Giriş
Sonraki kelimeyi belirlemek, dil modelleme olarak da bilinen sonraki kelime tahmininin görevidir. Biri NLP'ın kıyaslama görevleri dil modellemedir. En temel haliyle, bir dizi kelimeyi takip eden kelimeyi, meydana gelme olasılığı en yüksek olan kelimeye göre seçmeyi gerektirir. Birçok farklı alanda, dil modelleme çok çeşitli uygulamalara sahiptir.
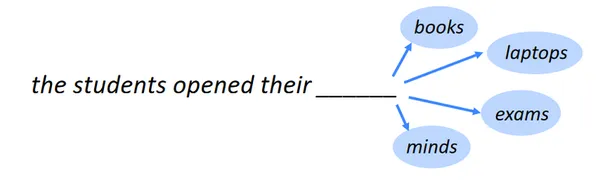
Öğrenme Hedefi
- İstatistiksel analiz, makine öğrenimi ve veri biliminde kullanılan çok sayıda modelin ardında yatan fikir ve ilkelerin farkına varın.
- Verilere dayalı kesin tahminler ve türler oluşturmak için regresyon, sınıflandırma, kümeleme vb. dahil tahmine dayalı modeller oluşturmayı öğrenin.
- Fazla uydurma ve yetersiz uydurma ilkelerini anlayın ve doğruluk, kesinlik, hatırlama vb. ölçümleri kullanarak model performansını nasıl değerlendireceğinizi öğrenin.
- Verileri nasıl önceden işleyeceğinizi ve modelleme için ilgili özellikleri nasıl belirleyeceğinizi öğrenin.
- Kılavuz arama ve çapraz doğrulamayı kullanarak hiperparametrelerde ince ayar yapmayı ve modelleri optimize etmeyi öğrenin.
Bu makale, Veri Bilimi Blogatonu.
İçindekiler
Dil Modelleme Uygulamaları
Dil modellemenin bazı dikkate değer uygulamaları şunlardır:
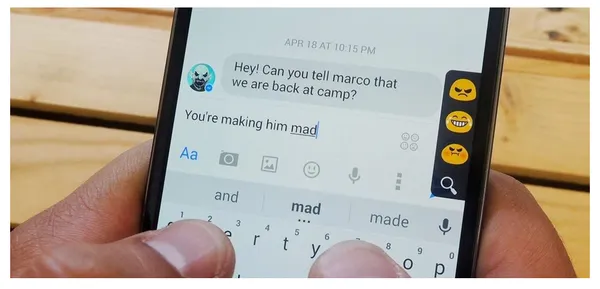
Mobil Klavye Metin Önerisi
Akıllı telefon klavyelerindeki mobil klavye metin önerisi veya akıllı metin veya otomatik öneriler adı verilen bir işlev, siz yazarken sözcükler veya tümceler önerir. Yazmayı daha hızlı ve daha az hataya açık hale getirmeyi ve daha kesin ve bağlamsal olarak uygun öneriler sunmayı amaçlar.
Ayrıca Oku: İçeriğe Dayalı Bir Öneri Sistemi Oluşturma
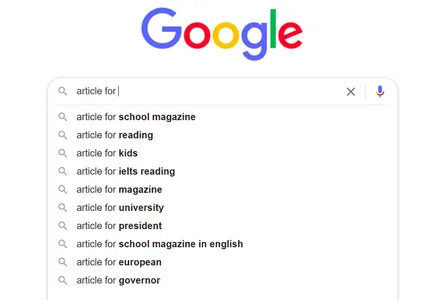
Google Arama Otomatik Tamamlama
Herhangi bir şey aramak için Google gibi bir arama motorunu her kullandığımızda, birçok fikir alıyoruz ve kelime öbekleri eklemeye devam ettikçe, öneriler daha iyi ve mevcut aramamızla daha alakalı hale geliyor. Peki nasıl olacak?
Doğal dil işleme (NLP) teknolojisi bunu mümkün kılar. Burada, cümlenin kalan sözcüklerini önceden söylemek için çift yönlü bir LSTM (Uzun kısa süreli bellek) modelini kullanan bir tahmin modeli oluşturmak için doğal dil işlemeyi (NLP) kullanacağız.
