Apache Spark için Amazon EMR çalışma zamanı, açık kaynak Apache Spark ile %100 API uyumlu olan, Apache Spark için performansı optimize edilmiş bir çalışma zamanıdır. İle Amazon EMR'si 6.9.0 sürümünde, Apache Spark için EMR çalışma zamanı eşdeğer Spark sürüm 3.3.0'ı destekler.
Amazon EMR 6.9.0 ile artık uygulamalarınızda herhangi bir değişiklik yapmanıza gerek kalmadan Apache Spark 3.x uygulamalarınızı daha hızlı ve daha düşük maliyetle çalıştırabilirsiniz. 3 TB ölçeğindeki TPC-DS performans testlerinden türetilen performans kıyaslama testlerimizde, Apache Spark 3.3.0 için EMR çalışma zamanının, açık kaynak Apache Spark 3.5'e göre ortalama 3.3.0 kat (toplam çalışma zamanı kullanılarak) performans artışı sağladığını bulduk. XNUMX.
Bu gönderide, bir TPC-DS uygulamasını çalıştıran kıyaslama testlerimizin sonuçlarını analiz ediyoruz. açık kaynaklı Apache Spark ve ardından açık kaynak Spark ile uyumlu, optimize edilmiş bir Spark çalışma zamanı ile birlikte gelen Amazon EMR 6.9'da. Ayrıntılı bir maliyet analizinden geçiyoruz ve son olarak karşılaştırmalı değerlendirme yapmak için adım adım talimatlar veriyoruz.
Gözlemlenen sonuçlar
Performans iyileştirmelerini değerlendirmek için, TPC-DS performans testi araç setinden türetilen açık kaynaklı bir Spark performans testi aracı kullandık. Testleri, Apache Spark için EMR çalışma zamanı ile yedi düğümlü (altı çekirdek düğüm ve bir birincil düğüm) c5d.9xlarge EMR kümesinde ve ikinci bir yedi düğümlü kendi kendini yöneten kümede gerçekleştirdik. Amazon Elastik Bilgi İşlem Bulutu (Amazon EC2) ile Spark'ın eşdeğer açık kaynak sürümü. Her iki testi de verilerle çalıştırdık. Amazon Basit Depolama Hizmeti (Amazon S3).
Dinamik Kaynak Tahsisi (DRA), değişen iş yükleri için kullanmak için harika bir özelliktir. Ancak, iki platformu yalnızca performans açısından karşılaştırdığımız ve test veri hacimlerinin değişmediği (bizim durumumuzda 3 TB) bir kıyaslama alıştırması için, elmalar arası bir karşılaştırma yapmak için değişkenlikten kaçınmanın en iyisi olduğuna inanıyoruz. Hem açık kaynak Spark hem de Amazon EMR'deki testlerimizde, kıyaslama uygulamasını çalıştırırken DRA'yı devre dışı bıraktık.
Aşağıdaki tablo, Amazon EMR sürüm 3 ile açık kaynaklı Spark sürüm 6.9.0 arasındaki 3.3.0 TB sorgu veri kümesindeki tüm sorgular için toplam iş çalıştırma süresini (saniye olarak) gösterir. TPC-DS testlerimizin, Amazon EC2'de Amazon EMR'de, aynı yapılandırmaya sahip açık kaynaklı bir Spark kümesi kullanmaya göre 3.5 kat daha hızlı olan toplam iş çalışma süresine sahip olduğunu gözlemledik.
