- پیشن گوئی
- ضروریات
- پچھلا
- پرائمری
- پرنسپل
- نجی
- مسئلہ
- مسائل
- عمل
- عمل
- پروسیسنگ
- تیار
- مصنوعات
- پروڈکٹ انوویشن
- پیداواری
- پروگرام
- پروگرامنگ
- منصوبے
- prototypes
- prototyping کے
- فراہم
- فراہم
- فراہم کرتا ہے
- پراجیکٹ
- عوامی
- شائع
- شائع
- ھیںچتی
- سوالات
- سوالات
- آر اینڈ ڈی
- رینج
- بلکہ
- ریڈی میڈ
- حقیقی دنیا
- احساس
- کو کم
- کو کم کرنے
- کمی
- خطے
- علاقائی
- خطوں
- بے حد
- باقی
- ہٹا
- ہٹا دیا گیا
- ذخیرہ
- کی نمائندگی کرتا ہے
- تحقیق
- وسائل
- متعلقہ
- نتائج کی نمائش
- کردار
- رن
- چل رہا ہے
- SA
- محفوظ
- sagemaker
- اسی
- محفوظ کریں
- توسیع پذیر
- پیمانے
- ترازو
- سکیلنگ
- سائنس
- سائنسدان
- سائنسدانوں
- سکرپٹ
- سیکنڈ
- سیکشن
- دیکھنا
- دیکھا
- حصوں
- منتخب
- انتخاب
- سینئر
- سیریز
- بے سرور
- کام کرتا ہے
- سروس
- سروسز
- مقرر
- سیکنڈ اور
- مشترکہ
- ہونا چاہئے
- دکھائیں
- نمائش
- شوز
- سادہ
- صرف
- چھٹی
- سست
- So
- حل
- حل
- حل
- کچھ
- ماخذ
- مقامی
- خاص طور پر
- وضاحتیں
- مخصوص
- اسپانسر شپ
- ڈھیر لگانا
- مراحل
- اسٹینڈ
- شروع کریں
- شروع
- رہنا
- مراحل
- ذخیرہ
- ذخیرہ
- ذخیرہ
- پردہ
- براہ راست
- حکمت عملی
- اسٹریٹجک پارٹنرشپ
- حکمت عملی
- بعد میں
- بعد میں
- کامیاب
- اس طرح
- سطح
- اضافے
- پائیداری
- پائیدار
- کے نظام
- سسٹمز
- ٹیبل
- لے لو
- ٹیم
- ٹیک
- ٹیکنالوجی
- ٹیکنالوجی
- ٹیسٹ
- سے
- کہ
- ۔
- کے بارے میں معلومات
- ماخذ
- برطانیہ
- دنیا
- ان
- تو
- وہاں.
- اس طرح
- یہ
- وہ
- اس
- ان
- تین
- ترقی کی منازل طے
- کے ذریعے
- تھرو پٹ
- وقت
- وقت کا سلسلہ
- اوقات
- عنوانات
- کرنے کے لئے
- آج
- مل کر
- اوزار
- ٹریک
- ٹریکنگ
- منتقل
- تبدیل
- ٹرانزٹ
- ٹرگر
- ٹرن
- دو
- قسم
- ٹائپ اسکرپٹ
- ٹھیٹھ
- Uk
- کے تحت
- انلاک
- ناممکن
- اپ ڈیٹ کرنے کے لئے
- تازہ ترین معلومات
- صلی اللہ علیہ وسلم
- URI
- استعمال
- استعمال کی شرائط
- استعمال کیا جاتا ہے
- رکن کا
- صارفین
- کا استعمال کرتے ہوئے
- UTC کے مطابق ھیں
- استعمال کرنا۔
- ویل
- قیمت
- مختلف اقسام کے
- مختلف
- کی طرف سے
- نقطہ نظر
- دورہ
- حجم
- چاہتے ہیں
- چاہتا ہے
- گرم
- تھا
- راستہ..
- طریقوں
- we
- موسم
- ویب
- ویب سازی
- تھے
- چاہے
- جس
- وسیع
- وسیع رینج
- گے
- خواہشات
- ساتھ
- بغیر
- کام
- کارکن
- کارکنوں
- دنیا
- فکر
- گا
- تحریری طور پر
- سال
- ابھی
- پیداوار
- آپ
- اور
- زیفیرنیٹ