Daha Fazla Bilgi: LSTM nedir? Uzun Kısa Süreli Belleğe Giriş
Gerekli Kitaplıkları ve Paketleri İçe Aktarın
Çift yönlü bir LSTM kullanarak bir sonraki sözcük tahmin modeli oluşturmak için gerekli kitaplıkları ve paketleri içe aktarmak en iyisi olacaktır. Genel olarak ihtiyaç duyacağınız kitaplıkların bir örneği aşağıda gösterilmiştir:
import pandas as pd
import os
import numpy as np import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.models import Sequential
from tensorflow.keras.optimizers import AdamVeri Kümesi Bilgileri
Uğraştığınız veri kümesinin özelliklerini ve özniteliklerini anlamak bilgi gerektirir. Rastgele seçilen ve 2019'da yayınlanan aşağıdaki yedi yayının orta makalesi bu veri kümesine dahil edilmiştir:
- Veri Bilimine Doğru
- UX Kolektifi
- Başlangıç
- Yazma Kooperatifi
- Veri Odaklı Yatırımcı
- Daha İyi İnsanlar
- Daha İyi Pazarlama
Veri Kümesi Bağlantısı: https://www.kaggle.com/code/ysthehurricane/next-word-prediction-bi-lstm-tutorial-easy-way/input
medium_data = pd.read_csv('../input/medium-articles-dataset/medium_data.csv')
medium_data.head()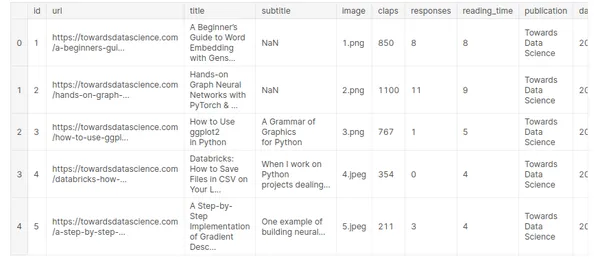
Burada on farklı alanımız ve 6508 kaydımız var ancak başlık alanını sadece bir sonraki kelimeyi tahmin etmek için kullanacağız.
print("Number of records: ", medium_data.shape[0])
print("Number of fields: ", medium_data.shape[1])
Veri kümesi bilgilerini inceleyerek ve anlayarak, bir sonraki kelime tahmini göreviniz için ön işleme prosedürlerini, modeli ve değerlendirme ölçütlerini seçebilirsiniz.
Çeşitli Makalelerin Başlıklarını Görüntüleyin ve Ön İşleme Alın
Makale başlıklarının hazırlanışını örneklendirmek için birkaç örnek başlığa göz atalım:
medium_data['title']
Başlıklardaki İstenmeyen Karakterleri ve Kelimeleri Kaldırma
Tahmin görevleri için metin verilerinin önceden işlenmesi bazen istenmeyen harflerin ve tümceciklerin başlıklardan çıkarılmasını içerir. İstenmeyen harfler ve sözcükler, verileri gürültüyle kirletebilir ve gereksiz karmaşıklık ekleyerek modelin performansını ve doğruluğunu azaltabilir.
- İstenmeyen Karakterler:
- Noktalama: Ünlem işaretlerini, soru işaretlerini, virgülleri ve diğer noktalama işaretlerini kaldırmalısınız. Genellikle tahmin atamasına yardımcı olmadıkları için bunları güvenle atabilirsiniz.
- Özel karakterler: Tahmin işi için gereksiz olan dolar işaretleri, @ sembolleri, hashtag'ler ve diğer özel karakterler gibi alfanümerik olmayan sembolleri kaldırın.
- HTML Etiketleri: Başlıklarda HTML işaretlemeleri veya etiketleri varsa, metni çıkarmak için uygun araçları veya kitaplıkları kullanarak bunları kaldırın.
- İstenmeyen Kelimeler:
- Durdurma Kelimeleri: "a", "an", "the", "is", "in" gibi sık kullanılan durdurma sözcüklerini ve önemli anlam veya tahmin gücü taşımayan diğer sık kullanılan sözcükleri kaldırın.
