ایک میں ملتے جلتے کالم تلاش کرنا ڈیٹا جھیل ڈیٹا کی صفائی اور تشریح، اسکیما میچنگ، ڈیٹا کی دریافت، اور متعدد ڈیٹا ذرائع میں تجزیات میں اہم ایپلی کیشنز ہیں۔ مختلف ذرائع سے ڈیٹا کو درست طریقے سے تلاش کرنے اور اس کا تجزیہ کرنے میں ناکامی ڈیٹا سائنسدانوں، طبی محققین، ماہرین تعلیم سے لے کر مالیاتی اور حکومتی تجزیہ کاروں تک ہر ایک کے لیے ممکنہ کارکردگی کے قاتل کی نمائندگی کرتی ہے۔
روایتی حل میں لغوی مطلوبہ الفاظ کی تلاش یا باقاعدہ اظہار کی مماثلت شامل ہوتی ہے، جو ڈیٹا کوالٹی کے مسائل جیسے غیر حاضر کالم کے ناموں یا متنوع ڈیٹاسیٹس میں مختلف کالم کے نام کے کنونشنز کے لیے حساس ہوتے ہیں (مثال کے طور پر، zip_code, zcode, postalcode).
اس پوسٹ میں، ہم کالم کے نام، کالم کے مواد، یا دونوں کی بنیاد پر ملتے جلتے کالموں کی تلاش کا حل ظاہر کرتے ہیں۔ حل استعمال کرتا ہے۔ قریب ترین پڑوسی الگورتھم میں دستیاب ایمیزون اوپن سرچ سروس لفظی طور پر ملتے جلتے کالم تلاش کرنے کے لیے۔ تلاش کو آسان بنانے کے لیے، ہم ڈیٹا جھیل میں انفرادی کالموں کے لیے پہلے سے تربیت یافتہ ٹرانسفارمر ماڈلز کا استعمال کرتے ہوئے خصوصیات کی نمائندگی (ایمبیڈنگ) بناتے ہیں۔ جملہ ٹرانسفارمرز لائبریری in ایمیزون سیج میکر. آخر میں، ہمارے حل سے تعامل کرنے اور نتائج کو دیکھنے کے لیے، ہم ایک انٹرایکٹو بناتے ہیں۔ اسٹریم لائٹ ویب ایپلیکیشن چل رہی ہے۔ اے ڈبلیو ایس فارگیٹ.
ہم شامل ہیں a کوڈ ٹیوٹوریل آپ کو نمونہ ڈیٹا یا آپ کے اپنے ڈیٹا پر حل چلانے کے لیے وسائل تعینات کرنے کے لیے۔
حل جائزہ
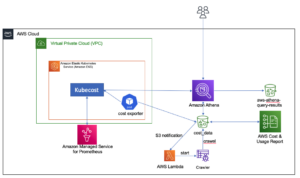
مندرجہ ذیل آرکیٹیکچر ڈایاگرام لفظی طور پر ملتے جلتے کالموں کو تلاش کرنے کے لیے دو مراحل کے ورک فلو کی وضاحت کرتا ہے۔ پہلا مرحلہ ایک چلتا ہے۔ AWS اسٹیپ فنکشنز ورک فلو جو ٹیبلر کالموں سے سرایت کرتا ہے اور اوپن سرچ سروس سرچ انڈیکس بناتا ہے۔ دوسرا مرحلہ، یا آن لائن انفرنس اسٹیج، فارگیٹ کے ذریعے اسٹریم لِٹ ایپلیکیشن چلاتا ہے۔ ویب ایپلیکیشن ان پٹ تلاش کے سوالات جمع کرتی ہے اور اوپن سرچ سروس انڈیکس سے استفسار کے تقریباً k-سب سے زیادہ ملتے جلتے کالموں کو بازیافت کرتی ہے۔

شکل 1. حل فن تعمیر
خودکار ورک فلو درج ذیل مراحل میں آگے بڑھتا ہے:
