Optik Karakter Tanıma (OCR), el yazısı/basılı metinleri makine ile kodlanmış metne dönüştürme yöntemi, çeşitli alanlardaki sayısız uygulamaları nedeniyle bilgisayarla görü alanında her zaman önemli bir araştırma alanı olmuştur — Bankalar ifadeleri karşılaştırmak için OCR kullanır; Hükümetler, anket geri bildirim toplamaları için OCR kullanır.

El yazısı ve basılı metin stillerindeki çeşitlilik nedeniyle, OCR'nin son yaklaşımları daha yüksek bir doğruluk elde etmek için derin öğrenmeleri içerir. Derin öğrenme, model eğitimi için çok miktarda veri gerektirdiğinden, Google gibi şirketler, OCR hizmetleriyle gelecek vaat eden sonuçlar üretme konusunda avantaj elde ediyor.
Bu makale, python'da basit bir eğitim, uygulama yelpazesi, fiyatlandırma ve diğer alternatifler dahil olmak üzere Google Vision OCR'nin ayrıntılarına dalmaktadır.
- Google Cloud Vision OCR nedir?
- Basit Bir Öğretici
- Neden OCR?
- Örnek Kullanım Durumları
- Fiyatlandırma
- Google Cloud Vision OCR'nin Öne Çıkan Özellikleri
- alternatifler
- Ortak sorunlar
Google Bulut Vizyonu nedir?

Google Cloud Vision OCR, görüntülerden metin çıkarmak için Google bulut vizyonu API'sinin bir parçasıdır. Özellikle, karakter tanımaya yardımcı olacak iki ek açıklama vardır:
- Metin_Ek Açıklama: Herhangi bir görüntüden (örneğin, sokak görünümlerinin veya manzaraların fotoğrafları) makine tarafından kodlanmış metinleri çıkarır ve çıkarır. Başlangıçta farklı aydınlatma koşullarında kullanılabilecek şekilde tasarlandığından, model bir anlamda farklı tarzlardaki sözcükleri okumada daha sağlam, ancak yalnızca daha seyrek bir düzeyde. Döndürülen JSON dosyası, tüm dizelerin yanı sıra tek tek sözcükleri ve bunlara karşılık gelen sınırlayıcı kutuları içerir.
- Document_Text_Açıklama: Bu, özellikle yoğun olarak sunulan metin belgeleri (örneğin, taranmış kitaplar) için tasarlanmıştır. Böylece, daha küçük ve daha yoğun metinlerin okunmasını desteklerken, vahşi görüntülere daha az uyarlanabilir. Paragraflar, bloklar ve aralar gibi bilgiler çıktı JSON dosyasına dahil edilir.
Google Cloud Vision'ın eksikliklerinin üstesinden gelen bir OCR çözümü arıyorsunuz veya bölgesel OCR? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik ve daha geniş belge türleri için bir dönüş!
Basit Bir Öğretici
Aşağıdaki bölüm, özellikle Google Cloud Vision OCR hizmeti için nasıl kullanılacağına ilişkin Google Vision API'yi kullanmaya başlama konusunda basit bir eğitim sunar.
Basit Genel Bakış
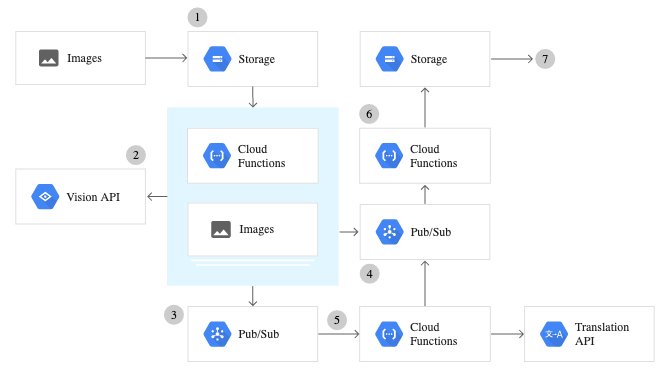
Bunun arkasındaki fikir çok sezgisel ve basittir.
1) Esasen Google Cloud Vision API'ye bir görüntü (uzaktaki veya yerel depolama alanınızdan) gönderirsiniz.