- Alakasız Kelimeler: Tahmin görevi veya etki alanıyla ilgili olmayan belirli kelimeleri tanımlayın ve kaldırın. Örneğin, film türlerini tahmin ediyorsanız, "film" veya "film" gibi kelimeler faydalı bilgiler sağlamayabilir.
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace(u'xa0',u' '))
medium_data['title'] = medium_data['title'].apply(lambda x: x.replace('u200a',' '))
dizgeciklere
dizgeciklere metni belirteçlere, sözcüklere, alt sözcüklere veya karakterlere böler ve ardından her simgeye benzersiz bir kimlik veya dizin atayarak bir sözcük dizini veya Kelime Dağarcığı oluşturur.
Belirteçleştirme işlemi aşağıdaki adımları içerir:
Metin ön işleme: Noktalama işaretlerini ortadan kaldırarak, küçük harfe çevirerek ve belirli bir göreve veya alana özgü gereksinimleri karşılayarak metni önceden işleyin.
dizgeciklere: Önceden işlenmiş metni, önceden belirlenmiş kurallar veya yöntemlerle ayrı belirteçlere bölme. Düzenli ifadeler, boşluklarla ayırma ve özel belirteçler kullanma, tüm yaygın belirteçleştirme teknikleridir.
Sözcük Dağarcığını Artırma Her simgeye benzersiz bir kimlik veya dizin atayarak sözcük dizini olarak da adlandırılan bir sözlük oluşturabilirsiniz. Bu süreçte her bir bilet ilgili indeks değerine eşlenir.
tokenizer = Tokenizer(oov_token='<oov>') # For those words which are not found in word_index
tokenizer.fit_on_texts(medium_data['title'])
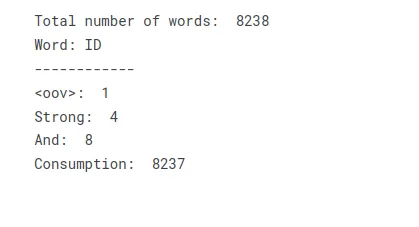
total_words = len(tokenizer.word_index) + 1 print("Total number of words: ", total_words)
print("Word: ID")
print("------------")
print("<oov>: ", tokenizer.word_index['<oov>'])
print("Strong: ", tokenizer.word_index['strong'])
print("And: ", tokenizer.word_index['and'])
print("Consumption: ", tokenizer.word_index['consumption'])Metni bir sözlüğe veya sözcük dizinine dönüştürerek, metni bir sayısal dizin koleksiyonu olarak temsil eden bir arama tablosu oluşturabilirsiniz. Metindeki her benzersiz kelime, sayısal girdi gerektiren daha fazla işleme veya modelleme işlemlerine izin veren karşılık gelen bir dizin değeri alır.
Başlıklar Metni Dizilere Dönüştürür ve N_gram Modeli Yapar.
Bu aşamalar, başlık dizilerine dayalı doğru tahmin için bir n-gram modeli oluşturmak için kullanılabilir:
- Başlıkları Dizilere Dönüştür: Her başlığı bir belirteç dizisine dönüştürmek için bir belirteç oluşturucu kullanın veya her bir fişi el ile onu oluşturan kelimelere ayırın. Sözlükteki her kelimeye ayrı bir sayı dizini atayın.
- n-gram oluştur: Dizilerden n-gramlar yapın. n-başlık belirteçlerinin sürekli akışına n-gram denir.
- Frekansı sayın: Veri kümesinde her n-gramın görünme sıklığını belirleyin.
- n-gram Modeli oluşturun: n-gram frekanslarını kullanarak n-gram modelini oluşturun. Model, önceki n-1 belirteçleri verilen her bir belirteç olasılığını takip eder. Bu, bir arama tablosu veya sözlük olarak görüntülenebilir.
- Sonraki Kelimeyi Tahmin Et: Bir n-1-belirteç dizisindeki beklenen bir sonraki belirteç, n-gram modeli kullanılarak tanımlanabilir. Bunu yapmak için, algoritmada olasılığı bulmak ve en yüksek olasılığa sahip bir jeton seçmek gerekir.
Daha Fazla Bilgi: N-gramlar Nedir ve Python'da Nasıl Uygulanır?
