Günümüzün dijital çağında veriler her kuruluşun başarısının merkezinde yer almaktadır. Veri alışverişinde en sık kullanılan formatlardan biri XML'dir. XML dosyalarını analiz etmek çeşitli nedenlerden dolayı çok önemlidir. İlk olarak, XML dosyaları finans, sağlık ve devlet dahil olmak üzere birçok sektörde kullanılmaktadır. XML dosyalarını analiz etmek, kuruluşların verileri hakkında bilgi edinmelerine yardımcı olarak daha iyi kararlar almalarına ve operasyonlarını iyileştirmelerine olanak tanır. Birçok uygulama ve sistem XML'i standart veri formatı olarak kullandığından, XML dosyalarını analiz etmek veri entegrasyonuna da yardımcı olabilir. Kuruluşlar, XML dosyalarını analiz ederek farklı kaynaklardan gelen verileri kolayca entegre edebilir ve sistemleri arasında tutarlılık sağlayabilir. Bununla birlikte, XML dosyaları yarı yapılandırılmış, yüksek düzeyde iç içe geçmiş veriler içerir; bu da, özellikle dosya büyükse ve karmaşık, oldukça iç içe geçmiş şema.
XML dosyaları uygulamalar için çok uygundur ancak analiz motorları için ideal olmayabilir. Sorgu performansını artırmak ve aşağıdaki gibi aşağı yönlü analiz motorlarına kolay erişim sağlamak için Amazon AtinaXML dosyalarını Parquet gibi sütunlu bir formatta önceden işlemek çok önemlidir. Bu dönüşüm, analitik iş akışlarında gelişmiş verimlilik ve kullanılabilirlik sağlar. Bu yazıda, XML verilerinin aşağıdakileri kullanarak nasıl işleneceğini göstereceğiz: AWS Tutkal ve Athena.
Çözüme genel bakış
XML dosya işleme iş akışınızı kolaylaştırabilecek iki farklı tekniği araştırıyoruz:
- 1. Teknik: AWS Glue tarayıcısını ve AWS Glue görsel düzenleyicisini kullanın – XML dosyalarınızın tablo yapısını tanımlamak için AWS Glue kullanıcı arayüzünü bir tarayıcıyla birlikte kullanabilirsiniz. Bu yaklaşım, kullanıcı dostu bir arayüz sağlar ve özellikle verilerini yönetmek için grafiksel bir yaklaşımı tercih eden kişiler için uygundur.
- Teknik 2: Çıkarımlı ve sabit şemalarla AWS Glue DynamicFrames'i kullanma – Tarayıcının, XML dosyalarındaki tek bir satırın işlenmesi konusunda bir sınırlaması vardır: 1 MB. Bu kısıtlamanın üstesinden gelmek için AWS Glue'yu oluşturmak için bir AWS Glue dizüstü bilgisayar kullanıyoruz
DynamicFrameshem çıkarımsal hem de sabit şemalardan yararlanılır. Bu yöntem, boyutu 1 MB'ı aşan satırlara sahip XML dosyalarının verimli şekilde işlenmesini sağlar.
Her iki yaklaşımda da nihai hedefimiz XML dosyalarını Apache Parquet formatına dönüştürerek Athena kullanılarak sorgulamaya hazır hale getirmektir. Bu tekniklerle XML verilerinizin işlem hızını ve erişilebilirliğini geliştirebilir, böylece değerli bilgileri kolaylıkla elde edebilirsiniz.
Önkoşullar
Bu eğitime başlamadan önce aşağıdaki önkoşulları tamamlayın (bunlar her iki teknik için de geçerlidir):
- XML dosyalarını indirin teknik1.xml ve teknik2.xml.
- Dosyaları bir yere yükleyin Amazon Basit Depolama Hizmeti (Amazon S3) kovası. Bunları farklı klasörlerdeki aynı S3 klasörüne veya farklı S3 klasörlerine yükleyebilirsiniz.
- Bir oluşturma AWS Kimlik ve Erişim Yönetimi ETL işiniz veya not defteriniz için talimatlarda belirtildiği şekilde (IAM) rolü AWS Glue Studio için IAM izinlerini ayarlayın.
- Rolünüze bir satır içi politika ekleyin. zaten: PassRole aksiyon:
- S3 klasörünüze erişimi olan role bir izin politikası ekleyin.
Artık önkoşulları tamamladığımıza göre ilk tekniği uygulamaya geçelim.
1. Teknik: AWS Glue tarayıcısını ve görsel düzenleyiciyi kullanın
Aşağıdaki diyagramda çözümü uygulamak için kullanabileceğiniz basit mimari gösterilmektedir.
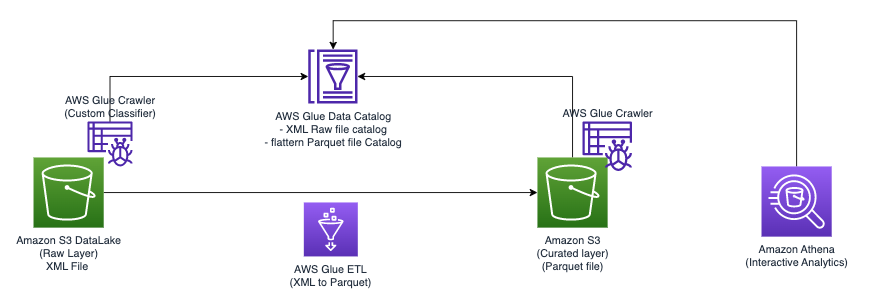
Amazon S3'te depolanan XML dosyalarını AWS Glue ve Athena kullanarak analiz etmek için aşağıdaki üst düzey adımları tamamlıyoruz:
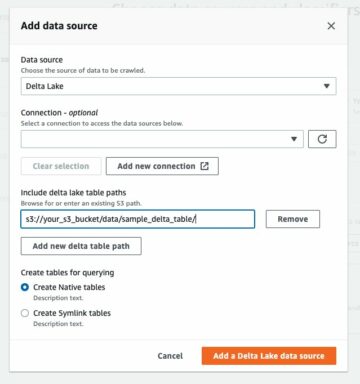
- XML meta verilerini ayıklamak ve AWS Glue Veri Kataloğu'nda bir tablo oluşturmak için bir AWS Glue tarayıcısı oluşturun.
- AWS Glue ayıklama, dönüştürme ve yükleme (ETL) işini kullanarak XML verilerini Athena'ya uygun bir formata (Parquet gibi) işleyin ve dönüştürün.
- AWS Glue konsolu veya AWS Glue konsolu aracılığıyla bir AWS Glue işi kurup çalıştırın. AWS Komut Satırı Arayüzü (AWS CLI'si).
- İşlenen verileri (Parquet formatında) Athena tablolarıyla kullanarak SQL sorgularını etkinleştirin.
- Amazon S3'te depolanan verilerinizdeki XML verilerini SQL sorgularıyla analiz etmek için Athena'nın kullanıcı dostu arayüzünü kullanın.
Bu mimari, AWS Glue ve Athena kullanarak Amazon S3'teki XML verilerini analiz etmeye yönelik ölçeklenebilir, uygun maliyetli bir çözümdür. Büyük veri kümelerini karmaşık altyapı yönetimi olmadan analiz edebilirsiniz.
XML dosyası meta verilerini çıkarmak için AWS Glue tarayıcısını kullanıyoruz. Genel amaçlı XML sınıflandırması için varsayılan AWS Glue sınıflandırıcısını seçebilirsiniz. Yaygın formatlar için yararlı olan XML veri yapısını ve şemasını otomatik olarak algılar.
Bu çözümde ayrıca özel bir XML sınıflandırıcı kullanıyoruz. Belirli XML şemaları veya formatları için tasarlanmış olup hassas meta veri çıkarmaya olanak tanır. Bu, standart olmayan XML formatları için veya sınıflandırma üzerinde ayrıntılı kontrole ihtiyaç duyduğunuzda idealdir. Özel bir sınıflandırıcı, yalnızca gerekli meta verilerin çıkarılmasını sağlayarak aşağı yöndeki işleme ve analiz görevlerini basitleştirir. Bu yaklaşım, XML dosyalarınızın kullanımını optimize eder.
