Yazara göre resim
Denetimsiz öğrenme paradigmasına aşina iseniz, boyut indirgeme ve boyut indirgeme için kullanılan aşağıdaki gibi algoritmalarla karşılaşırsınız: ana bileşen analizi (PCA). Makine öğrenimi için veri kümeleri genellikle çok sayıda özellik içerir, ancak bu tür yüksek boyutlu özellik alanları her zaman yardımcı olmaz.
Genel olarak, tüm özellikler değil eşit derecede önemlidir ve veri kümesindeki büyük bir varyans yüzdesini açıklayan belirli özellikler vardır. Boyut azaltma algoritmaları, özellik uzayının boyutunu, orijinal boyut sayısının bir kısmına indirmeyi amaçlar. Bunu yaparken, yüksek varyansa sahip özellikler korunur, ancak bunlar dönüştürülmüş özellik uzayındadır. Temel bileşen analizi (PCA), en popüler boyut azaltma algoritmalarından biridir.
Bu öğreticide, temel bileşen analizinin (PCA) nasıl çalıştığını ve scikit-learn kitaplığını kullanarak nasıl uygulanacağını öğreneceğiz.
Devam etmeden ve temel bileşen analizini (PCA) scikit-learn'de uygulamadan önce, PCA'nın nasıl çalıştığını anlamak faydalı olacaktır.