Bir sonraki kelimeyi veya belirteci tahmin etmek için başlıkların dizilerini kullanan bir n-gram modeli oluşturmak için bu aşamaları kullanabilirsiniz. Eğitim verilerine dayalı olarak, bu yöntem, başlıkların dil kullanımındaki istatistiksel ilişkileri ve eğilimleri yakaladığından doğru tahminler üretebilir.

input_sequences = []
for line in medium_data['title']: token_list = tokenizer.texts_to_sequences([line])[0] #print(token_list) for i in range(1, len(token_list)): n_gram_sequence = token_list[:i+1] input_sequences.append(n_gram_sequence) # print(input_sequences)
print("Total input sequences: ", len(input_sequences))
Dolgu Kullanarak Tüm Başlıkları Aynı Uzunlukta Yapın
Aşağıdaki adımları izleyerek her bir başlığın aynı boyutta olmasını sağlamak için dolgu kullanabilirsiniz:
- Diğer tüm başlıkları karşılaştırarak veri kümenizdeki en uzun başlığı bulun.
- Her birinin uzunluğunu genel sınırla karşılaştırarak her başlık için bu işlemi tekrarlayın.
- Bir başlık çok kısa olduğunda, belirli bir dolgu belirteci veya karakteri kullanılarak genişletilmelidir.
- Veri kümenizdeki her başlık için doldurma prosedürünü tekrar gerçekleştirin.
Dolgu, tüm başlıkların aynı uzunlukta olmasını sağlayacak ve post-processing veya model eğitimi için tutarlılık sağlayacaktır.
# pad sequences max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
input_sequences[1]
Özellikleri ve Etiketleri Hazırlayın
Verilen senaryoda, her girdi dizisinin son öğesini etiket olarak kabul edersek, başlıkların üzerinde tekil sözcüklerin toplam sayısına karşılık gelen vektörler olarak temsil etmek için tek geçişli kodlama gerçekleştirebiliriz.
# create features and label
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]
ys = tf.keras.utils.to_categorical(labels, num_classes=total_words) print(xs[5])
print(labels[5])
print(ys[5][14])
Çift Yönlü LSTM Sinir Ağı Mimarisi
Tekrarlayan sinir ağları (RNN'ler) Uzun Kısa Süreli Bellek (LSTM) ile kapsamlı diziler boyunca bilgi toplayabilir ve tutabilir. LSTM ağları, genellikle kaybolan gradyan sorunuyla mücadele eden ve uzun vadeli bağımlılığı sürdürmekte sorun yaşayan normal RNN'lerin kısıtlamalarının üstesinden gelmek için özel bellek hücreleri ve geçitleme teknikleri kullanır.
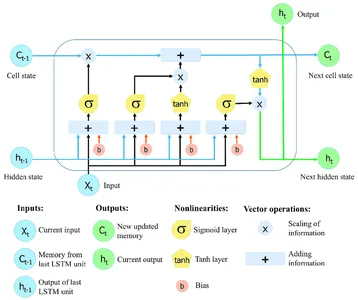
LSTM ağlarının kritik özelliği, zaman içinde bilgi depolayabilen bir bellek birimi görevi gören hücre durumudur. Hücre durumu üç ana kapı tarafından korunur ve kontrol edilir: unutma kapısı, giriş kapısı ve çıkış kapısı. Bu kapılar, LSTM hücresinin içine, dışına ve içine bilgi akışını düzenleyerek ağın seçici olarak farklı zaman adımlarında bilgileri hatırlamasına veya unutmasına izin verir.
Daha Fazla Bilgi: Uzun Kısa Süreli Bellek | LSTM Mimarisi
çift yönlü LSTM
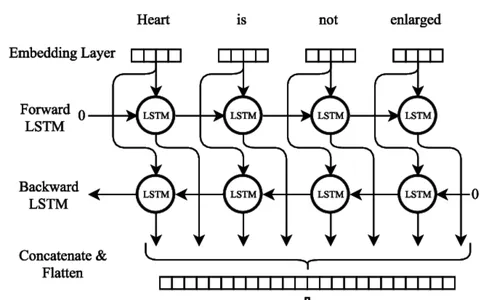
Bi-LSTM Yapay Sinir Ağı Modeli eğitimi
Çift yönlü bir LSTM (Bi-LSTM) sinir ağı modeli eğitilirken çok sayıda önemli prosedür izlenmelidir. İlk adım, bir sonraki kelimeyi gösteren, bunlara karşılık gelen giriş ve çıkış dizileriyle bir eğitim veri seti derlemektir. Metin verileri, ayrı satırlara bölünerek, noktalama işaretleri kaldırılarak ve büyük/küçük harf küçük harfe dönüştürülerek önceden işlenmelidir.