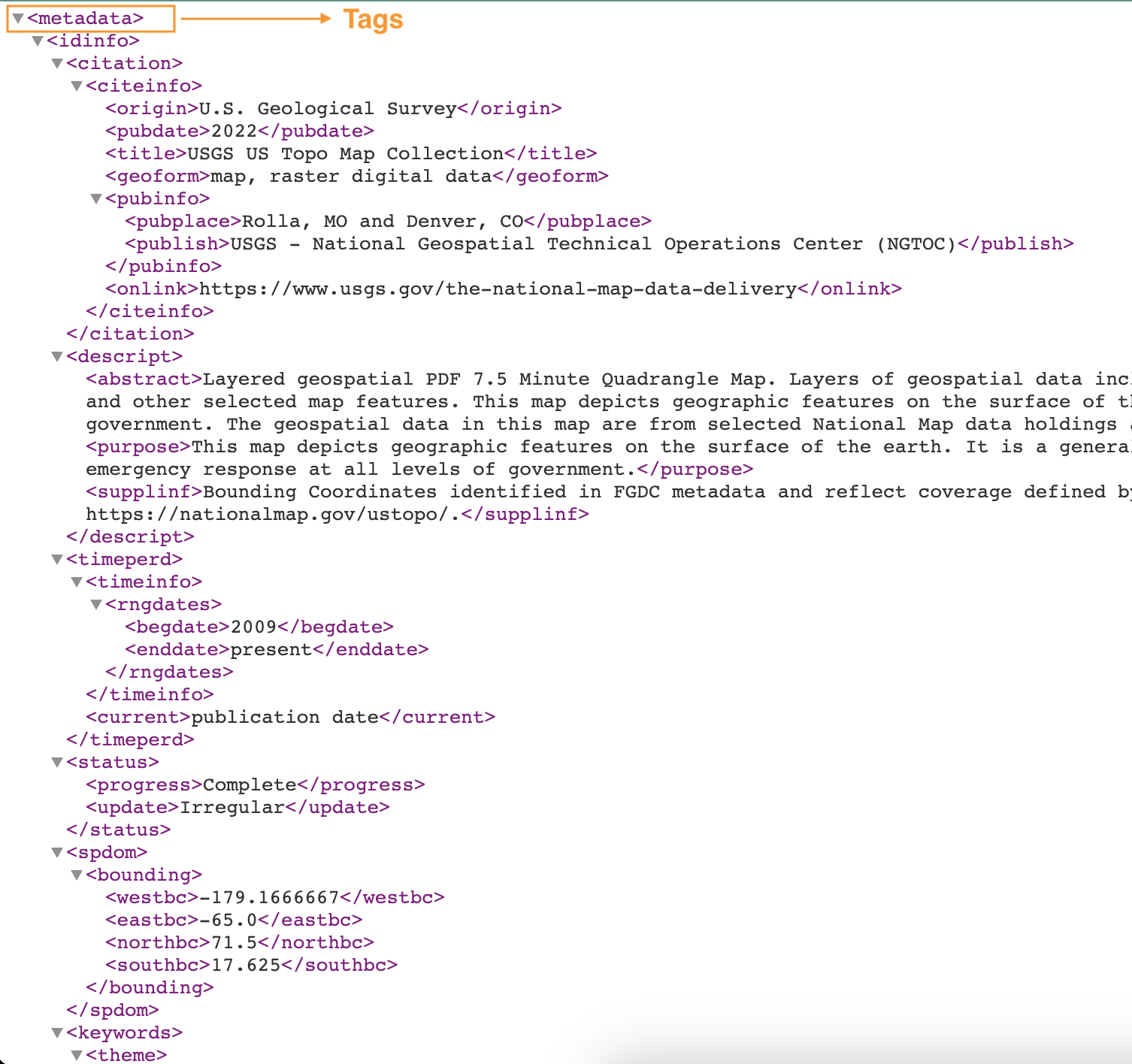
Aşağıdaki ekran görüntüsünde etiketler içeren bir XML dosyası örneği gösterilmektedir.
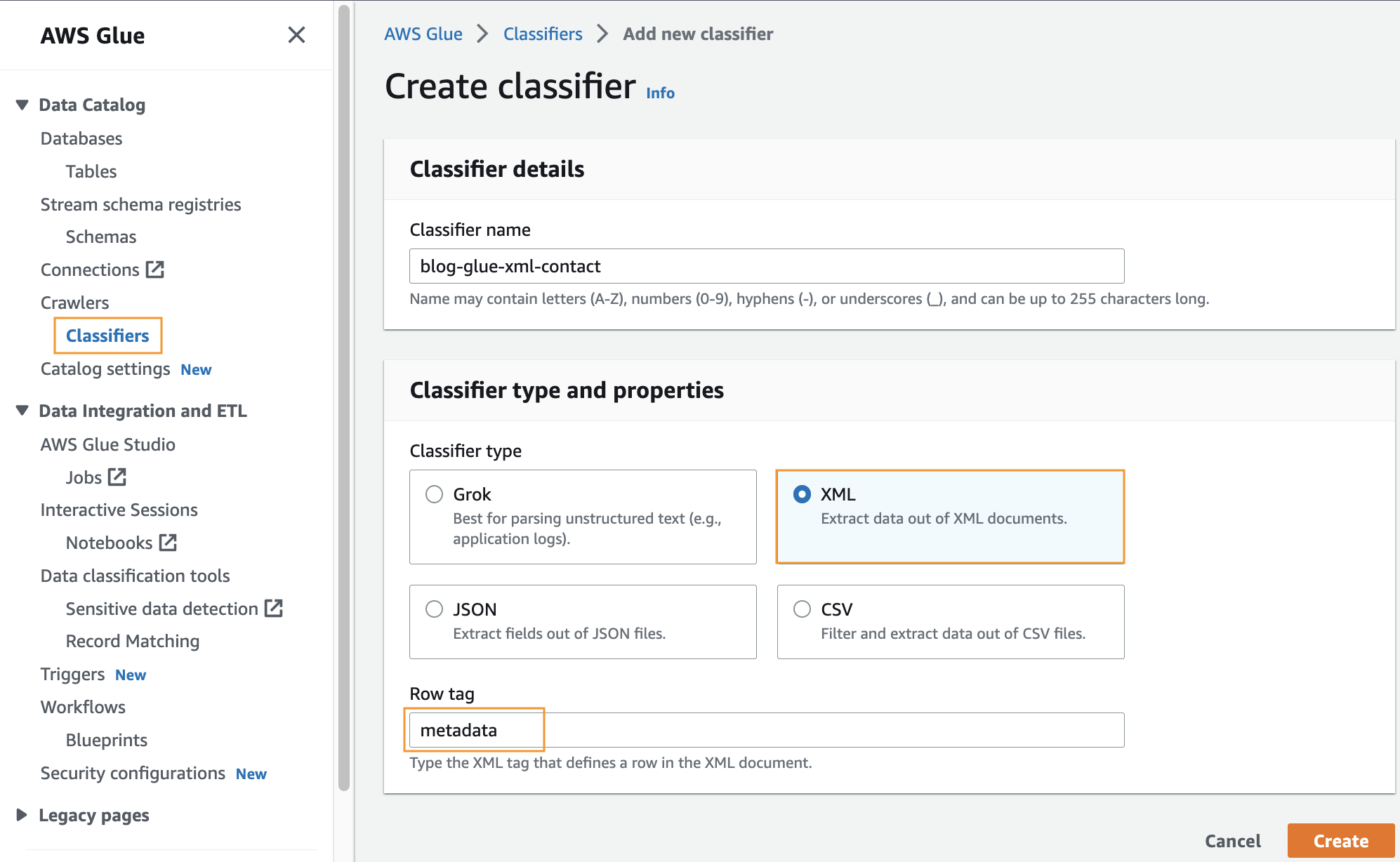
Özel bir sınıflandırıcı oluşturma
Bu adımda, bir XML dosyasından meta verileri çıkarmak için özel bir AWS Glue sınıflandırıcısı oluşturursunuz. Aşağıdaki adımları tamamlayın:
- AWS Tutkal konsolunda, altında Tarayıcıları gezinme bölmesinde öğesini seçin. Sınıflandırıcılar.
- Klinik Sınıflandırıcı ekle.
- seç XML sınıflandırıcı türü olarak
- Sınıflandırıcı için aşağıdaki gibi bir ad girin:
blog-glue-xml-contact. - İçin satır etiketi, meta verileri içeren kök etiketinin adını girin (örneğin,
metadata). - Klinik oluşturmak.
Xml dosyasını taramak için bir AWS Glue Crawler oluşturun
Bu bölümde, önceki adımda oluşturduğumuz müşteri sınıflandırıcısını kullanarak XML dosyasından meta verileri çıkarmak için bir Glue Crawler oluşturuyoruz.
Bir veritabanı oluşturun
- Git AWS Tutkal konsolu, seçmek veritabanları Gezinti bölmesinde.
- Tıklayın Veritabanı ekleyin.
- gibi bir isim verin
blog_glue_xml - Klinik oluşturmak veritabanı
Bir Tarayıcı Oluşturun
İlk tarayıcınızı oluşturmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Tarayıcıları Gezinti bölmesinde.
- Klinik tarayıcı oluştur.
- Üzerinde Tarayıcı özelliklerini ayarlama sayfasında yeni tarayıcı için bir ad girin (örneğin
blog-glue-parquet), ardından Sonraki. - Üzerinde Veri kaynaklarını ve sınıflandırıcıları seçin sayfa seç Henüz değil altında Veri kaynağı yapılandırması.
- Klinik Veri deposu ekleyin.
- İçin S3 yolu, şuraya göz at:
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Klasörün içindeki dosya yerine XML klasörünü seçtiğinizden emin olun.