Bahsedildiği gibi, temel bileşen analizi bir boyut indirgeme algoritmasıdır. Yani, özellik uzayının boyutsallığını azaltır. Ancak bu azalmayı nasıl sağlıyor?
The motivation behind the algorithm is that there are certain features that capture a large percentage of variance in the original dataset. So it’s important to find the maksimum varyansın yönleri veri kümesinde. Bu yönlere denir Ana bileşenleri. Ve PCA, temel olarak veri kümesinin ana bileşenlere bir yansımasıdır.
Peki ana bileşenleri nasıl bulacağız?
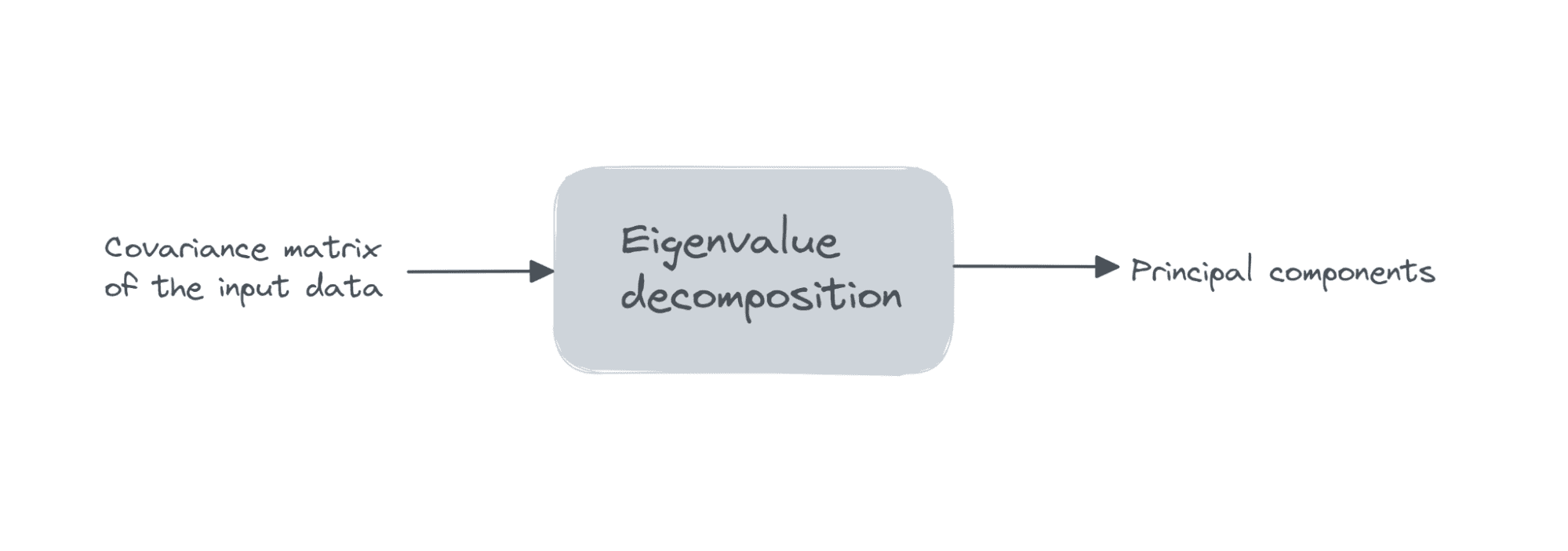
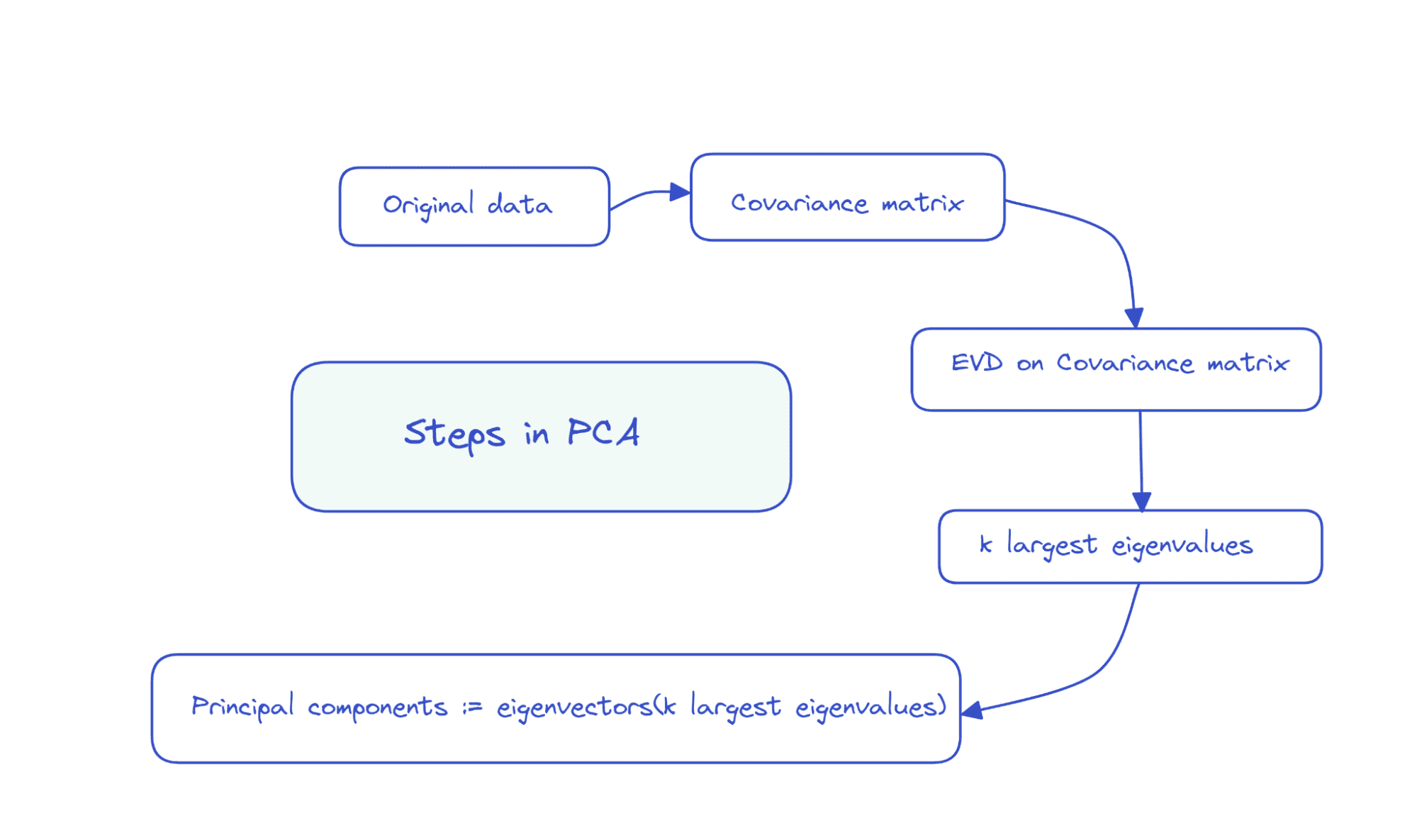
X veri matrisinin boyutlara sahip olduğunu varsayalım gözlem_sayısı x sayı_özellik sayısı, bız sunacağız özdeğer ayrıştırması üzerinde kovaryans matrisi X'in
Özelliklerin tümü sıfır ortalama ise, o zaman kovaryans matrisi XT X tarafından verilir. Burada XT, X matrisinin devrik değeridir. Başlangıçta özelliklerin tümü sıfır ortalama değilse, i sütununun ortalamasını her girişten çıkarabiliriz. bu sütunda ve kovaryans matrisini hesaplayın. Kovaryans matrisinin bir kare mertebe matrisi olduğunu görmek kolaydır. sayı_özellik.