- صارف ٹیبلولر ڈیٹاسیٹس کو ایک میں اپ لوڈ کرتا ہے۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون ایس 3) بالٹی، جو ایک کو طلب کرتی ہے۔ او ڈبلیو ایس لامبڈا۔ فنکشن جو سٹیپ فنکشنز ورک فلو کو شروع کرتا ہے۔
- ورک فلو ایک سے شروع ہوتا ہے۔ AWS گلو کام جو CSV فائلوں کو میں تبدیل کرتا ہے۔ اپاچی پارکیٹ ڈیٹا فارمیٹ
- سیج میکر پروسیسنگ جاب پہلے سے تربیت یافتہ ماڈلز یا حسب ضرورت کالم ایمبیڈنگ ماڈلز کا استعمال کرتے ہوئے ہر کالم کے لیے ایمبیڈنگ بناتی ہے۔ سیج میکر پروسیسنگ جاب ایمیزون S3 میں ہر ٹیبل کے لیے کالم ایمبیڈنگز کو محفوظ کرتا ہے۔
- ایک لیمبڈا فنکشن اوپن سرچ سروس ڈومین اور کلسٹر بناتا ہے تاکہ پچھلے مرحلے میں کالم ایمبیڈنگس کو انڈیکس کیا جا سکے۔
- آخر میں، ایک انٹرایکٹو Streamlit ویب ایپلیکیشن Fargate کے ساتھ تعینات کی گئی ہے۔ ویب ایپلیکیشن صارف کو اسی طرح کے کالموں کے لیے OpenSearch سروس کے ڈومین کو تلاش کرنے کے لیے سوالات داخل کرنے کے لیے ایک انٹرفیس فراہم کرتی ہے۔
آپ کوڈ ٹیوٹوریل سے ڈاؤن لوڈ کرسکتے ہیں۔ GitHub کے اس حل کو نمونے کے ڈیٹا یا اپنے ڈیٹا پر آزمانے کے لیے۔ اس ٹیوٹوریل کے لیے مطلوبہ وسائل کی تعیناتی کے بارے میں ہدایات پر دستیاب ہیں۔ Github کے.
شرطیں
اس حل کو لاگو کرنے کے لئے، آپ کو درج ذیل کی ضرورت ہے:
- An AWS اکاؤنٹ.
- AWS خدمات سے بنیادی واقفیت جیسے کہ AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK)، لیمبڈا، اوپن سرچ سروس، اور سیج میکر پروسیسنگ۔
- سرچ انڈیکس بنانے کے لیے ایک ٹیبلر ڈیٹا سیٹ۔ آپ اپنا ٹیبلر ڈیٹا لا سکتے ہیں یا سیمپل ڈیٹا سیٹس کو ڈاؤن لوڈ کر سکتے ہیں۔ GitHub کے.
سرچ انڈیکس بنائیں
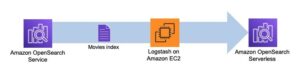
پہلا مرحلہ کالم سرچ انجن انڈیکس بناتا ہے۔ مندرجہ ذیل اعداد و شمار سٹیپ فنکشنز کے ورک فلو کی وضاحت کرتا ہے جو اس مرحلے کو چلاتا ہے۔

شکل 2 – سٹیپ فنکشنز ورک فلو – متعدد ایمبیڈنگ ماڈلز
ڈیٹا سیٹ
اس پوسٹ میں، ہم 400 سے زیادہ ٹیبلر ڈیٹاسیٹس سے 25 سے زیادہ کالموں کو شامل کرنے کے لیے ایک سرچ انڈیکس بناتے ہیں۔ ڈیٹاسیٹ درج ذیل عوامی ذرائع سے نکلتے ہیں:
انڈیکس میں شامل جدولوں کی مکمل فہرست کے لیے، کوڈ ٹیوٹوریل دیکھیں GitHub کے.