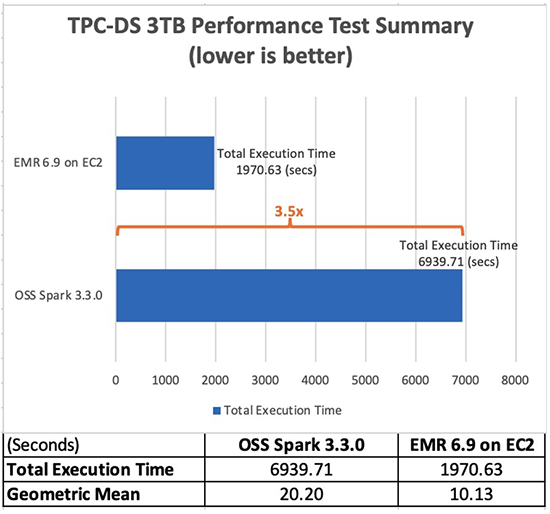
Apache Spark için EMR çalışma zamanı olsun ya da olmasın Amazon EMR 6.9'daki sorgu başına hızlanma aşağıdaki tabloda gösterilmektedir. Yatay eksen, 3 TB karşılaştırmalı değerlendirmedeki her sorguyu gösterir. Dikey eksen, EMR çalışma zamanı nedeniyle her sorgunun hızlanmasını gösterir. TPC-DS sorguları 10b, 24, 72 ve 95 için kayda değer performans kazanımları 96 kat daha hızlıdır.

Maliyet analizi
Apache Spark için EMR çalışma zamanının performans iyileştirmeleri doğrudan daha düşük maliyetlere dönüşür. Amazon EMR ve Amazon çalışma saatlerinin azalması sayesinde aynı uygulamayı aynı küme boyutuyla Amazon EC67 üzerinde açık kaynaklı Spark üzerinde çalıştırmak için katlanılan maliyete kıyasla Amazon EMR'de kıyaslama uygulamasını çalıştırırken %2'lik bir maliyet tasarrufu elde edebildik. EC2 kullanımı. Amazon EMR fiyatlandırması, EC2 bulut sunucularına sahip EMR kümelerinde çalışan EMR uygulamaları içindir. Amazon EMR fiyatı, EC2 bulut sunucusu fiyatı gibi temel bilgi işlem ve depolama fiyatlarına eklenir ve Amazon Elastik Blok Mağazası (Amazon EBS) maliyeti (EBS ciltleri ekleniyorsa). Genel olarak, ABD Doğu (K. Virginia) Bölgesinde tahmini kıyaslama maliyeti, Amazon EC27.01'de açık kaynaklı Spark için çalıştırma başına 2 USD ve Amazon EMR için çalıştırma başına 8.82 USD'dir.
| Kıyaslama İşi | Çalışma Zamanı (Saat) | Tahmini maliyeti | Toplam EC2 Örneği | Toplam vCPU | Toplam Bellek (GiB) | Kök Cihaz (Amazon EBS) |
|
Amazon EC2'de Açık Kaynak Spark (1 birincil ve 6 çekirdek düğüm) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EC2'de Amazon EMR (1 birincil ve 6 çekirdek düğüm) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Maliyet dökümü
Açık kaynaklı Spark on Amazon EC2 işinin (27.01 ABD doları) maliyet dökümü aşağıdadır:
- Toplam Amazon EC2 maliyeti – (7 * 1.728 ABD doları * 2.23) = (örnek sayısı * c5d.9xlarge saatlik ücret * saat cinsinden iş çalışma süresi) = 26.97 ABD doları
- Amazon EBS maliyeti – (0.1 USD/730 * 20 * 7 * 2.23) = (GB saatlik ücret başına Amazon EBS * kök EBS boyutu * örnek sayısı * saat cinsinden iş çalışma süresi) = 0.042 USD
Amazon EMR on Amazon EC2 işinin maliyet dökümü aşağıdadır (8.82 USD):
- Toplam Amazon EMR maliyeti – (7 * 0.27 USD * 0.63) = ((çekirdek düğüm sayısı + birincil düğüm sayısı)* c5d.9xlarge Amazon EMR fiyatı * saat cinsinden iş çalışma süresi) = 1.19 USD
- Toplam Amazon EC2 maliyeti – (7 * 1.728 USD * 0.63) = ((çekirdek düğüm sayısı + birincil düğüm sayısı)* c5d.9xlarge bulut sunucusu fiyatı * saat cinsinden iş çalışma süresi) = 7.62 USD
- Amazon EBS maliyeti – (0.1 USD/730 * 20 GiB * 7 * 0.63) = (GB saatlik ücret başına Amazon EBS * EBS boyutu * örnek sayısı * saat cinsinden iş çalışma süresi) = 0.012 USD
OSS Spark kıyaslamasını kurun
Aşağıdaki bölümlerde, kıyaslamanın ayarlanmasıyla ilgili adımların kısa bir taslağını sunuyoruz. Örneklerle birlikte ayrıntılı talimatlar için bkz. GitHub repo.