Yazara göre resim
İlk k ana bileşen, özvektörler tekabül k en büyük özdeğerler.
Dolayısıyla, PCA'daki adımlar aşağıdaki gibi özetlenebilir:
Yazara göre resim
Kovaryans matrisi simetrik ve pozitif yarı-belirli olduğundan, özdekompozisyon aşağıdaki formu alır:
XT X = D Λ DT
D, özvektörlerin matrisidir ve Λ, özdeğerlerin köşegen matrisidir.
Temel bileşenleri hesaplamak için kullanılabilecek başka bir matris çarpanlara ayırma tekniği, tekil değer ayrıştırması veya SVD'dir.
Tüm matrisler için tekil değer ayrıştırması (SVD) tanımlanmıştır. Bir X matrisi verildiğinde, X'in SVD'si şunu verir: X = U Σ VT Burada, U, Σ ve V sırasıyla sol tekil vektörlerin, tekil değerlerin ve sağ tekil vektörlerin matrisleridir. VT, V'nin devrik değeridir.
Dolayısıyla, X'in kovaryans matrisinin SVD'si şu şekilde verilir:

İki matris ayrıştırmasının denkliğinin karşılaştırılması:

Aşağıdakilere sahibiz:
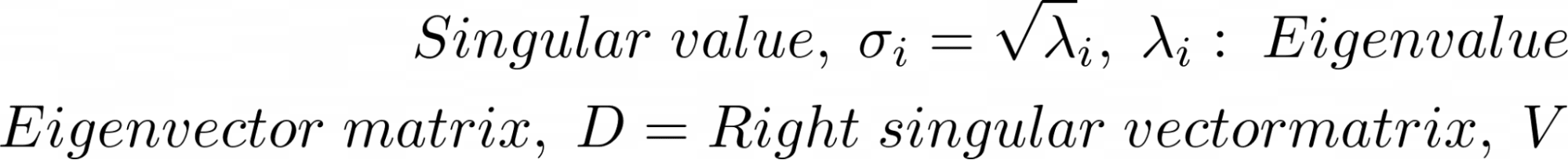
Bir matrisin SVD'sini hesaplamak için hesaplama açısından verimli algoritmalar vardır. PCA'nın scikit-learn uygulaması, ana bileşenleri hesaplamak için arka planda SVD'yi de kullanır.
Artık ana bileşen analizinin temellerini öğrendiğimize göre, bunun scikit-learn uygulamasına geçelim.
Adım 1 – Veri Kümesini Yükleyin
To understand how to implement principal component analysis, let’s use a simple dataset. In this tutorial, we’ll use the wine dataset available as part of scikit-learn’s veri kümeleri modülü.
Veri kümesini yükleyerek ve önişleyerek başlayalım:
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
Toplamda 13 özelliği ve 178 kaydı vardır.
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 alcohol 178 non-null float64 1 malic_acid 178 non-null float64 2 ash 178 non-null float64 3 alcalinity_of_ash 178 non-null float64 4 magnesium 178 non-null float64 5 total_phenols 178 non-null float64 6 flavanoids 178 non-null float64 7 nonflavanoid_phenols 178 non-null float64 8 proanthocyanins 178 non-null float64 9 color_intensity 178 non-null float64 10 hue 178 non-null float64 11 od280/od315_of_diluted_wines 178 non-null float64 12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
NoneAdım 2 – Veri Kümesini Ön İşleme Alın
As a next step, let’s preprocess the dataset. The features are all on different scales. To bring them all to a common scale, we’ll use the StandardScaler özellikleri sıfır ortalama ve birim varyansa dönüştüren:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)Adım 3 – Önceden İşlenmiş Veri Kümesinde PCA Gerçekleştirin
Temel bileşenleri bulmak için scikit-learn'deki PCA sınıfını kullanabiliriz. ayrışma modülü.
Ana bileşenlerin sayısını ileterek bir PCA nesnesini başlatalım n_components yapıcıya.