آپ نمونے کے ڈیٹا کو بڑھانے کے لیے اپنا ٹیبلر ڈیٹاسیٹ لا سکتے ہیں یا اپنا سرچ انڈیکس بنا سکتے ہیں۔ ہم دو Lambda فنکشنز کو شامل کرتے ہیں جو بالترتیب انفرادی CSV فائلوں یا CSV فائلوں کے بیچ کے لیے سرچ انڈیکس بنانے کے لیے Step Functions ورک فلو کو شروع کرتے ہیں۔
CSV کو Parquet میں تبدیل کریں۔
خام CSV فائلوں کو AWS Glue کے ساتھ Parquet ڈیٹا فارمیٹ میں تبدیل کیا جاتا ہے۔ پارکیٹ ایک کالم پر مبنی فارمیٹ فائل فارمیٹ ہے جسے بڑے ڈیٹا اینالیٹکس میں ترجیح دی جاتی ہے جو موثر کمپریشن اور انکوڈنگ فراہم کرتی ہے۔ ہمارے تجربات میں، پارکیٹ ڈیٹا فارمیٹ نے خام CSV فائلوں کے مقابلے اسٹوریج کے سائز میں نمایاں کمی کی پیشکش کی۔ ہم نے دوسرے ڈیٹا فارمیٹس (مثال کے طور پر JSON اور NDJSON) کو تبدیل کرنے کے لیے Parquet کو ایک عام ڈیٹا فارمیٹ کے طور پر بھی استعمال کیا کیونکہ یہ جدید ترین نیسٹڈ ڈیٹا ڈھانچے کو سپورٹ کرتا ہے۔
ٹیبلر کالم ایمبیڈنگز بنائیں
اس پوسٹ میں نمونہ ٹیبلر ڈیٹاسیٹس میں انفرادی ٹیبل کالموں کے لیے سرایت کرنے کے لیے، ہم مندرجہ ذیل پہلے سے تربیت یافتہ ماڈلز کا استعمال کرتے ہیں sentence-transformers کتب خانہ. اضافی ماڈلز کے لیے، دیکھیں پہلے سے تربیت یافتہ ماڈلز.
سیج میکر پروسیسنگ کا کام چلتا ہے۔ create_embeddings.py(کوڈایک ماڈل کے لیے۔ متعدد ماڈلز سے ایمبیڈنگس نکالنے کے لیے، ورک فلو متوازی SageMaker پروسیسنگ جابز چلاتا ہے جیسا کہ سٹیپ فنکشنز ورک فلو میں دکھایا گیا ہے۔ ہم ایمبیڈنگ کے دو سیٹ بنانے کے لیے ماڈل کا استعمال کرتے ہیں:
- کالم_نام_ایمبیڈنگز - کالم کے ناموں کی سرایت (ہیڈر)
- column_content_embeddings - کالم میں تمام قطاروں کی اوسط سرایت
کالم ایمبیڈنگ کے عمل کے بارے میں مزید معلومات کے لیے، کوڈ ٹیوٹوریل دیکھیں GitHub کے.
سیج میکر پروسیسنگ مرحلے کا متبادل یہ ہے کہ بڑے ڈیٹا سیٹس پر کالم ایمبیڈنگ حاصل کرنے کے لیے سیج میکر بیچ ٹرانسفارم بنانا ہے۔ اس کے لیے ماڈل کو سیج میکر اینڈ پوائنٹ پر تعینات کرنے کی ضرورت ہوگی۔ مزید معلومات کے لیے دیکھیں بیچ ٹرانسفارم استعمال کریں۔.
OpenSearch سروس کے ساتھ انڈیکس ایمبیڈنگز
اس مرحلے کے آخری مرحلے میں، ایک لیمبڈا فنکشن کالم ایمبیڈنگز کو اوپن سرچ سروس میں تقریباً k-Nearest-Neighbour (kNN) سرچ انڈیکس. ہر ماڈل کو اس کا اپنا سرچ انڈیکس تفویض کیا جاتا ہے۔ تخمینی کے این این سرچ انڈیکس پیرامیٹرز کے بارے میں مزید معلومات کے لیے، دیکھیں k-NN.