- Seçeneklerin geri kalanını varsayılan olarak bırakın ve Bir S3 veri kaynağı ekleyin.
- Genişletmek Özel sınıflandırıcılar – isteğe bağlı, blog-glue-xml-contact'ı seçin ve ardından Sonraki ve seçeneklerin geri kalanını varsayılan olarak bırakın.
- IAM rolünüzü seçin veya Yeni IAM rolü oluştur, son eki ekleyin
glue-xml-contact(Örneğin,AWSGlueServiceNotebookRoleBlog), ve Seç Sonraki. - Üzerinde Çıktıyı ve zamanlamayı ayarla sayfanın altında Çıkış yapılandırması, seçmek
blog_glue_xmliçin Hedef veritabanı. - Keşfet
console_tablolara eklenen önek olarak (isteğe bağlı) ve altında paletli program, frekansı ayarlı tutun Talep üzerine. - Klinik Sonraki.
- Tüm parametreleri gözden geçirin ve seçin tarayıcı oluştur.
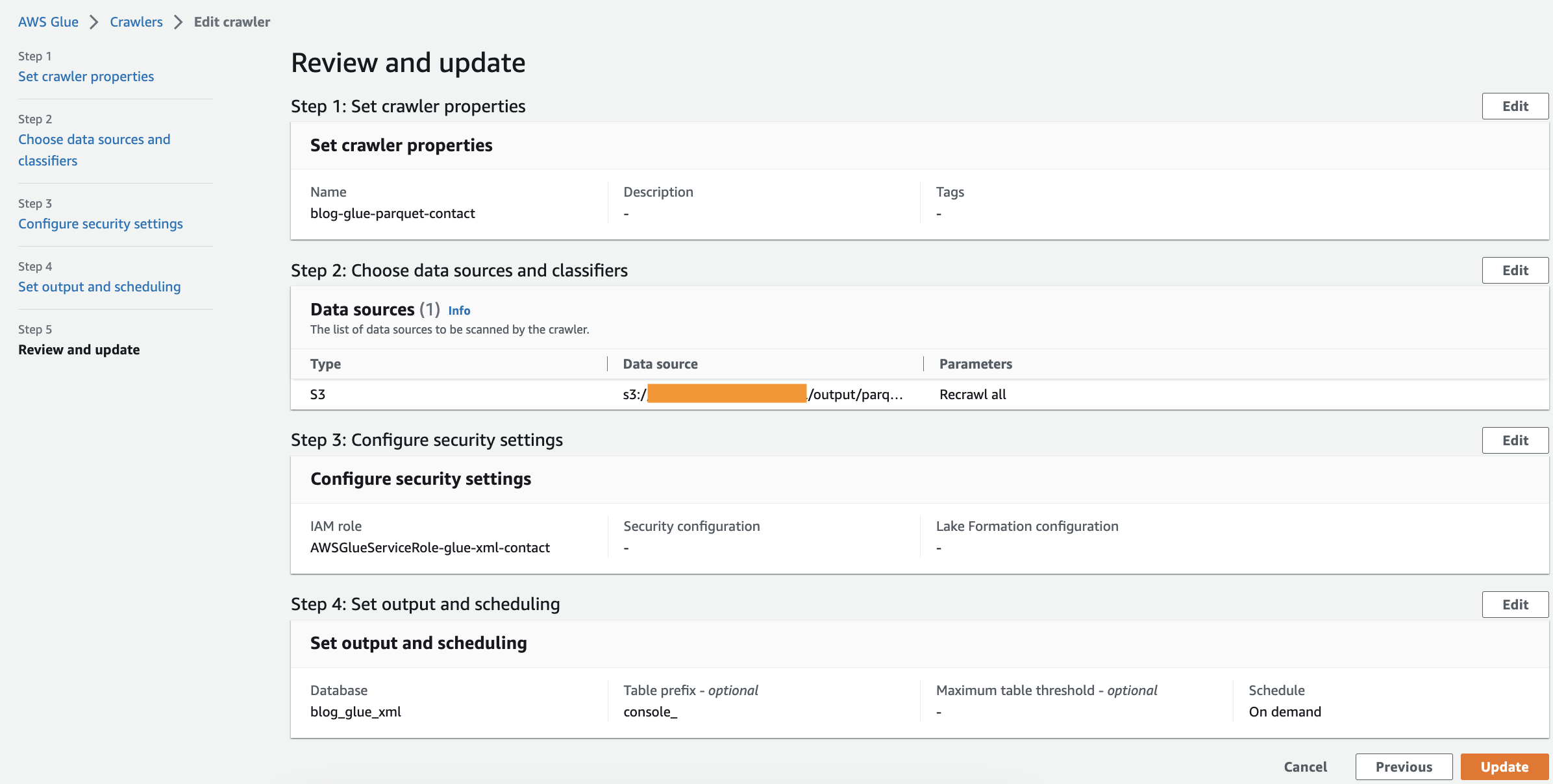
Tarayıcıyı Çalıştır
Tarayıcıyı oluşturduktan sonra çalıştırmak için aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Tarayıcıları Gezinti bölmesinde.
- Oluşturduğunuz tarayıcıyı açın ve seçin koşmak.
Tarayıcının tamamlanması 1-2 dakika sürecektir.
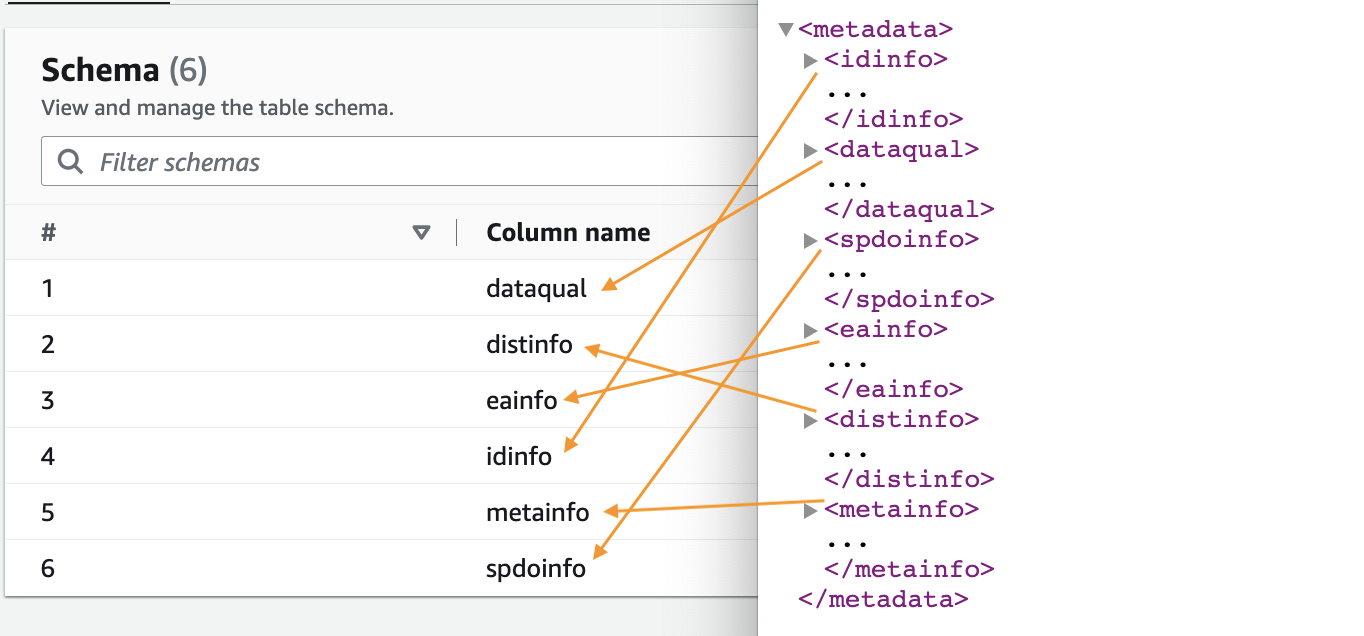
- Tarayıcı tamamlandığında, seçin veritabanları Gezinti bölmesinde.
- Oluşturduğunuz veritabanını seçin ve tarayıcı tarafından çıkarılan şemayı görmek için tablo adını seçin.
XML'i Parke formatına dönüştürmek için bir AWS Glue işi oluşturun
Bu adımda XML dosyasını Parquet dosyasına dönüştürmek için bir AWS Glue Studio işi oluşturursunuz. Aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Mesleki Öğretiler Gezinti bölmesinde.
- Altında İş oluşturseçin Boş bir tuval ile görsel.
- Klinik oluşturmak.
- İşi şu şekilde yeniden adlandırın:
blog_glue_xml_job.
Artık boş bir AWS Glue Studio görsel iş düzenleyiciniz var. Düzenleyicinin üst kısmında farklı görünümlere yönelik sekmeler bulunur.
- Seçin Senaryo AWS Glue ETL betiğinin boş kabuğunu görmek için sekmeyi tıklayın.