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
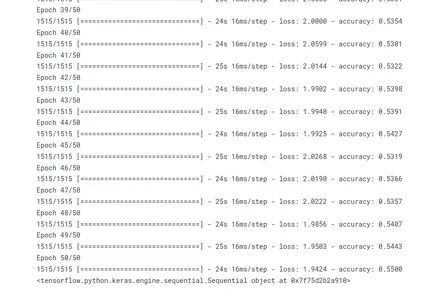
history = model.fit(xs, ys, epochs=50, verbose=1)
#print model.summary()
print(model)
fit() yöntemi çağrılarak model eğitilir. Eğitim verileri, giriş dizilerinden (xs) ve eşleşen çıkış dizilerinden (ys) oluşur. Model, tüm eğitim setinden geçerek 50 yinelemeden geçer. Eğitim sürecinde, eğitimin ilerleme durumu gösterilir (ayrıntılı=1).
Model Doğruluğunun ve Kaybının Çizilmesi
Eğitim boyunca bir modelin doğruluğunu ve kaybını çizmek, ne kadar iyi performans gösterdiği ve eğitimin nasıl gittiği hakkında içgörülü bilgiler sunar. Beklenen ve gerçek değerler arasındaki hata veya eşitsizliğe kayıp denir. Oysa model tarafından üretilen doğru tahminlerin yüzdesi doğruluk olarak bilinir.
import matplotlib.pyplot as plt def plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show() plot_graphs(history, 'accuracy')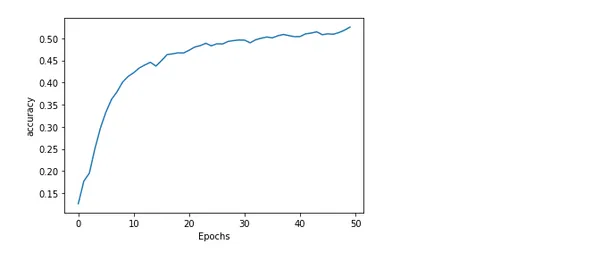
plot_graphs(history, 'loss')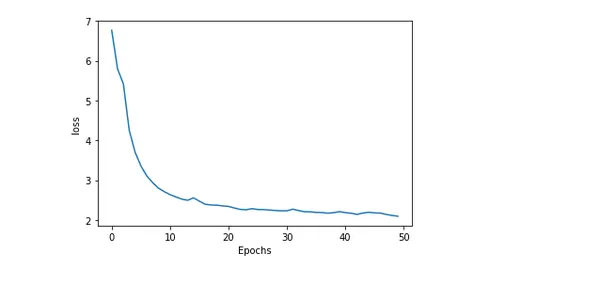
Başlığın Sonraki Kelimesini Tahmin Etme
Doğal dil işlemede büyüleyici bir zorluk, bir başlıktaki aşağıdaki kelimeyi tahmin etmektir. Modeller, metin verilerindeki kalıpları ve bağıntıları arayarak en olası konuşmayı önerebilir. Bu öngörü gücü, metin öneri sistemleri ve otomatik tamamlama gibi uygulamaları mümkün kılar. RNN'ler ve trafo tabanlı mimariler gibi gelişmiş yaklaşımlar doğruluğu artırır ve bağlamsal ilişkileri yakalar.
seed_text = "implementation of"
next_words = 2 for _ in range(next_words): token_list = tokenizer.texts_to_sequences([seed_text])[0] token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre') predicted = model.predict_classes(token_list, verbose=0) output_word = "" for word, index in tokenizer.word_index.items(): if index == predicted: output_word = word break seed_text += " " + output_word
print(seed_text)
Sonuç
Sonuç olarak, bir kelime dizisindeki sonraki kelimeyi tahmin edecek bir model eğitmek, Çift Yönlü LSTM kullanarak sonraki kelime tahmini olarak bilinen heyecan verici doğal dil işleme zorluğudur. İşte madde işaretleriyle özetlenen sonuç:
- Sıralı veri işleme için güçlü derin öğrenme mimarisi BI-LSTM, uzun vadeli ilişkileri ve tümce bağlamını yakalayabilir.