2) Görüntü, Google Cloud'da uzaktan işlenir ve aradığınız işleve göre ilgili JSON biçimlerini üretir.
3) JSON dosyası, işlev çağrıldıktan sonra çıktı olarak döndürülür.
Google Cloud Vision API'yi kurma
Google Vision API tarafından sağlanan herhangi bir hizmeti kullanmak için Google Cloud Console'u yapılandırmalı ve kimlik doğrulama için bir dizi adım gerçekleştirmelisiniz. Aşağıda, Vision API hizmetinin tamamının nasıl kurulacağına ilişkin adım adım bir genel bakış yer almaktadır.
- Google Cloud Console'da Proje Oluşturun - Herhangi bir Vision hizmetini kullanmaya başlamak için bir proje oluşturulmalıdır. Proje, ortak çalışanlar, API'ler ve fiyatlandırma bilgileri gibi kaynakları düzenler.
- Faturalandırmayı Etkinleştir — Vision API'yi etkinleştirmek için önce projeniz için faturalandırmayı etkinleştirmelisiniz. Fiyatlandırmanın ayrıntıları sonraki bölümlerde ele alınacaktır.
- Vision API'yi Etkinleştir
- Hizmet Hesabı Oluştur — Bir hizmet hesabı oluşturun ve oluşturulan projeye bağlantı verin, ardından bir hizmet hesabı anahtarı oluşturun. Anahtar çıktısı alınacak ve bilgisayarınıza bir JSON dosyası olarak indirilecektir.
- Ortam Değişkenini Ayarlayın GOOGLE_APPLICATION_CREDENTIALS; Bu ortam değişkenini ayarlamak için bunu Mac/Linux veya Windows'ta çalıştırın.
- Mac/Linux için kod blokları
- Windows için kod blokları
Yukarıda belirtilen adımların daha ayrıntılı bir prosedürü, buradan Google Cloud tarafından verilen resmi belgelerde bulunabilir:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Python'da Basit Google Vision OCR İşlevi
Google Cloud Vision API, Java, Node.js, Python'dan Google'ın kendi dili olan Go'ya kadar çok sayıda popüler dille çalışır. Basit olması için Python'da basit bir çağırma yöntemi sunuyoruz.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Başka bir deyişle, yöntem sonuç olarak işlevi çağırır. metin_annotation, ardından yanıtları daha fazla çıkarın ve bilgileri yazdırın. Document_text_annotation yoğun metinleri almak için aynı şekilde çağrılabilir. Görüntüyü şu şekilde ayarlayarak da görüntüleri uzaktan algılayabilirsiniz:
image.source.image_uri = uriburada uri görüntünün uri'sidir.
Kodların daha fazla detayına buradan ulaşılabilir:
https://cloud.google.com/vision
Google Cloud Vision'ın eksikliklerinin üstesinden gelen bir OCR çözümü mü arıyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik ve daha geniş belge türleri için bir dönüş!
Sunulan Çıktı Seviyesi
Metnin daha fazla veri analizine yardımcı olmak için, iki Google OCR işlevi, kullanıcıların kullanması için çeşitli düzeylerde çıktılar sağlar: metin_annotation, hem dizelerin tamamı (Google tarafından tek bir cümle veya tümcecik olarak kabul edilirse) hem de içindeki tek tek kelimeler; için Document_text_annotation, model yoğun metin için optimize edildiğinden, sayfa, blok, paragraf, sözcük ve aranın tümü çıktının bir parçası olarak sunulur.
Yine de ne kadar iyi çalışıyor?
Modeller ne kadar sağlam?
Daha önce de belirtildiği gibi Google, iki farklı durumda OCR için iki işlev sunar. Aşağıda, iki işlevin farklı veri türlerini alma kapasitesi açıklanmaktadır.
Basılı Veriler
Yorumlanması en kolay veri türü, basılı metin verileridir, yani, yazdırılan ve taranan bilgisayarla yazılmış metin. OCR, orijinal makine kodlu metinler yerine bu verilerin yalnızca basılı kopyasına sahip olduğumuzda gereklidir. Bu metinlerin çoğu sıkı ve sayfalar dolusu olduğundan, Document_text_annotation daha iyi bir seçenek olurdu.