Görsel düzenleyiciye yeni adımlar ekledikçe script otomatik olarak güncellenecektir.
- Seçin İş detayları tüm iş yapılandırmalarını görmek için sekmeyi tıklayın.
- İçin IAM rolü, seçmek
AWSGlueServiceNotebookRoleBlog. - İçin Tutkal versiyonu, seçmek Glue 4.0 – Spark 3.3, Scala 2, Python 3'ü destekler.
- set İstenen işçi sayısı 2 için.
- set Yeniden deneme sayısı 0 için.
- Seçin Görsel Görsel düzenleyiciye geri dönmek için sekmeyi tıklayın.
- Üzerinde Kaynak açılır menüden AWS Tutkal Veri Kataloğu.
- Üzerinde Veri kaynağı özellikleri – Veri Kataloğu sekmesinde aşağıdaki bilgileri sağlayın:
- İçin veritabanı, seçmek
blog_glue_xml. - İçin tablo, tarayıcının oluşturduğu console_ adıyla başlayan tabloyu seçin (örneğin,
console_geologicalsurvey).
- İçin veritabanı, seçmek
- Üzerinde Düğüm özellikleri sekmesinde aşağıdaki bilgileri sağlayın:
- değişim Name için
geologicalsurveyVeri kümesi. - Klinik Action ve dönüşüm Şemayı Değiştir (Eşlemeyi Uygula).
- Klinik Düğüm özellikleri ve dönüşümün adını Şemayı Değiştir (Eşlemeyi Uygula) olarak değiştirin
ApplyMapping. - Üzerinde Hedef menü seç S3.
- değişim Name için
- Üzerinde Veri kaynağı özellikleri - S3 sekmesinde aşağıdaki bilgileri sağlayın:
- İçin oluşturulanseçin Parke.
- İçin Sıkıştırma tipiseçin sıkıştırılmamış.
- İçin S3 kaynak türüseçin S3 konumu.
- İçin S3 URL'si, girmek
s3://${BUCKET_NAME}/output/parquet/. - Klinik Düğüm Özellikleri ve adını şu şekilde değiştirin
Output.
- Klinik İndirim işi kurtarmak için.
- Klinik koşmak işi yürütmek için.
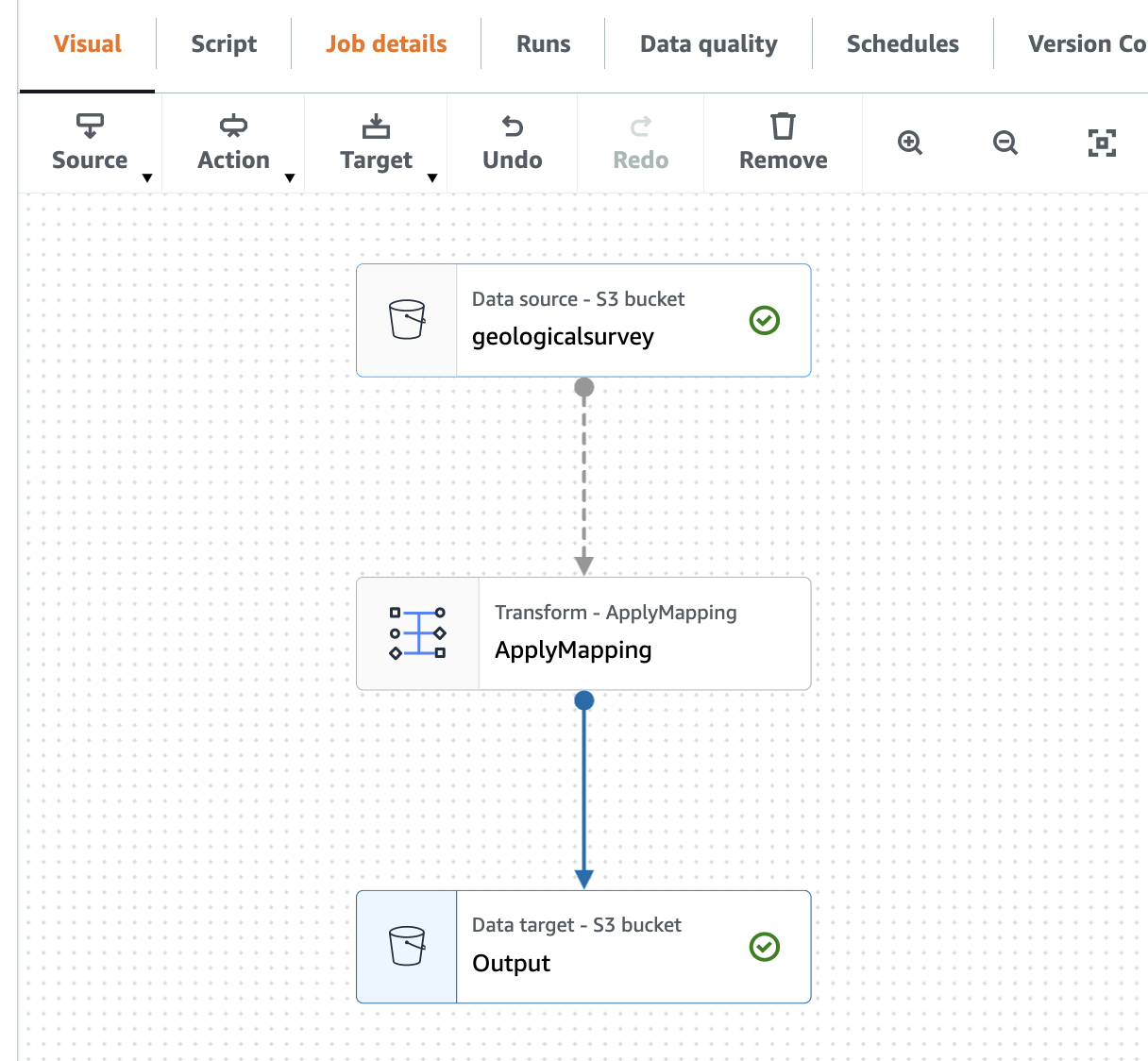
Aşağıdaki ekran görüntüsü işi görsel düzenleyicide göstermektedir.
Parke dosyasını taramak için bir AWS Gue Crawler oluşturun
Bu adımda, bir AWS Glue Studio işi kullanarak oluşturduğunuz Parquet dosyasından meta verileri çıkarmak için bir AWS Glue tarayıcısı oluşturursunuz. Bu sefer varsayılan sınıflandırıcıyı kullanırsınız. Aşağıdaki adımları tamamlayın:
- AWS Glue konsolunda seçin Tarayıcıları Gezinti bölmesinde.
- Klinik tarayıcı oluştur.
- Üzerinde Tarayıcı özelliklerini ayarlama sayfasında yeni tarayıcı için blog-tutkal-parke-temas gibi bir ad girin ve ardından Sonraki.
- Üzerinde Veri kaynaklarını ve sınıflandırıcıları seçin sayfa seç Henüz değil için Veri kaynağı yapılandırması.
- Klinik Veri deposu ekleyin.
- İçin S3 yolu, şuraya göz at:
s3://${BUCKET_NAME}/output/parquet/.
Seçtiğinizden emin olun parquet klasörün içindeki dosya yerine klasör.
- Önkoşul bölümünde oluşturulan IAM rolünüzü seçin veya Yeni IAM rolü oluştur (Örneğin,
AWSGlueServiceNotebookRoleBlog), ve Seç Sonraki. - Üzerinde Çıktıyı ve zamanlamayı ayarla sayfanın altında Çıkış yapılandırması, seçmek
blog_glue_xmliçin veritabanı. - Keşfet
parquet_tablolara eklenen önek olarak (isteğe bağlı) ve altında paletli program, frekansı ayarlı tutun Talep üzerine. - Klinik Sonraki.
- Tüm parametreleri gözden geçirin ve seçin tarayıcı oluştur.
Artık tamamlanması 1-2 dakika süren tarayıcıyı çalıştırabilirsiniz.

Parquet dosyası için yeni oluşturulan şemanın, XML dosyasının şemasına benzeyen AWS Glue Data Catalog'da ön izlemesini yapabilirsiniz.
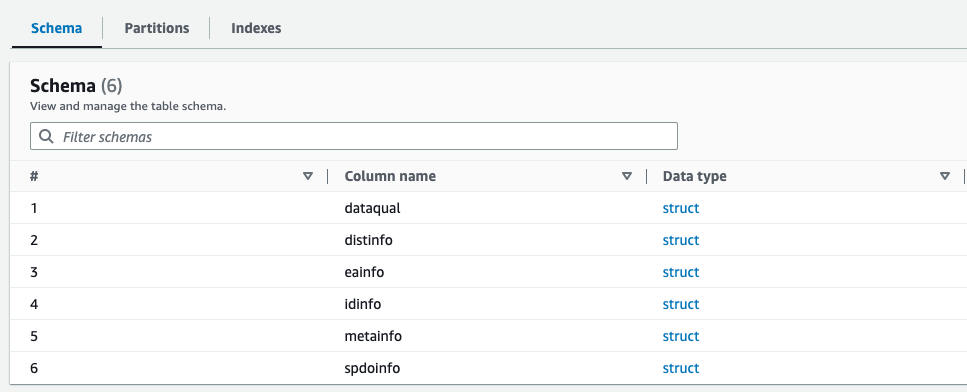
Artık Athena ile kullanıma uygun verilere sahibiz. Bir sonraki bölümde Athena kullanarak veri sorgulamaları gerçekleştiriyoruz.