- BI-LSTM eğitimi için ham metin verileri hazırlamak için veri hazırlama esastır. Bu, tokenizasyon, sözcük dağarcığı oluşturma ve metin vektörleştirmeyi içerir.
- Bir kayıp işlevi oluşturmak, bir optimize edici kullanarak modeli oluşturmak, onu önceden işlenmiş verilere uydurmak ve doğrulama kümelerindeki performansını değerlendirmek, BI-LSTM modelinin eğitimindeki adımlardır.
- BI-LSTM sonraki kelime tahmini, ustalaşmak için teorik bilgi ve uygulamalı deney kombinasyonunu gerektirir.
- Otomatik tamamlama, dil oluşturma ve metin önerme algoritmaları, sonraki sözcük tahmin modeli uygulamalarının örnekleridir.
Bir sonraki kelime tahmini için uygulamalar arasında sohbet robotları, makine çevirisi ve metin tamamlama yer alır. Daha fazla araştırma ve iyileştirme ile daha kesin ve bağlama duyarlı sonraki kelime tahmin modelleri oluşturabilirsiniz.
Sıkça Sorulan Sorular
A. Sonraki kelime tahmini, bir modelin belirli bir kelime dizisini veya bağlamı takip etmesi en muhtemel kelimeyi tahmin ettiği bir NLP görevidir. Eğitim verilerinden öğrenilen kalıplara ve ilişkilere dayalı olarak bir sonraki kelime için tutarlı ve bağlamsal olarak ilgili öneriler üretmeyi amaçlar.
A. Sonraki kelime tahmini, genellikle Tekrarlayan Sinir Ağlarını (RNN'ler) ve bunların Uzun Kısa Süreli Bellek (LSTM) ve Geçitli Tekrarlayan Birim (GRU) gibi türevlerini kullanır. Ek olarak, GPT (Generative Pre-trained Transformer) modelleri gibi Transformer tabanlı mimariler gibi modeller de bu görevde önemli ilerlemeler göstermiştir.
A. Tipik olarak, bir sonraki sözcük tahmini için eğitim verilerini hazırlarken, metni sözcük dizilerine böler ve girdi-çıktı çiftleri oluşturursunuz. Karşılık gelen çıktı, her giriş dizisi için metinde aşağıdaki sözcüğü temsil eder. Metnin ön işlenmesi, noktalama işaretlerinin kaldırılmasını, sözcüklerin küçük harfe dönüştürülmesini ve metnin tek tek sözcüklere dönüştürülmesini içerir.
A. Şaşkınlık, doğruluk veya en yüksek doğruluk gibi değerlendirme metriklerini kullanarak bir sonraki kelime tahmin modelinin performansını değerlendirebilirsiniz. Şaşkınlık, modelin bağlam göz önüne alındığında bir sonraki kelimeyi ne kadar iyi tahmin ettiğini ölçer. Doğruluk ölçümleri, tahmin edilen kelimeyi temel gerçekle karşılaştırırken, en yüksek doğruluk, modelin tahminini en olası en yüksek k yorum içinde dikkate alır.
Bu makalede gösterilen medya Analytics Vidhya'ya ait değildir ve Yazarın takdirine bağlı olarak kullanılır.
İlgili bağlantılar
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. Otomotiv / EV'ler, karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- Blok Ofsetleri. Çevre Dengeleme Sahipliğini Modernleştirme. Buradan Erişin.