ویب ایپ کے ساتھ آن لائن انفرنس اور سیمنٹک تلاش
ورک فلو کا دوسرا مرحلہ چلتا ہے a اسٹریم لائٹ ویب ایپلیکیشن جہاں آپ ان پٹ فراہم کر سکتے ہیں اور OpenSearch سروس میں انڈیکس کردہ لفظی طور پر ملتے جلتے کالم تلاش کر سکتے ہیں۔ ایپلی کیشن پرت ایک استعمال کرتی ہے۔ ایپلیکیشن لوڈ بیلنسر، فارگیٹ، اور لیمبڈا۔ ایپلیکیشن کا بنیادی ڈھانچہ حل کے حصے کے طور پر خود بخود تعینات ہوجاتا ہے۔
ایپلیکیشن آپ کو ان پٹ فراہم کرنے اور معنوی طور پر ملتے جلتے کالم کے نام، کالم کا مواد، یا دونوں تلاش کرنے کی اجازت دیتی ہے۔ مزید برآں، آپ تلاش سے واپس آنے کے لیے ایمبیڈنگ ماڈل اور قریب ترین پڑوسیوں کی تعداد منتخب کر سکتے ہیں۔ ایپلیکیشن ان پٹ وصول کرتی ہے، مخصوص ماڈل کے ساتھ ان پٹ کو سرایت کرتی ہے، اور استعمال کرتی ہے۔ اوپن سرچ سروس میں kNN تلاش کریں۔ انڈیکسڈ کالم ایمبیڈنگز تلاش کرنے اور دیے گئے ان پٹ سے ملتے جلتے کالم تلاش کرنے کے لیے۔ دکھائے گئے تلاش کے نتائج میں ٹیبل کے نام، کالم کے نام، اور شناخت کیے گئے کالموں کے لیے مماثلت کے اسکور شامل ہیں، نیز مزید تلاش کے لیے Amazon S3 میں ڈیٹا کے مقامات۔
مندرجہ ذیل تصویر ویب ایپلیکیشن کی ایک مثال دکھاتی ہے۔ اس مثال میں، ہم نے اپنی ڈیٹا لیک میں ایسے کالم تلاش کیے جن میں ملتے جلتے ہیں۔ Column Names (پے لوڈ کی قسمکے) district (پاؤ لوڈ)۔ استعمال شدہ ایپلیکیشن all-MiniLM-L6-v2 کے طور پر سرایت ماڈل اور واپس آئے 10 (k) ہمارے اوپن سرچ سروس انڈیکس سے قریبی پڑوسی۔
درخواست واپس آگئی transit_district, city, borough، اور location OpenSearch سروس میں ترتیب کردہ ڈیٹا پر مبنی چار سب سے ملتے جلتے کالمز کے طور پر۔ یہ مثال ڈیٹاسیٹس میں لفظی طور پر ملتے جلتے کالموں کی شناخت کے لیے تلاش کے نقطہ نظر کی صلاحیت کو ظاہر کرتی ہے۔

شکل 3: ویب ایپلیکیشن یوزر انٹرفیس
صاف کرو
اس ٹیوٹوریل میں AWS CDK کے ذریعہ تخلیق کردہ وسائل کو حذف کرنے کے لیے، درج ذیل کمانڈ کو چلائیں:
cdk destroy --allنتیجہ
اس پوسٹ میں، ہم نے ٹیبلر کالموں کے لیے ایک سیمنٹک سرچ انجن بنانے کے لیے اینڈ ٹو اینڈ ورک فلو پیش کیا۔
پر دستیاب ہمارے کوڈ ٹیوٹوریل کے ساتھ آج ہی اپنے ڈیٹا پر شروع کریں۔ GitHub کے. اگر آپ اپنی مصنوعات اور عمل میں ایم ایل کے استعمال کو تیز کرنے میں مدد چاہتے ہیں، تو براہ کرم رابطہ کریں۔ ایمیزون مشین لرننگ سلوشنز لیب.