El Yazısı Veriler
İçerik, elle yazılmış metinler içerebilir ve elle yazılmış verilerin stilleri büyük ölçüde değişebilir. Bununla birlikte, Google Vision OCR, el yazısı notlar çok dağınık olmadığı sürece iyi bir doğruluk sağlar. El yazısı verilerin ortamının ne kadar paketlendiğine bağlı olarak, duruma göre iki işlevden birini kullanırız.
Döndürülmüş/Vahşi Veriler
Görüntüler veya taranan fotoğraflar alışılmışın dışında veya hizalanmamış açılarda sunulduğunda, bunları vahşi veriler olarak kabul ederiz. Metinlerin ilk etapta algılanması potansiyel olarak daha zor olabilir ve bu nedenle genellikle metin_annotation ilk etapta vahşi verileri işlemek için tasarlanmış işlev. Farklı açılardan yakalanmış dikey metinler ve yol işaretlerinden geçme deneylerine dayanarak, Google Vision OCR'nin çeşitli ortamlardan alınan veriler üzerinde gerçekten iyi performans gösterdiğini gösteriyoruz.
Neden OCR?
Bugün sahip olduğumuz verilerin çoğu yapılandırılmamış biçimdedir. Örneğin, bir görüntü, taranmış bir belge veya bir fotoğraf verildiğinde, insanlar metinleri çabucak tanıyabilir ve anlamları daha fazla yorumlayabilirken, tüm metin verileri yalnızca renkli piksellerdir ve makinelere gerçek bir anlam sağlamaz.

Şirketler veya büyük şirketler büyük miktarda evrak işiyle uğraşırken, büyük veri hacmi, herhangi bir sınıflandırmanın veya veri işlemenin yalnızca insan çabasıyla yapılmasını imkansız hale getirecektir - bu, makine kodlu metinlerin kullanışlı hale geldiği zamandır.
OCR dönüşümünden sonra, verinin doğasına bağlı olarak bilgiler birden fazla farklı yöntemle analiz edilebilir:
- Sayısal veriler için, herhangi bir korelasyonu analiz etmek için istatistiksel yöntemler doğrudan uygulanabilir. Regresyon ve/veya sınıflandırma için tahmine dayalı modeller oluşturmak için geleneksel makine öğrenimi yöntemlerini (örneğin, KNN, K-Means, Linear Regresyon) veya derin öğrenme yaklaşımlarını da benimseyebiliriz.
- Metin verileri için daha fazla işleme aşaması gerekebilir. Metin verilerini analiz etme ve anlamlı istatistiklere dönüştürme sürecine genellikle doğal dil işleme (NLP) denir. Spesifik olarak, verilen içeriğe dayalı olarak sayıları ve hatta semantikleri/atmosferi çıkarabiliriz.
Tüm bu analizler, şirketlerin, özellikle de her gün büyük miktarda yeni veriye sahip olanların, sağlam modeller oluşturmasına ve hatta birçok süreci otomatikleştirmesine ve geleneksel emek yoğun ve hata dolu yaklaşımların yerini almasına izin verebilir. Aşağıdaki bölüm, OCR'nin nasıl kullanılabileceğine ilişkin bazı ayrıntılı örnekleri inceler.
Google Cloud Vision'ın eksikliklerinin üstesinden gelen bir OCR çözümü mü arıyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik ve daha geniş belge türleri için bir dönüş!
Örnek Kullanım Durumları
Plaka Okuma

OCR'nin günümüzde belki de en yaygın kullanımlarından biri plaka okuma uygulamasıdır. Gelişmiş ülkelerde, giriş zamanını, çıkış zamanını ve hatta araba başına tam park yerini belirlemek için park yerlerine genellikle plaka okuma modelleri eşlik eder. Hatta bazı otoparklar, park ücretlerini doğrudan ailelerden tahsil etmek için hükümet ağına bile bağlıdır - bunların tümü, gereksiz insan çabalarını hafifletir.
Plaka OCR modelleri, trafik ihlallerinde tespitler için de kullanılabilir ve polisin ihlalde bulunan aracın verilerini manuel olarak girme süresini kolaylaştırır.