OSS Spark kıyaslamamız için açık kaynak aracını kullanıyoruz Çakmaktaş Amazon EC2 tabanlı ürünümüzü başlatmak için Apache Spark küme. Flintrock, komut satırını kullanarak Amazon EC2'de bir Apache Spark kümesi başlatmanın hızlı bir yolunu sunar.
Önkoşullar
Aşağıdaki ön koşul adımlarını tamamlayın:
- Python 3.7.x veya üstüne sahip olun.
- Pip3 22.2.2 veya üzeri sürüme sahip olun.
- Python bin dizinini ortam yolunuza ekleyin. Flintrock ikili dosyası bu yola kurulacak.
- koşmak
aws configureyapılandırmak için AWS Komut Satırı Arayüzü (AWS CLI) kabuğu, kıyaslama hesabına işaret eder. bakın aws ile hızlı yapılandırma talimatlar için. - Bir var anahtar çifti OSS Spark birincil düğümüne erişim için kısıtlayıcı dosya izinleriyle.
- Gerekirse test hesabınızda yeni bir S3 grubu oluşturun.
- TPC-DS kaynak verilerini S3 klasörünüze girdi olarak kopyalayın.
- bölümünde verilen adımları izleyerek kıyaslama uygulamasını oluşturun. Spark-benchmark-montaj uygulaması oluşturma adımları. Alternatif olarak, önceden oluşturulmuş bir Spark-benchmark-montajı-3.3.0.jar Spark 3.3.0 tabanlı bir uygulama istiyorsanız.
Spark kümesini dağıtın ve kıyaslama işini çalıştırın
Aşağıdaki adımları tamamlayın:
- Flintrock aracını şekilde gösterildiği gibi pip aracılığıyla kurun. OSS Spark Benchmarking'i kurma adımları.
- Varsayılan bir yapılandırma dosyası açan flintrock configure komutunu çalıştırın.
- Varsayılanı değiştirin
config.yamlihtiyaçlarınıza göre dosya. Alternatif olarak, kopyalayıp yapıştırın config.yaml dosyası içeriği varsayılan yapılandırma dosyasına. Ardından dosyayı olduğu yere kaydedin. - Son olarak, Flintrock aracılığıyla Amazon EC7'de 2 düğümlü Spark kümesini başlatın.
Bu, bir birincil düğüm ve altı çalışan düğüm içeren bir Spark kümesi oluşturmalıdır. Herhangi bir hata mesajı görürseniz yapılandırma dosyası değerlerini, özellikle Spark ve Hadoop sürümlerini ve indirme kaynağı ve AMI özniteliklerini iki kez kontrol edin.
OSS Spark kümesi, YARN kaynak yöneticisiyle birlikte gelmez. Etkinleştirmek için kümeyi yapılandırmamız gerekiyor.
- Atomic Cüzdanı indirin : iplik-site.xml ve etkinleştirme-yarn.sh GitHub deposundaki dosyalar.
- Yer değiştirmek Flintrock kümenizdeki birincil düğümün IP adresiyle.
IP adresini Amazon EC2 konsolundan alabilirsiniz.
- Dosyaları Spark kümesinin tüm düğümlerine yükleyin.
- enable-yarn komut dosyasını çalıştırın.
- Hadoop'ta Snappy desteğini etkinleştirin (karşılaştırma işi Snappy sıkıştırılmış verilerini okur).
- Kıyaslama yardımcı programı uygulaması JAR dosyasını indirin Spark-benchmark-montajı-3.3.0.jar yerel makinenize.
- Bu dosyayı kümeye kopyalayın.
- Birincil düğümde oturum açın ve YARN'ı başlatın.
- Kıyaslama işini, açık kaynak Kıvılcım kümesinde gösterildiği gibi gönderin. Karşılaştırma işini gönder.