- Kaynak: https://www.analyticsvidhya.com/blog/2023/07/next-word-prediction-with-bidirectional-lstm/
- :vardır
- :dır-dir
- :olumsuzluk
- :Neresi
- 1
- 100
- 13
- 14
- 20
- 2019
- 50
- 9
- a
- Hakkımızda
- doğruluk
- doğru
- karşısında
- gerçek
- Adem
- eklemek
- ekleme
- Ayrıca
- gelişmeler
- tekrar
- Amaçları
- algoritma
- algoritmalar
- Türkiye
- Izin
- Ayrıca
- an
- analiz
- analytics
- Analitik Vidhya
- ve
- beklenen
- herhangi
- bir şey
- uygulamaları
- yaklaşımlar
- uygun
- mimari
- ARE
- göre
- mal
- AS
- Değerlendirme
- At
- öznitelikleri
- Otomatik tamamlama
- merkezli
- temel
- BE
- Çünkü
- arkasında
- olmak
- altında
- kıyaslama
- İYİ
- Daha iyi
- arasında
- blogathon
- mola
- inşa etmek
- bina
- fakat
- by
- denilen
- çağrı
- CAN
- ele geçirmek
- yakalar
- hangi
- taşımak
- dava
- hücre
- Hücreler
- meydan okuma
- değiştirme
- karakter
- özellikleri
- karakterler
- chatbots
- Klinik
- sınıflandırma
- kümeleme
- tutarlı
- toplamak
- Toplamak
- kombinasyon
- yorumlar
- ortak
- çoğunlukla
- karşılaştırmak
- karşılaştırarak
- tamamlama
- karmaşıklık
- kapsamlı
- sonuç
- Düşünmek
- dikkate
- oluşur
- kurucu
- kısıtlamaları
- kurmak
- tüketim
- bağlam
- bağlamsal
- sürekli
- kontrollü
- dönüştürme
- uyan
- yaratmak
- Oluşturma
- oluşturma
- kritik
- çok önemli
- akım
- veri
- Veri Hazırlama
- veri işleme
- veri bilimi
- ilgili
- derin
- derin öğrenme
- yoğun
- bağımlılık
- Belirlemek
- farklı
- takdir
- ekran
- görüntülenen
- farklı
- bölünmüş
- böler
- do
- Dolar
- domain
- Dont
- tahrik
- sırasında
- her
- eleman
- ortadan
- katıştırma
- Motor
- sağlamak
- devirler
- gerekli
- vb
- Eter (ETH)
- değerlendirmek
- değerlendirilir
- değerlendirme
- örnek
- örnekler
- heyecan verici
- beklenen
- ifade
- kapsamlı, geniş
- çıkarmak
- büyüleyici
- Daha hızlı
- mümkün
- Özellikler(Hazırlık aşamasında)
- Özellikler
- az
- alan
- Alanlar
- bulmak
- Ad
- uydurma
- akış
- takip et
- takip
- takip etme
- şu
- İçin
- Airdrop Formu
- bulundu
- Sıklık
- sık sık
- itibaren
- işlev
- daha fazla
- geçitli
- Gates,
- genellikle
- oluşturmak
- oluşturulan
- nesil
- üretken
- türler
- verilmiş
- gidiş
- Google Arama
- En büyük
- Grid
- Zemin
- Büyümek
- rehberlik
- hands-on
- olmak
- Var
- yardım et
- faydalı
- okuyun
- tarih
- ambar
- Ne kadar
- Nasıl Yapılır
- HTML
- HTTPS
- i
- ID
- fikirler
- tespit
- belirlemek
- if
- uygulamak
- uygulama
- ithalat
- iyileşme
- in
- dahil
- dahil
- içerir
- Dahil olmak üzere
- Artırmak
- indeks
- indeksler
- belirten
- bireysel
- bilgi
- giriş
- anlayışlı
- içine
- Giriş
- IT
- yineleme
- ONUN
- İş
- tutmak
- keras
- bilgi
- bilinen
- etiket
- Etiketler
- dil
- Soyad
- katmanları
- ÖĞRENİN
- öğrendim
- öğrenme
- uzunluk
- az
- kütüphaneler
- sevmek
- olasılık
- Muhtemelen
- LİMİT
- çizgi
- hatları
- LINK
- Uzun
- uzun süreli
- Bakın
- bakıyor
- arama
- kayıp
- düşürücü
- makine
- makine öğrenme
- makine çevirisi
- Ana
- sürdürmek
- yapmak
- YAPAR
- el ile
- çok
- usta
- Mastering
- uygun
- matplotlib
- Mayıs..