Athena'yı kullanarak Parke dosyasını sorgulayın
Athena sorgulamayı desteklemiyor XML dosya formatı, bu nedenle daha verimli veri sorgulama ve kullanım için XML dosyasını Parquet'e dönüştürdünüz. nokta gösterimi karmaşık türleri ve iç içe geçmiş yapıları sorgulamak için.
Aşağıdaki örnek kod, iç içe geçmiş verileri sorgulamak için nokta gösterimini kullanır:
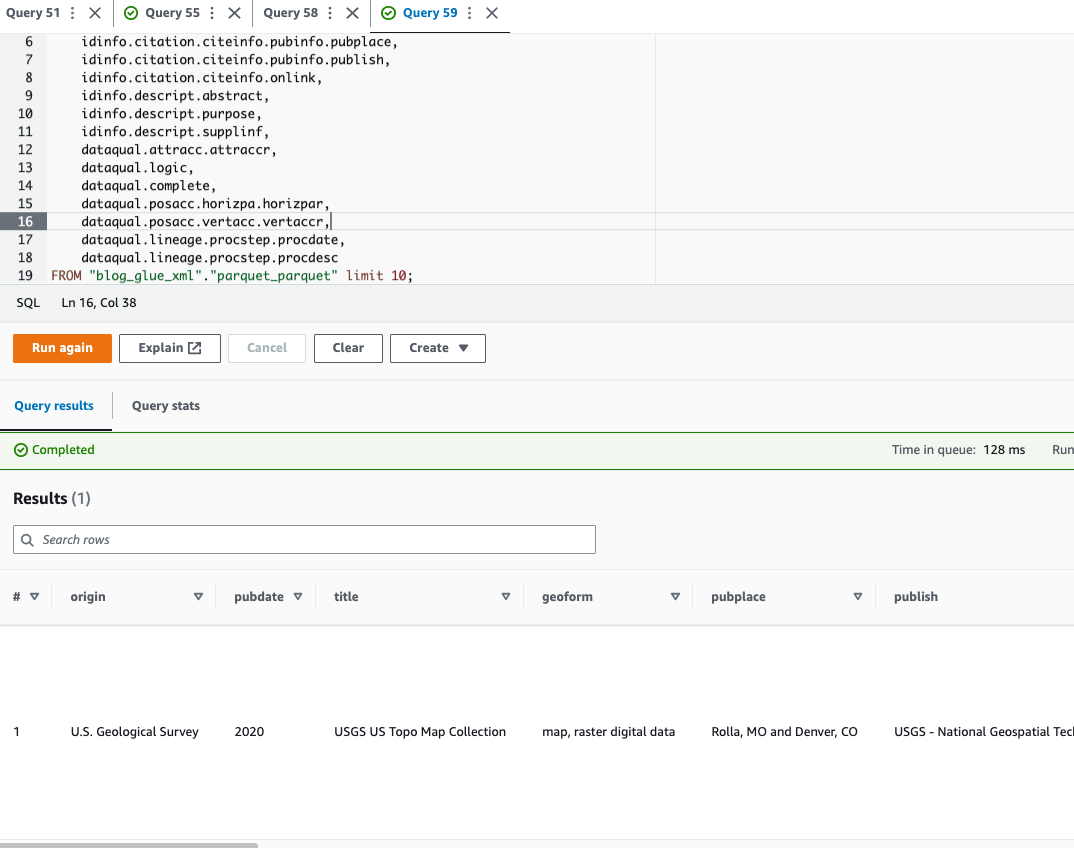
Artık teknik 1'i tamamladığımıza göre, teknik 2'yi öğrenmeye geçelim.
Teknik 2: Çıkarımlı ve sabit şemalarla AWS Glue DynamicFrames'i kullanma
Önceki bölümde, bir tablo oluşturmak için AWS Glue tarayıcısını, dosyayı Parquet formatına dönüştürmek için bir AWS Glue işini ve Parquet verilerine erişmek için Athena'yı kullanarak küçük bir XML dosyasını işleme sürecini ele aldık. Ancak tarayıcı, belirtilen değerleri aşan XML dosyalarını işlemeye geldiğinde sınırlamalarla karşılaşır. 1 MB boyutunda. Bu bölümde, bireysel olayları çıkarmak ve Athena kullanarak analiz yürütmek için ek ayrıştırma gerektiren daha büyük XML dosyalarının toplu işlenmesi konusunu derinlemesine inceleyeceğiz.
Yaklaşımımız XML dosyalarının AWS Glue aracılığıyla okunmasını içerir Dinamik Çerçevelerhem çıkarımsal hem de sabit şemaları kullanır. Daha sonra bireysel olayları Parke formatında çıkarıyoruz. ilişkilendirmek Athena'yı kullanarak bunları sorunsuz bir şekilde sorgulamamıza ve analiz etmemize olanak tanıyor.
Bu çözümü uygulamak için aşağıdaki üst düzey adımları tamamlarsınız:
- XML dosyasını okumak ve analiz etmek için bir AWS Glue not defteri oluşturun.
- kullanım
DynamicFramesileInferSchemaXML dosyasını okumak için. - Herhangi bir diziyi yuvalamak için ilişkiselleştirme işlevini kullanın.
- Verileri Parke formatına dönüştürün.
- Athena'yı kullanarak Parke verilerini sorgulayın.
- Önceki adımları tekrarlayın, ancak bu sefer bir şema iletin
DynamicFrameskullanmak yerineInferSchema.
Elektrikli araç nüfus verileri XML dosyasında response etiketini kök düzeyinde kullanın. Bu etiket bir dizi içerir row içine yerleştirilmiş etiketler. Satır etiketi, bir araç hakkında markası, modeli ve diğer ilgili ayrıntılar dahil olmak üzere bilgi sağlayan bir dizi başka satır etiketi içeren bir dizidir. Aşağıdaki ekran görüntüsü bir örneği göstermektedir.

AWS Glue Notebook Oluşturun
AWS Glue not defteri oluşturmak için aşağıdaki adımları tamamlayın:
- Açın AWS Tutkal Stüdyosu konsol, seç Mesleki Öğretiler Gezinti bölmesinde.
- seç Jupyter Not Defteri Ve seç oluşturmak.
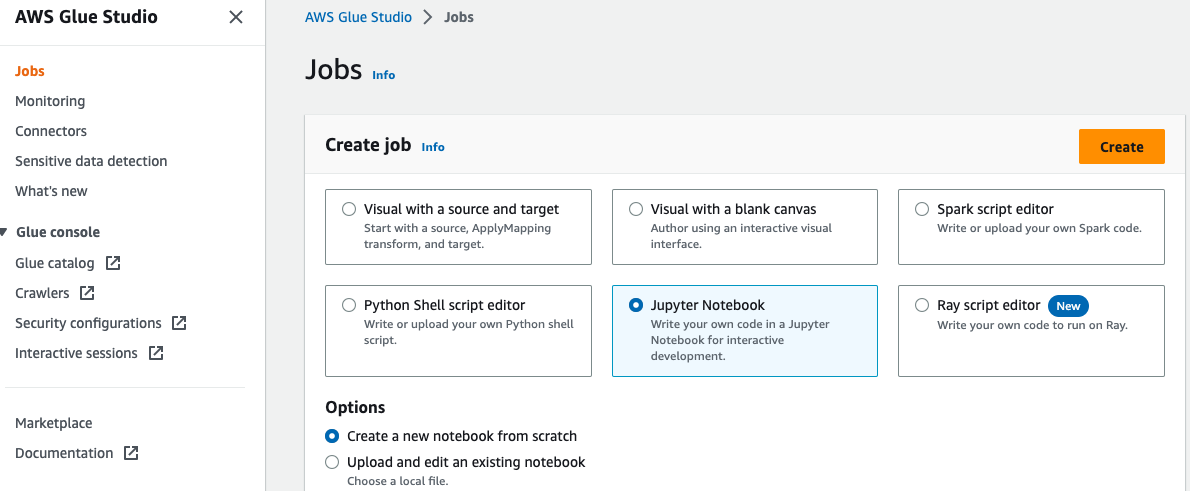
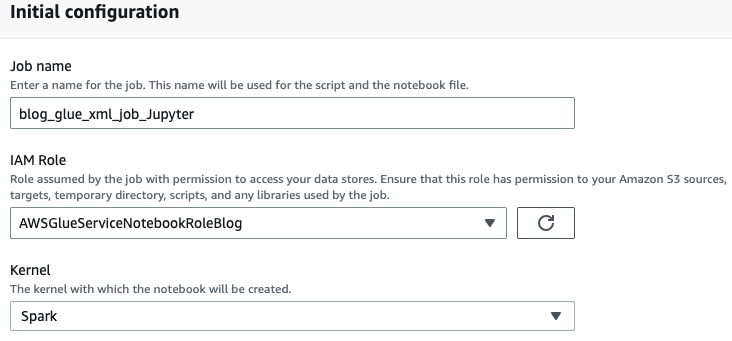
- AWS Glue işiniz için bir ad girin; örneğin
blog_glue_xml_job_Jupyter. - Önkoşullarda oluşturduğunuz rolü seçin (
AWSGlueServiceNotebookRoleBlog).