مصنفین کے بارے میں
![]() کچی اوڈومینی۔ AWS AI میں ایک اپلائیڈ سائنٹسٹ ہے۔ وہ AWS صارفین کے لیے کاروباری مسائل کو حل کرنے کے لیے AI/ML حل تیار کرتا ہے۔
کچی اوڈومینی۔ AWS AI میں ایک اپلائیڈ سائنٹسٹ ہے۔ وہ AWS صارفین کے لیے کاروباری مسائل کو حل کرنے کے لیے AI/ML حل تیار کرتا ہے۔
![]() ٹیلر میک نیلی۔ ایمیزون مشین لرننگ سلوشنز لیب میں ڈیپ لرننگ آرکیٹیکٹ ہے۔ وہ مختلف صنعتوں کے صارفین کو AWS پر AI/ML کا فائدہ اٹھاتے ہوئے حل تیار کرنے میں مدد کرتا ہے۔ وہ کافی کا ایک اچھا کپ، باہر، اور اپنے خاندان اور توانائی سے بھرپور کتے کے ساتھ وقت گزارتا ہے۔
ٹیلر میک نیلی۔ ایمیزون مشین لرننگ سلوشنز لیب میں ڈیپ لرننگ آرکیٹیکٹ ہے۔ وہ مختلف صنعتوں کے صارفین کو AWS پر AI/ML کا فائدہ اٹھاتے ہوئے حل تیار کرنے میں مدد کرتا ہے۔ وہ کافی کا ایک اچھا کپ، باہر، اور اپنے خاندان اور توانائی سے بھرپور کتے کے ساتھ وقت گزارتا ہے۔
![]() آسٹن ویلچ ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ وہ AWS پبلک سیکٹر کے صارفین کو اپنے AI اور کلاؤڈ کو اپنانے کو تیز کرنے میں مدد کے لیے اپنی مرضی کے مطابق ڈیپ لرننگ ماڈل تیار کرتا ہے۔ اپنے فارغ وقت میں، وہ پڑھنے، سفر کرنے اور جیو جِتسو سے لطف اندوز ہوتا ہے۔
آسٹن ویلچ ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ وہ AWS پبلک سیکٹر کے صارفین کو اپنے AI اور کلاؤڈ کو اپنانے کو تیز کرنے میں مدد کے لیے اپنی مرضی کے مطابق ڈیپ لرننگ ماڈل تیار کرتا ہے۔ اپنے فارغ وقت میں، وہ پڑھنے، سفر کرنے اور جیو جِتسو سے لطف اندوز ہوتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- کی صلاحیت
- ہمارے بارے میں
- غیر حاضر
- رفتار کو تیز تر
- تیز
- درست طریقے سے
- کے پار
- ایڈیشنل
- اس کے علاوہ
- جوڑتا ہے
- منہ بولابیٹا بنانے
- اعلی درجے کی
- AI
- AI / ML
- تمام
- کی اجازت دیتا ہے
- متبادل
- ایمیزون
- ایمیزون مشین لرننگ
- ایمیزون ایم ایل حل لیب
- تجزیہ کار کہتے ہیں
- تجزیاتی
- تجزیے
- اور
- اپاچی
- درخواست
- ایپلی کیشنز
- اطلاقی
- نقطہ نظر
- فن تعمیر
- تفویض
- آٹومیٹڈ
- خود کار طریقے سے
- دستیاب
- اوسط
- AWS
- AWS گلو
- کی بنیاد پر
- کیونکہ
- بگ
- بگ ڈیٹا
- لانے
- تعمیر
- عمارت
- بناتا ہے
- کاروبار
- صفائی
- بادل
- بادل اپنانا
- کلسٹر
- کوڈ
- کافی
- جمع کرتا ہے
- کالم
- کالم
- کامن
- مقابلے میں
- رابطہ کریں