Temel bileşenlerin sayısı, özellik alanını azaltmak istediğiniz boyutların sayısıdır. Burada bileşen sayısını 3 olarak ayarladık.
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
aramak yerine fit_transform() yöntemini de arayabilirsiniz fit() takip eden transform() yöntemi.
Scikit-learn'ün PCA uygulamasını kullandığımızda, kovaryans matrisinin hesaplanması, kovaryans matrisinde temel bileşenleri elde etmek için öz ayrıştırma veya tekil değer ayrışımı gerçekleştirme gibi temel bileşen analizindeki adımların nasıl soyutlandığına dikkat edin.
Adım 4 – PCA Nesnesinin Bazı Yararlı Niteliklerini İnceleme
PCA örneği pca yarattığımız, arka planda neler olup bittiğini anlamamıza yardımcı olan birkaç faydalı özelliğe sahiptir.
Özellik components_ maksimum varyansın yönlerini saklar (temel bileşenler).
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085 0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741 0.28675223] [-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951 0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619 -0.36490283] [-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896 0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459 -0.12674592]]
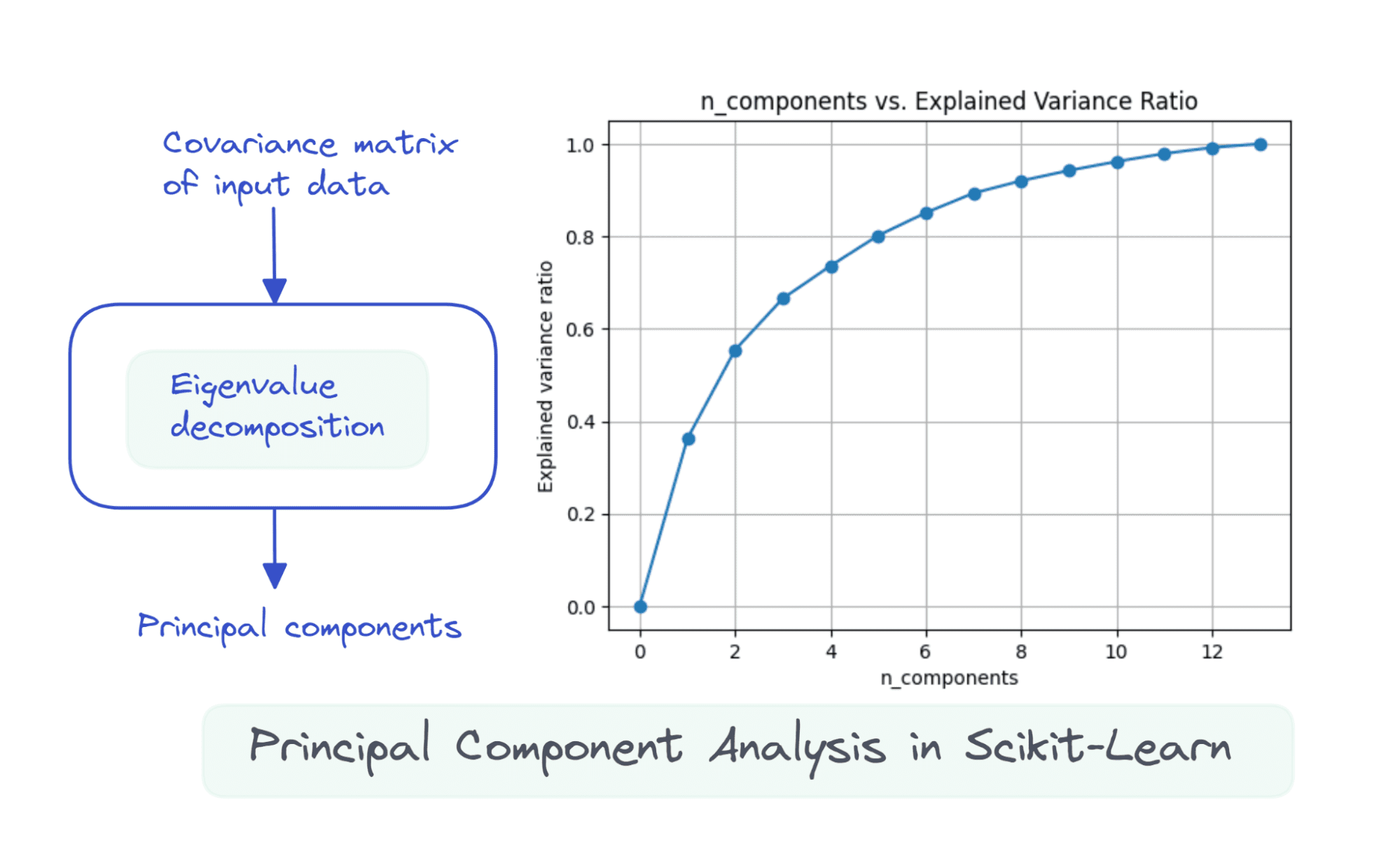
Temel bileşenlerin, veri kümesindeki maksimum varyansın yönleri olduğundan bahsetmiştik. ama nasıl ölçeceğiz toplam varyansın ne kadarı az önce seçtiğimiz temel bileşenlerin sayısında yakalanır mı?