Fiş ve Fatura Tarama

Finansal projeksiyonlar ve şirketlerin varlık ve yükümlülüklerinin dengelenmesi her firma için önemli faaliyetlerdir. Büyük şirketler yıl boyunca birden fazla sektörden büyük miktarlarda alımlar yaptıklarından, mali tabloları oluştururken tüm faturaları ve makbuzları titizlikle toplamaları ve işlemeleri gerekmektedir.
OCR yardımıyla, otomatikleştirilmiş ardışık düzenleri oluşturabiliriz. bir dizi fatura biçimini tanıyın ve bunları sayılara dönüştürün. Emek çabaları yalnızca kontrol için gereklidir ve yapılandırılmış veriler ve sayılar, şirketin giriş ve çıkışları hızlı bir şekilde dengelemesine, finansal tahminler oluşturmasına ve ayrıca şirketin mali durumu üzerinde herhangi bir kötü niyetli manipülasyona karşı dikkatli olmasına olanak sağlayabilir.
Elektrik Tıbbi Kayıtları

Hastaların verileri genellikle bireylerin yaşam tarzlarına bağlı olarak bir bölge, ülke ve hatta ülkeler arasında dağılmıştır. Kliniklerin ve hastanelerin farklı tarzları nedeniyle (büyük hastaneler veri tabanlarını organize etmiş olabilirken, daha küçük kliniklerdeki doktorlar kayıtları sadece elle yazabilir), hastaların yaşı (yaşlı hastalar, yenileme ve birleşmeden önce belirli bir veri tabanına eklenebilir). bilgisayarlar) ve bireylerin konumları (insanlar farklı bir şehre, hatta yurt dışına taşınabilirler), evrensel bir tıbbi bakım yapmak aslında çok zor olabilir.
Bu nedenle, iyi eğitimli bir OCR, EMR'yi bir hastaneden diğerine aktarırken veya elle yazılmış verileri makine metnine dönüştürürken kullanışlı olur - her ikisi de hastaların tıbbi geçmişini hızlı ve özlü bir şekilde anlama sürecini hızlandırabilir.
Formlar ve Anketler

Kuruluşlar (ister resmi ister resmi olmayan) mevcut promosyon planlarını ve ürünlerini geliştirmek için genellikle müşterilerden veya vatandaşlardan geri bildirim isteyebilir. Formlar genellikle elle yazıldığından, herhangi bir doğrudan istatistiksel analiz yapmak potansiyel olarak zor olacaktır. Bu nedenle, hesaplamaları kolaylaştırmak için yapılandırılmamış verilerin ve el yazısı anketlerin sayısal rakamlara dönüştürülmesi süreci OCR tarafından desteklenebilir ve hızlandırılabilir.
Google Cloud Vision'ın eksikliklerinin üstesinden gelen bir OCR çözümü mü arıyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik ve daha geniş belge türleri için bir dönüş!
Bulut Görüşü Fiyatlandırması
Google'a göre Web sitesi, her ikisi de metin_annotation ve Document_text_annotation aşağıdakilerle aynı fiyat seviyesinde sunulmaktadır:
Her ay için, ilk 1000 birim ücretsiz olarak verilir ve 1000-5000000, 1.5 birim başına 1000 ABD Doları olarak ücretlendirilir. 5000000 işaretine ulaştıktan sonra, fiyat 0.6 birim başına 1000 ABD Dolarına düşer (Google Vision API aracılığıyla gönderilen her görüntü bir birim olarak kabul edilir).