AWS Glue dizüstü bilgisayar, bir veritabanının nasıl sorgulanacağını ve çıktının Amazon S3'e nasıl yazılacağını gösteren önceden var olan bir örnekle birlikte gelir.
- Aşağıdaki ekran görüntüsünde gösterildiği gibi zaman aşımını (dakika olarak) ayarlayın ve AWS Glue etkileşimli oturumunu oluşturmak için hücreyi çalıştırın.
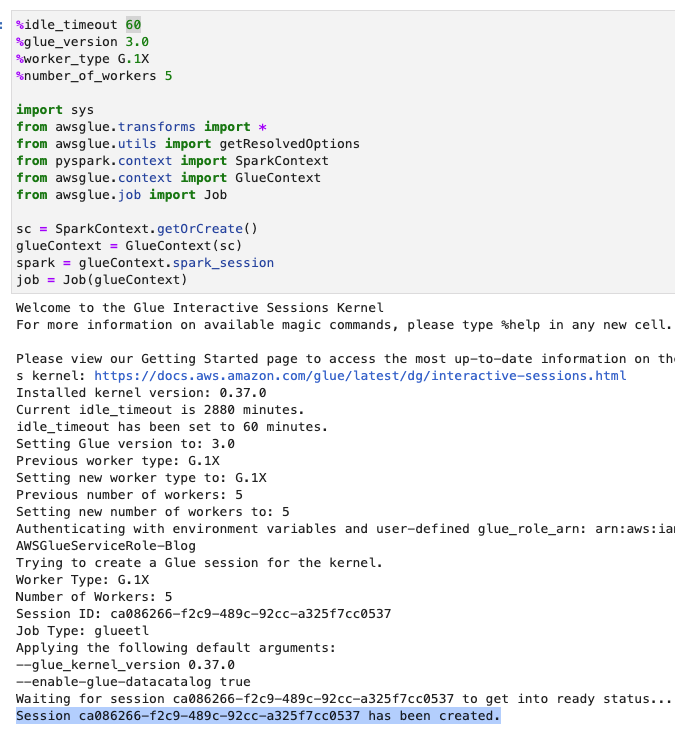
Temel Değişkenler oluşturun
Etkileşimli oturumu oluşturduktan sonra not defterinin sonunda aşağıdaki değişkenleri içeren yeni bir hücre oluşturun (kendi paket adınızı girin):
Şemayı çıkaran XML dosyasını okuyun
Eğer bir şemayı DynamicFrame, dosyaların şemasını çıkaracaktır. Verileri dinamik bir çerçeve kullanarak okumak için aşağıdaki komutu kullanabilirsiniz:
DynamicFrame Şemasını yazdırın
Şemayı aşağıdaki kodla yazdırın:
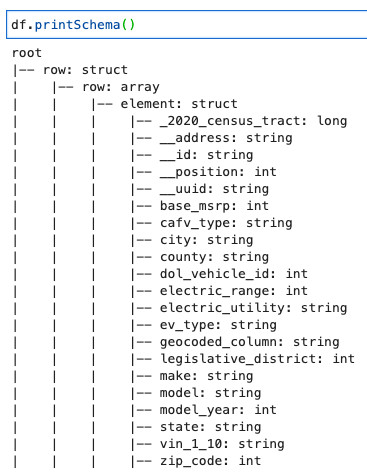
Şema iç içe geçmiş bir yapıyı göstermektedir. row birden fazla öğe içeren dizi. Bu yapıyı çizgilere ayırmak için AWS Glue'u kullanabilirsiniz. ilişkilendirmek dönüşüm:
Yalnızca satır dizisinin içerdiği bilgilerle ilgileniyoruz ve aşağıdaki komutu kullanarak şemayı görüntüleyebiliriz:
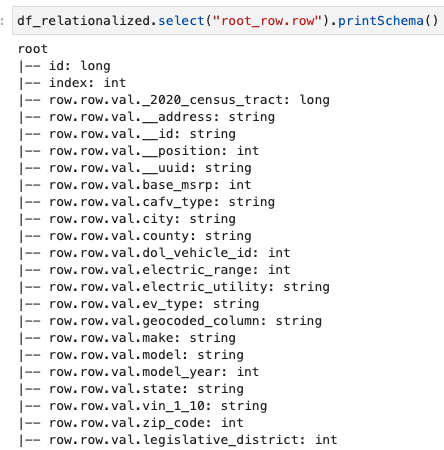
Sütun adları şunları içerir: row.rowveri kümesindeki dizi yapısına ve dizi sütununa karşılık gelir. Bu yazıdaki sütunları yeniden adlandırmıyoruz; bunu yapmaya yönelik talimatlar için bkz. AWS Glue: Bölüm 1'i kullanarak veri dosyalarındaki sütun adlarının dinamik eşlenmesini ve yeniden adlandırılmasını otomatikleştirin. Daha sonra aşağıdaki komutu kullanarak verileri Parquet formatına dönüştürebilir ve AWS Glue tablosunu oluşturabilirsiniz:
AWS Tutkal DynamicFrame Veri Kataloğu'nda bir şema oluşturmak ve güncellemek için ETL betiğinizde kullanabileceğiniz özellikler sağlar. biz kullanıyoruz updateBehavior Tabloyu doğrudan Veri Kataloğunda oluşturmak için parametre. Bu yaklaşımla, AWS Glue işi tamamlandıktan sonra bir AWS Glue tarayıcısını çalıştırmamıza gerek kalmıyor.

Bir şema ayarlayarak XML dosyasını okuyun
Dosyayı okumanın alternatif bir yolu da şemayı önceden tanımlamaktır. Bunu yapmak için aşağıdaki adımları tamamlayın:
- AWS Glue veri türlerini içe aktarın:
- XML dosyası için bir şema oluşturun:
- XML dosyasını okurken şemayı iletin:
- Veri kümesini daha önce olduğu gibi ayırın:
- Veri kümesini Parquet'e dönüştürün ve AWS Glue tablosunu oluşturun:
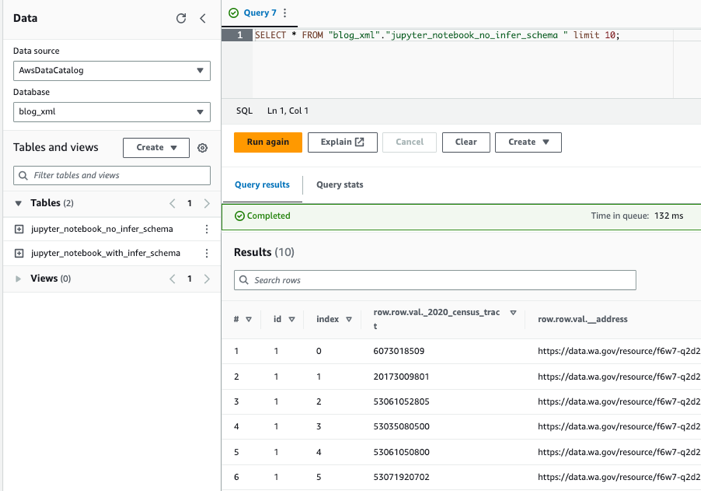
Athena'yı kullanarak tabloları sorgulama
Artık her iki tabloyu da oluşturduğumuza göre Athena kullanarak tabloları sorgulayabiliriz. Örneğin aşağıdaki sorguyu kullanabiliriz:
Temizlemek
Bu yazıda bir IAM rolü, bir AWS Glue Jupyter not defteri ve AWS Glue Veri Kataloğunda iki tablo oluşturduk. Ayrıca bazı dosyaları bir S3 klasörüne yükledik. Bu nesneleri temizlemek için aşağıdaki adımları tamamlayın:
- IAM konsolunda oluşturduğunuz rolü silin.
- AWS Glue Studio konsolunda özel sınıflandırıcıyı, tarayıcıyı, ETL işlerini ve Jupyter not defterini silin.
- AWS Glue Data Catalog'a gidin ve oluşturduğunuz tabloları silin.
- Amazon S3 konsolunda oluşturduğunuz klasöre gidin ve adlı klasörleri silin.
temp,infer_schema, veno_infer_schema.