The explained_variance_ratio_ öznitelik, her temel bileşenin yakaladığı toplam varyansın oranını yakalar. Böylece, seçilen bileşen sayısındaki toplam varyansı elde etmek için oranları toplayabiliriz.
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
Burada, üç ana bileşenin veri kümesindeki toplam varyansın %66.5'inden fazlasını yakaladığını görüyoruz.
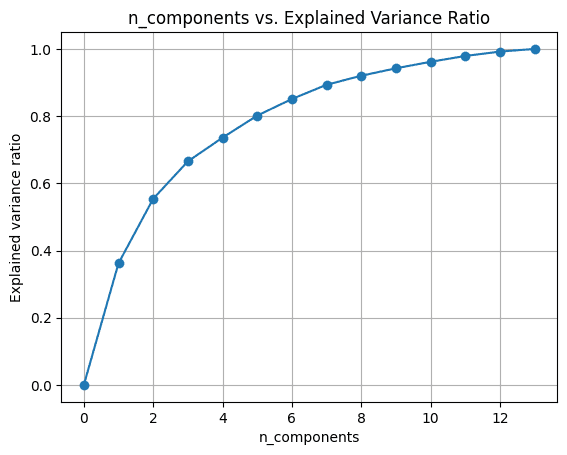
Adım 5 – Açıklanan Varyans Oranındaki Değişimin Analiz Edilmesi
Bileşen sayısını değiştirerek temel bileşen analizini çalıştırmayı deneyebiliriz. n_components.
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums: pca = PCA(n_components=num) pca.fit(scaled_df) var_ratio.append(np.sum(pca.explained_variance_ratio_))
görselleştirmek için explained_variance_ratio_ bileşen sayısı için, iki miktarı gösterildiği gibi çizelim:
import matplotlib.pyplot as plt plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
13 bileşenin hepsini kullandığımızda, explained_variance_ratio_ 1.0, veri kümesindeki varyansın %100'ünü yakaladığımızı gösterir.
In this example, we see that with 6 principal components, we’ll be able to capture more than 80% of variance in the input dataset.
Umarım scikit-learn kitaplığındaki yerleşik işlevselliği kullanarak ana bileşen analizini nasıl yapacağınızı öğrenmişsinizdir. Ardından, PCA'yı seçtiğiniz bir veri kümesine uygulamayı deneyebilirsiniz. Çalışmak için iyi veri kümeleri arıyorsanız, bu listeye göz atın. veri bilimi projeleriniz için veri kümeleri bulmak için web siteleri.
[1] Hesaplamalı Doğrusal Cebir, hızlı.ai
Bala Priya C Hindistan'dan bir geliştirici ve teknik yazardır. Matematik, programlama, veri bilimi ve içerik oluşturmanın kesiştiği noktada çalışmayı seviyor. İlgi ve uzmanlık alanları DevOps, veri bilimi ve doğal dil işlemeyi içerir. Okumaktan, yazmaktan, kodlama yapmaktan ve kahve içmekten hoşlanıyor! Şu anda öğreticiler, nasıl yapılır kılavuzları, fikir yazıları ve daha fazlasını yazarak öğrenmek ve bilgisini geliştirici topluluğuyla paylaşmak için çalışıyor.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoAiStream. Web3 Veri Zekası. Bilgi Genişletildi. Buradan Erişin.
- Adryenn Ashley ile Geleceği Basmak. Buradan Erişin.
- PREIPO® ile PRE-IPO Şirketlerinde Hisse Al ve Sat. Buradan Erişin.