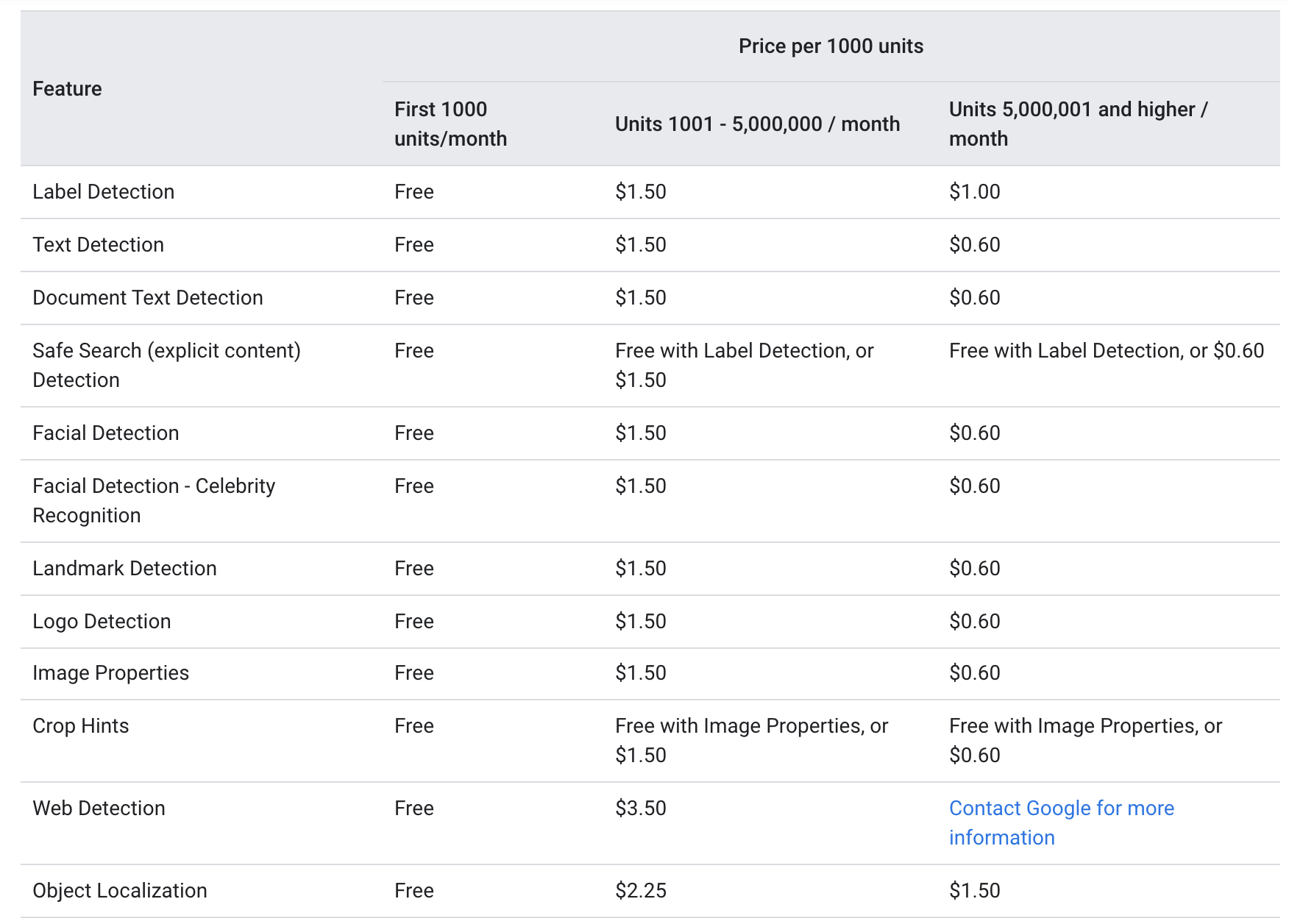
Yukarıdaki fiyatlandırma, OCR hizmetinin hem daha az sıklıkta kullanılan küçük şirketler hem de hizmetin ayda 5000000'den çok daha fazla gerekli olduğu büyük şirketler için nispeten uygun olduğunu göstermektedir.
Google Cloud Vision OCR'nin Öne Çıkan Özellikleri
Google OCR'nin çeşitli avantajları vardır, burada en önemli avantajlardan bazılarını açıklıyoruz:
- güçlü - Kullanıcıların kararına bağlı olarak iki tür metin belgesine hizmet eden iki işlev, Google Vision OCR'yi tek modelli OCR motorlarından nispeten daha sağlam kılar.
- Dil desteği - Belki de en büyük dil veri tabanına sahip olan Google, OCR'sinin 60'tan fazla dile uygulanabilir olmasını, birkaç düzine daha fazla denemeyi ve geri kalanların çoğunu başka bir dil koduna veya genel dil tanıyıcıya eşlemesini tavsiye etti.