Önemli Noktalar
AWS Glue'da şöyle bir özellik var: InferSchema AWS Glue'da DynamicFrames. Bir veri çerçevesinin yapısını, içerdiği verilere göre otomatik olarak belirler. Bunun tersine, şema tanımlamak, verileri yüklemeden önce veri çerçevesi yapısının nasıl olması gerektiğini açıkça belirtmek anlamına gelir.
Metin tabanlı bir format olan XML, sütunlarının veri türlerini kısıtlamaz. Bu, InferSchema işleviyle ilgili sorunlara neden olabilir. Örneğin, ilk çalıştırmada, A sütunu 2 değerine sahip bir dosya, A sütunu tam sayı olan bir Parke dosyasıyla sonuçlanır. İkinci çalıştırmada, yeni bir dosyanın C değerine sahip A sütunu vardır ve bu da dize olarak A sütununu içeren bir Parquet dosyasına yol açar. Artık S3'te, her biri farklı veri türlerinden oluşan bir A sütununa sahip olan ve aşağı yönde sorun yaratabilecek iki dosya var.
Aynı şey iç içe geçmiş yapılar veya diziler gibi karmaşık veri türlerinde de olur. Örneğin, bir dosyanın adı verilen bir etiket girişi varsa transaction, bir yapı olarak anlaşılmaktadır. Ancak başka bir dosya aynı etikete sahipse bu bir dizi olarak anlaşılır
Bu veri türü sorunlarına rağmen, InferSchema Şemayı bilmediğinizde veya şemayı manuel olarak tanımlamanın pratik olmadığı durumlarda kullanışlıdır. Ancak büyük veya sürekli değişen veri kümeleri için ideal değildir. Bir şema tanımlamak, özellikle karmaşık veri türlerinde daha kesindir ancak manuel çaba gerektirmesi ve veri değişikliklerine karşı esnek olmaması gibi kendi sorunları vardır.
InferSchema yanlış veri türü çıkarımı ve boş değerlerin işlenmesiyle ilgili sorunlar gibi sınırlamalara sahiptir. Şema tanımlamanın manuel çaba ve olası hatalar gibi sınırlamaları da vardır.
Bir şemayı çıkarmak ve tanımlamak arasında seçim yapmak projenin ihtiyaçlarına bağlıdır. InferSchema, küçük veri kümelerinin hızlı bir şekilde keşfedilmesi için mükemmeldir; oysa şema tanımlamak, doğruluk ve tutarlılık gerektiren daha büyük, karmaşık veri kümeleri için daha iyidir. Projenize en uygun olanı seçmek için her yöntemin ödünleşimlerini ve kısıtlamalarını göz önünde bulundurun.
Sonuç
Bu yazıda, AWS Glue kullanarak XML verilerini yönetmeye yönelik, her biri karşılaşabileceğiniz belirli ihtiyaçlara ve zorluklara yanıt verecek şekilde tasarlanmış iki tekniği inceledik.
Teknik 1, grafiksel arayüzü tercih edenler için kullanıcı dostu bir yol sunar. XML dosyalarınızın tablo yapısını zahmetsizce tanımlamak için bir AWS Glue tarayıcısını ve görsel düzenleyiciyi kullanabilirsiniz. Bu yaklaşım, veri yönetimi sürecini basitleştirir ve özellikle verilerini işlemenin basit bir yolunu arayanlar için caziptir.
Ancak, özellikle satırları 1 MB'tan büyük olan XML dosyalarıyla uğraşırken tarayıcının sınırlamalarının olduğunun farkındayız. Teknik 2'nin kurtarmaya geldiği yer burasıdır. AWS Glue'dan yararlanarak DynamicFrames hem çıkarımlanmış hem de sabit şemalarla ve bir AWS Glue dizüstü bilgisayar kullanarak, her boyuttaki XML dosyalarını verimli bir şekilde işleyebilirsiniz. Bu yöntem, 1 MB sınırlamasını aşan satırlara sahip XML dosyaları için bile sorunsuz işlemeyi sağlayan sağlam bir çözüm sağlar.
Veri yönetimi dünyasında gezinirken, bu tekniklerin araç setinizde bulunması, projenizin özel gereksinimlerine göre bilinçli kararlar vermenizi sağlar. İster 1. tekniğin basitliğini ister 2. tekniğin ölçeklenebilirliğini tercih edin, AWS Glue, XML verilerini etkili bir şekilde işlemek için ihtiyaç duyduğunuz esnekliği sağlar.
Yazarlar Hakkında
 Navnit ŞuklaAnalitik odaklı bir AWS Uzman Çözüm Mimarı olarak hizmet vermektedir. Müşterilerin verilerinden değerli içgörüler keşfetmelerine yardımcı olma konusunda güçlü bir istek duyuyor. Uzmanlığı sayesinde işletmelerin bilinçli, veri odaklı seçimlere ulaşmasını sağlayan yenilikçi çözümler üretiyor. Navnit Shukla'nın "AWS'de Veri Wrangling" başlıklı kitabın başarılı yazarı olması dikkat çekicidir.
Navnit ŞuklaAnalitik odaklı bir AWS Uzman Çözüm Mimarı olarak hizmet vermektedir. Müşterilerin verilerinden değerli içgörüler keşfetmelerine yardımcı olma konusunda güçlü bir istek duyuyor. Uzmanlığı sayesinde işletmelerin bilinçli, veri odaklı seçimlere ulaşmasını sağlayan yenilikçi çözümler üretiyor. Navnit Shukla'nın "AWS'de Veri Wrangling" başlıklı kitabın başarılı yazarı olması dikkat çekicidir.
 Patrick Müller AWS'de Kıdemli Veri Laboratuvarı Mimarı olarak çalışıyor. Ana sorumluluğu müşterilerin fikirlerini üretime hazır bir veri ürününe dönüştürmelerine yardımcı olmaktır. Patrick boş zamanlarında futbol oynamaktan, film izlemekten ve seyahat etmekten hoşlanıyor.
Patrick Müller AWS'de Kıdemli Veri Laboratuvarı Mimarı olarak çalışıyor. Ana sorumluluğu müşterilerin fikirlerini üretime hazır bir veri ürününe dönüştürmelerine yardımcı olmaktır. Patrick boş zamanlarında futbol oynamaktan, film izlemekten ve seyahat etmekten hoşlanıyor.
 Amogh Gaikwad Amazon Web Services'te Kıdemli Çözüm Geliştiricisidir. Küresel müşterilerin AWS'de AI/ML çözümleri oluşturmasına ve dağıtmasına yardımcı oluyor. Çalışmaları temel olarak bilgisayarlı görüntü ve doğal dil işlemeye odaklanıyor ve müşterilerin AI/ML iş yüklerini sürdürülebilirlik için optimize etmelerine yardımcı oluyor. Amogh, yüksek lisansını Bilgisayar Bilimleri alanında, Makine Öğrenimi alanında uzmanlaştı.
Amogh Gaikwad Amazon Web Services'te Kıdemli Çözüm Geliştiricisidir. Küresel müşterilerin AWS'de AI/ML çözümleri oluşturmasına ve dağıtmasına yardımcı oluyor. Çalışmaları temel olarak bilgisayarlı görüntü ve doğal dil işlemeye odaklanıyor ve müşterilerin AI/ML iş yüklerini sürdürülebilirlik için optimize etmelerine yardımcı oluyor. Amogh, yüksek lisansını Bilgisayar Bilimleri alanında, Makine Öğrenimi alanında uzmanlaştı.
 Sheela Sonone AWS'de Kıdemli Yerleşik Mimardır. AWS müşterilerinin verilerini, analizlerini ve AI/ML iş yüklerini ve uygulamalarını hızlandırma konusunda bilinçli seçimler yapmasına ve ödünler vermesine yardımcı oluyor. Boş zamanlarında ailesiyle, genellikle tenis kortlarında vakit geçirmekten hoşlanıyor.