- مواد
- کنونشنوں
- تبدیل
- تبدیل
- تخلیق
- بنائی
- پیدا
- کپ
- اپنی مرضی کے
- گاہکوں
- اعداد و شمار
- ڈیٹا تجزیات
- ڈیٹا لیک
- ڈیٹا کی معیار
- ڈیٹا سائنسدان
- ڈیٹاسیٹس
- گہری
- گہری سیکھنے
- مظاہرہ
- ثبوت
- تعیناتی
- تعینات
- تعینات
- تباہ
- ترقی
- تیار ہے
- مختلف
- دریافت
- متفق
- متنوع
- کتا
- ڈومین
- ڈاؤن لوڈ، اتارنا
- ہر ایک
- کارکردگی
- ہنر
- آخر سے آخر تک
- اختتام پوائنٹ
- انجن
- Ether (ETH)
- سب
- مثال کے طور پر
- کی تلاش
- نکالنے
- سہولت
- واقفیت
- خاندان
- خصوصیات
- اعداد و شمار
- فائل
- فائلوں
- فائنل
- آخر
- مالی
- مل
- تلاش
- پہلا
- کے بعد
- فارمیٹ
- سے
- مکمل
- تقریب
- افعال
- مزید
- حاصل
- دی
- اچھا
- حکومت
- ہیڈر
- مدد
- مدد کرتا ہے
- کس طرح
- کیسے
- HTML
- HTTPS
- کی نشاندہی
- شناخت
- پر عملدرآمد
- اہم
- in
- اسمرتتا
- شامل
- شامل
- انڈکس
- انفرادی
- صنعتوں
- معلومات
- انفراسٹرکچر
- شروع
- شروع کرتا ہے
- ان پٹ
- ہدایات
- بات چیت
- انٹرایکٹو
- انٹرفیس
- پکارتے ہیں۔
- شامل
- مسائل
- IT
- ایوب
- نوکریاں
- JSON
- لیب
- جھیل
- بڑے
- پرت
- سیکھنے
- لیورنگنگ
- لائبریری
- لسٹ
- لوڈ
- مقامات
- مشین
- مشین لرننگ
- کے ملاپ
- طبی
- ML
- ماڈل
- ماڈل
- زیادہ
- سب سے زیادہ
- ایک سے زیادہ
- نام
- نام
- نام
- ضرورت ہے
- پڑوسیوں
- تعداد
- کی پیشکش کی
- آن لائن
- دیگر
- باہر
- خود
- متوازی
- پیرامیٹرز
- حصہ
- پلاٹا
- افلاطون ڈیٹا انٹیلی جنس
- پلیٹو ڈیٹا
- مہربانی کرکے
- پوسٹ
- ممکنہ
- کو ترجیح دی
- پیش
- پچھلا
- مسائل
- آگے بڑھتا ہے
- عمل
- عمل
- پروسیسنگ
- تیار
- حاصل
- فراہم
- فراہم کرتا ہے
- عوامی
- معیار
- خام
- پڑھنا
- موصول
- باقاعدہ
- کی نمائندگی کرتا ہے
- کی ضرورت
- ضرورت
- محققین
- وسائل
- بالترتیب
- نتائج کی نمائش
- واپسی
- رن
- چل رہا ہے
- sagemaker
- سائنسدان
- سائنسدانوں
- تلاش کریں
- تلاش کے انجن
- تلاش
- دوسری
- شعبے
- سروس
- سروسز
- سیٹ
- دکھایا گیا
- شوز
- اہم
- اسی طرح
- سادہ
- ایک
- سائز
- حل
- حل
- حل
- ذرائع
- مخصوص
- اسٹیج
- شروع
- مرحلہ
- مراحل
- ذخیرہ
- اس طرح
- کی حمایت کرتا ہے
- مناسب
- ٹیبل
- ۔
- ان
- کے ذریعے
- وقت
- کرنے کے لئے
- آج
- تبدیل
- ٹرانسفارمرز
- سفر
- سبق
- استعمال کی شرائط
- رکن کا
- صارف مواجہ
- مختلف
- ویب
- ویب ایپلی کیشن
- جس
- کام کا بہاؤ
- گا
- اور
- زیفیرنیٹ