- Kullanım kolaylığı - Modelin kendisi, yerleşik Google Vision kitaplığının bir parçasıdır. API anahtarını (neredeyse tüm OCR motorları için gerekli olan) yapılandırmanın biraz daha can sıkıcı sürecinden sonra, işlev çağırma yöntemi çok sayıda dilde çok basit bir şekilde kullanılabilir.
- Ölçeklenebilirlik - Google'ın fiyatlandırma stratejisi, daha fazla kullanım daha ucuz bir ortalama fiyat sağladığından, kullanıcıları API kullanımını artırmaya teşvik eder.
- Hız - Google Cloud'un depolama platformu, API kullanımına harika bir şekilde eşlik ediyor. Görüntüleri sürücüye yükleyerek API'nin yanıt süresi çok hızlı ve ölçeklenebilir olabilir.

Google Cloud Vision'ın eksikliklerinin üstesinden gelen bir OCR çözümü mü arıyorsunuz? Nanonetler verin™ daha yüksek doğruluk, daha fazla esneklik ve daha geniş belge türleri için bir dönüş!
alternatifler
Aşağıda, her bir hizmetin avantajları ve dezavantajları ile birlikte, Google Vision API dışındaki bazı alternatif OCR hizmetleri verilmiştir.
ABBYY
ABBYY FineReader PDF, ABBYY tarafından geliştirilen ve özellikle pdf okumaya odaklanan bir OCR'dir.
- Artıları: Fiyatlandırma daha küçük sektörlere (1000, 2000 sayfa, vb.) ayrıldığından ABBYY, bireysel kullanıcılar için çok daha uygun maliyetlidir. Ayrıca ticarileştirilmiş bir uygulama olduğu için mühendislik dışı müşterilere yöneliktir.
- Eksileri: Yazılım yalnızca PDF formatına odaklanır ve büyük ölçekli OCR yaparken fiyat çok pahalı hale gelir.
- Ne zaman kullanmalı: Yalnızca PDF'leri hızlı bir şekilde işlemek isteyen bireysel kullanıcılar için ABBYY, daha fazla esneklik sağlayan ancak ekstra kodlar gerektiren Google Vision API'den daha uygun bir seçenek olabilir.
Microsoft
Microsoft Azure ayrıca OCR için Okuma API'si sunar.
- Artıları: Microsoft, kullanılacak daha da fazla sayıda veri için daha ucuz bir fiyat sağlar. Azure bulut depolama, Google Cloud ile benzer hizmetler sunar.
- Eksileri: Ücretsiz katman yoktur, diğer seçenekler ise düşük kullanım için ücretsiz API çağrıları sağlar.
- Ne zaman kullanmalı: Çok büyük ölçekli OCR üretim hatları, Microsoft'un fiyatlandırmasından yararlanabilir.
Kofax
ABBYY'ye benzer şekilde, Kofax da PDF'lerin OCR okumasını sunar
- Artıları: Bireysel kullanım için fiyat sabit olup, işletmeler için indirim uygulanmaktadır. 24/7 müşteri desteği de sağlanmaktadır.
- Eksileri: Kalitenin ABBYY'ninki kadar yüksek olmadığı iddia ediliyor.
- Ne zaman kullanmalı: Düşük kullanım gereksinimleri olan küçük işletmeler.
AWS Metni
AWS Textract, Google Vision API'ye kıyasla çok benzer bir role sahiptir. Hizmetleri ve fiyatları çok benzer ve bu nedenle hangisinin benimseneceği tamamen müşteri tercihlerine bağlı.
Nanonetler
Daha önce tartışılan hizmetlerden farklı olarak, Nanonet'lerin OCR'leri, her bir veri türü (örn. makbuzlar, faturalar, ehliyetler) üzerinde eğitilmiş sağlam modeller ile belirli kategorilere ayrılmıştır.
- Artıları: Kategoriye özel OCR'ler, dolayısıyla firmalar hedefe özel uygulamalar için OCR'ye ihtiyaç duyduğunda doğruluk açısından daha da iyi sonuçlar sağlar.