Sonuçları özetle
Test sonucu dosyasını çıktı S3 klasöründen indirin s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Yer değiştirmek $YOUR_S3_BUCKET S3 grup adınızla.) Amazon S3 konsolunu kullanabilir ve çıkış S3 konumuna gidebilir veya AWS CLI'yi kullanabilirsiniz.
Spark karşılaştırmalı değerlendirme uygulaması bir zaman damgası klasörü oluşturur ve bir abstract.csv önekinin içine bir özet dosyası yazar. Zaman damganız ve dosya adınız, önceki örnekte gösterilenden farklı olacaktır.
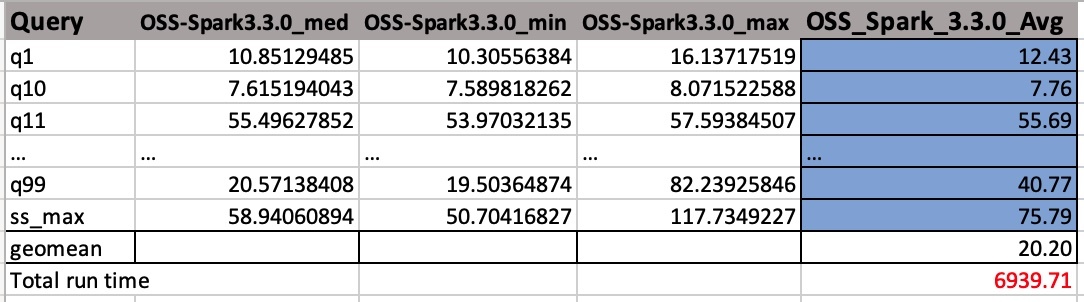
Çıktı CSV dosyalarının başlık adları olmayan dört sütunu vardır. Bunlar:
- Sorgu adı
- medyan zaman
- Minimum süre
- Maksimum süre
Aşağıdaki ekran görüntüsü örnek bir çıktıyı göstermektedir. Sütun adlarını manuel olarak ekledik. Geomean ve toplam iş çalışma süresini hesaplama şeklimiz aritmetik ortalamalara dayalıdır. ORTALAMA(B2:D2) formülünü kullanarak ilk olarak orta, minimum ve maksimum değerlerin ortalamasını alıyoruz. Sonra GEOMEAN(E2:E105) formülünü kullanarak Avg sütununun geometrik ortalamasını alırız.
Amazon EMR kıyaslamasını kurun
Ayrıntılı talimatlar için, bkz. EMR Karşılaştırmasını kurma adımları.
Önkoşullar
Aşağıdaki ön koşul adımlarını tamamlayın:
- koşmak
aws configureAWS CLI kabuğunuzu kıyaslama hesabına işaret edecek şekilde yapılandırmak için. bakın aws ile hızlı yapılandırma talimatlar için. - Kıyaslama uygulamasını Amazon S3'e yükleyin.
EMR kümesini dağıtın ve kıyaslama işini çalıştırın
Aşağıdaki adımları tamamlayın:
- AWS CLI kabuğunuzda Amazon EMR'yi komut satırını kullanarak aşağıda gösterildiği gibi çalıştırın EMR Kümesini dağıtın ve kıyaslama işini çalıştırın.
- Amazon EMR'yi bir birincil (c5d.9xlarge) ve altı çekirdekli (c5d.9xlarge) düğümle yapılandırın. bakın küme oluştur AWS CLI seçeneklerinin ayrıntılı açıklaması için.
- Küme kimliğini yanıttan depolayın. Bir sonraki adımda buna ihtiyacınız var.
- AWS CLI'deki eklenti adımlarını kullanarak karşılaştırma işini Amazon EMR'ye gönderin.
Sonuçları özetle
Çıktı grubundaki sonuçları özetleyin s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT OSS sonuçları için yaptığımız gibi ve karşılaştırın.
Temizlemek
İleride ücret alınmasını önlemek için, kılavuzdaki talimatları kullanarak oluşturduğunuz kaynakları silin. GitHub deposunun temizleme bölümü.
- EMR ve OSS Spark kümelerini durdurun. İçeriği korumak istemiyorsanız bunları da silebilirsiniz. Komut dosyasını çalıştırarak bu kaynakları silebilirsiniz. temizleme-benchmark-env.sh kıyaslama ortamınızdaki bir terminalden.