Sheela Sonone AWS'de Kıdemli Yerleşik Mimardır. AWS müşterilerinin verilerini, analizlerini ve AI/ML iş yüklerini ve uygulamalarını hızlandırma konusunda bilinçli seçimler yapmasına ve ödünler vermesine yardımcı oluyor. Boş zamanlarında ailesiyle, genellikle tenis kortlarında vakit geçirmekten hoşlanıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- $UP
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Hakkımızda
- ÖZET
- hızlanan
- erişim
- ulaşabilme
- başarılı
- doğruluk
- karşısında
- Action
- eklemek
- katma
- Ek
- adres
- Sonra
- yaş
- AI / ML
- Türkiye
- izin vermek
- Izin
- veriyor
- Ayrıca
- alternatif
- Amazon
- Amazon Atina
- Amazon Web Servisleri
- an
- analiz
- analytics
- çözümlemek
- analiz
- ve
- Başka
- herhangi
- Apache
- çekici
- uygulamaları
- Tamam
- yaklaşım
- yaklaşımlar
- mimari
- ARE
- Dizi
- AS
- yardım
- yardım
- At
- yazar
- otomatik olarak
- mevcut
- AWS
- AWS Tutkal
- Arka
- merkezli
- temel
- BE
- Çünkü
- önce
- başlamak
- olmak
- İYİ
- Daha iyi
- arasında
- boş
- kitap
- her ikisi de
- inşa etmek
- işletmeler
- fakat
- by
- denilen
- CAN
- katalog
- Sebeb olmak
- hücre
- zorluklar
- değişiklik
- değişiklikler
- değiştirme
- choices
- Klinik
- Şehir
- sınıflandırma
- istemciler
- kod
- Sütun
- Sütunlar
- COM
- geliyor
- ortak
- çoğunlukla
- tamamlamak
- Tamamlandı
- karmaşık
- bilgisayar
- Bilgisayar Bilimleri
- Bilgisayar görüşü
- koşul
- Davranış
- birlikte
- Düşünmek
- konsolos
- sürekli
- kısıtlamaları
- kurmak
- içermek
- içerdiği
- içeren
- kontrast
- kontrol
- dönüştürmek
- dönüştürülmüş
- uygun maliyetli
- uygun maliyetli çözüm
- ilçe
- Mahkemeler
- kaplı
- paletli
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Oluşturma
- çok önemli
- görenek
- müşteri
- Müşteriler
- veri
- veri entegrasyonu
- veri yönetimi
- veri-güdümlü
- veritabanı
- veri kümeleri
- ilgili
- kararlar
- Varsayılan
- tanımlamak
- tanımlarken
- altüst ederek aramak
- gösteriyor
- bağlıdır
- dağıtmak
- tasarlanmış
- detaylı
- ayrıntılar
- Geliştirici
- farklı
- zor
- dijital
- dijital yaş
- direkt olarak
- keşfetme
- farklı
- do
- Değil
- yapılmış
- Dont
- DOT
- sırasında
- dinamik
- her
- kolaylaştırmak
- kolayca
- kolay
- editör
- Efekt
- etkili bir şekilde
- verim
- verimli
- verimli biçimde
- çaba
- zahmetsizce
- Elektrik
- elektrikli araç
- elemanları
- kullanılarak
- güçlendirmek
- olarak güçlendiriyor
- boş
- etkinleştirmek
- etkinleştirme
- karşılaşma
- son
- Motorlar
- artırmak
- sağlamak
- olmasını sağlar
- Keşfet
- coşku
- giriş
- Hatalar
- özellikle
- Eter (ETH)
- Hatta
- olaylar
- Her
- örnek
- aşmak
- değiş tokuş
- Uzmanlık
- keşif
- keşfetmek
- keşfedilmeyi
- çıkarmak
- çıkarma
- aile
- Özellikler(Hazırlık aşamasında)
- Özellikler
- rakamlar
- fileto
- dosyalar
- maliye
- Ad
- sabit
- Esneklik
- odak
- odaklanmış
- takip etme
- İçin
- biçim
- ÇERÇEVE
- Ücretsiz
- Sıklık
- itibaren
- işlev
- Kazanç
- genel amaçlı
- oluşturmak
- Küresel
- Go
- gol
- Hükümet
- harika
- sap
- kullanma
- olur
- Koşum
- Var
- sahip olan
- he
- sağlık
- Network XNUMX'in Kalbi
- yardım et
- yardım
- yardımcı olur
- onu
- üst düzey
- büyük ölçüde
- onun
- Ne kadar
- Nasıl Yapılır
- Ancak
- HTML
- http
- HTTPS
- IAM
- ideal
- fikirler
- Kimlik
- if
- göstermektedir
- uygulamak
- uygulamaları
- uygulanması
- ithalat
- iyileştirmek
- gelişmiş
- in
- Dahil olmak üzere
- bireysel
- bireyler
- Endüstri
- bilgi
- bilgi
- Altyapı
- yenilikçi
- içeride
- anlayışlar
- yerine
- talimatlar
- entegre
- bütünleşme
- interaktif
- ilgili
- arayüzey
- içine
- içerir
- sorunlar
- IT
- ONUN
- İş
- Mesleki Öğretiler
- jpg
- json
- Jupyter Not Defteri
- tutmak
- Bilmek
- laboratuvar
- dil
- büyük
- büyük
- önemli
- ÖĞRENİN
- öğrenme
- seviye
- sevmek
- LİMİT
- sınırlama
- sınırlamaları
- çizgi
- hatları
- yük
- yükleme
- mantık
- bakıyor
- makine
- makine öğrenme
- Ana
- ağırlıklı olarak
- yapmak
- Yapımı
- yönetim
- yönetme
- Manuel
- el ile
- çok
- haritalama
- yüksek lisans
- Mayıs..
- anlamına geliyor
- Menü
- Metadata
- yöntem
- dakika
- model
- Daha
- daha verimli
- çoğu
- hareket
- filmler
- çoklu
- isim
- adlı
- isimleri
- Doğal (Madenden)
- Doğal lisan
- Doğal Dil İşleme
- Gezin
- Navigasyon
- gerekli
- gerek
- ihtiyaçlar
- yeni
- yeni
- sonraki
- özellikle
- defter
- şimdi
- numara
- nesneler
- of
- Teklifler
- on
- ONE
- bir tek
- Operasyon
- optimum
- optimize
- optimize
- Opsiyonlar
- or
- sipariş
- organizasyonlar
- Origin
- Diğer
- bizim
- dışarı
- çıktı
- tekrar
- Üstesinden gelmek
- kendi
- Kanal
- bölmesi
- parametre
- parametreler
- Bölüm
- özellikle
- geçmek
- yol
- patrick
- yapmak
- performans
- izinleri
- seçmek
- Platon
- Plato Veri Zekası
- PlatoVeri
- oynama
- politika
- nüfus
- sahip olmak
- Çivi
- potansiyel
- gerek
- tercih
- önkoşullar
- Önizleme
- önceki
- sorunlar
- süreç
- işlenmiş
- işleme
- PLATFORM
- proje
- Projeler
- özellikleri
- sağlamak
- sağlar
- yayınlamak
- amaç
- Python
- sorgular
- Hızlı
- daha doğrusu
- Okumak
- kolayca
- Okuma
- nedenleri
- Alınan
- tanımak
- başvurmak
- uygun
- Yer Alan Kurallar
- kurtarmak
- kaynak
- yanıt
- sorumluluk
- DİNLENME
- kısıtlamak
- kısıtlama
- Sonuçlar
- gürbüz
- Rol
- kök
- SIRA
- koşmak
- aynı
- İndirim
- Scala
- ölçeklenebilirlik
- ölçeklenebilir
- Bilim
- senaryo
- sorunsuz
- sorunsuz
- İkinci
- Bölüm
- görmek
- kıdemli
- Hizmetler
- Oturum
- set
- ayar
- birkaç
- o
- Kabuk
- meli
- şov
- gösterilen
- Gösteriler
- benzer
- Basit
- basitlik
- basitleştirilmesi
- tek
- beden
- küçük
- So
- Futbol
- çözüm
- Çözümler
- biraz
- Kaynak
- kaynaklar
- Kıvılcım
- uzman
- uzmanlaşmış
- özel
- özellikle
- hız
- Harcama
- SQL
- standart
- başlar
- Eyalet
- Açıklama
- belirten
- adım
- Basamaklar
- hafızası
- saklı
- basit
- kolaylaştırmak
- dizi
- güçlü
- yapı
- yapılar
- stüdyo
- başarı
- böyle
- uygun
- destek
- elbette
- Sürdürülebilirlik
- Sistemler
- tablo
- TAG
- ısmarlama
- Bizi daha iyi tanımak için
- alır
- görevleri
- teknikleri
- tenis
- göre
- o
- The
- Bilgi
- Dünya
- ve bazı Asya
- Onları
- sonra
- Orada.
- Bunlar
- onlar
- Re-Tweet
- Bu
- İçinden
- zaman
- Başlık
- başlıklı
- için
- bugünkü
- araç
- üst
- konu
- Dönüştürmek
- Dönüşüm
- Seyahat
- Dönüş
- öğretici
- iki
- tip
- türleri
- nihai
- altında
- Güncelleme
- güncellenmiş
- Yüklenen
- us
- KULLANILABİLİRLİK
- kullanım
- Kullanılmış
- kullanıcı
- Kullanıcı Arayüzü
- kullanıcı dostu
- kullanım
- kullanma
- genellikle
- Kullanılması
- Değerli
- değer
- Değerler
- araç
- versiyon
- üzerinden
- Görüntüle
- Gösterim
- vizyonumuz
- izlerken
- Yol..
- we
- ağ
- web hizmetleri
- Ne
- ne zaman
- oysa
- olup olmadığını
- hangi
- DSÖ
- neden
- irade
- ile
- içinde
- olmadan
- İş
- iş akışı
- iş akışları
- çalışır
- Dünya
- yazmak
- XML
- sen
- zefirnet