- Eksileri: Nanonets OCR, son derece spesifik ve uyarlanmış modeller nedeniyle vahşi ortamlarda daha az uygulanabilir olabilir
- Ne zaman kullanmalı: Firmalar, faturalar gibi belirli bir veri türü için OCR'ye ihtiyaç duyuyorsa, Nanonet'ler uygun maliyetli ve son derece doğru bir seçenek olabilir.
Yapabilirsin Nanonets Online OCR'yi buradan deneyin.
Bulut Görüşüyle İlgili Sık Karşılaşılan Sorunlar
Bu son bölümde, Stackoverflow'tan belge tarama ve OCR ile ilgili bazı soruları ele almayı amaçlıyoruz.
Sinir ağlarını kullanarak belgeleri tanıma
Google OCR'nin tam kullanımı budur! Belgeleri taramak ve metin alma işlemini gerçekleştirmek için yukarıdaki adımları izleyin.
OCR'den Sonra En Önemli Ayrıntıları Yakalama
Herhangi bir belgenin içindeki en anlamlı içeriği ayrıştırma fikrine doğal dil işleme denir. Her belge bu tür bilgileri farklı formatlarda içerdiğinden, bunu yapmak için bazı ML yaklaşımlarının benimsenmesi tavsiye edilir. Tabii ki, tüm kartlar aynı formattaysa, belirli anahtar karakterlere sahip metinleri almak için kural tabanlı yöntemler de (örneğin, @ içeriyorsa bir e-postadır) çalışmalıdır.
Çevrimdışı çalışabilir mi?
Bağlantı: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Ne yazık ki hayır. API, Google Cloud OCR'yi uzaktan çağırır ve API ücretli olduğu için çevrimdışı çalışamazsınız.
Bir metnin kalın mı yoksa italik mi olduğunu algılayabilir mi?
Hayır. Google OCR büyük olasılıkla metin içeriğini kalın veya italik olsa bile algılayacaktır, ancak OCR modeli yazı tipi türlerini anlayacak şekilde tasarlanmamıştır.
Güncelleme: Okuyuculardan gelen sorgulara dayalı olarak daha fazla bilgi eklendi.
- &
- a
- hızlandırılmış
- Hesap
- doğru
- karşısında
- faaliyetler
- adres
- avantajları
- Türkiye
- alternatif
- alternatifleri
- her zaman
- tutarları
- analiz
- çözümlemek
- Başka
- api
- API'ler
- uygulamayı yükleyeceğiz
- uygulanabilir
- Uygulama
- uygulamaları
- uygulamalı
- yaklaşımlar
- ALAN
- etrafında
- göre
- Varlıklar
- Doğrulama
- otomatikleştirmek
- Otomatik
- ortalama
- masmavi
- Azure Bulutu
- arka fon
- Bankalar
- temel
- önce
- yarar
- faydaları
- fatura
- Engellemek
- pim
- Kitaplar
- sınır
- sonları
- araba
- Kartlar
- belli
- karakterler
- ücret
- yüklü
- daha ucuz
- denetleme
- Şehir
- sınıflandırma
- bulut
- bulut depolama
- kod
- ortak
- Şirketler
- şirket
- karşılaştırıldığında
- tamamen
- bilgisayar
- bilgisayarlar
- bağlı
- Düşünmek
- konsolos
- içeren
- içerik
- içindekiler
- Dönüştürme
- Kurumlar
- uyan
- maliyetler
- olabilir
- ülkeler
- ülke
- yaratmak
- çevrimiçi kurslar düzenliyorlar.