- Eğer kullandıysanız AWS Bulut9 kullanarak kıyaslama uygulaması JAR dosyasını oluşturmak için IDE'niz olarak Spark-benchmark-montaj uygulaması oluşturma adımları, ortamı da silmek isteyebilirsiniz.
Sonuç
Amazon EMR 3.5'ı kullanarak Apache Spark iş yüklerinizi uygulamalarınızda herhangi bir değişiklik yapmadan 6.9.0 kat daha hızlı ve daha düşük maliyetle (toplam çalışma süresine göre) çalıştırabilirsiniz.
Güncel bilgilerden haberdar olmak için Büyük Veri Bloguna abone olun. RSS beslemesi Apache Spark için EMR çalışma zamanı, en iyi yapılandırma uygulamaları ve ayarlama önerileri hakkında daha fazla bilgi edinmek için.
Geçmiş kıyaslama testleri için, bkz. Apache Spark için Amazon EMR çalışma zamanı ile Apache Spark 3.0 iş yüklerini 1.7 kat daha hızlı çalıştırın. Performansın 1.7 katı olan geçmiş kıyaslama sonucunun geometrik ortalamaya dayandığına dikkat edin. Geometrik ortalamaya göre, Amazon EMR 6.9'daki performans iki kat daha hızlıydı.
yazarlar hakkında
 Sekar Srinivasan AWS'de Büyük Veri ve Analitik odaklı bir Kıdemli Uzman Çözüm Mimarıdır. Sekar, verilerle çalışma konusunda 20 yılı aşkın deneyime sahiptir. Müşterilerin mimarilerini modernize eden ölçeklenebilir çözümler oluşturmalarına ve verilerinden içgörüler üretmelerine yardımcı olma konusunda tutkulu. Boş zamanlarında kar amacı gütmeyen projelerde, özellikle de imkanları kısıtlı Çocukların eğitimine odaklanan projelerde çalışmayı sever.
Sekar Srinivasan AWS'de Büyük Veri ve Analitik odaklı bir Kıdemli Uzman Çözüm Mimarıdır. Sekar, verilerle çalışma konusunda 20 yılı aşkın deneyime sahiptir. Müşterilerin mimarilerini modernize eden ölçeklenebilir çözümler oluşturmalarına ve verilerinden içgörüler üretmelerine yardımcı olma konusunda tutkulu. Boş zamanlarında kar amacı gütmeyen projelerde, özellikle de imkanları kısıtlı Çocukların eğitimine odaklanan projelerde çalışmayı sever.
 Prabu Ravichandran Analitik, veri Gölü mimarisi ve uygulamasına odaklanan, Amazon Web Hizmetleri'nde Kıdemli Veri Mimarıdır. Müşterilerin AWS hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler tasarlamasına ve oluşturmasına yardımcı olur. Prabu, boş zamanlarında seyahat etmekten ve ailesiyle vakit geçirmekten hoşlanır.