- anlam
- önlemler
- medya
- orta
- Bellek
- yöntem
- yöntemleri
- Metrikleri
- olabilir
- hata
- Telefon
- model
- Modelleme
- modelleri
- Daha
- çoğu
- film
- şart
- Doğal (Madenden)
- Doğal lisan
- Doğal Dil İşleme
- gerekli
- Gereksiz
- ihtiyaçlar
- ağ
- ağlar
- sinirsel
- sinir ağı
- nöral ağlar
- sonraki
- nlp
- Gürültü
- dikkate değer
- numara
- sayısız
- dizi
- meydana
- meydana gelen
- of
- teklif
- Teklifler
- on
- ONE
- bir tek
- Operasyon
- optimize
- or
- OS
- Diğer
- bizim
- dışarı
- çıktı
- tekrar
- tüm
- Üstesinden gelmek
- Sahip olunan
- paketler
- ped
- çiftleri
- pandalar
- Bölüm
- belirli
- desen
- yüzde
- yapmak
- performans
- gerçekleştirir
- ifadeler
- Platon
- Plato Veri Zekası
- PlatoVeri
- noktaları
- mümkün
- rötuş
- güç kelimesini seçerim
- önceden
- gerek
- Hassas
- tahmin
- tahmin
- tahmin
- tahmin
- Tahminler
- öngörür
- hazırlık
- Hazırlamak
- hazırlanmış
- hazırlanması
- önceki
- ilkeler
- olasılık
- Sorun
- prosedür
- prosedürler
- gelir
- süreç
- işleme
- üretmek
- Ilerleme
- uygun
- önermek
- korumalı
- sağlamak
- yayınlar
- yayınlanan
- Python
- soru
- rasgele
- Çiğ
- Okumak
- teslim almak
- alır
- Tavsiye
- tavsiyeler
- kayıtlar
- gerileme
- düzenli
- düzenlemek
- İlişkiler
- uygun
- kalan
- hatırlamak
- Kaldır
- kaldırma
- temsil etmek
- temsil
- temsil
- gerektirir
- gerektirir
- araştırma
- kurallar
- koşmak
- güvenli bir şekilde
- aynı
- senaryo
- Bilim
- Ara
- arama motoru
- Arıyor
- seçilmiş
- ayrı
- ayırma
- Dizi
- vermektedir
- set
- Setleri
- Yedi
- kısa
- kısa dönem
- meli
- gösterilen
- önemli
- İşaretler
- beri
- beden
- akıllı telefon
- biraz
- sofistike
- özel
- özel
- özel
- bölmek
- aşamaları
- Eyalet
- istatistiksel
- adım
- Basamaklar
- dur
- mağaza
- dizi
- güçlü
- Çabalama
- sonraki
- böyle
- Önerdi
- Sistemler
- tablo
- alır
- alma
- Konuşmak
- Görev
- görevleri
- teknikleri
- Teknoloji
- on
- tensorflow
- dönem
- o
- The
- ve bazı Asya
- Onları
- sonra
- teorik
- böylece
- Bunlar
- onlar
- Re-Tweet
- Bu
- üç
- İçinden
- boyunca
- bilet
- zaman
- Başlık
- başlıkları
- için
- simge
- dizgeciklere
- tokenizing
- Jeton
- çok
- araçlar
- Toplam
- iz
- eğitilmiş
- Eğitim
- transformatör
- dönüşüm
- Çeviri
- Trendler
- sorun
- Hakikat
- DÖNÜŞ
- türleri
- tipik
- altında yatan
- benzersiz
- birim
- istenmeyen
- kullanım
- kullanım
- Kullanılmış
- kullanım
- kullanma
- genellikle
- kullanır
- Kullanılması
- onaylama
- değer
- Değerler
- çeşitlilik
- çeşitli
- oldu
- we
- webp
- İYİ
- Ne
- Nedir
- ne zaman
- oysa
- hangi
- süre
- bütün
- geniş
- irade
- ile
- içinde
- Word
- sözler
- olur
- yazmak
- yazı yazıyor
- X
- sen
- zefirnet