- Oluşturma
- akım
- müşteri
- Kullanıcı Desteği
- Müşteriler
- veri
- veri analizi
- veri işleme
- veritabanı
- veritabanları
- gün
- ilgili
- karar
- derin
- bağımlı
- bağlı
- tanımlamak
- tasarlanmış
- detaylı
- ayrıntılar
- algılandı
- Belirlemek
- gelişmiş
- farklı
- zor
- direkt
- direkt olarak
- Çeşitlilik
- Doktorlar
- evraklar
- etki
- aşağı
- sürücü
- sürme
- her
- kolaylaştırılması
- kenar
- çaba
- çabaları
- E-posta
- ortaya
- etkinleştirmek
- teşvik
- işletmelerin
- çevre
- özellikle
- esasen
- vb
- örnekler
- Çıkış
- Hulasa
- aileleri
- HIZLI
- Özellikler
- geribesleme
- Fiyatlandırma(Yakında)
- Finans
- mali
- Firma
- Ad
- sabit
- Esneklik
- odaklanır
- takip et
- takip etme
- biçim
- formlar
- bulundu
- Ücretsiz
- itibaren
- işlev
- fonksiyonlar
- daha fazla
- genel
- alma
- hükümet
- Hükümetler
- büyük
- sap
- yardım et
- okuyun
- Yüksek
- daha yüksek
- büyük ölçüde
- tarih
- Hastanelerinden olan İstanbul Cerrahi Hastanesi'nde
- Ne kadar
- Nasıl Yapılır
- HTTPS
- insan
- İnsanlar
- Fikir
- görüntü
- görüntüleri
- önemli
- imkânsız
- iyileştirmek
- dahil
- içerir
- Dahil olmak üzere
- bireysel
- bireyler
- bilgi
- bilgi
- örnek
- sezgisel
- sorunlar
- IT
- kendisi
- Java
- koruma
- anahtar
- emek
- dil
- Diller
- büyük
- büyük
- büyük
- İlanlar
- öğrenme
- seviye
- seviyeleri
- Kütüphane
- Lisans
- lisansları
- yaşam tarzı
- Muhtemelen
- LINK
- yerel
- yer
- yerleri
- Uzun
- makine
- makine öğrenme
- Makineler
- büyük
- yapmak
- tavır
- el ile
- Haritalar
- işaret
- masif
- anlam
- anlamlı
- tıbbi
- orta
- adı geçen
- yöntemleri
- Microsoft
- ML
- model
- modelleri
- para
- Ay
- Daha
- çoğu
- hareket
- çoklu
- Doğal (Madenden)
- Tabiat
- ihtiyaçlar
- ağ
- yine de
- notlar
- numara
- sayılar
- sayısız
- sunulan
- Teklifler
- resmi
- çevrimdışı
- Online
- optimize
- seçenek
- Opsiyonlar
- sipariş
- Düzenlenmiş
- Diğer
- kendi
- paketlenmiş
- otopark
- Bölüm
- belirli
- özellikle
- Geçen
- İnsanlar
- belki
- ağladım
- platform
- Polis
- Popüler
- güçlü
- fiyat
- fiyatlandırma
- süreç
- Süreçler
- işleme
- üretim
- Ürünler
- proje
- projeksiyonları
- umut verici
- promosyon
- sağlamak
- sağlanan
- sağlar
- sağlama
- alımları
- kalite
- hızla
- menzil
- değişen
- RE
- okuyucular
- Okuma
- son
- tanımak
- kayıtlar
- ilişkin
- bölge
- uzak
- gerektirir
- gereklidir
- Yer Alan Kurallar
- gerektirir
- araştırma
- Kaynaklar
- yanıt
- DİNLENME
- Sonuçlar
- yol
- Rol
- koşmak
- aynı
- ölçeklenebilir
- ölçek
- taramak
- tarama
- Sektörler
- duyu
- Dizi
- hizmet
- Hizmetler
- servis
- set
- ayar
- önemli
- İşaretler
- benzer
- Basit
- beri
- küçük
- So
- Yazılım
- katı
- çözüm
- biraz
- özel
- özellikle
- Dönme
- aşamaları
- başladı
- ifadeleri
- istatistiksel
- istatistik
- hafızası
- Stratejileri
- sokak
- yapılandırılmış
- destek
- Destekler
- Anket
- şartlar
- The
- bu nedenle
- İçinden
- boyunca
- zaman
- zamanlar
- bugün
- karşı
- geleneksel
- trafik
- Eğitim
- aktarma
- dönüşüm
- türleri
- altında
- anlamak
- anlayış
- birimleri
- Evrensel
- kullanım
- kullanıcılar
- genellikle
- çeşitli
- vizyonumuz
- hacim
- İzle
- olup olmadığını
- süre
- DSÖ
- Daha geniş
- pencereler
- içinde
- sözler
- İş
- çalışır
- olur
- X
- yıl