Prabu Ravichandran Analitik, veri Gölü mimarisi ve uygulamasına odaklanan, Amazon Web Hizmetleri'nde Kıdemli Veri Mimarıdır. Müşterilerin AWS hizmetlerini kullanarak ölçeklenebilir ve sağlam çözümler tasarlamasına ve oluşturmasına yardımcı olur. Prabu, boş zamanlarında seyahat etmekten ve ailesiyle vakit geçirmekten hoşlanır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- Plato blok zinciri. Web3 Metaverse Zekası. Bilgi Güçlendirildi. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 yıl
- 7
- 9
- a
- Yapabilmek
- Hakkımızda
- yukarıdaki
- erişim
- Hesap
- katma
- adres
- tavsiye
- Türkiye
- tahsis
- Amazon
- Amazon EC2
- Amazon EMR'si
- Amazon Web Servisleri
- analiz
- analytics
- çözümlemek
- ve
- Apache
- Apache Spark
- api
- Uygulama
- uygulamaları
- mimari
- öznitelikleri
- ortalama
- AVG
- AWS
- eksen
- merkezli
- Inanmak
- kıyaslama
- İYİ
- en iyi uygulamalar
- arasında
- Büyük
- büyük Veri
- Engellemek
- Arıza
- inşa etmek
- bina
- dava
- değişiklik
- değişiklikler
- yükler
- Grafik
- Küme
- Sütun
- Sütunlar
- nasıl
- karşılaştırmak
- karşılaştırma
- uyumlu
- hesaplamak
- yapılandırma
- konsolos
- içerik
- çekirdek
- Ücret
- tasarruf
- maliyetler
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- oluşturur
- Müşteriler
- veri
- Veri Gölü
- Tarih
- Varsayılan
- Türetilmiş
- tanım
- detaylı
- cihaz
- DID
- farklı
- direkt olarak
- özürlü
- Değil
- Dont
- indir
- her
- Doğu
- ebs
- Eğitim
- etkinleştirmek
- çevre
- Eşdeğer
- hata
- özellikle
- tahmini
- Eter (ETH)
- değerlendirmek
- örnek
- örnekler
- Egzersiz
- deneyim
- aile
- Daha hızlı
- Özellikler(Hazırlık aşamasında)
- fileto
- dosyalar
- Nihayet
- Ad
- odaklanmış
- odaklanmış
- takip etme
- formül
- bulundu
- Ücretsiz
- itibaren
- gelecek
- Kazançlar
- üreten
- GitHub
- harika
- Hadoop'un
- yardım
- yardımcı olur
- Yatay
- SAAT
- Ancak
- HTML
- HTTPS
- uygulama
- iyileşme
- iyileştirmeler
- in
- giriş
- anlayışlar
- örnek
- talimatlar
- ilgili
- IP
- IP Adresi
- IT
- İş
- tutmak
- göl
- başlatmak
- ÖĞRENİN
- çizgi
- yerel
- yer
- makine
- Yapımı
- müdür
- tavır
- el ile
- maksimum
- anlamına geliyor
- Bellek
- mesajları
- Daha
- isim
- isimleri
- Gezin
- gerek
- gerekli
- ihtiyaçlar
- yeni
- sonraki
- düğüm
- düğümler
- Kar amacı gütmeyen
- dikkate değer
- numara
- ONE
- açık kaynak
- optimize
- Opsiyonlar
- sipariş
- Bize
- taslak
- tüm
- tutkulu
- geçmiş
- yol
- performans
- izinleri
- Platformlar
- Platon
- Plato Veri Zekası
- PlatoVeri
- Nokta
- Moruk
- Çivi
- uygulamalar
- fiyat
- Fiyatlar
- fiyatlandırma
- birincil
- özel
- Projeler
- sağlamak
- sağlanan
- sağlar
- yalnızca
- Python
- Hızlı
- oran
- gerçekleştirmek
- Indirimli
- bölge
- serbest
- değiştirmek
- kaynak
- Kaynaklar
- yanıt
- kısıtlayıcı
- sonuç
- Sonuçlar
- gürbüz
- kök
- koşmak
- koşu
- aynı
- İndirim
- Tasarruf
- ölçeklenebilir
- ölçek
- İkinci
- saniye
- Bölüm
- bölümler
- kıdemli
- Hizmetler
- ayar
- kurulum
- Kabuk
- meli
- gösterilen
- Gösteriler
- Basit
- ALTINCI
- beden
- Çözümler
- Kaynak
- Kıvılcım
- uzman
- Harcama
- başlama
- adım
- Basamaklar
- hafızası
- abone ol
- böyle
- ÖZET
- destek
- Destekler
- tablo
- Bizi daha iyi tanımak için
- terminal
- test
- testleri
- The
- ve bazı Asya
- İçinden
- zaman
- zamanlar
- zaman damgası
- için
- araç
- araç
- Toplam
- çevirmek
- Seyahat
- altında yatan
- temel sosyal haklardan mahrum
- us
- kullanım
- kullanım
- yarar
- Değerler
- versiyon
- üzerinden
- Virjinya
- hacimleri
- ağ
- web hizmetleri
- hangi
- süre
- irade
- olmadan
- İş
- işçi
- çalışma
- X
- XML
- tatlım
- yıl
- zefirnet