- Kaynak: https://www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html?utm_source=rss&utm_medium=rss&utm_campaign=principal-component-analysis-pca-with-scikit-learn
- :vardır
- :dır-dir
- :olumsuzluk
- $UP
- 1
- 10
- 11
- 12
- 13
- 14
- 66
- 7
- 8
- 9
- a
- Yapabilmek
- Hesap
- Başarmak
- karşısında
- önde
- amaç
- Alkol
- algoritma
- algoritmalar
- Türkiye
- Ayrıca
- her zaman
- analiz
- analiz
- ve
- ARE
- alanlar
- AS
- At
- öznitelikleri
- yazma
- mevcut
- uzakta
- Temeller
- BE
- olmuştur
- arkasında
- getirmek
- yerleşik
- fakat
- by
- hesaplanması
- çağrı
- denilen
- çağrı
- CAN
- ele geçirmek
- yakalar
- belli
- değişiklik
- Kontrol
- seçim
- seçti
- seçilmiş
- sınıf
- kodlama
- Sütun
- Sütunlar
- nasıl
- ortak
- topluluk
- bileşen
- bileşenler
- hesaplamak
- bilgisayar
- içerik
- içerik yaratımı
- uyan
- çevrimiçi kurslar düzenliyorlar.
- oluşturma
- Şu anda
- veri
- veri bilimi
- veri kümeleri
- tanımlı
- Geliştirici
- DevOps
- farklı
- Boyut
- boyutlar
- yol tarifi
- do
- yok
- yapıyor
- her
- verimli
- giriş
- eşit olarak
- esasen
- incelenmesi
- örnek
- Uzmanlık
- açıkladı
- tanıdık
- HIZLI
- Özellikler(Hazırlık aşamasında)
- Özellikler
- bulmak
- Ad
- takip
- takip etme
- şu
- İçin
- Airdrop Formu
- kesir
- itibaren
- işlevsellik
- genel
- almak
- verilmiş
- verir
- Go
- gidiş
- Tercih Etmenizin
- Rehberler
- Var
- yardım et
- faydalı
- onu
- okuyun
- Yüksek
- başlık
- umut
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- i
- if
- uygulamak
- uygulama
- ithalat
- önemli
- in
- dahil
- Hindistan
- belirten
- başlangıçta
- giriş
- örnek
- faiz
- kavşak
- IT
- sadece
- KDNuggets
- bilgi
- dil
- büyük
- büyük
- ÖĞRENİN
- öğrendim
- öğrenme
- sol
- Kütüphane
- sevmek
- Liste
- ll
- yük
- yükleme
- bakıyor
- makine
- makine öğrenme
- matematik
- matplotlib
- Matris
- maksimum
- ortalama
- anlam
- ölçmek
- Bellek
- adı geçen
- yöntem
- modül
- Daha
- çoğu
- En popüler
- Motivasyon
- çok
- Doğal (Madenden)
- Doğal lisan
- Doğal Dil İşleme
- sonraki
- numara
- dizi
- nesne
- of
- on
- ONE
- Görüş
- or
- sipariş
- orijinal
- dışarı
- çıktı
- tekrar
- paradigma
- Bölüm
- Geçen
- yüzde
- yapmak
- icra
- parçalar
- Platon
- Plato Veri Zekası
- PlatoVeri
- Popüler
- pozitif
- Anapara
- işleme
- Programlama
- Projeksiyon
- oran
- Okuma
- kayıtlar
- azaltmak
- azaltır
- azalma
- sırasıyla
- krallar gibi yaşamaya
- koşu
- s
- aynı
- ölçek
- terazi
- Bilim
- scikit-öğrenme
- görmek
- set
- birkaç
- Shape
- paylaşımı
- o
- gösterilen
- Basit
- tekil
- So
- biraz
- uzay
- alanlarda
- kare
- başlama
- adım
- Basamaklar
- Yine
- mağaza
- böyle
- alır
- Teknik
- göre
- o
- The
- Temelleri
- Onları
- sonra
- Orada.
- Bunlar
- Re-Tweet
- üç
- için
- Toplam
- transforme
- denemek
- öğretici
- Öğreticiler
- iki
- tipik
- altında
- anlamak
- birim
- denetimsiz öğrenme
- us
- kullanım
- kullanım
- Kullanılmış
- kullanma
- değer
- Değerler
- vs
- we
- Ne
- Nedir
- ne zaman
- Vikipedi
- ŞARAP
- ile
- İş
- çalışma
- çalışır
- yazar
- yazı yazıyor
- X
- sen
- zefirnet
- sıfır



